最近学习了3Blue1Brown的《线性代数的本质》系列视频和一点吴恩达老师的深度学习内容,于是想要尝试用一篇博客来记录我的学习成果
为了更好地深入理解深度学习的内容,我重新回顾线性代数的内容,并且尝试用几何的视角来理解线性代数
本篇博客会涉及线性代数中行列式,张成的空间,特征值和特征向量的内容和对深度学习的总的认识
向量表示和矩阵乘法
1.线性代数里,会把一个向量写成一个列向量 的形式,比方说=(a,b) 会写成
的形式,表示标准基
伸缩a倍,
伸缩b倍后相加的结果
2.其实一个矩阵的每一列都可以看作是一个基向量 ,比如说就可以看成是向量
=(a,b)和
=(c,d) 分别写成
和
,然后将他们按列排列
3.线性变换(伸缩,旋转,投影等)可以在标准坐标系下描述为一个变换矩阵,比方说矩阵,记作A,输入一个
=
,
要经历A变换得到
,写成
=x
+y
=
,得到
的过程本质上是
在空间做伸缩和旋转,在
方向上伸缩x倍得到
,在
方向上伸缩b倍得到
,将
和
合成得到
,看图可知,就是
经过伸缩旋转得到
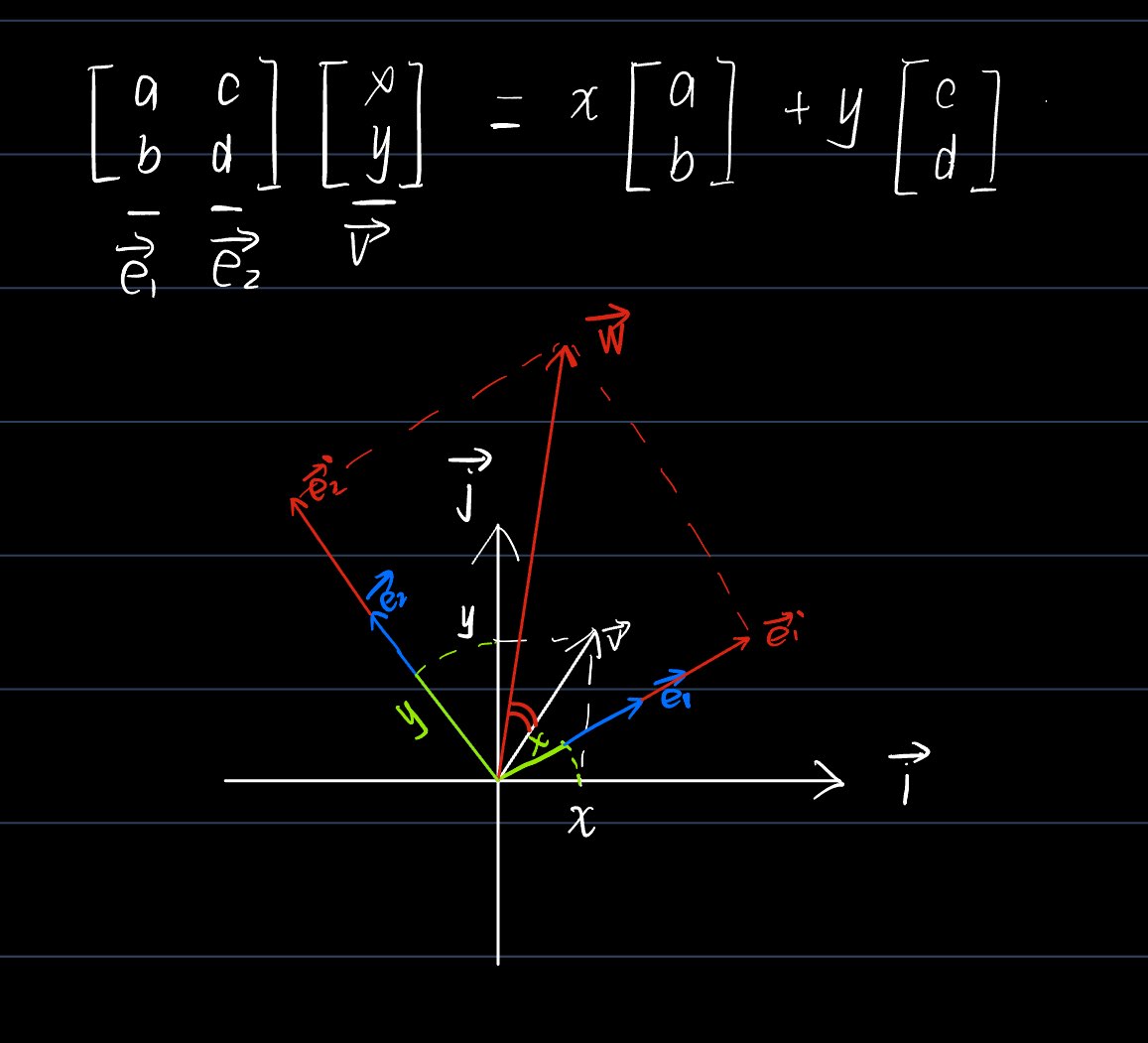
4.如果将这个换成一个矩阵,
,求这个矩阵经历A变换,就可以看做两个向量
,
分别经历A变换后再组合,即
=x1
+y1
=
和
=x2
+y2
=
,
得到=
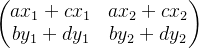
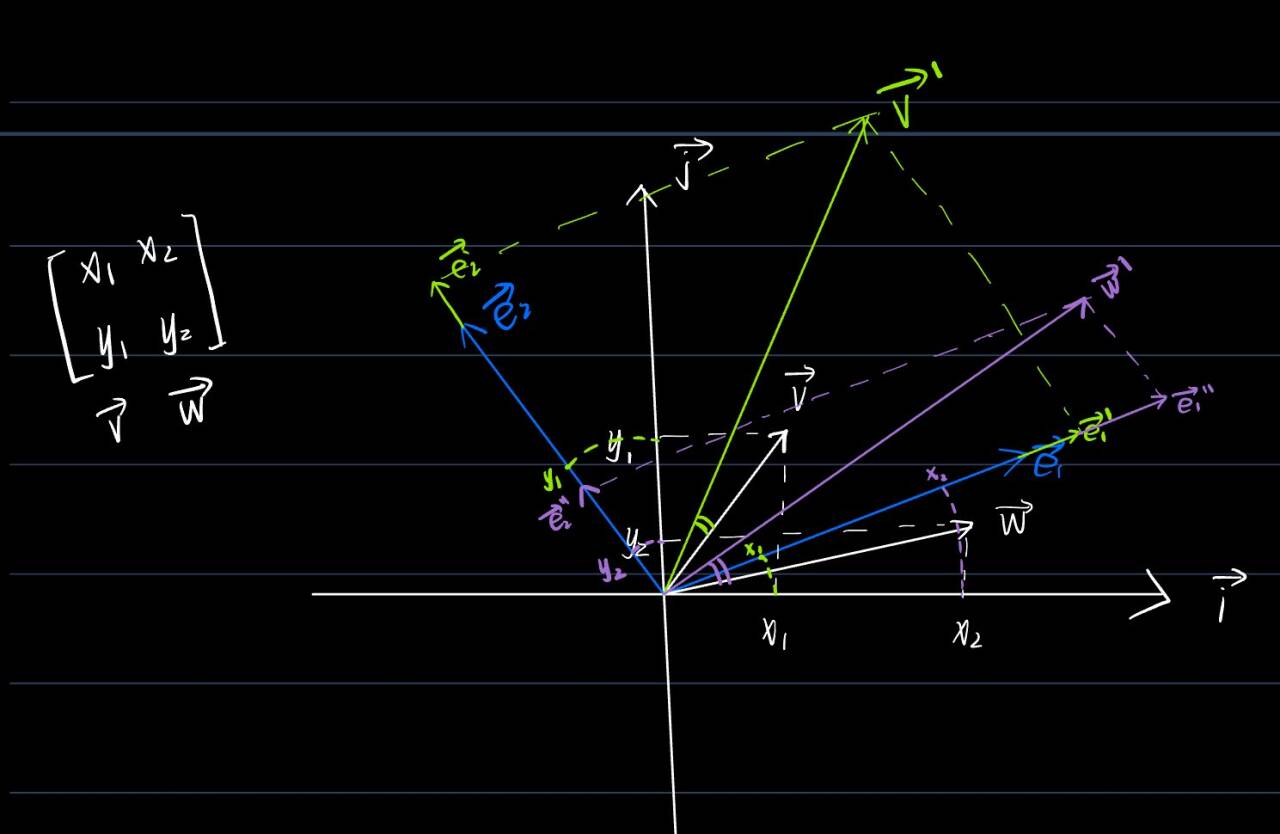
在图像上表示就是这样,得到矩阵经过A变换后得到新的一组基向量和
张成的空间
对于一个一维向量而言,可以用这个一维向量表示向量所在直线上的所有位置,它的张成空间就是这条直线上的所有位置
对于两个不共线的向量而言,可以用这两个向量作为一组基底,表示两个向量所在平面的所有位置,那么它们的张成空间就是整个平面
对于三个不共面的向量而言,可以用这三个向量作为一组基底,表示整个三维空间的所有位置,它们的张成空间就是整个三维空间
行列式,秩
为什么我上面要强调是不共线或者不共面的向量呢?
想象一下,如果那两个向量,
是共线的,那么其中一个向量就能用另一个向量来表示,比如
=c
,那么这两个向量是线性相关的,由于这两个向量都在同一条直线上,那么就不能用这两个向量来表示平面内的所有位置而只能表示这条直线上的所有位置,此时空间由二维被压缩为一维的
行列式=一个经历线性变换后空间面积或者体积的缩放倍数,因为上述两个向量的张成空间由二位被压缩为一维,面积变为0,那么两个向量组成的矩阵的行列式等于0
秩描述变换后列空间(所有列向量张成的空间)的维数,此时秩=1
特征向量和特征值
,假如对于一个矩阵A,它对应一个特征向量
,
经过矩阵A的线性变换等效于将
缩放
倍,也就是说,特征向量
在经历矩阵A的线性变换后没有离开
的张成空间,只是在原本所在的直线上进行缩放
如果对于一个矩阵A有多个特征向量,我们把这组特征向量作为一组基底,那么在这组基底下进行矩阵A的线性变换在各个基方向上是各自独立的,那么就可以使用这组特征基更加方便地计算。这里引入对角化,实现换基底,,A是变换作用在标准基下的表示,D是变换作用在特征基下的表示,P是特征基组成的矩阵在标准基下的表示,AP表示用标准坐标系下P进行矩阵A的线性变换,而AP左乘
则是为了将AP得到的矩阵用特征基来表示,由于各个特征基向量的方向是独立的,于是经历A变换只是在自己的方向上缩放特征值倍,这样的线性变换用矩阵表示成一个对角矩阵,类似
,这样就能在各个基方向上各不干扰地进行操作,怎么理解呢?拿标准正交基
和
作例子,有一个向量
=(x,y),在
方向上的投影有向长度是x,在
方向上的投影长度又向长度是y,如果要消掉在其中一个方向上的影响,直接置零就好了,因为
和
是正交的,是互不影响的,消去其中一个方向上的分量并不会影响另一个方向上的分量,假如我们选取的一组基不是正交的,把向量向这组基的两个方向上分解后,要消去其中一个分量,总会对另一个方向上的分量有影响。特征基也具有和标准正交基类似的特征,值得注意的事特征基不一定正交,但它们在线性无关的情况下能够作为一组基底,使矩阵表示变得更加简单。应用到pca图像处理比方说图像识别中,把一个特征向量看做一种特征,用特征值来描述特征的重要程度,有一些图像特征其实根本与图像识别没有联系,这些特征的重要程度很低(特征值很小),于是我们想要删掉这些特征,只保留真正有用的特征,但是前提是删掉这些特征不会影响到其他特征,而特征基各个基方向是独立的的特性恰恰符合这个要求。
深度学习是什么
深度学习听起来高大上,包含许多复杂的概念,好像是一个很庞大的体系,初学者不好理解,但是其实就是一个框架:
1.选定一个多层感知机制(神经网络层数,层的神经元数,激活函数)
2.输入x经过多层线性变换+激活函数运算得到预测值ŷ
3.这时输入x、真实输出y和预测值是已知的,参数是未知的,随机初始化参数
4.选定一个合适的损失函数(最小二乘法,交叉熵等)
5.根据梯度下降算法调整参数
以上内容均为个人理解,如有偏差,欢迎指教