本文适合谁:对线性代数完全陌生、或者曾经学过但早就忘光了的读者。不需要任何数学背景,只需要知道加法和乘法。目标是读完后能看懂"神经网络的本质是矩阵乘法"这句话的含义。
一、为什么要讲线性代数
先说一个不太直觉的事实:向量和矩阵根本不是AI发明的。它们出现在物理、工程、经济、图形学里,已经有几百年历史了。AI只是这些工具的一个应用场景。
但AI让这个工具变得极其重要,因为它帮AI解决了一个根本问题:计算机如何处理任何信息。
计算机只认识数字。一张图片、一段声音、一篇文章------在计算机眼里,这些都必须先变成数字,才能被处理。但光有一堆数字还不够,数字之间的关系同样重要:这两张图片有多像?这两个用户的兴趣有多接近?这两段文字说的是不是同一件事?
要回答这些问题,就需要对数字做有组织的、批量的数学运算------这正是线性代数的核心价值。
具体来说,AI里有三个需求,线性代数全解决了:
第一,表示数据。任何输入(图像、文字、用户行为)都可以用一组有序的数字来表示,叫做向量。这是统一的、计算机友好的数据格式。
第二,变换数据。神经网络的本质是把输入数据经过一系列变换,最终输出有意义的结果。每一次变换,在数学上就是一次矩阵乘法。
第三,批量处理。实际训练时,每次不是处理一个样本,而是几十、几百个同时处理。矩阵运算天然支持批量计算,还能充分利用GPU的并行能力。
所以,学线性代数不是为了应付考试,而是为了真正理解:神经网络的每一层到底在做什么。
二、向量:用坐标描述一切
向量就是坐标
先从最简单的直觉说起。
你用地图导航,你的位置可以用经度和纬度两个数字表示:[116.4, 39.9](北京大概的坐标)。这两个数字,有顺序、有意义,放在一起就是一个向量。
换一个例子。天气预报显示今天:温度28℃、湿度70%、气压1013hPa、风速15km/h。这四个数字打包在一起,就是描述今天天气的一个向量:[28, 70, 1013, 15]。
再换一个。描述一个用户的特征:年龄32岁、月消费金额1500元、最近30天登录次数20次、购买品类3个。打包在一起:[32, 1500, 20, 3]。这也是一个向量。
你看到规律了吗?向量就是"用一组有顺序的数字来描述一个事物的多个特征"。它不是抽象的数学概念,它就是你每天都在用的坐标系思维。
向量在AI中的应用
AI把这个思路推向了极致:任何东西都可以被向量化。
| 场景 | 向量的含义 | 维度 |
|---|---|---|
| 地图导航 | 位置坐标 [经度, 纬度] |
2维 |
| 天气预报 | [温度, 湿度, 气压, 风速] |
4维 |
| 用户画像 | [年龄, 消费金额, 活跃天数, ...] |
N维 |
| 图像像素 | 28×28的图片展开为784个数字 | 784维 |
| 文字语义 | 一段文字的语义表示 | 1536维(以OpenAI为例) |
为什么要把东西变成向量?
因为向量可以做数学运算。"猫"和"狗"只是两个字符,无法比较;但如果把它们都变成向量,就能用数学算出它们有多相似。这正是语义搜索和RAG(检索增强生成)的基础。
向量的基本运算
python
import numpy as np
a = np.array([1.0, 2.0, 3.0])
b = np.array([4.0, 5.0, 6.0])
# 加法:对应位置相加,物理意义是"合并两个向量的信息"
print(a + b) # [5. 7. 9.]
# 数乘:每个元素乘同一个数,效果是缩放长度不改变方向
print(2 * a) # [2. 4. 6.]
# 点积:对应位置相乘再求和,反映两个向量的"对齐程度"
print(np.dot(a, b)) # 1×4 + 2×5 + 3×6 = 32
# 向量长度(模):所有元素平方和的平方根
print(np.linalg.norm(a)) # √(1²+2²+3²) ≈ 3.74运行这段代码,你应该看到:
a + b输出[5. 7. 9.]2 * a输出[2. 4. 6.]- 点积结果是
32.0 - 向量长度约为
3.742
其中点积是最重要的运算。两个向量的点积越大,说明它们越"对齐",也就是越相似。这个性质在Transformer的注意力机制里至关重要------后面会讲到。
余弦相似度:衡量两个向量有多"像"
在语义搜索里,我们经常需要回答这个问题:这两段文字有多相似?
直觉上,相似度应该看"方向"而不是"长度"。一篇1000字的文章和一篇100字的摘要,如果说的是同一件事,向量长度不同,但方向应该相近。
余弦相似度专门度量方向的接近程度:
python
def cosine_similarity(a, b):
# 点积除以两个向量长度的乘积,结果在[-1, 1]之间
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
a = np.array([1.0, 2.0, 3.0])
print(cosine_similarity(a, a)) # 1.0:完全相同
print(cosine_similarity(a, -a)) # -1.0:完全相反
print(cosine_similarity(a, np.array([0.0, 0.0, 1.0]))) # 约0.8:有一定相似- 余弦相似度接近1:方向相同,非常相似
- 余弦相似度接近0:方向垂直,不相关
- 余弦相似度接近**-1**:方向相反
RAG的向量检索、语义搜索,用的就是这个公式。
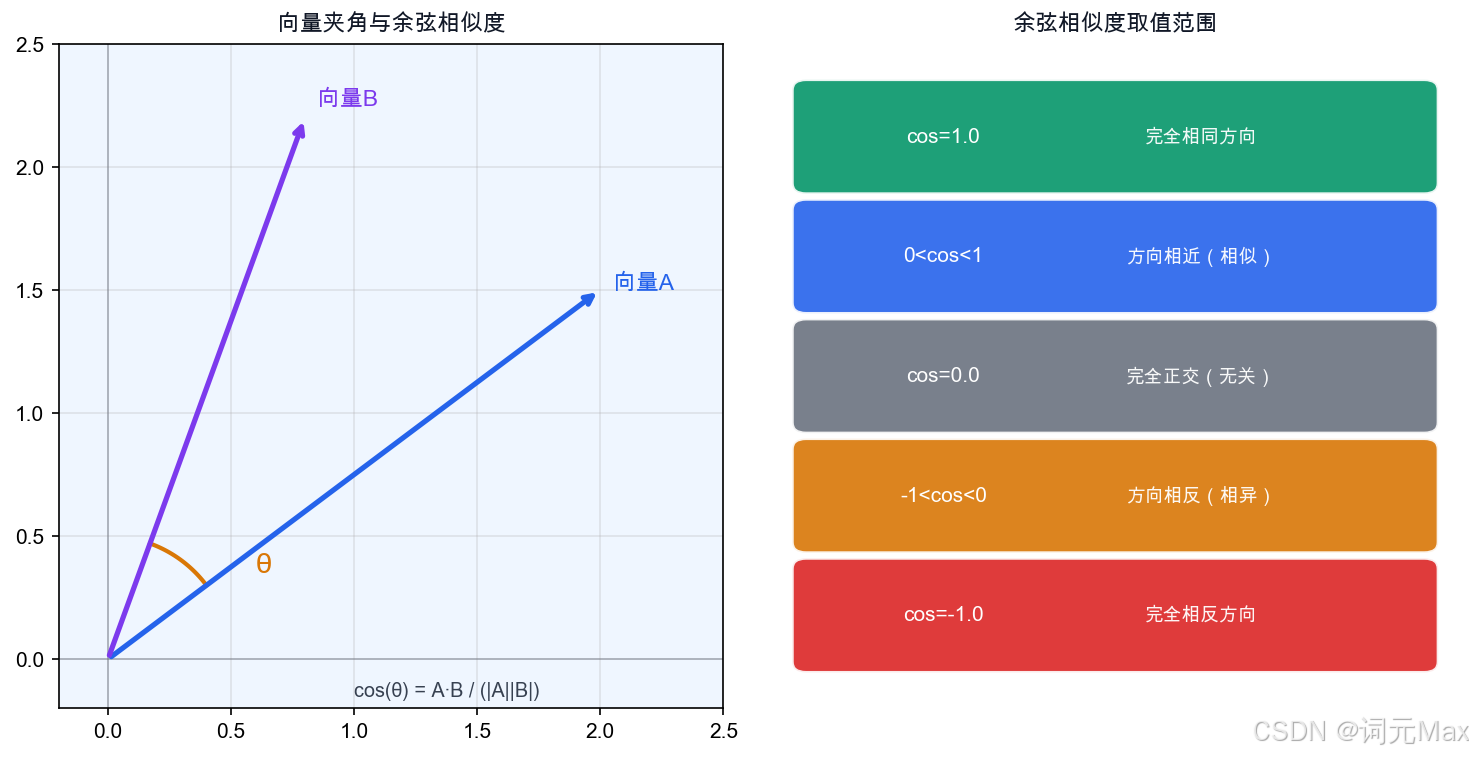
余弦相似度:向量夹角越小,语义越相近
难度提示:接下来的矩阵部分比向量稍难一点。如果感觉吃力,可以先跳过数学细节,记住核心结论:"矩阵乘法 = 神经网络的核心计算"。等后面遇到具体应用时再回来看,会更容易理解。
三、矩阵:二维的数字表格
矩阵的直觉:Excel表格
如果向量是"一列数字",那矩阵就是"多列数字拼在一起",形成一张二维的数字表格。
你用Excel管理用户数据:每行是一个用户,每列是一个特征(年龄、消费金额、活跃天数)。这个表格就是一个矩阵。
python
import numpy as np
# 一个3行4列的矩阵,代表3个用户、每人4个特征
M = np.array([
[32, 1500, 20, 3], # 用户A
[25, 800, 5, 1], # 用户B
[45, 5000, 30, 8] # 用户C
])
print(M.shape) # (3, 4):3行4列但矩阵不只是用来存数据的。它更重要的作用是描述变换------把一组向量从一个空间"变换"到另一个空间。
想象一台压缩机:把一个3维的向量放进去,出来变成了2维的。这个"压缩"操作,在数学上就是一次矩阵乘法。
神经网络的每一层,本质上就是一次矩阵乘法:接收输入向量,乘以一个权重矩阵,输出一个新向量。通过多层变换,网络逐渐把原始像素、词语变换成"有意义的特征表示"。
矩阵乘法:最重要的操作
先建立直觉。你有一个100个用户的数据集,每个用户有32个特征。现在你想从这32个特征中提取出更抽象的64个特征(比如"消费倾向"、"活跃程度")。
这个"提取特征"的过程,就是一次矩阵乘法:用一个32×64的权重矩阵,把32维特征映射到64维。而且这个操作可以对100个用户同时进行------批量处理,一次搞定。
矩阵乘法的规则:左矩阵的列数必须等于右矩阵的行数,输出矩阵的形状是(左矩阵行数,右矩阵列数)。
python
A = np.array([[1, 2],
[3, 4],
[5, 6]]) # 形状:3×2
B = np.array([[7, 8, 9],
[10, 11, 12]]) # 形状:2×3
C = A @ B # @ 是矩阵乘法运算符
print(C.shape) # (3, 3):结果是3×3矩阵
print(C)
# 输出:
# [[ 27 30 33]
# [ 61 68 75]
# [ 95 106 117]]下面是神经网络一层前向传播的完整示例:
python
# 实际意义:100个样本,每个32个特征
# 经过一层神经网络,变成64个特征
X = np.random.randn(100, 32) # 100个样本
W = np.random.randn(32, 64) # 权重矩阵
b = np.random.randn(64) # 偏置
output = X @ W + b # 一次矩阵乘法,批量处理100个样本
print(output.shape) # (100, 64)运行后你会看到 output.shape 是 (100, 64),说明100个样本同时完成了从32维到64维的变换。注意:这里没有用任何循环,矩阵乘法天然就是批量操作。
为什么GPU擅长矩阵乘法
矩阵乘法结果的每个位置,都是一次独立的点积运算,彼此完全不相关,可以同时进行。
GPU有几千个计算核心,可以同时并行执行大量乘加运算,一次性算出矩阵所有位置的值。CPU只有几十个核心,效率无法相比。
这就是深度学习需要GPU的根本原因------不是因为GPU"更快",而是因为矩阵乘法的数学结构天然适合GPU的并行架构。
四、Embedding:向量在文字处理中的应用
注意:这一节是向量在NLP(Natural Language Processing,自然语言处理,让计算机理解和生成人类语言的技术领域)的具体应用,第6章《Embedding向量化原理》会完整展开。这里只做概念引入。
文字本身无法做数学运算。"猫"和"狗",计算机看到的只是两串字符,没法计算它们有多相似。
如果直接给每个字分配一个编号(猫=1,狗=2,汽车=3......),又会引入错误的含义:数字2和1更接近,难道暗示"狗"比"汽车"更像"猫"?
Embedding(嵌入)解决了这个问题:把文字转换成高维向量,使得语义相近的词在向量空间里也位置相近。"猫"和"狗"的向量很接近,"猫"和"汽车"的向量距离较远。
python
# 概念示意(非真实代码)
# "猫" → [0.2, 0.8, -0.3, 0.5, ...] # 1536个数字
# "狗" → [0.3, 0.7, -0.2, 0.4, ...] # 和猫的向量很接近
# "汽车" → [-0.5, 0.1, 0.9, -0.2, ...] # 和猫的向量差距大有了向量表示,就能用余弦相似度计算"猫和狗有多像"------这是语义搜索、RAG检索等技术的数学基础。
五、Transformer中的线性代数
先别慌:这一节只是让你知道"Transformer是矩阵运算"这件事。看不懂公式完全正常,第5章会用完整的代码和图解来拆解它。
Transformer(一种主流神经网络架构,ChatGPT等大模型的基础)处理文字时,面对的问题是:每个词需要"关注"句子里的其他词,才能理解自己在这里的具体含义。
比如"苹果公司发布了新手机",这里的"苹果"是公司而不是水果,模型需要通过关注"公司"和"手机"这两个词来消歧义。
这个"每个词关注每个词"的过程,在数学上天然是一个矩阵运算。Transformer的注意力机制核心公式:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) × V用中文翻译这个公式在做什么:
- Q(Query,查询):当前这个词"想问什么"
- K(Key,键):句子里每个词"能回答什么"
- V(Value,值):句子里每个词"实际包含的信息"
想象你在图书馆找书(Q是你的问题,K是每本书的标题,V是书的内容)。你用问题和每本书标题做相似度比较(QK^T),找到最相关的书,然后按相关程度加权读取书的内容(× V)。
整个过程全是矩阵运算,这就是为什么GPU能大幅加速LLM推理。
现在只需要记住:注意力机制 = 矩阵运算 = GPU的强项。具体细节在第5章第5篇《Transformer架构详解》再深入。
六、完整实践代码
下面的代码把本文介绍的核心概念串联起来,验证向量运算、矩阵乘法以及神经网络一层前向传播:
python
import numpy as np
# === 1. 向量基本运算 ===
a = np.array([1.0, 2.0, 3.0])
b = np.array([4.0, 5.0, 6.0])
print("点积:", np.dot(a, b)) # 32.0
print("余弦相似度:", np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
# 约0.9746,说明这两个向量方向很接近
# === 2. 矩阵乘法 ===
A = np.random.randn(3, 4)
B = np.random.randn(4, 5)
C = A @ B
print("矩阵乘法结果形状:", C.shape) # (3, 5)
# === 3. 转置 ===
print("A的形状:", A.shape) # (3, 4)
print("A转置的形状:", A.T.shape) # (4, 3)
# === 4. 用矩阵乘法模拟一层神经网络 ===
batch_size = 32
input_dim = 128
output_dim = 64
X = np.random.randn(batch_size, input_dim) # 32个样本,每个128维
W = np.random.randn(input_dim, output_dim) # 权重矩阵
b = np.random.randn(output_dim) # 偏置向量
output = X @ W + b # 线性变换
print("神经网络一层输出形状:", output.shape) # (32, 64)运行这段代码,重点观察形状的变化:输入是(32, 128),权重是(128, 64),输出是(32, 64)。每个样本从128维变成了64维,而且32个样本是同时完成变换的。这就是神经网络一层的完整数学过程。
小结
| 概念 | 直觉理解 | 在AI中的作用 |
|---|---|---|
| 向量 | 一组有顺序的数字,就是坐标 | 表示特征、词语、图片的数字形式 |
| 矩阵 | 二维的数字表格,Excel那种 | 神经网络权重、批量数据处理 |
| 矩阵乘法 | 把一组向量批量变换到新空间 | 神经网络每一层的核心计算 |
| 余弦相似度 | 两个向量的夹角有多小 | 语义搜索、向量检索 |
| 转置 | 行列互换 | Transformer的注意力计算中用到 |
向量和矩阵是工具,不是AI专属。理解了它们的本质,你会发现它们出现在物理、经济、图形学的每个角落------AI只是其中一个应用场景。
核心结论:神经网络的训练和推理,本质上是大量矩阵乘法的串联执行。 理解这一点,你就理解了为什么AI需要GPU,为什么数据要转成向量,以及Transformer为什么能有效处理文字。
后续应用:本文知识将在以下章节直接用到:
- 第5章 Transformer架构详解(Q/K/V矩阵的完整代码实现)
- 第6章 Embedding向量化原理(文字如何变成向量的完整原理)
- 第16章 LoRA原理(低秩矩阵分解,直接用到矩阵的概念)
下一篇看微积分------模型是怎么"学习"的?