大模型的Context窗口是什么?怎么理解?------从原理到实战,一篇讲透
作者 :Weisian
发布时间:2026年4月

直击痛点:
"面试官:'大模型的Context窗口是什么?'你:'就是模型能处理的最大Token数......'面试官:'那为什么长窗口模型会忘记中间的内容?怎么解决?'你:'呃......可能是注意力机制的问题......'------这又是一个'知道定义但讲不清原理'的死亡问答:看似简单的概念,却能暴露你对大模型架构和工程落地的理解深度。"
在大模型开发与落地中,Context窗口(上下文窗口) 是决定模型能力上限的核心指标之一:
- 业务开发者:不懂窗口限制,导致长文档总结、多轮对话频繁截断;
- 算法工程师:不理解窗口底层机制,无法做长文本推理、RAG上下文管理;
- 产品经理:不清楚窗口大小的成本差异,盲目追求超大窗口抬高预算;
- 面试者:只会背窗口数值,讲不清原理、优化方案与工程实践。
解决方案:深入理解Context窗口的本质、限制原因、长上下文技术、以及实际应用策略,掌握一套逻辑严密、生动易懂的解释框架。

📌 核心一句话 :
Context窗口是大模型单次推理能接收、处理、记住的最大Token总量,相当于模型的"短期工作记忆",超过这个容量,模型就会"记不住"早期内容。------就像你一次能看几行字,超过这个范围的信息模型就会"忘记"。
📌 面试金句先记牢:
- Context窗口定义:模型单次交互可处理的最大Token数,是模型的短期记忆上限,单位为Token而非字符;
- 为什么有限制:受Transformer注意力机制复杂度O(n²),窗口翻倍,计算量翻4倍,显存翻4倍,是架构与硬件共同决定的硬上限;
- 溢出后果:早期内容被截断、遗忘,逻辑断裂、推理出错,RAG检索失效;
- 窗口分类:原生窗口、滑动窗口、扩展窗口(ROPE/NTK)、分页窗口,成本与效果依次平衡;
- 多轮对话陷阱:对话历史+新提问+系统提示+输出预留,共同占用窗口,越长越易溢出;
- RoPE(旋转位置编码):LLaMA、Qwen等主流模型使用,有外推能力;
- ALiBi(线性偏置注意力):用距离惩罚替代位置编码,外推能力强;
- 滑动窗口注意力:只关注附近Token,复杂度O(n×w),可处理超长序列;
- Lost in the Middle现象:模型更关注开头和结尾,中间内容容易遗忘;
- 窗口≠字数:中文1Token≈1.2~1.5汉字,英文1Token≈4字母,窗口大小决定可承载的语义信息量;
- 窗口与Token的关系:1K窗口≈750英文单词≈500-800汉字;
- RAG与窗口:检索片段+提示词+历史+输出 < 窗口大小,否则需要压缩。
- 优化核心:裁剪历史、摘要压缩、分块处理、窗口扩展、滑动窗口,解决溢出问题;
- 成本关联:窗口越大,参数量、显存占用、推理耗时、计费成本越高,并非越大越好;
- 技术本质:限定模型注意力覆盖的序列长度,控制计算量与内存开销的边界机制。
一、Context窗口到底是什么?------从"工作记忆"讲起
1.1 一句话概括
Context窗口(上下文窗口) :大模型在一次完整推理 中,能"看全、记住、计算关联"的最大Token数量,是模型短期工作记忆的物理上限。

1.2 通俗类比:工作记忆
想象你在读书:
| 窗口大小 | 类比 | 模型能力 |
|---|---|---|
| 1K窗口 | 一次只能看半页书 | 只能处理短信、简短问答 |
| 4K窗口 | 一次能看2-3页 | 可以处理短文章、邮件 |
| 8K窗口 | 一次能看5-6页 | 可处理中等长度文档(GPT-3.5级别) |
| 32K窗口 | 一次能看20页 | 可处理短篇小说 |
| 128K窗口 | 一次能看80页 | 可处理中篇小说(GPT-4级别) |
| 200K窗口 | 一次能看120页 | 可处理长篇小说(Claude级别) |
| 1M窗口 | 一次能看600页 | 可处理三体三部曲(Gemini级别) |
核心洞察:
Context窗口就像模型的"工作记忆"。你给它一本书,它只能同时"看"其中几页。超出窗口的内容,不是"记不住",而是"根本没看到"。

生活类比升级 :
把大模型比作学生 ,Context窗口就是学生的课桌:
- Token:课桌上的课本、笔记、习题纸;
- Context窗口大小:课桌能平铺摆放的资料总数量;
- 正常推理:学生能同时看到所有资料,联动理解、答题;
- 窗口溢出:资料太多堆不下,早期的课本被挤到地上,学生看不到,自然"记不住";
- 超大窗口:超大课桌,能摆更多资料,但价格更贵、占用空间更大、翻找更慢。
关键类比:课桌大小固定,资料只能摆这么多,多了必须扔掉一部分,这就是Context窗口的核心约束。

1.3 Context窗口的组成(必考点)
Context窗口只认Token,不认字符/字数,所有长度计算都以Token为基准:
上下文总Token = 系统提示Token + 对话历史Token + 用户新提问Token + 检索片段Token + 输出预留Token- 模型不关心你输入的是中文、英文还是代码,只统计总Token数;
- 总Token ≤ 窗口大小 → 正常推理;
- 总Token > 窗口大小 → 溢出截断/推理报错。
注意:
模型的 Context Window(上下文总 Token 窗口) = 本轮「所有输入 Token + 本轮所有输出 Token」的总和上限。不是只算输入,是输入 + 输出打包一起不能超窗口。

1.4 直观示例:不同窗口的承载能力
以通用模型、中文场景为例(1Token≈1.3汉字):
| 窗口大小 | 总承载Token | 约等于中文 | 适用场景 |
|---|---|---|---|
| 2K | 2048 | ≈2600汉字 | 简单问答、短句生成 |
| 8K | 8192 | ≈10600汉字 | 常规对话、短文总结 |
| 32K | 32768 | ≈42600汉字 | 长文档、多轮对话、中等RAG |
| 128K | 131072 | ≈17万汉字 | 长篇小说、复杂RAG、多工具Agent |
| 200K | 204800 | ≈26万汉字 | 超长篇文档、全量知识库检索 |

1.5 窗口不是"永久记忆"
重要误区:Context窗口≠长期记忆。
- 窗口是单次推理的短期工作记忆,只对当前请求有效;
- 对话结束后,模型不会保存任何内容,下一轮对话需重新传入完整历史;
- 想实现长期记忆,必须靠外部存储(Redis/数据库)+ RAG检索,而非依赖窗口。

二、为什么Context窗口有限?
2.1 根本原因:注意力机制的O(n²)复杂度
Transformer的核心是自注意力机制,每个Token需要与窗口内所有其他Token计算注意力:
复杂度分析:
- 窗口大小 = n
- 注意力计算量 = O(n²)
- 窗口翻倍 → 计算量翻4倍
- 显存存储 = O(n²)(需要存储注意力矩阵)数学直觉:
n=1K (1024): 计算量 ≈ 1M次
n=2K (2048): 计算量 ≈ 4M次 (4倍)
n=4K (4096): 计算量 ≈ 16M次 (16倍)
n=8K (8192): 计算量 ≈ 64M次 (64倍)
n=128K: 计算量 ≈ 16B次 (160亿次!)- n:序列长度(即Context窗口内的Token数);
- n翻倍 → 计算量翻4倍,显存占用翻4倍;
- n过大 → 显存爆仓、推理时间指数级增加、硬件无法支撑。
生活化类比 :
整理房间时,每一件物品都要和其他所有物品比对摆放位置。
- 10件物品:比对100次,轻松完成;
- 100件物品:比对10000次,耗时极长;
- 10000件物品:比对1亿次,根本无法完成。
Context窗口就是人为限定物品数量,让比对任务可执行。

2.2 显存瓶颈
以LLaMA 7B为例,不同窗口大小的显存需求:
| 窗口大小 | 注意力矩阵显存(FP16) | 总显存估算 |
|---|---|---|
| 2K | ~16MB | ~14GB |
| 4K | ~64MB | ~14.5GB |
| 8K | ~256MB | ~15GB |
| 16K | ~1GB | ~16GB |
| 32K | ~4GB | ~20GB |
| 64K | ~16GB | ~32GB |
| 128K | ~64GB | ~80GB |
大模型推理时,所有上下文Token的向量、注意力矩阵、中间结果都要加载到GPU显存:
- 窗口越大,占用显存越多;
- 7B模型8K窗口:占用约10GB显存;
- 7B模型128K窗口:占用约60GB+显存,消费级显卡无法运行。
类比:手机运行APP,后台开的程序(上下文)越多,占用内存越大,超过上限就会闪退。

2.3 训练成本约束
模型必须在对应窗口大小的语料上预训练/微调,才能正常使用:
- 训练2K窗口成本低、速度快;
- 训练128K窗口需要更长文本语料、更多算力、更长训练周期;
- 超大窗口模型的训练/推理成本,是小窗口的10倍以上。

2.4 窗口不是越大越好
| 窗口大小 | 优势 | 劣势 |
|---|---|---|
| 小窗口(2K/8K) | 推理快、显存占用低、成本低、适合实时交互 | 承载内容少,易溢出 |
| 大窗口(32K/128K) | 支持长文本、多轮对话、复杂RAG | 推理慢、显存占用高、成本高、延迟高 |
工程原则:够用即可,避免盲目追求超大窗口抬高成本。

2.5 位置编码的挑战
Transformer本身不感知Token顺序,需要位置编码告诉模型"谁在前谁在后"。
常见位置编码:
| 类型 | 原理 | 外推能力 | 代表模型 |
|---|---|---|---|
| 绝对位置编码 | 给每个位置分配固定向量 | 差(超出训练长度失效) | 原始Transformer |
| 相对位置编码 | 编码Token间距离 | 较好 | T5 |
| RoPE(旋转位置编码) | 旋转矩阵编码位置 | 好 | LLaMA、Qwen、GPT-NeoX |
| ALiBi | 注意力分数减去距离惩罚 | 很好 | Bloom |

三、Context窗口的组成:哪些内容会占用它?
很多开发者翻车,就是不知道所有输入内容都会占用窗口,而非只有用户提问。
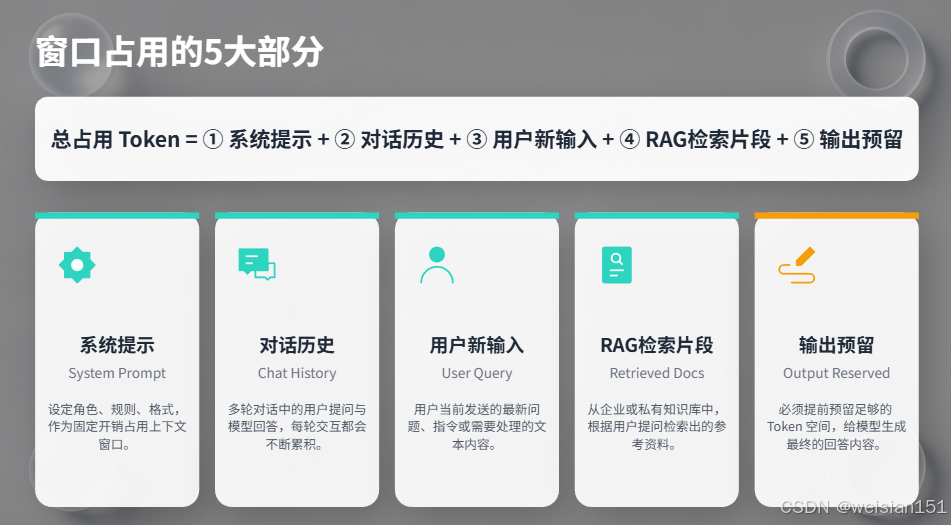
3.1 窗口占用的5大部分
总占用Token = ①系统提示 + ②对话历史 + ③用户新输入 + ④RAG检索片段 + ⑤输出预留- 系统提示(System Prompt)
设定角色、规则、格式,固定占用窗口,不可省略。 - 对话历史(Chat History)
多轮对话的用户提问+模型回答,每轮都会累积占用。 - 用户新输入(User Query)
当前最新的问题或指令。 - RAG检索片段(Retrieved Docs)
从知识库拉取的参考资料,是长文本场景的主要占用项。 - 输出预留(Output Reserved)
必须提前预留Token给模型生成回答,否则回答会被截断。
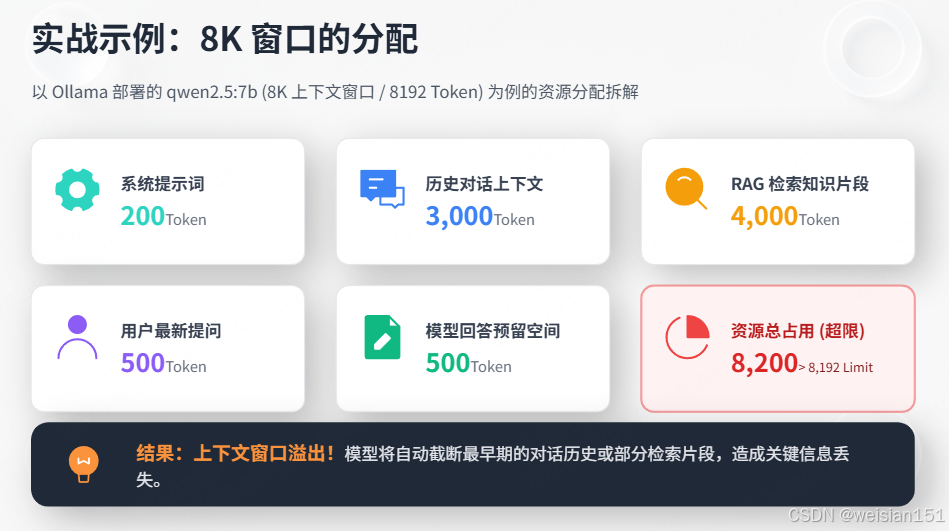
3.2 实战示例:8K窗口的分配
以Ollama部署的qwen2.5:7b(8K窗口)为例:
- 系统提示:200 Token
- 对话历史:3000 Token
- RAG检索片段:4000 Token
- 用户新输入:500 Token
- 输出预留:500 Token
- 总计:8200 Token > 8192 Token
- 结果:窗口溢出,早期对话历史/检索片段被截断。
3.3 可运行代码:计算上下文总Token(Ollama场景)
python
from transformers import AutoTokenizer
# 加载Qwen2.5分词器(适配Ollama qwen2.5:7b)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B", trust_remote_code=True)
def calculate_context_tokens(system_prompt: str, history: list, query: str, rag_docs: list) -> dict:
"""
计算上下文各部分Token占用,判断是否溢出
:param system_prompt: 系统提示词
:param history: 对话历史 [(user, ai), ...]
:param query: 用户新提问
:param rag_docs: RAG检索文档列表
:return: 各部分Token数+总占用+是否溢出
"""
# 1. 系统提示Token
sys_tokens = len(tokenizer.encode(system_prompt))
# 2. 对话历史Token
history_text = ""
for user_msg, ai_msg in history:
history_text += f"用户:{user_msg}\nAI:{ai_msg}\n"
hist_tokens = len(tokenizer.encode(history_text))
# 3. 用户新输入Token
query_tokens = len(tokenizer.encode(query))
# 4. RAG文档Token
rag_text = "\n".join(rag_docs)
rag_tokens = len(tokenizer.encode(rag_text))
# 5. 输出预留(固定500 Token)
output_reserve = 500
# 总计
total_tokens = sys_tokens + hist_tokens + query_tokens + rag_tokens + output_reserve
# 模型窗口大小(qwen2.5:7b默认8K)
context_window = 8192
return {
"系统提示": sys_tokens,
"对话历史": hist_tokens,
"用户提问": query_tokens,
"RAG片段": rag_tokens,
"输出预留": output_reserve,
"总占用": total_tokens,
"窗口大小": context_window,
"是否溢出": total_tokens > context_window
}
# 测试示例
if __name__ == "__main__":
result = calculate_context_tokens(
system_prompt="你是专业的技术文档助手,精准回答用户问题",
history=[("什么是Token?", "Token是模型最小语义单元")],
query="结合文档讲一下Context窗口优化",
rag_docs=["Context窗口是模型最大处理Token数,溢出会截断内容", "优化方式包括裁剪历史、分块检索、窗口扩展"]
)
print("📊 上下文Token占用明细:")
for k, v in result.items():
print(f"{k}:{v}")四、Context窗口溢出会怎样?严重后果
4.1 四大典型溢出后果
- 早期内容遗忘
模型只记住窗口后半部分内容,前面的对话、资料完全"失忆"。 - 逻辑断裂推理错误
无法关联前后文,回答前后矛盾、答非所问。 - RAG检索失效
关键参考资料被截断,模型只能瞎编。 - 输出被强制截断
回答写到一半突然停止,语句不完整。

4.2 生活化类比:听报告记笔记
- 笔记本(Context窗口)只有10页;
- 报告前9页讲核心原理,第10页讲结论;
- 你只能记10页,记满后前面的内容被擦掉;
- 最后你只记住结论,完全不知道原理,自然讲不清楚。

4.3 溢出后的默认处理策略
主流大模型(Ollama/OpenAI/Claude)默认规则:
从前往后截断 → 保留最新内容,删除最早内容。
- 多轮对话:删掉早期对话;
- RAG场景:删掉早期检索片段;
- 长文本:删掉文本开头部分。

五、不同模型的Context窗口
5.1 主流模型窗口对比
| 模型 | 窗口大小 | 技术 | 备注 |
|---|---|---|---|
| GPT-3.5 | 4K-16K | 标准Transformer | 早期版本4K,后续16K |
| GPT-4 | 8K-128K | 未知 | 8K/32K/128K版本 |
| GPT-4 Turbo | 128K | 优化架构 | 约300页文档 |
| Claude 3 | 200K | 优化架构 | 约500页 |
| Claude 3.5 | 200K | 优化 | - |
| LLaMA 2 | 4K | RoPE | 可外推到8K+ |
| LLaMA 3 | 8K | RoPE | 可外推到128K |
| Qwen 2.5 | 32K-128K | RoPE+NTK | 7B:32K, 72B:128K |
| DeepSeek | 128K | MLA | 高效注意力 |
| Gemini 1.5 | 1M | 稀疏注意力 | 约1500页 |
| Mistral | 32K | 滑动窗口 | 高效长文本 |
5.2 窗口大小与能力的关系
| 窗口大小 | 相当于 | 适用场景 |
|---|---|---|
| 1K | 750英文词 / 500汉字 | 短信、简短问答 |
| 4K | 3000词 / 2000汉字 | 邮件、短文 |
| 8K | 6000词 / 4000汉字 | 短篇论文、博客 |
| 32K | 24000词 / 16000汉字 | 短篇小说 |
| 128K | 96000词 / 64000汉字 | 中篇小说(《老人与海》约5万字) |
| 200K | 150000词 / 100000汉字 | 长篇小说(《了不起的盖茨比》约5万字) |
| 1M | 750000词 / 500000汉字 | 三体三部曲(约90万字) |

六、长窗口技术:如何突破限制?
6.1 滑动窗口注意力(Sliding Window Attention)
原理:每个Token只关注附近w个Token,不关注全窗口。
复杂度:O(n × w),w远小于n| 窗口大小 | 全注意力 | 滑动窗口(w=4K) |
|---|---|---|
| 32K | O(1B) | O(128M) |
| 128K | O(16B) | O(512M) |
代表模型:Mistral、Qwen(部分层使用)

python
def compare_attention_complexity(n, window_size=4096):
"""对比全注意力和滑动窗口的复杂度"""
full = n ** 2
sliding = n * window_size
print(f"n={n}: 全注意力={full/1e6:.1f}M, 滑动窗口={sliding/1e6:.1f}M, 节省={full/sliding:.1f}x")
print("📊 滑动窗口注意力效果")
print("=" * 50)
for n in [8192, 16384, 32768, 65536, 131072]:
compare_attention_complexity(n)6.2 稀疏注意力(Sparse Attention)
原理:只计算部分注意力对,如:
- 局部注意力:看附近Token
- 全局注意力:少数Token看全窗口
- 随机注意力:随机采样

6.3 线性注意力(Linear Attention)
原理:将O(n²)降为O(n):
传统: Attention(Q,K,V) = softmax(QK^T) × V
线性: 将softmax分解为 φ(Q) × φ(K)^T,利用矩阵乘法结合律
6.4 位置编码外推
RoPE的外推能力:
| 训练长度 | 模型 | 可外推长度 | 技巧 |
|---|---|---|---|
| 2K | LLaMA 7B | 8K+ | 直接外推 |
| 2K | Qwen 7B | 32K+ | NTK缩放 |
| 4K | LLaMA 2 | 32K+ | 线性缩放 |
| 8K | LLaMA 3 | 128K+ | RoPE + 缩放 |
NTK缩放:改变旋转角度的频率,让模型"感觉"窗口被压缩了。

七、Context窗口的工程实践
7.1 RAG中的窗口管理
核心原则:检索片段 + 系统提示词 + 历史对话 + 输出 < 窗口大小

python
def rag_context_manager(query, retrieved_docs, system_prompt="", max_window=8192):
"""RAG中的Context窗口管理"""
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
# 计算各部分Token
query_tokens = len(enc.encode(query))
system_tokens = len(enc.encode(system_prompt))
# 预留输出空间(约500 Token)
reserved_output = 500
available_for_docs = max_window - query_tokens - system_tokens - reserved_output
print(f"📊 RAG Context管理")
print(f"总窗口: {max_window} Token")
print(f"系统提示: {system_tokens} Token")
print(f"用户查询: {query_tokens} Token")
print(f"预留输出: {reserved_output} Token")
print(f"可用文档: {available_for_docs} Token")
# 按相关性排序,选择文档直到填满窗口
selected_docs = []
current_tokens = 0
for doc in retrieved_docs:
doc_tokens = len(enc.encode(doc))
if current_tokens + doc_tokens <= available_for_docs:
selected_docs.append(doc)
current_tokens += doc_tokens
else:
# 尝试截断最后一个文档
remaining = available_for_docs - current_tokens
if remaining > 100:
truncated = enc.decode(enc.encode(doc)[:remaining])
selected_docs.append(truncated)
break
print(f"实际使用文档: {len(selected_docs)}个, {current_tokens} Token")
print(f"窗口利用率: {(query_tokens + system_tokens + current_tokens) / max_window:.1%}")
return selected_docs7.2 对话历史管理策略
| 策略 | 原理 | 适用场景 |
|---|---|---|
| 先进先出(FIFO) | 删除最早的消息 | 通用聊天 |
| 滑动窗口 | 保留最近N轮 | 短期记忆场景 |
| 摘要压缩 | 用LLM总结历史 | 长对话,保留关键信息 |
| 重要性评分 | 保留重要消息 | 复杂任务 |
| 混合策略 | 保留开头+最近 | 平衡 |

python
def sliding_window_history(history, max_tokens=4000, keep_first=True):
"""滑动窗口管理对话历史"""
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
# 计算历史总Token数
total_tokens = sum(len(enc.encode(msg)) for msg in history)
if total_tokens <= max_tokens:
return history
# 需要裁剪
if keep_first:
# 保留第一条消息 + 最近的消息
first_msg = history[0]
remaining = history[1:]
first_tokens = len(enc.encode(first_msg))
available = max_tokens - first_tokens
# 从后往前加消息
selected = [first_msg]
current = first_tokens
for msg in reversed(remaining):
msg_tokens = len(enc.encode(msg))
if current + msg_tokens <= available:
selected.append(msg)
current += msg_tokens
else:
break
return selected
else:
# 只保留最近的消息
selected = []
current = 0
for msg in reversed(history):
msg_tokens = len(enc.encode(msg))
if current + msg_tokens <= max_tokens:
selected.append(msg)
current += msg_tokens
else:
break
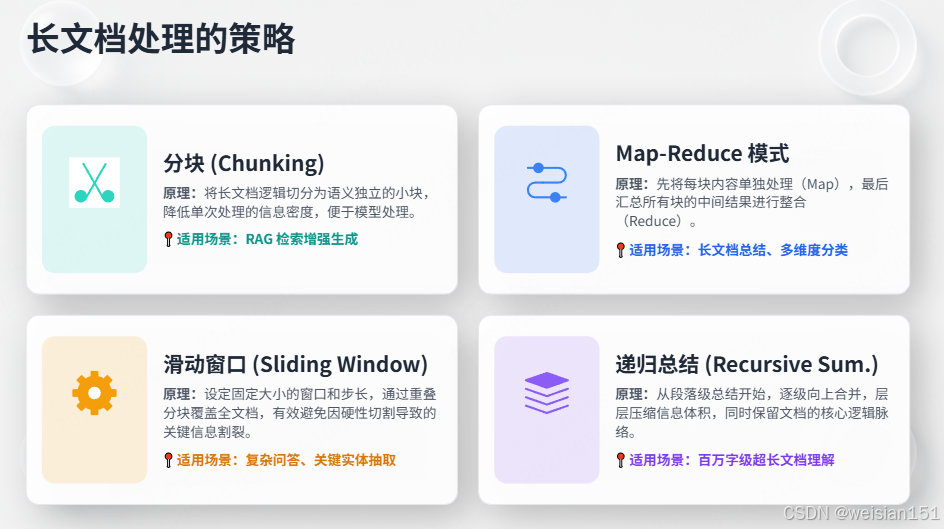
return list(reversed(selected))7.3 长文档处理的策略
| 策略 | 原理 | 适用场景 |
|---|---|---|
| 分块(Chunking) | 将长文档切成小块 | RAG检索 |
| Map-Reduce | 每块单独处理,汇总结果 | 总结、分类 |
| 滑动窗口 | 重叠分块,覆盖全文档 | 问答、实体抽取 |
| 递归总结 | 逐级总结,压缩信息 | 超长文档理解 |
python
def chunk_document(text, chunk_size=2000, overlap=200):
"""将长文档分块"""
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
tokens = enc.encode(text)
chunks = []
for i in range(0, len(tokens), chunk_size - overlap):
chunk_tokens = tokens[i:i + chunk_size]
chunk_text = enc.decode(chunk_tokens)
chunks.append(chunk_text)
print(f"📄 文档分块结果")
print(f"原文Token数: {len(tokens)}")
print(f"分块大小: {chunk_size} Token, 重叠: {overlap} Token")
print(f"分块数量: {len(chunks)}")
return chunks八、面试高频题详解
Q1:Context窗口是什么?为什么有限制?
参考答案 :
Context窗口是模型单次推理能处理的最大Token数量,相当于模型的"工作记忆"。
限制原因:
- 注意力复杂度O(n²):窗口翻倍,计算量翻4倍
- 显存瓶颈:注意力矩阵占用O(n²)显存
- 位置编码外推限制:超出训练长度位置编码失效
生活类比:就像你的短期记忆,一次能记住7±2个数字------这是认知限制。

Q2:RoPE是什么?为什么重要?
参考答案 :
RoPE(旋转位置编码)是一种位置编码方法,通过旋转矩阵编码Token位置,让注意力只依赖相对距离。
重要性:
- 有外推能力:训练在4K,可以推到32K+
- 主流模型使用:LLaMA、Qwen、GPT-NeoX
- 配合NTK缩放可进一步扩展窗口

Q3:什么是"Lost in the Middle"现象?
参考答案 :
模型在长窗口中更关注开头和结尾,对中间内容容易遗忘。
原因:
- 注意力分布自然偏向开头和结尾
- 位置编码的中间区域区分度低
- 训练数据中重要信息多在开头/结尾
缓解方法:
- 重复关键信息
- 分块+总结
- RAG检索相关片段

Q4:长窗口模型有什么缺点?
参考答案:
- 推理更慢:O(n²)计算量
- 显存更大:需要存储更多KV Cache
- Lost in Middle:中间信息易遗忘
- 成本更高:API按Token计费
- 并非总是需要:大多数任务不需要超长窗口

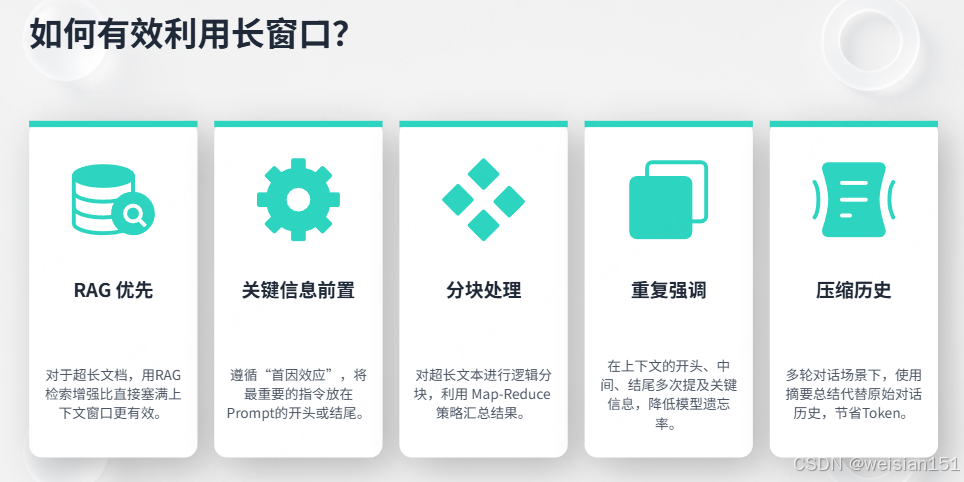
Q5:如何有效利用长窗口?
参考答案:
- RAG优先:对于超长文档,用RAG检索比塞满窗口更有效
- 关键信息前置:重要指令放在开头或结尾
- 分块处理:超长内容分块,Map-Reduce
- 重复强调:重要信息在开头、中间、结尾都提
- 压缩历史:多轮对话用摘要替代原始历史
九、话术速查表
| 问题类型 | 回答时间 | 核心要点 |
|---|---|---|
| Context窗口是什么 | 10秒 | 模型单次能处理的Token数,即"工作记忆" |
| 为什么有限制 | 20秒 | O(n²)复杂度 + 显存瓶颈 + 位置编码 |
| RoPE是什么 | 15秒 | 旋转位置编码,支持长度外推 |
| Lost in Middle | 20秒 | 模型记不住中间内容,只关注开头结尾 |
| 窗口大小对比 | 15秒 | 8K≈6K词,128K≈96K词,1M≈750K词 |
| 长窗口缺点 | 15秒 | 更慢、更贵、中间易忘 |
| 如何选窗口 | 20秒 | 够用就好,普通任务8-32K足够 |
| RAG与窗口 | 15秒 | 检索片段+提示词+输出 < 窗口 |
| 历史管理 | 15秒 | FIFO、摘要压缩、滑动窗口 |
| 外推技术 | 15秒 | RoPE、ALiBi、NTK缩放 |
总结
核心知识点速记
Context窗口是工作记忆,一次能看多少Token。
O(n²)复杂度,窗口翻倍计算四倍。
RoPE旋转编码好,训练4K推32K。
长窗口有Lost Middle,开头结尾记得清,中间内容常遗忘。
8K约六千英文词,128K能读中篇小说。
RAG检索优先用,别把窗口全填满。
对话历史要管理,摘要压缩省空间。核心要点回顾
- Context窗口定义:模型单次推理能处理的Token数,即"工作记忆";
- 限制原因:注意力O(n²)复杂度 + 显存瓶颈 + 位置编码限制;
- RoPE:旋转位置编码,主流模型使用,支持长度外推;
- Lost in Middle:模型更关注开头结尾,中间内容易遗忘;
- 窗口大小对比:1K≈750英文词,8K≈6K词,128K≈96K词;
- 长窗口缺点:推理慢、显存大、成本高、中间易忘;
- RAG与窗口:检索片段+提示词+输出 < 窗口大小;
- 历史管理:FIFO、摘要压缩、滑动窗口;
- 外推技术:RoPE、ALiBi、NTK缩放;
- 最佳实践:够用就好,优先RAG,关键信息放两端。

写在最后
Context窗口看似只是一个"容量参数",但讲透它需要理解注意力机制的复杂度、位置编码的原理、长窗口的技术挑战、以及工程落地的权衡。面试官问Context窗口,不是在考"大小多少",而是在考察:
- 对模型架构的理解------知道为什么O(n²)是瓶颈
- 工程化思维------知道RAG和长窗口怎么配合
- 实际问题解决能力------知道Lost in Middle怎么缓解
记住:能讲清楚Context窗口的人,大模型应用架构设计、成本优化、性能调优都不会差。
如果觉得有帮助,欢迎点赞、收藏、转发!有问题欢迎在评论区留言交流。