一、背景与目标
本方案旨在针对文件下载接口建立一套可闭环的性能压测与资源监控机制。整体测试流程分为"缓存预热"与"正式并发压测"两个核心阶段,其各自承载着不同的战略目标:
1、阶段一:缓存预热阶段(消除磁盘 I/O 噪声)
文件下载服务属于典型的 I/O 密集型业务。预热的核心目的不是探查并发极限,而是通过低并发的常态化请求,提前将目标文件从底层物理磁盘加载到操作系统的 Page Cache(内存页缓存) 中。从而在后续的正式压测中,排除由于硬盘寻道、读盘延迟带来的非必要资源噪声,确保性能数据纯净、可信。
2、阶段二:正式压测阶段(探明吞吐容量与系统边界)
在确保缓存命中、全链路进入基于内存的数据发送状态后,启动并发压测。核心目的如下:
验证业务容量:获取系统在目标并发条件下的真实 TPS(每秒完成下载事务数)、TTFB(首字节响应时间)及平均下载耗时,检验是否满足验收标准。
摸清资源边界:通过持续的高压流量,实时观测服务器的 CPU、内存、磁盘 I/O(IOWait)以及网卡发送(Network Transmit)吞吐上限,定位全链路的性能瓶颈,为后续架构扩容或配置调优(如 Buffer 优化、引入 CDN)提供数据支撑。
二、整体结构
1、压测工具(JMeter)
仅使用两套脚本:
- 预热脚本(功能验证 + 预热)
- 正式压测脚本(性能测试)
2、监控系统(只用于观测)
- Node Exporter
- Prometheus
- Grafana(1860 Dashboard)
3、被测系统
- 文件下载服务(Nginx / Spring Boot)
- Linux 操作系统(Page Cache 机制)
三、预热脚本执行方案
阶段一:调试阶段(GUI模式)
✔ 目标
验证接口正确性,确保文件内容无误。
✔ JMeter组件状态
| 组件 | 状态 |
|---|---|
| Thread Group(预热脚本) | 开启 |
| Aggregate Report | 开启 |
| Assertion Results | 开启 |
| View Results Tree | 开启 |
| MD5校验 | 开启 |
✔ 校验
- HTTP 状态码 = 200
- 文件大小正确
- MD5 校验通过
- 无断言失败
阶段二:预热阶段(Non-GUI模式)
✔ 目标
通过低并发循环请求,将文件加载进入 Page Cache。
✔ JMeter配置
| 项目 | 配置 |
|---|---|
| 线程数 | 1 ~ 5 |
| Ramp-Up | 低速 |
| 运行方式 | 持续循环请求 |
❌ 必须关闭组件
- View Results Tree
- Assertion Results
- MD5 校验
- responseData / samplerData
四、预热阶段监控指标体系(Prometheus + Grafana)
1、核心指标
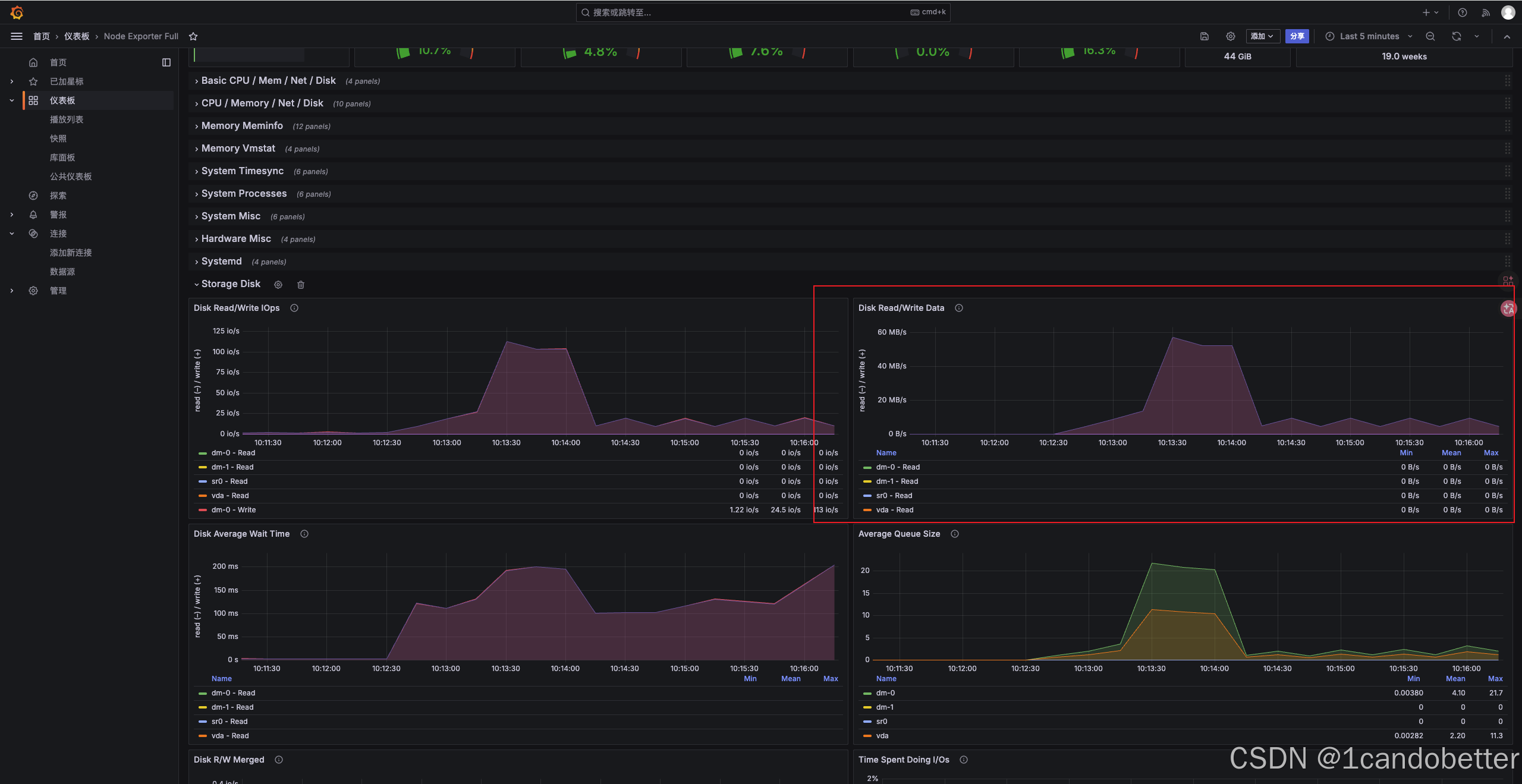
Disk Read Bytes(Node Exporter)
用于判断磁盘是否仍在读取文件。可以参考 Grafana 中 Storage Disk 大项下的 Disk Read/Write Data 表盘,重点关注 Read Data 曲线(磁盘读取速率,单位:MB/s)。
-
核心作用:在文件下载服务的压测中,用于精准观测 Page Cache(内存页缓存) 的命中状态与生效时机。
-
高能现象解读:当大并发下载流量持续高位爆发(如 Network Transmit 保持满载)时,若 Read Data 曲线从前期的波峰出现断崖式下跌,并最终持续收敛、贴近低位(甚至接近 0 B/s),说明文件已全部进入内存缓存。系统此时已断开对物理硬盘的依赖,转为纯内存秒发,处于最理想的性能状态。
-
异常判定 :若压测全程 Read Data 保持高位震荡且无法回落,说明 Page Cache 未能有效命中,需警惕物理磁盘 I/O 成为全局性能瓶颈。
未预热状态
- 指标持续增长
- 明显波动
预热完成状态
- 接近 0
- 长时间稳定不再增长
2、边界条件
该方案执行前提:
目标文件总大小 < 服务器可用内存(Page Cache 可容纳范围)
如果出现以下情况:
- 文件过大(如几十 GB)
- 或测试文件总量远超内存
Linux Page Cache 会触发 LRU 淘汰机制:
- 文件不断被换出缓存
- 磁盘持续重复读取
- Disk Read Bytes 无法趋近 0
结论
❌ 此时不适用"预热完成"
✔ 应直接进入磁盘 I/O 性能压测模式
3、辅助指标(用于稳定性判断)
响应时间(RT)
来源:JMeter
- 波动 < 10%
- 整体趋于稳定
CPU 使用率
来源:Grafana
- 无持续上升趋势
- 无异常波动
内存缓存(Page Cache)
- Cached 内存逐步上升
- 最终趋于稳定
五、预热完成判定
当同时满足以下条件时,认为预热完成:
- Disk Read Bytes ≈ 0 并保持稳定
- RT 进入稳定区间(波动 < 10%)
- CPU 无持续变化趋势
- Page Cache 进入稳定状态
六、正式压测阶段执行方案
1、目标
在完成缓存预热后,启动正式并发压测。本阶段旨在探明系统在目标并发负载下的常态吞吐能力与资源边界,通过对业务表现与服务器底层资源的双向观测,验证系统是否能够达到生产环境的验收标准,并精准捕获可能存在的性能瓶颈。
2、JMeter配置
| 组件 | 状态 |
|---|---|
| Thread Group(压测脚本) | 开启 |
| Summariser | 开启 |
| 响应状态码断言 | 开启 |
| 响应大小校验 | 开启 |
必须关闭的组件
- View Results Tree
- Assertion Results
- MD5校验
- responseData保存
- samplerData保存
- Debug日志输出
说明:上述组件会显著增加压测机CPU、内存及磁盘IO开销,可能导致压测机本身成为性能瓶颈,影响测试结果准确性。
3、JMeter性能防护
调整 JMeter 日志级别:
text
log_level.jmeter=WARN或:
text
log_level.jmeter=ERROR避免:
- 日志刷屏
- CPU资源被日志消耗
- 磁盘空间快速增长
- 压测机成为瓶颈
4、监控系统与指标观测
压测过程中需同时结合 JMeter 与 Grafana 进行指标观测。
| 指标类型 | 关注指标 | 查看位置 |
|---|---|---|
| 业务指标 | 成功率、TTFB、下载耗时、TPS | JMeter |
| 资源指标 | CPU、IO Wait、内存、网络带宽 | Grafana |
(1)JMeter业务指标
压测结束后,通过 JTL 文件生成 HTML Report 进行分析。需要重点关注以下指标,具体数值根据具体情况而定:
| 验收指标 | JMeter指标 |
|---|---|
| 成功率 ≥ 99% | Error % |
| 90% Latency(TTFB) ≤ 1s | 90th Percentile Latency |
| 平均下载耗时 ≤ 3s | Average Response Time(Avg) |
| TPS/吞吐能力 | Throughput |
说明:
- Latency(TTFB)表示收到第一个字节所需时间。如果 Latency 很高,说明服务器压力大、网络建连慢或后端业务代码(如 Spring Boot 读磁盘)卡顿。
- Response Time表示整个文件下载完成耗时。如果 Latency 很低(如 50ms)但 RT 很高(如 5s),说明服务器响应很快,但传输文件太慢。瓶颈通常在服务器出口带宽打满、或网络传输效能低。
- 文件下载场景需同时关注Latency与Response Time。
成功率 ≥ \ge ≥ 99% → \rightarrow → Error %
在 JMeter 的 HTML 报告(Statistics 表)中,该字段显示的名称是 Error %,在看报告时确保该数值 ≤ 1 % \le 1\% ≤1% 即可。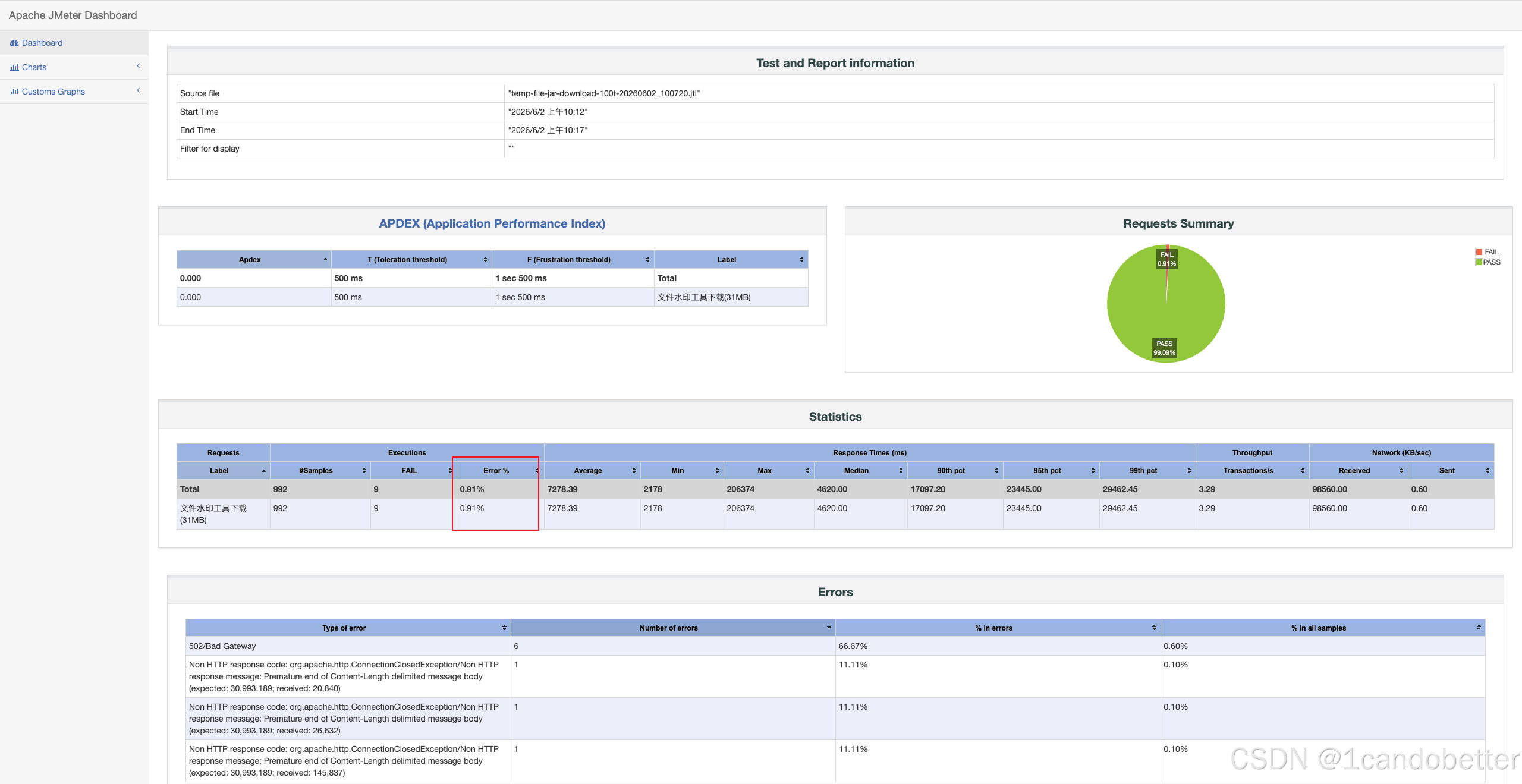
90% Latency(TTFB) ≤ \le ≤ 1s → \rightarrow → 90th Percentile Latency
JMeter 默认的首页大表(Statistics)中,90th pct 默认展示的是 Response Time(总耗时),而不是 Latency。
在文件下载压测场景中,这两者物理意义完全脱节(Response Time 包含文件传输耗时,必然远大于 Latency),需要单独统计 JTL 文件中的 Latency 字段。
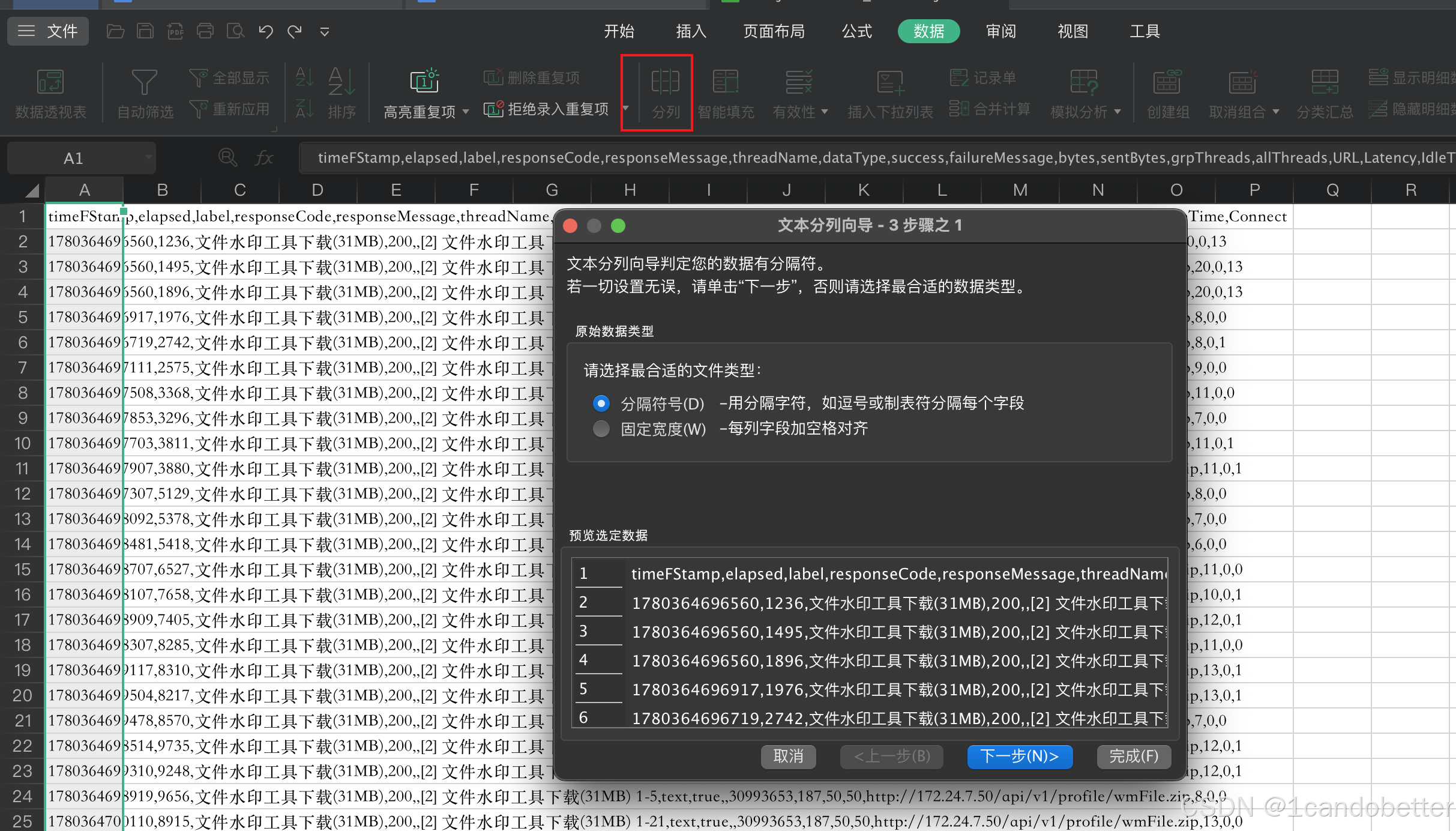
统计步骤如下:
step1 :使用 WPS 或 Excel 打开压测生成的 .jtl 文件(JTL 本质上是 CSV 格式数据文件)。
step2 :如未自动分列,可使用 数据 → 分列 功能,将数据按逗号(,)拆分为标准表格。
step3 :找到 Latency 列(单位:毫秒)。
step4 :对该列数据进行升序排序。
step5:在任意空白单元格输入以下公式:
excel
=PERCENTILE(C:C,0.9)(注:将 C:C 替换为实际存放 Latency 数据的整列字母)
平均下载耗时 ≤ \le ≤ 3s → \rightarrow → Average Response Time(Avg)
在 JMeter 的 HTML 报告(Statistics 表)中,该字段显示的名称是 Average(单位为毫秒 ms)。在看报告时,需确保该数值 ≤ 3000 ms \le 3000\text{ ms} ≤3000 ms 即可。
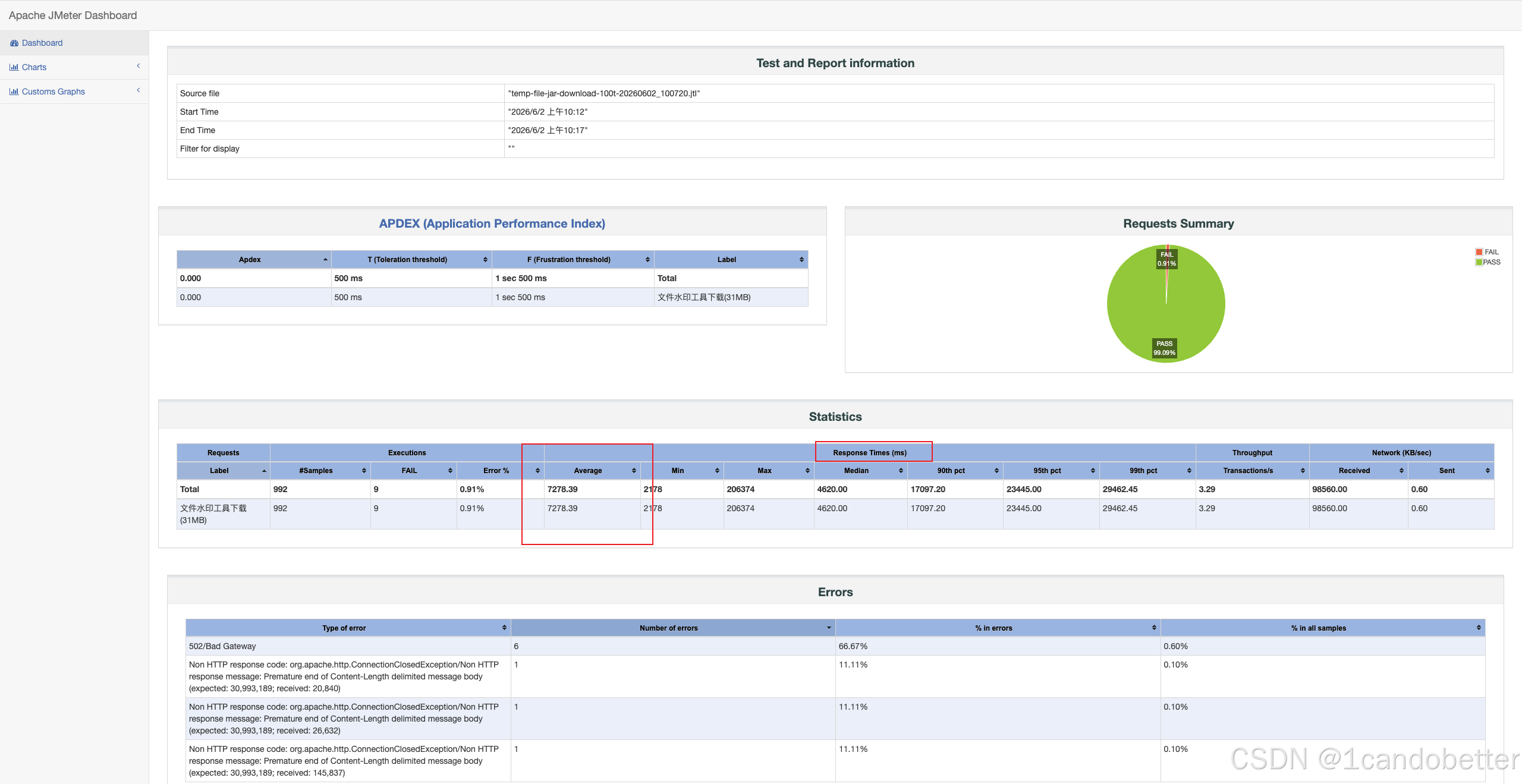
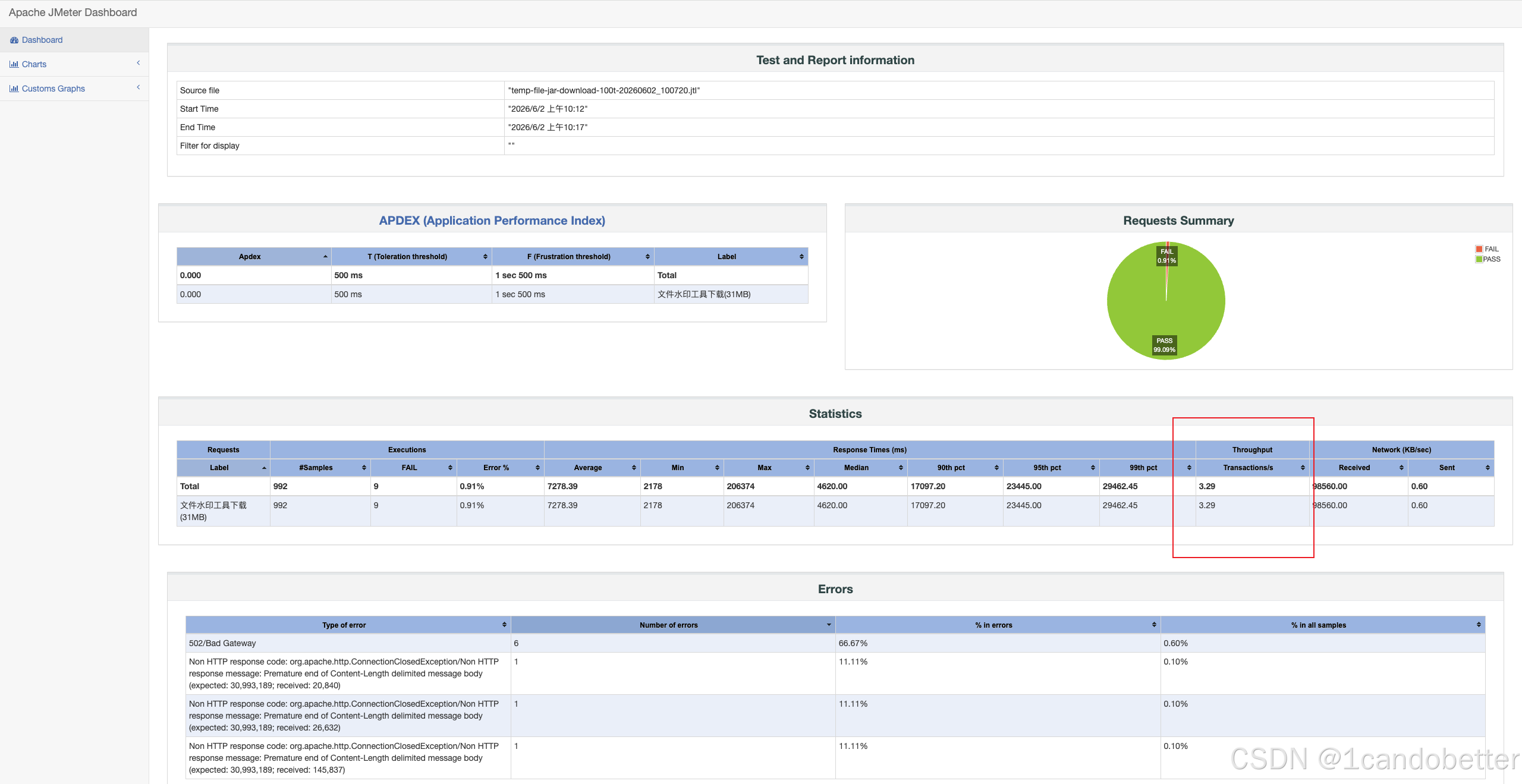
TPS/吞吐能力 → \rightarrow → Throughput
在 JMeter 的 HTML 报告(Statistics 表)中,该指标对应的字段名称是 Transactions/s(即每秒处理的事务数 / TPS)。它代表系统每秒钟能成功处理多少次完整的"文件下载"请求。在常规 API(如登录、查询)压测中,该值通常越高越好。但在大文件下载场景中,由于网络带宽的物理限制,TPS 通常会显得非常低(甚至只有个位数)。
(2)Grafana资源指标
通过 Prometheus + Node Exporter(1860 Dashboard)监控服务器资源情况。重点关注以下指标,具体数值根据具体情况而定:
| 验收指标 | Grafana表盘 | 关注指标 |
|---|---|---|
| CPU平均使用率 ≤ 85% | CPU Basic | CPU Usage |
| IO Wait平均使用率 ≤ 30% | CPU Basic | IOWait |
| 内存平均使用率 ≤ 70% | Memory Basic | Memory Usage |
| 网络带宽占用 ≤ 70% | Network Traffic | Receive / Transmit |
| 磁盘读取压力 | Disk Read/Write Data | Read Data |
| 磁盘IO压力 | Disk Read/Write IOPS | Read IOPS / Write IOPS |
说明:
- CPU Usage持续接近100%说明CPU已成为瓶颈。
- IOWait持续升高说明CPU正在等待磁盘读写。
- 下载接口通常优先受到磁盘和网络资源限制。
- Read Data持续较高说明文件仍主要从磁盘读取。
- Read Data明显下降并趋于稳定说明Page Cache已生效。
CPU平均使用率 ≤ \le ≤ 85% → \rightarrow → CPU Usage
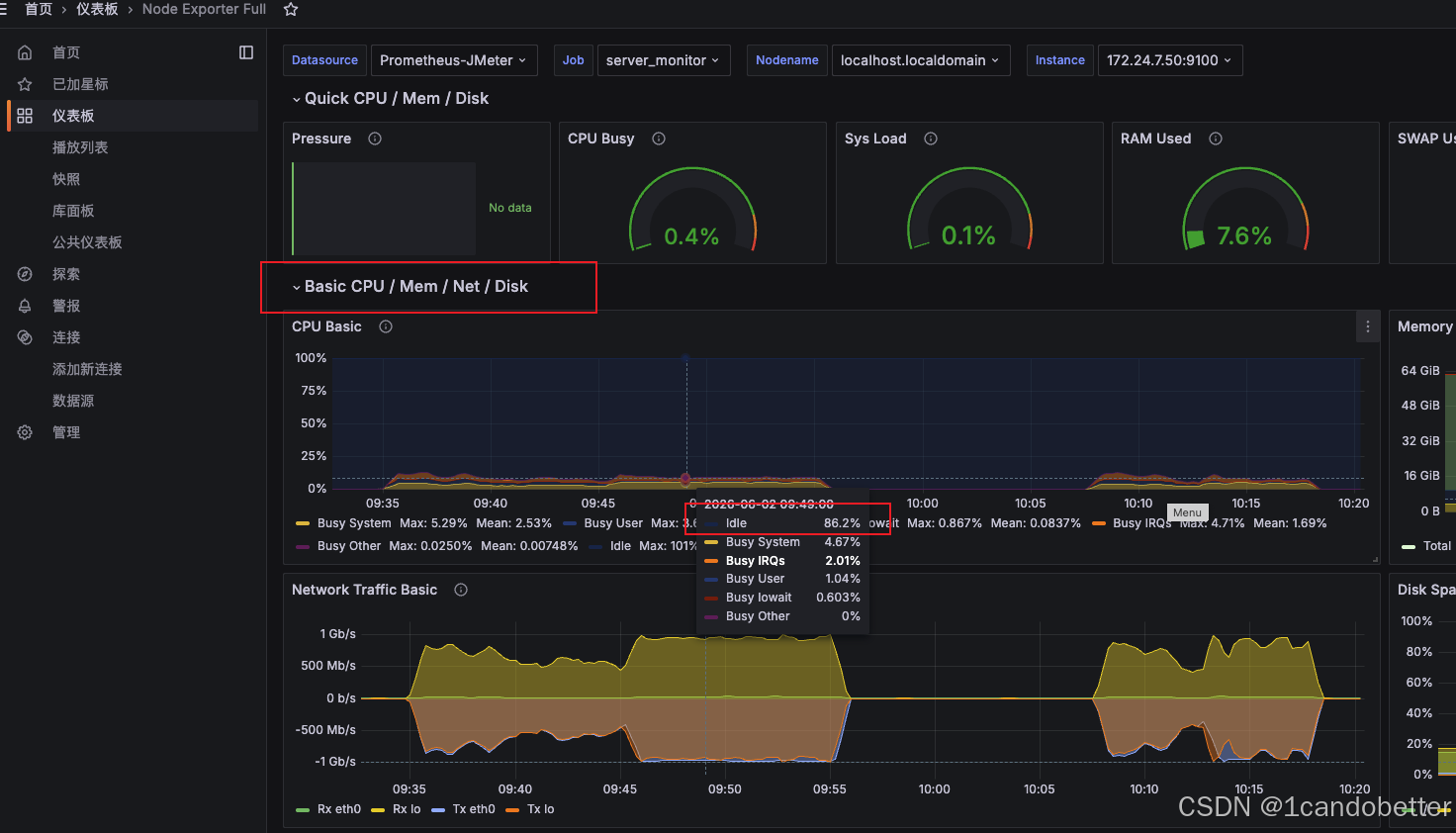
在 Grafana 1860 面板的 CPU Basic 模块中,将鼠标悬停在压测时间段的曲线上查看弹出的 Tooltip 提示框。重点观察 Idle(空闲率) 的百分比数值。只要 Idle 持续大于 15%,就意味着 CPU 使用率稳稳低于 85% 的红线,可以通过编辑表盘读取CPU相关的平均值。
IO Wait平均使用率 ≤ \le ≤ 30% → \rightarrow → IOWait
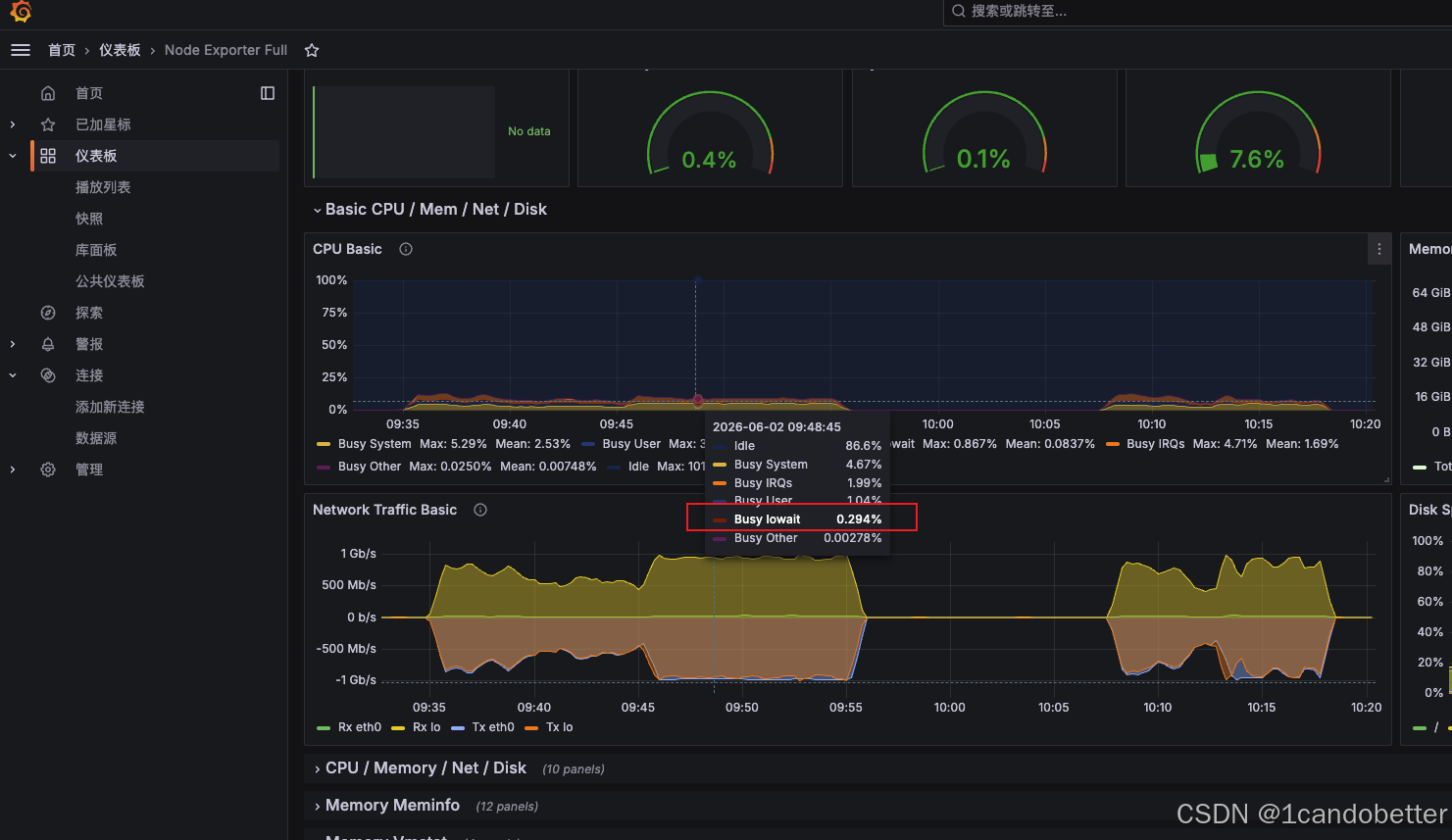
在 Grafana 1860 面板的 CPU Basic 模块中,将鼠标悬停在压测时间段的曲线上查看弹出的 Tooltip 提示框。关注iowait 曲线(通常代表 CPU 等待磁盘 I/O 完成的时间占比)。如果 IOWait 持续飙高( > 30 % > 30\% >30%),说明 CPU 绝大多数时间都在原地踏步,死等磁盘把文件读出来。
内存平均使用率 ≤ \le ≤ 70% → \rightarrow → Memory Usage
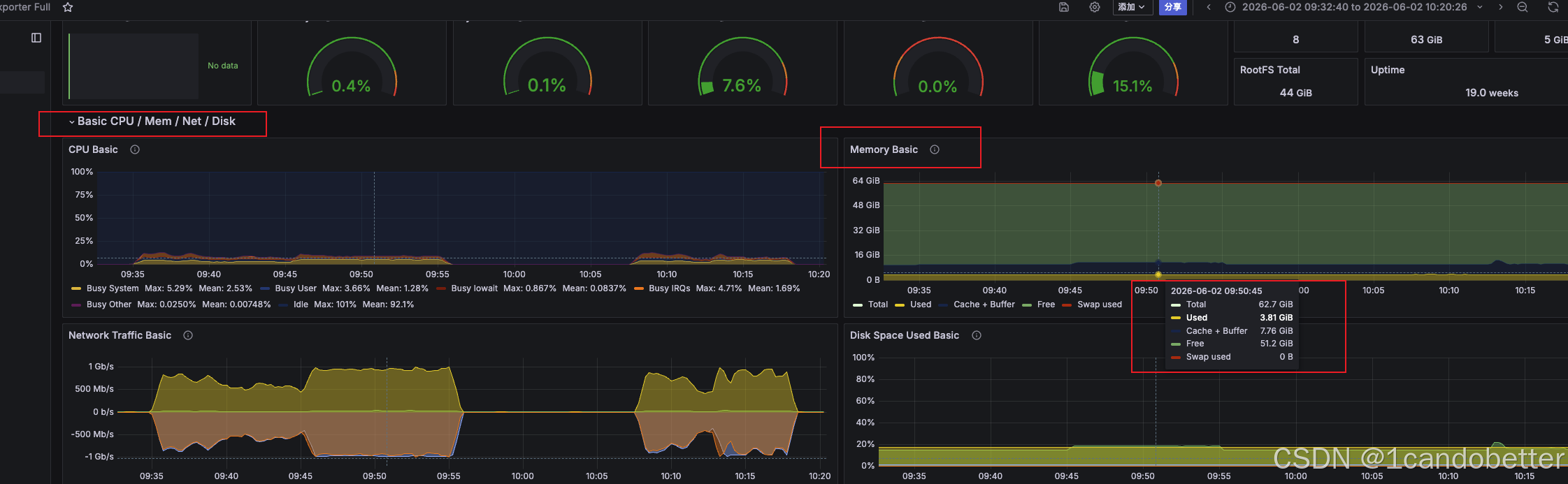
在 Memory Basic 模块中,将鼠标悬停在压测期间的曲线上,重点观察弹出提示框中 Used(黄色区域 / 已用物理内存)的百分比或绝对大小。
在压测大文件下载时,常会出现绿色 Free(完全空闲内存)迅速缩小,甚至看板整体提示"内存使用率接近 100%"的情况,容易让人怀疑后端 Java 服务发生了内存泄漏。
这实际上是 Linux 中 Page Cache(页缓存)机制带来的现象:Linux 系统为了加速文件读取,会自动将高频下载的 31MB 文件缓存在内存中(对应图中的深蓝色 Cache + Buffer 区域)。
计算公式:真实的业务内存占用率仅计算 Used / Total。
合格判定 :只要黄色的 Used 曲线持续稳定且 ≤ 70%,即使绿色 Free 内存因被 Cache 占用而变得极低,也可判定内存指标合格。当系统有新的业务进程需要内存时,Linux 会迅速释放 Cache 供系统使用,这是一种健康的内存管理机制。
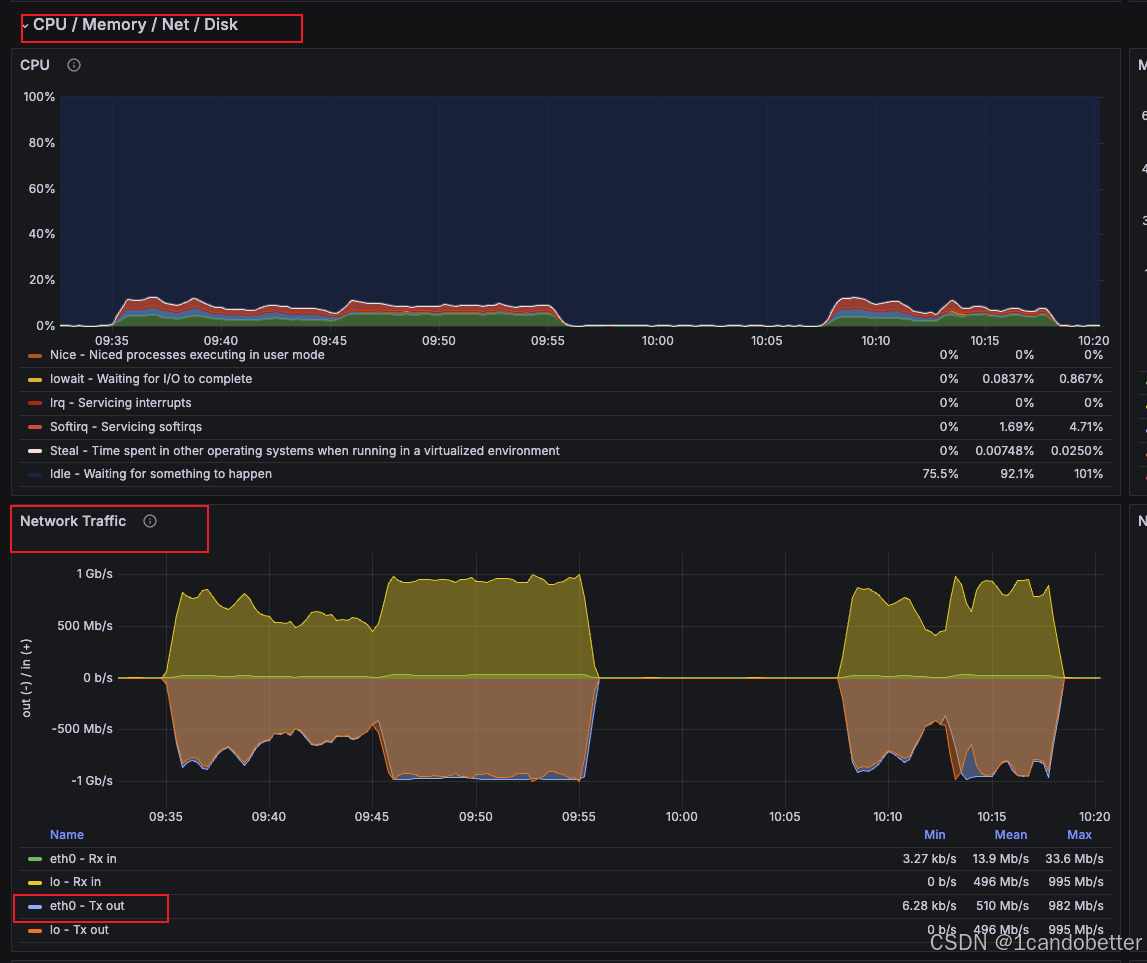
网络带宽占用 ≤ \le ≤ 70% → \rightarrow → Receive / Transmit
在 Network Traffic 模块中,找到网络吞吐量图表。对于文件下载服务,需要关注 Transmit 曲线(通常代表服务器向外发送数据的网络吞吐量)。
-
监控方向 :因为用户是在下载文件,服务器扮演的是"把数据推送给客户端"的角色,所以需要关注 Transmit(发送) ,也就是eth0 - Tx out 。
-
物理基准测定 :由于实验室内网环境隔离,推荐使用 iPerf3 工具进行内存级纯流量对撞来测定真实物理带宽。
-
压测机(客户端) :配置终端代理(端口 7897)后,通过
HOMEBREW_NO_AUTO_UPDATE=1 brew install iperf3极速安装(以MACOS为例)。 -
Linux 被测机(服务端) :在外网通过
curl捞下阿里云官方 CentOS 7 离线包,用scp传进内网后执行rpm -ivh iperf3-*.rpm安装。 -
满血对撞 :服务器执行
systemctl stop firewalld && iperf3 -s;Mac 终端执行iperf3 -c 服务器IP冲刺 10 秒,即可在回显的Bitrate中拿到真实的物理网络带宽上限(分母) 。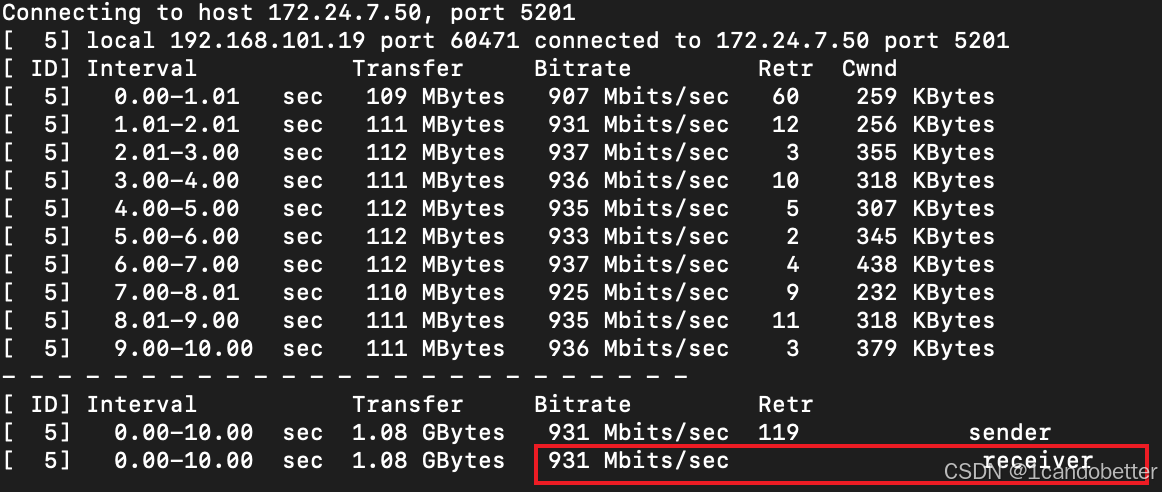
-
占用率计算公式 :
网络带宽占用率 = Grafana 中 Transmit 曲线压测稳定期的平均值 (Mbps) iPerf3 实测物理网络带宽 (Mbps) × 100 % \text{网络带宽占用率} = \frac{\text{Grafana 中 Transmit 曲线压测稳定期的平均值 (Mbps)}}{\text{iPerf3 实测物理网络带宽 (Mbps)}} \times 100\% 网络带宽占用率=iPerf3 实测物理网络带宽 (Mbps)Grafana 中 Transmit 曲线压测稳定期的平均值 (Mbps)×100%
(注:计算时取压测稳定周期内的平均值,更能真实反映高并发下的常态吞吐,避免瞬时偶发峰值的干扰。)
-
判定标准 :若最终计算出的占用率超过物理带宽的
70%,说明网络管道即将吃满。此时极易触发 TCP 拥塞控制算法,导致局域网内发生严重的网络队列排队、丢包以及重传(Retransmit)现象。
磁盘读取压力 → \rightarrow → Read Data
在 Disk Read/Write Data 模块中,查看本地磁盘读写速率图表,关注 Read Data(磁盘读取速率,单位:MB/s)曲线。如果在压测持续过程中,Read Data 出现明显下降并趋于平稳(甚至接近 0),而服务器的 Network Transmit(网络发送)仍然保持在高位,这说明 Page Cache(内存页缓存)机制已生效。系统不再频繁从硬盘读取数据,而是直接从内存中发送文件,属于理想的性能状态,详情见四、预热阶段监控指标体系。
磁盘IO压力 → \rightarrow → Read IOPS / Write IOPS
在 Storage Disk 模块中,找到 Disk Read/Write IOPS 图表。关注 Read IOPS 曲线(每秒磁盘读取次数)。
- 理想状态(双趋零现象) :在预热阶段充分、缓存完美命中的常态下,正式压测期间的 Read IOPS 应当与上面的 Read Data 同步趋于 0 次/秒。这证明全链路请求已实现纯内存级零延迟响应,物理硬盘处于完美的静默保护状态。
- 联动分析(异常排查):若发现 Read IOPS 异常飙高,必须结合上面的 Read Data 协同诊断:
- 情况 A(高 IOPS + 高 Data):说明 Page Cache 内存容量不足,导致缓存频繁失效,系统被迫重新向硬盘大流量读盘。
- 情况 B(高 IOPS + 低 Data) :说明系统正陷入严重的高频小碎片文件寻道泥潭(大量的磁盘 I/O 都在数千字节的元数据或小分块上打转)。此时物理硬盘虽然吞吐量不大,但会被高频寻道彻底卡死,通常需要通过增大后端读取缓冲区(Buffer 大小)或将文件块连续存储来优化。
(3)稳定运行阶段数据统计原则
本方案采用固定并发压测方式执行,示例如下:
bash
./run_test.sh watermark 100 --all -Jduration=600 -Jramp.up.time=20参数说明:
- Ramp-Up:20秒
- 目标并发数:100线程
- 总运行时间:600秒
统计区间确定
压测开始后的前20秒属于线程启动阶段,该阶段数据不能代表目标并发下的真实资源消耗。
需要注意的是,Ramp-Up结束后系统仍可能出现短暂瞬态波动(如TCP握手排队、上下文切换暴增)。
因此建议在Ramp-Up基础上增加一段稳定缓冲期,这里以 Ramp-Up = 20s 为例:
- 总运行时间:600秒
- Ramp-Up:20秒
- 稳定缓冲期:20秒
- 有效统计区间:40秒 ~ 600秒
重点关注指标(取稳定运行阶段的平均值):
- CPU平均使用率
- IOWait平均使用率
- 内存平均使用率
- 网络带宽平均占用率
- 磁盘读写平均值
验收原则
以稳定运行阶段的平均值作为最终结果,不建议统计整个压测周期(含Ramp-Up阶段)的平均值,否则会低估系统在目标并发下的实际资源消耗。
5、执行中动态观测机制
压测执行期间,测试人员需实施"双向联动观测",重点捕捉以下系统异动与危险信号。
JMeter 端
- TPS 异动:关注 TPS 能否平稳对齐目标值,是否存在剧烈的锯齿状下跌。
- 错误突变:一旦 Error(错误率)出现持续增长,或出现连环断言失败,需立即记录时间戳。
- 延迟翘头:观察 Latency(延迟)是否随着时间推移出现明显的线性攀升。
Grafana 端(实时刷新基础资源看板)
- CPU 见顶:CPU 总使用率是否持续逼近或超过 85% 的高危水位。
- I/O 阻塞:IOWait 是否持续超过 30%,若伴随 Disk Read 飙高,说明 Page Cache 正在失效。
- 网络吃满(观察吞吐上限与拥堵异动) :密切观测 Network Transmit 曲线与
70%安全红线 的相对位置与形态:- 形态 A :若曲线在 70% 附近被压扁成平线,任凭增加并发也无法继续突破,说明网络管道已因微观丢包和 TCP 拥塞控制踩了刹车,网络吞吐已达常态饱和极限。
- 形态 B) :若曲线轻松跨过 70% 继续上扬 ,说明内网链路质量极佳(可继续下探极限);但此时已跨入"网络高危区",必须死盯 JMeter 侧的 Error(错误率)与 Latency(延迟),一旦这两个指标发生同步突变飙升,即宣告网络性能开始恶化,应立即停止加压。
6、最终验收判定标准
同时满足以下条件时,认为本次压测通过,注意前两项(TTFB与下载耗时)为与文件体积、网络环境强相关的业务定制指标,后续需按需动态调整,以下仅为示例:
- P90 Latency(TTFB) ≤ 1s
- 平均下载耗时 ≤ 3s
- 成功率 ≥ 99%
- 文件下载无中断
- CPU平均使用率 ≤ 85%
- IOWait平均使用率 ≤ 30%
- 内存平均使用率 ≤ 70%
- 网络带宽占用 ≤ 70%
- 无OOM
- 无服务异常退出
- 无系统告警
压测结束后需保存:
- JTL结果文件
- HTML Report
- Grafana监控截图
- 服务端日志
作为最终测试报告附件。
七、核心原则
1、JMeter职责
只负责产生流量,不参与系统状态判断。
2、Grafana职责
只负责观测系统资源变化,不参与压测逻辑。
3、MD5使用原则
仅用于功能验证阶段。
4、View Results Tree原则
仅允许存在于调试阶段。
5、GUI / Non-GUI原则
GUI:仅调试与问题排查
Non-GUI:正式预热与压测执行模式
八、压测前日志治理:避免日志成为性能瓶颈
在本次文件下载接口预热过程中,曾出现日志文件在短时间内快速增长至数十 GB 的情况。排查后发现,问题并非由业务逻辑导致,而是压测期间大量请求触发了应用日志输出。
与日常业务场景相比,压测环境具有持续高并发、长时间循环请求的特点。即使单次请求仅产生少量日志,在高频访问下也会被迅速放大,最终带来以下问题:
- 日志文件快速膨胀,占满磁盘空间;
- 增加磁盘写入压力,影响压测结果;
- 干扰磁盘 IO、CPU 等监控指标;
- 极端情况下导致服务异常或压测中断。
因此,在正式执行预热和压测前,应提前检查并调整日志级别,尽量关闭非必要日志输出,仅保留关键异常日志。
参考配置如下:
yaml
logging:
level:
com.ruoyi: error
org.springframework: warn
org.zalando.logbook: off配置说明:
com.ruoyi: error:仅保留业务异常日志;org.springframework: warn:减少 Spring 框架运行日志输出;org.zalando.logbook: off:关闭 HTTP 请求与响应日志记录。
其中,org.zalando.logbook 在压测场景下尤其需要关注。该组件会记录请求与响应相关信息,在持续高频访问时可能产生大量日志内容,从而影响压测环境稳定性。
建议在压测开始前完成以下检查:
- 关闭 DEBUG、TRACE 日志;
- 关闭请求响应日志打印;
- 关闭 SQL 输出日志;
- 检查日志滚动策略是否生效;
- 检查日志目录剩余空间;
- 监控压测期间日志增长速度。
日志治理虽然不直接影响业务功能,但会影响压测结果的真实性和环境稳定性,应作为压测准备工作的必查项之一。
九、总结
本文围绕文件下载接口的性能压测,提出了一套以缓存预热和双向观测为核心的执行方案。整体流程分为两个阶段:先通过低并发请求将文件加载进入 Page Cache,消除磁盘 I/O 对测试结果的干扰;再在缓存命中的前提下启动正式并发压测,评估系统的真实吞吐能力和资源边界。
在监控方面,方案同时使用 JMeter 关注业务指标(TPS、错误率、TTFB、下载耗时),以及 Grafana 关注资源指标(CPU、IOWait、内存、网络带宽、磁盘读写)。通过两组数据的对照,可以更准确地定位瓶颈位置。
实际执行中需要注意几点:
- 预热是否完成,应以 Disk Read 是否趋近于零为判断依据。
- 压测前应关闭非必要的日志输出(如 Logbook、DEBUG、SQL 日志),避免日志刷盘影响性能或占满磁盘。
- JMeter 与 Grafana 需同步观测,单一视角容易误判瓶颈。
- TTFB、下载耗时、带宽占用等指标应根据文件大小和实际网络环境设定,不宜直接套用固定数值。
通过本方案,可以较为系统地完成文件下载接口的压测工作,获取可用于后续扩容或调优的数据,同时形成一套适用于 I/O 密集型业务的压测方法。