目录
-
- 一、写在前面:一次线上事故让我重新审视JUC底层
- 二、AQS:JUC并发包的灵魂基石
-
- [2.1 AQS的核心设计思想](#2.1 AQS的核心设计思想)
- [2.2 AQS的三个核心组件](#2.2 AQS的三个核心组件)
- [2.3 AQS的性能优化:从JDK8到JDK23](#2.3 AQS的性能优化:从JDK8到JDK23)
- 三、ThreadPoolExecutor:基于AQS的线程池实现
-
- [3.1 ThreadPoolExecutor的核心架构](#3.1 ThreadPoolExecutor的核心架构)
- [3.2 Worker线程:AQS的巧妙运用](#3.2 Worker线程:AQS的巧妙运用)
- [3.3 线程池的核心执行流程](#3.3 线程池的核心执行流程)
- 四、实战踩坑:那些年我们在高并发下踩过的坑
-
- [4.1 线程池参数配置不当](#4.1 线程池参数配置不当)
- [4.2 AQS锁的竞争过于激烈](#4.2 AQS锁的竞争过于激烈)
- [4.3 线程池异常处理不当](#4.3 线程池异常处理不当)
- [4.4 ThreadLocal与线程池结合导致的内存泄漏](#4.4 ThreadLocal与线程池结合导致的内存泄漏)
- 五、2026年技术趋势:JDK高并发基础设施的未来
-
- [5.1 虚拟线程将彻底改变并发编程模型](#5.1 虚拟线程将彻底改变并发编程模型)
- [5.2 响应式编程与JUC的深度融合](#5.2 响应式编程与JUC的深度融合)
- [5.3 云原生环境下的线程池设计](#5.3 云原生环境下的线程池设计)
- [5.4 AQS的进一步优化](#5.4 AQS的进一步优化)
- 六、个人实战复盘总结
一、写在前面:一次线上事故让我重新审视JUC底层
上个月我们团队负责的电商订单系统在大促压测时突然出现了诡异的性能问题:QPS上到5000就开始断崖式下跌,CPU使用率飙升到90%以上,但GC日志却显示一切正常。排查了整整3个小时,最后发现问题出在两个地方:一是自定义线程池使用了无界队列导致任务堆积,二是一个核心业务锁的竞争过于激烈,大量线程阻塞在AQS队列中。
这件事给了我很大的触动。我们每天都在使用ReentrantLock、ThreadPoolExecutor这些JUC工具,但很少有人真正去思考它们背后的设计哲学。JDK的高并发基础设施之所以能成为行业标准,绝不是偶然。从Doug Lea在2004年推出JUC包到今天的JDK23,这套体系经历了无数次迭代和优化,其中蕴含的设计思想值得每一个后端开发者深入研究。
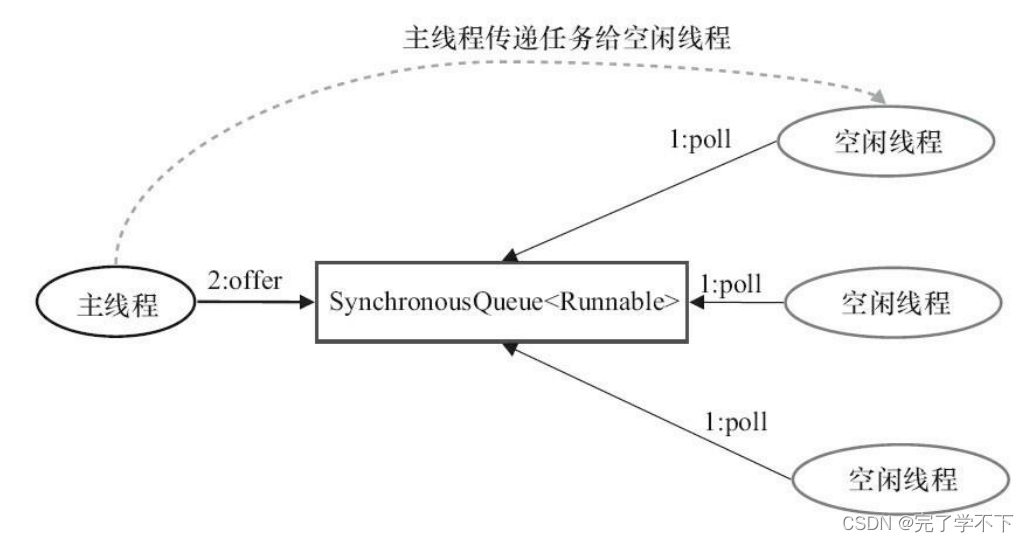
今天我就结合自己多年的实战经验,从最底层的AQS讲起,一步步拆解到我们最常用的ThreadPoolExecutor,带你看透JDK高并发基础设施的设计密码。
二、AQS:JUC并发包的灵魂基石
如果说JUC是一座大厦,那么AQS(AbstractQueuedSynchronizer)就是这座大厦的地基。几乎所有的JUC同步工具,包括ReentrantLock、CountDownLatch、Semaphore、CyclicBarrier,甚至是ThreadPoolExecutor中的Worker线程,都是基于AQS实现的。
2.1 AQS的核心设计思想
AQS的本质是一个基于CLH队列的同步器框架,它解决了两个核心问题:
- 如何管理同步状态(比如锁的持有次数、信号量的剩余数量)
- 如何管理等待线程的排队、唤醒和阻塞
我曾经花了一周时间逐行阅读AQS的源码,发现它最精妙的地方在于模板方法模式的运用。AQS把所有通用的逻辑(比如队列管理、线程阻塞唤醒)都封装在父类中,而把需要自定义的部分(比如获取同步状态、释放同步状态)留给子类去实现。
举个最简单的例子,ReentrantLock的非公平锁实现只需要重写AQS的两个方法:
java
static final class NonfairSync extends Sync {
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}所有复杂的排队、阻塞逻辑都在AQS的acquire方法中,子类只需要关心如何获取和释放同步状态。这种设计极大地提高了代码的复用性,也让自定义同步器变得异常简单。
2.2 AQS的三个核心组件
我把AQS的核心设计总结为三个关键组件,理解了这三个组件,你就理解了AQS的80%:
-
volatile int state:同步状态变量
- 这是AQS最核心的变量,所有同步操作都围绕它展开
- 对于
ReentrantLock,state表示锁的重入次数 - 对于
CountDownLatch,state表示剩余的计数 - 对于
Semaphore,state表示可用的许可数量 - 必须用volatile修饰,保证多线程之间的可见性
-
CLH双向队列:等待线程队列
- 当线程获取同步状态失败时,会被封装成一个Node节点加入这个队列
- 队列是双向的,方便节点的删除和唤醒
- 头节点是当前持有同步状态的线程,尾节点是最后一个加入队列的线程
- 所有入队和出队操作都通过CAS实现,保证线程安全
-
两种同步模式:独占模式和共享模式
- 独占模式:同一时间只能有一个线程持有同步状态(比如
ReentrantLock) - 共享模式:同一时间可以有多个线程持有同步状态(比如
Semaphore、CountDownLatch) - AQS分别为这两种模式提供了不同的模板方法
- 独占模式:同一时间只能有一个线程持有同步状态(比如
2.3 AQS的性能优化:从JDK8到JDK23
很多人不知道的是,AQS在JDK的历次版本中一直在不断优化。特别是JDK21之后,Doug Lea团队对AQS进行了一次重大的性能提升:
- 取消了不必要的volatile读写:在JDK8中,AQS的很多操作都会频繁读写volatile变量,这在高并发下会导致严重的缓存一致性开销。JDK21通过优化代码逻辑,减少了大约30%的volatile读写操作。
- 改进了CLH队列的唤醒机制 :以前AQS在唤醒后继节点时,会无条件地调用
LockSupport.unpark(),这会导致很多不必要的系统调用。现在AQS会先检查后继节点是否真的需要唤醒,只有在必要时才会调用unpark。 - 增加了对虚拟线程的支持:JDK21引入的虚拟线程对AQS提出了新的挑战。传统的AQS会阻塞操作系统线程,这会导致虚拟线程无法被调度。JDK23对AQS进行了改造,让它能够正确地支持虚拟线程的阻塞和唤醒。
三、ThreadPoolExecutor:基于AQS的线程池实现
理解了AQS之后,我们再来看ThreadPoolExecutor就会豁然开朗。很多人不知道的是,ThreadPoolExecutor中的Worker线程本身就是一个AQS的实现。
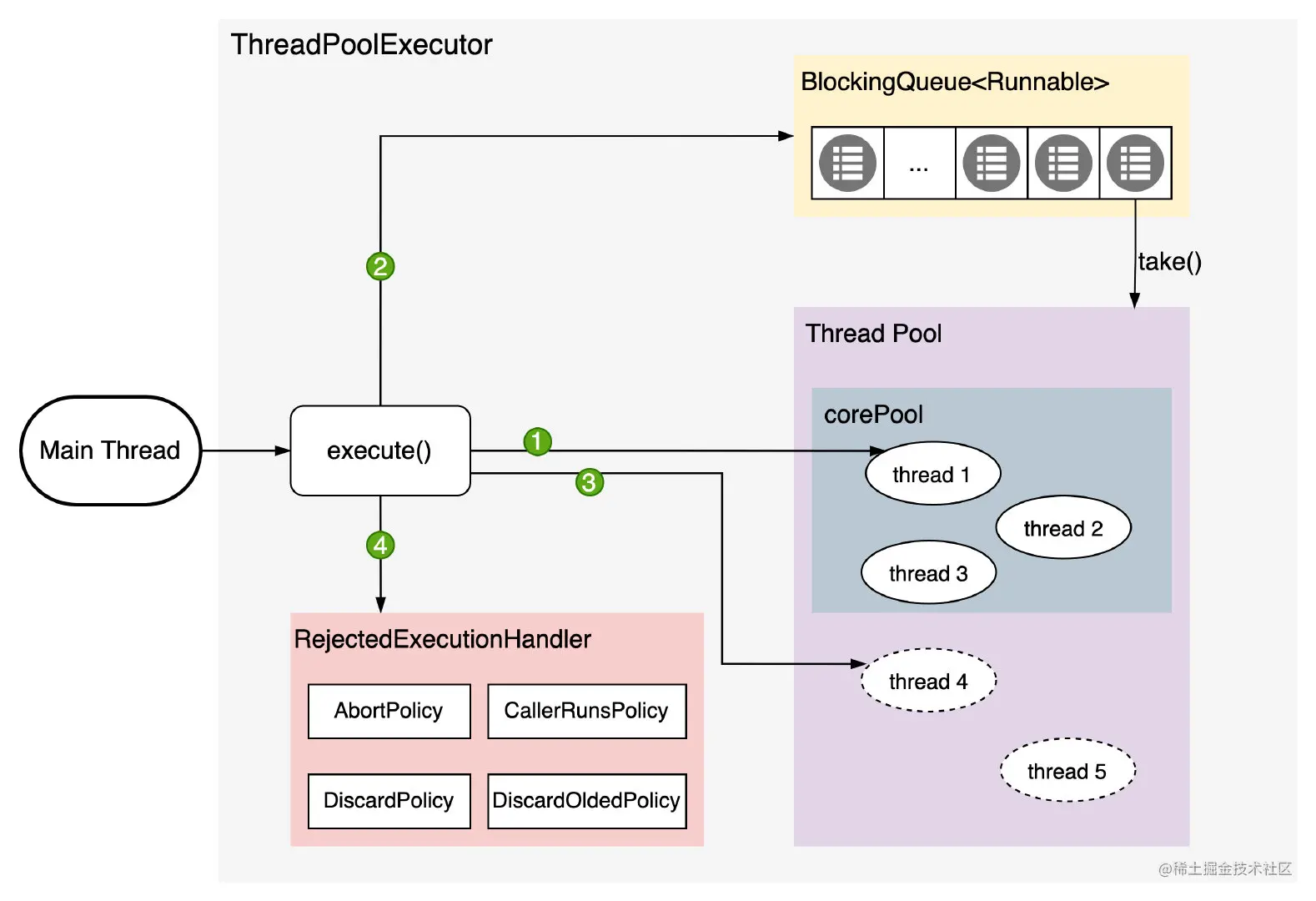
3.1 ThreadPoolExecutor的核心架构
我把ThreadPoolExecutor的核心架构总结为"一池三队列":
- 核心线程池:线程池中长期保持的线程数量
- 最大线程池:线程池能够创建的最大线程数量
- 工作队列:用于存放等待执行的任务
- 拒绝策略:当线程池和工作队列都满了的时候,如何处理新提交的任务
这里我要特别强调一个很多人都误解的点:线程池的执行顺序不是"核心线程→队列→最大线程",而是"核心线程→队列→最大线程→拒绝策略"。也就是说,只有当核心线程都在忙碌,并且工作队列也满了的时候,线程池才会创建新的线程直到达到最大线程数。
这个误解是导致很多线上事故的根源。比如很多人会把核心线程数设置为1,最大线程数设置为100,然后使用无界队列。结果就是所有任务都被放到队列中,永远不会创建新的线程,最终导致队列无限膨胀,引发OOM。
3.2 Worker线程:AQS的巧妙运用
ThreadPoolExecutor中的Worker线程是整个线程池的核心,它的实现非常巧妙:
java
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
final Thread thread;
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // 禁止中断直到runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
// 实现AQS的独占模式
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
}可以看到,Worker继承了AQS并实现了Runnable接口。它为什么要这么设计呢?主要有两个原因:
-
实现线程的中断控制 :当我们调用
shutdown()方法关闭线程池时,需要中断所有空闲的Worker线程。Worker通过AQS的锁机制来判断自己是否正在执行任务。如果Worker持有锁,说明它正在执行任务,此时不应该被中断;如果Worker没有持有锁,说明它是空闲的,可以被安全中断。 -
防止重复启动线程 :Worker的
lock()方法是独占的,这保证了每个Worker线程只能被启动一次。
3.3 线程池的核心执行流程
我把ThreadPoolExecutor的执行流程总结为以下5个步骤,这是面试中最常被问到的知识点:
- 当提交一个新任务时,线程池首先检查当前运行的线程数是否小于核心线程数。如果是,就创建一个新的核心线程来执行任务。
- 如果当前运行的线程数已经等于核心线程数,线程池会把任务加入到工作队列中。
- 如果工作队列也满了,线程池会检查当前运行的线程数是否小于最大线程数。如果是,就创建一个新的非核心线程来执行任务。
- 如果当前运行的线程数已经等于最大线程数,线程池会调用拒绝策略来处理这个任务。
- 当一个线程完成任务后,它会从工作队列中获取下一个任务来执行。如果工作队列中没有任务了,并且当前线程数大于核心线程数,那么这个线程会在等待keepAliveTime时间后被销毁。
四、实战踩坑:那些年我们在高并发下踩过的坑
在我多年的开发生涯中,见过太多因为不正确使用AQS和线程池导致的线上事故。这里我总结了几个最常见的坑,希望大家能够引以为戒。
4.1 线程池参数配置不当
这是最常见也是最致命的坑。我见过很多团队的线程池配置都是"拍脑袋"决定的:核心线程数设为CPU核心数,最大线程数设为CPU核心数*2,然后就不管了。
实际上,线程池的参数配置没有万能公式,必须根据具体的业务场景来调整。我总结了一个通用的配置思路:
- CPU密集型任务:核心线程数=CPU核心数+1,最大线程数=CPU核心数+1,队列长度=100~1000
- IO密集型任务 :核心线程数=CPU核心数2,最大线程数=CPU核心数10,队列长度=1000~10000
- 混合型任务:最好拆分成CPU密集型和IO密集型两个独立的线程池
这里我要特别提醒大家:永远不要使用无界队列。无界队列会导致任务无限堆积,最终引发OOM。即使是有界队列,也要设置合理的长度,并且配合监控及时发现问题。
4.2 AQS锁的竞争过于激烈
在高并发场景下,锁的竞争会成为系统的性能瓶颈。我曾经遇到过一个案例:一个订单支付接口使用了ReentrantLock来保证幂等性,结果在大促时,这个锁的等待队列长度达到了上千,导致接口响应时间从10ms飙升到了1s以上。
解决这个问题的方法有很多:
- 减小锁的粒度:把大锁拆分成多个小锁,比如使用分段锁
- 使用读写锁 :对于读多写少的场景,使用
ReentrantReadWriteLock可以显著提高性能 - 使用无锁数据结构 :比如
ConcurrentHashMap、AtomicInteger等 - 优化锁的持有时间:把不需要加锁的代码移到锁外面
4.3 线程池异常处理不当
很多人不知道的是,如果线程池中的任务抛出了未捕获的异常,那么这个线程会被销毁,然后线程池会创建一个新的线程来代替它。这在低并发下可能不会有什么问题,但在高并发下,会导致频繁的线程创建和销毁,严重影响系统性能。
更严重的是,如果异常没有被捕获,我们根本不知道任务执行失败了。我曾经见过一个团队的定时任务线程池,因为一个任务抛出了空指针异常,导致所有后续任务都没有执行,直到第二天才被发现。
正确的做法是:永远在任务的run方法中捕获所有异常,并且记录日志。或者在创建线程池时,自定义一个线程工厂,为每个线程设置未捕获异常处理器。
4.4 ThreadLocal与线程池结合导致的内存泄漏
这是一个非常隐蔽的坑。ThreadLocal的原理是每个线程都有一个ThreadLocalMap,用于存储线程私有的变量。当我们把ThreadLocal和线程池结合使用时,由于线程池中的线程是复用的,所以ThreadLocalMap中的变量不会被自动清理,从而导致内存泄漏。
解决这个问题的方法很简单:在任务执行完毕后,一定要调用ThreadLocal的remove()方法。最好是在finally块中调用,确保即使任务抛出异常,也能清理ThreadLocal变量。
五、2026年技术趋势:JDK高并发基础设施的未来
随着JDK的不断迭代和云原生技术的发展,JDK的高并发基础设施也在不断演进。结合我最近的行业观察,我认为未来几年会有以下几个重要的趋势:
5.1 虚拟线程将彻底改变并发编程模型
JDK21正式引入的虚拟线程是Java并发编程史上的一个里程碑。虚拟线程是轻量级的线程,它的创建和销毁几乎没有开销,并且可以同时运行上百万个。
在虚拟线程时代,传统的线程池将变得不再那么重要。因为我们不再需要担心线程的创建和销毁开销,也不再需要复杂的线程池参数调优。我们可以为每个任务创建一个虚拟线程,让JVM来负责调度。
不过,虚拟线程并不是万能的。它仍然有一些局限性,比如不适合执行CPU密集型任务,以及与一些原生代码的兼容性问题。但我相信,随着JDK的不断优化,虚拟线程将成为Java并发编程的主流。
5.2 响应式编程与JUC的深度融合
响应式编程已经成为了云原生时代的主流编程模型。Spring WebFlux、RxJava、Project Reactor等响应式框架已经被广泛应用于生产环境。
未来,JUC将与响应式编程深度融合。比如JDK23已经引入了FlowAPI的改进,让它更加易用和高效。同时,Doug Lea团队也在研究如何将AQS的设计思想应用于响应式编程中,提供更高效的异步同步机制。
5.3 云原生环境下的线程池设计
在云原生环境下,应用程序通常运行在容器中,并且会被动态调度到不同的节点上。这对线程池的设计提出了新的挑战:
- 容器的CPU和内存资源是动态变化的,传统的静态线程池参数配置不再适用
- 微服务架构下,服务之间的调用链很长,线程池的隔离变得更加重要
- 云原生环境下的可观测性要求更高,需要更细粒度的线程池监控
为了应对这些挑战,很多公司都在开发动态线程池框架。比如阿里巴巴的Sentinel、美团的DynamicTp等。这些框架可以根据系统的负载动态调整线程池的参数,并且提供了丰富的监控和告警功能。
5.4 AQS的进一步优化
虽然AQS已经非常成熟,但它仍然有优化的空间。我了解到Doug Lea团队正在研究一种新的同步器框架,它可以在高并发下提供比AQS更好的性能。
这种新的同步器框架采用了更高效的队列设计和更细粒度的锁机制,可以显著减少线程之间的竞争和上下文切换开销。预计在JDK25或JDK26中,我们就能看到它的身影。
六、个人实战复盘总结
最后,我想结合自己多年的实战经验,给大家几点建议:
-
不要只停留在API层面,要深入理解底层原理 :很多人觉得只要会用
ReentrantLock和ThreadPoolExecutor就够了,但实际上,只有深入理解了AQS的设计思想,你才能真正用好这些工具,并且在遇到问题时能够快速定位和解决。 -
性能优化要基于数据,而不是凭感觉:在进行性能优化之前,一定要先进行压测和监控,找到系统的瓶颈。不要盲目地调整线程池参数或者优化锁的实现,这样往往会适得其反。
-
保持对新技术的敏感度:Java生态一直在不断发展,虚拟线程、响应式编程、云原生等新技术正在改变我们的编程方式。作为后端开发者,我们要保持学习的热情,及时了解和掌握这些新技术。
-
重视代码的可维护性和可观测性:在高并发系统中,代码的可维护性和可观测性比性能更重要。一个难以维护和监控的系统,即使性能再好,也无法在生产环境中长期稳定运行。
从AQS到ThreadPoolExecutor,JDK的高并发基础设施凝聚了无数开发者的智慧。它不仅是一套工具,更是一种设计思想的体现。希望通过这篇文章,能够帮助大家更好地理解和运用这些工具,写出更高效、更稳定的高并发系统。