MySQL C语言连接库
引言:
网上关于MySQL C API的资料不少,但很多都太简略,要么直接贴一堆代码不解释,要么版本太老连不上。自己折腾的时候踩了不少坑,我顺手整理了一遍,希望能帮到和我一样需要手写C连数据库的人。
一.准备工作
先理清一个概念:MySQL数据库是服务端,跑在某个机器上(可能是本地也可能是远程)。我们要写一个C程序,去连接这个服务端,执行SQL,拿回结果。那C程序怎么知道怎么跟MySQL说话?这就需要MySQL官方提供的客户端库------Connector/C。
这个库做了几件事:
封装了MySQL的网络协议(其实就是MySQL自己的一套通信格式)
提供了一套函数,比如mysql_query、mysql_fetch_row这些
帮你处理连接、认证、数据转换之类的底层细节
所以用之前,先去MySQL官网下载Connector/C,选对操作系统和架构。Linux下一般是.tar.gz包,Windows下是.zip。
二.库长什么样
解压之后,目录结构大概是这样的:
cpp
mysql-connector-c-版本号-平台
├── include/
│ ├── mysql.h # 最主要的头文件,函数声明都在里面
│ ├── mysql_version.h
│ ├── mysql_time.h
│ └── ... # 一堆其他头文件
└── lib/
├── libmysqlclient.a # 静态库
├── libmysqlclient.so # 动态库的软链接
├── libmysqlclient.so.18 # 另一个软链接
└── libmysqlclient.so.18.3.0 # 真正的动态库文件include里的mysql.h是我们写代码时要包含的,lib里的库文件是链接时要用的。
**静态库(.a)**会把代码直接编进你的可执行文件,文件会变大,但运行时不需要额外找库。动态库(.so)是运行时动态加载的,可执行文件小,但运行时系统必须能找到这个.so文件。
三.测试程序证库
写一个最简单的程序,只调一个函数,看看能不能编译、能不能跑。
cpp
// test.c
#include <stdio.h>
#include <mysql.h>
int main()
{
// 这个函数返回一个字符串,是客户端库的版本号
const char *version = mysql_get_client_info();
printf("MySQL client version: %s\n", version);
return 0;
}编译命令:
cpp
gcc -o test test.c -I./include -L./lib -lmysqlclient解释一下这几个参数:
-I./include:告诉编译器去哪里找头文件(mysql.h就在这里面)
-L./lib:告诉链接器去哪里找库文件
-lmysqlclient:链接libmysqlclient这个库。前缀lib和后缀.so/.a可以省略,编译器会自动补齐
如果编译成功,会产生一个test可执行文件。但这时候跑一下:
会看到这样的错误:
cpp
./test: error while loading shared libraries: libmysqlclient.so.18: cannot open shared object file: No such file or directory这就是动态库的问题。编译的时候我们用-L告诉了链接器库在哪,但运行的时候,操作系统不知道这个路径。它默认会去/usr/lib、/lib这些系统目录找,找不到就报错。
解决办法有三个:
方法一:设置环境变量
bash
export LD_LIBRARY_PATH=./lib:$LD_LIBRARY_PATH
./test这个环境变量告诉动态链接器去当前目录的lib子目录下找库。注意这个方法只对当前终端窗口有效,关了就没了。
方法二:把库拷到系统目录
bash
sudo cp lib/libmysqlclient.so* /usr/lib/不推荐,容易污染系统环境。
方法三:编译的时候加上-rpath
bash
gcc -o test test.c -I./include -L./lib -lmysqlclient -Wl,-rpath=./lib-rpath会把库的搜索路径直接写进可执行文件里。这个比较干净,建议用这个。
四.正式连接数据库
测试通过之后,就可以真正连数据库了。
4.1 初始化
使用库之前必须先初始化,得到一个MYSQL句柄。这个句柄后面几乎所有函数都要用到。
cpp
MYSQL *mysql = mysql_init(NULL);
if (mysql == NULL) {
fprintf(stderr, "mysql_init() failed\n");
return -1;
}参数传NULL表示让库自己分配内存。如果你已经有一个MYSQL结构体变量,也可以传它的地址。
4.2 设置字符集(重要)
不设置字符集会出中文乱码。
cpp
if (mysql_set_character_set(mysql, "utf8") != 0) {
fprintf(stderr, "set character set failed: %s\n", mysql_error(mysql));
}为什么必须做这一步?
因为MySQL服务端默认的字符集可能是latin1,客户端库默认也是latin1。如果你的数据库里存了中文,或者你要写入中文,编码对不上就是乱码。设置成utf8基本能解决绝大多数情况。
4.3 建立连接
初始化完,就要真正去连数据库服务器了。用到的是mysql_real_connect函数:
cpp
MYSQL *mysql_real_connect(
MYSQL *mysql, // init返回的句柄
const char *host, // 主机名或IP,填"127.0.0.1"或"localhost"
const char *user, // 数据库用户名
const char *password, // 密码
const char *db, // 要连接的数据库名,比如"test_db"
unsigned int port, // 端口,MySQL默认3306
const char *unix_socket,// Unix socket路径,一般填NULL
unsigned long clientflag // 客户端标志,一般填0
);返回值:成功返回第一个参数(也就是mysql句柄),失败返回NULL。
示例演示:
cpp
MYSQL *conn = mysql_real_connect(
mysql,
"127.0.0.1", // 本地MySQL
"root", // 用户名
"123456", // 密码
"mydb", // 数据库名
3306, // 端口
NULL, // socket
0 // 标志
);
if (conn == NULL) {
fprintf(stderr, "Connection failed: %s\n", mysql_error(mysql));//mysql_error函数很重要
mysql_close(mysql);
return -1;
}
printf("Connected successfully!\n");4.4 执行非查询SQL(增删改)
连接成功后,就可以执行SQL了。执行语句用mysql_query:
cpp
int mysql_query(MYSQL *mysql, const char *query);返回值:0表示成功,非0表示出错。
示例演示:插入一条数据
cpp
const char *sql = "INSERT INTO users (name, age) VALUES ('张三', 25)";
if (mysql_query(conn, sql) != 0) {
fprintf(stderr, "Insert failed: %s\n", mysql_error(conn));
} else {
printf("Insert success, affected rows: %lld\n", mysql_affected_rows(conn));
}mysql_affected_rows返回受影响的记录数,对INSERT就是插入的行数,对UPDATE就是修改的行数,对DELETE就是删除的行数。
更新和删除类似,就是换SQL语句。
4.5 执行查询SQL(查)并获取结果
查询比增删改多一个步骤:你得把结果拿回来。
先执行查询:
cpp
const char *sql = "SELECT id, name, age FROM users";
if (mysql_query(conn, sql) != 0) {
fprintf(stderr, "Query failed: %s\n", mysql_error(conn));
return -1;
}查询成功后,结果还在MySQL服务器那边,没传到你的程序里。需要用mysql_store_result把它拉回来:
cpp
MYSQL_RES *result = mysql_store_result(conn);
if (result == NULL) {
fprintf(stderr, "mysql_store_result failed: %s\n", mysql_error(conn));
return -1;
}注意:mysql_store_result会分配内存来存放结果集,用完必须释放,不然内存泄漏。
拿到结果集之后,可以看看有多少行、多少列:
函数演示:
cpp
int row_count = mysql_num_rows(result);
int field_count = mysql_num_fields(result);
printf("共 %d 行,%d 列\n", row_count, field_count);想看列名(表头)的话:
cpp
MYSQL_FIELD *fields = mysql_fetch_fields(result);
for (int i = 0; i < field_count; i++) {
printf("%s\t", fields[i].name);
}
printf("\n");
最关键的,取每一行的数据:
cpp
MYSQL_ROW row;
while ((row = mysql_fetch_row(result)) != NULL) {
for (int i = 0; i < field_count; i++) {
// row[i]可能是NULL(数据库里存的是NULL值)
// 直接printf("%s", row[i])会崩溃
if (row[i] == NULL) {
printf("NULL\t");
} else {
printf("%s\t", row[i]);
}
}
printf("\n");
} MYSQL_ROW其实就是char**,每行是一个char*数组,每个元素是字符串形式的数据。不管你数据库里存的是整数还是日期,取出来都是字符串,需要的话自己转换。
最后释放结果集:
cpp
mysql_free_result(result);4.6 完整的查询示例
把上面的串起来:
cpp
#include <stdio.h>
#include <mysql.h>
int main()
{
MYSQL *conn = mysql_init(NULL);
if (conn == NULL) {
fprintf(stderr, "mysql_init failed\n");
return 1;
}
if (mysql_set_character_set(conn, "utf8") != 0) {
fprintf(stderr, "set charset failed\n");
mysql_close(conn);
return 1;
}
if (mysql_real_connect(conn, "127.0.0.1", "root", "123456", "mydb", 3306, NULL, 0) == NULL) {
fprintf(stderr, "connect failed: %s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
if (mysql_query(conn, "SELECT id, name, age FROM users") != 0) {
fprintf(stderr, "query failed: %s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
MYSQL_RES *result = mysql_store_result(conn);
if (result == NULL) {
fprintf(stderr, "store result failed: %s\n", mysql_error(conn));
mysql_close(conn);
return 1;
}
int fields = mysql_num_fields(result);
MYSQL_ROW row;
while ((row = mysql_fetch_row(result)) != NULL) {
for (int i = 0; i < fields; i++) {
printf("%s\t", row[i] ? row[i] : "NULL");
}
printf("\n");
}
mysql_free_result(result);
mysql_close(conn);
return 0;
}4.7 事务操作
默认情况下,每执行一条SQL就会自动提交。如果想把多条SQL作为一个事务,需要先关闭自动提交:
cpp
// 关闭自动提交
if (mysql_autocommit(conn, 0) != 0) {
fprintf(stderr, "set autocommit failed\n");
}
// 执行几条SQL
mysql_query(conn, "UPDATE account SET money = money - 100 WHERE id = 1");
mysql_query(conn, "UPDATE account SET money = money + 100 WHERE id = 2");
// 检查有没有出错,没有就提交
if (/* 都成功了 */) {
mysql_commit(conn);
} else {
mysql_rollback(conn);
}
// 恢复自动提交
mysql_autocommit(conn, 1);六、易错点:
找不到动态库:编译用-L指定了路径,但运行时系统不认识。解决办法:用-rpath或者设LD_LIBRARY_PATH。
中文乱码:连上后立刻mysql_set_character_set改成utf8,别等。
结果集内存泄漏:mysql_store_result返回的MYSQL_RES,一定要mysql_free_result。这个很容易忘。
NULL值崩溃:mysql_fetch_row返回的字段可能是NULL,直接printf("%s")会段错误,要判断一下。
mysql_error是调试神器:几乎所有函数失败后,都可以用mysql_error(conn)看具体原因。
端口号是整数不是字符串:3306,不是"3306"。
密码明文写在代码里:生产环境别这么干,从配置文件或环境变量读。
七、建议:
- 这套API封装得比较底层,好处是可控性强,坏处是写起来啰嗦。每次查询都要:query → store_result → fetch_row → free_result,重复劳动很多。
- 如果项目规模变大,建议自己封装一层,或者考虑用更高层的库。但作为理解MySQL通信机制的学习,从头写一遍还是很有价值的。
- 另外,以上代码都没有做完整的错误处理,实际项目中建议每个函数调用都检查返回值,出错了及时清理资源退出。
MYSQL连接池原理与简易数据网站数据流动是如何进行的
引言:
假设你写了一个网站,后台挂了个MySQL。每个用户请求来了,你都要去连一下数据库,查完关掉。访问量小还好,但一旦用户多了,比如几百个人同时点你的网站------那每次请求都新建连接、断开连接,MySQL压力很大的。为什么?
因为TCP三次握手建连接、MySQL认证、再四次挥手断开,这套流程走一遍几十毫秒。单次看着不多,但一秒钟来几千次,CPU直接拉满,所以就有了连接池。
一.连接池的定义
**连接池是一种预先创建并维护多个数据库连接的机制。**程序启动时,提前创建一批线程,每个线程与MySQL建立好连接,这些线程被统一管理形成一个池子。当有数据库操作任务到来时,任务被封装成结构体(包含SQL语句和回调函数)推入任务队列,池中的空闲线程循环等待并从队列中取出任务执行,执行完成后根据是否设置了回调函数决定是否回调结果。连接池内部采用生产者-消费者模型,通过任务队列实现线程间的任务调度。
简单来说就是提前建好一堆MySQL连接,放在一个池子里。谁要用就来拿,用完还回去,而不是真的关掉。
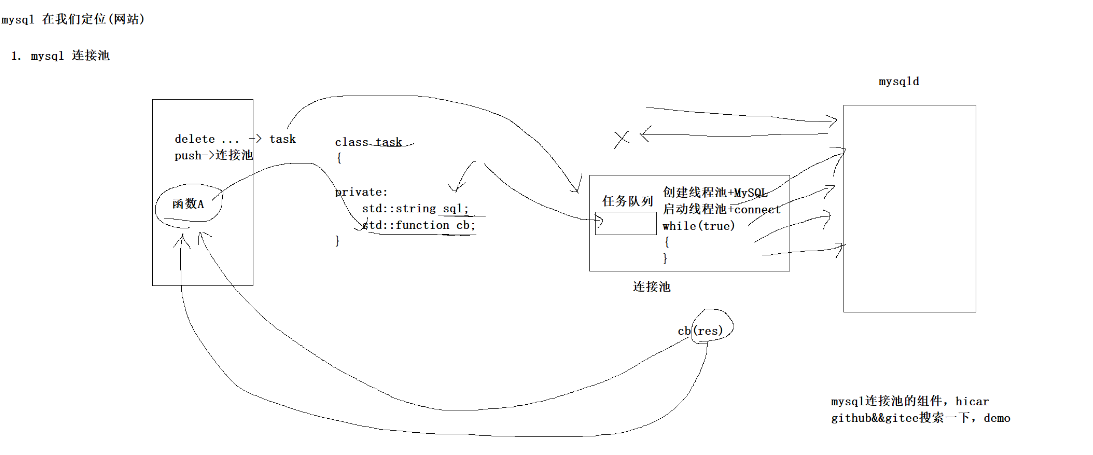
我用图片大致画了一下
大致流程是:
程序启动的时候,一次性创建N个MySQL连接(比如20个)
把这20个连接扔进一个队列或者列表里
每个线程(或者每个请求)要从池子里"借"一个连接
用完再"还"回去
如果池子里的连接都被借走了,后来的请求要么等,要么报错
同时我写的图片里还写了"delete... -> task,push -> 连接池",是指:执行完删除操作后,封装成一个task,再推回连接池?还是说任务队列里放着要执行的SQL,连接池负责取出来跑。这个看具体实现。
二.一个简单的连接池要有什么
一个简单的连接池 (Connection Pool)核心要解决的就是一个问题:复用连接,避免每次操作数据库都三次握手、登录认证、断开挥手。
一个最简但可用 的连接池需要具备的 5 个核心要素:
核心组件(缺一不可)
1. 连接容器(Connection Container)
用 队列 (Queue)或 列表(List)存放可用连接
通常用
BlockingQueue(如 Java 的LinkedBlockingQueue)操作:
push(归还连接)、pop(取连接)
2. 连接创建器(Connection Creator)
负责创建真正的数据库连接
需要参数:URL、用户名、密码、驱动类名
3. 连接获取方法(getConnection())
- 从连接容器中取出一个空闲连接
- 如果容器为空:
- 且未达到最大连接数 → 创建新连接
- 且已达到最大连接数 → 等待(超时机制)
4. 连接归还方法(close() 或 releaseConnection())
不是真正关闭数据库连接
而是把连接放回连接容器(清空事务状态、重置自动提交等)
5. 连接配置参数(>=3 个)
| 参数 | 作用 |
|---|---|
| 最小空闲连接数 | 池启动时预先创建多少个连接 |
| 最大连接数 | 池最多能创建多少个连接 |
| 连接超时时间 | 获取连接时等待多久(防止死等) |
三.网站数据流动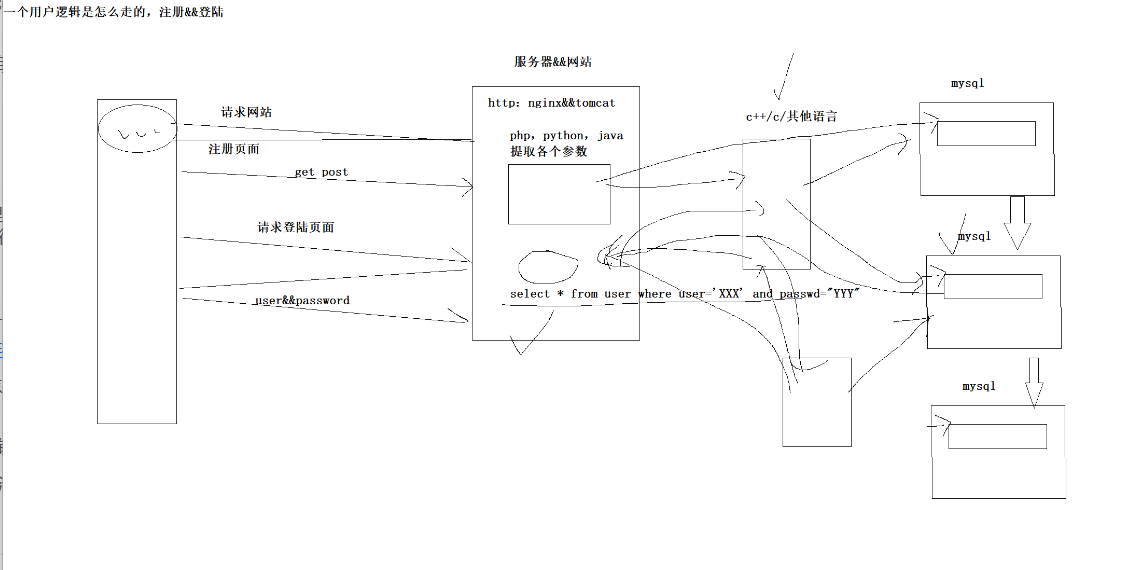
客户端和服务器之间的事
- 用户打开注册页面,填了一堆信息,点提交。这时候浏览器和网站服务器先来一次TCP三次握手,握完了才能发数据。请求一般是POST方式,账号密码什么的都塞在请求体里。
- 服务器收到请求,开始处理。具体用什么语言就看网站怎么搭的了,PHP、Java、Python都比较常见。不管什么语言,干的活都差不多:把HTTP请求里的参数抠出来,比如username、password、email这些,再判断一下这是个注册请求还是登录请求(通常看URL路径就能知道)。
- 参数都拿齐了,后端代码就开始拼SQL语句。注册的话大概是这样的
**SQL拼好之后,就得发给数据库了。**但这里有个问题:数据库可能不止一台。
小网站一台MySQL就能扛住,但流量大了,或者要做高可用,就得搞数据库集群。比如一主多从,主库负责写,从库负责读。或者分库分表,不同数据放在不同机器上。
这时候服务器直连某一个数据库就不太灵活了。所以中间通常会加一层------叫数据库中间件。
图片里提到"选择用效率高的语言(C/C++/其它语言)写成",确实,很多中间件底层是用C或C++写的,比如ProxySQL、MaxScale、Vitess这些。用这些语言主要是为了性能,毕竟中间件要处理大量的网络转发和协议解析,用Python这种解释型语言扛不住高并发。
中间件做什么事呢?
- 第一,负载均衡。 比如你有一个主库两个从库,读请求来了,中间件决定发给哪个从库,别让某一个压力太大。可以按轮询、按权重、或者按连接数来分配。
- 第二,读写分离。 中间件能解析SQL语句,看出你是SELECT还是INSERT/UPDATE/DELETE。SELECT走从库,写操作走主库。应用程序不用自己操心连哪个库,只管连中间件就行。
- 第三,故障转移。 某个数据库挂了,中间件能自动把请求转发到其他健康的节点,应用程序基本没感知。
所以说,中间件有点像数据库侧的反向代理。Nginx是转发HTTP请求,数据库中间件是转发MySQL协议请求。位置不同,干的活类似。
总结:最后整个数据流动的路径大概是:
cpp
客户端 -> 三次握手 -> 发送HTTP请求 -> Web服务器(Nginx/Apache) ->
后端代码(PHP/Java/Python)提取参数、拼SQL -> 数据库中间件 ->
中间件做负载均衡、读写分离 -> 实际MySQL数据库 -> 结果原路返回中间件这一层,小网站可以没有,直接连数据库也行。但上了规模之后,基本都会加一层,不然数据库那边容易出问题。
四.连接池的几个关键点
- 最小连接数和最大连接数:池子一开始创建多少个,最多能扩展到多少个。设太小了高并发不够用,设太大了MySQL那边连接数撑不住。
- 连接存活检查:连接存活检查:MySQL配置wait_timeout,空闲过久连接被MySQL服务端断开。Hikari不在取连接时ping,空闲期后台自动校验失效连接并销毁;老旧/C++连接池一般取出前执行ping,无效就废弃创建新连接。
- 空闲回收:池子里那些很久没人用的连接,可以定时关掉一些,释放资源。
- 超时等待:池子里没空闲连接了,新来的请求最多等多久。等不到就报错返回,别让请求一直卡着。
补充:
- 图片里写的"一个用户逻辑是怎么走的,注册&登陆",其实就是上面这一串:浏览器 -> http服务器 -> 后端代码提取参数 -> 从连接池拿连接 -> 执行SQL -> 返回结果 -> 连接放回池子。
- 连接池这个组件不算复杂,但用好了效果很明显。GitHub上搜"mysql connection pool c++"或者"HikariCP mysql"能找到不少参考代码,抄一个下来改改就能用。
- 要是真准备自己写,注意处理好线程安全和连接失效的问题就行,别写出内存泄漏或者死锁。