先从一个场景理解 GAN:一个造假者和一个鉴定师的博弈
GAN,全称是 Generative Adversarial Network,生成对抗网络。它最核心的思想不是"我直接告诉模型怎么生成一张图片",而是设计一个对抗场景,让两个模型互相竞争、互相逼迫,最后把生成能力训练出来。
你可以把 GAN 想象成一个"造假者"和一个"鉴定师"的训练过程。
一开始,造假者水平很差,画出来的东西一眼假;鉴定师也很普通,只会分辨一些很明显的真假。然后训练开始:造假者不断尝试生成假图片,想骗过鉴定师;鉴定师不断学习真实图片和假图片之间的区别,想把造假者抓出来。随着训练进行,鉴定师越来越会看细节,造假者也被迫越来越会模仿真实数据。
最后如果训练得比较理想,就会出现一种平衡:造假者生成的图片已经足够逼真,鉴定师也很难判断它到底是真的还是假的。这个时候,我们真正想要的其实不是鉴定师,而是那个已经训练好的"造假者",也就是 生成器 Generator。
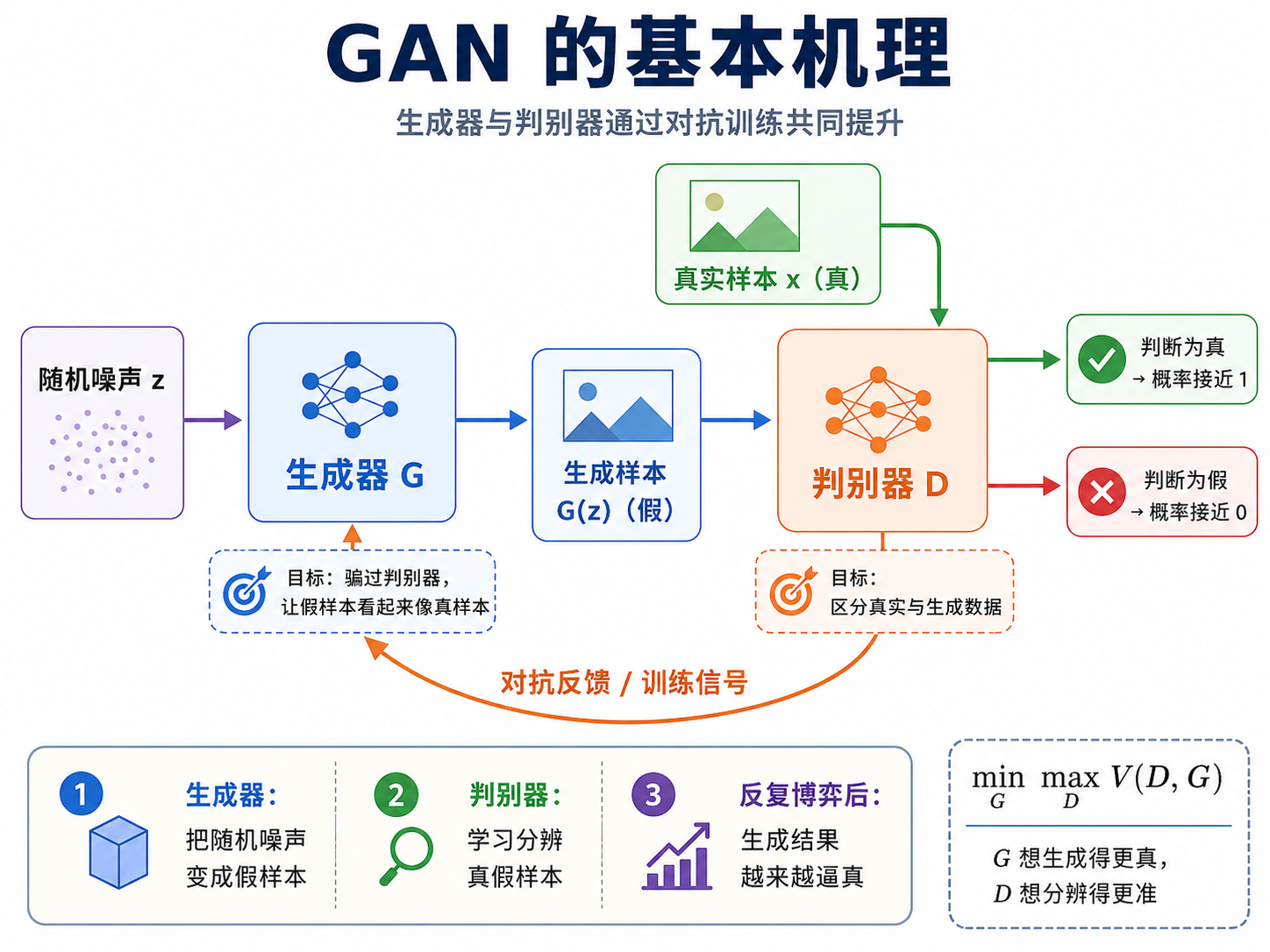
GAN 的两个核心角色:生成器和判别器
GAN 里面有两个主要模块。
第一个是 生成器 Generator,简称 G。它的任务是从一个随机噪声开始,生成一个看起来像真实数据的东西。比如生成图片时,它一开始拿到的可能只是一串随机数字,这串数字本身没有明确意义,但生成器会把它一步一步变成一张图片。刚开始生成的图可能像雪花噪声,但训练久了之后,它就可能生成一张人脸、一只猫、一个医学影像切片,甚至一个特定风格的图像。
第二个是 判别器 Discriminator,简称 D。它的任务是判断输入的数据是真的还是假的。真实数据来自训练集,假数据来自生成器。判别器会输出一个概率,比如它认为这张图有 90% 的可能是真的,或者只有 10% 的可能是真的。
所以 GAN 的结构其实非常清楚:
生成器负责造,判别器负责查。生成器想骗过判别器,判别器想识破生成器。
这两个模块不是单独训练的,而是互相影响的。判别器越强,生成器就必须生成更真实的东西;生成器越强,判别器就必须学会更细节的真假差异。GAN 的"对抗"二字就在这里。
GAN核心公式
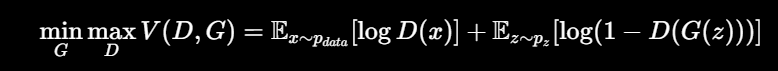
它其实就表达一句话:
判别器 DDD 想分清真假,生成器 GGG 想骗过判别器。
其中:
x:真实数据,比如真实图片。
z:随机噪声。
G(z):生成器用噪声造出来的假图片。
D(x):判别器认为真实图片是真的概率。
D(G(z)):判别器认为假图片是真的概率。
判别器的目标是:
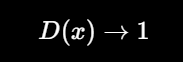
真实图片要判成真。
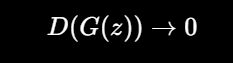
假图片要判成假。
所以判别器希望最大化这个公式,也就是:
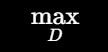
它越能分清真假,得分越高。
生成器的目标正好相反。它希望自己造出来的假图被判成真(生成模型只能影响第二个式子):
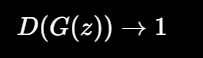
所以生成器要最小化判别器识别假图的能力,也就是:
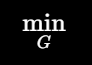
意思就是:
判别器拼命提高鉴别能力,生成器拼命提高造假能力。
在代码里,常见写法会变成两个 loss:
判别器 loss:
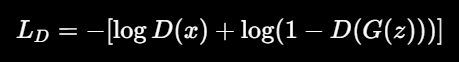
意思是:真实图判真,假图判假。
生成器 loss:
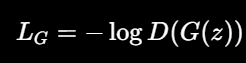
意思是:让假图被判成真。
最后如果训练理想,生成器生成的分布接近真实数据分布:
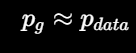
这时判别器已经分不清真假。
GAN应用场景
目前 GAN 的应用主要集中在图像生成、图像增强、图像修复和数据扩充等场景中。它可以用来生成人脸、动漫头像、商品图等视觉内容,也可以用于图像超分辨率,把低清图像变得更加清晰;在图像修复中,GAN 能根据周围区域补全缺失内容,例如修复老照片、去除遮挡或补全破损部分;在图像风格转换中,它可以实现白天到夜晚、素描到真实图像、普通照片到特定风格图像的转换。除此之外,GAN 在医学影像、遥感图像和工业检测中也有较多应用,例如生成医学影像样本进行数据增强、提高卫星图像分辨率、生成缺陷样本辅助工业质检等。整体来看,GAN 最适合处理那些需要"让生成结果看起来更真实"的任务,它的价值不只是生成新图像,更在于通过对抗训练逼迫模型学习真实数据背后的纹理、结构和分布规律。