目录
[2、真正好用的办法是给 AI 做一套上下文分层](#2、真正好用的办法是给 AI 做一套上下文分层)
[4、让 AI 按需取上下文,而不是一次吃完整个仓库](#4、让 AI 按需取上下文,而不是一次吃完整个仓库)
我第一次明显感觉到 AI Coding 的"上下文不够用",是在查一个串口 DMA 偶发丢包的问题。
现象很熟悉:线上偶现、复现条件模糊、日志不完整、代码里还有几段历史包袱。AI 一开始表现得很聪明,能顺着 HAL_UARTEx_RxEventCallback 往下读,也能把环形缓冲区、空闲中断、半传输中断这些点串起来。可聊着聊着,它开始忘记前面确认过的事实,甚至又建议我去检查一个刚刚已经排除掉的方向。
那一刻很像在一颗 SRAM 紧张的 MCU 上调试:不是 CPU 不够快,而是关键数据放不下。上下文窗口,就是 AI Coding 的片上 RAM。
嵌入式工程师对资源限制很敏感。Flash、SRAM、栈、DMA buffer、中断优先级,任何一个资源边界没算清楚,系统都会用很隐蔽的方式提醒你。
AI Coding 也是这样。
它能读到的内容有限,能稳定记住的内容有限,能同时权衡的约束也有限。当仓库稍微复杂一点,问题就会从"生成代码"变成"维护现场"。
1、压缩有用,但别把它当最终方案
上下文压缩通常会把长对话整理成几段摘要。它能帮你继续工作,但我不建议把它当成长期方案。
因为压缩最容易丢三类东西。
第一类是证据。
比如原始讨论里有一句:"rx_len == 0 只在空闲中断重复进入时出现,半传输路径没有复现。"压缩后可能只剩下"怀疑空闲中断处理异常"。前者能指导下一步,后者只是方向感。
第二类是约束。
嵌入式项目里的约束往往不是写在代码里的。比如"这颗芯片的这个 UART 和 RS485 方向脚共用一个历史驱动,不能直接改初始化顺序",这种约束一旦被压缩掉,AI 很可能给出看似正确但无法落地的方案。
第三类是排除路径。
调试最宝贵的不只是发现了什么,还有排除了什么。压缩经常保留结论,却丢掉"为什么不是它"。下一轮 AI 又会沿着旧路走一遍,浪费时间,也容易把人带偏。
压缩应该像日志归档,不应该像断电重启。
一个更稳的做法是:压缩只保留可验证事实,不保留含糊判断。
| 不建议这样压缩 | 更建议这样压缩 |
|---|---|
| 可能是 DMA 处理有问题 | 现象只在 UART3 DMA 空闲中断路径复现,半传输回调未复现 |
| 之前试过几个方法都不行 | 已排除波特率误差、接收缓冲区大小不足、上层协议解析越界 |
| 这个模块比较特殊 | 该模块不能使用堆内存,不能在中断中调用阻塞日志,不能改公开协议结构体 |
| 需要注意历史兼容 | 设备端固件版本小于 2.8 时仍使用旧帧头,兼容逻辑在 protocol_parse_frame |
2、真正好用的办法是给 AI 做一套上下文分层
我现在更倾向于把 AI Coding 的上下文分成四层。
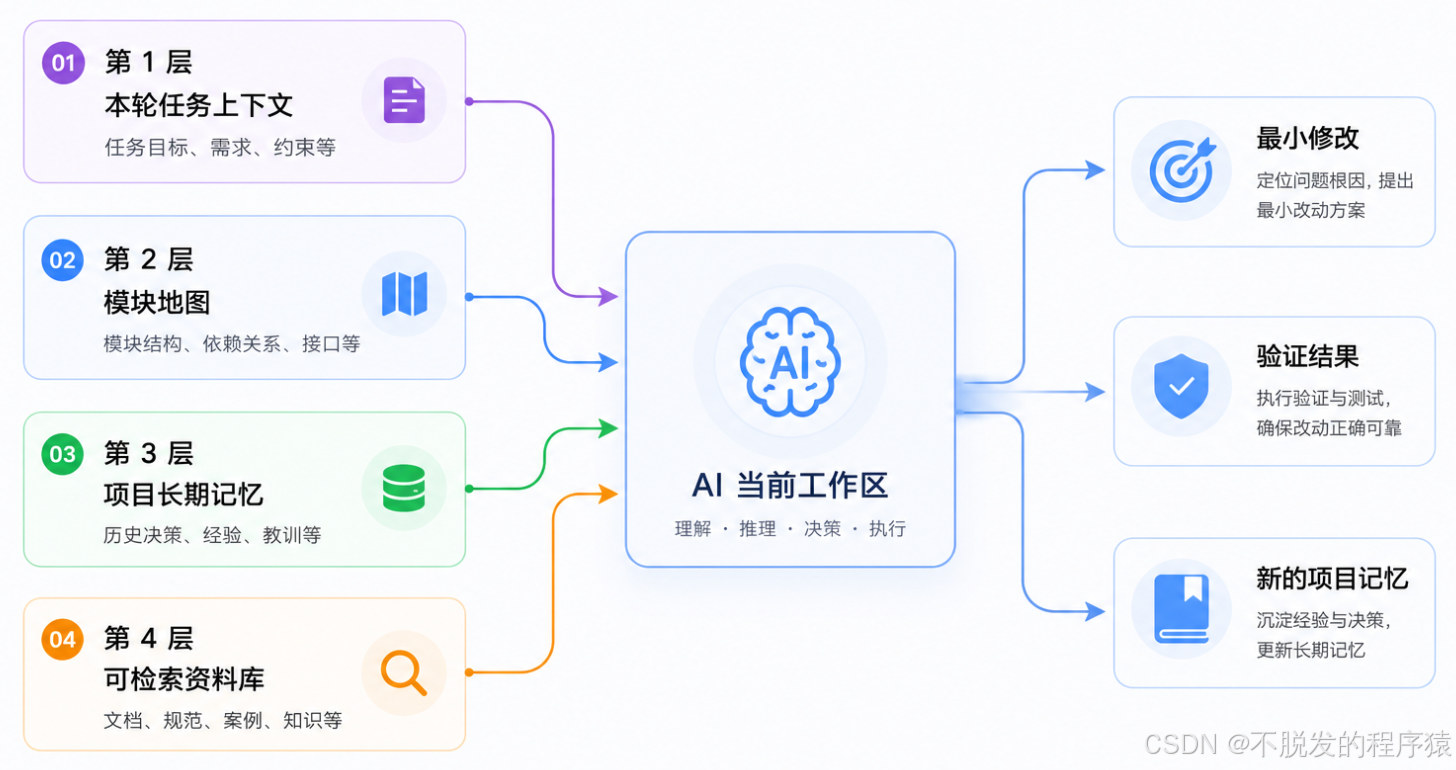
第 1 层是本轮任务上下文。
只放这次要解决的问题、必须遵守的约束、最近的报错、相关文件和期望输出。它应该短,最好一屏能看完。
第 2 层是模块地图。
比如串口模块有哪些入口,协议解析在哪里,板级差异在哪里,哪些文件不要碰。这个东西不需要每次都重新解释,应该沉淀成项目文档。
第 3 层是项目长期记忆。
包括历史坑点、架构决策、调试经验、常用命令、测试板卡差异。它不一定很长,但必须稳定。
第 4 层是可检索资料库。
比如芯片手册片段、寄存器说明、协议文档、错误日志、代码符号索引。AI 不需要一次性吃下所有资料,它只需要在需要的时候拿到正确片段。
这四层配起来,AI 才不需要把所有东西都塞进一个上下文窗口里。
3、给上下文做预算,别把窗口交给运气
上下文资源有限,就应该有预算。
我通常会按下面的比例分配。
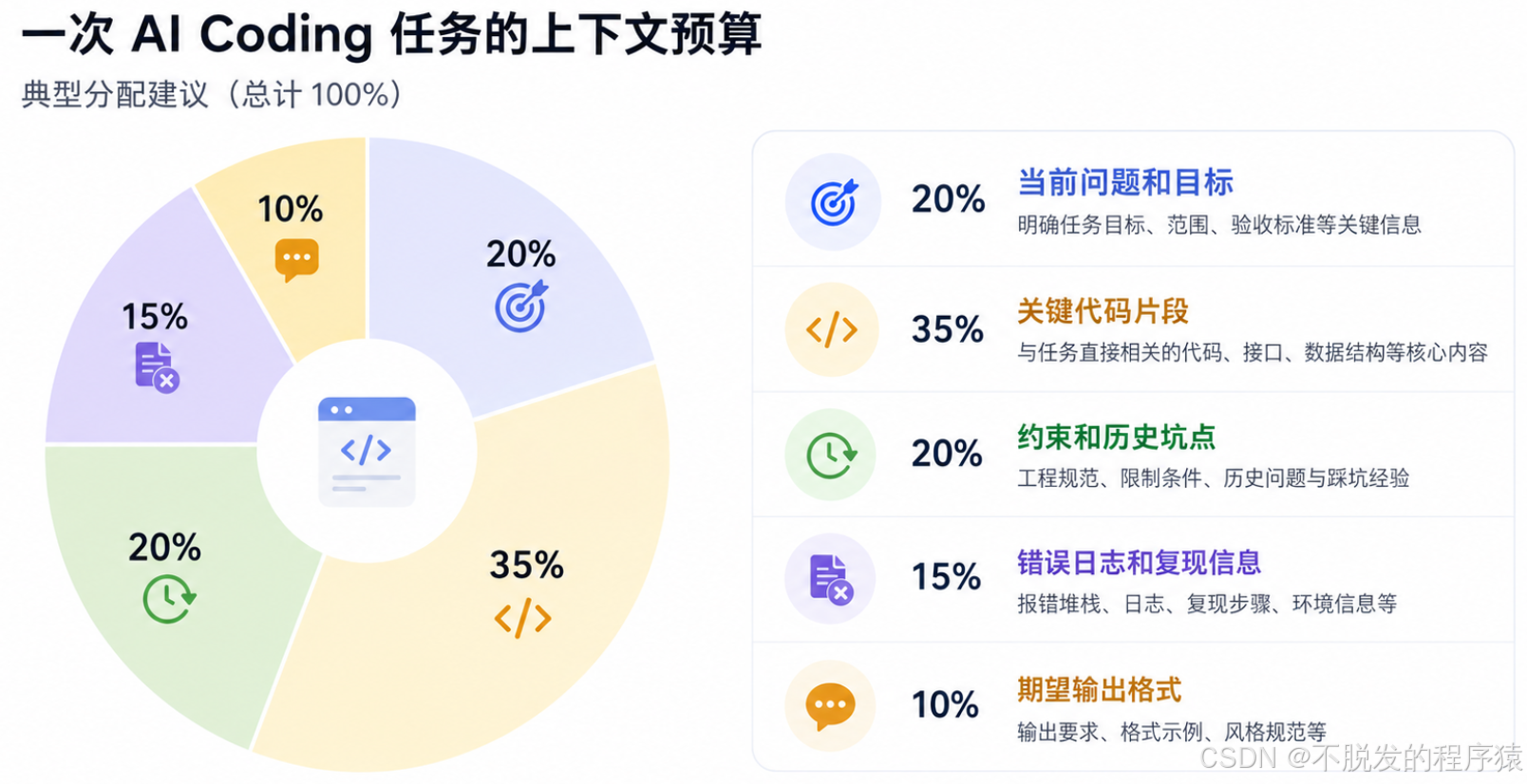
这个比例不是标准答案,但它能提醒我们:不要让源码把所有空间吃完。
对复杂任务,我会先给 AI 一张任务卡
# 任务卡
## 当前问题
设备运行 8 小时后,UART3 偶发出现协议帧错位。重启后恢复。
## 目标
定位帧错位是发生在 DMA 接收层、环形缓冲区层,还是协议解析层。
## 范围
本轮只分析 `Drivers/uart_dma.c`、`App/Protocol/protocol_parser.c` 和最近一次日志。
## 约束
- 不改协议结构体。
- 不引入堆内存。
- 不在中断里加阻塞日志。
- 不做大范围重构。
## 已知事实
- UART1 未复现,UART3 复现。
- 丢包前出现过 17 次 `rx_len == 0`。
- 环形缓冲区满计数没有增加。
- 协议层 CRC 错误计数增加。
## 希望输出
- 最可能的故障链路。
- 需要继续确认的证据。
- 最小修改建议。
- 验证步骤。这张任务卡的作用很直接:把 AI 的注意力锁在本轮问题上。
不要指望 AI 自己判断什么重要。工程师要做的是把重要性排序交给它。
**4、**让 AI 按需取上下文,而不是一次吃完整个仓库
大仓库里,最糟糕的方式是把大量文件一股脑塞进去。
更好的方式是先建立索引,让 AI 先知道去哪里找。
你可以把索引理解成代码仓库的目录缓存。
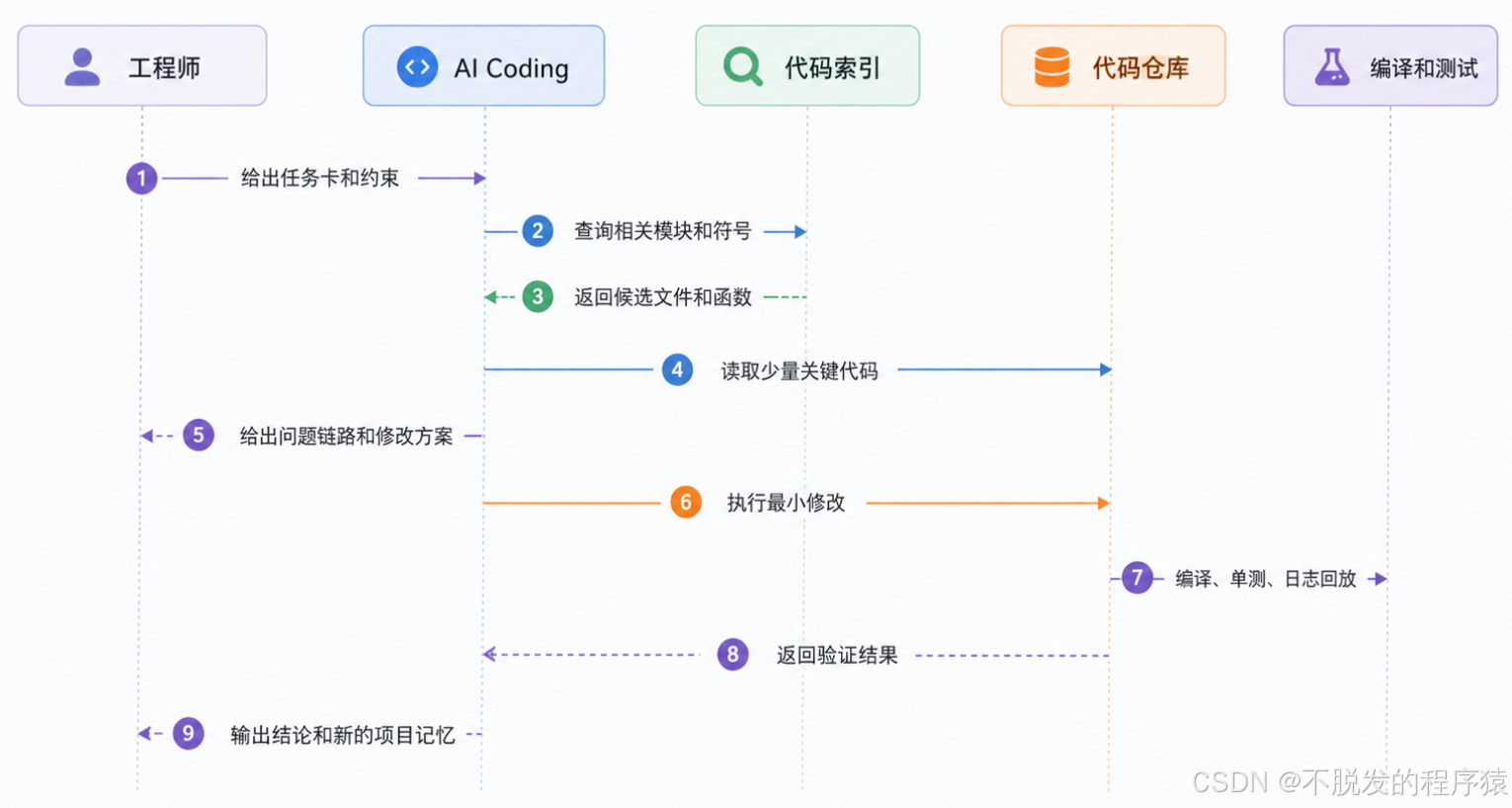
这个流程里,AI 不是靠"记住一切"工作,而是靠"需要时找到正确材料"工作。
如果你的工具链支持代码检索、符号索引、语义搜索,可以用起来。如果没有,也可以从很简单的方式开始:
- 为关键模块写
docs/*.md。 - 用
rg快速找符号、宏、配置项。 - 维护
CHANGELOG_DEBUG.md记录疑难问题。 - 把常用调试命令写进
docs/commands.md。 - 把芯片手册关键页摘成短笔记,不要整本塞给 AI。
这些东西看起来土,但有效。
嵌入式项目里,真正提高效率的经常不是更炫的工具,而是少走三次弯路。
5、大任务必须拆,不拆就是浪费上下文
AI Coding 很容易让人产生一种冲动:既然它能写代码,那干脆让它一次性完成。
"帮我把这个驱动重构一下,顺便修 bug,加测试,再优化性能。"
这类任务通常会把上下文打爆。不是模型不努力,而是任务边界太大。
更靠谱的拆法是按工程链路拆:
| 阶段 | 目标 | 产物 |
|---|---|---|
| 读代码 | 搞清模块边界和数据流 | 模块地图 |
| 定位问题 | 找到最可能故障链路 | 证据链 |
| 最小修改 | 只动必要代码 | 补丁 |
| 验证 | 编译、单测、回放、压力测试 | 验证记录 |
| 沉淀 | 更新文档和 Skill | 项目记忆 |
每一轮只解决一个问题。
这和嵌入式调试很像。示波器一次只抓几个通道,逻辑分析仪也要设置触发条件。你不能把所有信号都接上,然后指望自己一眼看懂。
6、一个我认为可落地的工作流
如果从零开始改造,我会这样做。
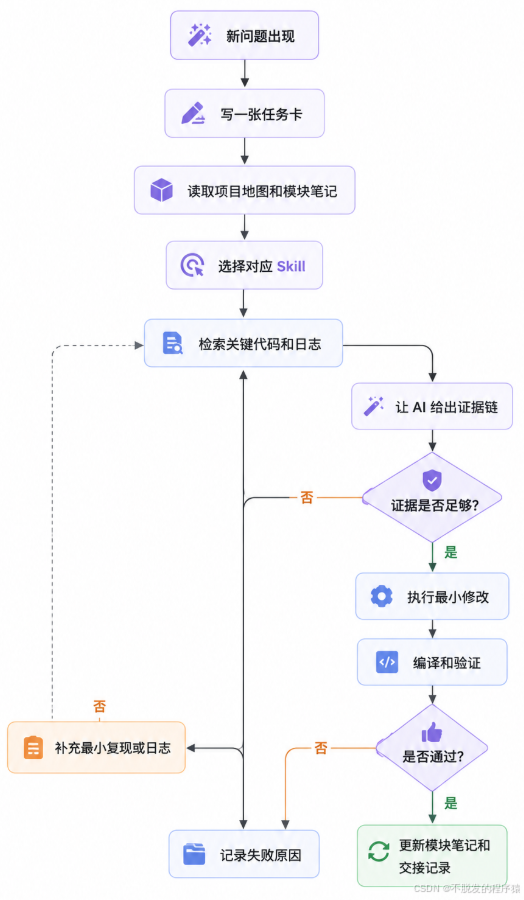
这个流程有几个关键点。
第一,先写任务卡,再让 AI 干活。
任务卡会强迫你把问题说清楚。很多时候,写任务卡的过程本身就能暴露盲点。
第二,先让 AI 给证据链,再让它改代码。
如果它说不清"为什么是这里",直接动代码就是碰运气。AI 写补丁很快,回滚错误方向很慢。
第三,每次通过验证后都要更新项目记忆。
这一步最容易被省掉,但它决定下一次 AI 是不是还要重新踩坑。
一个团队的 AI Coding 用得好不好,不看它一次能生成多少代码。
我更愿意看三个指标:
- 它能不能少重复问项目背景。
- 它能不能少走已经排除过的路。
- 它的修改能不能稳定通过验证并沉淀成下一次的经验。
如果做不到,那上下文再大也只是晚一点溢出。
把上下文管好,AI 才不会只是一个能写代码的聊天窗口。它会慢慢变成项目里的第二块工作台:一边放代码,一边放证据,一边留下下一次还能接着用的经验。