文章目录
- [异步机制与阻塞规避:Redis 单线程模型的生存之道](#异步机制与阻塞规避:Redis 单线程模型的生存之道)
- [Redis 实例的四类交互对象](#Redis 实例的四类交互对象)
- 五大阻塞点
-
- 阻塞点一:集合全量查询和聚合操作
- [阻塞点二:bigkey 删除](#阻塞点二:bigkey 删除)
- 阻塞点三:清空数据库
- [阻塞点四:AOF 日志同步写](#阻塞点四:AOF 日志同步写)
- [阻塞点五:从库加载 RDB 文件](#阻塞点五:从库加载 RDB 文件)
- 关键路径与异步执行
- 异步子线程机制
- 惰性删除的命令
-
- [lazy-free 的配置项](#lazy-free 的配置项)
- [lazy-free 的触发条件](#lazy-free 的触发条件)
- 不能异步的阻塞点怎么办
- [4.0 之前版本的 bigkey 删除策略](#4.0 之前版本的 bigkey 删除策略)
- 写操作是否在关键路径上
- 总结
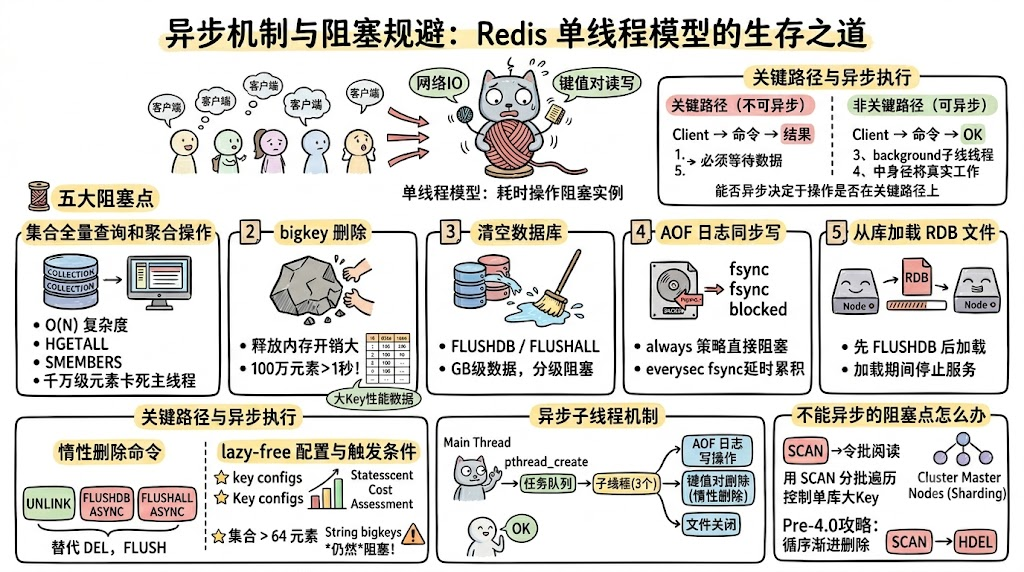
异步机制与阻塞规避:Redis 单线程模型的生存之道
Redis 的高性能建立在单线程模型之上:主线程负责网络 IO 和所有键值对的读写操作。这个设计避免了多线程的锁竞争和上下文切换开销,但也意味着任何一个耗时操作都会直接阻塞整个实例,所有客户端的请求都得排队等着。
理解 Redis 的阻塞点在哪里、哪些可以异步化、哪些必须在主线程完成,是保障 Redis 性能稳定的基本功。
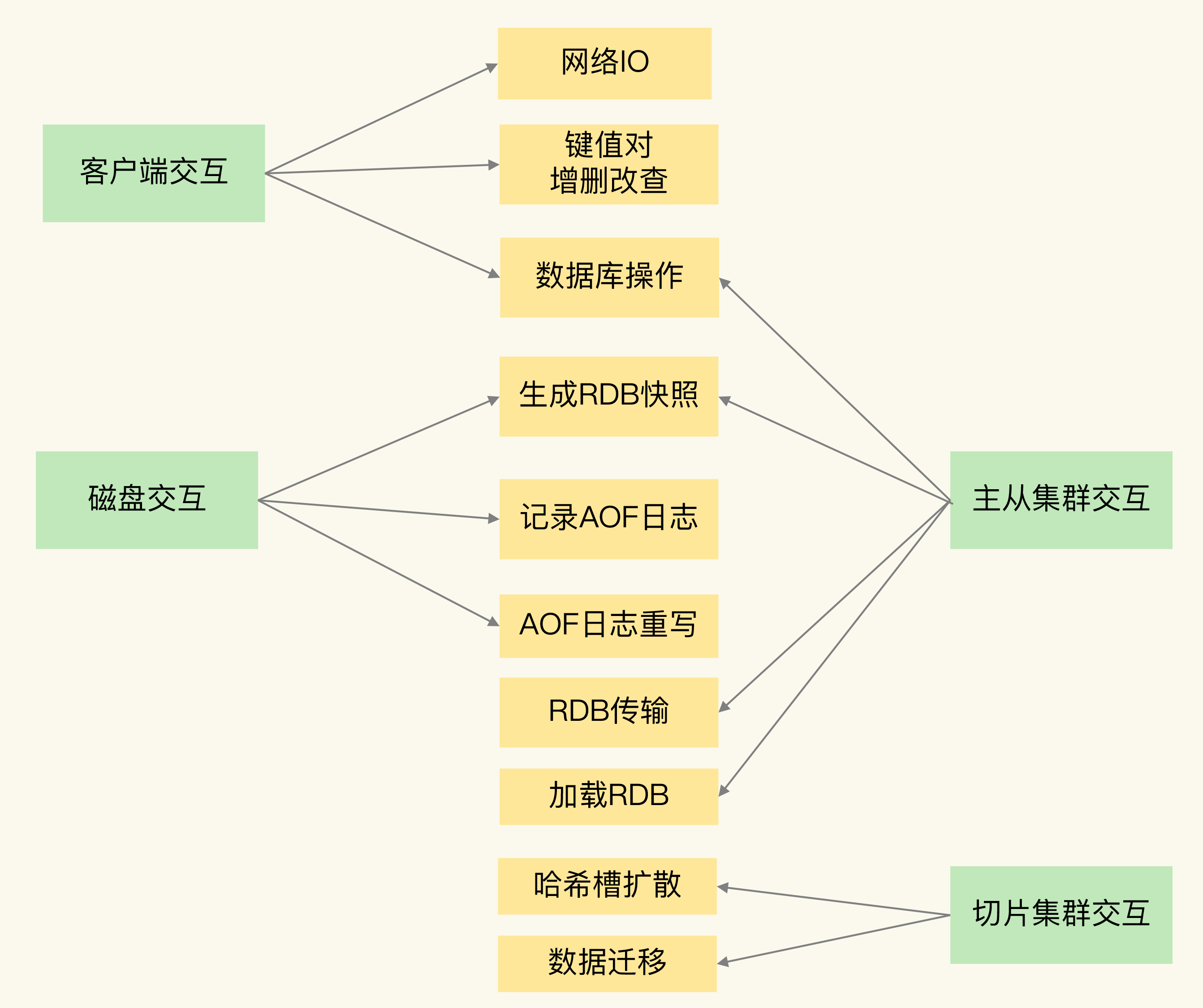
Redis 实例的四类交互对象
Redis 运行时要和四类对象打交道,每类交互都可能产生阻塞:
- 客户端:网络 IO、键值对增删改查、数据库级操作
- 磁盘:RDB 快照生成、AOF 日志写入、AOF 重写
- 主从节点:主库生成和传输 RDB、从库接收 RDB 并加载
- 切片集群实例:哈希槽信息传递、数据迁移
逐一分析这四类交互中的阻塞风险。
五大阻塞点
阻塞点一:集合全量查询和聚合操作
网络 IO 本身不是问题------Redis 用 IO 多路复用(epoll/kqueue)处理连接,主线程不会阻塞在等待连接上。真正的问题出在命令执行阶段。
判断一个命令是否有阻塞风险,最直接的标准是看复杂度是否为 O(N)。涉及集合的全量操作几乎都是 O(N):
HGETALL:返回 Hash 的所有 field-valueSMEMBERS:返回 Set 的所有成员LRANGE key 0 -1:返回 List 的所有元素ZRANGE key 0 -1:返回 Sorted Set 的所有元素SINTERSTORE、SUNIONSTORE、SDIFFSTORE:集合聚合运算
当集合元素达到百万级,一条 HGETALL 就可能耗时几百毫秒甚至秒级,直接把主线程卡住。
阻塞点二:bigkey 删除
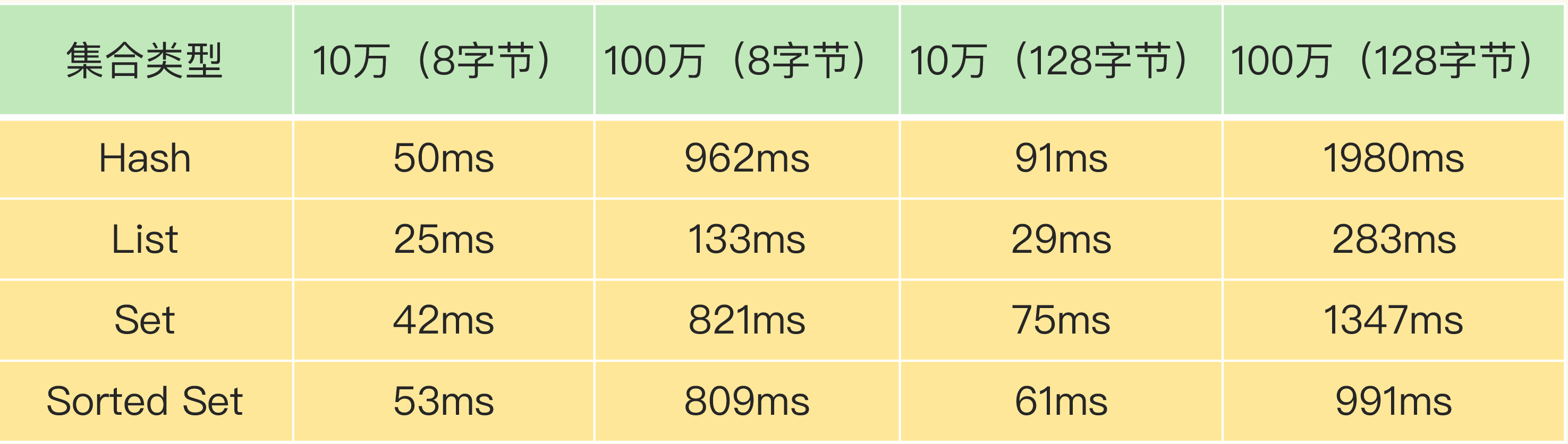
删除操作看起来简单,但本质是释放内存。操作系统在释放内存时需要把内存块插入空闲链表,这个过程本身有开销。如果一次性释放大量内存(比如删除一个包含百万元素的 Hash),空闲链表操作的累积耗时会非常可观。
实测数据很有说服力:
| 集合类型 | 10 万元素 | 100 万元素 |
|---|---|---|
| Hash | 约 51ms | 约 1980ms |
| List | 约 29ms | 约 570ms |
| Set | 约 48ms | 约 820ms |
| Sorted Set | 约 52ms | 约 980ms |
Redis 正常响应时间在微秒级,一个 DEL 操作耗时近 2 秒,对在线业务来说是灾难性的。
阻塞点三:清空数据库
FLUSHDB 和 FLUSHALL 本质上是删除所有键值对,和 bigkey 删除是同一类问题,只是规模更大。一个几十 GB 的实例执行 FLUSHALL,阻塞时间可能达到分钟级。
阻塞点四:AOF 日志同步写
Redis 的 AOF 持久化有三种写回策略:always(每条命令都同步写盘)、everysec(每秒写盘)、no(交给 OS 决定)。
always 策略下,每条写命令执行后都要等 fsync 完成才能处理下一条。单次 fsync 耗时约 1-2ms,高并发写入时这个延迟会累积。everysec 策略虽然是异步的,但如果上一秒的 fsync 还没完成,新的写操作也会被阻塞。
阻塞点五:从库加载 RDB 文件
主从同步时,从库收到 RDB 文件后需要先 FLUSHDB 清空自己的数据(撞上阻塞点三),然后加载 RDB 到内存。RDB 文件越大,加载越慢。一个 4GB 的 RDB 文件加载可能需要几十秒,这段时间从库无法对外服务。
关键路径与异步执行
五个阻塞点不是都能异步化的。判断标准是:这个操作是否在关键路径上。
关键路径操作是指客户端发出请求后,必须等待结果返回才能继续的操作。典型的关键路径操作是读操作------客户端发了 GET,必须等到值返回才能做后续处理。
非关键路径操作是指客户端不需要等待具体结果的操作。比如删除操作,客户端只需要知道"删除请求已接受"就够了,至于内存什么时候真正释放,客户端并不关心。
按这个标准分类:
| 阻塞点 | 是否关键路径 | 能否异步 |
|---|---|---|
| 集合全量查询和聚合 | 是(客户端等数据) | 不能 |
| bigkey 删除 | 否(客户端不等释放结果) | 能 |
| 清空数据库 | 否(客户端不等释放结果) | 能 |
| AOF 日志同步写 | 否(不返回数据给客户端) | 能 |
| 从库加载 RDB | 是(加载完才能服务) | 不能 |
三个可以异步化的操作,Redis 通过子线程机制来处理。
异步子线程机制
Redis 主线程启动后,通过 pthread_create 创建三个后台子线程,分别负责:
- AOF 日志写操作
- 键值对删除(惰性删除)
- 文件关闭
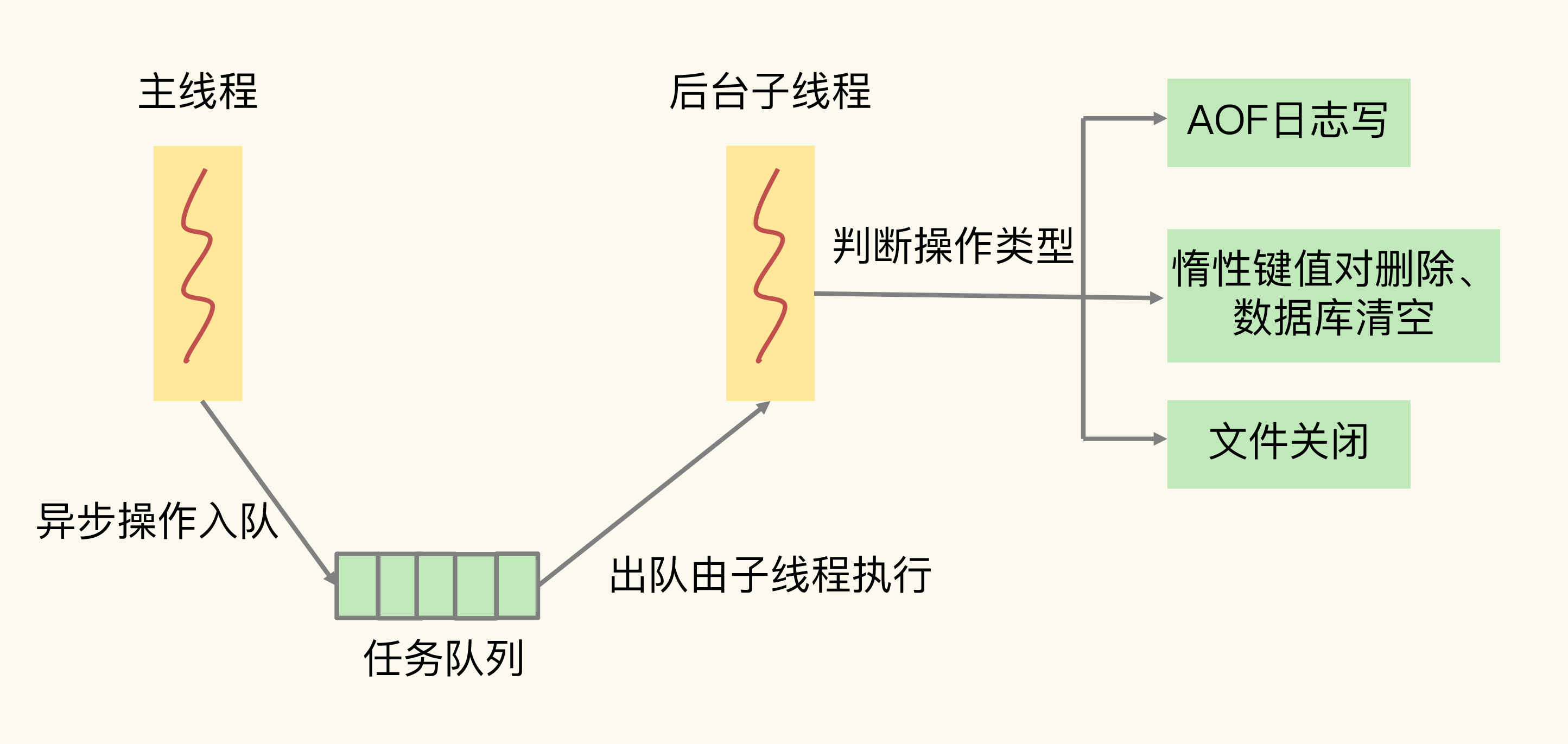
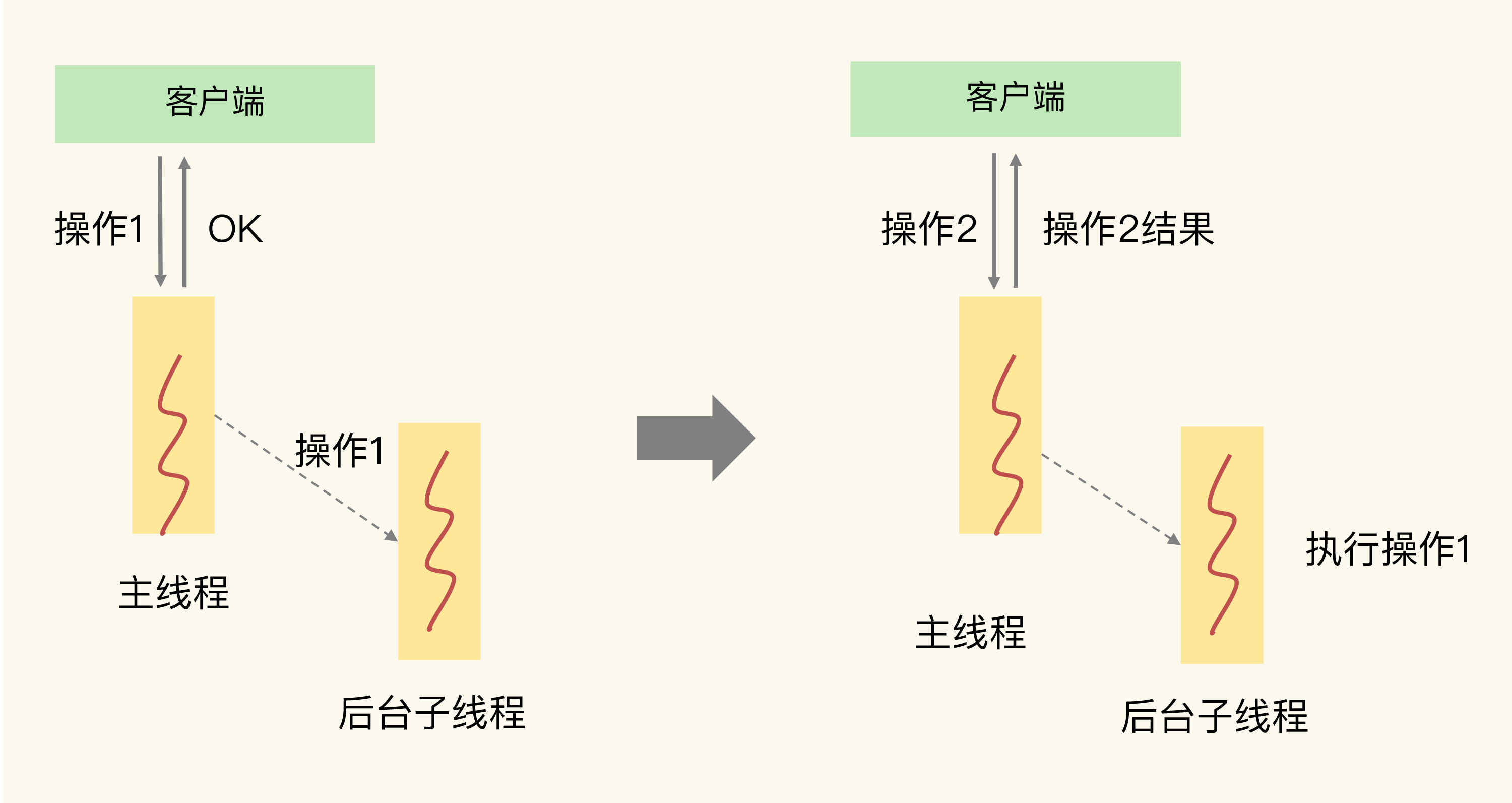
主线程和子线程之间通过一个任务队列交互。工作流程是:
- 主线程收到删除或清空命令
- 主线程把操作封装成任务,放入任务队列
- 主线程立即给客户端返回 OK
- 后台子线程从队列取出任务,执行实际的内存释放
这种模式叫惰性删除(lazy free)------主线程标记"要删",但实际删除延后到子线程执行。
AOF 的异步写也类似:everysec 策略下,主线程把"写 AOF"封装成任务放入队列,子线程负责实际的 fsync 操作。主线程不用等 fsync 完成就能继续处理下一条命令。
惰性删除的命令
异步删除是 Redis 4.0 引入的功能,对应的命令是:
bash
# 异步删除 key(替代 DEL)
UNLINK key1 key2 key3
# 异步清空数据库(替代 FLUSHDB / FLUSHALL)
FLUSHDB ASYNC
FLUSHALL ASYNCUNLINK 和 DEL 的语义完全一致,区别只在于内存释放是异步的。对客户端来说,UNLINK 返回后 key 就已经不可见了(从键空间中移除),但底层内存可能还没释放。
lazy-free 的配置项
Redis 4.0+ 提供了四个 lazy-free 配置开关:
lazyfree-lazy-expire yes # key 过期删除时异步释放
lazyfree-lazy-eviction yes # 内存淘汰时异步释放
lazyfree-lazy-server-del yes # RENAME 等命令覆盖旧 key 时异步释放
replica-lazy-flush yes # 从库全量同步清空数据时异步释放默认都是关闭的,需要手动开启。
lazy-free 的触发条件
一个容易被忽略的细节:即使开启了 lazy-free,Redis 也不是所有删除都走异步。Redis 会先评估释放内存的代价,如果代价很低就直接在主线程释放,避免跨线程传递数据的开销。
具体的判断逻辑(源码中的 lazyfreeGetFreeEffort 函数):
- Hash / Set 底层是哈希表(非 ziplist / intset)且元素超过 64 个 → 异步
- Sorted Set 底层是跳表(非 ziplist)且元素超过 64 个 → 异步
- List 的链表节点数超过 64 个 → 异步
- 其他情况(String 不管多大、小集合、ziplist 编码的集合)→ 主线程直接释放
这意味着 String 类型的 bigkey 即使开了 lazy-free,删除时仍然会阻塞主线程。因为 String 的内存是连续的一块,释放代价被认为是低的。所以最根本的建议还是:不要在 Redis 里存 bigkey。
不能异步的阻塞点怎么办
对于集合全量查询和聚合操作,建议用 SCAN 系列命令分批读取:
bash
# 分批遍历 Hash
HSCAN myhash 0 COUNT 200
# 分批遍历 Set
SSCAN myset 0 COUNT 200每次只取一小批数据,单次命令耗时可控,不会长时间阻塞主线程。聚合计算放到客户端做,或者用从库来跑。
对于从库加载 RDB 文件,核心策略是控制 RDB 文件大小。主库数据量建议控制在 2-4GB,这样 RDB 文件能在可接受的时间内加载完成。如果数据量更大,应该用切片集群把数据分散到多个实例。
4.0 之前版本的 bigkey 删除策略
如果 Redis 版本低于 4.0,没有 UNLINK 和 lazy-free,删除 bigkey 只能用渐进式删除:
bash
# Hash 类型的渐进式删除
HSCAN bigkey 0 COUNT 200
# 拿到一批 field 后
HDEL bigkey field1 field2 ... field200
# 重复直到 HSCAN 返回 cursor 为 0
# 最后 DEL bigkey 删除空壳每次只删 200 个元素,单次 HDEL 耗时很短,不会阻塞主线程。Set 用 SSCAN + SREM,Sorted Set 用 ZSCAN + ZREM,List 用 LTRIM 逐段裁剪。
写操作是否在关键路径上
这是一个值得思考的问题。SET、HSET、SADD 这些写操作,客户端通常需要知道是否写入成功。但"成功"的含义因场景而异:
- 如果客户端只关心"数据写进去了",且命令是幂等的(多次执行结果一样),那写操作可以不算关键路径。
- 如果客户端需要根据返回值做分支判断(比如 SADD 返回 1 表示新增、0 表示已存在),那就是关键路径。
- 如果 Redis 配置了 maxmemory 但没设淘汰策略,写入可能返回 OOM 错误,客户端必须感知这个错误,此时也是关键路径。
所以写操作是否在关键路径上,取决于业务对返回值的依赖程度。
总结
Redis 的阻塞规避策略可以归纳为三层:
- 架构层:用 IO 多路复用避免网络阻塞,用子进程处理 RDB 和 AOF 重写
- 命令层:用 SCAN 替代全量查询,用 UNLINK 替代 DEL,用 ASYNC 选项替代同步清空
- 运维层:控制单 key 大小避免 bigkey,控制实例数据量避免 RDB 过大,合理配置 AOF 写回策略
单线程模型不是 Redis 的弱点,而是它的设计选择。只要把阻塞操作识别出来并妥善处理,单线程的 Redis 完全能支撑百万级 QPS。关键是对每一个可能耗时的操作都保持警觉,在设计阶段就把风险消灭掉。
