微信公众号近 1~2 年,主推贴图类型作品,并且对这类内容有比较明显的流量倾斜。再叠加这两年 AI 生图的成熟,Nano Banana Pro 和 GPT-Image-2 先后出世,既然图片生产不再是卡点,那很多人会很自然地想到一个项目:用 OpenClaw、Codex、Claude Code 这类 Agent 工具,把公众号贴图自动化做起来。
理论上,这听起来像一个很好且成本不高的生意。AI 负责生图,Agent 负责写文案,公众号负责推荐流。人只要选图、点发布,甚至再往后一点,连选图都可以交给 Agent。
但实际上真的有这么简单吗?我自己维护的公众号《女程序媛多肉》,看起来只是发了几张漂亮照片,短短 3 天吸引了 220 个左右的粉丝。但真正做下来,我却花了大量的功夫。AI 小绿书表面是生图项目,底层其实是一个很典型的 Agent 工程项目。 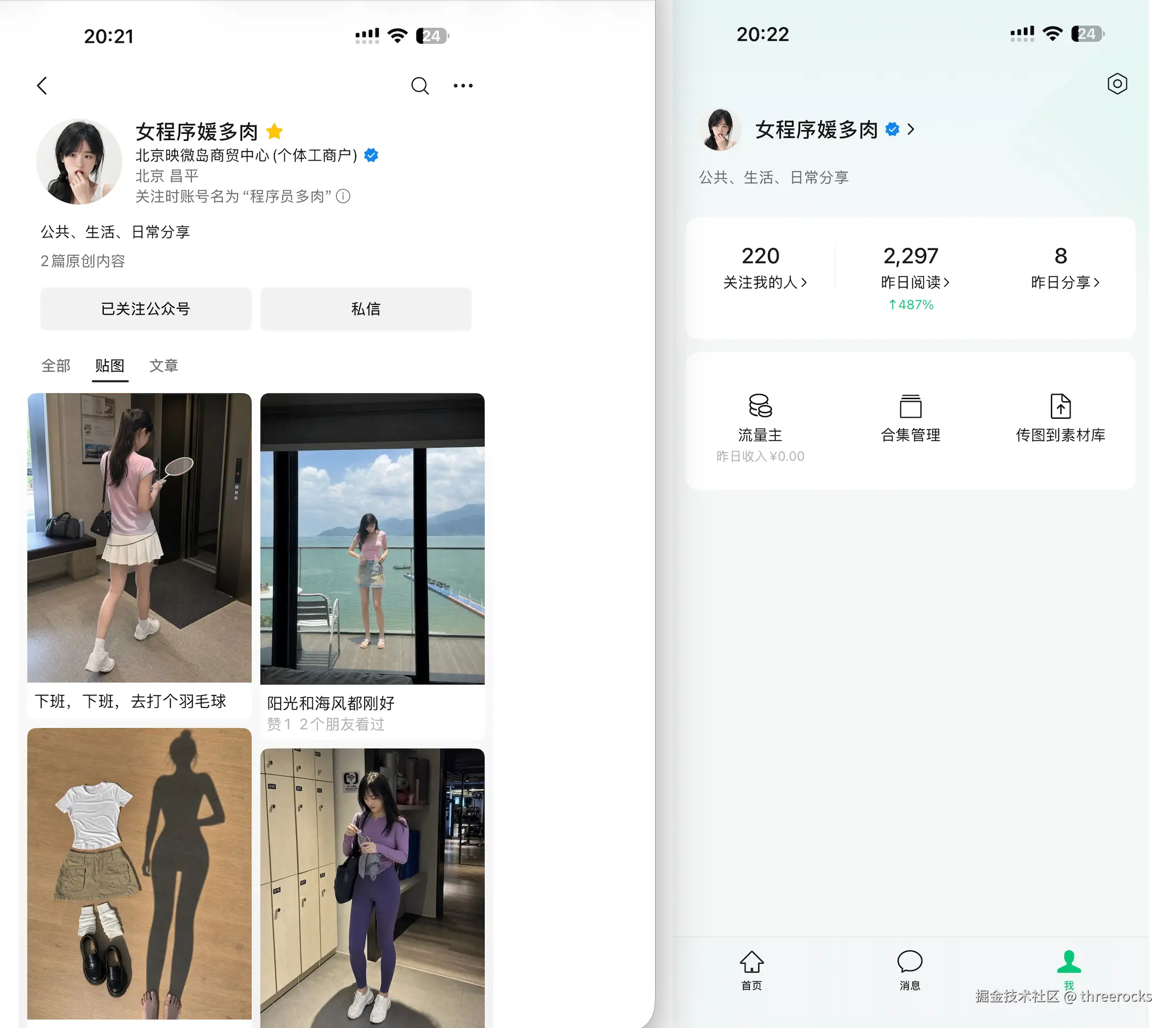 这个过程里,我们踩了不少坑。下面我做一下总结,希望对你在 AI 工程化的思路上有所帮助。
这个过程里,我们踩了不少坑。下面我做一下总结,希望对你在 AI 工程化的思路上有所帮助。
1. 人物一致性
做 AI 贴图的第一反应,通常是追求画面质量和惊艳的感觉,比如更漂亮的人、更干净的背景、更精致的穿搭、更像摄影大片的光线。模型也很愿意往这个方向走,因为这些东西在训练分布里太常见了。
但对《女程序媛多肉》来说,我们真正要做的不是"生成一个好看的女生",而是让固定人物【多肉】持续出现在固定生活半径里。这个区别非常关键。一开始最容易出现的问题,就是每张图单独看都不错,但放在一起不像同一个人。脸型轻微漂移,发量变了,刘海变了,身材比例变了,妆感变了,甚至气质也从普通女程序员通勤照,慢慢跑成网红写真。
更麻烦的是,这种问题不是一句 prompt 能解决的。你写"same girl""same face""保持角色一致",模型有时会把一致性理解成角色设定稿,于是画面开始变得更干净、更棚拍、更像 AI 人像。当然,也不是说你生成一张固定的角色信息卡就可以了,理论上它和 prompt 面临同样的问题。
我们后来对这个问题的判断是:角色一致性不能来自"设定稿强约束",而应该来自"同一生活序列"。也就是说,不能把主模特锚点当成画风来源。它只能提供身份边界,告诉模型不要漂成别人。真正的出图锚点,应该逐渐迁移到同一人物、同一天、同一场景、同一手机成像分布下的连续生活照。
所以我们在流程里做了几个约束:
- 固定人物身份:22 岁北京女程序员,多肉。
- 固定生活半径:出租屋门口、公司电梯、园区、工位附近、楼下取快递。
- 固定内容语境:通勤穿搭、程序员日常、出门前的小选择。
- 同组连续性:同一套图里发型、刘海、包、袜子、鞋子、场景、光线和拍摄语境必须一致。
- 禁止人物镜子图:因为镜中人物和真实人物一旦不一致,一眼假会非常明显。
这套约束很像开发工作中的工程配置。但它解决的是账号最核心的问题:用户关注的不是一张图,而是一个可以持续出现的人。
2. 衣服经常不是穿上去,而是贴上去
贴图账号如果要做穿搭,第二个大坑是服装。很多 AI 图第一眼看还行,细看会发现衣服像贴在身体表面。裙摆没有重量,袜口没有压痕,鞋底没有接触,口袋没有厚度,衣服褶皱也不是来自肩膀、腰线、坐姿或包带,而是模型随手画出来的纹理。
这类问题在普通审美里可能只是瑕疵,但在穿搭内容里是硬伤。因为用户看到的是"这件衣服穿在身上是什么效果"。如果衣服只是像一层贴图,穿搭展示就不成立。
我们后来把穿搭任务单独抽成了一个契约:只要用户给了衣服、裤子、鞋、包或说"穿这个",系统就必须把一级目标锁死为:固定模特多肉,穿用户给定服装,在已批准场景里生成真实日常照片。
这里面有几个优先级非常硬:第一,必须是多肉本人。第二,衣服必须穿在她身上。第三,第一张图必须清楚展示服装。第四,一组图必须像同一天同一套衣服的连续照片,而不是不同批次拼出来的好看图。
这个约束解决了一个很常见的漂移:用户明明要穿搭图,Agent 却很容易跑去做账号策划、场景图、海报、泛日常内容,或者生成一张"氛围很好但衣服看不清"的图。
我们现在会在生成前强制写 generation-packet.md。里面不只写"生成一张真实照片",而是要把主体服装身份、摄影事件、构图透视、光源曝光、投影接触、头发皮肤表情、服装材质受力、环境生活细节、文件质感瑕疵和负向熔断都写进去。
可能你觉得这个太重了?但做久了发现,AI 生图最怕的就是目标太软。你给它一个软目标,它就会用训练分布里最安全、最漂亮的方式把你糊弄过去。
还有,要先定义失败条件,再让模型生成。比如:
- 鞋底漂浮,失败。
- 裙摆没有接触暗部,失败。
- 衣服像贴图,失败。
- 包带和手臂没有遮挡关系,失败。
- 给定服装看不清,失败。
- 只生成环境不生成人,失败。
这比写一堆"高质量、真实、自然"有效得多。

3. 不懂摄影、绘图和光影,AI 只会更快地犯错
这也是我做这个项目之后一个很强烈的感受:想用好 AI,首先你必须对 AI 正在做的那个领域足够熟。否则,你无法判断 AI 的产物是否达标。一旦这样的作品发出去,结果可想而知。
不要以为 AI 生图的门槛是 prompt,其实不是。prompt 只是表达方式,真正起作用的是你有没有能力判断一张图为什么真,为什么假,哪里不符合摄影逻辑,哪里不符合人体和服装逻辑。
比如"光影真实"这四个字,模型听不懂。你要能拆成更具体的问题:
- 主光从哪里来?
- 鞋底接触阴影落在哪个面上?
- 裙摆、袜口、包带和手臂有没有遮挡暗部?
- 背景里的桌脚、鞋架、门把手、瓶罐有没有同一光源下的影子?
- 头发是不是一整片假发壳,还是有发束、遮挡和局部暗部?
- 皮肤是不是塑料磨皮,还是保留了毛孔、黑眼圈、鼻翼微红和环境光影响?
- 衣服褶皱是不是来自肩袖、腰线、坐姿、包带、重力和接触,还是随机噪声?
不懂这些,Agent 就只能写"真实、自然、高质量、手机随手拍"。听起来对,但生成出来大概率还是错。
所以,我们后来把摄影、绘图、光影、服装材质这些专业知识都放进了输入包和门禁里。它们不只是审查标准,也要进入真正提交给生成器的 prompt。
这点很重要。如果专业知识只停留在"生成后挑图",那 AI 仍然是在乱抽。只有把专业知识前置到生成包里,模型才有机会朝正确方向走。
这也是我现在对 AI 的一个基本判断:AI 会降低执行成本,但不会取消领域知识的价值。恰恰相反,它会放大领域知识的差距。
一个懂摄影、懂绘图、懂光影、懂内容平台的人,用 AI 是在加速生产。一个完全不懂这些东西的人,用 AI 只是更快地产出大量看起来完整、实际上经不起检查的内容。
这件事放到代码里也一样。你不懂工程,AI 写出代码你也不知道哪里危险。你不懂内容,AI 生成图文你也不知道哪里假。你不懂平台,AI 写出标题你也不知道为什么没有二跳信号。
AI Native 不是把人变成按钮操作员。真正的 AI Native,是把人的专业判断拆成机器能执行、能检查、能复用的流程。

4. 朱雀不是玄学,真实相机链路才是关键
做公众号图片,绕不开 AI 味。我们内部有一个硬门禁:最终展示照和生活照必须过腾讯朱雀,检测状态为绿色,也就是 AI probability 小于 40%。
这个门禁一加上,很多看起来不错的图直接被淘汰。
这里有个很有意思的现象:不是"穿搭题材"容易红,也不是"人物一致"天然会红。我们做过真实照片对照,真实地铁照、真实碎花裙照片、用户 iPhone 原生照片都能过绿色,甚至隐私处理后仍然能保持很低的 AI 概率。
反过来,Codex 内置生成的干净人像,或者强角色设定稿风格的参考图,经常会直接红到 90% 以上。这给我们的启发很大。
朱雀真正敏感的,不只是画面里有没有美女,而是整张图有没有真实相机分布:曝光、噪声、压缩、白平衡、边缘畸变、局部过曝、背景杂物、自然遮挡、动作瞬间、文件链路。
所以我们的解决思路不是继续堆"realistic""8K""high quality"。这些词没有用,甚至经常有反效果。
我们后来把低 AI 味拆成几类可执行约束:
- 人物为什么在这里?
- 她正在做什么?
- 谁在拍?
- 手机在哪个高度?
- 光从哪里来?
- 哪些地方应该糊一点?
- 哪些生活瑕疵应该保留?
- 哪些背景细节说明这不是棚拍?
比如同样是"出门前穿搭照",我们不会只写"真实手机照"。而会写成:
同一位 22 岁的北京女程序员多肉,早上出门前站在出租屋门口,正在把水杯和门卡放进电脑 tote 包。朋友在胸口高度随手拍到她低头整理包的一瞬间。手机广角,有轻微边缘畸变,廉价顶灯混合窗边弱光,墙面局部过曝。穿搭轮廓是视觉焦点,脸部不需要完美正脸。保留轻微黑眼圈、发丝凌乱、针织毛边、鞋面使用痕迹、桌上线缆和门口鞋子不齐。
这段话看起来啰嗦,但它不是修辞。它是在描述这张照片是怎么被拍到的。
这也是我们后来对"低 AI 味"的技术理解:不要用结果形容词,要写摄影事件。

5. 测试驱动生产
如果你让一个 Agent 负责从生成到验收,它大概率会变成一个很会夸自己的员工。它会告诉你:图像真实,人物一致,服装展示清楚,适合发布。
但你一看图,手指错了,包带断了,脚没有落地,脸跟上一张不像,场景像样板间,评论入口也不存在。这不是某个模型的问题,而是职责设计的问题。
生产 Agent 天然倾向于让任务继续往前走。它刚生成完一批图,很容易用语言把结果解释成合格。所以我们后来把测试/质量门禁提高到了最高优先级。
它不是事后背书,而是全过程参与:
- brief 阶段,判断目标是否清晰。
- generation packet 阶段,判断输入包有没有填完整。
- raw output 阶段,判断图片类型、人物、衣服、场景、一眼假。
- group candidate 阶段,判断同组人物、发型、配饰、袜子、鞋子、光线是否连续。
- final candidate 阶段,判断朱雀、隐私处理、运营风险和观众感受。
只要测试 Agent 判失败,生产 Agent 必须返工。用户喜欢、单张好看、朱雀绿色、隐私处理完成,都不能替代测试通过。
这个规则看起来有点反直觉。很多人会说,用户都觉得好看了,为什么还不能过?
原因很简单:我们要做的是长期账号资产,不是单张满意图。单张图好看但人物漂移,会伤害账号一致性。朱雀绿色但服装不清楚,会伤害穿搭目标。图片漂亮但标题没有点击理由,会伤害发布效果。
测试驱动生产的价值,就是阻止"主观满意"变成流程通行证。
6. 上下文会污染生成
做 Agent 项目的人应该都遇到过类似问题:一个上下文聊久了,模型会把历史里无关的东西带进当前任务。图像生成里这个问题更明显。
你前面讨论过海报,它可能把人物图生成成海报。你前面讨论过账号策划,它可能突然输出一张设定页。你前面看过失败图,它可能把失败图里的构图继续带进去。
所以我们把图像生成也当作一个不可靠外部系统来管理。核心原则是:生成提示必须从 08-generation-packet.md 派生,而不是从长会话临时拼接。
如果第一张输出已经跨领域偏航,比如人物图变成海报、UI、科普图、无人物图,立刻熔断。不能在同一上下文里继续"再试一次"。
熔断后要写 09-generation-debug.md:
- 本次输入包摘要是什么?
- 实际输出是什么?
- 偏离类型是什么?
- 是否疑似上下文污染?
- 下一步是新窗口隔离,还是补参考,还是明确授权 fallback?
这一步很重要。因为很多 AI 内容生产失败,不是模型完全不会做,而是上下文已经脏了。你继续改 prompt,只是在污染环境里做随机抽卡。
我们后来的做法是渐进披露:每个阶段只读必要信息。生成前只读本次 packet 和必要资产卡,门禁阶段只读候选图和检查表,发布包阶段只读通过门禁的作品和文案。历史 runs 可以参考,但不能变成当前上下文的垃圾场。
这套思路其实和软件工程里的隔离很像。不要让一个脏环境承担生产任务。

7. 贴图不是发图,是设计二跳信号
回到公众号贴图本身。如果只从技术角度看,我们很容易沉迷生成质量。但贴图内容能不能被推荐流继续放大,还要看另一层:用户有没有理由点开、停留、评论、收藏。
这也是我们后来专门加贴图增长门禁的原因。每篇贴图进入发布包前,都要回答几个问题:
- 首图点击理由是什么?
- 目标人群和垂直标签是什么?
- 和近 7 天内容相比,信息增量在哪里?
- 评论触发点是否安全且具体?
- 有没有准备 3 条安全评论引子?
- 发布后 15/60/180 分钟分别看什么数据?
- 什么情况下使用流量券,什么情况下不救?
这里面最重要的,不是学标题党。恰恰相反,我们明确禁止搬运、洗稿、低俗擦边、诱导私信、无意义评论堆叠。
贴图增长真正要解决的是:这张图为什么值得被推荐系统继续测试。比如标题只是"粉色上衣 + 牛仔短裙",它就是服装陈列。但标题如果是"上班穿粉色会不会太学生气",用户就能进入一个具体场景:公司氛围、年龄感、通勤、同事眼光、自己的衣柜。
这个差别不是文案技巧,而是内容结构。我们的技术思考是:Agent 不应该只生成图片,还应该生成发布前的增长证据。
如果它说这篇适合发布,就必须给出首图点击理由、评论触发点、差异化和复盘指标。否则就是空判断。
8. 最终我们怎么组织这条生产线
现在这条线大概被拆成几个角色。这不是为了显得复杂,而是因为单 Agent 很难同时承担"创造、执行、审查、运营、复盘"这些互相冲突的职责。
一个 Agent 既负责生产,又负责验收,就会自证成功。一个 Agent 既负责图片真实感,又负责增长判断,就会把"图好看"误判成"适合发布"。一个 Agent 既负责长期账号资产,又负责短期流量,就很容易为了点击牺牲边界。
所以我们更愿意把它做成多 Agent 设计。
第一个是上下文 Agent。它负责当天背景:北京天气、季节、通勤实用性、流行穿搭线索、可用场景建议。它不直接生成最终图,只负责把当天语境补齐。
第二个是主生产 Agent。它负责写生产计划和 generation-packet.md。这里最重要的是把目标写死:固定模特,多肉,穿给定服装,在已批准场景里展示。不能漂移成海报、账号策划、泛日常或者无人物场景。
第三个是生成执行。生成只吃 packet,不吃长会话里的随口描述。输出第一张就偏航,立刻熔断,不盲目重试。
第四个是测试/质量门禁 Agent。它有最高否决权。它检查人物、服装、场景、光影、材质、手、鞋、包、朱雀、隐私和组图连续性。没有证据就没有通过。
第五个是贴图增长门禁。它检查这篇内容有没有推荐流二跳信号:首图、标题、评论点、差异化、关键词、复盘指标。
第六个是发布包。只有通过前面门禁的作品,才能进入最终包。微信公众号也只允许自动创建草稿,不替用户点最终发布。
这就是我理解的 Agent Native 工程化。不是把一个大 prompt 写得越来越长,也不是把所有任务都塞给一个超级 Agent,而是把人的专业流程拆成多个职责明确的 Agent:谁负责补上下文,谁负责生产,谁负责失败熔断,谁负责摄影和真实感门禁,谁负责贴图增长,谁负责最终发布边界。
每个 Agent 都有自己的输入、输出和否决条件。它们之间不是聊天接力,而是工程链路。
这套流程看起来很重。但它的目的不是把简单事情复杂化,而是把不稳定的 AI 能力放进稳定系统里。
以前我们靠感觉判断"这张能不能发"。现在我们至少能说清楚:它在哪个门禁失败,失败原因是什么,下次要改输入包、场景、prompt、图像策略还是增长结构。
这就是工程化的价值。

9. 所以这是不是躺着收钱?
如果只看《女程序媛多肉》3 天 220 粉,这件事确实有吸引力。但我不会把它包装成躺赚项目。
因为真正跑起来之后,你会发现里面每一步都需要判断:
- 角色一致性怎么保?
- 给定服装怎么确保穿在身上?
- 图片怎么从 AI 人像分布拉回真实相机分布?
- 朱雀红了,是换 prompt,还是换底图路线?
- 第一张图偏成海报,是继续试,还是熔断?
- 图好看但没有点击理由,到底发不发?
- 数据在 1000 左右卡住,是首图弱、标题弱、评论弱,还是内容同质化?
这些问题没有一个能靠"再写一个神 prompt"彻底解决。它需要的是 Agent 工程化。
模型负责生成,Agent 负责执行流程,门禁负责否决,人工负责判断,数据负责纠偏。
我现在越来越觉得,这条线真正有价值的地方,不是它能不能立刻赚多少钱,而是它把 AI 内容生产里的很多问题都压缩到一个很小的场景里。
你会同时练到生图、提示词、角色一致性、真实感门禁、内容增长、发布边界、数据复盘和多 Agent 协作。这比单纯做几张漂亮图有意思得多。

我的判断
《女程序媛多肉》这 3 天 220 粉,只是一个开始。它说明公众号贴图这条线确实有窗口,也说明 AI 能显著降低内容生产成本。
但它同时也说明另一件事:AI 自动化不是让人少做事,而是把人的判断拆成流程。
角色一致性、服装上身、真实相机分布、朱雀门禁、上下文隔离、熔断机制、增长信号、发布复盘,这些东西拆清楚之后,AI 才不是在随机抽卡。
它才开始像生产。
所以如果你问我,这条 AI 小绿书路线值不值得做。
我的答案是:值得,但别把它当躺赚。
把它当一个小型 Agent 工程项目来做,你会更接近真实结果。