前言
大家好我是咪的Coding。
在使用 Spring Boot 进行开发的日常里,我们习惯了用 @Autowired 注入一个 Service,用 @Component 交出一个类,然后用 @SpringBootApplication 启动一切。一切似乎都那么"魔法",以至于我们有时会忘记:这一切运转的背后,是一套极其精密且优雅的容器系统。

Spring 最核心的基石,毫无疑问是 IOC(控制反转)容器 ,以及构建于其上的 自动装配(Autowiring) 机制。它们一个负责管理对象的整个生命周期,一个负责智能地编织对象间的依赖关系。
本文将尝试剥开"魔法"的外衣,从设计思想到核心源码脉络,层层递进地深度解析 IOC 容器如何诞生、如何工作,以及自动装配如何实现"无声明"的依赖注入。阅读之后,你不仅能理解"怎么用",更能洞悉"为什么是这样"。
一、反转的真相:什么是 IOC 容器?
1.1 从"主动拉取"到"被动接收"
控制反转(Inversion of Control)并非一种技术,而是一种设计思想。要理解它,我们回归到一个没有 Spring 的对象依赖场景。
假设我们有一个 MovieService,它需要调用 MovieRepository 来查询电影数据。
传统方式(正转):
java
public class MovieService {
private MovieRepository repository;
public MovieService() {
// 主动拉取:自己负责创建所依赖的对象
this.repository = new JdbcMovieRepository();
}
}在这种方式下,MovieService 直接控制了 MovieRepository 的创建时机和具体实现。这种"控制"让代码高度耦合。一旦我们需要将 JdbcMovieRepository 换成 MongoMovieRepository,就必须修改 MovieService 的源代码。
IOC 方式(反转):
java
public class MovieService {
private MovieRepository repository;
// 被动接收:通过构造器从外部传入依赖
public MovieService(MovieRepository repository) {
this.repository = repository;
}
}此时,MovieService 放弃了创建 MovieRepository 的控制权,而只是声明"我需要一个 MovieRepository"。控制权从"类的内部代码"反转给了"外部的第三方",这便是控制反转 。这个负责提供依赖、组装对象的"第三方",就是 IOC 容器。
容器负责:创建对象 → 管理对象的依赖关系 → 注入依赖 → 最终销毁对象。
这个过程的核心操作,就是 依赖注入(DI, Dependency Injection)。
所以常有人说:IOC 是思想,DI 是其实现方式。
二、容器的蓝图:BeanDefinition 与容器的启动
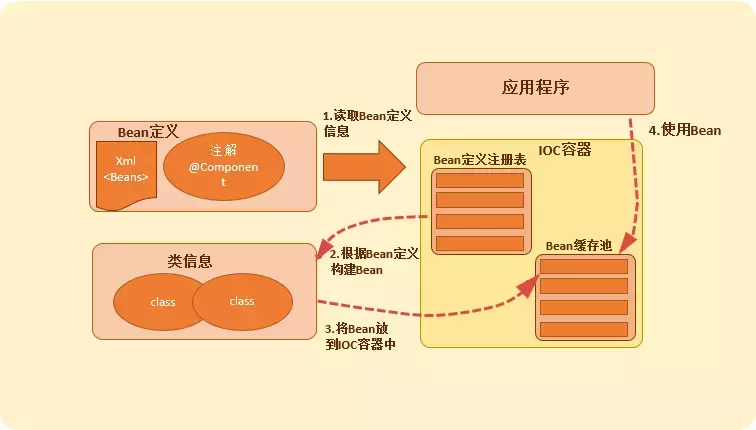
Spring IOC 容器并非魔法口袋,它不能凭空知道该创建哪些对象。一切管理行为的起点,是一张张精密的"图纸"------BeanDefinition。
2.1 BeanDefinition:Bean 的身份档案
当 Spring 通过 XML 的 <bean>、@Component 注解或 Java Config 的 @Bean 方法扫描到你的类时,它并不会立刻实例化这个类,而是首先将其抽象为一个 BeanDefinition 对象。
这个对象存储了生成一个完整 Bean 所需的全部元数据:
- 全限定类名 (
beanClassName):具体要实例化的类。 - 作用域 (
scope):单例(singleton)还是原型(prototype)。 - 依赖 (
dependsOn):依赖的其他 Bean 名称。 - 是否懒加载 (
lazyInit)。 - 构造器参数与属性值 (
constructorArgumentValues、propertyValues):即注入的依赖。
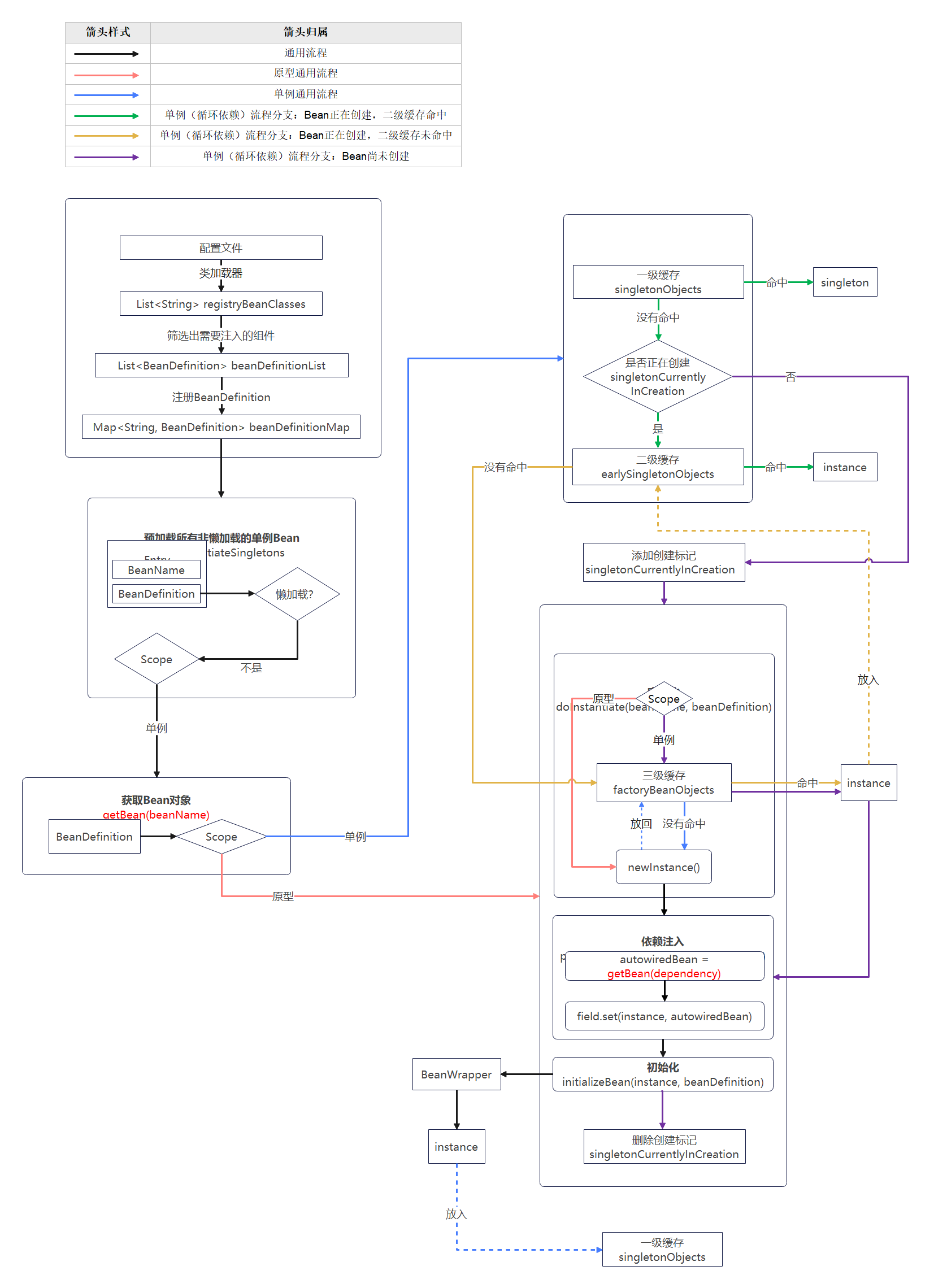
如果把 IOC 容器比作一个庞大的制造工厂,BeanDefinition 就是产品的设计蓝图。工厂的流水线启动前,必须先把所有蓝图收归入库,这就是容器的启动阶段。
2.2 容器的核心流程:定位、载入、注册
以经典的 ApplicationContext(如 AnnotationConfigApplicationContext)为例,它的启动主要经历三个步骤:
- 资源定位 :找到描述 Bean 的"资源"。比如
@ComponentScan指定的包路径,或是 XML 配置文件。 - 载入与解析 :将找到的资源解析成
BeanDefinition对象。例如ClassPathBeanDefinitionScanner会扫描带有@Component等注解的类,并为每个类创建一个ScannedGenericBeanDefinition。 - 注册 :将解析好的
BeanDefinition存入一个中心化的注册中心。这个注册中心在 Spring 中是一个ConcurrentHashMap,位于DefaultListableBeanFactory内:private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);。
至此,容器的"图纸库"建立完毕,但没有任何 Bean 被实例化。真正的"生产"发生在后续的刷新阶段。
三、生命之主:Bean 的创建与依赖注入原理
当容器执行 refresh() 方法时,会触发所有非懒加载的单例 Bean 的初始化。这个"生产"过程远比你想象的复杂,因为它要解决一个终极难题:如何按正确顺序,创建出依赖关系错综复杂的对象图?
3.1 创建的主干道:doCreateBean
Spring 创建 Bean 的逻辑枢纽在 AbstractAutowireCapableBeanFactory 类的 doCreateBean 方法中。它的核心步骤清晰勾勒了整个生命周期:
- 实例化 (
createBeanInstance):通过反射(或CGLIB代理等)调用构造器创建 Bean 的一个原始实例,此时其内部的所有依赖字段都还是null。 - 属性填充 (
populateBean):这是依赖注入真正发生的地方。容器会根据BeanDefinition里的propertyValues,或者解析@Autowired、@Resource等注解,通过反射将依赖的 Bean 注入到当前实例中。 - 初始化 (
initializeBean):如果 Bean 实现了InitializingBean接口,或定义了init-method,则依次调用。@PostConstruct注解的处理也在此阶段前后执行。
3.2 循环依赖的"阳谋":三级缓存
依赖注入中最经典的挑战是循环依赖。
比如 A 依赖 B,B 依赖 A,在 Spring 创建 A 时,需要注入 B,于是转去创建 B;创建 B 时,又需要注入 A。若没有特殊处理,这会陷入无限递归的死锁。
Spring 的单例池用三级缓存精妙地解决了可解决的循环依赖(仅限于单例 Bean 的 setter 注入):
- 一级缓存 (
singletonObjects):存放完全创建好的单例 Bean。 - 二级缓存 (
earlySingletonObjects):存放提前暴露出来的原始 Bean 实例(已实例化但未填充属性、未初始化)。 - 三级缓存 (
singletonFactories):存放能生成这个早期 Bean 引用的工厂(ObjectFactory)。
破局流程(A 与 B 相互依赖):
- A 实例化后,在未填充属性前,会把自己的一个工厂放入三级缓存。这个工厂能返回 A 的早期引用(或一个包装后的代理)。
- A 填充属性时,发现自己依赖 B,于是去获取 B。
- 容器发现 B 不存在,于是走 B 的创建流程。B 实例化后填充属性时,发现自己依赖 A。
- 容器尝试获取 A。此时 A 虽然未创建完成,但其工厂已在三级缓存中。于是容器通过工厂获得 A 的早期引用,并将其提升至二级缓存,然后顺利将此引用注入到 B 中。
- B 随后完成属性填充、初始化,最终被放入一级缓存。
- A 拿到完整的 B 后,继续完成自身的属性填充和初始化,最终进入一级缓存。
这个设计的本质是:利用一个内存中的中间态引用,打破对象创建的强依赖顺序。它不是"解决"了循环依赖,而是通过将"半成品"提前暴露,绕开了死锁。
四、自动装配的本质:从 XML 的 autowire 到注解驱动
"自动装配"这个词在 Spring 历史上经历了两次语义跃迁,理解这一点至关重要。
4.1 XML 时代的雏形
在纯 XML 时代,就有自动装配的概念:<bean id="movieService" class="..." autowire="byType"/>。其原理是:容器在填充属性时,会检查 BeanDefinition 的 autowireMode 属性。若为 byType,它会根据属性的 setter 方法参数类型,去容器中寻找匹配的 Bean 并注入。
这种方式的"自动"极其有限,仅仅是省去了显式的 <property> 标签,根源仍在 XML 声明。
4.2 注解革命的实现:后置处理器
现代 Spring 的自动装配,核心是注解驱动的依赖注入 ,其主角是 @Autowired、@Value、@Resource 等。实现这一魔法的关键演员,是 BeanPostProcessor(后置处理器) 家族。
具体来说,是 AutowiredAnnotationBeanPostProcessor 这个特殊的后置处理器。它会在容器启动时被注册,并等待着拦截每一个 Bean 的实例化过程。
五、深度拆解 @Autowired:一场精密的匹配游戏
当 populateBean 方法执行到处理注解注入的逻辑时,真正的核心流程才刚刚开始。
5.1 元数据的预先扫描
AutowiredAnnotationBeanPostProcessor 并不会在每个 Bean 创建时才去解析它的字段和方法。为提升性能,它使用了缓存 :在第一次处理某个类的 Bean 时,它会用反射遍历该类的所有字段和方法,找出标注了 @Autowired、@Value、@Inject 的成员,封装成 InjectionMetadata 并缓存起来。后续同类型的 Bean 可以直接复用这份元数据。
5.2 依赖解析(resolveDependency)
找到需要注入的目标(如一个 MovieRepository 类型的字段)后,容器会调用 DefaultListableBeanFactory#resolveDependency 方法进行依赖解析。这是一套精密的匹配算法:
- 按类型匹配(核心) :依据字段的类型(
MovieRepository),去容器中查找所有符合此类型的 Bean。这会得到一个候选者列表。 - 多候选者的裁决(限定) :
- 如果找到多个同类型的 Bean,Spring 会尝试按字段名称(
movieRepository)进行byName的二次筛选。 - 若还不够,它会寻找
@Qualifier注解,用明确的名字限定。 - 如果仍无法裁决,但有 Bean 标记了
@Primary,则优先选择它。 - 若所有条件都无法选出唯一 Bean,则抛出经典的
NoUniqueBeanDefinitionException。
- 如果找到多个同类型的 Bean,Spring 会尝试按字段名称(
- 惰性注入的代理 :如果匹配的 Bean 是懒加载的(
@Lazy),或者需要解决循环依赖,容器并不会立即注入真实对象,而是注入一个代理对象。只有在你真正调用代理的方法时,它才会去容器中取回目标 Bean 完成调用。
5.3 注入的执行
解析出最终的一个或多个 Bean 引用后,剩下的就是简单的反射调用:field.set(bean, resolvedDependency)。
至此,一个注解驱动的自动装配完美收官。它本质上是容器在某个特定生命周期阶段(属性填充),根据特定的规则(注解+类型),自动执行的动作序列。它不是魔法,而是一套组合了元数据缓存、类型/名称匹配算法和反射的、高度抽象的代码工程。
六、广义"自动装配"的延伸:Spring Boot 自动配置
今天,当我们谈论"自动装配"时,无法绕开 Spring Boot 的 AutoConfiguration。虽然它和我们上面讲的 @Autowired 依赖注入是不同层面的东西,但它们的哲学一脉相承。
Spring Boot 的 @EnableAutoConfiguration 注解,通过 @Import 引入了 AutoConfigurationImportSelector。该类会利用 SPI 机制(SpringFactoriesLoader),从所有 jar 包的 META-INF/spring.factories 文件中,加载以 EnableAutoConfiguration 为 key 的全限定类名列表。
这些类名就是一个个标注了 @Configuration 的自动配置类,比如 DataSourceAutoConfiguration。它们内部充满了 @ConditionalOnClass、@ConditionalOnMissingBean 等条件注解。
启动流程如下:
- 加载所有候选自动配置类。
- 过滤掉那些不满足条件(如类路径下没有相关依赖)的配置。
- 将剩下的配置类当作普通的
@Configuration类,解析其内部的@Bean方法,并把生成的BeanDefinition注册到容器中。
因此,Spring Boot 的"自动配置",本质上是利用条件化编程,在容器启动前,动态地向 IOC 容器批量注册了一批 BeanDefinition。它扩展了"谁负责把对象放入容器"的控制权,从"开发者显式声明"反转为"框架根据环境自动判断和声明"。这与 IOC 的思想同根同源,是控制反转在容器元数据层面的一次宏大实践。
总结
回望全文,我们穿越了 Spring IOC 与自动装配的迷雾,其内在逻辑层层递进:
- IOC 容器 是 Spring 的地基,它的本质是通过一个中央注册表(
BeanDefinitionMap)来接管对象创建与依赖管理的控制权。 - 依赖注入 是 IOC 的核心行为,发生在 Bean 的属性填充阶段,通过反射实现。三级缓存机制则以精巧的设计打破了单例 setter 注入的循环依赖僵局。
- 自动装配 是依赖注入的智能化升级。它通过
BeanPostProcessor机制介入 Bean 的生命周期,利用类型匹配、名称筛选和限定符裁决算法,自动解析并注入依赖,将开发者从繁杂的 XML 配置中彻底解放。 - 而 Spring Boot 自动配置,则是这一思想在容器元数据注册层面的升华,让容器自己"懂得"根据环境来装配自身。
这一切并非魔法,而是卓越的架构设计、对设计模式炉火纯青的运用(工厂、模板方法、后置处理器等),以及惊人的代码驾驭能力的共同产物。当我们下次看到 @Autowired 时,眼里看到的应该不再只是一个注解,而是背后那一整套有条不紊运转着的、精密而优雅的容器世界。
感谢你看到这里,如果喜欢咪的Coding的话可以点个关注支持一下吧!也欢迎各位在评论区留言!