文章目录
- 前言
-
- 一、第一代:离线计算时代(传统数仓)
- [二、 第二代:实时计算时代(实时数仓)](#二、 第二代:实时计算时代(实时数仓))
- [三、 第三代:AI 湖仓一体时代(未来趋势)](#三、 第三代:AI 湖仓一体时代(未来趋势))
- 四、三代数仓核心对比
- 五、数仓发展思考
- 六、整体总结
前言
系列文章完整串联业务系统 + 数据集成 + 数据仓库 + BI 落地全链路。
深度拆解企业标准四层数仓架构 :ODS 原始层→DW 明细层→DIM 维度层→DM 主题层,详解每层设计逻辑、字段规范、脱敏规则、落地开发要点,搭配汽车流通 / 航空制造 ERP/MOM 真实业务案例 ,讲透如何把杂乱的原始数据,沉淀为企业可复用、可对账、可赋能的标准数据资产。
数据仓库建设发展的不同时期对比及思考
-
离线计算时代(传统数仓或)
-
实时计算时代(实时数仓)
-
基于 AI 的湖仓一体时代(未来趋势)
将从架构、成本、性能、维护、场景五个维度,带你看清数仓 30 年演进路线,把握未来方向。
从最早只能隔天看数据的离线数仓 ,到能秒级更新的实时数仓 ,再到未来的 AI 湖仓一体,每一代升级,解决的都是企业最实在的问题:数据准不准、出数快不快、全不全、成本高不高、维护难不难。
这一篇,采用时间线、架构、成本、性能、维护难度、适用场景6 个维度,把三代数仓一次性讲明白:
1)离线计算时代(传统数仓)
2)实时计算时代(实时数仓)
3)AI 湖仓一体时代(未来趋势)
看完你就知道:你们公司现在该用哪套、未来该往哪走。
一、第一代:离线计算时代(传统数仓)
关键词:T+1、批量跑数、稳定、做报表首选
离线数仓是最经典、最成熟的模式,核心就是算历史数据、出固定报表、做经营分析、支持审计回溯。它不追求秒级出数,只追求准确、稳、能查历史。
1)两条主流技术路线
(1)轻量离线:Kettle / DataX + 普通数据库
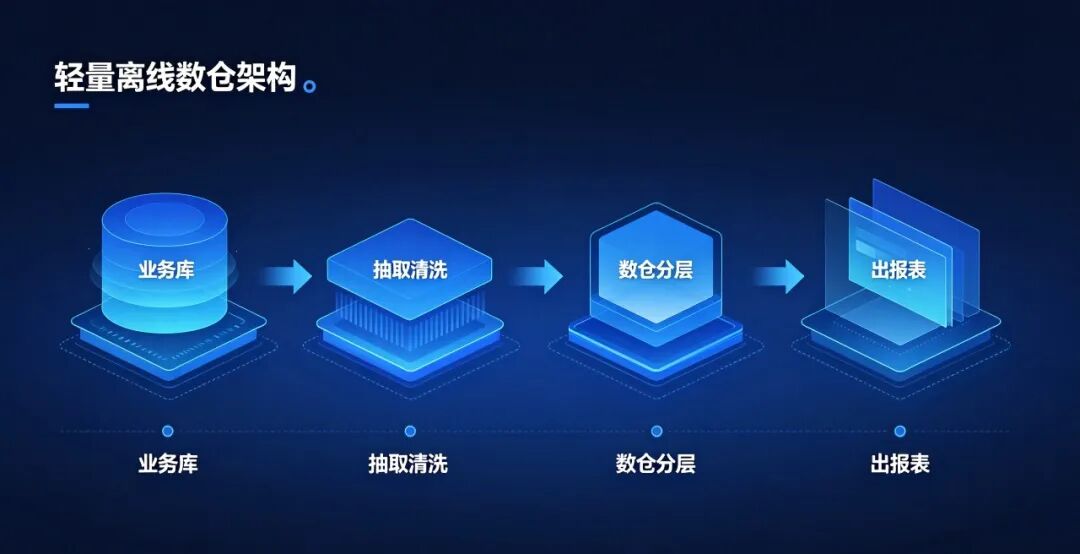
架构:业务库 → 抽取清洗 → 数仓分层 → 出报表
特点:轻量简单、不用搭大数据环境
成本:极低,一台服务器就能跑
性能:百万到千万级数据,每天凌晨跑一次
维护:很简单,脚本 + 定时调度就行
适用场景:中小企业、系统不多、数据量不大,只需要日报 / 周报 / 月报。
实战案例:区域汽车经销商、单店售后体系,用 DataX 同步订单、库存、客户数据,每天凌晨跑批,给管理层看经营报表。
(2)海量离线:Hive + Hadoop 生态
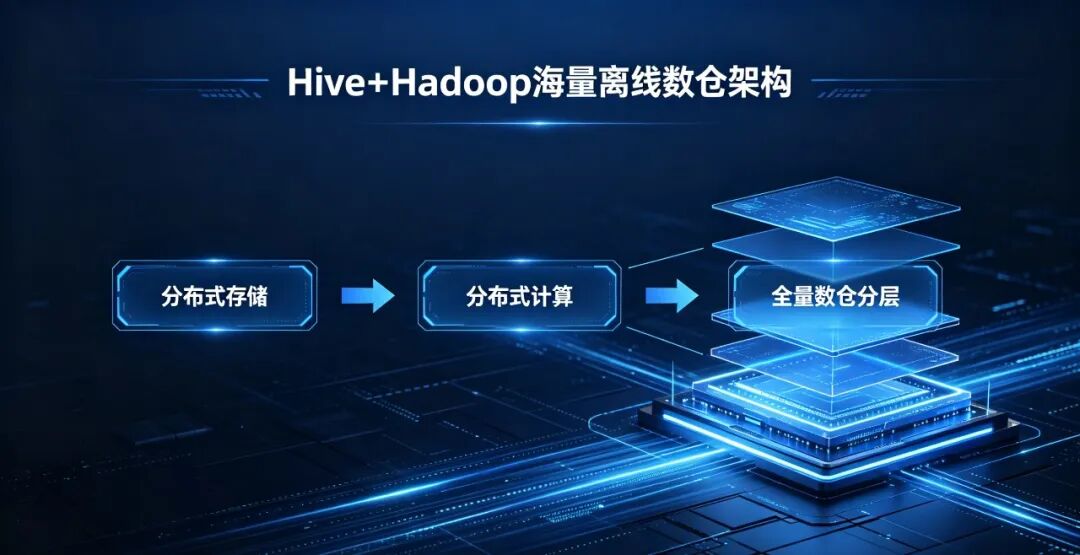
架构:分布式存储 → 分布式计算 → 全量数仓分层
特点:能扛 TB/PB 级海量数据、吞吐大、可扩展
成本:中等,需要集群和运维
性能:数据量再大也能稳定跑批
维护:相对复杂,需要专业大数据运维
适用场景:大型集团、多系统全接入、数据量超大、全业务分析。
实战案例:大型汽车集团、航空制造企业,ERP+CRM+MES+WMS 全部接入,每天新增上亿条数据,必须用 Hive+Hadoop 才能支撑。2)两条路线的相同与不同
相同点:都是批量计算、都是 T+1 出数、保证最终结果一致。
不同点:
Kettle/DataX:轻、快、易上手 → 中小企业首选
Hive+Hadoop:能扛海量数据、稳 → 大型集团必备二、
二、 第二代:实时计算时代(实时数仓)

关键词:秒级、流式处理、CDC、Kafka+Flink
当业务需要实时库存、实时销量、实时大屏、实时预警、实时营销时,隔天出数的离线方案完全顶不住,实时数仓就成了标配。
1)核心工具
消息队列:Kafka
计算引擎:Flink
数据采集:CDC(变更数据捕获)
2)CDC:实时数仓的 "源头活水"
CDC 直接抓取业务库的增删改,不影响业务、不锁表、延迟极低,让数据从 "小时同步" 变成秒级同步。
3)为什么一定要 Kafka + Flink 一起用?
很多人会问:两者都能做 CDC,为啥不能单独用?答案很简单:分工不同、能力互补、缺一不可。
Kafka:负责接住数据、削峰填谷、系统解耦遇到突发流量(比如集中交车、批量入库、大促下单),Kafka 先把流量 "稳住、排好队、平稳放出",保证下游不被冲垮、数据不丢不堵。
Flink:负责实时计算、清洗、关联、统一口径真正的实时加工、多表关联、指标计算、输出宽表,都要靠 Flink。
一句话记住:Kafka 管 "进" 和 "稳",Flink 管 "算" 和 "准"。
4)实时数仓整体特点
架构:CDC → Kafka → Flink → 实时数仓 → 大屏 / 接口
成本:偏高,资源消耗更大
性能:秒级~亚秒级
维护:中等,链路长但标准统一
场景:实时大屏、实时库存、实时风控、实时营销三、
三、 第三代:AI 湖仓一体时代(未来趋势)
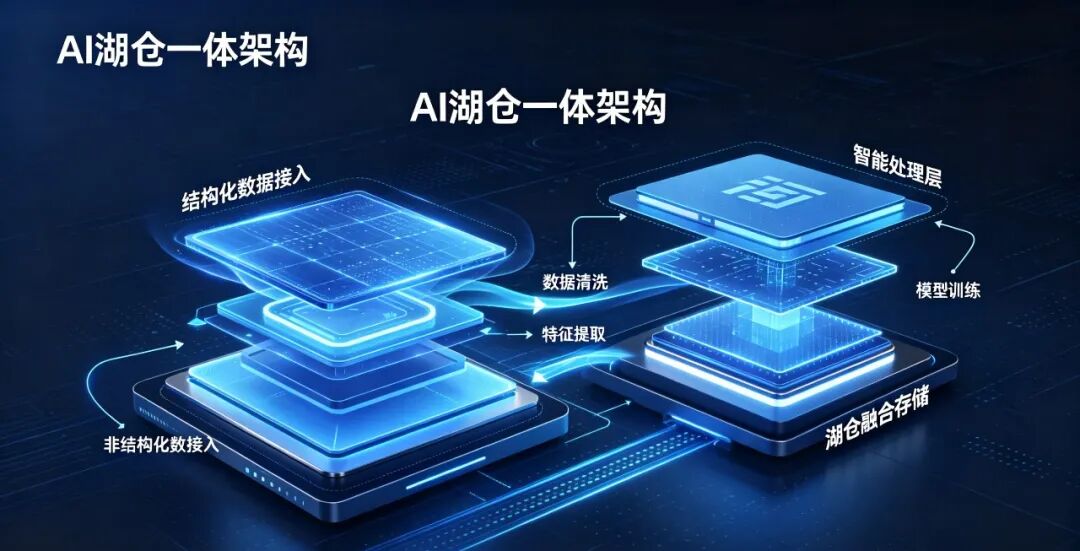
关键词:统一、智能、极简、支持全类型数据
湖仓一体是架构的终极简化;再加上 AI,整个数仓建设方式会被彻底改变。
1)核心能力(只讲趋势、点到为止)
AI 可以直接处理图片、文档、音频、视频、合同、质检单、报修记录等非结构化数据。
AI 自动把非结构化数据转成结构化数据,大幅减少人工清洗。
AI 实现结构化 + 非结构化数据统一接入、统一治理、统一分析。
整体流程极大简化、门槛降低、效率大幅提升,让数据建设从 "靠人堆" 走向 "靠智能"。
2)后续说明
AI 湖仓一体我目前也在持续学习和实践中,本篇只做趋势点明,不展开太深;等我把后面 BI(商务智能)内容全部讲完,会用一篇专门文章做更深入的讲解和落地思路分享。
四、三代数仓核心对比
完整版 6 维度表格
| 架构类型 | 时间线 | 架构特点 | 成本 | 性能 | 维护难度 | 适用场景 |
|---|---|---|---|---|---|---|
| 离线数仓(Kettle/DataX) | 早期~至今 | 简单 ETL、轻量同步 | 极低 | T+1 隔天出数 | 最简单 | 中小企业、固定报表、经营分析 |
| 离线数仓(Hive+Hadoop) | 大数据时代~至今 | 分布式存储计算、海量支撑 | 中等 | T+1、高吞吐 | 较重 | 大型集团、PB 级数据、全业务分析 |
| 实时数仓(Kafka+Flink) | 近 10 年主流 | 流式实时、秒级计算 | 较高 | 秒级实时 | 中等 | 实时大屏、实时库存、实时营销 |
| AI 湖仓一体(未来) | 正在到来 | 统一存储、AI 智能处理 | 逐步下降 | 统一智能、全链路 | 极简 | 全类型数据、AI 分析、自动治理 |
五、数仓发展思考
-
没有最好的架构,只有最适合的架构,小公司没必要硬上大数据,大公司也不能一直用轻量同步凑活。
-
实时不是替代离线,而是互相补充,离线管历史、管准确、管回溯;实时管业务、管响应、管效率。
-
未来一定走向:统一入口、统一治理、智能驱动数据不再分散、不再重复建设、不再靠大量人工清洗。
-
数仓的核心逻辑永远没变口径统一、标准先行、质量可控、高度复用,不管技术怎么迭代,这条永远不会变。
六、整体总结
数据仓库 30 年,从离线到实时,从海量到智能,每一步升级,都是为了让数据更贴近业务、更支撑决策;对企业来说,不必盲目追新,但要顺势而为:先把离线做稳,再把实时做通,最后稳步走向未来。
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识