VoxCPM 是一个高保真的语音合成工具包,以连续空间扩散自回归建模为核心,为你的应用带来真实自然、富有表现力的声音。
GitHub 地址https://github.com/OpenBMB/VoxCPM
使用版本 v2.0.3
主要解决离线环境部署时,模型文件从互联网拉取问题
1. 安装
互联网环境安装,方便拉取模型
bash
pip install voxcpm2.启动Web Demo 网页演示
网页演示需要克隆源码仓库。如果你在上一步通过 pip install voxcpm 完成安装,仍然需要克隆仓库:
bash
git clone https://github.com/OpenBMB/VoxCPM.git
cd VoxCPM
pip install -e .
python app.pyWeb Demo 在首次使用时还会额外下载一个 ASR 模型(SenseVoice-Small),用于 prompt 音频转写。
3. 启动后直接在网页访问,触发完成一次音频生成
模型文件会自动下载到本地
涉及3个模型
- models--openbmb--VoxCPM2
- SenseVoiceSmall
- speech_zipenhancer_ans_multiloss_16k_base
分别会下载到以下路径
~/.cache/huggingface/hub/models--openbmb--VoxCPM2/
~/.cache/modelscope/hub/models/iic/SenseVoiceSmall/
~/.cache/modelscope/hub/models/iic/speech_zipenhancer_ans_multiloss_16k_base/(speech_zipenhancer_ans_multiloss_16k_base我手动下载的,不确定是否是上面路径,自行判断)
4. 把这些模型目录打包,移到内网环境
k8s部署就挂到pvc

使用docker.io/pytorch/pytorch:2.9.1-cuda12.6-cudnn9-runtime 镜像自行构建或者下载其他人上传的voxcpm镜像
5. 启动时找不到模型从互联网拉取解决
主要是没有从本地检查到这两个模型:
SenseVoiceSmall
speech_zipenhancer_ans_multiloss_16k_base
修改变量等方式未解决,需要修改app.py代码从本地读取模型文件
可以直接人工改的模型位置,搜'SenseVoiceSmall'
self.asr_model_id = "iic/SenseVoiceSmall" #改为
self.asr_model_id = "/root/.cache/modelscope/hub/models/iic/SenseVoiceSmall"speech_zipenhancer_ans_multiloss_16k_base
代码文件内没有(真实调用生成音频时才会加载),改了部分代码,可以直接复制下面的app.py使用 (能正常启动不需要参考下面代码文件)
启动命令:
powershell
python app.py --zipenhancer-path /root/.cache/modelscope/hub/models/iic/speech_zipenhancer_ans_multiloss_16k_base
#如果遇到torch.compile 调用的 triton 编译器找不到 C 编译器问题,安装gcc等。或使用下面启动参数跳过
python3 app.py --no-optimize
python
import os
import re
import sys
import logging
import numpy as np
import torch
import gradio as gr
from typing import Optional, Tuple
from funasr import AutoModel
from pathlib import Path
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import voxcpm
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger = logging.getLogger(__name__)
# ---------- Inline i18n (en + zh-CN only) ----------
_USAGE_INSTRUCTIONS_EN = (
"**VoxCPM2 --- Three Modes of Speech Generation:**\n\n"
"🎨 **Voice Design** --- Create a brand-new voice \n"
"No reference audio required. Describe the desired voice characteristics "
"(gender, age, tone, emotion, pace ...) in **Control Instruction**, and VoxCPM2 "
"will craft a unique voice from your description alone.\n\n"
"🎛️ **Controllable Cloning** --- Clone a voice with optional style guidance \n"
"Upload a reference audio clip, then use **Control Instruction** to steer "
"emotion, speaking pace, and overall style while preserving the original timbre.\n\n"
"🎙️ **Ultimate Cloning** --- Reproduce every vocal nuance through audio continuation \n"
"Turn on **Ultimate Cloning Mode** and provide (or auto-transcribe) the reference audio's transcript. "
"The model treats the reference clip as a spoken prefix and seamlessly **continues** from it, faithfully preserving every vocal detail."
"Note: This mode will disable Control Instruction."
)
_EXAMPLES_FOOTER_EN = (
"---\n"
"**💡 Voice Description Examples:** \n"
"Try the following Control Instructions to explore different voices: \n\n"
"**Example 1 --- Gentle & Melancholic Girl** \n"
'`Control Instruction`: *"A young girl with a soft, sweet voice. '
'Speaks slowly with a melancholic, slightly tsundere tone."* \n'
'`Target Text`: *"I never asked you to stay... It\'s not like I care or anything. '
'But... why does it still hurt so much now that you\'re gone?"* \n\n'
"**Example 2 --- Laid-Back Surfer Dude** \n"
'`Control Instruction`: *"Relaxed young male voice, slightly nasal, '
'lazy drawl, very casual and chill."* \n'
'`Target Text`: *"Dude, did you see that set? The waves out there are totally gnarly today. '
"Just catching barrels all morning --- it's like, totally righteous, you know what I mean?\"*"
)
_USAGE_INSTRUCTIONS_ZH = (
"**VoxCPM2 --- 三种语音生成方式:**\n\n"
"🎨 **声音设计(Voice Design)** \n"
"无需参考音频。在 **Control Instruction** 中描述目标音色特征"
"(性别、年龄、语气、情绪、语速等),VoxCPM2 即可为你从零创造独一无二的声音。\n\n"
"🎛️ **可控克隆(Controllable Cloning)** \n"
"上传参考音频,同时可选地使用 **Control Instruction** 来指定情绪、语速、风格等表达方式,"
"在保留原始音色的基础上灵活控制说话风格。\n\n"
"🎙️ **极致克隆(Ultimate Cloning)** \n"
"开启 **极致克隆模式** 并提供参考音频的文字内容(可自动识别)。"
"模型会将参考音频视为已说出的前文,以**音频续写**的方式完整还原参考音频中的所有声音细节。"
"注意:该模式与可控克隆模式互斥,将禁用Control Instruction。\n\n"
)
_EXAMPLES_FOOTER_ZH = (
"---\n"
"**💡 声音描述示例(中英文均可):** \n\n"
"**示例 1 --- 深宫太后** \n"
'`Control Instruction`: *"中老年女性,声音低沉阴冷,语速缓慢而有力,'
'字字深思熟虑,带有深不可测的城府与威慑感。"* \n'
'`Target Text`: *"哀家在这深宫待了四十年,什么风浪没见过?你以为瞒得过哀家?"* \n\n'
"**示例 2 --- 暴躁驾校教练** \n"
'`Control Instruction`: *"暴躁的中年男声,语速快,充满无奈和愤怒"* \n'
'`Target Text`: *"踩离合!踩刹车啊!你往哪儿开呢?前面是树你看不见吗?'
'我教了你八百遍了,打死方向盘!你是不是想把车给我开到沟里去?"* \n\n'
"---\n"
"**🗣️ 方言生成指南:** \n"
"要生成地道的方言语音,请在 **Target Text** 中直接使用方言词汇和句式,"
"并在 **Control Instruction** 中描述方言特征。 \n\n"
"**示例 --- 广东话** \n"
'`Control Instruction`: *"粤语,中年男性,语气平淡"* \n'
'✅ 正确(粤语表达):*"伙計,唔該一個A餐,凍奶茶少甜!"* \n'
'❌ 错误(普通话原文):*"伙计,麻烦来一个A餐,冻奶茶少甜!"* \n\n'
"**示例 --- 河南话** \n"
'`Control Instruction`: *"河南话,接地气的大叔"* \n'
'✅ 正确(河南话表达):*"恁这是弄啥嘞?晌午吃啥饭?"* \n'
'❌ 错误(普通话原文):*"你这是在干什么呢?中午吃什么饭?"* \n\n'
"🤖 **小技巧:** 不知道方言怎么写?可以用豆包、DeepSeek、Kimi 等 AI 助手"
"将普通话翻译为方言文本,再粘贴到 Target Text 中即可。 \n\n"
)
_I18N_TRANSLATIONS = {
"en": {
"reference_audio_label": "🎤 Reference Audio (optional --- upload for cloning)",
"show_prompt_text_label": "🎙️ Ultimate Cloning Mode (transcript-guided cloning)",
"show_prompt_text_info": "Auto-transcribes reference audio for every vocal nuance reproduced. Control Instruction will be disabled when active.",
"prompt_text_label": "Transcript of Reference Audio (auto-filled via ASR, editable)",
"prompt_text_placeholder": "The transcript of your reference audio will appear here ...",
"control_label": "🎛️ Control Instruction (optional --- supports Chinese & English)",
"control_placeholder": "e.g. A warm young woman / 年轻女性,温柔甜美 / Excited and fast-paced",
"target_text_label": "✍️ Target Text --- the content to speak",
"generate_btn": "🔊 Generate Speech",
"generated_audio_label": "Generated Audio",
"advanced_settings_title": "⚙️ Advanced Settings",
"ref_denoise_label": "Reference audio enhancement",
"ref_denoise_info": "Apply ZipEnhancer denoising to the reference audio before cloning",
"normalize_label": "Text normalization",
"normalize_info": "Normalize numbers, dates, and abbreviations via wetext",
"cfg_label": "CFG (guidance scale)",
"cfg_info": "Higher → closer to the prompt / reference; lower → more creative variation",
"dit_steps_label": "LocDiT flow-matching steps",
"dit_steps_info": "LocDiT flow-matching steps --- more steps → maybe better audio quality, but slower",
"usage_instructions": _USAGE_INSTRUCTIONS_EN,
"examples_footer": _EXAMPLES_FOOTER_EN,
},
"zh-CN": {
"reference_audio_label": "🎤 参考音频(可选 --- 上传后用于克隆)",
"show_prompt_text_label": "🎙️ 极致克隆模式(基于文本引导的极致克隆)",
"show_prompt_text_info": "自动识别参考音频文本,完整还原音色、节奏、情感等全部声音细节。开启后 Control Instruction 将暂时禁用",
"prompt_text_label": "参考音频内容文本(ASR 自动填充,可手动编辑)",
"prompt_text_placeholder": "参考音频的文字内容将自动识别并显示在此处 ...",
"control_label": "🎛️ Control Instruction(可选 --- 支持中英文描述)",
"control_placeholder": "如:年轻女性,温柔甜美 / A warm young woman / 暴躁老哥,语速飞快",
"target_text_label": "✍️ Target Text --- 要合成的目标文本",
"generate_btn": "🔊 开始生成",
"generated_audio_label": "生成结果",
"advanced_settings_title": "⚙️ 高级设置",
"ref_denoise_label": "参考音频降噪增强",
"ref_denoise_info": "克隆前使用 ZipEnhancer 对参考音频进行降噪处理",
"normalize_label": "文本规范化",
"normalize_info": "自动规范化数字、日期及缩写(基于 wetext)",
"cfg_label": "CFG(引导强度)",
"cfg_info": "数值越高 → 越贴合提示/参考音色;数值越低 → 生成风格更自由",
"dit_steps_label": "LocDiT 流匹配迭代步数",
"dit_steps_info": "LocDiT 流匹配生成迭代步数 --- 步数越多 → 可能生成更好的音频质量,但速度变慢",
"usage_instructions": _USAGE_INSTRUCTIONS_ZH,
"examples_footer": _EXAMPLES_FOOTER_ZH,
},
"zh-Hans": None, # alias, filled below
"zh": None, # alias, filled below
}
_I18N_TRANSLATIONS["zh-Hans"] = _I18N_TRANSLATIONS["zh-CN"]
_I18N_TRANSLATIONS["zh"] = _I18N_TRANSLATIONS["zh-CN"]
for _d in _I18N_TRANSLATIONS.values():
if _d is not None:
for _k, _v in _I18N_TRANSLATIONS["en"].items():
_d.setdefault(_k, _v)
I18N = gr.I18n(**_I18N_TRANSLATIONS)
DEFAULT_TARGET_TEXT = (
"VoxCPM2 is a creative multilingual TTS model from ModelBest, "
"designed to generate highly realistic speech."
)
_CUSTOM_CSS = """
.logo-container {
text-align: center;
margin: 0.5rem 0 1rem 0;
}
.logo-container img {
height: 80px;
width: auto;
max-width: 200px;
display: inline-block;
}
/* Toggle switch style */
.switch-toggle {
padding: 8px 12px;
border-radius: 8px;
background: var(--block-background-fill);
}
.switch-toggle input[type="checkbox"] {
appearance: none;
-webkit-appearance: none;
width: 44px;
height: 24px;
background: #ccc;
border-radius: 12px;
position: relative;
cursor: pointer;
transition: background 0.3s ease;
flex-shrink: 0;
}
.switch-toggle input[type="checkbox"]::after {
content: "";
position: absolute;
top: 2px;
left: 2px;
width: 20px;
height: 20px;
background: white;
border-radius: 50%;
transition: transform 0.3s ease;
box-shadow: 0 1px 3px rgba(0,0,0,0.2);
}
.switch-toggle input[type="checkbox"]:checked {
background: var(--color-accent);
}
.switch-toggle input[type="checkbox"]:checked::after {
transform: translateX(20px);
}
"""
_APP_THEME = gr.themes.Soft(
primary_hue="blue",
secondary_hue="gray",
neutral_hue="slate",
font=[gr.themes.GoogleFont("Inter"), "Arial", "sans-serif"],
)
# ---------- Model ----------
class VoxCPMDemo:
def __init__(self, model_id: str = "openbmb/VoxCPM2", zipenhancer_path: str | None = None, no_optimize: bool = False) -> None:
self.device = "cuda" if torch.cuda.is_available() else "cpu"
logger.info(f"Running on device: {self.device}")
self.asr_model_id = "/root/.cache/modelscope/hub/models/iic/SenseVoiceSmall"
self.asr_model: Optional[AutoModel] = AutoModel(
model=self.asr_model_id,
disable_update=True,
log_level="DEBUG",
device="cuda:0" if self.device == "cuda" else "cpu",
)
self.voxcpm_model: Optional[voxcpm.VoxCPM] = None
self._model_id = model_id
self._zipenhancer_path = zipenhancer_path
self._no_optimize = no_optimize
def get_or_load_voxcpm(self) -> voxcpm.VoxCPM:
if self.voxcpm_model is not None:
return self.voxcpm_model
logger.info(f"Loading model: {self._model_id}")
kwargs = dict(optimize=not self._no_optimize)
if self._zipenhancer_path:
kwargs["zipenhancer_model_id"] = self._zipenhancer_path
self.voxcpm_model = voxcpm.VoxCPM.from_pretrained(self._model_id, **kwargs)
logger.info("Model loaded successfully.")
return self.voxcpm_model
def prompt_wav_recognition(self, prompt_wav: Optional[str]) -> str:
if prompt_wav is None:
return ""
res = self.asr_model.generate(input=prompt_wav, language="auto", use_itn=True)
return res[0]["text"].split("|>")[-1]
def _build_generate_kwargs(
self,
*,
final_text: str,
audio_path: Optional[str],
prompt_text_clean: Optional[str],
cfg_value_input: float,
do_normalize: bool,
denoise: bool,
inference_timesteps: int = 10,
) -> dict:
generate_kwargs = dict(
text=final_text,
reference_wav_path=audio_path,
cfg_value=float(cfg_value_input),
inference_timesteps=inference_timesteps,
normalize=do_normalize,
denoise=denoise,
)
if prompt_text_clean and audio_path:
generate_kwargs["prompt_wav_path"] = audio_path
generate_kwargs["prompt_text"] = prompt_text_clean
return generate_kwargs
def generate_tts_audio(
self,
text_input: str,
control_instruction: str = "",
reference_wav_path_input: Optional[str] = None,
prompt_text: str = "",
cfg_value_input: float = 2.0,
do_normalize: bool = True,
denoise: bool = True,
inference_timesteps: int = 10,
) -> Tuple[int, np.ndarray]:
current_model = self.get_or_load_voxcpm()
text = (text_input or "").strip()
if len(text) == 0:
raise ValueError("Please input text to synthesize.")
control = (control_instruction or "").strip()
# Strip any parentheses (half-width/full-width) from control text to avoid
# breaking the "(control)text" prompt format expected by the model.
control = re.sub(r"[()()]", "", control).strip()
final_text = f"({control}){text}" if control else text
audio_path = reference_wav_path_input if reference_wav_path_input else None
prompt_text_clean = (prompt_text or "").strip() or None
if audio_path and prompt_text_clean:
logger.info(f"[Voice Cloning] prompt_wav + prompt_text + reference_wav")
elif audio_path:
logger.info(f"[Voice Control] reference_wav only")
else:
logger.info(f"[Voice Design] control: {control[:50] if control else 'None'}...")
logger.info(f"Generating audio for text: '{final_text[:80]}...'")
generate_kwargs = self._build_generate_kwargs(
final_text=final_text,
audio_path=audio_path,
prompt_text_clean=prompt_text_clean,
cfg_value_input=cfg_value_input,
do_normalize=do_normalize,
denoise=denoise,
inference_timesteps=inference_timesteps,
)
wav = current_model.generate(**generate_kwargs)
return (current_model.tts_model.sample_rate, wav)
# ---------- UI ----------
def create_demo_interface(demo: VoxCPMDemo):
gr.set_static_paths(paths=[Path.cwd().absolute() / "assets"])
def _generate(
text: str,
control_instruction: str,
ref_wav: Optional[str],
use_prompt_text: bool,
prompt_text_value: str,
cfg_value: float,
do_normalize: bool,
denoise: bool,
dit_steps: int,
):
actual_prompt_text = prompt_text_value.strip() if use_prompt_text else ""
actual_control = "" if use_prompt_text else control_instruction
sr, wav_np = demo.generate_tts_audio(
text_input=text,
control_instruction=actual_control,
reference_wav_path_input=ref_wav,
prompt_text=actual_prompt_text,
cfg_value_input=cfg_value,
do_normalize=do_normalize,
denoise=denoise,
inference_timesteps=int(dit_steps),
)
return (sr, wav_np)
def _on_toggle_instant(checked):
"""Instant UI toggle --- no ASR, no blocking."""
if checked:
return (
gr.update(visible=True, value="", placeholder="Recognizing reference audio..."),
gr.update(visible=False),
)
return (
gr.update(visible=False),
gr.update(visible=True, interactive=True),
)
def _run_asr_if_needed(checked, audio_path):
"""Run ASR after the UI has updated. Only when toggled ON."""
if not checked or not audio_path:
return gr.update()
try:
logger.info("Running ASR on reference audio...")
asr_text = demo.prompt_wav_recognition(audio_path)
logger.info(f"ASR result: {asr_text[:60]}...")
return gr.update(value=asr_text)
except Exception as e:
logger.warning(f"ASR recognition failed: {e}")
return gr.update(value="")
with gr.Blocks() as interface:
gr.HTML(
'<div class="logo-container">'
'<img src="/gradio_api/file=assets/voxcpm_logo.png" alt="VoxCPM Logo">'
"</div>"
)
gr.Markdown(I18N("usage_instructions"))
with gr.Row():
with gr.Column():
reference_wav = gr.Audio(
sources=["upload", "microphone"],
type="filepath",
label=I18N("reference_audio_label"),
)
show_prompt_text = gr.Checkbox(
value=False,
label=I18N("show_prompt_text_label"),
info=I18N("show_prompt_text_info"),
elem_classes=["switch-toggle"],
)
prompt_text = gr.Textbox(
value="",
label=I18N("prompt_text_label"),
placeholder=I18N("prompt_text_placeholder"),
lines=2,
visible=False,
)
control_instruction = gr.Textbox(
value="",
label=I18N("control_label"),
placeholder=I18N("control_placeholder"),
lines=2,
)
text = gr.Textbox(
value=DEFAULT_TARGET_TEXT,
label=I18N("target_text_label"),
lines=3,
)
with gr.Accordion(I18N("advanced_settings_title"), open=False):
DoDenoisePromptAudio = gr.Checkbox(
value=False,
label=I18N("ref_denoise_label"),
elem_classes=["switch-toggle"],
info=I18N("ref_denoise_info"),
)
DoNormalizeText = gr.Checkbox(
value=False,
label=I18N("normalize_label"),
elem_classes=["switch-toggle"],
info=I18N("normalize_info"),
)
cfg_value = gr.Slider(
minimum=1.0,
maximum=3.0,
value=2.0,
step=0.1,
label=I18N("cfg_label"),
info=I18N("cfg_info"),
)
dit_steps = gr.Slider(
minimum=1,
maximum=50,
value=10,
step=1,
label=I18N("dit_steps_label"),
info=I18N("dit_steps_info"),
)
run_btn = gr.Button(I18N("generate_btn"), variant="primary", size="lg")
with gr.Column():
audio_output = gr.Audio(label=I18N("generated_audio_label"))
gr.Markdown(I18N("examples_footer"))
show_prompt_text.change(
fn=_on_toggle_instant,
inputs=[show_prompt_text],
outputs=[prompt_text, control_instruction],
).then(
fn=_run_asr_if_needed,
inputs=[show_prompt_text, reference_wav],
outputs=[prompt_text],
)
run_btn.click(
fn=_generate,
inputs=[
text,
control_instruction,
reference_wav,
show_prompt_text,
prompt_text,
cfg_value,
DoNormalizeText,
DoDenoisePromptAudio,
dit_steps,
],
outputs=[audio_output],
show_progress=True,
api_name="generate",
)
return interface
def run_demo(
server_name: str = "0.0.0.0",
server_port: int = 8808,
show_error: bool = True,
model_id: str = "openbmb/VoxCPM2",
zipenhancer_path: str | None = None,
no_optimize: bool = False,
):
demo = VoxCPMDemo(model_id=model_id, zipenhancer_path=zipenhancer_path, no_optimize=no_optimize)
interface = create_demo_interface(demo)
interface.queue(max_size=10, default_concurrency_limit=1).launch(
server_name=server_name,
server_port=server_port,
show_error=show_error,
i18n=I18N,
theme=_APP_THEME,
css=_CUSTOM_CSS,
)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
"--model-id", type=str, default="openbmb/VoxCPM2",
help="Local path or HuggingFace repo ID (default: openbmb/VoxCPM2)",
)
parser.add_argument("--port", type=int, default=8808, help="Server port")
parser.add_argument(
"--zipenhancer-path", type=str, default=os.environ.get("ZIPENHANCER_MODEL_PATH"),
help="Local path to ZipEnhancer model (default: $ZIPENHANCER_MODEL_PATH env var, or auto-download from ModelScope)",
)
parser.add_argument(
"--no-optimize", action="store_true", default=False,
help="Disable torch.compile optimization (avoids triton C compiler requirement)",
)
args = parser.parse_args()
run_demo(model_id=args.model_id, server_port=args.port, zipenhancer_path=args.zipenhancer_path, no_optimize=args.no_optimize)6. web端使用
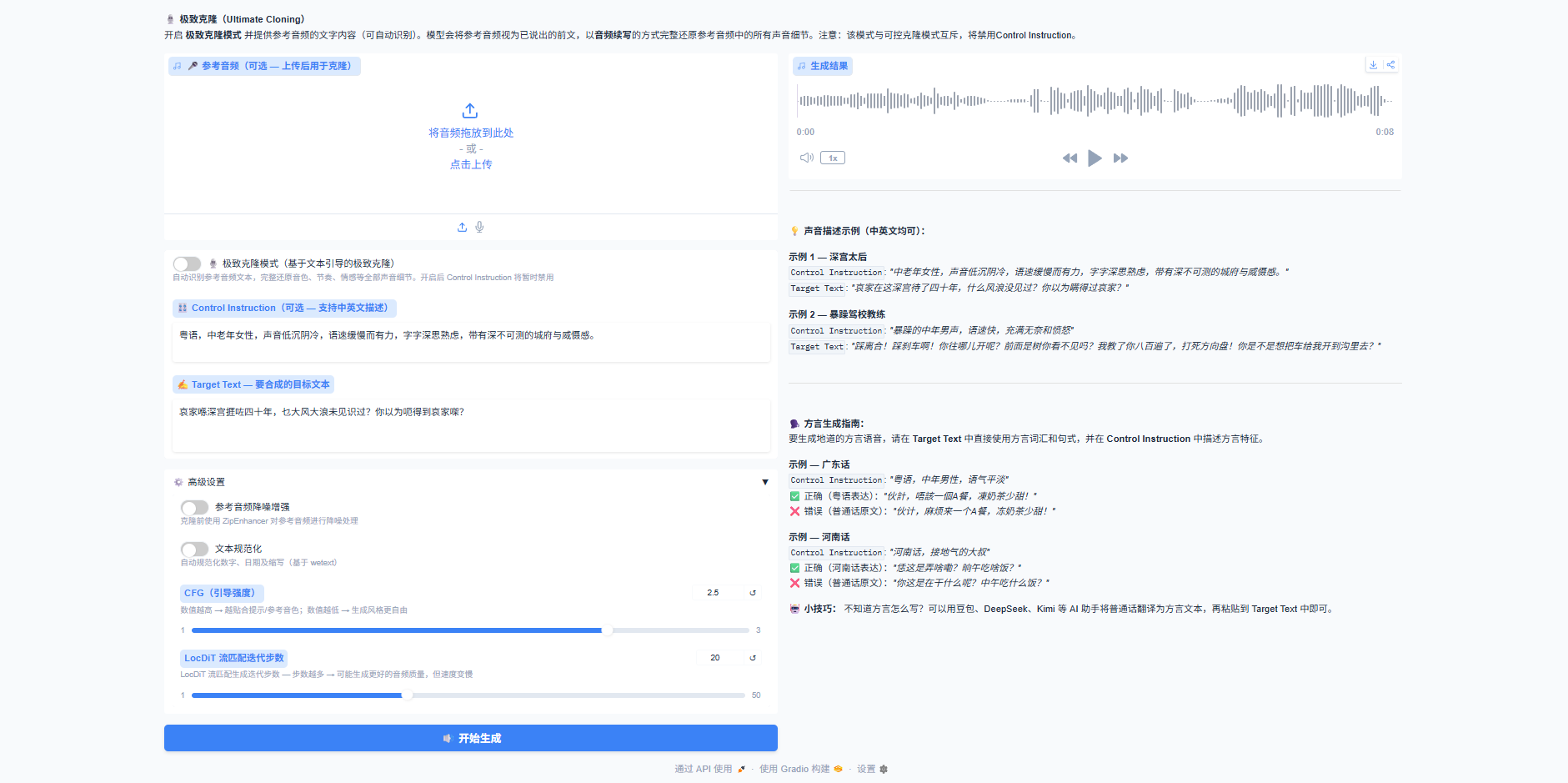
A800 3g.40gb mig,8秒生成速度 <7s (增加了10迭代步数
