容器化带来了部署的便利性,但也增加了监控的复杂度:每个容器都是一个动态的、短暂的目标。如何实时查看容器的资源使用情况?如何持久化存储监控数据并可视化?当容器性能不佳时如何定位瓶颈?本文将介绍 Docker 内置的 docker stats、cAdvisor + Prometheus + Grafana 监控栈,以及常见的性能优化策略。
一、实时监控:docker stats
docker stats 命令可以实时显示运行中容器的资源使用情况:
bash
docker stats输出字段:
CONTAINER ID / NAME
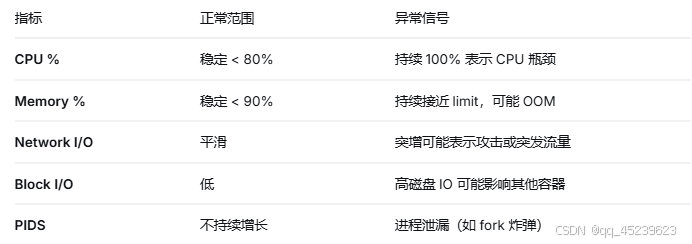
CPU %:CPU 使用百分比(相对于宿主机总 CPU)
MEM USAGE / LIMIT:内存使用量 / 限制(若未限制,显示宿主机总内存)
MEM %:内存使用百分比
NET I/O:网络收发数据量
BLOCK I/O:磁盘读写数据量
PIDS:进程数(需设置 --pids-limit 才能显示限制)
常用选项:
bash
docker stats --no-stream # 只输出一次
docker stats --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}"二、持久化监控:cAdvisor + Prometheus + Grafana
对于生产环境,需要历史数据和可视化图表。开源方案通常是 cAdvisor 收集容器指标,Prometheus 存储和查询,Grafana 展示。
2.1 cAdvisor(Container Advisor)
cAdvisor 是 Google 开源的容器资源监控工具,自动发现本机所有容器,暴露 Prometheus 格式的指标。
运行 cAdvisor:
bash
docker run -d \
--name=cadvisor \
--restart=always \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
gcr.io/cadvisor/cadvisor:latest访问 http://localhost:8080 可查看简洁的 UI,但通常只作为指标收集器。
2.2 Prometheus 配置
创建 prometheus.yml:
yaml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']启动 Prometheus 容器:
bash
docker run -d --name prometheus \
-p 9090:9090 \
-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus2.3 Grafana 仪表盘
bash
docker run -d --name grafana -p 3000:3000 grafana/grafana访问 http://localhost:3000,添加 Prometheus 数据源(URL http://prometheus:9090),然后导入 Docker 监控仪表盘(例如 ID 193 或 893),即可看到每个容器的 CPU、内存、网络、磁盘图表。
三、关键性能指标解读
四、性能优化策略
4.1 合理设置资源限制
bash
docker run -d --name app --cpus=1 --memory=512m --memory-reservation=256m myapp--cpus:限制 CPU 核心数(可为小数)。
--memory:硬限制,超过会触发 OOM Kill。
--memory-reservation:软限制,当宿主机内存紧张时优先回收。
4.2 CPU 优化
对于多核应用,分配 --cpus=2 或使用 --cpuset-cpus=0-1 绑定特定核心,提升缓存命中率。
避免使用 --cpu-shares 来控制权重(相对值),不如直接限制更明确。
4.3 内存优化
应用内减少对象分配,降低 GC 频率。
使用 --oom-score-adj 调整 OOM 优先级。
考虑使用 --memory-swap 控制 swap 使用(设为 -1 禁用 swap 可提升性能但降低稳定性)。
4.4 磁盘 I/O 优化
使用 --device-read-bps、--device-write-bps 限制磁盘带宽。
对于写密集的容器,挂载 tmpfs 到临时目录(如 /tmp),减少真实磁盘压力。
使用 --blkio-weight 设置 I/O 权重。
bash
docker run -d --name mysql \
--device-read-bps /dev/sda:10mb \
--tmpfs /var/lib/mysql/tmp:rw,noexec,nosuid,size=256m \
mysql4.5 网络优化
使用 host 网络模式可以提升性能(但牺牲隔离)。
调整网络驱动:--network host 或自定义 bridge 并开启 mtu 设置。
避免频繁创建和销毁网络命名空间(例如短生命周期容器)。
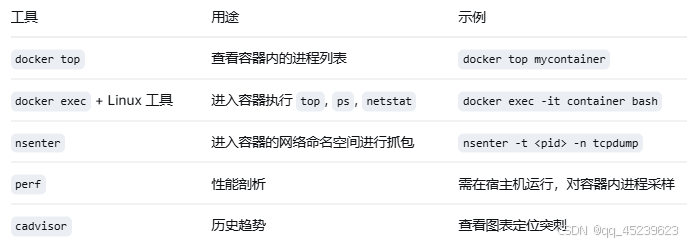
五、性能排查实用工具
六、实践:定位 CPU 飙升问题
发现 docker stats 显示某容器 CPU 持续 100%。
进入容器:docker exec -it highcpu bash。
运行 top 查看进程 PID。
宿主机上使用 perf top -p 分析热点函数。
若为 Java 应用,使用 jstack 或 async-profiler;若为 Node.js,使用 --prof 标志。
七、最佳实践总结
监控优先:部署 cAdvisor + Prometheus + Grafana,设置告警(如 CPU > 80% 持续 5 分钟)。
资源限制必须做:防止单容器拖垮整个宿主机。
日志分离:结合日志管理,避免日志 I/O 影响性能。
镜像优化:小的镜像不仅节省空间,也减少启动时间。
定期巡检:使用 docker system df 查看空间使用,清理无用资源。
八、小结
Docker 监控和性能优化是一个持续的过程。从 docker stats 实时查看,到搭建完整的监控栈,再到针对具体瓶颈调优,每一步都能提升系统的稳定性和效率。记住:没有监控的容器部署就像闭眼开车。