多租户不是一个功能,是一次手术。
给一个已经在生产环境跑着的系统加多租户支持,不能停机重写,不能推倒重来。只能在系统运行的同时,一层一层把数据结构、权限模型、鉴权链路全部换掉------就像给一辆高速行驶的车换发动机。
这两天做的,就是这件事的前三个阶段。
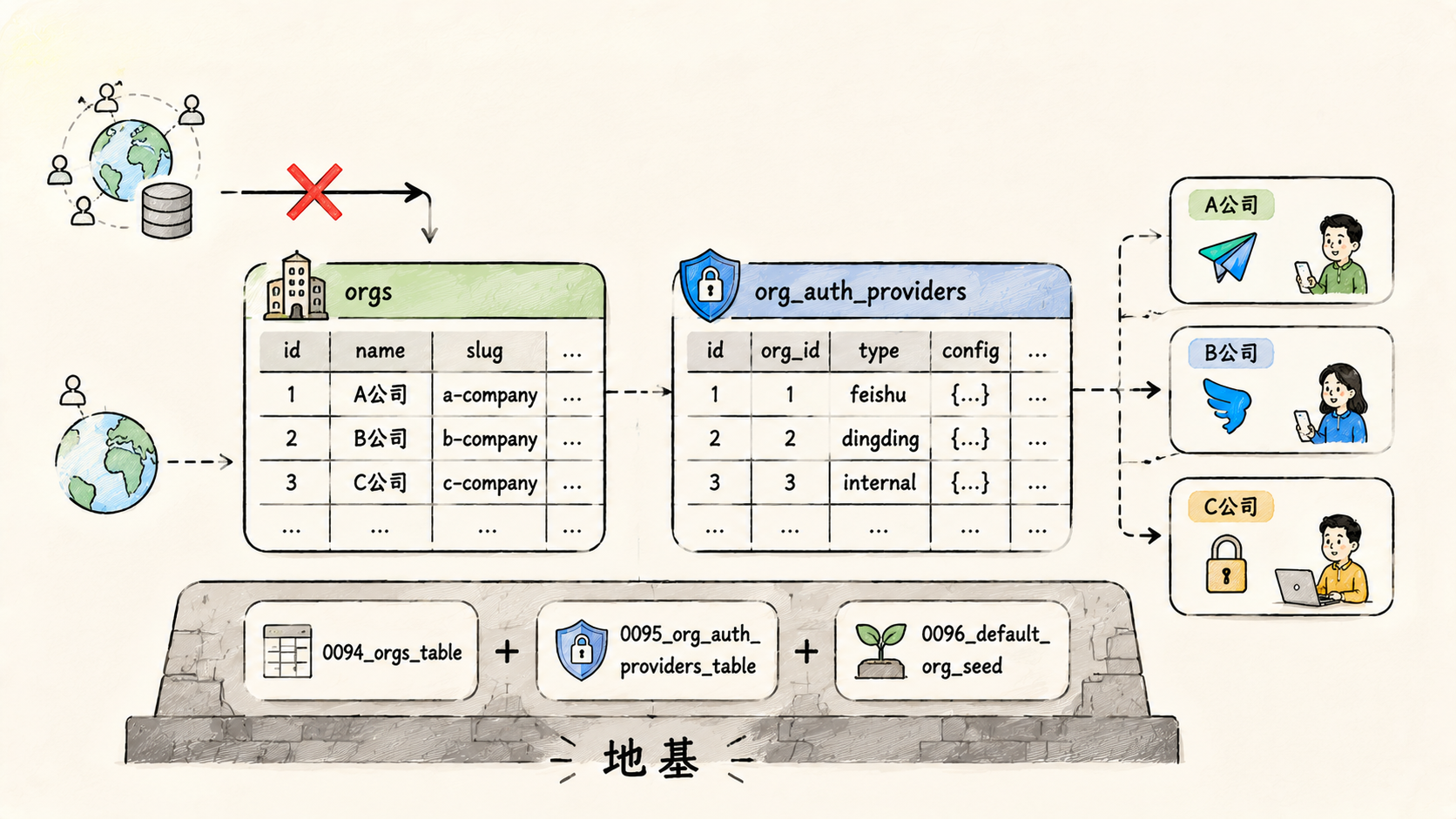
一、先建地基:组织表和认证源
多租户的起点是一张"组织表"。
在这张表存在之前,系统里所有的用户、权限、数据都是"全局"的概念------没有"谁的数据"这个维度,只有"数据存在不存在"。加了组织表之后,系统才有了最基本的租户概念:每一条数据,都可以开始追问"这属于哪个组织"。
配套的是"组织认证源表"。不同租户可能用不同的身份认证方式------A 公司用飞书登录,B 公司用钉钉登录,C 公司用内部账号。这张表让每个组织可以绑定自己的认证源,而不是全系统共用一套登录入口。
这两张表加上初始的默认组织数据,是整个多租户改造的地基。没有它们,后续所有改造都无处落脚。
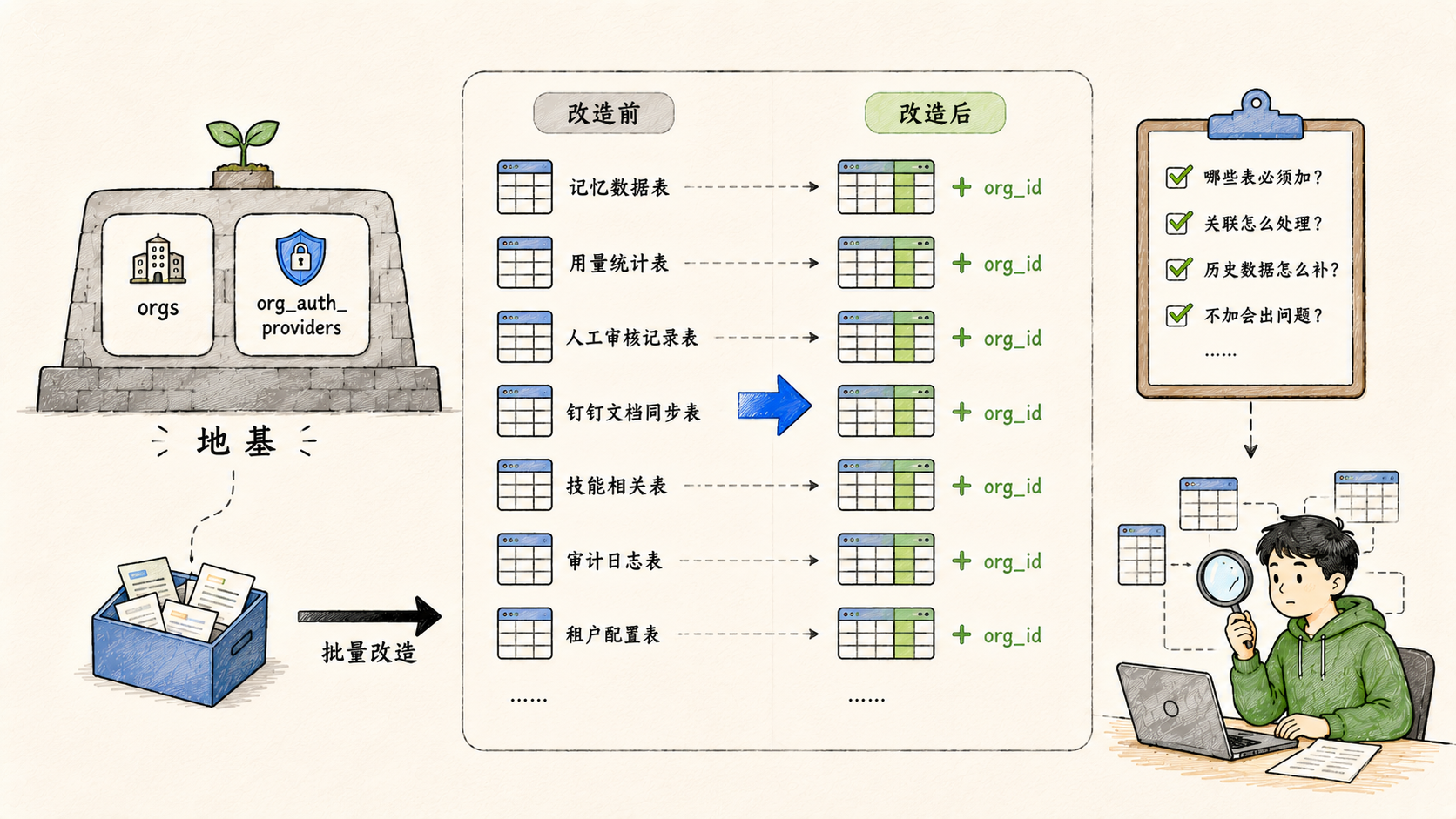
二、二十多张表批量加组织字段:最重的一次结构改造
地基打完,下一步是让业务数据真正感知到"组织"这个维度。
这次一口气给二十多张业务表批量增加了"所属组织"字段。涉及的范围包括:记忆数据、用量统计、人工审核记录、钉钉文档同步信息、技能相关表、审计日志、租户配置......几乎覆盖了系统里所有有业务含义的核心表。
这是这波改造里最重的一次提交,也是最关键的一步。
加字段本身不复杂,难的是判断哪些表必须加、加完之后表之间的关联怎么处理、历史数据怎么补、不加会不会在后续某个地方出问题。二十多张表意味着做了一次完整的数据模型审计------确认了系统里每一份有状态的数据,都需要带上组织维度。
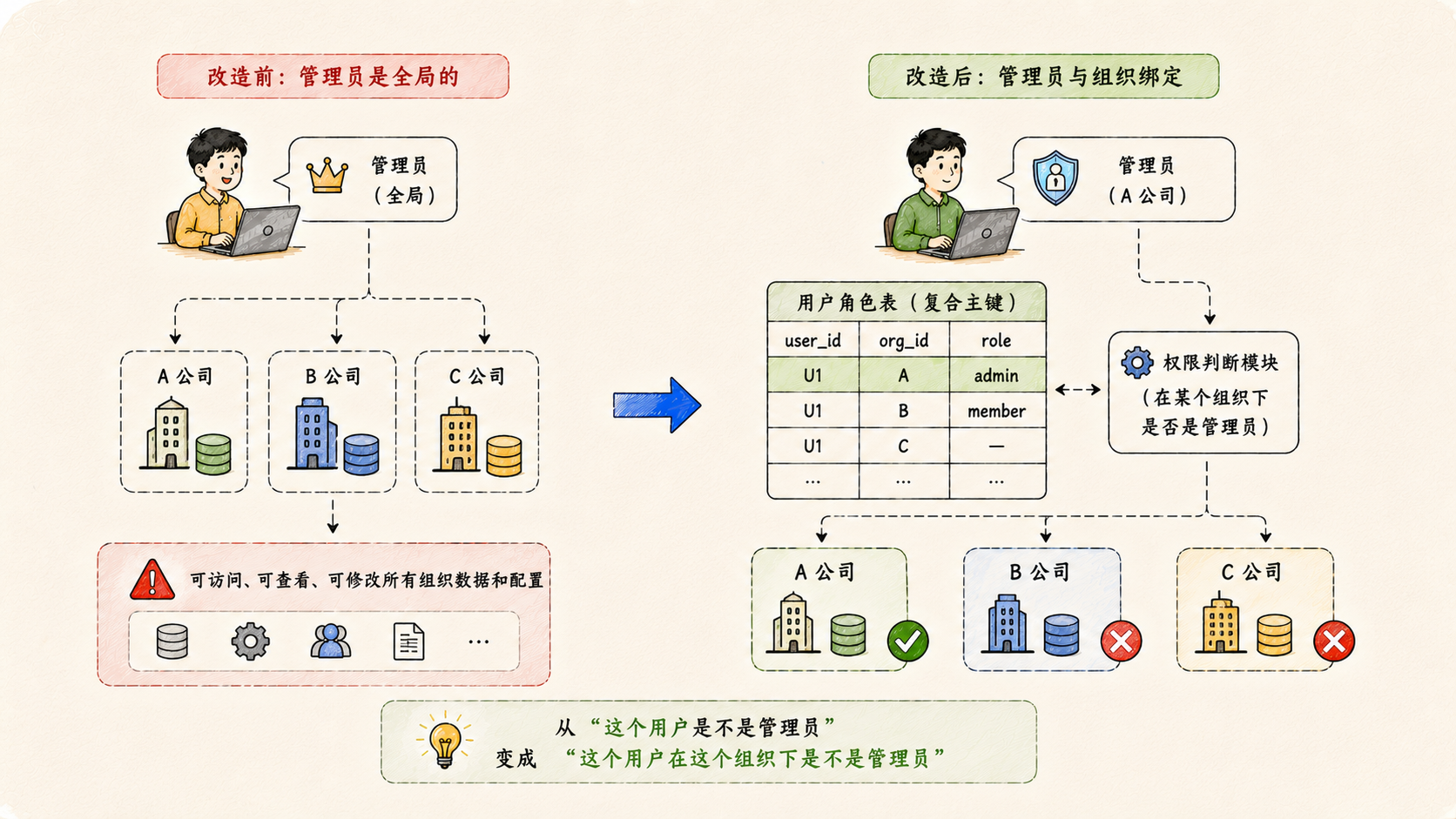
三、管理员权限去全局化
原来的系统里,"管理员"是一个全局概念:你是管理员,你就能管所有东西。
多租户场景下,这个假设不成立了。A 公司的管理员不应该能看到 B 公司的数据,更不应该能修改 B 公司的配置。管理员身份必须和组织绑定。
这次改造把用户角色表的主键结构改成了带组织字段的复合结构,同时新增了专门的处理模块,负责"在某个组织下判断是否是管理员"的逻辑。
这是一个看起来很小、实际影响面很大的改动。所有涉及权限判断的地方,都需要从"这个用户是不是管理员"变成"这个用户在这个组织下是不是管理员"。 一字之差,是完全不同的权限模型。
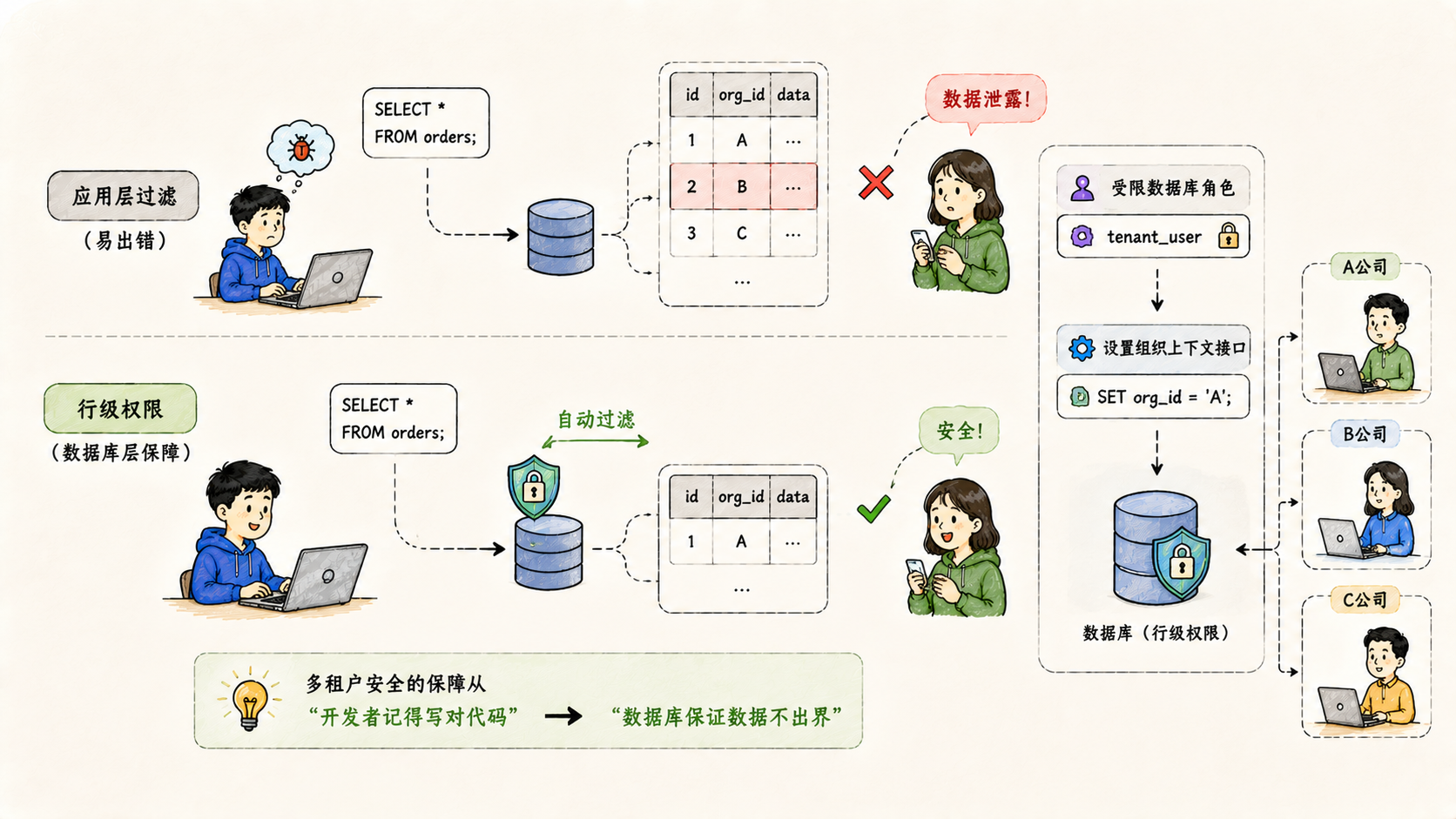
四、行级权限:数据隔离从应用层下沉到数据库层
前三步是在应用层加字段、改逻辑。但应用层的隔离有一个根本性的弱点:只要有一处代码忘记加组织过滤条件,数据就会跨租户泄露。 随着系统越来越复杂,靠人工保证每一个查询都带上过滤条件,是不可持续的。
行级权限的思路是把这一层下沉到数据库本身------数据库在执行每一条查询之前,自动检查当前会话的组织上下文,只返回属于这个组织的数据。哪怕应用层的查询忘了加过滤条件,数据库也不会把其他组织的数据返回出来。
这次改造引入了受限数据库角色 和设置组织上下文的接口,是行级权限基础设施的第一步:让数据库知道"当前请求属于哪个组织"。后续每一条查询就可以基于这个上下文做自动过滤。
这个方向的意义在于:多租户安全的保障从"开发者记得写对代码"变成了"数据库保证数据不出界"。 两者的可靠性不在同一个量级。
写到这里,可以大致看清这次改造的架构层次:
-
第一层:概念层 ------ 组织表存在,系统有了租户的概念
-
第二层:数据层 ------ 二十多张表带上组织字段,数据有了归属
-
第三层:权限层 ------ 管理员身份绑定组织,权限有了边界
-
第四层:隔离层 ------ 行级权限在数据库执行,隔离有了保障
每一层都是下一层的前提。跳过任何一层直接往下做,都会在某个地方留下漏洞。
这次没有跳。
这,是第四十一天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。