目录
一、背景
实现目标:adf变量及参数传送到databricks使用
二、实操
1.传变量
(1).adf里新建管道,新建【设置变量】
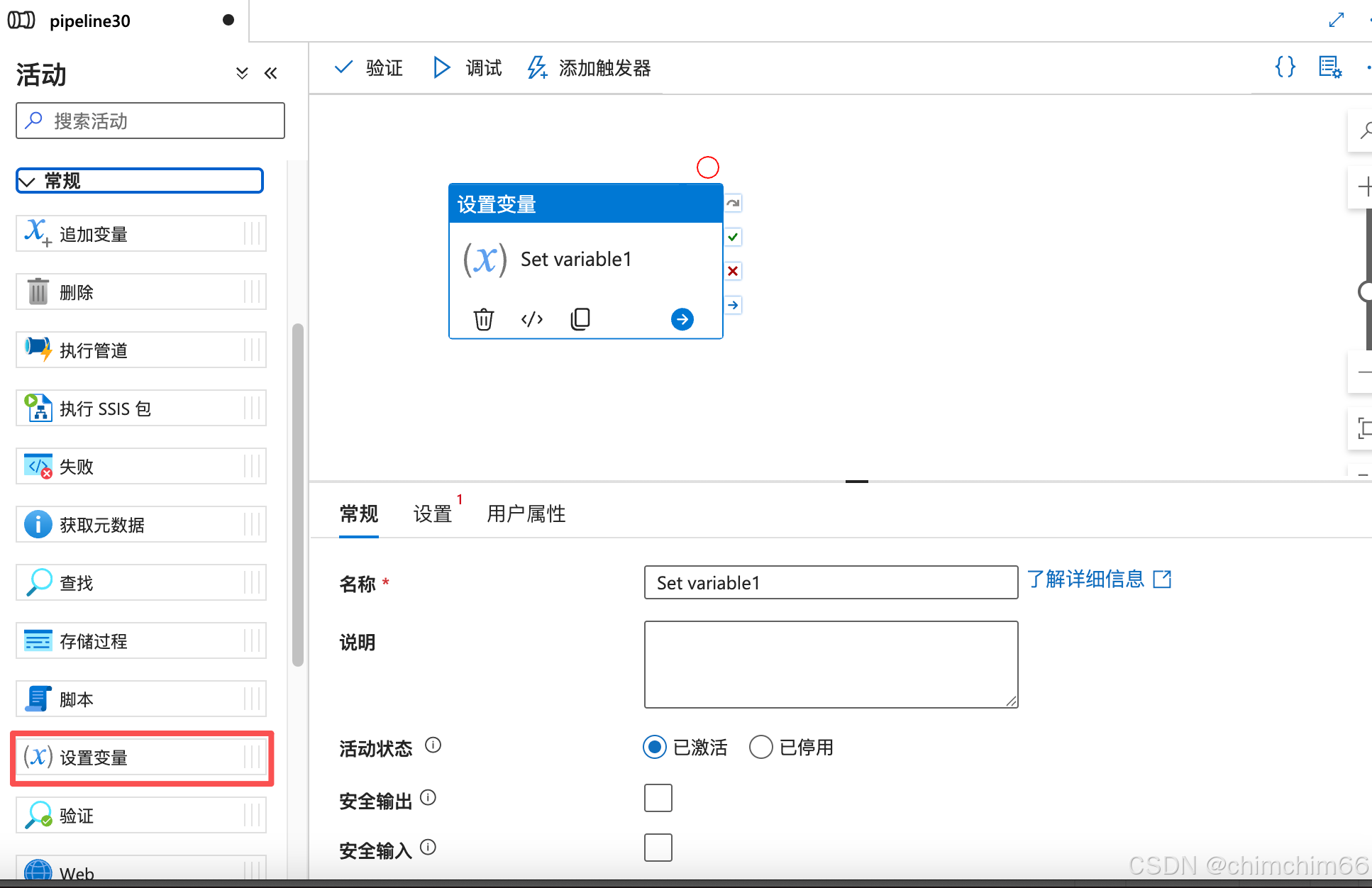
示例:
设置管道变量
biz_date:@{addDays(convertFromUtc(utcNow(), 'China Standard Time'),-1,'yyyyMMdd')}
biz_date_new:@{addDays(convertFromUtc(utcNow(), 'China Standard Time'),-1,'yyyy-MM-dd')}
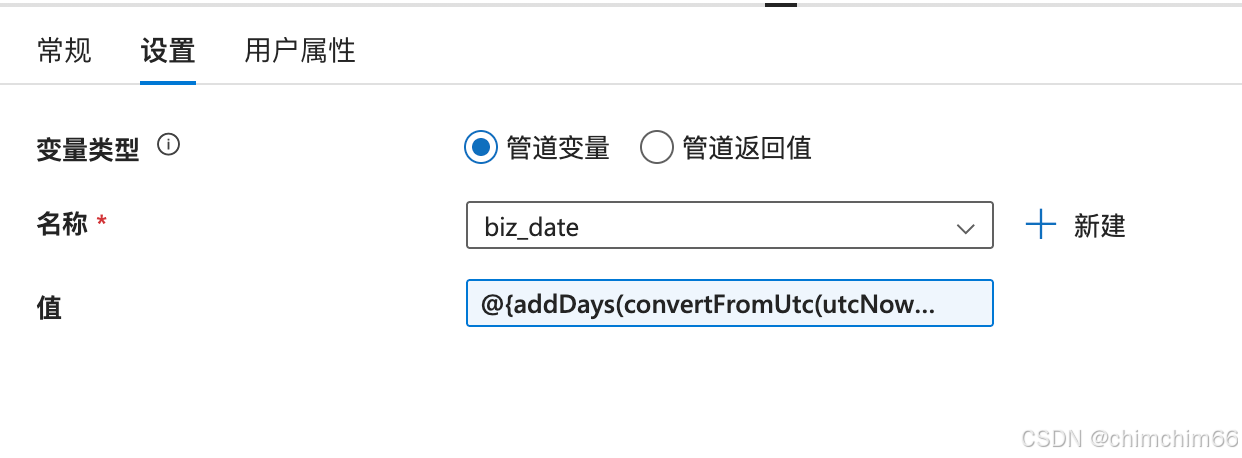
(2).插入【笔记本】
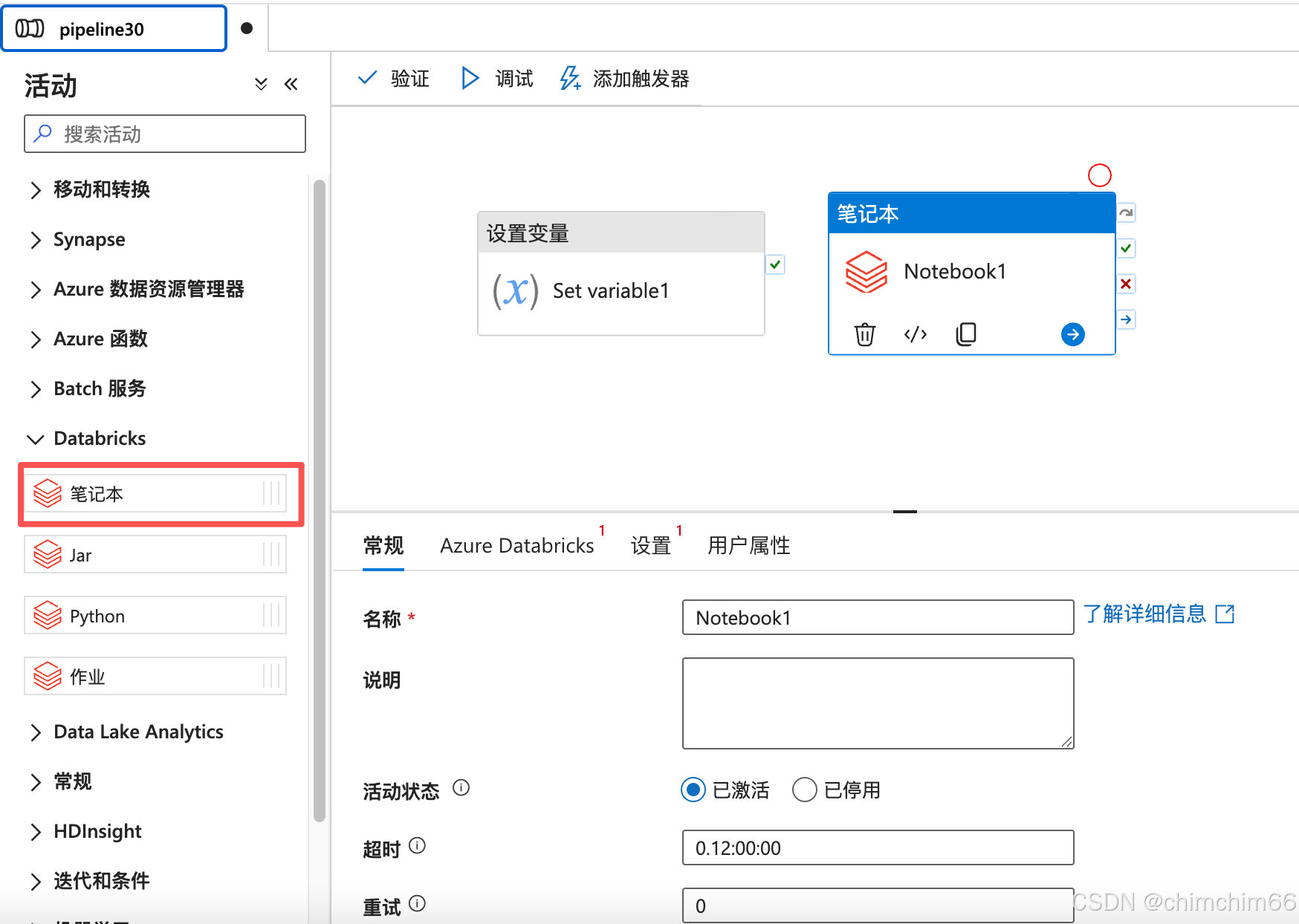
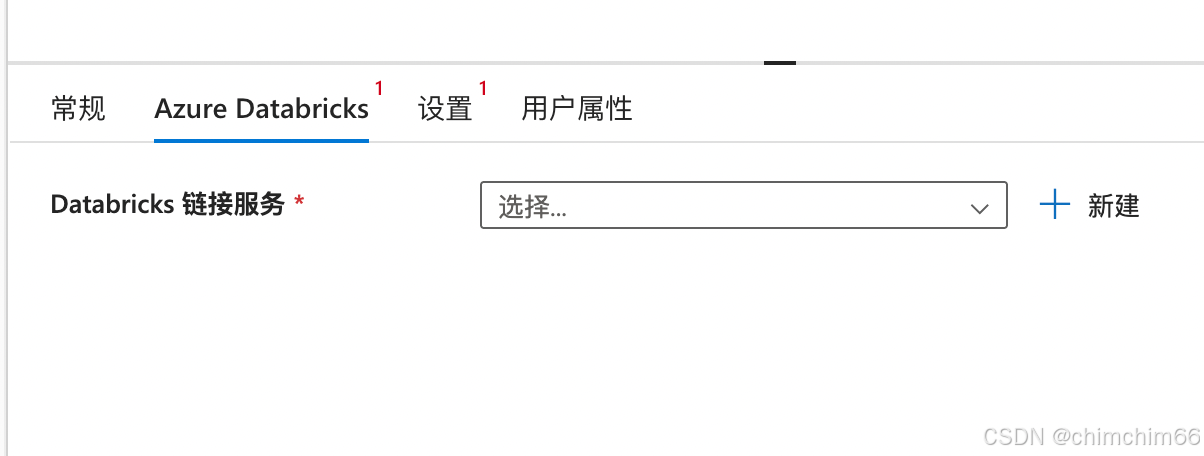
配置服务
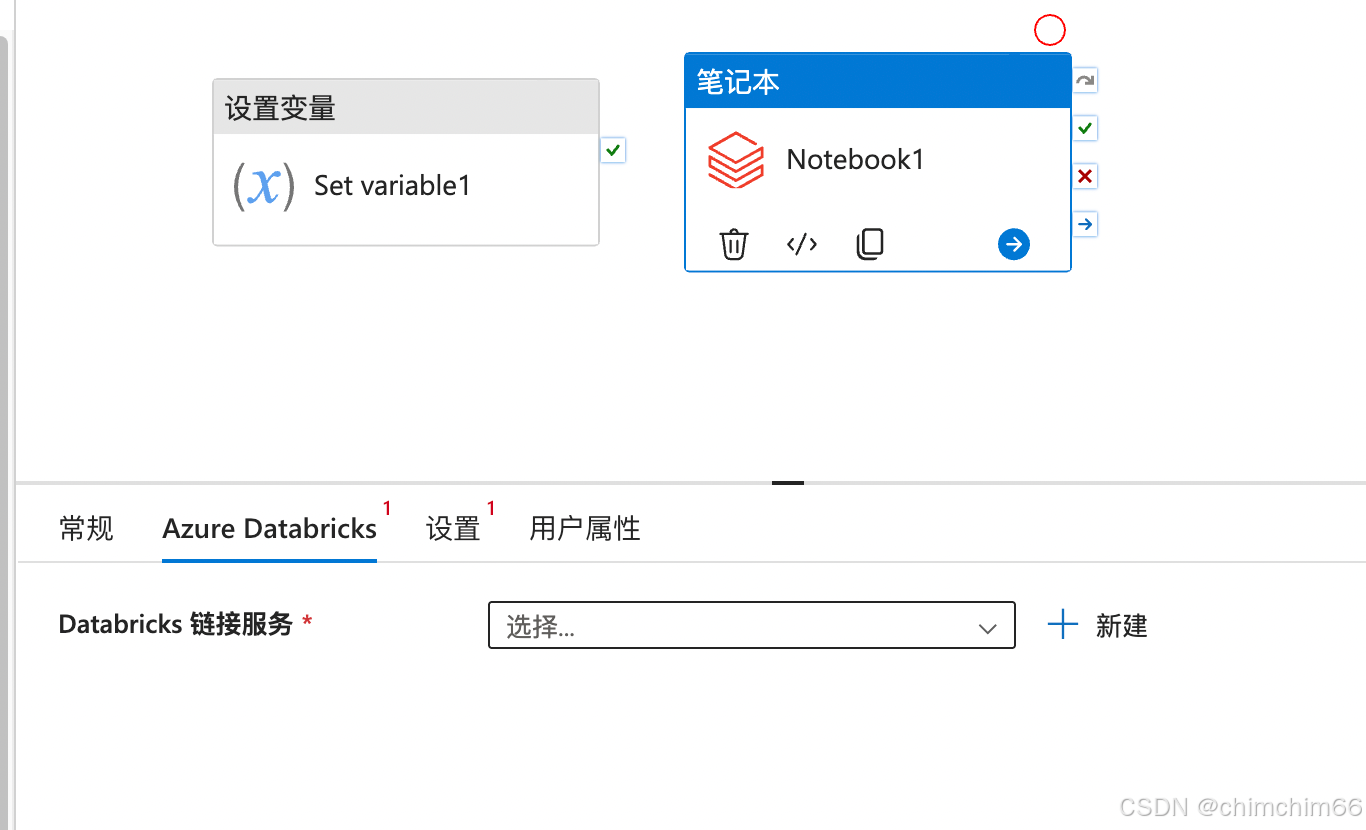
设置中添加笔记本路径
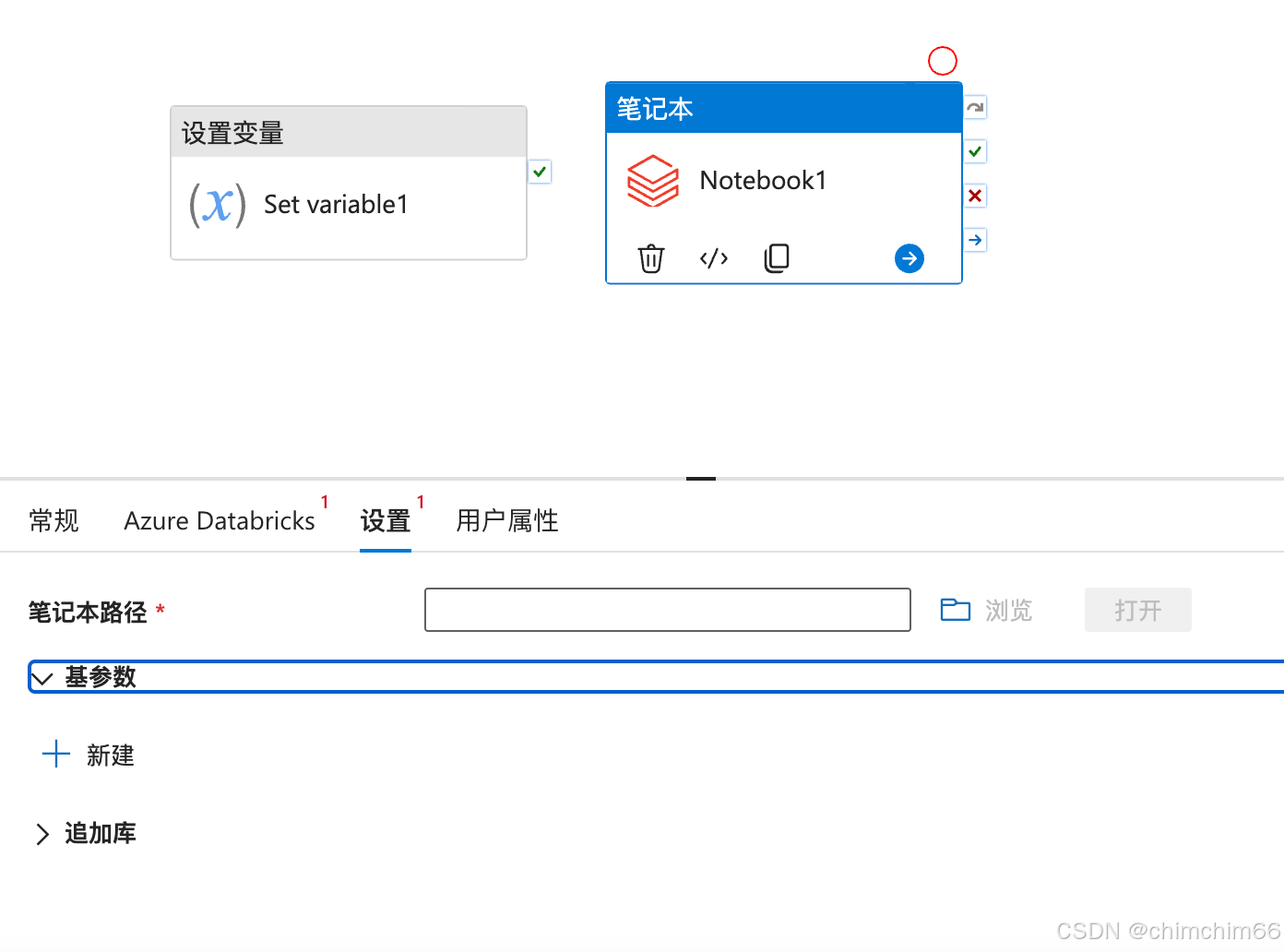
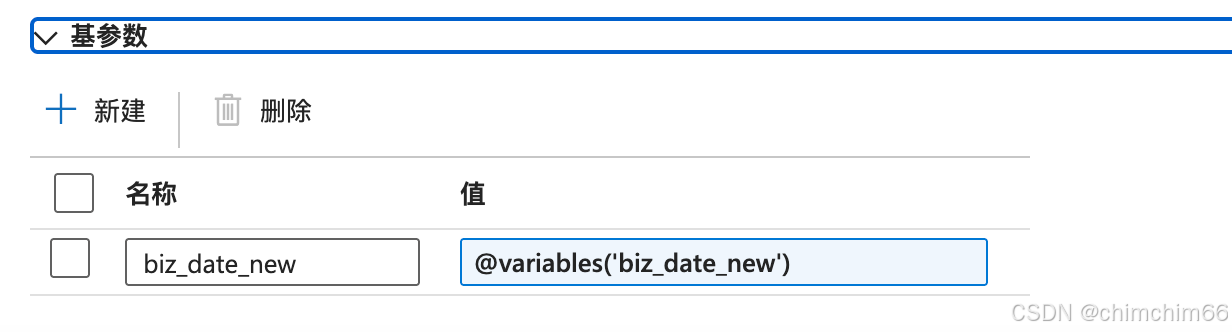
配置基参数
biz_date:@variables('biz_date)
biz_date_new::@variables('biz_date_new')
databricks【笔记本】-【sql】组件中直接使用变量即可
sql
select '${biz_date}';
select '${biz_date_new}'2.传参数
新建参数
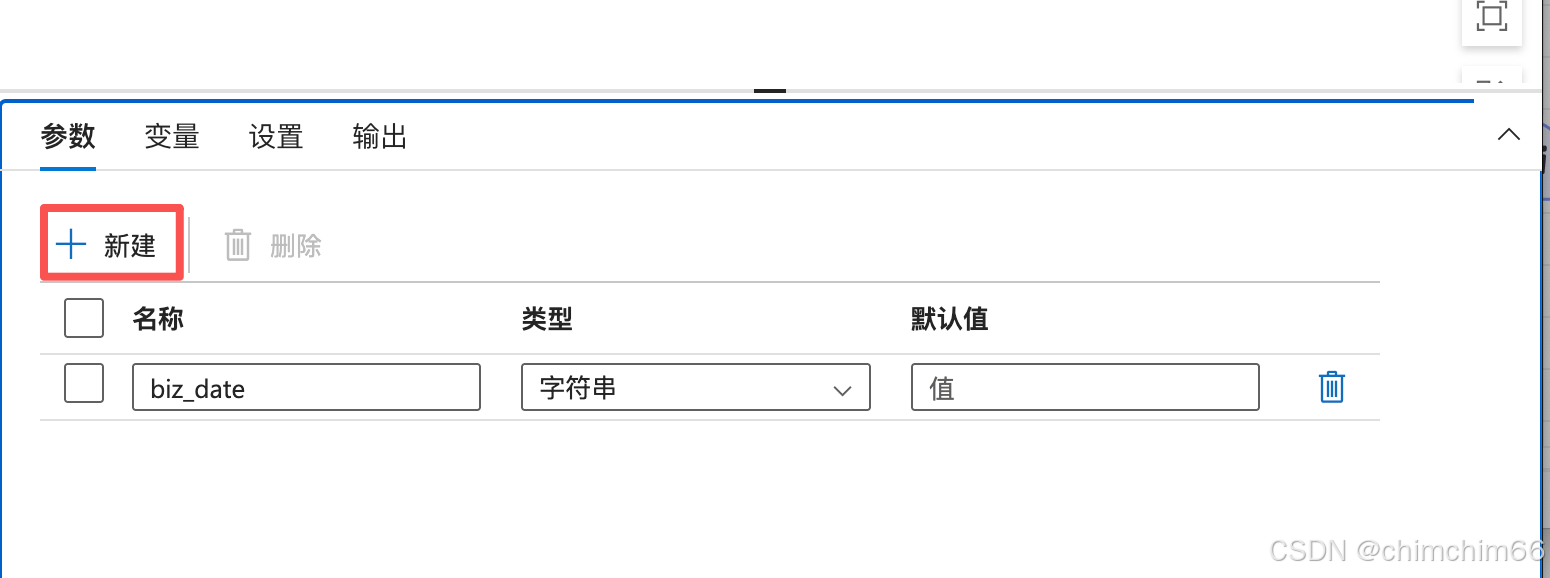
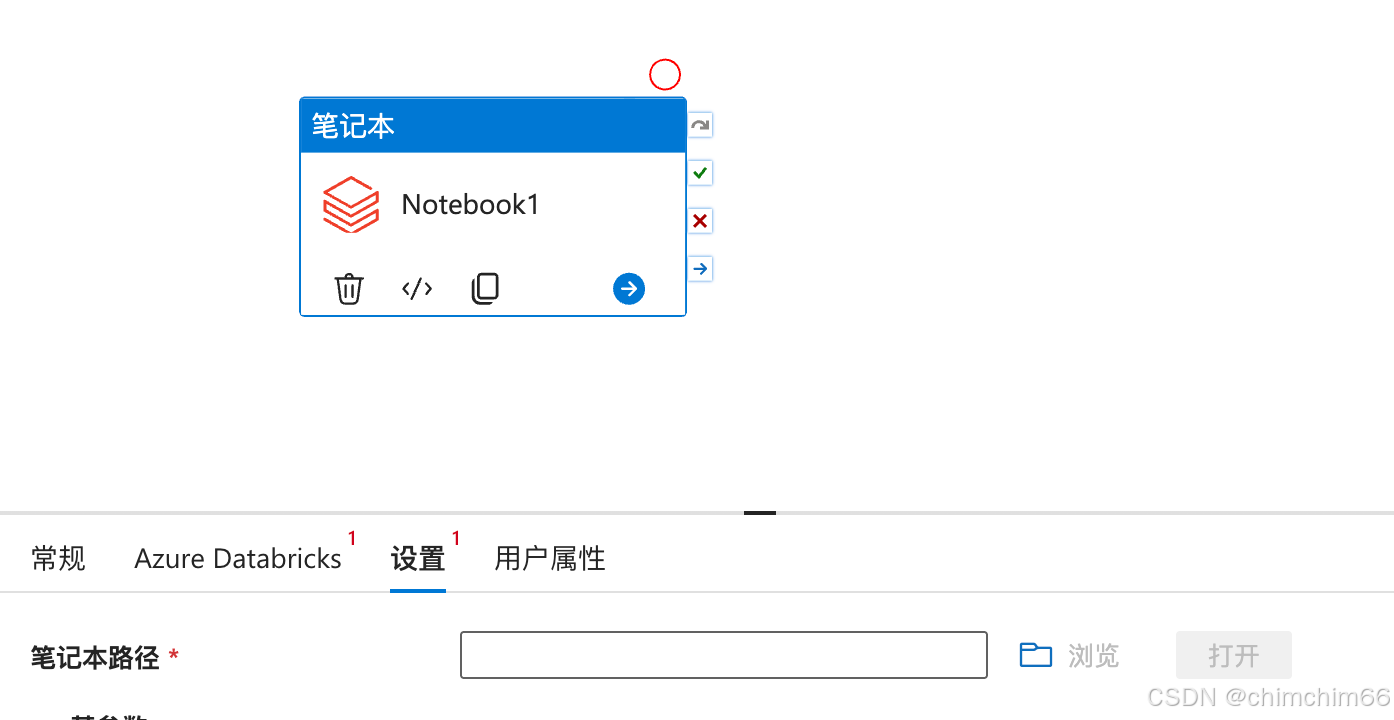
新建notebook
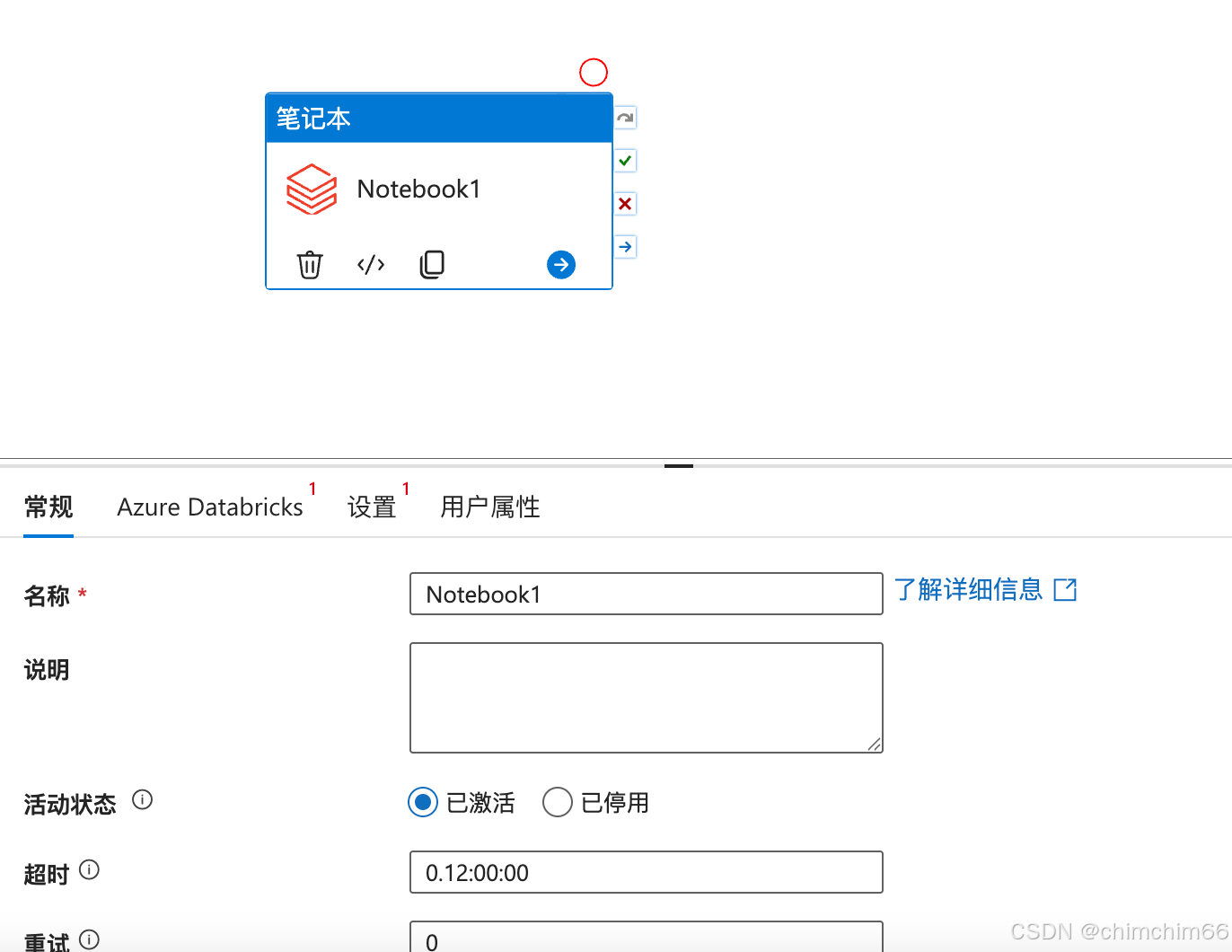
配置服务
设置笔记本路径
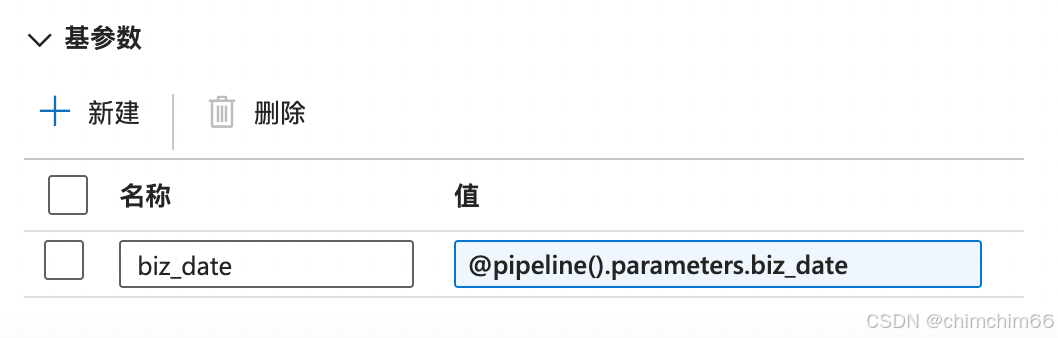
设置基参数
biz_date:@pipeline().parameters.biz_date
databricks【笔记本】-【python】组件使用参数
python
# 1. 接收来自 ADF 的变量
biz_date = dbutils.widgets.get("biz_date")
# 2.
sql_query = f"""
SELECT count(*) as total_count
FROM table_name
WHERE biz_date = '{biz_date}'
"""
# 3. 执行 SQL 并获取结果
# .collect()[0][0] 表示取第一行第一列的值
result_df = spark.sql(sql_query)
count_value = result_df.collect()[0][0]
# 4. 返回给 ADF
dbutils.notebook.exit(str(count_value))