摘要
OpenCV 的 parallel_for_ 是其所有并行计算的统一入口,支持 7 种并行后端(TBB / HPX / OpenMP / GCD / WinRT / MS-Concurrency / pthreads),运行时可通过环境变量切换优先级或替换为自定义后端。本文从 OpenCV 4.8.0 源码(parallel.cpp + parallel_impl.cpp)逐层拆解:后端选择优先级链、parallel_for_ 的嵌套检测与 nstripes 分配策略、pthreads 线程池的自旋等待-条件变量混合唤醒机制、ParallelJob 的原子工作窃取调度、以及 x86/ARM64/RISC-V 三种架构的 CPU Yield 指令差异。
一、为什么需要统一并行框架?
OpenCV 面临一个经典的跨平台并行困境:不同操作系统和编译器支持不同的并行 API(Linux 有 pthreads/OpenMP,macOS 有 GCD,Windows 有 PPL/Concurrency),而用户应用本身可能也有自己的线程池(TBB/自定义)。如果 OpenCV 内部用一套线程池,用户应用用另一套,就会出现 CPU 资源过度订阅(over-subscription)-- 线程数远超核心数,上下文切换开销反而拖慢性能。
OpenCV 的解决方案:
- 编译时:按优先级选择一个并行后端
- 运行时:允许用户通过 API 或环境变量替换后端
- 统一入口 :所有并行操作通过
parallel_for_一个函数分发
二、后端选择:7 级优先级链
parallel.cpp:90-149 定义了编译时后端选择的优先级:
| 优先级 | 宏定义 | 后端 | 平台 | 来源 |
|---|---|---|---|---|
| 1 (最高) | HAVE_TBB |
Intel TBB | 跨平台 | 需显式启用 |
| 2 | HAVE_HPX |
HPX | 跨平台 | 需显式启用 |
| 3 | HAVE_OPENMP |
OpenMP | 跨平台 | 编译器内置 |
| 4 | HAVE_GCD |
Grand Central Dispatch | macOS | 系统自带 |
| 5 | WINRT |
WinRT Concurrency | Windows RT | 系统自带 |
| 6 | HAVE_CONCURRENCY |
MS PPL | Windows (MSVC 10+) | 运行时自带 |
| 7 (最低) | HAVE_PTHREADS_PF |
pthreads 线程池 | Unix/Linux | OpenCV 自实现 |
cpp
// parallel.cpp:136-149 -- 编译时框架标识
#if defined HAVE_TBB
# define CV_PARALLEL_FRAMEWORK "tbb"
#elif defined HAVE_HPX
# define CV_PARALLEL_FRAMEWORK "hpx"
#elif defined HAVE_OPENMP
# define CV_PARALLEL_FRAMEWORK "openmp"
#elif defined HAVE_GCD
# define CV_PARALLEL_FRAMEWORK "gcd"
// ...
#elif defined HAVE_PTHREADS_PF
# define CV_PARALLEL_FRAMEWORK "pthreads"
#endif运行时替换 (parallel_backend.hpp):
cpp
// 通过 API 替换后端
cv::parallel::setParallelForBackend(myCustomBackend);
// 通过环境变量调整优先级
// OPENCV_PARALLEL_PRIORITY_TBB=9999 // 提升 TBB 优先级
// OPENCV_PARALLEL_PRIORITY_OPENMP=0 // 禁用 OpenMP
// OPENCV_PARALLEL_PRIORITY_LIST=TBB,OPENMP // 指定高优先级列表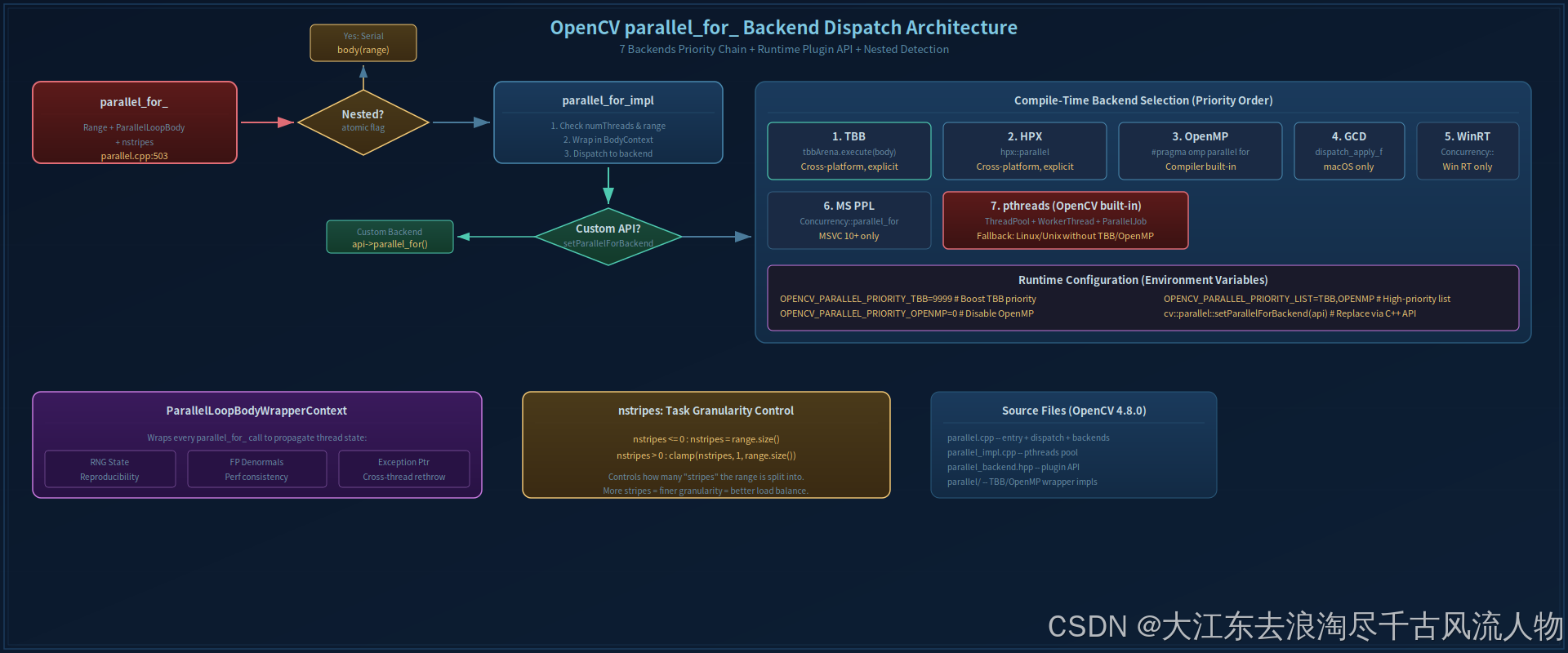
图 1:OpenCV parallel_for_ 后端调度架构 -- 从 parallel_for_ 入口到 7 种后端的分发路径,含运行时替换和嵌套检测。重绘自 design skill
三、parallel_for_ 核心流程
3.1 入口函数:嵌套检测
parallel.cpp:503-538
cpp
void parallel_for_(const Range& range, const ParallelLoopBody& body, double nstripes)
{
if (range.empty()) return;
static std::atomic<bool> flagNestedParallelFor(false);
bool isNotNestedRegion = !flagNestedParallelFor.exchange(true);
if (isNotNestedRegion) {
parallel_for_impl(range, body, nstripes);
flagNestedParallelFor = false;
} else {
body(range); // 嵌套调用退化为串行
}
}关键设计:嵌套的 parallel_for_ 自动退化为串行执行。用原子标志检测,避免线程池内再创建线程池导致的死锁或过度订阅。
3.2 分发函数:nstripes 与后端选择
parallel.cpp:548-627
nstripes 控制任务切分粒度:
nstripes = { range.size() , if nstripes ≤ 0 min ( max ( nstripes , 1 ) , range.size() ) , otherwise \text{nstripes} = \begin{cases} \text{range.size()}, & \text{if nstripes} \le 0 \\ \min(\max(\text{nstripes}, 1), \text{range.size()}), & \text{otherwise} \end{cases} nstripes={range.size(),min(max(nstripes,1),range.size()),if nstripes≤0otherwise
分发逻辑:
- 检查
numThreads-- 为 0 或 1 时串行执行 - 检查 range 大小 -- 为 1 时串行执行
- 检查是否有自定义 API 后端 -- 优先使用
- 按编译时选定的框架分发(TBB arena / OpenMP pragma / GCD dispatch / pthreads pool)
cpp
// OpenMP 分发路径
#pragma omp parallel for schedule(dynamic) \
num_threads(numThreads > 0 ? numThreads : numThreadsMax)
for (int i = stripeRange.start; i < stripeRange.end; ++i)
pbody(Range(i, i + 1));
// TBB 分发路径
tbbArena.execute(pbody);
// GCD (macOS) 分发路径
dispatch_apply_f(count, concurrent_queue, &pbody, block_function);
// pthreads 分发路径
parallel_for_pthreads(stripeRange, pbody, stripeRange.size());3.3 ParallelLoopBodyWrapperContext:线程状态传播
每次 parallel_for_ 调用都创建一个 WrapperContext,负责三件事:
| 传播项 | 为什么需要 | 实现 |
|---|---|---|
| RNG 状态 | 保证可复现性 | 主线程 RNG 拷贝到每个 worker |
| FP Denormals | 避免性能陷阱 | 传播 denormals-are-zero 标志 |
| 异常 | 跨线程异常传递 | std::exception_ptr + mutex |
四、pthreads 线程池:自旋等待 + 条件变量
当没有 TBB/OpenMP 等外部框架时,OpenCV 使用自己的 pthreads 线程池(parallel_impl.cpp)。
4.1 ThreadPool 单例
cpp
// parallel_impl.cpp:85-109
class ThreadPool {
static ThreadPool& instance(); // 懒汉单例
void run(const Range& range, const ParallelLoopBody& body, double nstripes);
void reconfigure(unsigned new_threads_count);
unsigned num_threads;
std::vector<Ptr<WorkerThread>> threads;
Ptr<ParallelJob> job;
};4.2 WorkerThread:混合等待策略
Worker 线程的等待策略是 自旋等待 + 条件变量 的两阶段混合:
- 自旋阶段 :循环检查
has_wake_signal,每次循环执行CV_PAUSE()让出 CPU 流水线 - 睡眠阶段 :自旋次数超过阈值后,
pthread_cond_wait挂起线程
cpp
// 环境变量控制自旋参数
OPENCV_THREAD_POOL_ACTIVE_WAIT_PAUSE_LIMIT = 16; // CV_PAUSE 循环次数
OPENCV_THREAD_POOL_ACTIVE_WAIT_WORKER = 2000; // Worker 自旋总次数
OPENCV_THREAD_POOL_ACTIVE_WAIT_MAIN = 10000; // 主线程自旋总次数为什么主线程自旋次数(10000)远大于 Worker(2000)? 主线程提交任务后需要等待完成,更长的自旋可以避免 pthread_cond_wait 的系统调用开销,减少 wake-up 延迟。
4.3 跨架构 CPU Yield 指令
parallel_impl.cpp:30-72 -- 不同 CPU 架构的 CV_PAUSE 实现:
| 架构 | 指令 | 说明 |
|---|---|---|
| x86/x86_64 | _mm_pause() |
Skylake+ 约 140 cycles,暗示 CPU 当前在自旋 |
| ARM64 (AArch64) | yield |
提示处理器让出超线程资源 |
| ARM32 | 空内存屏障 | asm volatile("" ::: "memory") |
| MIPS (r2+) | pause |
类似 x86 的 pause |
| PPC64 | or 27,27,27 |
IBM Power 的 yield hint |
| RISC-V | nop |
PAUSE 指令尚未进入 ISA 规范 |
| LoongArch | nop |
同 RISC-V |
cpp
// x86: Skylake 后 _mm_pause 约 140 cycles,无需循环
#define CV_PAUSE(v) do { (void)v; _mm_pause(); } while (0)
// ARM64: yield 指令 + 循环
#define CV_PAUSE(v) do { \
for (int __delay = (v); __delay > 0; --__delay) { \
asm volatile("yield" ::: "memory"); \
} \
} while (0)4.4 ParallelJob:原子工作窃取
parallel_impl.cpp:287-360
cpp
unsigned execute(bool is_worker_thread) {
const int remaining_multiplier = min(nstripes,
max(min(100u, num_threads * 4), num_threads * 2));
for (;;) {
int chunk_size = max(1, (task_count - current_task) / remaining_multiplier);
int id = current_task.fetch_add(chunk_size, memory_order_seq_cst);
if (id >= task_count) break;
body(Range(range.start + id, range.start + min(task_count, id + chunk_size)));
}
}核心设计:
- 动态 chunk 大小:剩余任务越少,chunk 越小,负载越均匀
- 原子 fetch_add:无锁分配,避免 mutex 竞争
- Cache-line 对齐 :
current_task、active_thread_count、completed_thread_count之间用int64 dummy_[8]隔开,避免 false sharing
#mermaid-svg-7efwuD9gk2e7K53e{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-7efwuD9gk2e7K53e .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-7efwuD9gk2e7K53e .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-7efwuD9gk2e7K53e .error-icon{fill:#552222;}#mermaid-svg-7efwuD9gk2e7K53e .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-7efwuD9gk2e7K53e .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-7efwuD9gk2e7K53e .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-7efwuD9gk2e7K53e .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-7efwuD9gk2e7K53e .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-7efwuD9gk2e7K53e .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-7efwuD9gk2e7K53e .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-7efwuD9gk2e7K53e .marker{fill:#333333;stroke:#333333;}#mermaid-svg-7efwuD9gk2e7K53e .marker.cross{stroke:#333333;}#mermaid-svg-7efwuD9gk2e7K53e svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-7efwuD9gk2e7K53e p{margin:0;}#mermaid-svg-7efwuD9gk2e7K53e .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-7efwuD9gk2e7K53e .cluster-label text{fill:#333;}#mermaid-svg-7efwuD9gk2e7K53e .cluster-label span{color:#333;}#mermaid-svg-7efwuD9gk2e7K53e .cluster-label span p{background-color:transparent;}#mermaid-svg-7efwuD9gk2e7K53e .label text,#mermaid-svg-7efwuD9gk2e7K53e span{fill:#333;color:#333;}#mermaid-svg-7efwuD9gk2e7K53e .node rect,#mermaid-svg-7efwuD9gk2e7K53e .node circle,#mermaid-svg-7efwuD9gk2e7K53e .node ellipse,#mermaid-svg-7efwuD9gk2e7K53e .node polygon,#mermaid-svg-7efwuD9gk2e7K53e .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-7efwuD9gk2e7K53e .rough-node .label text,#mermaid-svg-7efwuD9gk2e7K53e .node .label text,#mermaid-svg-7efwuD9gk2e7K53e .image-shape .label,#mermaid-svg-7efwuD9gk2e7K53e .icon-shape .label{text-anchor:middle;}#mermaid-svg-7efwuD9gk2e7K53e .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-7efwuD9gk2e7K53e .rough-node .label,#mermaid-svg-7efwuD9gk2e7K53e .node .label,#mermaid-svg-7efwuD9gk2e7K53e .image-shape .label,#mermaid-svg-7efwuD9gk2e7K53e .icon-shape .label{text-align:center;}#mermaid-svg-7efwuD9gk2e7K53e .node.clickable{cursor:pointer;}#mermaid-svg-7efwuD9gk2e7K53e .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-7efwuD9gk2e7K53e .arrowheadPath{fill:#333333;}#mermaid-svg-7efwuD9gk2e7K53e .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-7efwuD9gk2e7K53e .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-7efwuD9gk2e7K53e .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-7efwuD9gk2e7K53e .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-7efwuD9gk2e7K53e .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-7efwuD9gk2e7K53e .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-7efwuD9gk2e7K53e .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-7efwuD9gk2e7K53e .cluster text{fill:#333;}#mermaid-svg-7efwuD9gk2e7K53e .cluster span{color:#333;}#mermaid-svg-7efwuD9gk2e7K53e div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-7efwuD9gk2e7K53e .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-7efwuD9gk2e7K53e rect.text{fill:none;stroke-width:0;}#mermaid-svg-7efwuD9gk2e7K53e .icon-shape,#mermaid-svg-7efwuD9gk2e7K53e .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-7efwuD9gk2e7K53e .icon-shape p,#mermaid-svg-7efwuD9gk2e7K53e .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-7efwuD9gk2e7K53e .icon-shape .label rect,#mermaid-svg-7efwuD9gk2e7K53e .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-7efwuD9gk2e7K53e .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-7efwuD9gk2e7K53e .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-7efwuD9gk2e7K53e :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 嵌套检测
Yes
No
nstripes=1
自定义 API
TBB
OpenMP
GCD
pthreads
parallel_for_ 入口
首次调用?
parallel_for_impl
串行 body
api->parallel_for
tbbArena.execute
#pragma omp parallel for
dispatch_apply_f
ThreadPool::run
ParallelJob 原子分配
Worker 自旋 + CV_PAUSE
fetch_add 获取 chunk
执行 body Range
五、实际调参指南
5.1 选择后端
| 场景 | 推荐后端 | 原因 |
|---|---|---|
| 应用已用 TBB | TBB | 避免线程池冲突 |
| 纯 OpenCV 应用 | OpenMP 或 pthreads | 开箱即用 |
| macOS | GCD | 系统级调度,无需配置 |
| 嵌入式 Linux | pthreads | 依赖最少 |
5.2 环境变量调优
bash
# 查看当前后端
python3 -c "import cv2; print(cv2.getBuildInformation())" | grep "Parallel framework"
# 设置线程数(0 = 自动,等于 CPU 核心数)
export OPENCV_NUM_THREADS=4
# pthreads 线程池调优
export OPENCV_THREAD_POOL_ACTIVE_WAIT_WORKER=5000 # 增大自旋(低延迟场景)
export OPENCV_THREAD_POOL_ACTIVE_WAIT_WORKER=100 # 减小自旋(省电场景)
图 2:OpenCV pthreads 线程池内部调度 -- 自旋等待 + 条件变量两阶段唤醒、原子 fetch_add 工作窃取、cache-line 对齐防 false sharing。重绘自 design skill
小结
三个值得学习的设计:
-
嵌套检测用原子标志 -- 用一个
atomic<bool>而非 TLS 计数器检测嵌套parallel_for_,简洁且无平台差异。嵌套时退化串行,避免线程池死锁。 -
自旋-睡眠两阶段等待 -- 纯自旋浪费 CPU,纯条件变量有 syscall 延迟。pthreads 后端用可配置的自旋次数做过渡,主线程(等完成)比 Worker(等任务)自旋更久(10000 vs 2000),反映了两者对延迟的不同敏感度。
-
动态 chunk 大小 + cache-line 隔离 --
fetch_add的 chunk 大小随剩余任务动态缩小,尾部任务分配更均匀。三个原子变量之间插入 64 字节 dummy 避免 false sharing,在多核下显著减少 cache line bouncing。
对 VIO/SLAM 的启示 :Polaris 项目使用 TBB 作为并行后端(parallel_for 在 BA 线性化中大量使用)。理解 OpenCV 的后端选择机制和线程池配置,有助于排查多线程性能问题 -- 特别是 TBB + OpenCV pthreads 混用时的资源竞争。