下面是MIT一众科学家提出的tyche:
提出了Tyche,一种用于上下文医学图像分割的随机策略,既能推广到新任务,也能捕捉不确定性。Tyche能够为未见生物医学数据集中的图像生成多个候选分割,无需重新训练微调。
摘要
现有的基于学习的医学图像分割解决方案存在两个重要缺陷。第一,对于大多数新的分割任务,都需要训练或微调一个新模型。这需要大量的资源和机器学习专业知识,因此对于医学研究人员和临床医生来说通常是不可行的。第二,现有的大多数分割方法针对给定图像只输出一个单一的确定性分割掩码。然而在实践中,对于什么是正确的分割往往存在相当大的不确定性,不同的专家标注者经常会以不同的方式分割同一幅图像。我们使用 Tyche 同时解决这两个问题。Tyche 是一个利用上下文集(context set)为以前未见过的任务生成随机预测而无需重新训练的模型。Tyche 与其他上下文分割方法有两个重要区别:(1) 我们引入了一种新颖的卷积块架构,使得预测之间能够相互交互。(2) 我们引入了上下文测试时增强(in-context test-time augmentation),这是一种提供预测随机性的新机制。当与适当的模型设计和损失函数相结合时,Tyche 可以为新的或未见过的医学图像和分割任务预测出一组合理且多样化的分割候选,而无需重新训练。
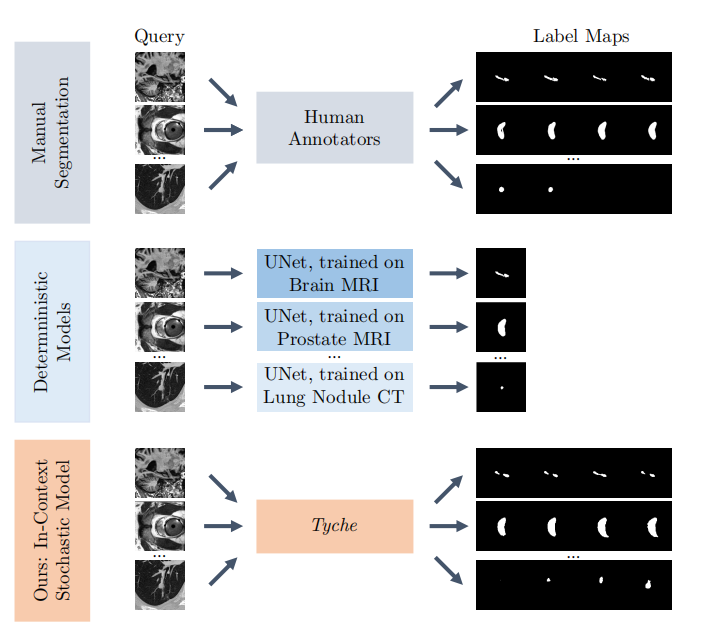
图1
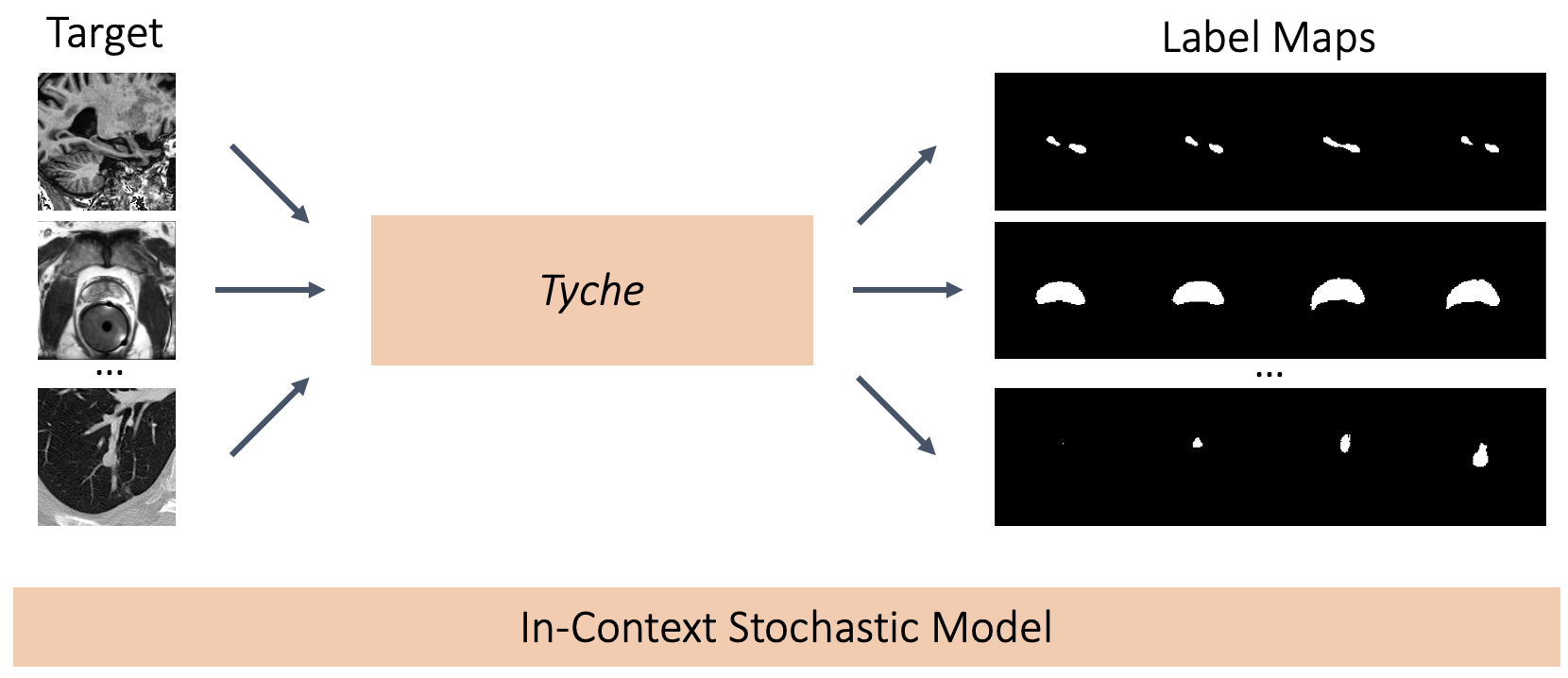
第一个上下文随机分割框架。人类标注者(上方)能够处理各种各样的任务,并且不同的标注者常常产生不同的分割结果。现有的自动化方法(中间)通常是任务特定的,每张图像只提供一个分割结果。Tyche(下方)能够在无需重新训练或微调的情况下,捕捉到不同模态和解剖结构下标注者之间的分歧。
- 引言
分割是医学图像分析中研究和临床应用的核心步骤。然而,当前的医学图像分割方法在两个关键领域存在不足。首先,分割通常涉及针对每个新模态和生物医学领域训练一个新模型,鉴于生物医学研究和临床环境中可用的资源和专业知识,这很快就变得不可行。其次,模型大多数时候只提供一个单一的解决方案,而在许多情况下,目标图像包含模糊的区域,并不存在单一的正确分割。这种模糊性可能来源于噪声大或低对比度的图像、任务定义的差异,或者人类评分者的解释和下游目标 12, 55。未能考虑这种模糊性可能会影响下游分析、诊断和治疗。
最近的研究分别处理这些问题。上下文学习方法(in-context learning)通过使用输入上下文或提示来引导推理,从而泛化到未见过的医学图像分割任务 19, 128, 129。这些方法是确定性的,对于给定的输入图像和任务只预测一个单一的分割结果。
另外,随机或概率性分割方法在推理时输出多个合理分割结果,以反映任务的不确定性 11, 67, 95。每个这样的模型都是为特定任务训练的,并且只能针对该任务在推理时输出多个合理分割。为新任务训练或微调模型需要技术专业知识和计算资源,而这些在生物医学环境中通常是缺乏的。
我们提出 Tyche,一个用于随机上下文医学图像分割的框架(图 1)。Tyche 包含针对不同场景的两个变体。第一个是 Tyche-TS(训练时随机性),一个专门设计用于产生多个候选分割的系统。第二个是 Tyche-IS(推理时随机性),一个测试时解决方案,利用预训练的确定性上下文模型。
Tyche 的输入是要分割的图像(目标)以及定义任务的图像-分割对组成的上下文集。这使得模型在部署时能够执行未见过的分割任务,无需训练新模型。Tyche-TS 学习可能的标签图分布,并预测一组合理的随机分割。Tyche-TS 通过一种新颖的卷积机制、精心选择的损失函数以及作为额外输入的噪声,使不同预测的内部表示能够相互交互,从而鼓励多样化的预测。在 Tyche-IS 中,我们展示了将测试时增强同时应用于目标和上下文集,并结合已训练的上下文模型,能够产生有竞争力的分割候选。
我们提出了第一个用于上下文学习的概率分割解决方案。我们为我们的框架开发了两个变体:Tyche-TS(训练以最大化最佳预测的质量)和 Tyche-IS(可以直接与现有上下文模型一起使用)。针对 Tyche-TS,我们引入了一种新机制 SetBlock,以鼓励多样化的分割候选。Tyche-TS 比现有的随机方法更简单,它能在一次前向传播中预测所有分割候选。通过对二十个未见过的医学成像任务进行严格的实验和消融研究,我们展示了两个框架产生的解决方案都优于现有的上下文和交互式分割基线,并且能够与在特定数据集上训练的专用随机网络的性能相当。
- 相关工作
生物医学分割是一个被广泛研究的问题,最近的方法以类似 UNet 的架构为主 6, 51, 107。这些模型处理各种各样的任务,例如不同的解剖区域、区域内要分割的不同结构、不同的图像模态以及不同的图像设置。对于大多数方法,针对这些因素的每种组合都需要训练或微调一个新模型。此外,大多数模型没有考虑图像的模糊性,只提供单一的确定性输出。
多个预测。不确定性估计可以帮助用户决定对分割结果有多大信心 26,并指导下游任务。不确定性通常分为偶然不确定性(数据中的不确定性)和认知不确定性(模型中的不确定性)29, 61。在这项工作中,我们专注于偶然不确定性。医学图像也是异方差的,即不确定性的程度在图像不同区域有所变化。
存在不同的策略来捕获不确定性。可以为每个像素分配一个概率 45, 52, 62, 76,或者使用轮廓策略和差异损失函数来预测最大和最小的合理分割 73, 132。然而,这些策略没有捕获像素之间的相关性。为了解决这个问题,一些方法针对给定图像生成多个合理的标签图 11, 67, 68, 95, 130。实现这一点的方法包括直接建模像素相关性,例如通过多元高斯分布(低秩)协方差 95 或更复杂的分布 15。另外,各种框架将类似 UNet 架构的潜在分层表示与变分自编码器相结合 11, 67, 68。最近,扩散模型已被用于集成 130 或产生随机分割 105, 133。一些方法明确地对不同标注者进行建模以捕获模糊性 48, 100, 111, 124。但这些方法不适用于我们的框架,因为我们的框架中标注者的数量及其特征是未知的。
上述大多数模型涉及复杂的建模或较长的运行时间,并且需要在每个分割任务上进行训练。在 Tyche 中,我们借鉴了这些方法的直觉,但将更高效的机制与上下文策略相结合来预测分割候选。
上下文学习。少样本框架使用少量示例来泛化到新任务 31, 80, 98, 101, 113, 117, 134,有时通过微调现有的预训练模型 32, 99, 120, 125。上下文学习分割方法(ICL)直接使用少量示例作为输入来推断任务的标签图 9, 19, 63, 63, 129, 129。这使它们能够泛化到新任务。例如,UniverSeg 使用增强的基于 UNet 的架构来泛化到训练期间未见过的医学图像分割任务 19。我们基于这些思想,使得无需重新训练即可分割新任务,但将此范式扩展到建模随机分割。
测试时增强。测试时增强(TTA)策略使用测试输入的扰动并对得到的预测进行集成。现有的 TTA 框架建模准确性 33, 64, 116, 119、鲁棒性 25 以及不确定性估计 5, 90。测试时增强已应用于不同的解剖结构和模态,包括脑 MRI 和眼底图像 3, 5, 49, 53, 97, 127。先前的工作已经将模型预测在一组输入变换上的方差形式化为捕获偶然不确定性 5, 126, 127。
Tyche 对 TTA 的使用与先前的工作不同。Tyche 不是通过对测试输入的扰动进行分割集成或像素级不确定性估计,而是将 TTA 扩展到上下文设置,并使用单个 TTA 预测来建模不确定性。
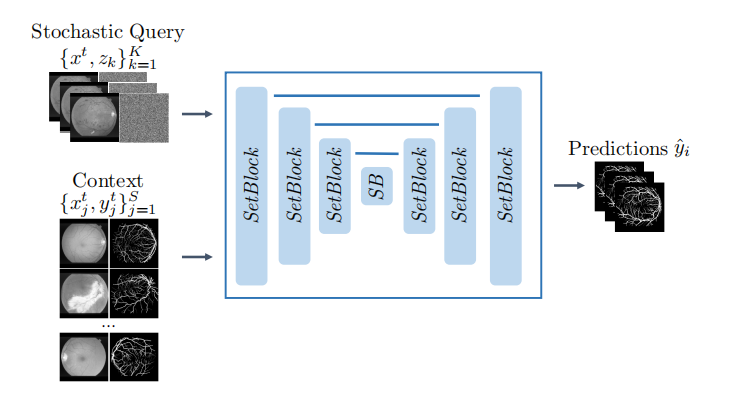
图2
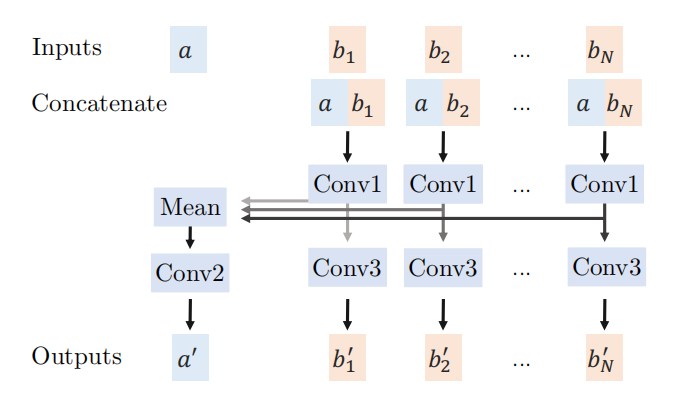
图3




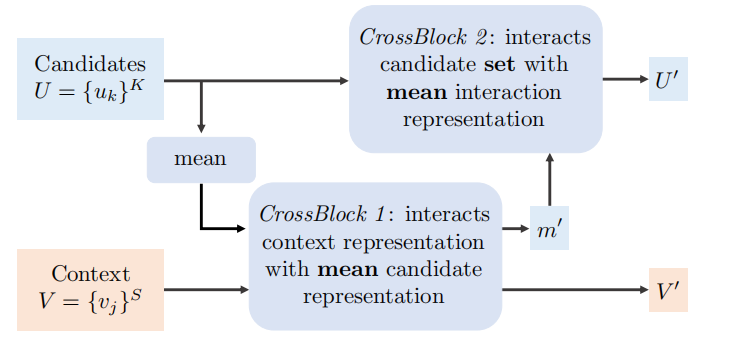
图4




对于每个用例,我们从每个数据集的相应开发集中采样上下文。因此,网络在训练时看不到任何 O.D. 数据集。
我们区分单标注者数据和多标注者数据。
单标注者数据。对于单标注者数据,我们基于近期出版物中使用的 MegaMedical 19, 131,并采用了 73 个数据集的集合,这些数据集来自不同的公共生物医学领域和不同的模态 1, 2, 7, 14, 16, 17, 19, 21, 24, 34-36, 39, 40, 42, 43, 50, 54, 56, 57, 59, 69, 71, 72, 74, 75, 77-79, 82-89, 91, 96, 103, 104, 106, 110, 112, 115, 118, 121, 122, 135, 137-139。MegaMedical 涵盖了各种解剖结构和模态,包括脑 MRI、心脏超声、胸部 CT 和牙科 X 光。我们还使用了涉及模拟形状、强度和图像伪影的合成数据 19, 44。用于域外(O.D.)测试的单标注者数据集包括:PanDental 1、WBC 139、SCD 104、ACDC 14 和 SpineWeb 138。
多标注者数据。对于多标注者 I.D. 数据,我们使用了来自 Qubiq 92 的四个数据集:Brain Growth、Brain Lesions、Pancreas Lesions 和 Kidney。我们还模拟了一个由随机形状(blob)组成的多评分者数据集。对于 O.D. 多标注者数据,我们使用了四个数据集。其中一个包含来自一家大医院的脑 MRI 上的海马体分割图。我们围绕海马体裁剪体积 67,以聚焦于评分者意见不一致的区域。第二个是公开可用的肺结节数据集 LIDC-IDRI 4。该数据集以显著的评分者间变异性而闻名。它包含 1018 次胸部 CT 扫描,每次由来自一个包含 12 名标注者的池中的 4 名标注者进行标注。最后,我们还使用了视网膜眼底图像 STARE 47(由 2 名评分者标注)以及来自 MICCAI 2021 QUBIQ 挑战赛的前列腺数据 92(在两个任务上由 6 名评分者标注)。单标注者和多标注者数据合并后,我们的 O.D. 组包含 20 个在训练时未见过的任务(有些数据集包含多个任务)。
4.2. 评估
我们通过定性和定量分析单个预测质量和预测分布来评估我们的方法。我们还通过消融研究来检验模型选择。
随机分割的一个主要用例是向人类评分者提供一小组分割结果,供其选择最适合其目的的那个。在这种情况下,如果至少有一个预测与评分者所寻找的结果匹配,则该模型可被视为良好。因此,我们采用最佳候选 Dice 指标。

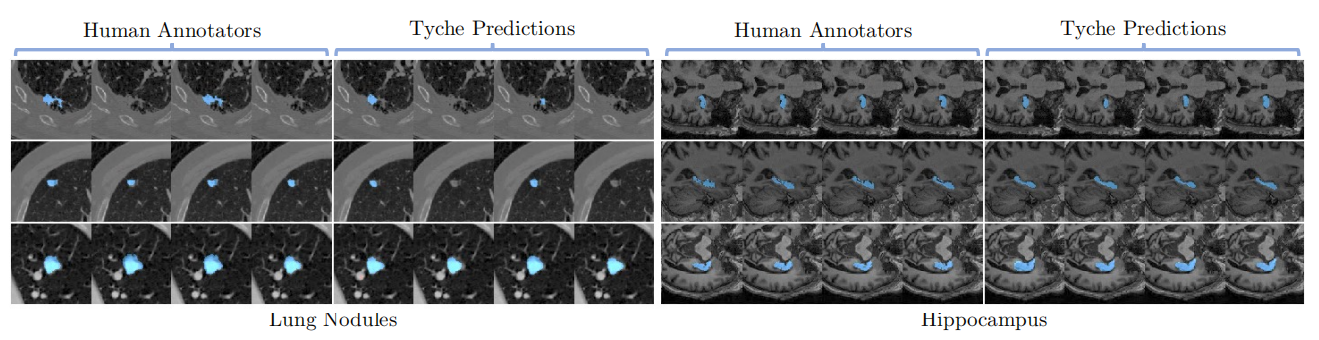
图5
4.3. 基准方法
Tyche 是第一个在上下文中产生随机分割预测的方法。因此,我们将 Tyche 与现有的基准方法进行比较,这些方法各自只实现了我们目标的一个子集。
上下文方法。我们与能够利用上下文集的确定性框架进行比较:一种少样本方法 SENet 108,以及两种上下文学习方法 UniverSeg 19 和 SegGPT 129。我们使用与 Tyche 相同的数据划分策略和相同的增强变换集来训练 UniverSeg 和 SENet。对于 SegGPT,我们使用公开的模型,该模型在自然图像和医学图像的混合数据上训练。补充材料中的图 13 显示,使用更多数据训练的 UniverSeg 优于其公开版本。
text\[79, 749, 466, 899, 501, 614, 888, 643]
随机上界。我们与任务特定的概率分割方法进行比较,这些方法在特定数据集上训练并表现良好。我们分别在 20 个保留任务上独立训练 Probabilistic UNet 67、PhiSeg 11 以及 CIDM(一种最新的扩散网络 105)。对于每个任务,我们训练三个模型变体:无增强、弱增强以及与 Tyche 目标相同强度的增强。对于每个基准变体,我们在 O.D. 开发划分上进行训练,并选择在相应 O.D. 验证划分上表现最好的模型。然后,我们将这些基准与 Tyche 在保留的 O.D. 测试划分上进行比较。
这些模型明确针对它们所评估的数据集进行了优化,而 Tyche 则不使用这些数据集进行训练。由于它们是在 O.D. 数据集划分上进行训练、调优和评估的------而我们在问题设置中明确希望避免这种情况,因为这在许多医学环境中并不容易实现------因此它们作为性能的上界。
交互式分割方法。我们与两种交互式方法进行比较:SAM 66 和 SAM-Med2D 23。这些方法可以提供多个分割,但与 Tyche 不同,它们需要人工交互,这超出了我们的范围。SAM 还具有分割图像中所有元素的功能,但在医学影像方面优化较少。我们假设基于 SAM 的模型能够获得与 ICL 方法相同的信息:几个图像-分割对作为上下文来引导分割任务。我们使用 I.D. 开发数据集对 SAM 进行微调。为了替代人工交互,我们提供一个边界框、平均上下文标签图以及 10 次点击(5 个正样本、5 个负样本)作为输入。对于 SAM-Med2D,我们使用一个边界框以及若干正负点击作为输入。对于 SAM 和 SAM-Med2D,我们都从平均上下文标签图生成点击和边界框。
我们使用一次交互迭代,并通过采样不同的点击集和不同的平均上下文集来生成不同的合理分割候选。
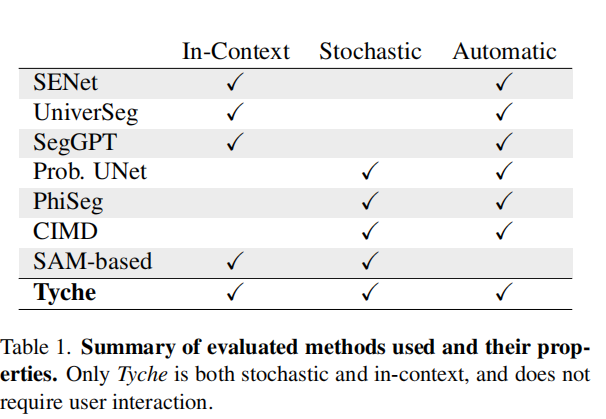
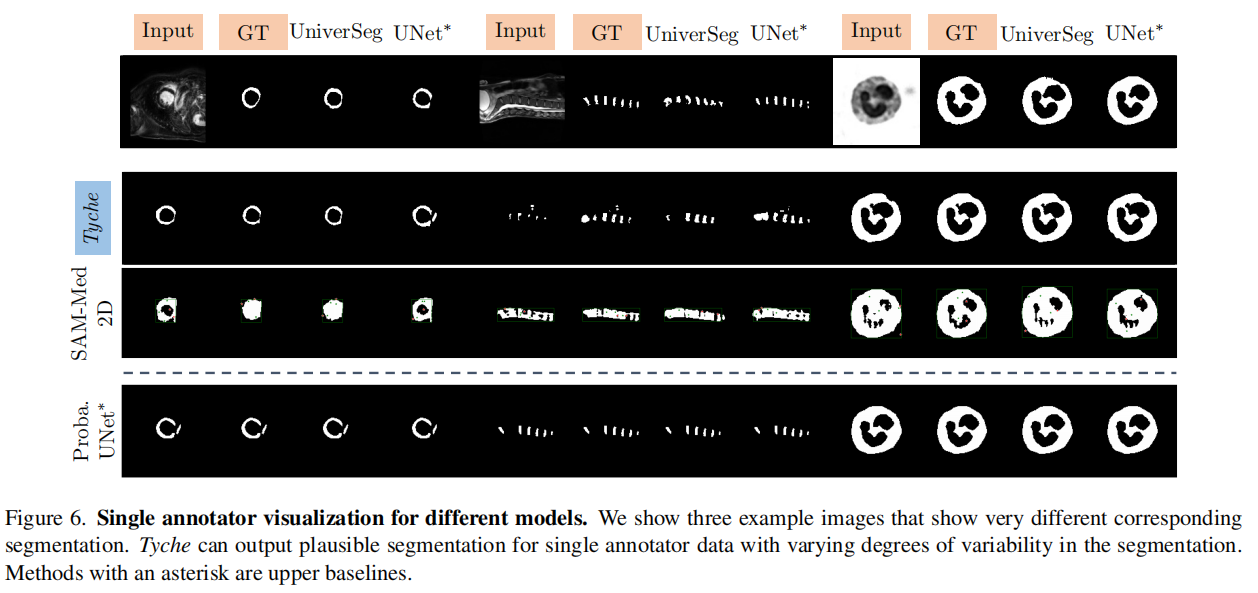
4.4. 实验
我们在多标注者和单标注者 O.D. 数据上评估所有模型。然后,我们分别分析 Tyche 的变体,并对每个变体进行消融研究以验证参数选择。最后,我们比较 GPU 推理运行时间和模型参数。
在补充材料中,我们进一步分析了输入噪声、上下文集、预测数量、SetBlock 和候选损失。我们还提供了额外的性能指标和每个数据集的结果。我们还在少样本设置下比较了 Tyche 和 PhiSeg 的性能。最后,我们提供了更多的可视化结果。



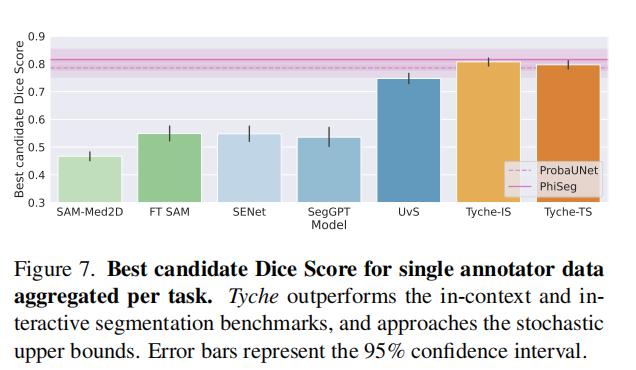
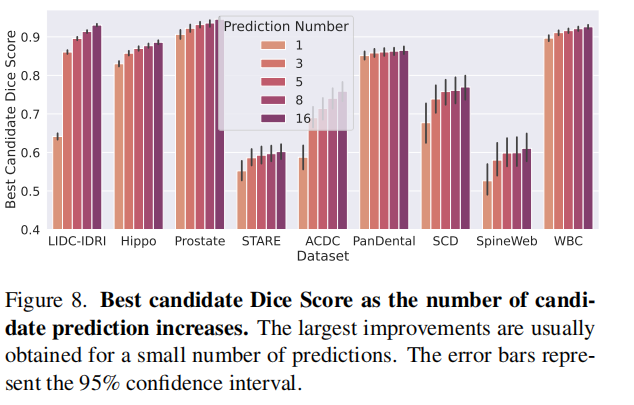
表 2. 不同模型在上下文大小为 16(上下文方法)且预测数量设为 8 时的广义能量距离。数值越低越好。Tyche 优于交互式和上下文基线,并与随机上界相当。
Table 2. Generalized Energy Distance for different models with a context size of 16 for in-context methods and a number of predictions set to 8. Lower is better. Tyche outperforms interactive and in-context baselines, and matches stochastic upper bounds.
| GED²(↓) | Hippocampus | LIDC-IDRI | Prostate Task 1 | Prostate Task 2 | STARE | |
|---|---|---|---|---|---|---|
| Interactive | SAM | 0.57 ± 0.02 | 0.90 ± 0.01 | 0.20 ± 0.03 | 0.31 ± 0.06 | 0.89 ± 0.06 |
| SAM-Med2d | 0.93 ± 0.02 | 1.01 ± 0.01 | 0.80 ± 0.09 | 0.78 ± 0.11 | 1.52 ± 0.05 | |
| I-C & Stochastic (Ours) | Tyche-IS | 0.21 ± 0.01 | 0.41 ± 0.01 | 0.12 ± 0.02 | 0.20 ± 0.05 | 0.73 ± 0.03 |
| Tyche-TS | 0.22 ± 0.01 | 0.40 ± 0.01 | 0.09 ± 0.02 | 0.15 ± 0.03 | 0.62 ± 0.03 | |
| Stochastic Upper Bound | PhiSeg | 0.14 ± 0.01 | 0.33 ± 0.01 | 0.12 ± 0.01 | 0.17 ± 0.05 | 1.22 ± 0.02 |
| ProbaUNet | 0.13 ± 0.01 | 0.51 ± 0.01 | 0.08 ± 0.01 | 0.18 ± 0.05 | 0.76 ± 0.06 | |
| CIDM | 0.17 ± 0.01 | 0.42 ± 0.01 | 0.14 ± 0.02 | 0.26 ± 0.04 | 0.87 ± 0.05 |
表 3. 不同模型在上下文大小为 16(上下文方法)且预测数量设为 8 时的最佳候选 Dice 分数。数值越高越好。Tyche 优于交互式和上下文基线,并与随机上界相当。
Table 3. Best candidate Dice score for different models with a context size of 16 for in-context methods and a number of predictions set to 8. Higher is better. Tyche outperforms interactive and in-context baselines, and matches stochastic upper bounds.
| Max Dice (↑) | Hippocampus | LIDC-IDRI | Prostate Task 1 | Prostate Task 2 | STARE | |
|---|---|---|---|---|---|---|
| In-Context | UniverSeg | 0.84 ± 0.01 | 0.67 ± 0.01 | 0.91 ± 0.01 | 0.88 ± 0.03 | 0.51 ± 0.02 |
| SegGPT | 0.10 ± 0.01 | 0.68 ± 0.01 | 0.94 ± 0.01 | 0.89 ± 0.03 | 0.02 ± 0.01 | |
| SENet | 0.68 ± 0.01 | 0.00 ± 0.00 | 0.83 ± 0.02 | 0.83 ± 0.02 | 0.30 ± 0.03 | |
| Interactive | SAM | 0.71 ± 0.01 | 0.55 ± 0.01 | 0.90 ± 0.01 | 0.85 ± 0.03 | 0.50 ± 0.03 |
| SAM-Med2d | 0.52 ± 0.01 | 0.42 ± 0.01 | 0.62 ± 0.04 | 0.64 ± 0.06 | 0.21 ± 0.03 | |
| I-C & Stochastic (Ours) | Tyche-IS | 0.87 ± 0.01 | 0.90 ± 0.00 | 0.94 ± 0.01 | 0.91 ± 0.01 | 0.52 ± 0.03 |
| Tyche-TS | 0.88 ± 0.01 | 0.91 ± 0.00 | 0.95 ± 0.01 | 0.93 ± 0.01 | 0.60 ± 0.02 | |
| Stochastic Upper Bound | PhiSeg | 0.88 ± 0.00 | 0.91 ± 0.00 | 0.93 ± 0.01 | 0.91 ± 0.02 | 0.15 ± 0.01 |
| ProbaUNet | 0.91 ± 0.00 | 0.86 ± 0.01 | 0.95 ± 0.00 | 0.91 ± 0.03 | 0.59 ± 0.02 | |
| CIDM | 0.84 ± 0.01 | 0.92 ± 0.00 | 0.93 ± 0.01 | 0.87 ± 0.02 | 0.41 ± 0.04 |
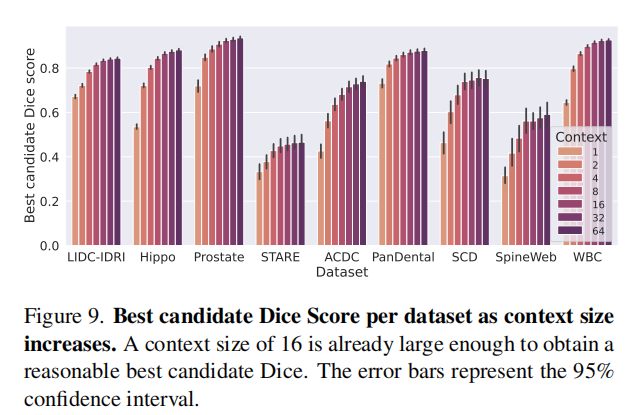
表 4. Tyche 变体的消融研究。上:Tyche-TS,分别无模拟多标注者数据、有 SetBlock、有 SetBlock 中的标准差。下:Tyche-IS,分别对目标、上下文和包含非增强上下文的大上下文进行增强。
Table 4. Ablation Study for Tyche variants. Top: Tyche-TS, without simulated multi-annotator data, with SetBlock, with Standard Deviation in SetBlock. Bottom: Tyche TeS, with Target, Context and Large Context augmentations.
| Blob | SetBlock | Std | Max. DSC(↑) | GED²(↓) | |
|---|---|---|---|---|---|
| × | 0.810 ± 0.01 | 0.349 ± 0.04 | |||
| × | × | 0.771 ± 0.02 | 0.425 ± 0.05 | ||
| ✓ | ✓ | 0.802 ± 0.01 | 0.425 ± 0.05 | ||
| ✓ | ✓ | ✓ | 0.811 ± 0.01 | ||
| Target | CS | CS+ | Max. DSC(↑) | GED²(↓) | |
| ✓ | 0.776 ± 0.02 | 0.477 ± 0.04 | |||
| ✓ | 0.700 ± 0.02 | 0.410 ± 0.05 | |||
| ✓ | 0.561 ± 0.02 | 0.867 ± 0.05 | |||
| ✓ | ✓ | 0.813 ± 0.01 | 0.333 ± 0.04 | ||
| ✓ | ✓ | 0.808 ± 0.01 | 0.358 ± 0.04 |
(数值)在各个任务上取平均。
表 4 显示,模拟多标注者数据带来的改进可以忽略不计,添加标准差也是如此。然而,SetBlock 是提高最佳候选 Dice 分数的关键部分。
我们研究了 Tyche-IS 中三种 TTA 类型的性能:对目标增强、对上下文增强(CS),以及对上下文增强并同时包含非增强上下文(CS+):
表 5. 对于 8 个预测和上下文大小为 16 的推理运行时间和模型参数。
Table 5. Inference Runtime and Model Parameters for 8 predictions and a context size of 16.
| Inference Time (ms) | Parameters | |
|---|---|---|
| UniverSeg | 96.62 ± 0.61 | 1.2M |
| SegGPT | 2857.19 ± 4.38 | 370M |
| SENet | 14.91 ± 0.21 | 0.89M |
| FT-SAM | 1036.75 ± 4.61 | 94M |
| SAM-Med2D | 188.8 ± 7.58 | 91M |
| PhiSeg | 11.35 ± 0.67 | 221.1M |
| ProbaUNet | 8.44 ± 0.46 | 5M |
| CIDM | 1.7 × 10⁵ ± 27488 | 85.6M |
| Tyche-IS | 128.57 ± 2.62 | 61.2M |
| Tyche-TS | 18.09 ± 0.61 | 1.7M |
(即对上下文增强并包含非增强上下文)。表 4 显示,仅对目标或上下文之一添加噪声会导致次优性能,而同时对目标和上下文进行增强则会提高性能。
5.3. 推理运行时间
我们通过每种方法预测 8 个分割候选来比较推理运行时间,并将该过程重复 300 次。我们使用 NVIDIA V100 GPU。表 5 显示,Tyche 明显比 SegGPT 和 CIDM 更快且更小,但不如某些任务特定的随机模型快。Tyche-IS 的参数量少于 Tyche-TS,但需要额外的推理时间。
6. 结论
我们提出了 Tyche,第一个用于随机上下文分割的框架。对于任何(新的)分割任务,Tyche 可以直接产生多样化的分割候选,从业者可以从中选择最合适的一个,并更好地理解潜在的不确定性。Tyche 能够泛化到训练时未见过的图像数据,并且优于上下文和交互式基准。此外,Tyche 在那些已有专门训练过的随机模型的任务上,往往也能达到与之相当的性能。Tyche 有两个变体:一个专为优化最佳分割候选而设计,推理时间快;另一个是测试时增强变体,可与现有上下文学习方法结合使用。我们期待进一步研究 Tyche-TS 和 Tyche-IS 所捕获的不同类型的不确定性。我们还将通过更复杂的支持集(包括可变标注者和多种图像模态)来扩展 Tyche 的能力。
7.实验代码已复现:首页微信可思
方法
Tyche捕捉了医学图像分割中固有的歧义,同时推广到新任务而无需重新训练。
Tyche使用定义切割任务的输入上下文集图像-分割对来了解如何分割输入目标图像。关键是,它通过输出灵活数量的合理预测来捕捉不确定性。
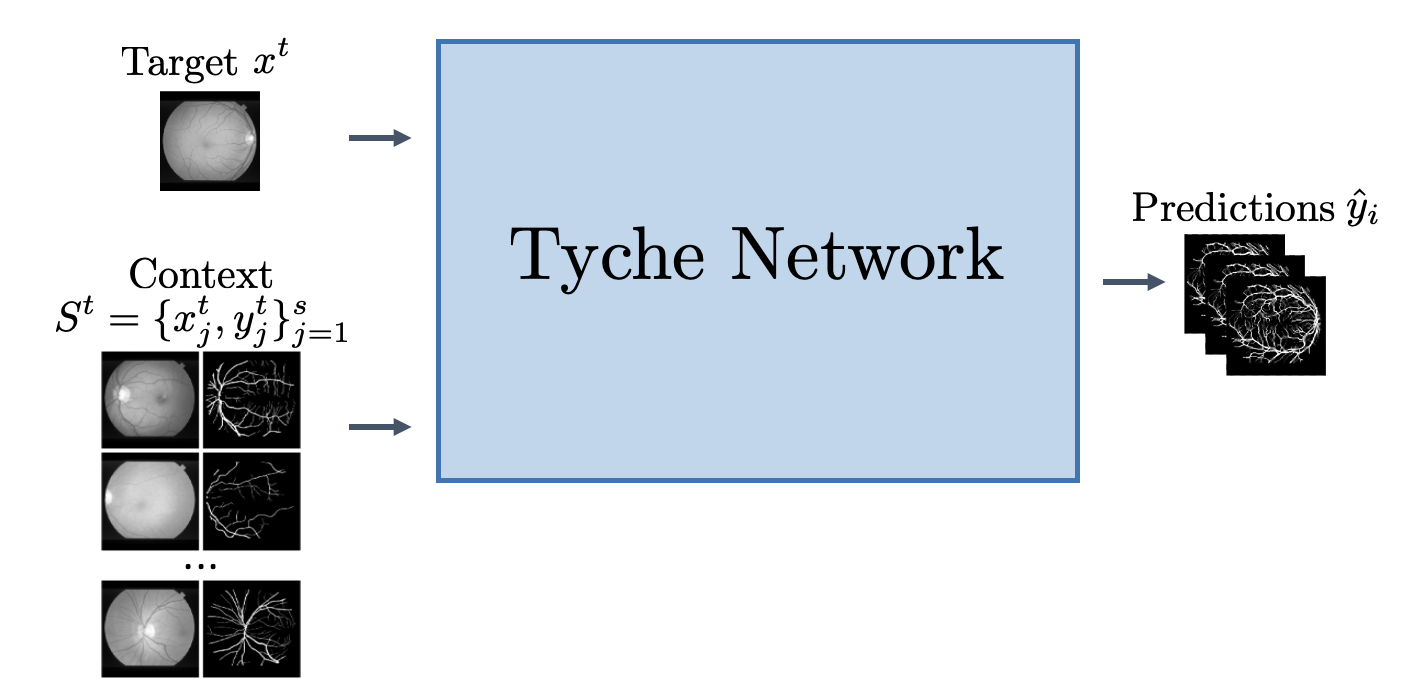
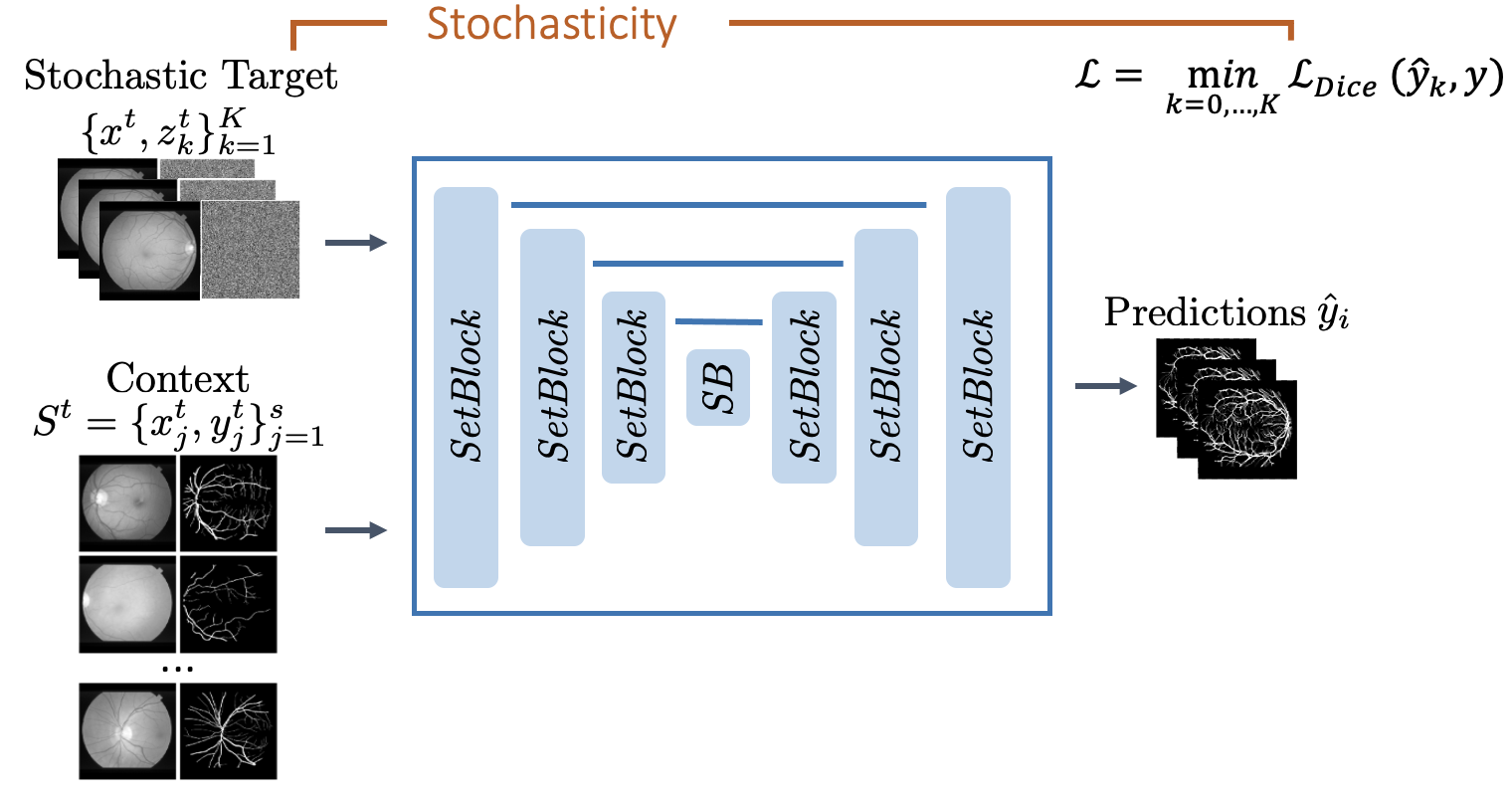
我们通过以下方式捕捉不确定性:
(1)最佳候选骰子输掉(以对冲其赌注),通过仅反向传播梯度以获得最佳预测来鼓励多样性。
(2) SetBlock,一种用于预测在每一层相互作用的架构机制。
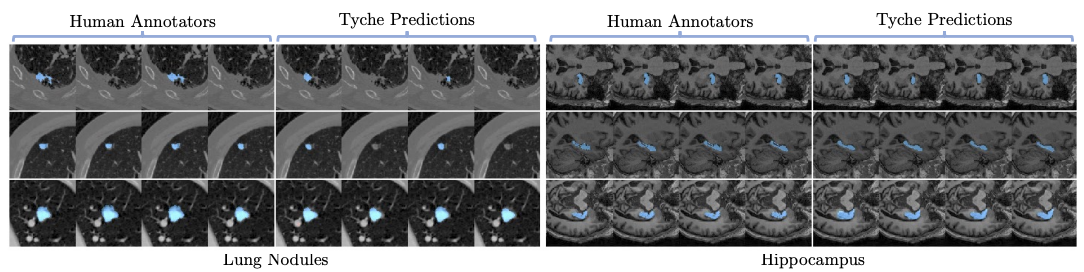
可视化
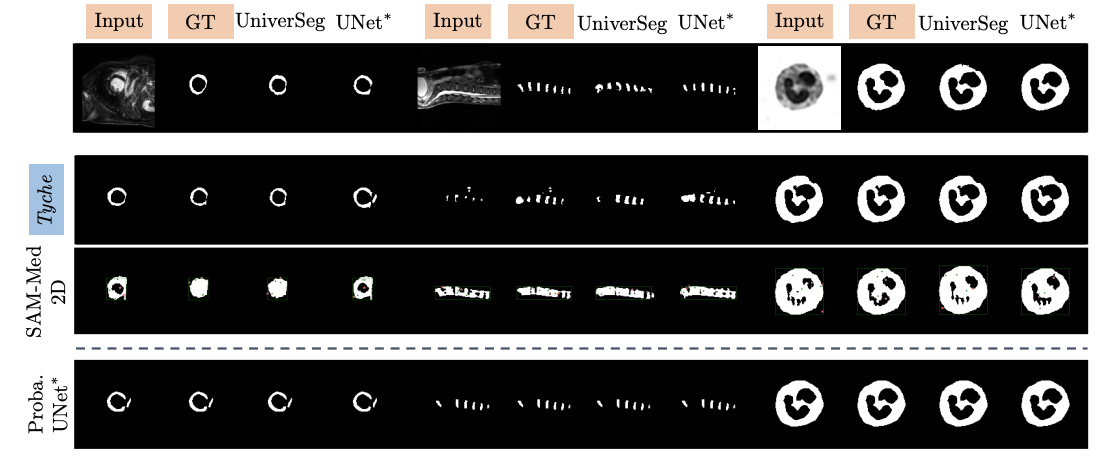
Tyche通过提供合理、多样化的解决方案,准确捕捉目标图像中的模糊性,即使是针对新的、此前未见过的分割领域和目标。
多注释者数据示例:
单标注数据示例: