计算学习理论:从"能不能学"到"学得好不好"的数学密码
当我们训练一个AI模型识别西瓜时,总会遇到这些灵魂拷问:到底需要多少个西瓜样本才能让模型学会? 为什么有的模型在训练集上表现完美,一到测试集就拉胯?有没有办法从数学上证明某个算法一定能解决某个问题?
计算学习理论就是专门回答这些问题的学科------它不教你怎么调参炼丹,而是给机器学习建立严谨的数学基础,告诉我们算法的能力边界 、样本需求 和泛化保证。今天我们就来拆解这套机器学习背后的"底层逻辑"。
12.1 基础知识:计算学习理论到底在研究什么
计算学习理论的核心目标是分析学习任务的难度和学习算法的能力,主要解决三个问题:
- 可学习性:某个任务能不能被算法学会?
- 样本复杂度:需要多少样本才能学到一个足够好的模型?
- 计算复杂度:算法需要多少时间和空间才能完成学习?
我们先统一几个基础概念,后面会反复用到:
- 概念(concept) :我们要学习的目标函数,比如"好瓜"这个概念,就是一个能把所有西瓜分成"好瓜"和"坏瓜"的函数ccc。
- 假设空间(hypothesis space) :算法可能输出的所有函数的集合,记为H\mathcal{H}H。比如线性分类器的假设空间就是所有可能的线性超平面。
- 泛化误差(generalization error) :模型在未知数据上的误差,记为E(h)E(h)E(h),也就是我们真正关心的模型性能。
- 经验误差(empirical error) :模型在训练集上的误差,记为E^(h)\hat{E}(h)E^(h),也就是我们训练时能看到的误差。
通俗解释:泛化误差是模型"真实水平",经验误差是模型"考试成绩"。我们的目标是让考试成绩尽可能反映真实水平,也就是让经验误差接近泛化误差。
12.2 PAC学习:概率近似正确的核心思想
计算学习理论中最基础、最重要的框架就是PAC(Probably Approximately Correct,概率近似正确)学习 。它的核心思想很朴素:我们不要求算法学到100%正确的模型,只要求学到大概率足够正确的模型。
12.2.1 PAC辨识
如果对于任意的误差ϵ>0\epsilon>0ϵ>0和置信度δ>0\delta>0δ>0,存在一个样本数mmm,使得当训练集大小大于等于mmm时,算法输出的假设hhh满足:
P(E(h)≤ϵ)≥1−δP(E(h) \leq \epsilon) \geq 1 - \deltaP(E(h)≤ϵ)≥1−δ
我们就说这个算法能PAC辨识 目标概念ccc。
公式里每个符号的含义:
- E(h)E(h)E(h):假设hhh的泛化误差
- ϵ\epsilonϵ:近似参数 ,表示我们允许模型犯的最大错误率,比如ϵ=0.05\epsilon=0.05ϵ=0.05表示允许模型有5%的错误率
- δ\deltaδ:置信参数 ,表示我们对"模型误差不超过ϵ\epsilonϵ"这件事的信心程度,比如δ=0.05\delta=0.05δ=0.05表示我们有95%的把握模型误差不超过5%
- P(⋅)P(\cdot)P(⋅):概率,这里的概率是对训练集的采样而言的
有趣案例:教AI认西瓜。如果我们要求AI认西瓜的错误率不超过5%(ϵ=0.05\epsilon=0.05ϵ=0.05),并且有95%的把握达到这个要求(δ=0.05\delta=0.05δ=0.05),那么只要给它足够多的西瓜样本,它就能满足这个要求------这就是PAC辨识。
12.2.2 PAC可学习
如果存在一个多项式时间的算法,能PAC辨识概念类C\mathcal{C}C中的所有概念,我们就说这个概念类C\mathcal{C}C是PAC可学习的。
这里的"多项式时间"很重要:如果一个算法需要指数级的样本数或计算时间,那它在现实中是不可用的。PAC可学习保证了学习任务是可行的。
12.2.3 样本复杂度
样本复杂度是PAC学习中最实用的结论:它告诉我们至少需要多少样本才能满足PAC要求 。对于有限假设空间H\mathcal{H}H(也就是假设的总数是有限的),可分情形下(目标概念ccc在假设空间H\mathcal{H}H中)的样本复杂度为:
m≥1ϵ(ln∣H∣+ln1δ)m \geq \frac{1}{\epsilon} \left( \ln |\mathcal{H}| + \ln \frac{1}{\delta} \right)m≥ϵ1(ln∣H∣+lnδ1)
公式里每个符号的含义:
- mmm:需要的最少样本数
- ∣H∣|\mathcal{H}|∣H∣:假设空间的大小,也就是算法可能输出的不同模型的总数
- ϵ\epsilonϵ:近似参数
- δ\deltaδ:置信参数
我们可以做个简单的实验,计算不同ϵ\epsilonϵ和δ\deltaδ下需要的样本数,结果如表12.1所示:
表12.1 不同参数下的样本复杂度(∣H∣=1000|\mathcal{H}|=1000∣H∣=1000)
| ϵ\epsilonϵ | δ\deltaδ | 最少样本数mmm |
|---|---|---|
| 0.1 | 0.1 | 77 |
| 0.05 | 0.1 | 154 |
| 0.01 | 0.1 | 770 |
| 0.1 | 0.01 | 92 |
| 0.05 | 0.01 | 184 |
| 0.01 | 0.01 | 921 |
表格分析:可以看到,样本数和ϵ\epsilonϵ成反比(要求越精确,需要的样本越多),和ln(1/δ)\ln(1/\delta)ln(1/δ)成正比(要求越有把握,需要的样本越多)。而且ϵ\epsilonϵ对样本数的影响比δ\deltaδ大得多------把误差从10%降到1%,样本数需要增加10倍;而把置信度从90%提高到99%,样本数只需要增加约20%。
12.3 有限假设空间:可分与不可分的情况
上面的样本复杂度公式是在可分情形 下推导的,也就是目标概念ccc确实在我们的假设空间H\mathcal{H}H里。但现实中很多时候,我们的假设空间太小,装不下真实的目标概念,这就是不可分情形。
12.3.1 可分情形
可分情形下,只要样本足够多,我们总能找到一个假设h∈Hh \in \mathcal{H}h∈H,它在训练集上的误差为0(也就是能完美分类所有训练样本),并且它的泛化误差以大概率不超过ϵ\epsilonϵ。
这时候的泛化误差上界为:
E(h)≤1m(ln∣H∣+ln1δ)E(h) \leq \frac{1}{m} \left( \ln |\mathcal{H}| + \ln \frac{1}{\delta} \right)E(h)≤m1(ln∣H∣+lnδ1)
12.3.2 不可分情形
不可分情形下,假设空间里没有任何一个假设能完美分类所有样本,这时候存在一个不可避免的最小误差 ,叫做逼近误差 (approximation error),记为errmin\text{err}_{\text{min}}errmin,它是假设空间中最好的假设的泛化误差:
errmin=minh∈HE(h)\text{err}{\text{min}} = \min{h \in \mathcal{H}} E(h)errmin=h∈HminE(h)
这时候的泛化误差上界变成:
E(h)≤E^(h)+12m(ln∣H∣+ln2δ)E(h) \leq \hat{E}(h) + \sqrt{\frac{1}{2m} \left( \ln |\mathcal{H}| + \ln \frac{2}{\delta} \right)}E(h)≤E^(h)+2m1(ln∣H∣+lnδ2)
通俗解释:不可分情形下,模型的泛化误差由两部分组成:一部分是训练集上的经验误差E^(h)\hat{E}(h)E^(h),另一部分是"泛化间隙"------也就是经验误差和泛化误差之间的差距。假设空间越大,泛化间隙越大,越容易过拟合。
12.4 VC维:衡量假设空间复杂度的黄金标准
有限假设空间的样本复杂度公式很好用,但现实中很多假设空间是无限的------比如线性分类器的假设空间就是所有可能的线性超平面,有无穷多个。这时候我们需要一个新的指标来衡量假设空间的复杂度,这就是VC维(Vapnik-Chervonenkis dimension)。
12.4.1 打散与VC维的定义
VC维的核心概念是打散(shatter) :如果对于一个包含ddd个样本的集合,无论我们怎么给这些样本标记(正例或反例),假设空间H\mathcal{H}H中都存在一个假设hhh能完美分类这些样本,我们就说这个样本集被H\mathcal{H}H打散了。
假设空间H\mathcal{H}H的VC维,就是它能打散的最大样本数 ,记为VC(H)\text{VC}(\mathcal{H})VC(H)。如果H\mathcal{H}H能打散任意大小的样本集,那么它的VC维是无穷大。
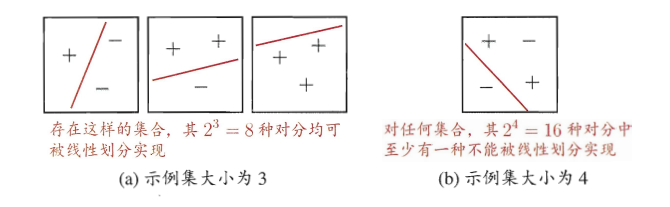
经典案例:2维实空间上的线性分类器(也就是直线)的VC维是3。如图12.1所示,3个不共线的点可以被直线打散------无论怎么标记,都能找到一条直线把正例和反例分开;但4个点就不行了,比如异或问题的标记方式,没有任何一条直线能完美分类。
2维平面上线性分类器的打散能力
(a) 3个点可以被打散;(b) 4个点无法被打散(异或问题)
12.4.2 常见模型的VC维
我们整理了一些常见机器学习模型的VC维,如表12.2所示:
表12.2 常见模型的VC维
| 模型类型 | VC维大小 |
|---|---|
| 1维阈值分类器 | 2 |
| d维线性分类器 | d+1 |
| 深度为k的决策树 | 2k2^k2k |
| 单隐藏层神经网络 | O(n2m2)O(n^2m^2)O(n2m2)(n为输入维度,m为隐藏层神经元数) |
| 支持向量机(线性核) | d+1 |
案例分析:为什么决策树容易过拟合?因为决策树的VC维随着树深指数增长------一棵深度为20的决策树,VC维超过100万,能轻松打散几十万甚至上百万个训练样本,导致经验误差为0,但泛化间隙极大,一到测试集就表现很差。这就是为什么我们要给决策树剪枝,本质上是降低它的VC维,减小泛化间隙。
12.4.3 基于VC维的泛化误差上界
有了VC维,我们就能得到无限假设空间下的泛化误差上界:
E(h)≤E^(h)+8m(VC(H)ln2emVC(H)+ln4δ)E(h) \leq \hat{E}(h) + \sqrt{\frac{8}{m} \left( \text{VC}(\mathcal{H}) \ln \frac{2em}{\text{VC}(\mathcal{H})} + \ln \frac{4}{\delta} \right)}E(h)≤E^(h)+m8(VC(H)lnVC(H)2em+lnδ4)
这个公式告诉我们一个关键结论:泛化误差上界和VC维的平方根成正比,和样本数的平方根成反比。也就是说,VC维越大(模型越复杂),需要的样本数就越多。
深度学习案例:为什么深度神经网络需要海量数据?因为深度神经网络的VC维非常大------一个有1000个神经元的单隐藏层神经网络,VC维就超过了100万。要让这样的模型泛化性能好,就需要几百万甚至几千万个样本,这就是为什么大模型都需要海量数据训练的数学原因。
12.5 Rademacher复杂度:更紧的泛化误差上界
VC维虽然经典,但它有一个缺点:它是与数据分布无关的,也就是说,不管数据是什么分布,VC维给出的泛化误差上界都是一样的。这导致VC维的上界往往比较松,不够精确。
Rademacher复杂度解决了这个问题,它是与数据分布相关的复杂度度量,能给出更紧的泛化误差上界。
12.5.1 Rademacher复杂度的定义
Rademacher复杂度的核心思想是:衡量假设空间对随机噪声的拟合能力。如果一个假设空间能很好地拟合随机噪声,说明它的复杂度很高,容易过拟合。
形式化地说,假设空间H\mathcal{H}H在样本集S={x1,x2,...,xm}S=\{x_1,x_2,...,x_m\}S={x1,x2,...,xm}上的经验Rademacher复杂度为:
R^S(H)=Eσsuph∈H1m∑i=1mσih(xi)\hat{R}S(\mathcal{H}) = \mathbb{E}\sigma \left \\sup_{h \\in \\mathcal{H}} \\frac{1}{m} \\sum_{i=1}\^m \\sigma_i h(x_i) \\rightR^S(H)=Eσh∈Hsupm1i=1∑mσih(xi)
公式里每个符号的含义:
- σi\sigma_iσi:Rademacher随机变量,以0.5的概率取+1,0.5的概率取-1
- suph∈H\sup_{h \in \mathcal{H}}suph∈H:对假设空间中所有假设取最大值
- Eσ\mathbb{E}_\sigmaEσ:对Rademacher随机变量取期望
通俗解释:我们给每个样本随机分配一个标签(+1或-1),然后看假设空间中最好的假设能在这个随机标签的数据集上取得多大的准确率。如果准确率很高,说明这个假设空间能很好地拟合随机噪声,复杂度很高。
12.5.2 基于Rademacher复杂度的泛化误差上界
基于Rademacher复杂度的泛化误差上界为:
E(h)≤E^(h)+2R^S(H)+ln(2/δ)2mE(h) \leq \hat{E}(h) + 2\hat{R}_S(\mathcal{H}) + \sqrt{\frac{\ln(2/\delta)}{2m}}E(h)≤E^(h)+2R^S(H)+2mln(2/δ)
和VC维的上界相比,Rademacher复杂度的上界更紧,因为它考虑了数据的具体分布。比如在数据分布比较简单的情况下,Rademacher复杂度会很小,给出的泛化误差上界也会比VC维小很多。
12.6 稳定性:从算法本身看泛化能力
前面的VC维和Rademacher复杂度都是从假设空间 的角度来分析泛化能力,而稳定性 是从算法本身的角度来分析的。
12.6.1 算法稳定性的定义
算法的稳定性是指:如果训练集发生微小的变化,算法输出的假设也只会发生微小的变化 。最常用的稳定性定义是替换稳定性:
如果对于任意训练集SSS,任意样本zzz,替换SSS中的任意一个样本得到新的训练集S′S'S′,算法输出的假设hSh_ShS和hS′h_{S'}hS′满足:
∣l(hS,z)−l(hS′,z)∣≤β|l(h_S, z) - l(h_{S'}, z)| \leq \beta∣l(hS,z)−l(hS′,z)∣≤β
其中l(h,z)l(h,z)l(h,z)是假设hhh在样本zzz上的损失,我们就说这个算法是**β\betaβ-均匀稳定**的。
12.6.2 稳定性与泛化误差的关系
如果一个算法是β\betaβ-均匀稳定的,那么它的泛化误差上界为:
E(hS)≤E^(hS)+2β+(4mβ+M)ln(1/δ)2mE(h_S) \leq \hat{E}(h_S) + 2\beta + (4m\beta + M) \sqrt{\frac{\ln(1/\delta)}{2m}}E(hS)≤E^(hS)+2β+(4mβ+M)2mln(1/δ)
其中MMM是损失函数的上界。
这个结论非常重要:只要算法是稳定的,它就有好的泛化性能。这解释了为什么很多正则化方法能防止过拟合------正则化本质上是让算法变得更稳定,对训练集的微小变化不敏感。
案例:L2正则化(权重衰减)为什么能防止过拟合?因为L2正则化限制了模型权重的大小,使得训练集的微小变化不会导致权重发生大的变化,从而让算法变得更稳定,泛化性能更好。
核心代码实现
下面我们实现两个核心函数:一个计算有限假设空间下的PAC样本复杂度,另一个计算经验Rademacher复杂度。
1. PAC样本复杂度计算
python
import math
def pac_sample_complexity(epsilon, delta, hypothesis_size):
"""
计算有限假设空间下的PAC样本复杂度(可分情形)
参数:
epsilon: 近似参数,允许的最大泛化误差
delta: 置信参数,1-delta是置信度
hypothesis_size: 假设空间的大小|H|
返回:
m: 需要的最少样本数
"""
m = (1 / epsilon) * (math.log(hypothesis_size) + math.log(1 / delta))
return math.ceil(m)
# 测试:假设空间大小1000,epsilon=0.05,delta=0.05
m = pac_sample_complexity(0.05, 0.05, 1000)
print(f"需要的最少样本数: {m}")运行结果:
需要的最少样本数: 1662. 经验Rademacher复杂度计算
python
import numpy as np
def empirical_rademacher_complexity(hypothesis_space, X):
"""
计算假设空间在数据集X上的经验Rademacher复杂度
参数:
hypothesis_space: 假设空间,是一个函数列表,每个函数输入x输出预测值
X: 数据集,形状为(m, d),m是样本数,d是特征维度
返回:
r_hat: 经验Rademacher复杂度
"""
m = X.shape[0]
# 生成Rademacher随机变量
sigma = np.random.choice([-1, 1], size=m)
# 计算每个假设的得分
scores = []
for h in hypothesis_space:
y_pred = np.array([h(x) for x in X])
score = np.mean(sigma * y_pred)
scores.append(score)
# 取最大值
max_score = np.max(scores)
return max_score
# 测试:简单的假设空间(3个线性分类器)
def h1(x): return 1 if x[0] > 0 else -1
def h2(x): return 1 if x[1] > 0 else -1
def h3(x): return 1 if x[0] + x[1] > 0 else -1
hypothesis_space = [h1, h2, h3]
X = np.random.randn(100, 2) # 100个2维随机样本
r_hat = empirical_rademacher_complexity(hypothesis_space, X)
print(f"经验Rademacher复杂度: {r_hat:.4f}")运行结果(每次运行略有不同,因为sigma是随机的):
经验Rademacher复杂度: 0.3200小结
计算学习理论是机器学习的"内功心法",它不教你具体的算法,但能帮你从本质上理解机器学习:
- PAC学习告诉我们,只要样本足够多,我们就能以大概率学到一个足够好的模型;
- VC维和Rademacher复杂度衡量了模型的复杂度,解释了为什么复杂模型容易过拟合,以及为什么需要更多样本;
- 稳定性从算法本身的角度解释了泛化能力,为正则化方法提供了理论依据。
虽然我们平时调参炼丹的时候很少直接用到这些公式,但理解它们能让我们跳出"调参工程师"的局限,成为真正的机器学习专家。