目录
[1. 双亲表示法](#1. 双亲表示法)
[2. 并查集的概念](#2. 并查集的概念)
[3. 并查集的实现](#3. 并查集的实现)
[4. 并查集的优化](#4. 并查集的优化)
[1. P3367 【模板】并查集 - 洛谷](#1. P3367 【模板】并查集 - 洛谷)
[2. P1551 亲戚 - 洛谷](#2. P1551 亲戚 - 洛谷)
[3. P1596 Lake Counting S - 洛谷](#3. P1596 Lake Counting S - 洛谷)
[4. P1955 程序自动分析 - 洛谷](#4. P1955 程序自动分析 - 洛谷)
一、并查集是什么?
1. 双亲表示法
并查集其实就是通过双亲表示法实现的一个个森林。森林是树的一种形式。所谓双亲表示法就是对于当前这个节点,只需要将它的双亲存下来即可。所以我们首先需要知道什么是双亲表示法?
实现方法
通过一个数组来存储,数组下标表示当前节点的编号,数组中的值表示以当前编号为下标的节点的父亲节点的编号,这就实现了双亲表示法 。如图所示: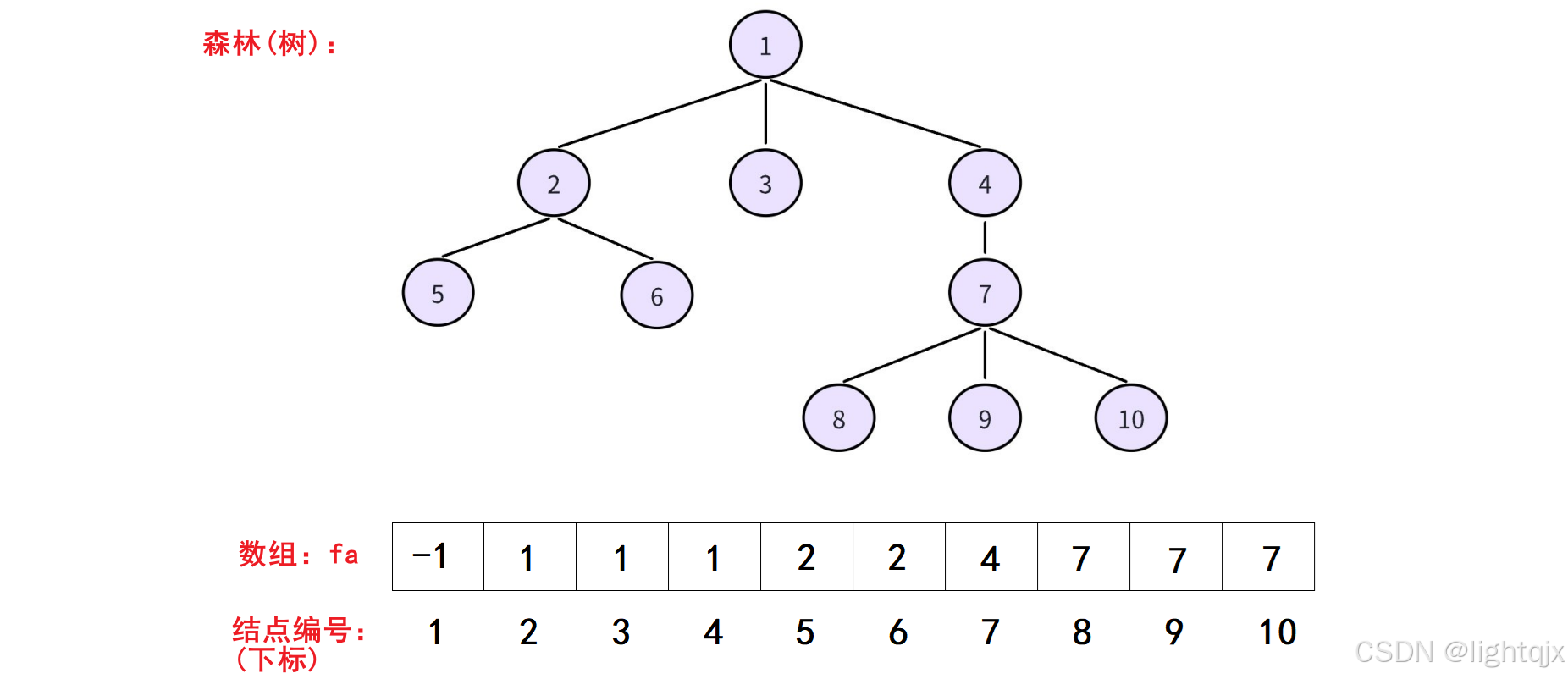 其中,编号为1的节点是根节点,它没有父亲,所以数组中的值才设置为 -1 ; 编号为 2,3,4 节点的父亲都是编号是 1 ;编号为 5,6 节点的父亲编号是 2,......
其中,编号为1的节点是根节点,它没有父亲,所以数组中的值才设置为 -1 ; 编号为 2,3,4 节点的父亲都是编号是 1 ;编号为 5,6 节点的父亲编号是 2,......
在并查集中,为了代码好实现,我们一般都将根节点编号在数组中的值 设置为它自己的编号,即自己指向自己。所以得: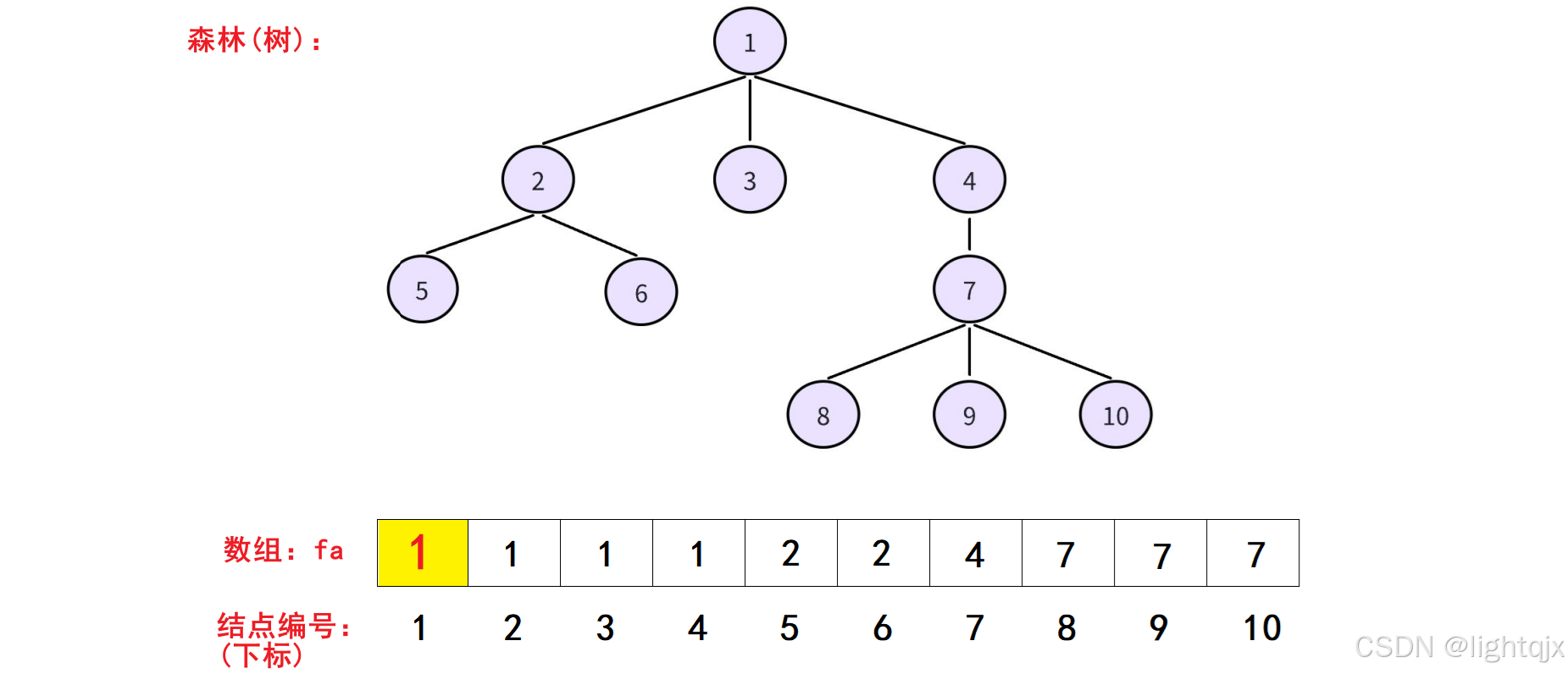
这样,我们就可以快速找到一个节点在这个森林的根节点。
2. 并查集的概念
并查集(Union Find)就是一种用于维护元素所属集合的数据结构,这些集合都是有上面这种双亲表示法实现的森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素,而根节点来代表整个集合。
主要的解决的相关问题就是需要频繁执行下面三种操作的问题:
- 查询操作:查找元素 x 属于哪一个集合。一般会在每个集合中选取一个元素作为代表,查询的是这个集合中的代表元素;
- 合并操作:将元素 x 所在的集合与元素 y 所在的集合合并成一个集合;(注意,合并的是元素所在的集合,不是这两个元素!)
- 判断操作:判断元素 x 和 y 是否在同一个集合。
这三个操作中最关键的操作就是查询操作,其他两个操作都可以基于查询操作实现。
比如如果这里有三个集合,按照并查集,这里我们就可以将每个集合都建立成一个个森林,通过数组下标表示每个元素,数组中的值则表示它们的父亲。即: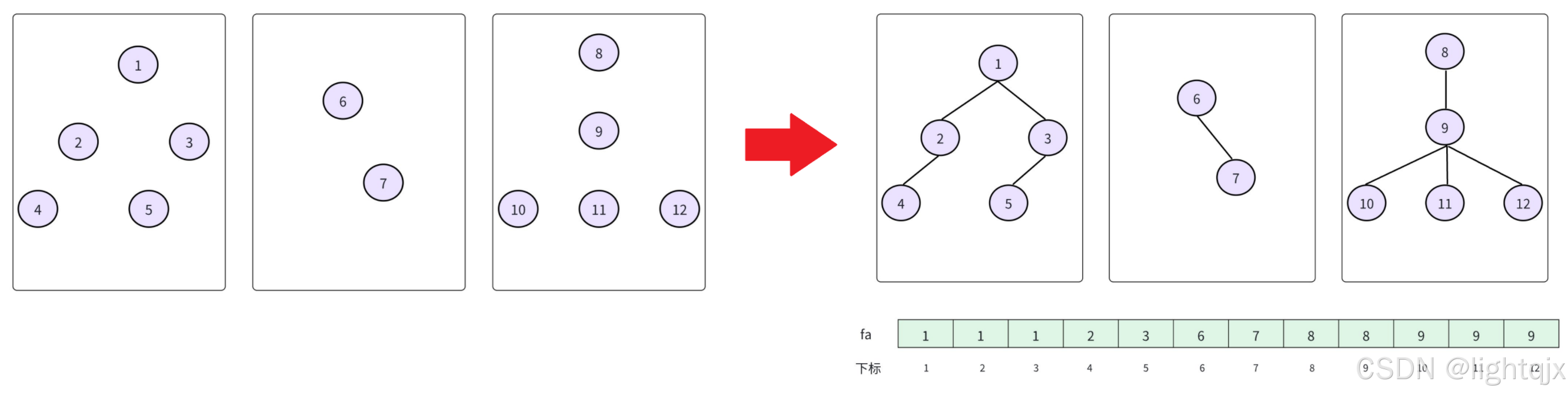
这样,第一个集合就可以用1来表示,第二个集合就可以用6来表示,第三个集合可以用8来不表示。如果要找4这个元素的所在集合,则就可以通过这个数组,不断的向上找父亲,直到根节点,那么就可以通过根节点来快速表示当前的集合。
3. 并查集的实现
(1)初始化
初始状态下,所有的元素都是单独成为一个集合,即: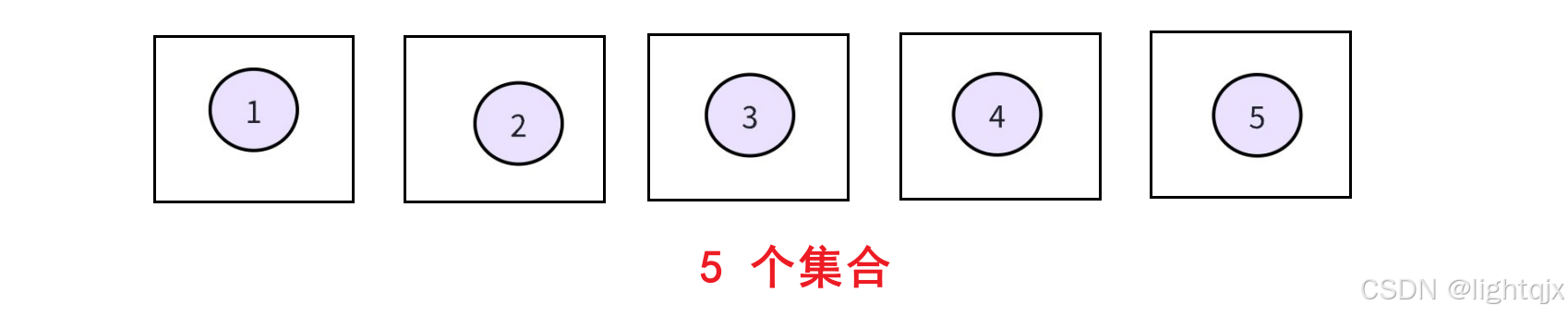 所以在fa数组中,只需要让它们自己指向自己即可。实现代码:
所以在fa数组中,只需要让它们自己指向自己即可。实现代码:
cpp
// 初始化
void init()
{
// 每个元素都单成一个集合
for(int i = 1; i <= n; i++) fa[i] = i;
}(2)查询操作★★★
查询操作是并查集的核心操作,其余所有的操作都是基于查询操作实现的!
查询就是找到一个元素 x 所属的集合,即找到元素 x 所在森林的根节点。比如下图中找12所在集合: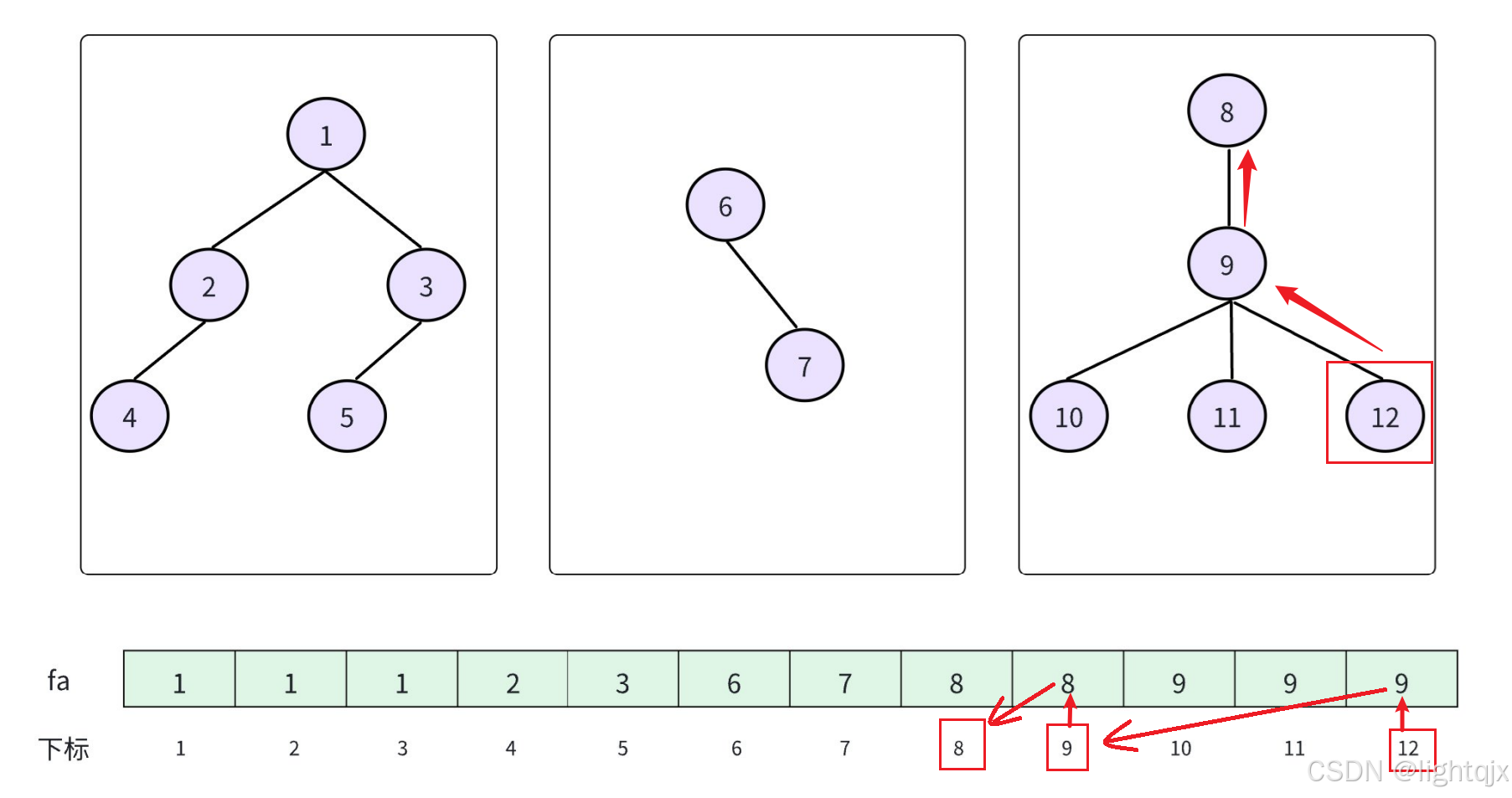 我们需要先通过12找到它的父亲fa12 = 9,再通过 9 找到它的父亲fa9 = 8,此时8的父亲就是它自己,所以8就是当前森林的根节点,即 12 的所在集合就是 8。
我们需要先通过12找到它的父亲fa12 = 9,再通过 9 找到它的父亲fa9 = 8,此时8的父亲就是它自己,所以8就是当前森林的根节点,即 12 的所在集合就是 8。
所以,查询操作就是一个不断重复的过程:
判断当前是不是根节点,若是,则直接终止寻找;若不是,则继续通过fax找它的父亲。重复此过程直到找到根节点。
实现代码就可以通过递归实现:
cpp
// 查询
int find(int x) // 查询元素x所在的集合
{
if(fa[x] == x) return x; // 找到根节点
return find(fa[x]); // 找fa[x]的父亲
}一行代码实现:
cpp
// 查询
int find(int x) // 查询元素x所在的集合
{
return fa[x] == x ? x : find(fa[x]);
}(3)合并操作
合并操作就是将元素 x 所在的集合与元素 y 所在的集合合并成⼀个集合,即让两棵树合并。具体实现可以让元素 x 所在的树的根节点指向 y 所在树的根节点(反过来也可)。所以合并的操作逻辑就是:
- 先找到 x 所在集合的根节点 fx ; y 所在集合的根节点 fy 。
- 然后修改 fx 的父亲为 fy ,即 fafx = fy 。(反过来也行)
代码实现:
cpp
// 合并
void un(int x, int y) // 合并x和y所在的集合
{
int fx = fa[x];
int fy = fa[y];
fa[fx] = fy; // fx的父亲是fy
}(4)判断操作
判断元素 x 和元素 y 是否在同一集合,即判断两者所在树的根节点是否相同。通过判断两个find的的值是否相等即可。代码实现:
cpp
// 判断
bool issame(int x, int y) // 判断x和y是否在同一集合
{
return find(x) == find(y);
}4. 并查集的优化
我们如果通过上述方法,将各个数据都合并到一个集合中,则会出现的情况就是 得到的森林是一个单链表。即: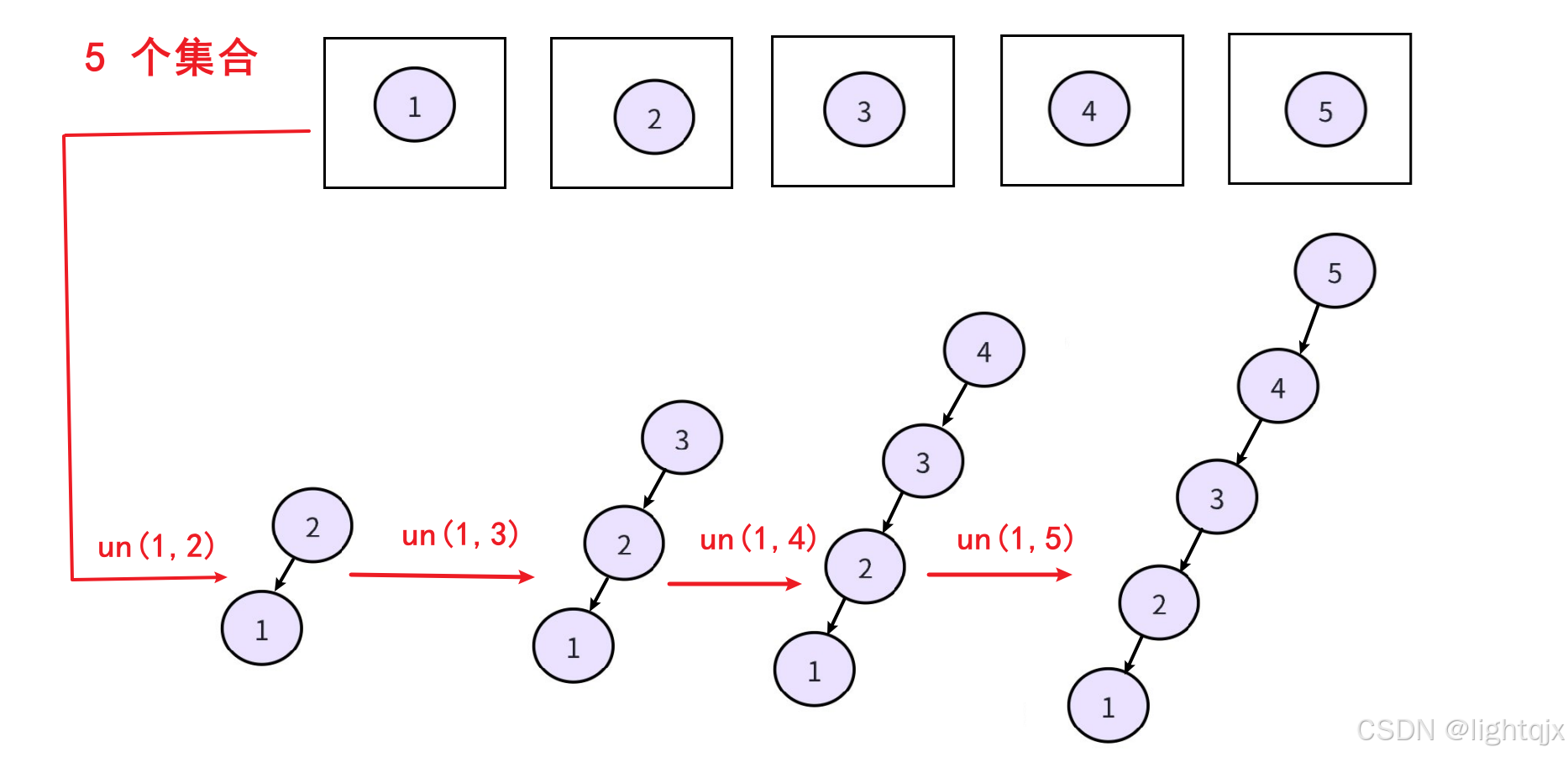
这样的话,我们查找的时间复杂度就是 O(n) 了,查找变成 O(n) 了,则其他两个操作合并和判断的时间复杂度也都会变成 O(n) ,这样属于需要频繁操作的情况时间开销是很大的。所以我们哈还需要对当前上面我们实现的并查集进行优化。
优化策略我们可以采用路径压缩 :即在查询时,把被查询的节点到根节点的路径上的所有节点的父节点设置为根节点,从而减小树的深度。这样我们查询短时间复杂度就变成 O(1) 了。即:
所以我们只允许修改查询操作的实现即可(将" return find(fax ") 修改为"return fax = find(fax)" 即可),代码实现为:
cpp
// 查询
int find(int x) // 查询元素x所在的集合
{
if(fa[x] == x) return x; // 找到根节点
return fa[x] = find(fa[x]); // 找fa[x]的父亲 + 路径压缩
}一行代码实现:
cpp
// 查询
int find(int x) // 查询元素x所在的集合
{
return fa[x] == x ? x : fa[x] = find(fa[x]);
}这段代码中 " fax = find(fax); " 的意思就是说让我们在递归玩出,回溯过程中将找到的fax 的父亲作为x的父亲。这样就变成了在该集合中所有的元素都只有一个父亲 。这样基于find函数实现合并和操作中,每次合并都会先将两个集合改成只有两层的树结构,然后再合并。
二、并查集相关例题
下面我们通过几个例题来加深对并查集的理解。
1. P3367 【模板】并查集 - 洛谷
题目链接:P3367 【模板】并查集 - 洛谷
问题内容:
解题方法:这就是一道完全的并查集模板题目,将并查集的各个操作都实现即可解答。实现代码为:
cpp
#include <iostream>
using namespace std;
const int N = 2e5 + 10;
int n, m;
int fa[N]; // 双亲表示法的数组
int find(int x)
{
if(fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
void un(int x, int y)
{
int fx = find(x);
int fy = find(y);
fa[fx] = fy;
}
bool issame(int x, int y)
{
return find(x) == find(y);
}
int main()
{
cin >> n >> m;
// 初始化
for(int i = 1; i <= n; i++) fa[i] = i;
while(m--)
{
int z, x, y; cin >> z >> x >> y;
if(z == 1) un(x, y);
if(z == 2)
{
if(issame(x, y)) cout << "Y" << endl;
else cout << "N" << endl;
}
}
return 0;
}2. P1551 亲戚 - 洛谷
题目链接:P1551 亲戚 - 洛谷
问题内容: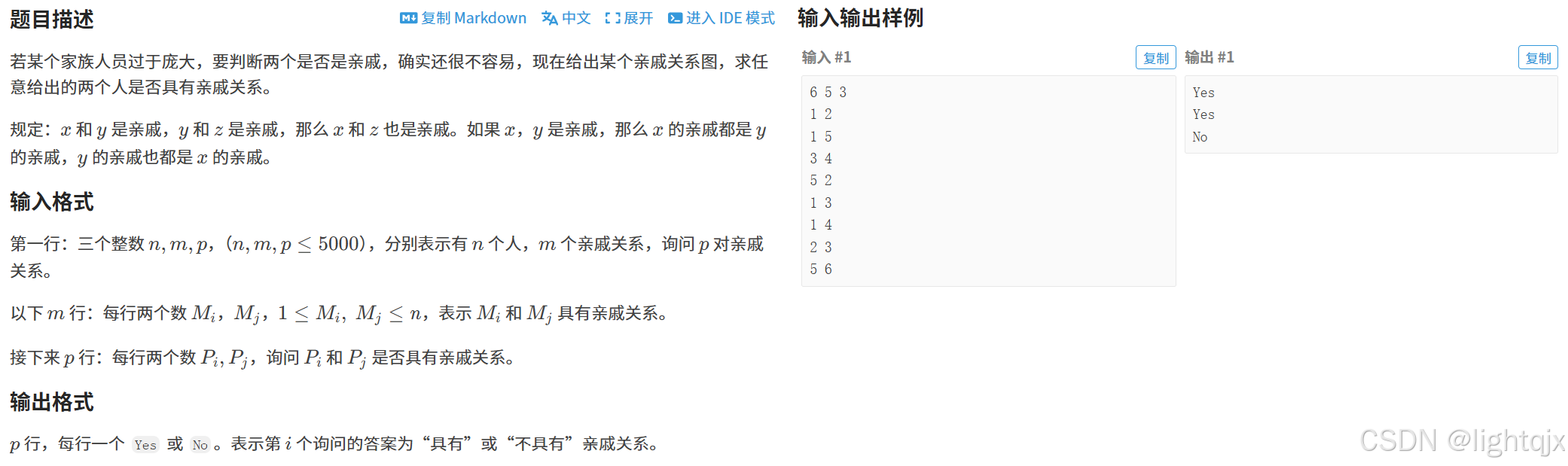
解题思路:将是亲戚的人员编号都放在一个集合中,初始的时候这 n 个人各自就是一个集合,那么只要 x 和 y 是亲戚,就可以让让 x 所在集合和 y 所在的集合合并。然后,在判断两个数是否是亲戚时,就是判断它们是否在同一个集合中即可。所以我们这道题的解决方法就是并查集。
实现代码:
cpp
#include <iostream>
using namespace std;
const int N = 2e5 + 10;
int n, m, p;
int fa[N]; // 双亲表示法的数组
int find(int x)
{
if(fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
void un(int x, int y)
{
int fx = find(x);
int fy = find(y);
fa[fx] = fy;
}
bool issame(int x, int y)
{
return find(x) == find(y);
}
int main()
{
cin >> n >> m >> p;
// 初始化
for(int i = 1; i <= n; i++) fa[i] = i;
// m 次关系来维护并查集
while(m--)
{
int x, y; cin >> x >> y;
un(x, y); // 是亲戚就放在同一个集合中
}
// q 次询问
while(p--)
{
int x, y; cin >> x >> y;
if(issame(x, y)) cout << "Yes" << endl;
else cout << "No" << endl;
}
return 0;
}3. P1596 Lake Counting S - 洛谷
题目链接:P1596 USACO10OCT Lake Counting S - 洛谷
问题内容: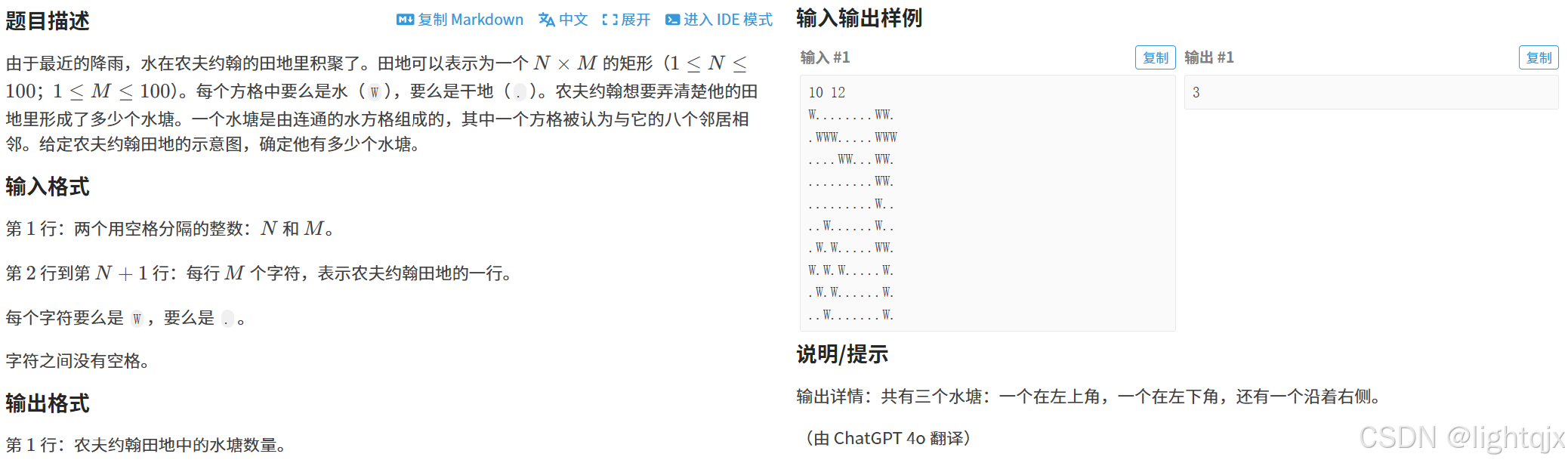
解决方法:
解法1:这道题就是一个 求联通块 数目的问题,创建的解题方法就是 BFS 或者是 DFS 就可以解决。
解法2:通过并查集来解决。解决思路下:
可以将相同联通块都放在一个集合中。所以我们就可以从上到下,从左到右开始遍历,每一个位置,每次遍历到一个位置,先判断它是不是 'W' ,若是,则我们就可以看看它的周围8个位置是否也是 'W' ,若是,则将这两个位置都标记到一个集合中。
优化:遍历到一个为 'W' 的位置时,我们可以不需要将8个位置度判断一个,其实只需要判断 4 个位置即可(可以是 左下,下,右下,右)。
所以这道题就是需要遍历整个矩阵,每次遇到一个水坑时,就把这个水坑的右、下,左下以及右下的水坑合并在⼀起。
代码实现:
cpp
#include <iostream>
using namespace std;
const int N = 110;
int n, m;
char arr[N][N];
int fa[N * N];
// 方向数组
int dx[4] = {1, 1, 1, 0};
int dy[4] = {-1, 0, 1, 1};
int find(int x)
{
if(fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
void un(int x, int y)
{
int fx = find(x);
int fy = find(y);
fa[fx] = fy;
}
bool issame(int x, int y)
{
return find(x) == find(y);
}
int main()
{
cin >> n >> m;
for(int i = 0; i < n; i++)
{
for(int j = 0; j < m; j++)
{
cin >> arr[i][j];
int x = i * m + j;
fa[x] = x; // 并查集初始化
}
}
// 合并连在一起的w
for(int i = 0; i < n; i++)
{
for(int j = 0; j < m; j++)
{
if(arr[i][j] != 'W') continue;
int x = i * m + j; // 转为一维
for(int k = 0; k < 4; k++)
{
int a = i + dx[k], b = j + dy[k];
if(a < 0 || a >= n || b < 0 || b >= m) continue;
if(arr[a][b] == 'W')
{
// 转为一维
int y = a * m + b;
un(x, y);
}
}
}
}
// 统计结果
int ret = 0;
for(int i = 0; i < m * n; i++)
{
// 只统计W的位置
int x = i / m, y = i % m;
if(arr[x][y] == 'W')
{
if(fa[i] == i) ret++;
}
}
cout << ret << endl;
return 0;
}4. P1955 程序自动分析 - 洛谷
题目链接:P1955 NOI2015 程序自动分析 - 洛谷
问题内容: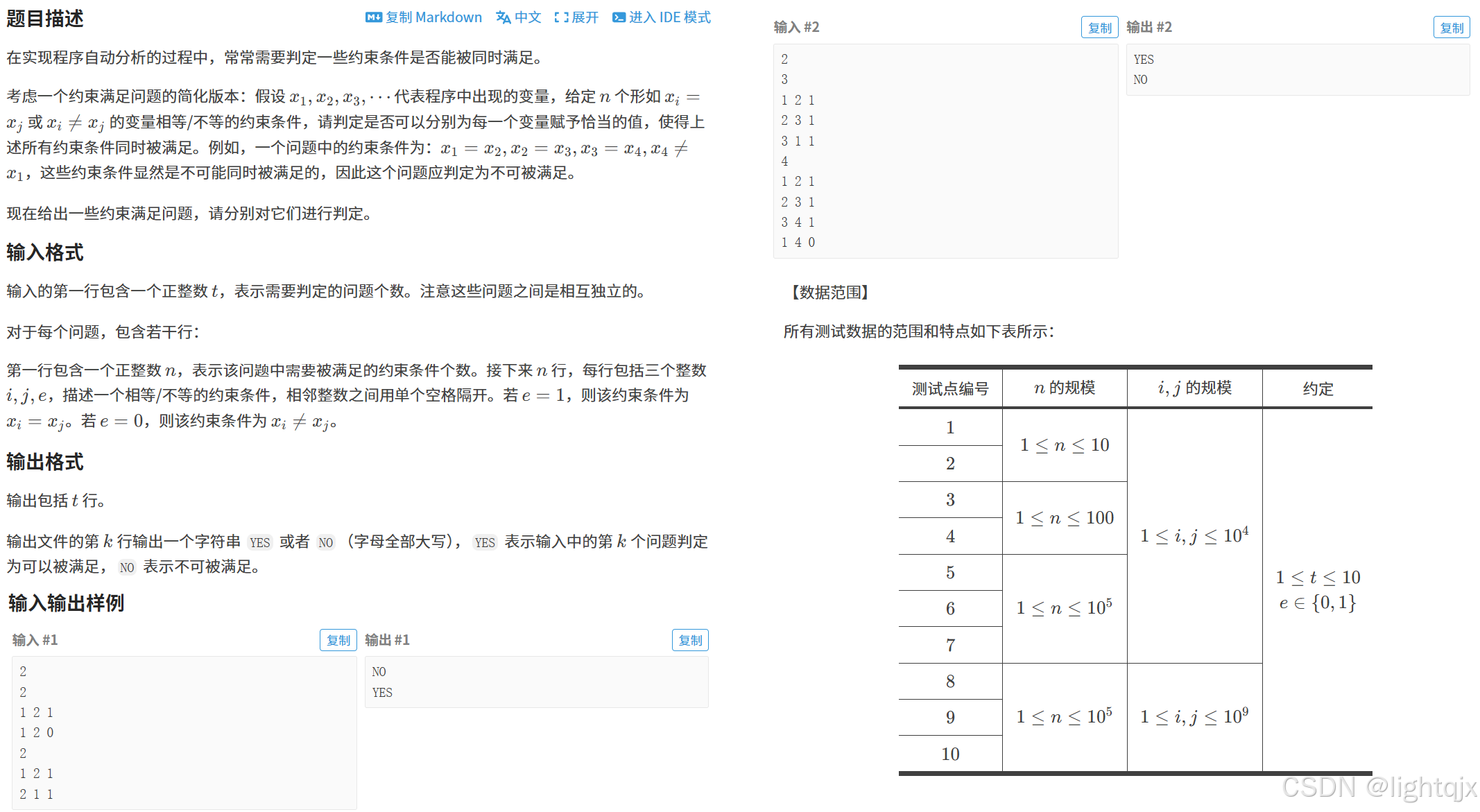
解决方法:这道题的意思就是给出一组约束条件,让你判断这个条件成不成立。我们的解题思路就是:
- 先处理所有的相等的条件,如果相等则将它们都放在同一个集合中,即并查集的合并;
- 然后再出来所有不相等的条件,判断不相等的数在不在同一个集合中,如果在同一个集合中,则这两个数既满足相等又满足不相等,就矛盾了,说明当前这组约束条件不满足。就输出 NO;
- 处理完所有条件,如果都满足,则就输出 YES。
优化:因为这里的约束条件中的 i 和 j 数据范围比较大,而约束条件个数比较小,空间消耗太大了,所以我们这里就可以使用【离散化】的思想将输入的 i 和 j 都映射成一个较小的数,然后再来进行并查集操作。
代码实现如下:
cpp
#include <iostream>
#include <unordered_map>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10;
int t; // 多组数据测试
int n;
struct node
{
int x, y, e;
}a[N];
int pos; // 标记当前元素
int disc[N * 2]; // 帮助离散化
unordered_map<int, int> id; // <原始的值, 离散化之后的值>
int fa[N * 2]; // 维护并查集
int find(int x)
{
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y)
{
int fx = find(x), fy = find(y);
fa[fx] = fy;
}
bool issame(int x, int y)
{
return find(x) == find(y);
}
bool solve()
{
// 对于每组数据操作前都要清空数据
pos = 0;
id.clear();
cin >> n; // n个约束条件
for(int i = 1; i <= n; i++)
{
cin >> a[i].x >> a[i].y >> a[i].e;
disc[++pos] = a[i].x;
disc[++pos] = a[i].y;
}
// 离散化
sort(disc + 1, disc + 1 + pos);
int cnt = 0; // 标记去重后的数据个数
for(int i = 1; i <= pos; i++)
{
int x = disc[i];
if(id.count(x)) continue;
cnt++;
id[x] = cnt;
}
// 维护并查集
for(int i = 1; i <= cnt; i++) fa[i] = i; // 初始化
// 处理所有相等的信息
for(int i = 1; i <= n; i++)
{
int x = a[i].x, y = a[i].y, e = a[i].e;
if(e == 1) un(id[x], id[y]); // 合并
}
// 处理所有不相等的信息,判断是否合法
for(int i = 1; i <= n; i++)
{
int x = a[i].x, y = a[i].y, e = a[i].e;
if(e == 0)
{
if(issame(id[x], id[y])) return false;
}
}
return true;
}
int main()
{
cin >> t;
while(t--)
{
if(solve()) cout << "YES" << endl;
else cout << "NO" << endl;
}
return 0;
}感谢各位观看!希望大家多多支持!