目录
[1. 检查 MTU 限制:](#1. 检查 MTU 限制:)
[2. 分割数据报:](#2. 分割数据报:)
[3. 添加 IP 头部:](#3. 添加 IP 头部:)
[4. 发送分片:](#4. 发送分片:)
[1. 接收分片:](#1. 接收分片:)
[2. 排序与组装:](#2. 排序与组装:)
[3. 传递给上层协议:](#3. 传递给上层协议:)
[1. 分片过程](#1. 分片过程)
[2. 组装过程(接收方)](#2. 组装过程(接收方))
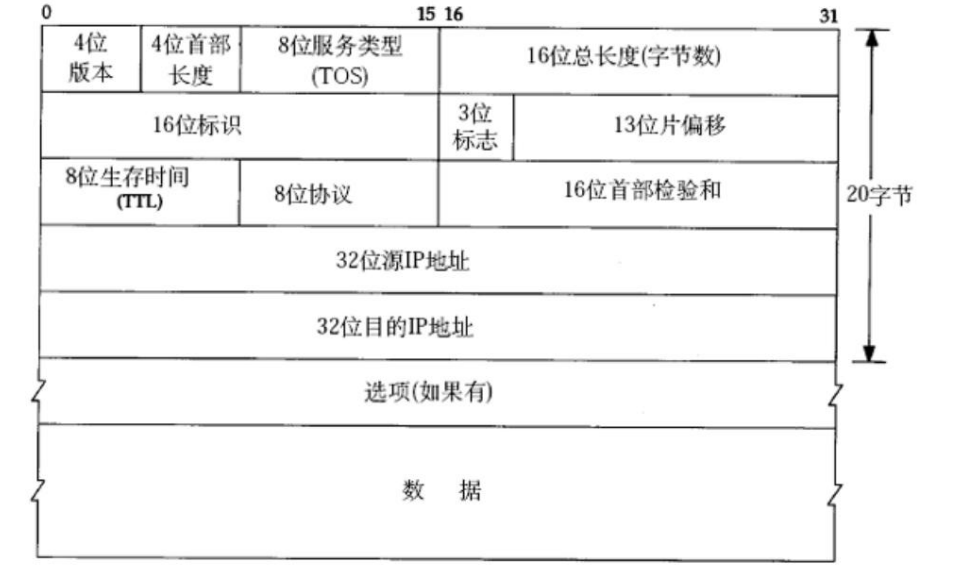
• 16 位标识(id): 唯一的标识主机发送的报文. 如果 IP 报文在数据链路层被分片 了, 那么每一个片里面的这个 id 都是相同的.
• 3 位标志字段: 第一位保留(保留的意思是现在不用, 但是还没想好说不定以后要 用到). 第二位置为 1 表示禁止分片, 这时候如果报文长度超过 MTU, IP 模块就会丢 弃报文. 第三位表示"更多分片", 如果分片了的话, 最后一个分片置为 0, 其他是 1. 类 似于一个结束标记.
• 13 位分片偏移(framegament offset): 是分片相对于原始 IP 报文开始处的偏移. 其实就是在表示当前分片在原报文中处在哪个位置. 实际偏移的字节数是这个值 除 以 8 得到的. 因此, 除了最后一个报文之外(之前如果都是 8 的整数倍,最后一片的 偏移量也一定是 8 的整数倍), 其他报文的长度必须是 8 的整数倍(否则报文就不连续 了).
• 注意:片偏移(13 位)表示本片数据在它所属的原始数据报数据区中的偏移量 (以 8 字节为单位)
分片与组装的过程
分片
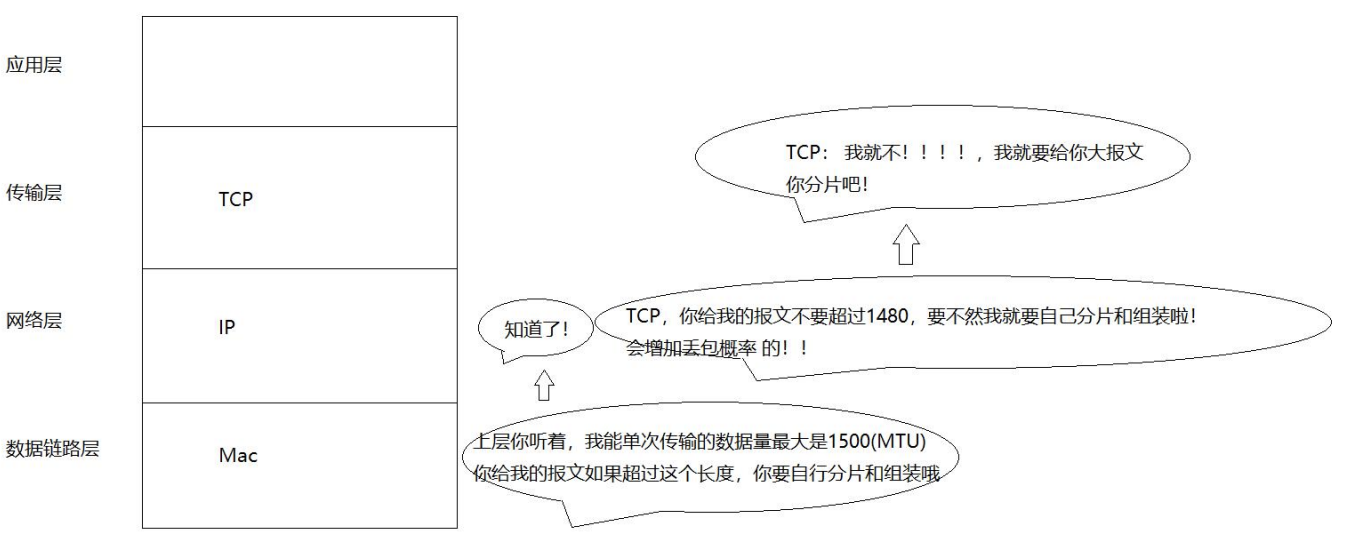
1. 检查 MTU 限制:
○ 当一个 IP 数据报的大小超过了网络的 MTU(最大传输单元)限制时,就需 要进行分片。MTU 是数据链路层对 IP 层数据包进行封装时所能接受的最大数据 长度。
2. 分割数据报:
○ IP 层将原始的 IP 数据报分割成多个较小的片段。
○ 对于每个片段,IP 层会设置相应的标识(Identification)、偏移量 (Fragment Offset)和标志位(Flags)等字段。
○ 标识字段用于标识属于同一个数据报的不同分片,确保所有分片能够被正确 地重新组装。
○ 偏移量字段指示了当前分片相对于原始数据报的起始位置,以 8 字节为单 位。
○ 标志位字段包含了 3 个位,其中 MF(More Fragment)位用于指示是否还 有更多的分片,DF(Do Not Fragment)位用于指示数据报是否允许进行分片。
3. 添加 IP 头部:
○ 每个分片都会加上自己的 IP 头部,与完整 IP 报文拥有类似的 IP 头结构,但 MF 和 Fragment Offset 等字段的值会有所不同。
4. 发送分片:
○ 分片在传输过程中独立传输,每个分片都有自己的 IP 头部,并且各自独立 地选择路由。
组装
1. 接收分片:
○ 当目的主机的 IP 层接收到这些分片后,会根据标识字段将属于同一个数据 报的所有分片挑选出来。
2. 排序与组装:
○ 利用片偏移字段,IP 层会对属于同一个数据报的分片进行排序。
○ 当所有的分片都到达并正确排序后,IP 层会将这些分片重新组装成一个完整 的 IP 数据报。
3. 传递给上层协议:
○ 组装好的 IP 数据报会传递给上层的协议进行处理。
注意:
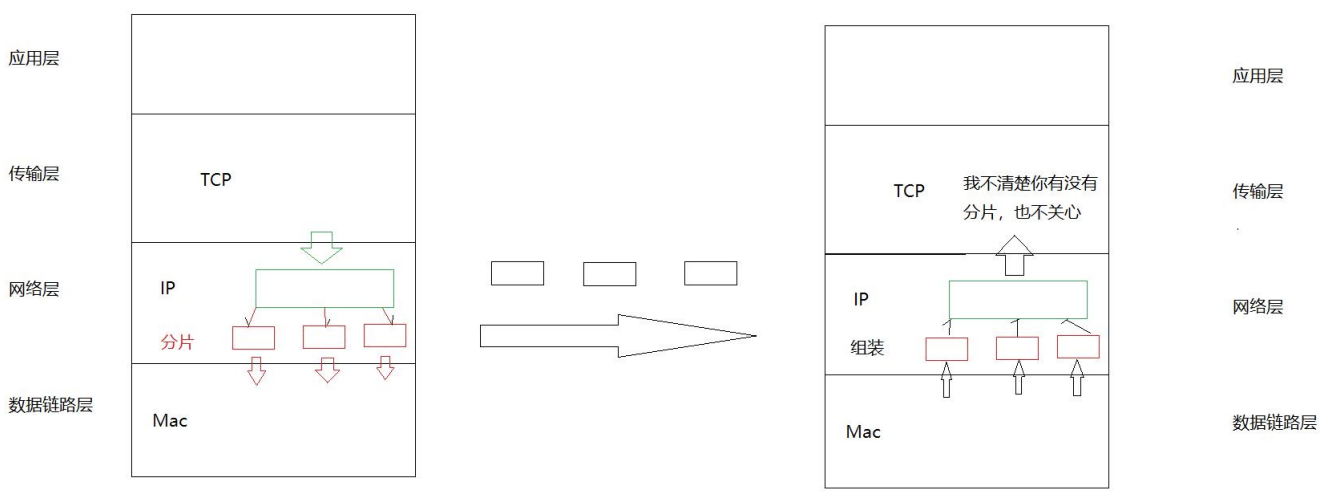
• IP 分片对传输层是透明的,这意味着传输层无需关心数据是否被分片以及如何 重新组装。
• 接收方如何得知自己收到的报文分片了?
IP数据报头部中有三个关键字段帮助判断:
标志位(Flags)中的MF(More Fragments)位
若
MF=1,表示当前分片之后还有更多分片。片偏移(Fragment Offset)字段
若
片偏移 > 0,表示当前分片不是原始报文的第一个分片。总长度(Total Length)字段
结合IP头部的"总长度"与"片偏移",也可间接判断。
结论 :只要收到一个IP包满足
MF=1或者片偏移 > 0,就说明它是一个分片(且该报文被分片了)。(第一个分片片偏移=0但MF=1;最后一个分片MF=0但片偏移>0;中间的分片两者都满足)
• 接收方如何得知自己收到的分片收全了?
接收方对**相同标识符(Identification)**的所有分片进行重组,判断是否收全的条件是:
收到了一个
MF=0的分片(即最后一个分片);并且该分片的片偏移 + 数据长度,恰好等于从第一个分片推导出的原始数据报总长度(或等于所有已收分片的数据总长度)。
在实际实现中,重组过程会维护一个重组缓冲区 ,持续接收同一标识符的分片。当遇到
MF=0的分片时,检查它结束位置是否覆盖了所有数据范围。如果覆盖完整,则重组成功;否则,可能丢失中间分片。另外,IP协议还设计了重组超时定时器(通常几十秒):如果定时器到期仍未收齐全部分片,则丢弃已收到的分片,并向源端发送ICMP超时消息(类型11,代码1)。
• 接收方如何组合形成完整的报文?
组合过程如下(以IPv4为例):
根据标识符(Identification)分类
接收方从接收到的IP包中提取
标识符字段,将相同标识符的分片归到同一个重组任务。按片偏移排序
每个分片的
片偏移字段指示了该分片的数据在原始数据报中的起始位置(以8字节为单位)。接收方将这些分片按片偏移从小到大的顺序排列。拼接数据
从第一个分片(片偏移=0)开始,依次取出每个分片的数据部分,按照片偏移的顺序放入一个连续的缓冲区中。
第一个分片可能(但不必)包含IP头部的选项,但重组时只提取数据部分。
后续分片只包含数据,不包含原始IP头部。
去除分片头部
每个分片都有自己的IP头部(20字节+选项),重组后的数据报只需要保留第一个分片的IP头部(或重建一个简化的头部),然后修改
总长度、清除分片相关标志(MF=0,片偏移=0),更新头部校验和。交付上层协议
完整IP数据报重组后,根据头部中的协议字段(如6=TCP,17=UDP),交给相应的传输层模块处理。传输层完全感知不到曾经发生过IP分片。
简化的例子
假设一个1480字节的UDP报文(数据部分1460字节+UDP头8字节)需要经过一个MTU=1000的链路。
-
原始IP数据报总长度 = 1480 + 20(IP头)= 1500字节
-
分片1:IP头+前980字节数据,MF=1,片偏移=0
-
分片2:IP头+后500字节数据,MF=0,片偏移=980/8=122.5?不对,片偏移单位是8字节,980不是8的倍数?实际IP分片要求每片数据长度是8字节的整数倍(除了最后一片)。这里为简化,假设合理分片。
接收方收到分片1(MF=1)、分片2(MF=0,片偏移=122):
-
分片1数据长度=960字节(必须8倍数,假设),分片2数据长度=500字节(不足8倍数也可)。
-
计算分片2结束位置 = 片偏移×8 + 分片2数据长度 = 122×8 + 500 = 976 + 500 = 1476字节
-
原始数据报总数据长度应为1476字节(不含IP头)。第一个分片偏移0,数据960字节。
-
检查:960 + 500 = 1460?不对,需要精确对齐,实际例子中会严格保证。
关键是,接收方通过排序和拼接,就能恢复出原始数据。
分片与组装过程的示意图
分片组装场景

分片组装过程
• 假设在 IP 层,有一个大小为 3000 字节的报文,如何分片?如何组装呢
1. 分片过程
-
每个分片包含自己的 IP 头部(20 字节)。
-
每个分片携带的数据部分必须是 8 字节的整数倍(除了最后一个分片)。
-
每个分片的最大数据量 = MTU - IP头部 = 1500 - 20 = 1480 字节(正好是 8 的倍数)。
分片结果:
| 分片 | 数据部分偏移(原始数据中的起始字节) | 数据长度 | IP 头部总长度 | MF 标志 | 片偏移(单位:8 字节) | 计算 |
|---|---|---|---|---|---|---|
| 1 | 0 | 1480 | 1500 | 1 | 0 | 1480/8=185 |
| 2 | 1480 | 1480 | 1500 | 1 | 185 | (1480+1480)/8=370? 不对,第二片的片偏移=1480/8=185 |
| 3 | 2960 | 20 | 40 | 0 | 370 | 2960/8=370 |
说明:
-
原始数据总长 = 2980 字节。
-
第一片:携带数据 0, 1479(共 1480 字节),IP 报头总长度 = 1500,MF=1,片偏移=0。
-
第二片:携带数据 1480, 2959(共 1480 字节),IP 报头总长度 = 1500,MF=1,片偏移=185(因为 1480 ÷ 8 = 185)。
-
第三片:携带数据 2960, 2979(共 20 字节),IP 报头总长度 = 40,MF=0,片偏移=370(因为 2960 ÷ 8 = 370)。
2. 组装过程(接收方)
接收方可能收到乱序的分片,例如顺序是:分片2、分片1、分片3。
步骤 1:识别属于同一原始数据报的分片
根据 IP 头中的 源 IP、目的 IP、协议、标识符 四个字段将分片归类。此处假设所有分片的标识符(Identification)相同(如 0x1234)。
步骤 2:按片偏移排序
收到的分片信息:
| 分片 | 片偏移 | MF | 数据长度 |
|---|---|---|---|
| 2 | 185 | 1 | 1480 |
| 1 | 0 | 1 | 1480 |
| 3 | 370 | 0 | 20 |
排序后:
| 分片 | 片偏移 | MF | 数据长度 | 起始字节 | 结束字节(不含) |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 1480 | 0 | 1480 |
| 2 | 185 | 1 | 1480 | 1480 | 2960 |
| 3 | 370 | 0 | 20 | 2960 | 2980 |
步骤 3:检查是否收全
-
最后一个分片的 MF=0,其结束位置 = 片偏移 × 8 + 数据长度 = 370×8 + 20 = 2960 + 20 = 2980 字节。
-
这正好等于原始数据总长度(所有分片数据之和)。
-
收全条件满足。
步骤 4:重组数据
创建一个 2980 字节的缓冲区,按顺序复制:
-
复制分片1 的数据(1480 字节)到缓冲区 0, 1479。
-
复制分片2 的数据(1480 字节)到缓冲区 1480, 2959。
-
复制分片3 的数据(20 字节) 到缓冲区 2960, 2979。
步骤 5:构建完整的 IP 数据报
-
取出第一个分片的 IP 头部(或重建一个),将其中的 总长度 修改为 3000(20 头部 + 2980 数据)。
-
清除分片标志:MF=0,片偏移=0。
-
重新计算 IP 头部校验和。
-
将重组后的数据附加到头部后面。
这样就得到了一个完整的 3000 字节 IP 数据报,可以交付给上层协议(如 TCP/UDP)。
注意:
-
如果某个分片丢失(例如一直没收到 MF=0 的分片),接收方会启动一个重组超时定时器(典型值 30 秒)。超时后丢弃已收到的分片,并可能发送 ICMP 超时 消息(类型 11,代码 1)。
-
传输层(TCP/UDP)完全感知不到分片的存在 ------ 它们收到的就是已经组装好的完整报文。