目录
1.摘要
针对存在多优先级任务节点与静态障碍物的大规模智能体场景,本文提出了一种基于双层耦合平均场博弈(MFG)的集成任务分配与轨迹规划,该框架创新性地将轨迹规划的最小代价引入任务分配中,利用多群体MFG规划任务节点间的智能体最优轨迹并计算其代价,进而基于离散时间有限状态空间MFG在离散空间内实现兼顾全局最优与精准调节的任务分配。
2.问题描述
场景描述
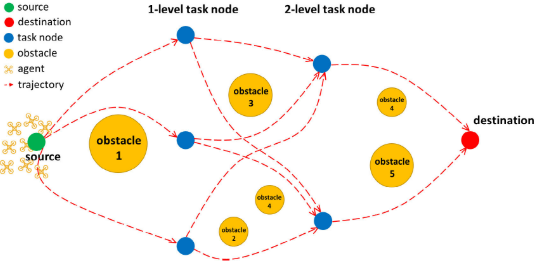
本文在限定时段 t 0 , t f t_0,t_f t0,tf内、包含多静态障碍物及多优先级任务节点的大规模智能体 (数量 N → ∞ ) N\to\infty) N→∞)集成任务分配与轨迹规划问题。智能体从起点出发,历经按重要程度划分为 K K K 个等级的离散任务节点集,最终抵达终点(节点 M M M)。在时间序列 T T T上,智能体于 t 0 t_{0} t0时刻在起点规划未来路径,并在各阶段时段 t k , t k + 1 t_k,t_{k+1} tk,tk+1内决策出避障的最优轨迹。
单智能体决策
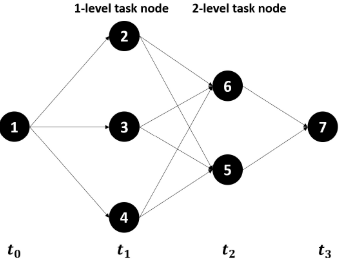
在轨迹规划中,智能体 n n n_n nn在时段 t k , t k + 1 t_k,t_{k+1} tk,tk+1内的动作和状态分别受限于闭凸集 U U U和有界空间 S S S,并考虑环境干扰与系统误差,其动态特征由如下线性随机微分方程描述:
d s n ( t ) = ( A s n ( t ) + B u n ( t ) ) d t + D d ω n ( t ) ds_n(t)=(As_n(t)+Bu_n(t))dt+Dd\omega_n(t) dsn(t)=(Asn(t)+Bun(t))dt+Ddωn(t)
在任务分配中,依据任务层级构建有向图 G G G ,智能体在 t k t_k tk 时刻所处节点为当前状态,其决策策略为向下一层级节点的转移概率 P n , t k i j P_{n,t_k}^{ij} Pn,tkij(当 j ∉ O U T ( i ) j\notin OUT(i) j∈/OUT(i) 时概率为0),该策略构成了概率单纯形空间 P \mathcal{P} P。
问题陈述
将ITATP问题转化为博弈问题,通过个体代价最小化协同大规模智能体行为。
轨迹规划目标 智能体在相邻层级节点间寻优以最小化能耗并规避障碍物与其他智能体。在时段 t k , t k + 1 t_k,t_{k+1} tk,tk+1内的博弈优化模型为:
min u n ∈ U J ( s n , s − n , u n , t k ) \min_{u_n\in U}J(s_n,s_{-n},u_n,t_k) un∈UminJ(sn,s−n,un,tk)
d s n ( t ) = ( A s n ( t ) + B u n ( t ) ) d t + D d ω n ( t ) ds_n( t) = ( As_n( t) + Bu_n( t) ) dt+ Dd\omega n( t) dsn(t)=(Asn(t)+Bun(t))dt+Ddωn(t), s n ( t k ) = s t k s_n( t_k) = s{t_k} sn(tk)=stk
任务分配目标 智能体综合考虑最优轨迹代价集 J ∗ J^* J∗、节点需求量 J L J_L JL及群体影响 ϕ − n \phi_{-n} ϕ−n,决策离散时段的节点选择策略序列 { P n , t k } \left\{P_{n,t_k}\right\} {Pn,tk}。博弈优化模型为:
min { P n , t k } t k ∈ T V n ( J ∗ , J L , ϕ − n , { P n , t k } t k ∈ T , G n , t f ) \min_{\{P_{n,t_k}\}{t_k\in T}}V_n(J^*,J_L,\phi{-n},\{P_{n,t_k}\}{t_k\in T},G{n,t_f}) {Pn,tk}tk∈TminVn(J∗,JL,ϕ−n,{Pn,tk}tk∈T,Gn,tf)
s.t. P n , t k i j ≥ 0 , ∑ j ∈ O U T ( i ) P n , t k i j = 1 , ∑ n = 1 N φ n , t k j ≥ 1 \text{s.t. }P_{n,t_k}^{ij}\geq0,\sum_{j\in OUT(i)}P_{n,t_k}^{ij}=1,\sum_{n=1}^N\varphi_{n,t_k}^j\geq1 s.t. Pn,tkij≥0,j∈OUT(i)∑Pn,tkij=1,n=1∑Nφn,tkj≥1
3.双层耦合平均场博弈
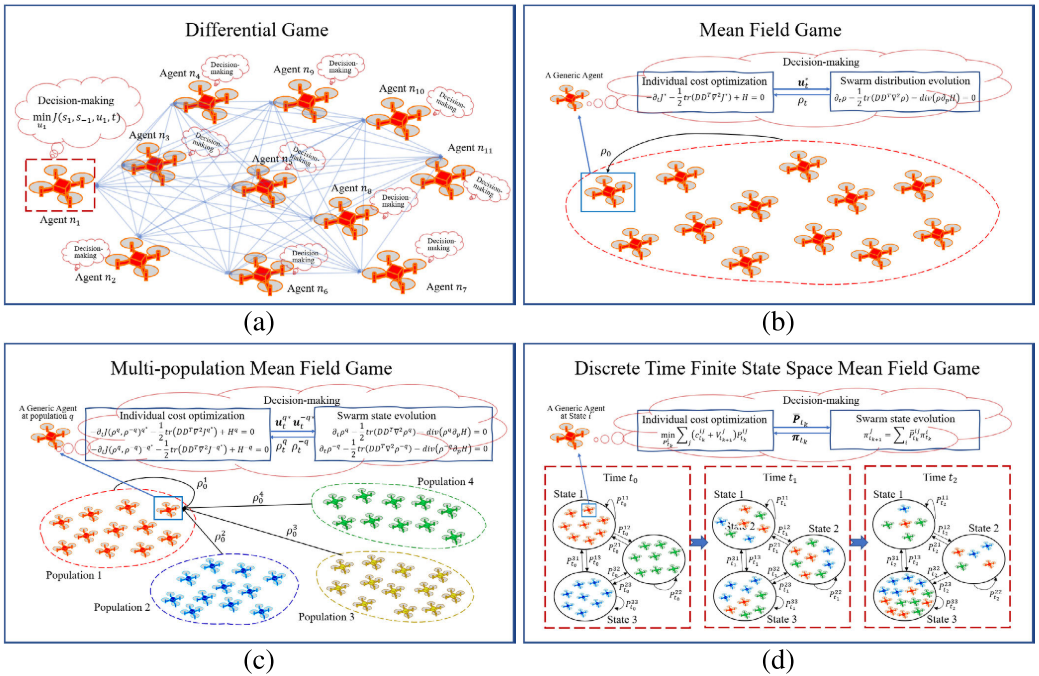
平均场博弈模型(MFG)
针对大规模同质博弈者导致的计算爆炸问题,MFG将个体间博弈转化为个体与群体状态分布的博弈。初始分布由狄拉克函数 δ \delta δ近似表示:
m 0 = 1 N ∑ n = 1 N δ s n ( t 0 ) m_0=\frac1N\sum_{n=1}^N\delta_{s_n(t_0)} m0=N1n=1∑Nδsn(t0)
多群体平均场博弈(MPMFG)用于处理存在多个不同集群的场景,个体决策时需同时兼顾本集群及其他集群的状态分布影响。
离散时间有限状态空间平均场博弈(DTFSSMFG)适用于离散时间决策与有限状态演化场景,个体的策略表现为状态间的转移概率,决策受各状态上智能体数量分布的影响。
多群体平均场博弈(MPMFG)轨迹规划
MPMFG轨迹规划问题转化为代表性智能体在 Q Q Q个分流与聚合子群体中的控制寻优。通过最小化包含能耗、避障及终端导向的综合代价泛函:
min u q ∈ U J ( s q , ρ q , ρ − q , u q , t k ) = E ∫ t k t k + 1 F ( s q , ρ q , ρ − q , u q , t ) d t + G ( s q ( t k + 1 ) ) \min_{u_q\in U}J(s_q,\rho_q,\rho_{-q},u_q,t_k)=\mathbb{E}\left\\int_{t_k}\^{t_{k+1}}F(s_q,\\rho_q,\\rho_{-q},u_q,t)dt+G(s_q(t_{k+1}))\\right uq∈UminJ(sq,ρq,ρ−q,uq,tk)=E∫tktk+1F(sq,ρq,ρ−q,uq,t)dt+G(sq(tk+1))
基于动态规划原理和 Legendre 变换定义 Hamilton 函数:
H ( s q , p q , ρ q , ρ − q , u q , t ) = max u q ∈ U { − A s q ( t ) + B u q ( t ) T p q − F ( s q , ρ q , ρ − q , u q , H(s_q,p_q,\rho_q,\rho_{-q},u_q,t)=\max_{u_q\in U}\{-As_q(t)+Bu_q(t)^Tp_q-F(s_q,\rho_q,\rho_{-q},u_q, H(sq,pq,ρq,ρ−q,uq,t)=uq∈Umax{−Asq(t)+Buq(t)Tpq−F(sq,ρq,ρ−q,uq,
离散时间有限状态空间平均场博弈(DTFSSMFG)任务分配
智能体在节点 i i i 的转移代价 c t k i j c_{t_k}^{ij} ctkij 由两部分耦合而成:
轨迹代价直接耦合 MPFMG 优化结果:
c t k i j ( 1 ) = α 1 min u ∈ U E ∫ t k t k + 1 F ( s , ρ i j , ρ − i j , u , t ) d t + G ( s ( t k + 1 ) ) c_{t_k}^{ij(1)} = \alpha_1 \min_{u \in U} \mathbb{E} \left \\int_{t_k}\^{t_{k+1}} F(s, \\rho_{ij}, \\rho_{-ij}, u, t) dt + G(s(t_{k+1})) \\right ctkij(1)=α1u∈UminE∫tktk+1F(s,ρij,ρ−ij,u,t)dt+G(s(tk+1))
需求代引入群体分布 π t k \pi_{t_k} πtk 函数 c t k i j ( 2 ) ( π t k , P t k i ) c_{t_k}^{ij(2)}(\pi_{t_k}, P_{t_k}^i) ctkij(2)(πtk,Ptki),用以调节节点覆盖率与智能体数量。
依据动态规划原理,单个智能体通过求解以下约束优化问题来决定最优策略:
min P t k i ∈ P ∑ j ∈ O U T ( i ) ( c t k i j + V t k + 1 j ) P t k i j \min_{P_{t_k}^i \in \mathcal{P}} \sum_{j \in OUT(i)} (c_{t_k}^{ij} + V_{t_{k+1}}^j) P_{t_k}^{ij} Ptki∈Pminj∈OUT(i)∑(ctkij+Vtk+1j)Ptkij
s.t. P t k i j ≥ 0 P_{t_k}^{ij} \geq 0 Ptkij≥0, ∑ j ∈ O U T ( i ) P t k i j = 1 \sum_{j \in OUT(i)} P_{t_k}^{ij} = 1 ∑j∈OUT(i)Ptkij=1, ∑ j ∉ O U T ( i ) P t k i j = 0 \sum_{j \notin OUT(i)} P_{t_k}^{ij} = 0 ∑j∈/OUT(i)Ptkij=0
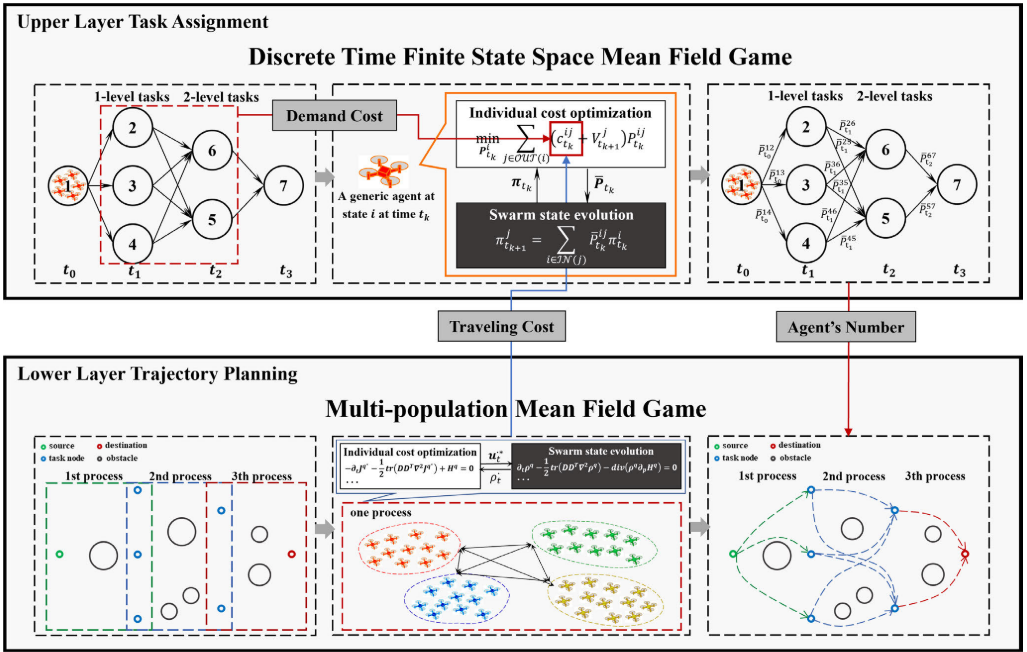
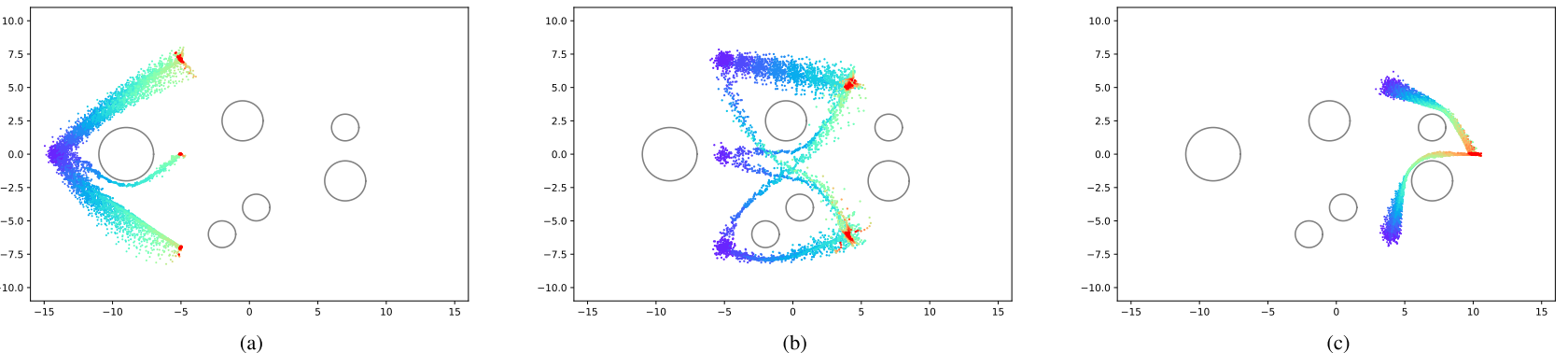
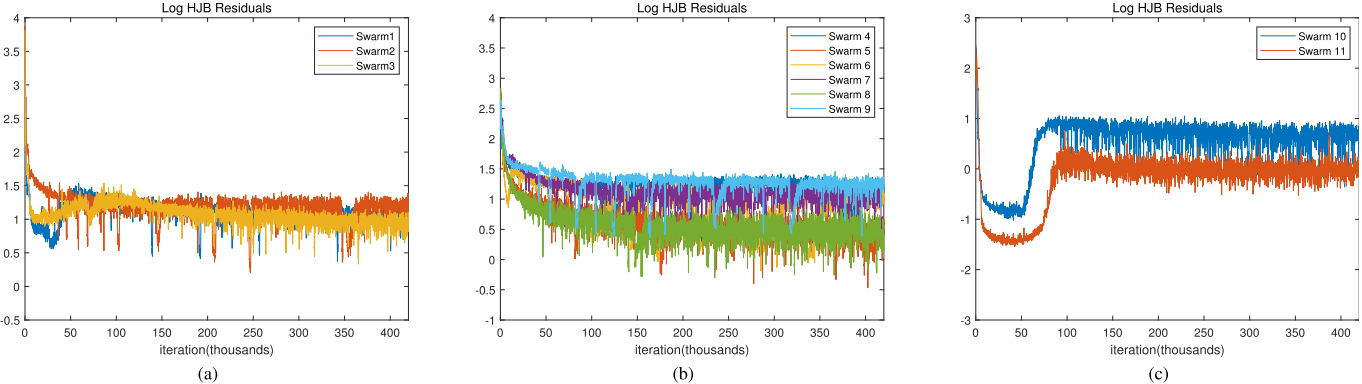
4.论文结果
5.参考文献
Niu Z, Yao W, Jin Y, et al. Integrated task assignment and trajectory planning for a massive number of agents based on bilayer-coupled mean field gamesJ. IEEE Transactions on Automation Science and Engineering, 2024, 22: 1833-1852.
6.算法辅导·应用定制·读者交流
xx