📖标题:AtlasVA: Self-Evolving Visual Skill Memory for Teacher-Free VLM Agents
🌐来源:arXiv, 2605.17933v1
🛎️文章简介
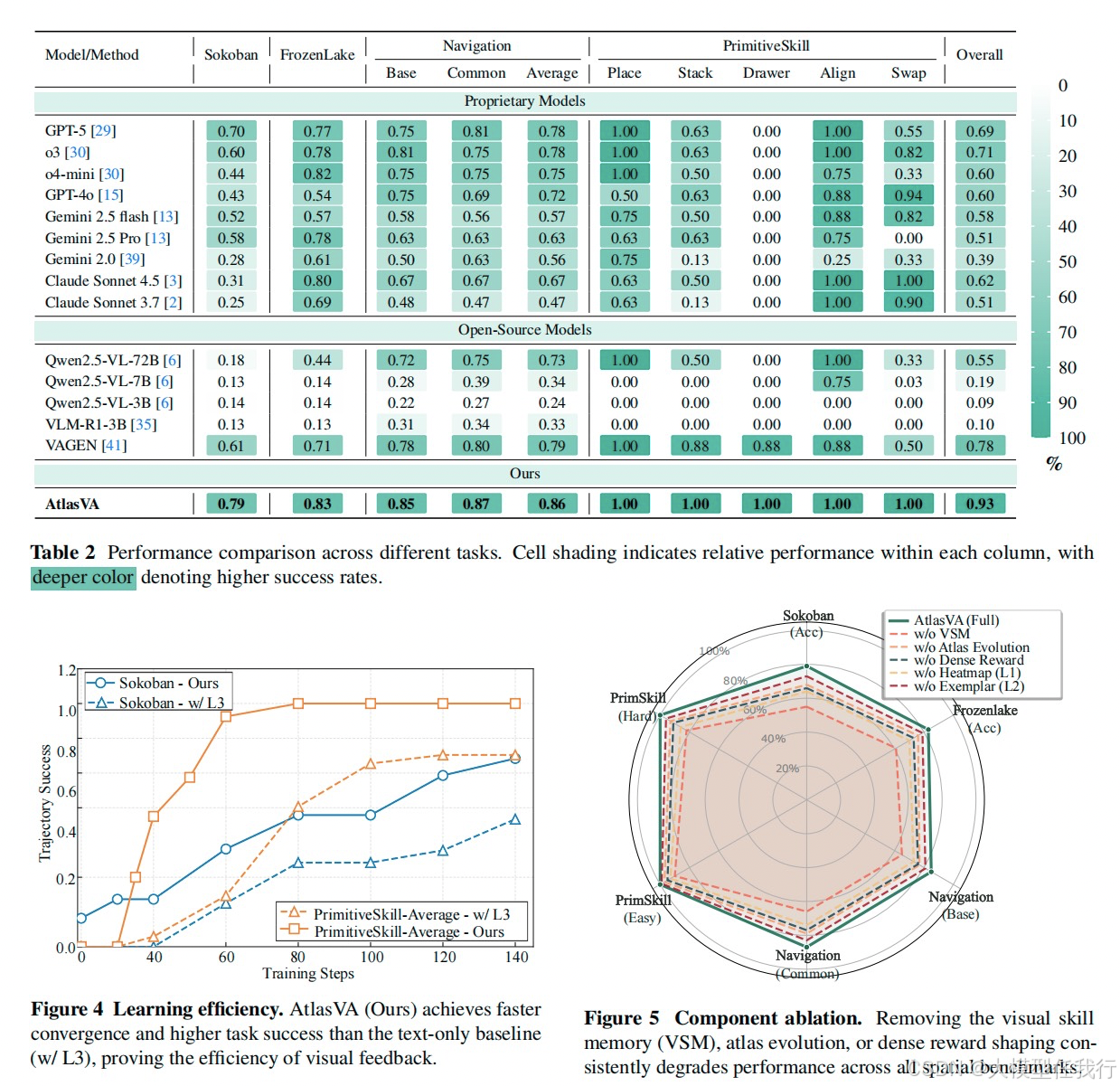
🔸研究问题:如何解决现有VLM代理依赖文本记忆导致空间信息丢失及依赖外部教师模型的问题?
🔸主要贡献:论文提出AtlasVA,一种无需教师模型的自进化视觉技能记忆框架,通过三层视觉记忆和密集视觉奖励塑造,显著提升VLM在空间任务中的性能。
📝重点思路
🔸构建三层视觉技能记忆(VSM):包含空间热力图(危险与亲和度)、视觉范例(成功/失败截图)和符号文本技能,将经验保留在视觉模态中,避免文本压缩带来的几何结构丢失。
🔸实现无教师地图自进化机制:直接利用轨迹统计数据和轻量级网格启发式方法,通过指数移动平均(EMA)动态更新危险和亲和度热力图,无需外部LLM进行总结或修正,实现完全自主的知识积累。
🔸开发基于地图的密集视觉奖励塑造:将自进化的空间先验转化为势函数,计算每一步的亲和度增益和危险惩罚,为强化学习提供稠密且坐标感知的梯度信号,解决稀疏奖励下的信用分配难题。
🔸形成感知-优化闭环:改进的策略生成更高质量的轨迹,进而 refine 视觉地图,更准确的地图又提供更优的奖励信号,形成自我强化的训练循环。
🔎分析总结
🔸性能超越大模型:在Sokoban、FrozenLake、3D导航及机械臂操作基准测试中,仅用3B参数基座模型的AtlasVA平均成功率达0.93,显著优于GPT-5等更大规模的专有模型及开源基线。
🔸空间推理能力极强:在需要密集几何规划的任务中表现尤为突出,如Sokoban成功率从基线的0.14提升至0.79,证明视觉热力图能有效嵌入几何先验,克服纯文本表示的局限。
🔸加速收敛与样本效率:相比仅使用文本规则的基线,AtlasVA在训练初期即快速提升成功率,证实了密集视觉反馈能有效缓解长视野任务中的探索困难,大幅提高样本效率。
🔸组件有效性验证:消融实验显示,移除视觉记忆、地图进化或密集奖励均导致性能大幅下降,证明各层级互补性及无教师自进化机制的有效性,且视觉范例池的动态更新对维持上下文相关性至关重要。
💡个人观点
论文打破了VLM记忆必须文本化的思维定势,回归视觉本源。通过"热力图+范例"的原生视觉记忆,既保留了空间拓扑细节,又通过自进化机制摆脱了对昂贵教师模型的依赖。