RS-Claw & XSkill 深度分析
Part 1: RS-Claw (2605.13391) --- 层次化技能树驱动的RS Agent工具探索
1.1 核心动机
现有RS Agent采用被动工具选择范式:
| 范式 | 做法 | 问题 |
|---|---|---|
| Flat | 全量工具描述注入context | 长horizon任务context空间爆炸 (Earth-Bench 104工具消耗20k+ tokens) |
| RAG | 语义检索筛选工具子集 | 单次检索可能遗漏后续关键步骤所需工具 |
RS-Claw的核心论点 : Agent应该是工具空间中的主动探索者(active explorer),而非被动接收者。
1.2 架构
外链图片转存中...(img-y20mzhNs-1780756200497)
Figure 1: 左: 被动范式(Flat导致context溢出, RAG遗漏工具);右: RS-Claw的主动探索范式------通过层次化技能树实现推理与工具加载交错进行。
外链图片转存中...(img-q4ksAqJ2-1780756200498)
Figure 2: 整体框架。上部: 统一序贯决策建模,Agent从动作空间中自主选择action。下部: 沿技能树的渐进式信息展开(Progressive Disclosure)。
三层设计:
Layer 1 --- 统一序贯决策建模:
- 将RS agent任务求解建模为POMDP
- Agent的action space: 探索工具 ∪ 调用工具 ∪ 回答终止
- 关键: "探索工具"成为agent的内在action ------ agent主动决定何时展开哪部分工具树
Layer 2 --- 层次化技能树构建:
- 将RS工具语义封装为"Skill"(技能)
- 按领域专家知识组织为层次化树结构:
- L1: 技能分支摘要 (如: 图像预处理 → 光谱分析 → 目标检测 → ...)
- L2: 技能详细描述 + 参数规格
- 仅在被探索到时才加载详细信息
Layer 3 --- 渐进式信息展开策略:
- Agent首先读取L1摘要 → 选择相关技能分支
- 展开L2获取工具详细信息 → 调用执行
- 如需更多工具 → 回到L1继续探索
- 效果: context消耗从 O(N) → O(K), K<<N
1.3 实验设计
Benchmark: Earth-Bench (Earth-Agent的benchmark)
Baselines:
- Flat: 全量工具注册 (你的C1)
- RAG: retrieval-augmented工具选择 (你的C2)
消融:
- RS-Claw vs 2-layer-only (仅两层 vs 完整三层)
- 同域工具缩放 (same-domain tool scaling)
- 跨域工具缩放 (cross-domain tool scaling)
关键结果:
- Input token压缩率达86%
- Qwen3-32b AP模式下较Flat提升12.45%
- 在所有模型和评估模式上全面超越 Flat + RAG baselines
Part 2: XSkill (2603.12056) --- 多模态Agent的持续学习框架
2.1 核心动机
多模态Agent面临两个瓶颈:
- 低效的工具使用: 简单问题浪费过多步骤,复杂问题探索深度不够
- 僵化的工具编排: 单一执行路径,难以跨任务泛化
XSkill解决方案 : 双流知识框架 ------ Experiences (经验) + Skills(技能)
2.2 双流知识定义
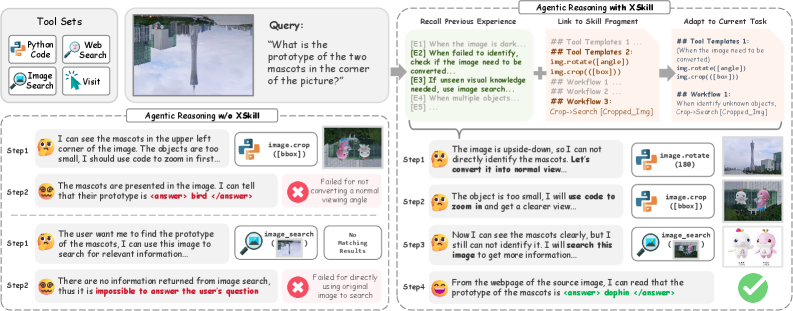
Figure 1: 左右对比。Baseline agent因visual-semantic gap失败(忽视倒置图像、未隔离小目标);XSkill检索相关经验和技能,生成视觉感知修正→裁剪→识别的正确执行计划。
Skills (技能) = 结构化任务级指导
- 定义: k = (ℳ, 𝒲, 𝒫) → 元数据 + 工作流序列 + 可复用工具模板
- 存储: 结构化Markdown文档
- 作用: 提供planning层级的workflow蓝图
Experiences (经验) = 简洁动作级指导
- 定义: e = (c, a, v) → 触发条件 + 推荐动作 + 语义嵌入
- 存储: JSON, 每条 ≤ L_max 词
- 作用: 提供action层级的战术知识(工具选择、错误恢复)
2.3 两阶段架构
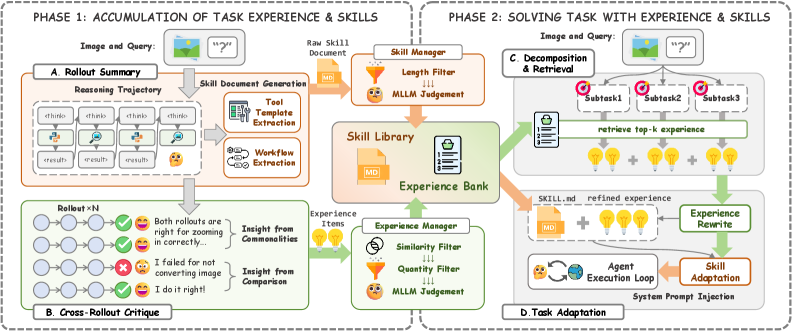
Figure 2: 两阶段框架。Phase I (积累): 从多路径rollout中蒸馏Skills + Experiences。Phase II (推理): 分解任务→检索→适配→注入。
Phase I: 知识积累
- Rollout Summary: MLLM对每个task做N次独立rollout,对轨迹做视觉感知摘要
- Cross-Rollout Critique: 对比成功/失败轨迹,找出因果因素
- Hierarchical Consolidation: 相似知识合并去重,超量时删除低质条目
Phase II: 推理执行
- Task Decomposition Retrieval: 将任务分解为子任务 → 每子任务独立检索相关经验
- Experience Rewrite: 将通用经验改写为当前视觉上下文相关的具体指导
- Skill Adaptation: 裁剪不相关章节、注入改写后的经验、调整代码模板
- Non-Prescriptive Injection: 作为参考而非强制执行
2.4 实验设计
5个Benchmark × 4个Backbone模型:
| Domain | Benchmark | 工具 |
|---|---|---|
| Visual Agentic Tool Use | VisualToolBench, TIR-Bench | Code, Search-W, Visit |
| Multimodal Search | MMSearch-Plus, MMBrowseComp | Code, Search-W, Search-I, Visit |
| Comprehensive | AgentVista | 全工具 |
Backbone: Gemini-2.5-Pro, Gemini-3-Flash, GPT-5-mini, o4-mini (+ open-source Qwen3-VL)
Baselines:
- No Tools: 纯MLLM
- w/ Tools: 有工具无经验积累
- AWM (Agent Workflow Memory): 从历史轨迹提取可复用workflow
- DC (Dynamic CheatSheet): 动态维护策略+代码片段memory
- Agent-KB: 跨域经验结构化知识库 + 混合检索
核心结果 (Table 2):
- Gemini-3-Flash上Average@4提升6.71pp (33.63 → 40.34)
- TIR-Bench上超越最强baseline Agent-KB 11.13pp
- GPT-5-mini和o4-mini使用Gemini-3-Flash积累的知识 → 跨模型迁移有效 (+2.58~4.16pp)
2.5 消融实验
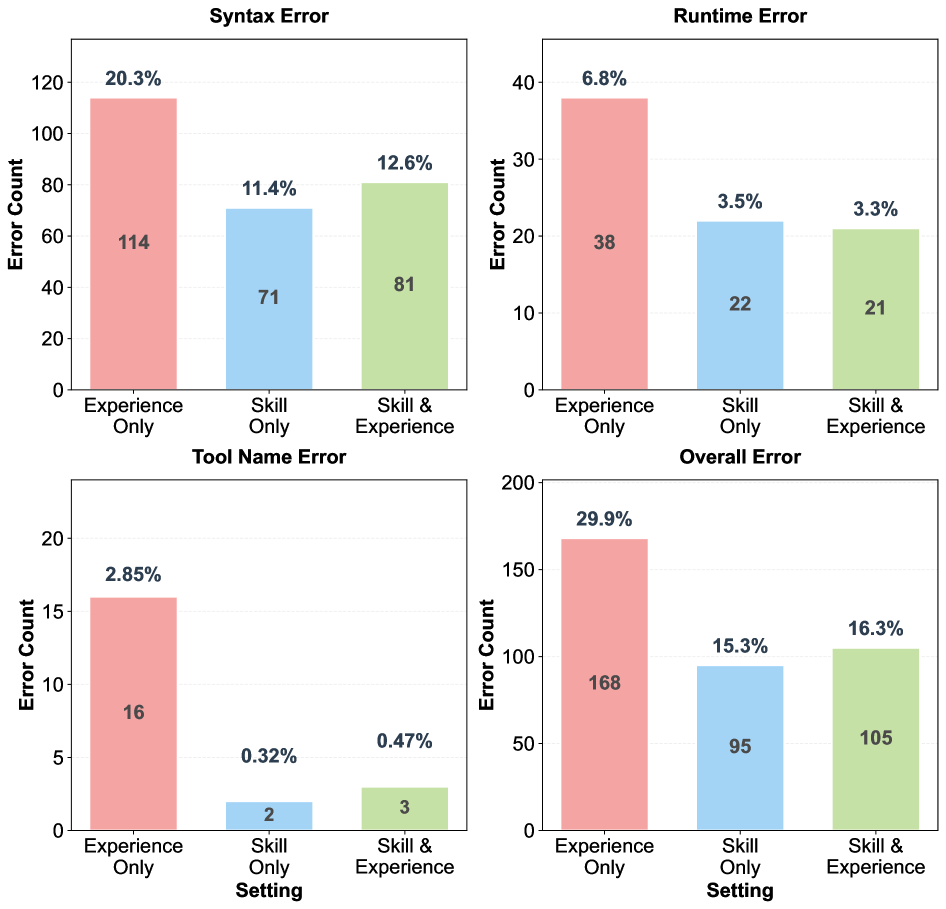
Figure 3: VisualToolBench错误分析。Skills显著降低语法错误(tool name 16→2, syntax 114→71)和运行时错误。
| 消融项 | Average@4 下降 | 说明 |
|---|---|---|
| 去掉Experiences | -3.04 | 动作级指导关键 |
| 去掉Skills | -3.85 | 任务级指导更关键 |
| 去掉Experience Manager (Phase1) | -4.09 | 积累质量 > 检索机制 |
| 去掉Skill Manager (Phase1) | -3.62 | 同上 |
| 去掉Task Decomposition (Phase2) | -1.28 | 检索优化 |
| 去掉Task Adaptation (Phase2) | -1.52 | 适配优化 |
关键结论: Phase 1 (知识积累质量) > Phase 2 (检索适配机制),但两者都必要。
2.6 交叉分析
Skills → 提升工具使用效率:
- 错误率: 29.9% → 15.3%
- Syntax errors: 114 → 71 (-38%)
- Tool name errors: 16 → 2 (-87.5%)
Experiences → 提升工具编排灵活性:
- VisualToolBench: Code interpreter使用 66.63% → 76.97%
- MMSearch-Plus: Image search使用 15.43% → 24.63%
Rollout数量N的影响 (Figure 4):
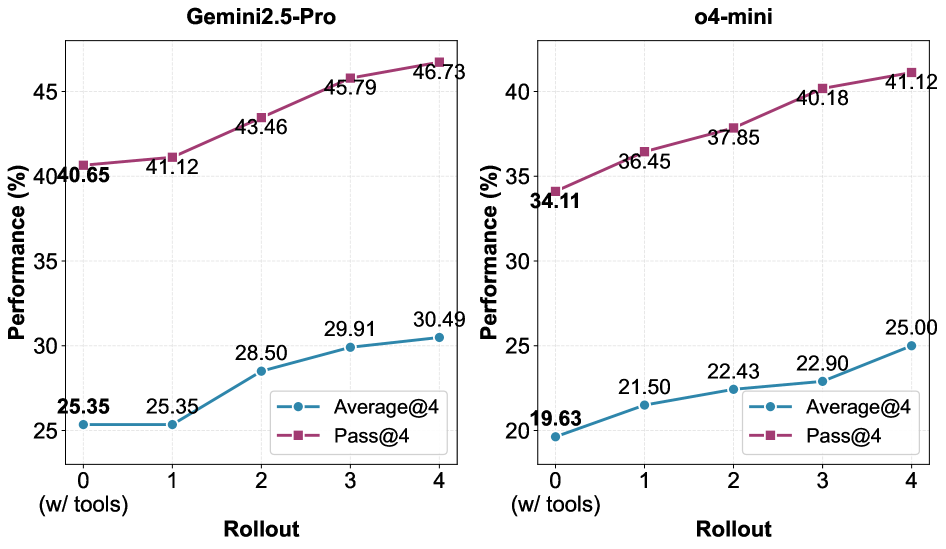
- N越大性能越好 (更多trajectory diversity → 更高质量知识)
跨任务零样本迁移 (Figure 5):
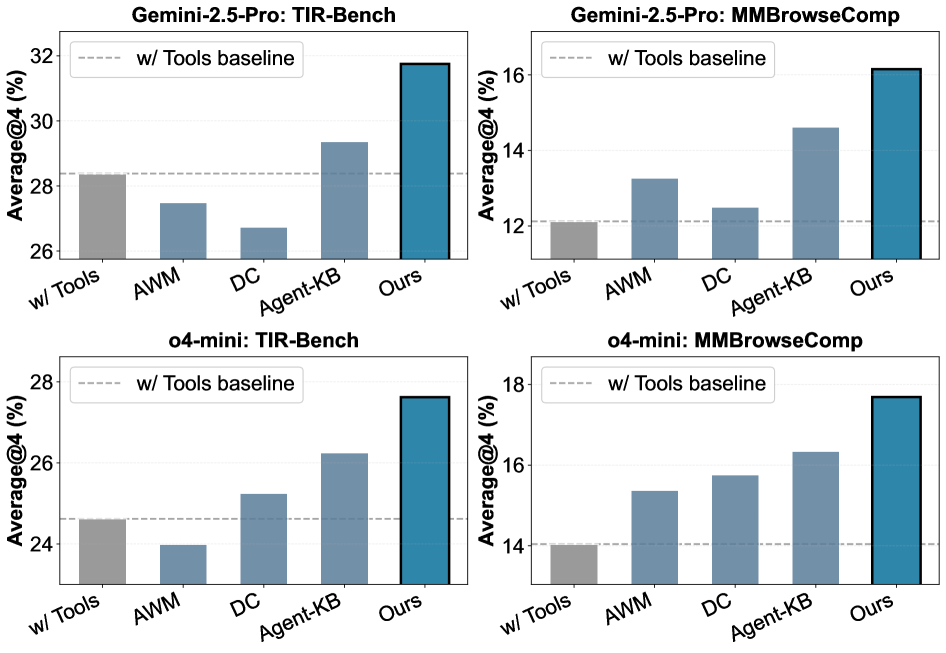
- VisualToolBench知识 → TIR-Bench / MMSearch-Plus知识 → MMBrowseComp
- 一致超越所有baseline