声明:
- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
前言背景:
在之前的学习中,我们已经见识过了各种网络为了提升性能而做出的努力:
-
ResNet-v2:通过前向反馈(Identity Mapping)解决了深层网络的梯度消失问题。
-
Inception 系列:通过并行多路径(Split-Transform-Merge)增加了网络的宽度,捕获多尺度特征。
-
DenseNet:通过特征复用(Feature Reuse)把通道利用到了极致。
但是,这些网络都有各自的痛点。Inception 虽好,但它的子网络结构太复杂了;而 ResNet 虽然简单好堆叠,但一味地加深或加宽,边际效益会严重递减。
ResNeXt(CVPR 2017)的出现就是为了解决这个矛盾。 它的核心思想一句话总结就是:用极其简单、模块化的方式,把 Inception 的"多分支"思想融入到 ResNet 的残差结构中。 论文引入了一个全新的维度------基数(Cardinality),并证明了增加基数比单纯增加深度或宽度更有效。
核心改动:
改动 1:引入全新维度------基数(Cardinality)
在传统的网络设计中,我们通常只关注深度(Depth)和宽度(Width,即通道数)。ResNeXt 创新性地提出了第三个核心超参数:基数(Cardinality)。
1.1 什么是基数?
基数指的是一个残差块(Block)中并行且结构完全相同的分支数量。
width = int(out_channels * (base_width / 64.)) * cardinality1.2 为什么有效?
传统的 ResNet 是在一个高维空间进行特征变换,而 ResNeXt 将高维特征拆分为C个低维特征(Split),在独立的子空间进行变换(Transform),最后再聚合起来(Merge)。实验表明,在保持计算量(FLOPs)和参数量不变的前提下,提高基数 C带来的准确率提升,远大于去堆叠层数或加宽通道。
改动 2:化繁为简的"同构多分支"结构(对比 Inception)
2.1 抛弃人工精调
在学习 InceptionV3 时,我们知道它为了优化性能,设计了极其复杂的 Module A、B、C。这些卷积核大小和通道数全是专家肉眼调参出来的,换个数据集可能就不适用了。
*
2.2 拓扑结构完全相同
ResNeXt 吸收了 Inception 的并行分支思想,但做了一个强有力的约束:所有并行分支的拓扑结构必须完全一模一样。这样就省去了繁琐的设计,让它和 ResNet 一样易于在代码中堆叠。
改动 3:借助分组卷积(Grouped Convolution)完美落地
如果直接在代码里用 for 循环写 32 个一模一样的分支,不仅代码臃肿,GPU 算起来也极慢。ResNeXt 巧妙地利用了分组卷积实现了这个结构。
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride, padding=1, groups=cardinality, bias=False)
#设置了一个新参数groups=cardinality
#输入通道和输出通道会被均分为 cardinality(例如 32)个独立的组。
假设这一层的输入通道数(width)和输出通道数都是 128,cardinality 为 32。
那么普通卷积核的形状会是 (128, 128, 3, 3)。
加了 groups=32 后,计算会被分成 32 个组。第1组的 4 (128÷32) 个输出通道只和第1组的 4 个输入通道进行卷积,以此类推。3.1 核心等价性
ResNeXt 的核心 Block(如C=32)在数学和结构上,完全等价于将 ResNet 瓶颈层(Bottleneck)中间的3*3卷积替换为 groups=32 的分组卷积。
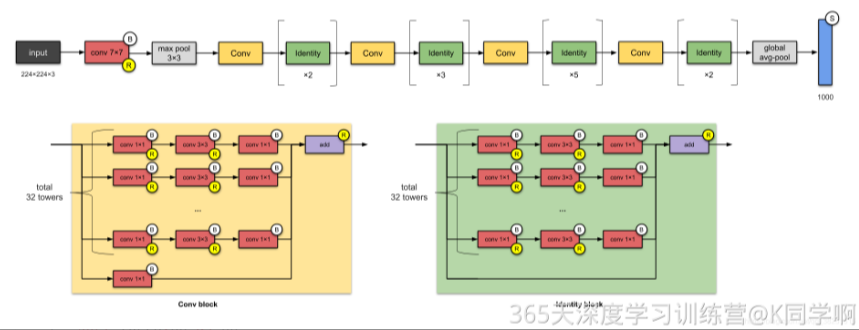
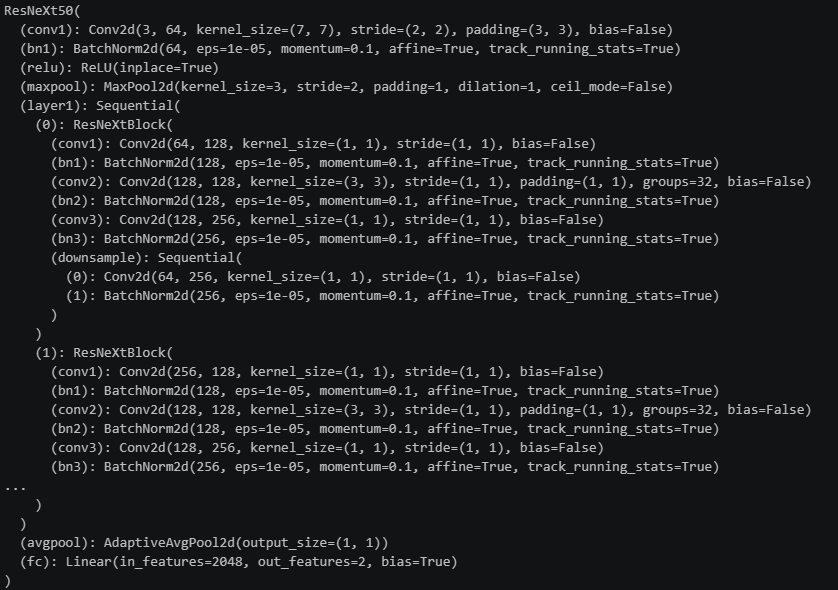
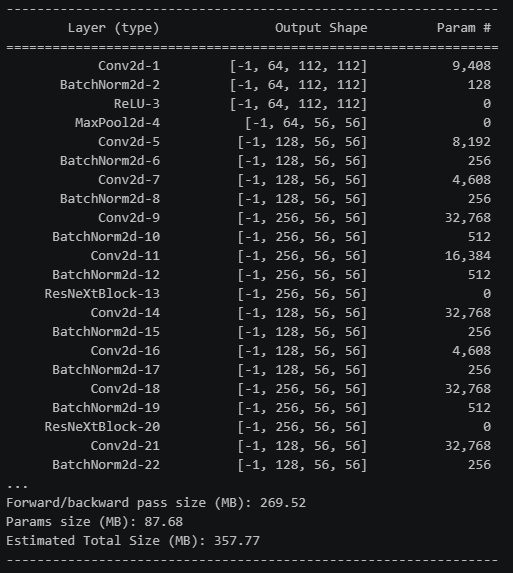
网络具体参数:
训练结果:
训练配置:
initial_lr = 0.001
optimizer = torch.optim.AdamW(model.parameters(), lr=initial_lr)
loss_fn = nn.CrossEntropyLoss()
num_epochs = 100
scheduler = CosineAnnealingLR(optimizer, T_max=num_epochs)训练记录:
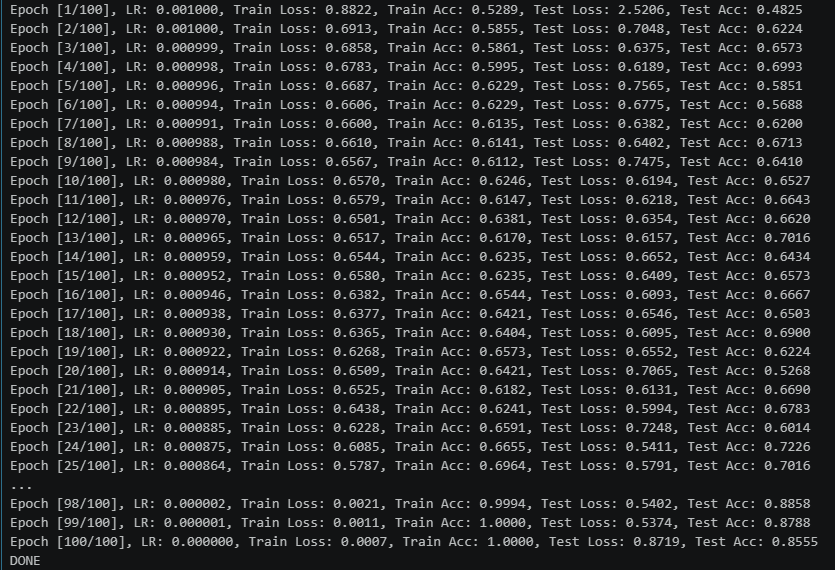
总结:
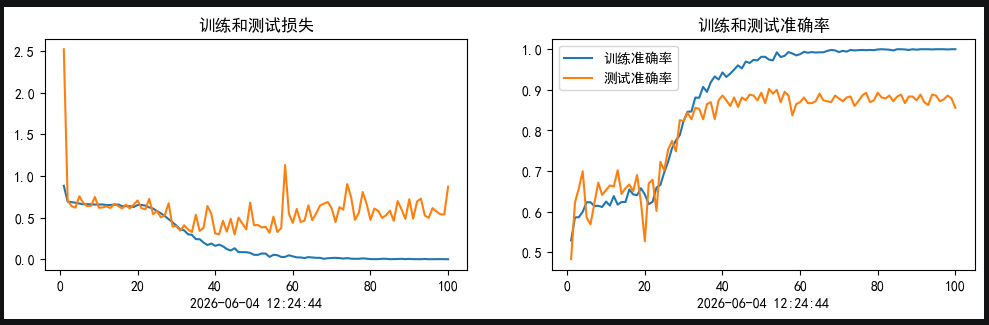
本次实验通过对 ResNeXt 网络的搭建与在猴豆病数据集上完成了训练,深入理解了其核心的"聚合残差变换"思想。相比于之前学习的 ResNet-v2 和 DenseNet,ResNeXt 最大的特点在于引入了基数(Cardinality)这一维度。它吸收了 Inception 的多分支架构灵感,但又通过同构化的设计规避了 Inception 繁琐的超参数微调,在简化模型结构的同时提升了特征提取的效率。
模型经过 100 个 Epoch 的训练,最终训练集准确率达到了100**%** ,但测试集准确率稳定在88-89%,始终没有突破90%。出现了明显的过拟合现象。可能有这些原因:
-
ResNeXt 的多分支结构提供了极高的自由度,在当前数据集规模较小时,模型容易"背诵"训练样本中的噪声特征。
-
由于采用了分组卷积,每个子分支的通道数较窄,可能每个支路学习的东西太少了,参数和数据量比不理想,可以不分那么细的支路。
-
支路依赖?感觉如果一个模型发现一个支路很容易正确的话就会产生依赖。
可以尝试加入一些dropout层或者数据增强手段