本栏目内容由人工智能学院 星马梦缘、Inst Sec. (MHL)、Nan(ZN)、sssTNT(SCY)同学共同提供,感谢几位同学的辛勤付出!!!
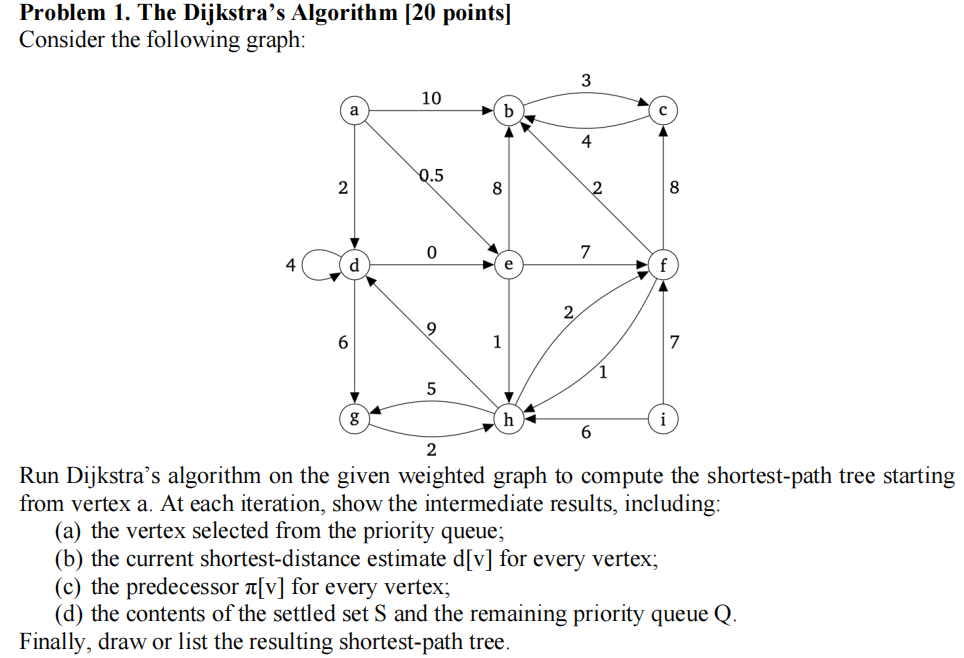
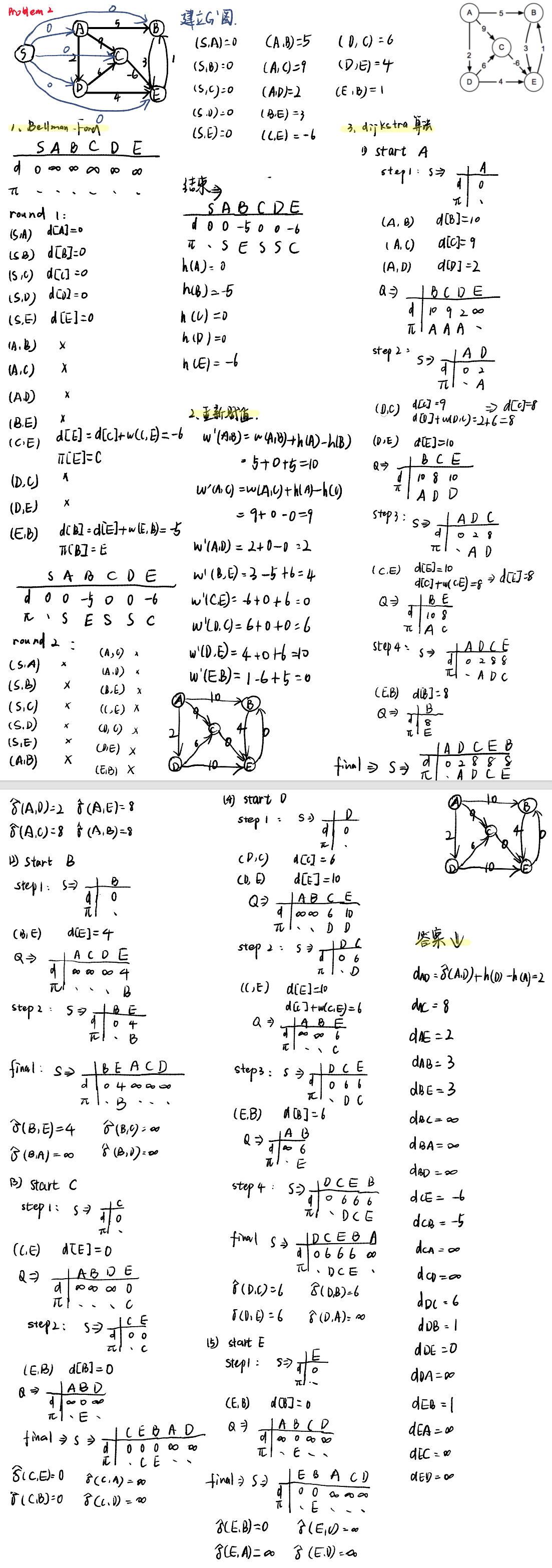
题目一------单源最短路 考场标准时间15m
维护S Q表,Q按照从小到大的价值排序,每次选最小代价的点出来探索。
翻译:
在给定的带权有向图上运行Dijkstra算法,计算从顶点 a 出发的最短路径树(shortest-path tree)。
具体要求:
在每一次迭代(循环)中,请展示以下四个中间结果:
-
(a) 从**优先队列(priority queue)**中选出的顶点;
-
(b) 每个顶点当前的最短距离估计值 dv ;
-
(c) 每个顶点的前驱节点 πv(即路径上的上一个节点);
-
(d) 已确定集合 S 的内容,以及剩余优先队列 Q 的内容。
最后:
画出或列出最终生成的最短路径树。
涉及考点
Dijkstra 算法
简单来说,虽然"拓扑排序+松弛"在 DAG(有向无环图)中效率极高( O(V+E) ),但它有一个致命的**硬伤,**处理不了"环",而 Dijkstra 算法虽然慢一点( O((V+E)logV)),却解决了这个硬伤。
1. 最大的问题:它处理不了"环"(通用性差)
这是最根本的原因。
- 拓扑排序的前提 :图必须是无环的(DAG)。如果图中有环(比如 A->B->C->A),拓扑排序根本无法进行(找不到入度为0的节点),整个算法直接瘫痪。
- 现实世界的图 :绝大多数现实生活中的图都是有环 的。
- 地图导航:你可以从 A 走到 B,也可以从 B 走回 A(双向道路)。
- 网络路由:数据包可以在网络中绕圈子。
Dijkstra 的优势 :它不依赖拓扑排序,它通过贪心策略(每次选当前距离最近的点)来处理节点。它完全不在乎图中有没有环,只要没有"负权环",它都能完美工作。
结论 :我们忍受 Dijkstra 稍微慢一点点(多一个 logV ),是为了换取它能处理任意有环图的能力。


总结
| 算法 | 你的总结 | 核心关键词 |
|---|---|---|
| Bellman-Ford | 能解决负权边,有向/无向有环图 | 全能兜底 |
| 拓扑+松弛 | 解决有向无环图(无法解决循环依赖) | 极速特化 |
| Dijkstra | 解决非负有环图 | 通用标准 |
解析
我的答案
维护S Q表,Q按照从小到大的价值排序,每次选最小代价的点出来探索。


zn同学的答案 交叉验证通过

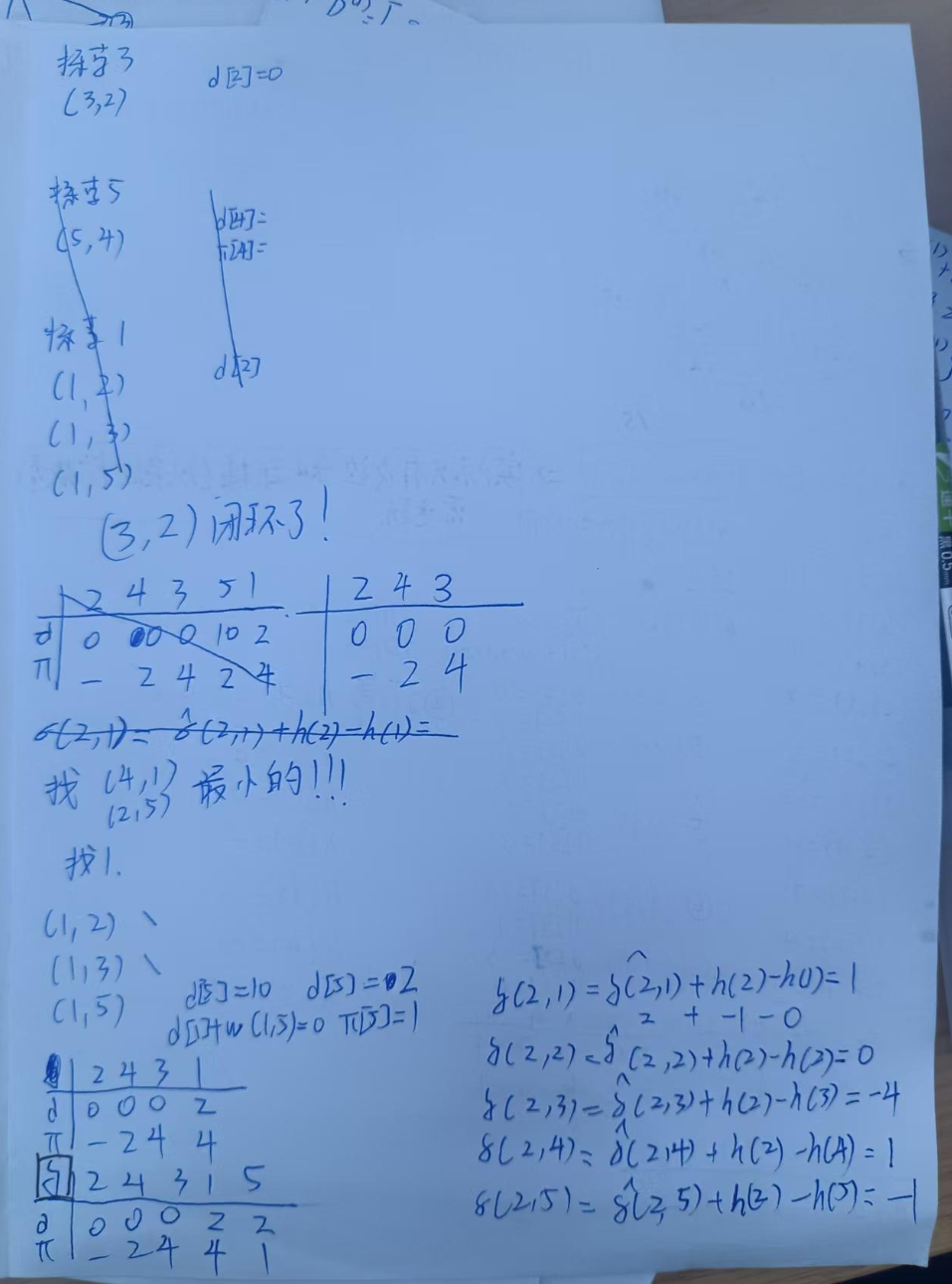
题目二------多源最短路 考场标准时间40m
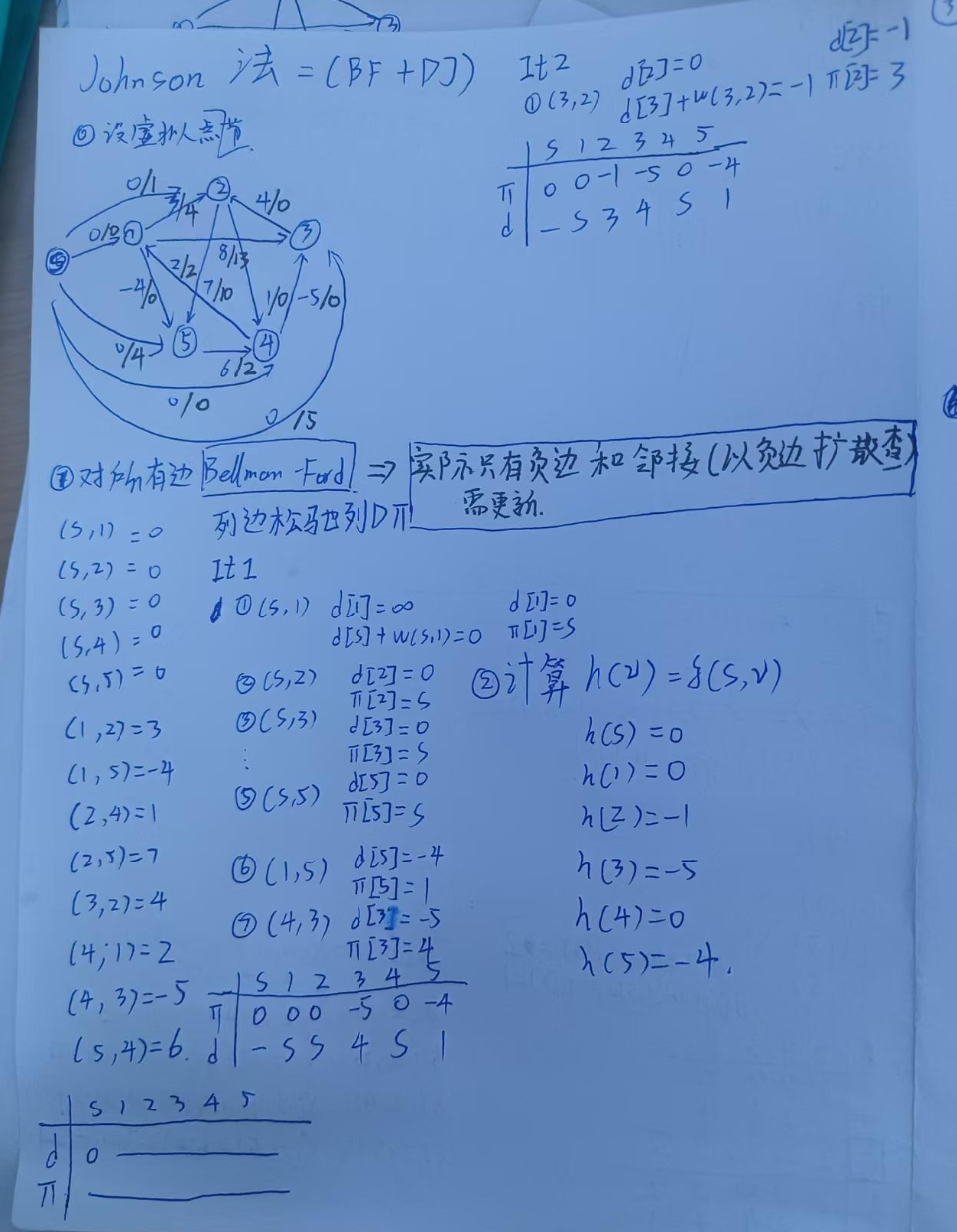
原理是由于DJ法无法处理负权边问题,因此引入一个"零势能面",将负权边转为正权边。
首先引入一个超级原点,就是零势能面,然后计算所有点到原点的最短路,用BellmanFOrd即可。
遍历所有变更新到无变化。
然后记录所有点到原点的最短路长度(相当于海拔高度有正有负),然后就能得到最低的海平面。
我们的任务就是以最低的海平面为0m。
因此引入变化势能函数尖w(A,B)=w(A,B)+h(A)-h(B)
这样算出来的新权重就是全为正的,可以用DJ法。
接下来就是用多源DJ法计算多源最短路,每次算出来一个点都要计算转换后的权重,也就是
σ(A,B)=δ(A,B)+h(B)-h(A),注意,这里是后减前,是为了还原到原始权重去计算!!!
这个σ就是最短路距离了!
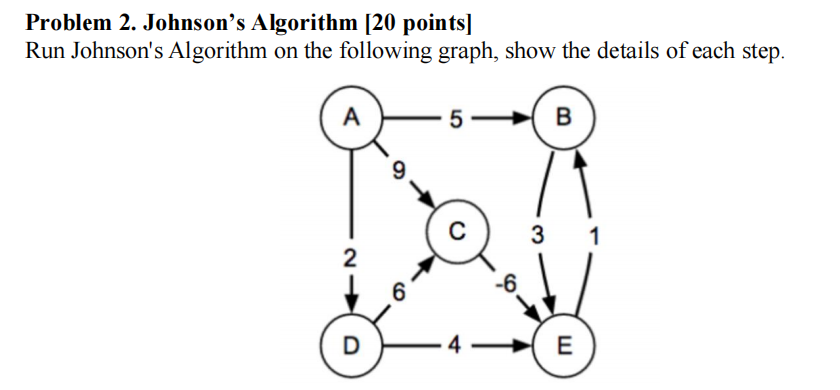
翻译:用约翰逊算法解决多源最短路的问题
涉及考点
Johnson 算法(降低复杂度)
D法只适用于非负权边的图,因此对于有负权边的就必须对每个点跑一遍BF。
考虑将负权边变成非负的边,这样就能用D法了。




可是w(uv)可能是负的啊
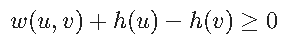

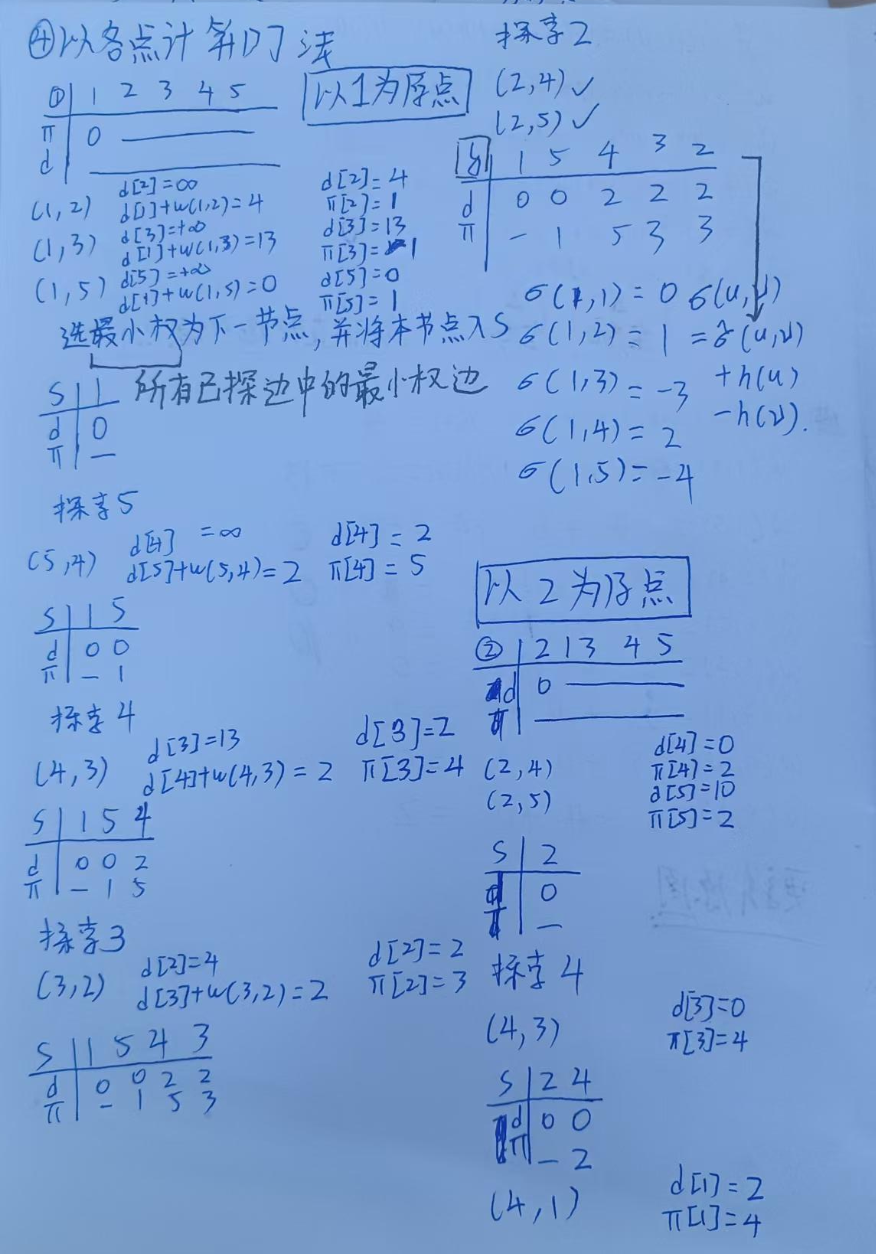
总体思路:
将负权边转换为非负权边,引入势能函数,保证负权非负
1.引入超级原点S,将S与所有节点相连,权重为0
2.列出所有边
3.使用Bellmanford进行单元最短路计算,列边松弛列dΠ,得到S到各个点的最短路
4.计算势能 h(v)=δ(s,v)
5.计算等效边权w(u,v)_hat
6.这时就可以迪杰斯特拉了

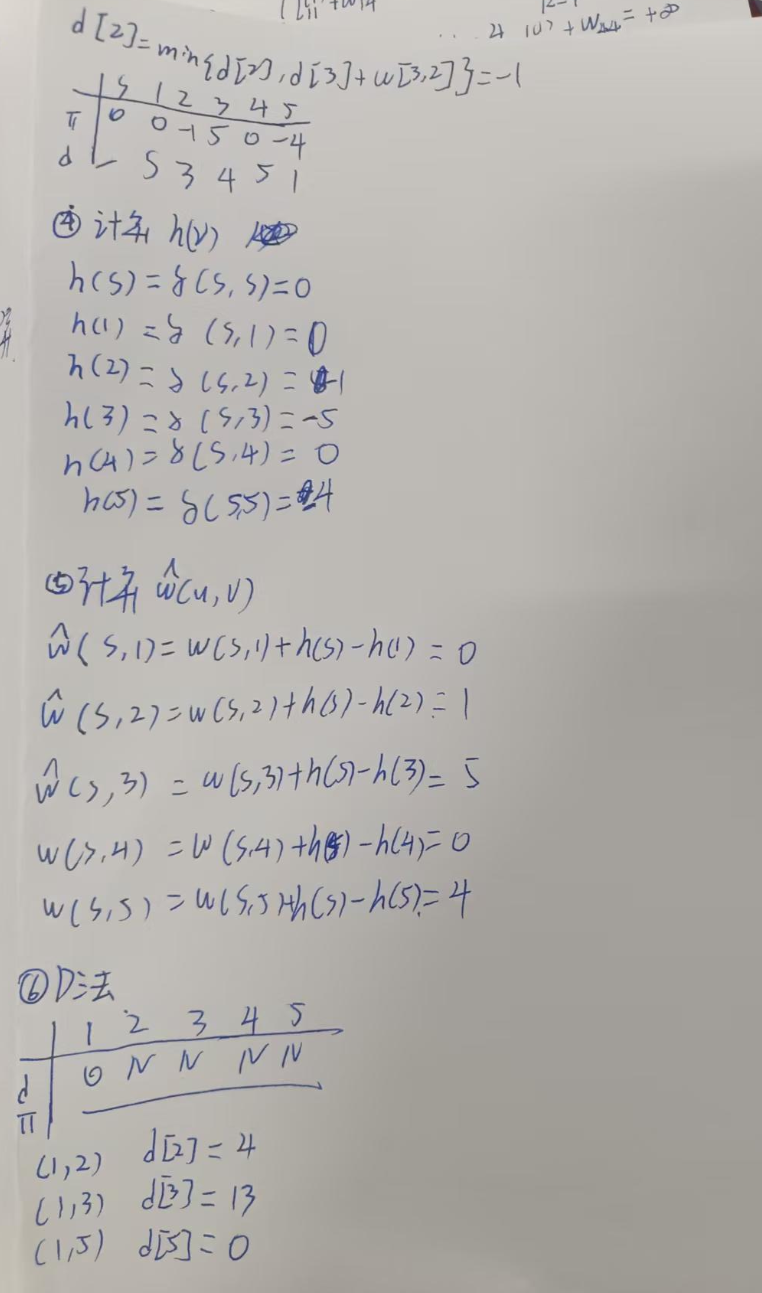

最多需要遍历最短路径长度的边的轮数,每轮复杂度E


解析
我的答案



zn同学的答案 交叉验证通过
sssTNT同学的答案 交叉验证通过

题目三------找最短增广路 考场标准时间16m
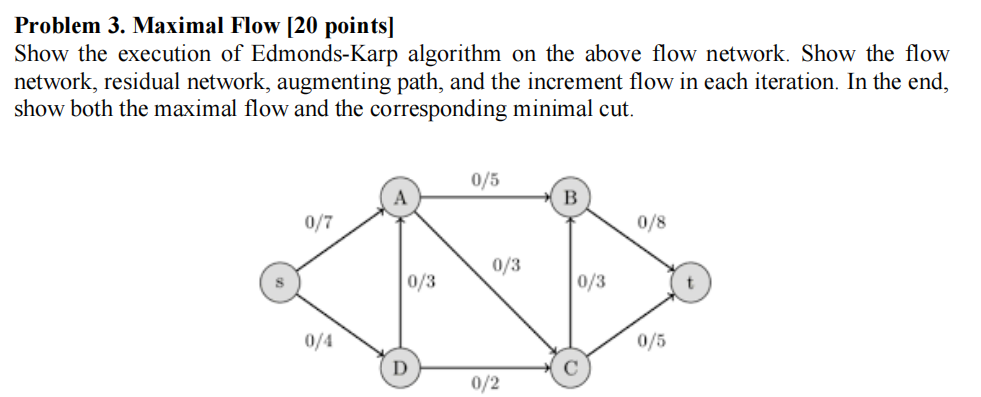
翻译:
展示 Edmonds-Karp 算法在上述流量网络上的执行过程。请在每次迭代中,展示流量网络、残余网络、增广路径以及增加的流量(增量流)。最后,展示最大流量以及对应的最小割。
涉及考点
依赖于三个概念:
剩余网络:每条边还剩余多少流量
增广路:寻找可达路
cuts:如何将网络切割为两部分,限制流量上限
1. 剩余网络(Residual Network)
"这条路还能再走多少?"
- 定义:在原网络的基础上,根据当前的流量情况,构建出一个"还能容纳多少新流量"的网络。
- 核心指标:剩余容量(Residual Capacity)
- 正向边:如果一条水管容量是 10,已经流了 3,那么剩余容量就是 10−3=710−3=7 。代表你还可以往里塞 7 个单位的流量。
- 反向边(精髓所在) :这是 Ford-Fulkerson 算法最巧妙的地方。如果一条边已经流了 3 个单位的流量,算法会人为地增加一条反向边,其剩余容量为 3。
- 为什么要有反向边? 它代表了**"反悔"**的能力。如果你后来发现之前流的这 3 个单位走错路了,可以通过反向边把这 3 个流量"退"回去,重新分配给其他路径。没有反向边,算法很容易陷入局部最优解。
2. 增广路径(Augmenting Path)
"找到一条能走通的路,并灌入流量。"
- 定义 :在剩余网络中,从源点(Source)到汇点(Sink)的一条连通路径。只要这条路径上所有边的剩余容量都大于 0,它就是一条增广路径。
- 瓶颈容量(Bottleneck Capacity) :一条路径能增加多少流量,取决于这条路上最窄的那根管子(即路径上剩余容量最小的那条边)。
- 操作步骤 :
- 在剩余网络中找到一条增广路径。
- 找出该路径上的最小剩余容量(瓶颈)。
- 沿着这条路径,正向边加上这个流量,反向边减去这个流量(更新剩余网络)。
- 重复上述过程,直到再也找不到增广路径为止。
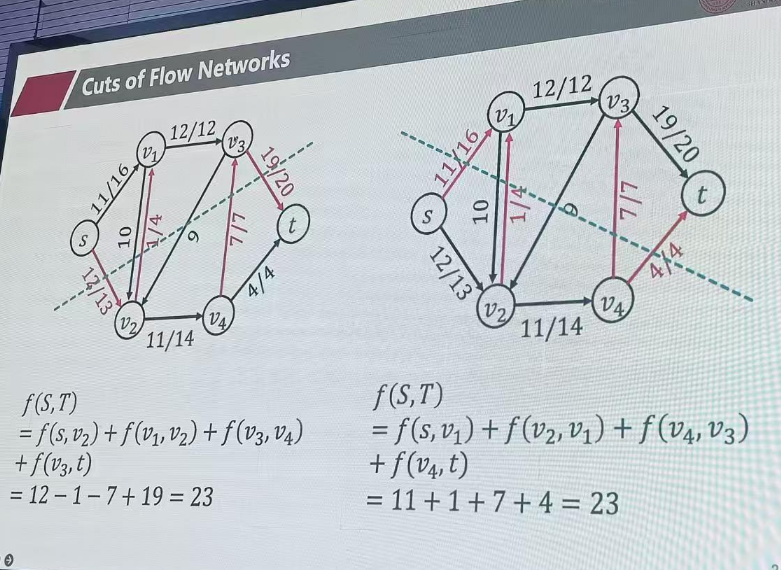
3. 割(Cut)与最大流最小割定理
"流量的天花板在哪里?"
- 定义:割是将网络中的所有顶点分成两个互不相交的集合:包含源点的集合 SS 和包含汇点的集合 TT 。
- 割的容量:所有从 SS 指向 TT 的边的容量之和。你可以把它想象成把网络切成两半,切面上所有水管的总粗细。
- 最大流最小割定理(Max-Flow Min-Cut Theorem) :这是 Ford-Fulkerson 算法正确性的数学基石。
- 定理指出:一个网络的最大流量 = 该网络的最小割容量。
- 直观理解:无论你中间的路网修得多么复杂,最终能流到终点的最大水量,一定受限于整个网络中最薄弱的那个"瓶颈截面"(最小割)。
- 算法终止条件:当剩余网络中再也找不到增广路径时,说明源点和汇点在剩余网络中不连通了。此时,所有能从源点到达的点构成集合 SS ,其余点构成集合 TT 。这个 (S,T)(S,T) 割的容量恰好等于当前的流量,证明已经达到了理论上限(最大流)

第一行是正向边,减去流量
第二行是反向边,允许退还流量,加回去
同时表达正向容量和反向容量才是完整的当前状态。
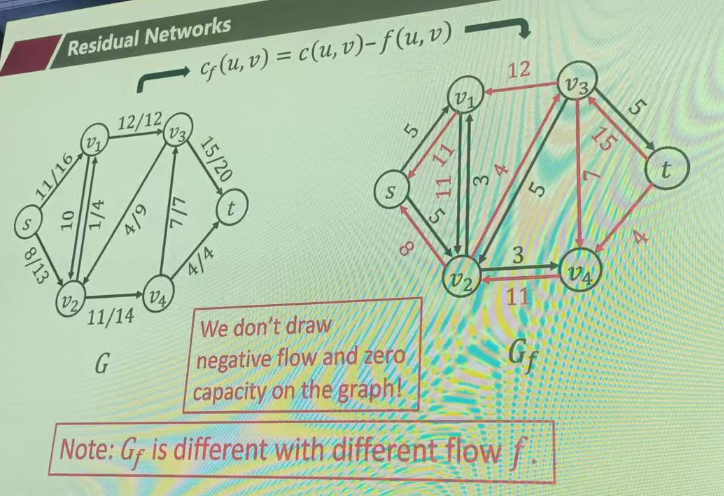
计算残差网络
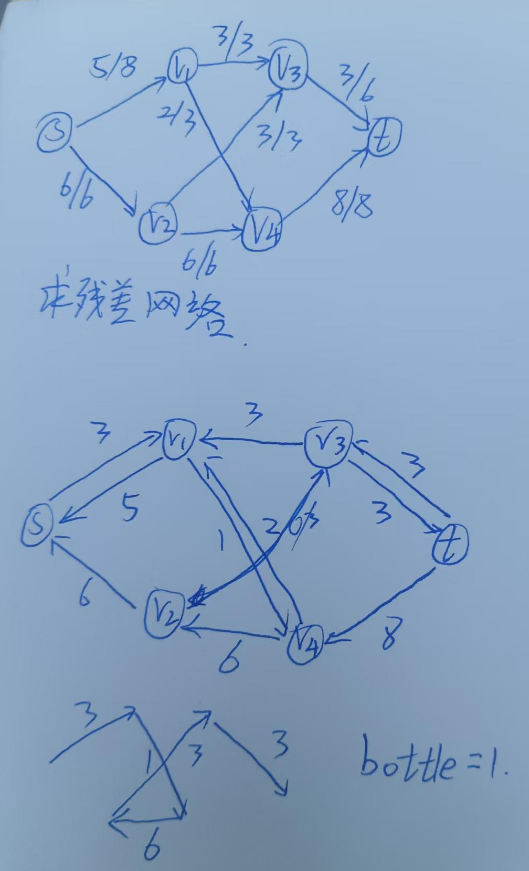
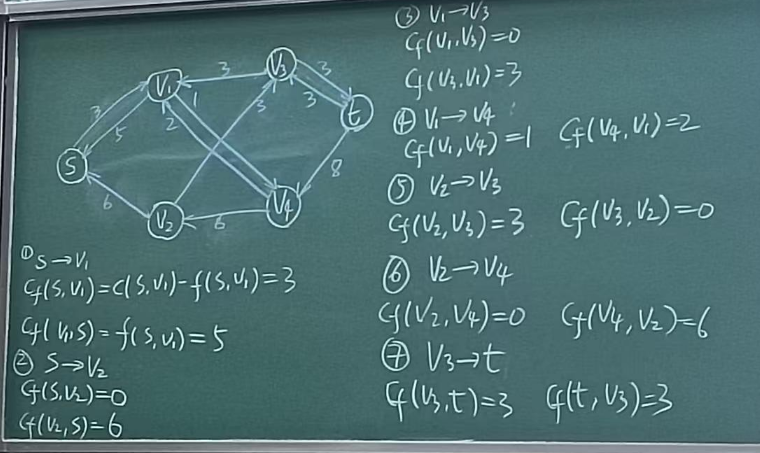
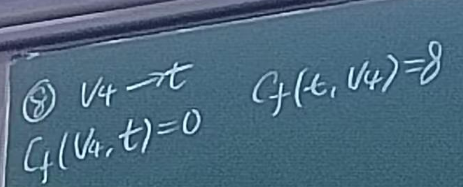
流增广
新流量 = 旧流量 + 正向推流 - 反向退流(要同时对正反边两个状态作出修改)






切割的流
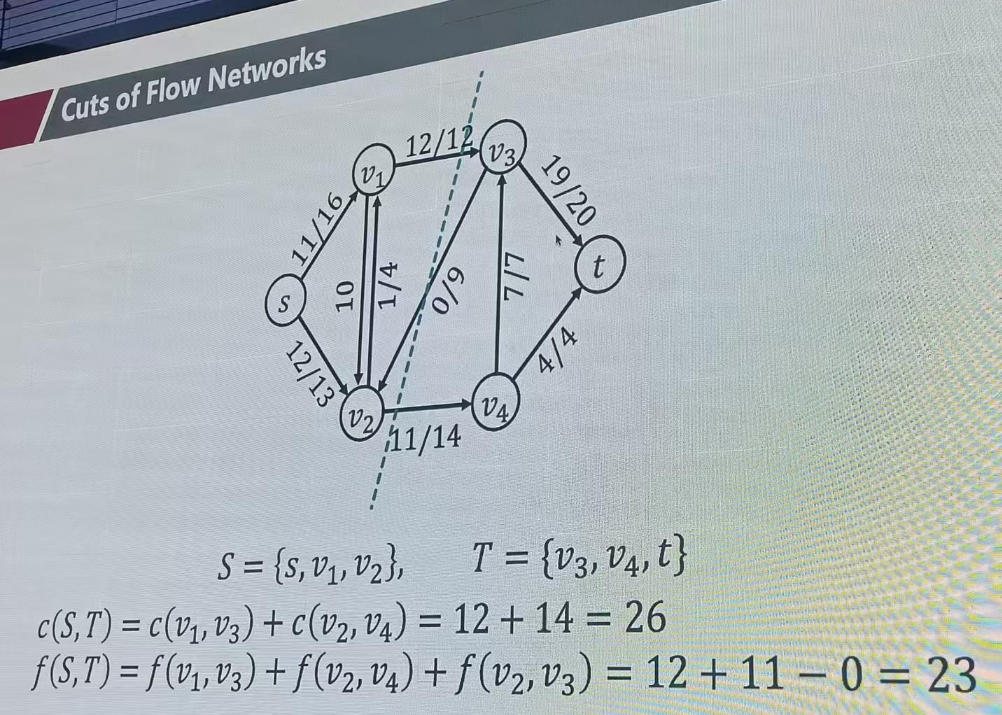
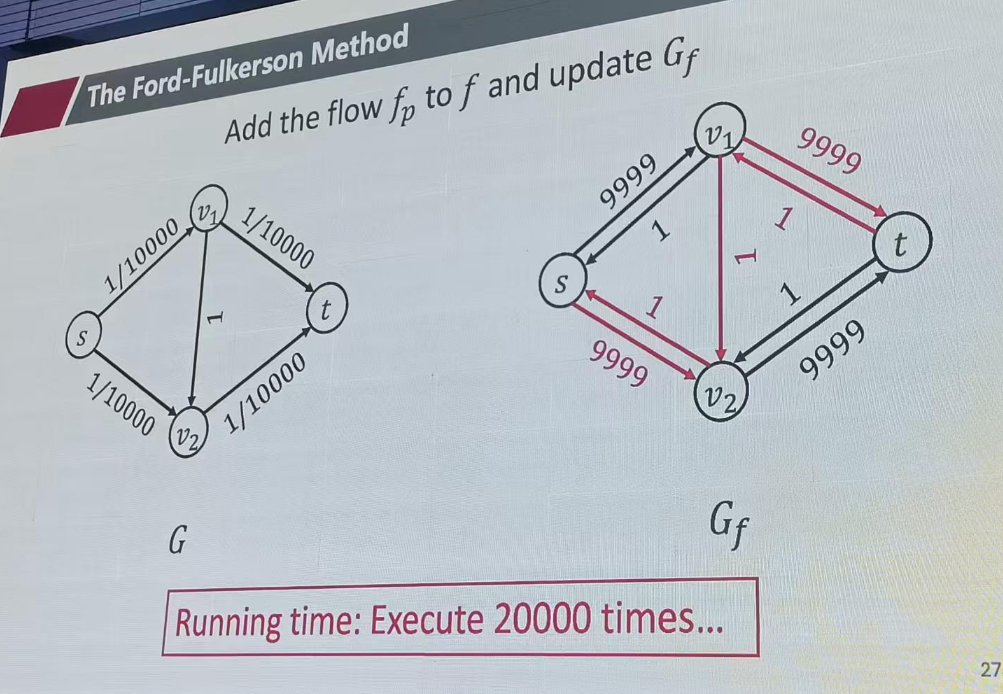
EK法 找最短增广路
增广路径的选择会极大影响复杂度,因此需要一种快速方案
EK法,找最短的路径
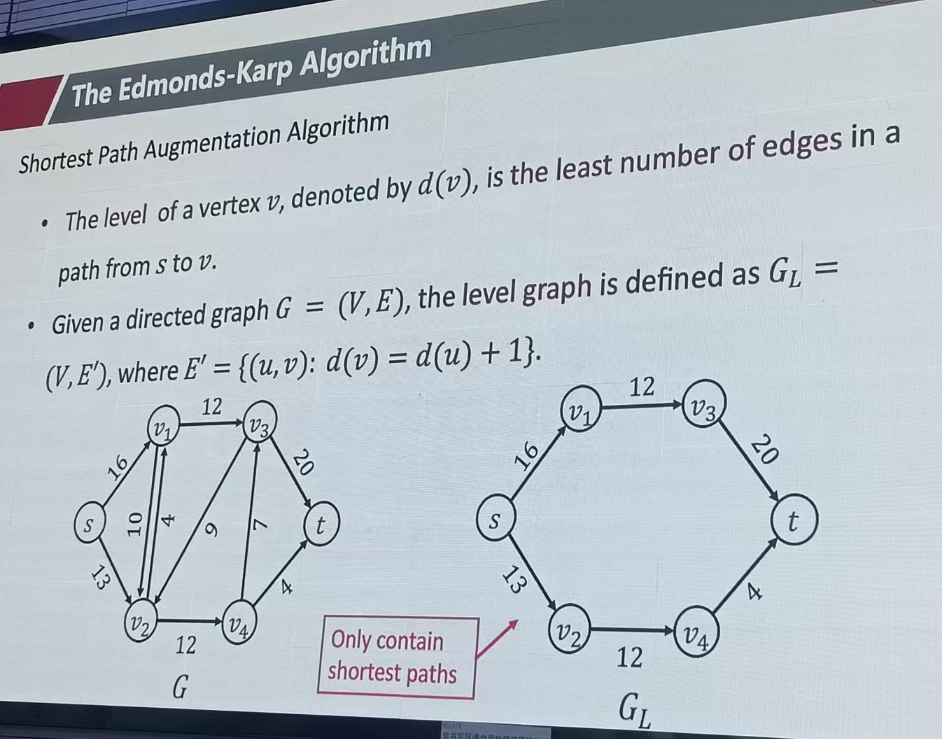

算法流程

示例:
不在是在残差图中招任意一条最短路,而是构建一个GL层次图,在层次图里面找一条最短路
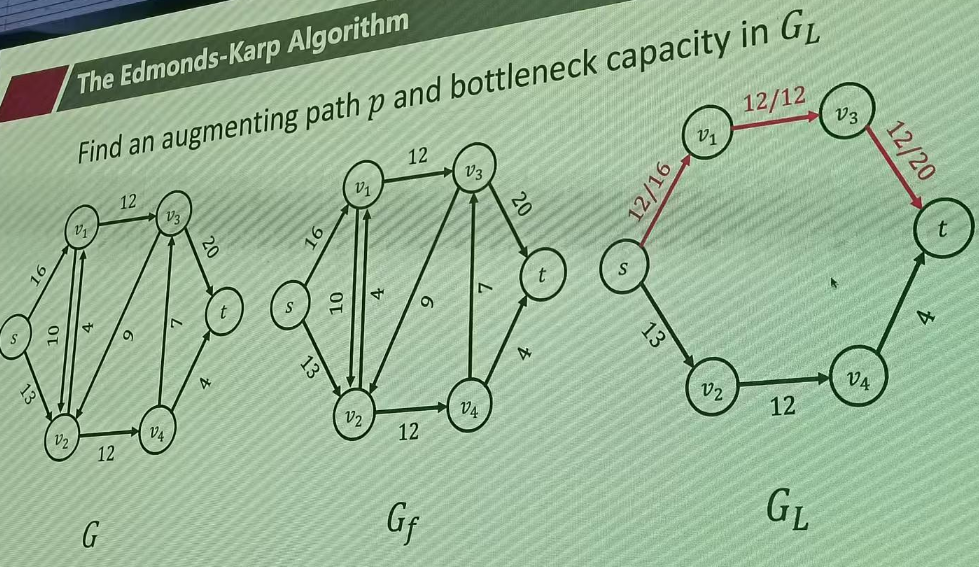
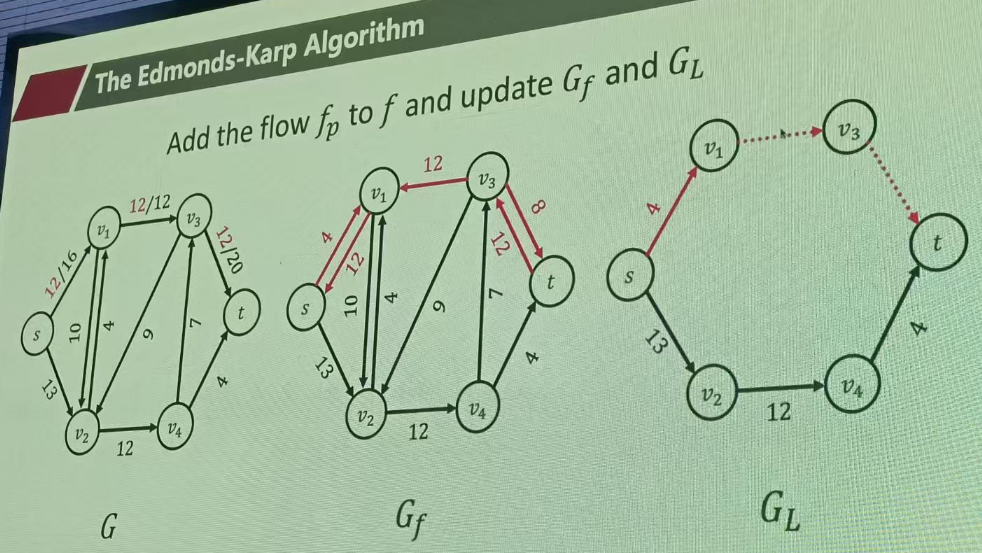
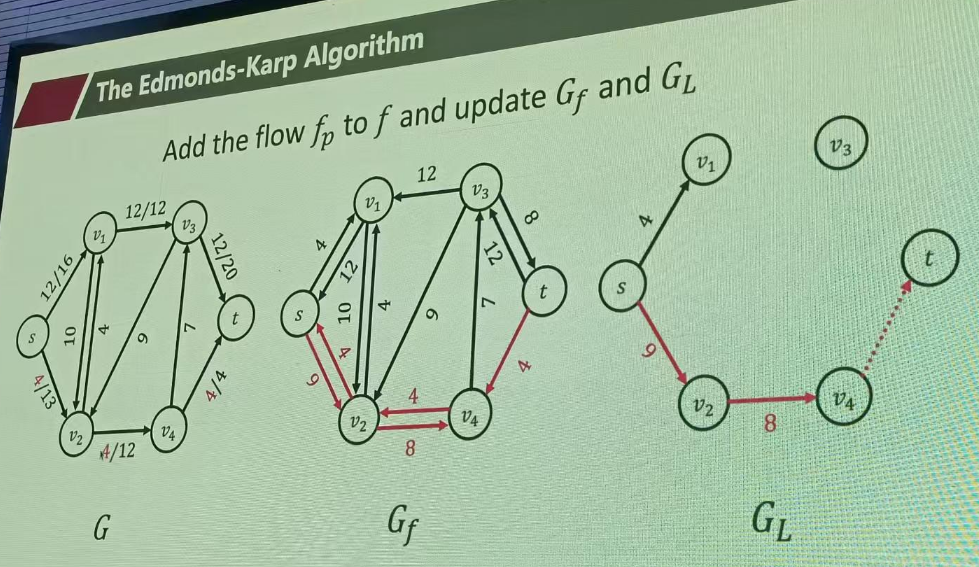
当当前的GL层次图没有到t的路径时,就重新在残差图中构建层次图
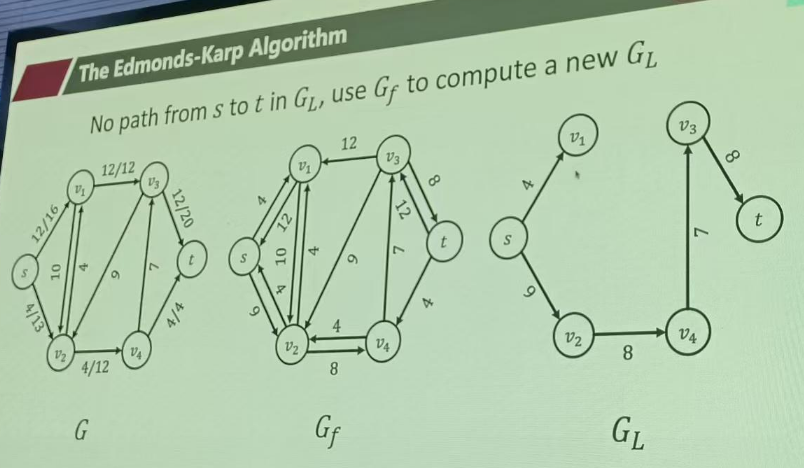
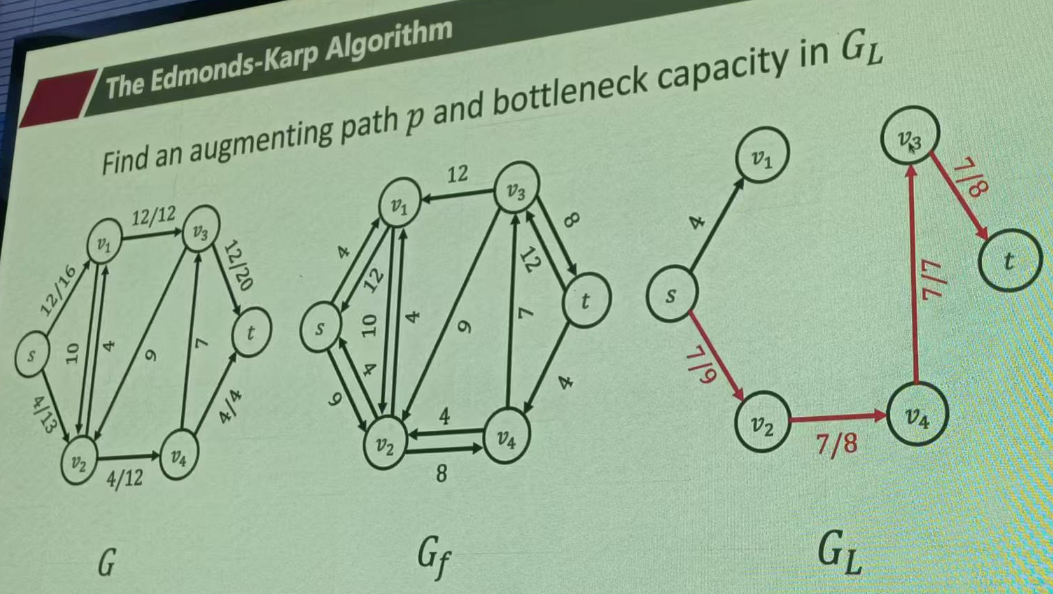
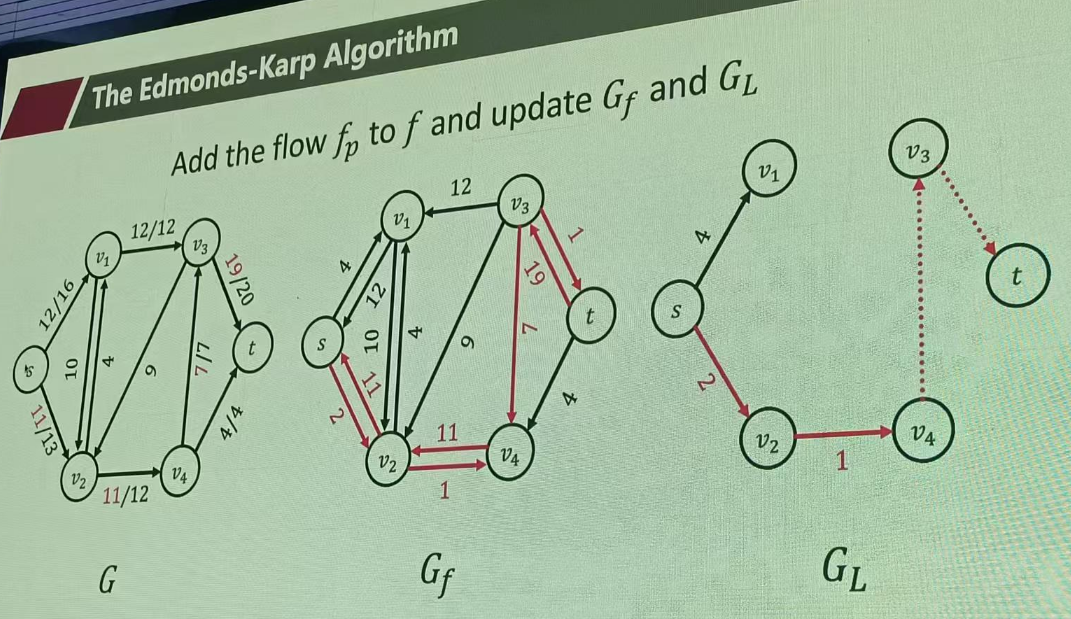
原图只带几比几、残图有双向边、层图有通也有断
算法复杂度:

解析
我的答案
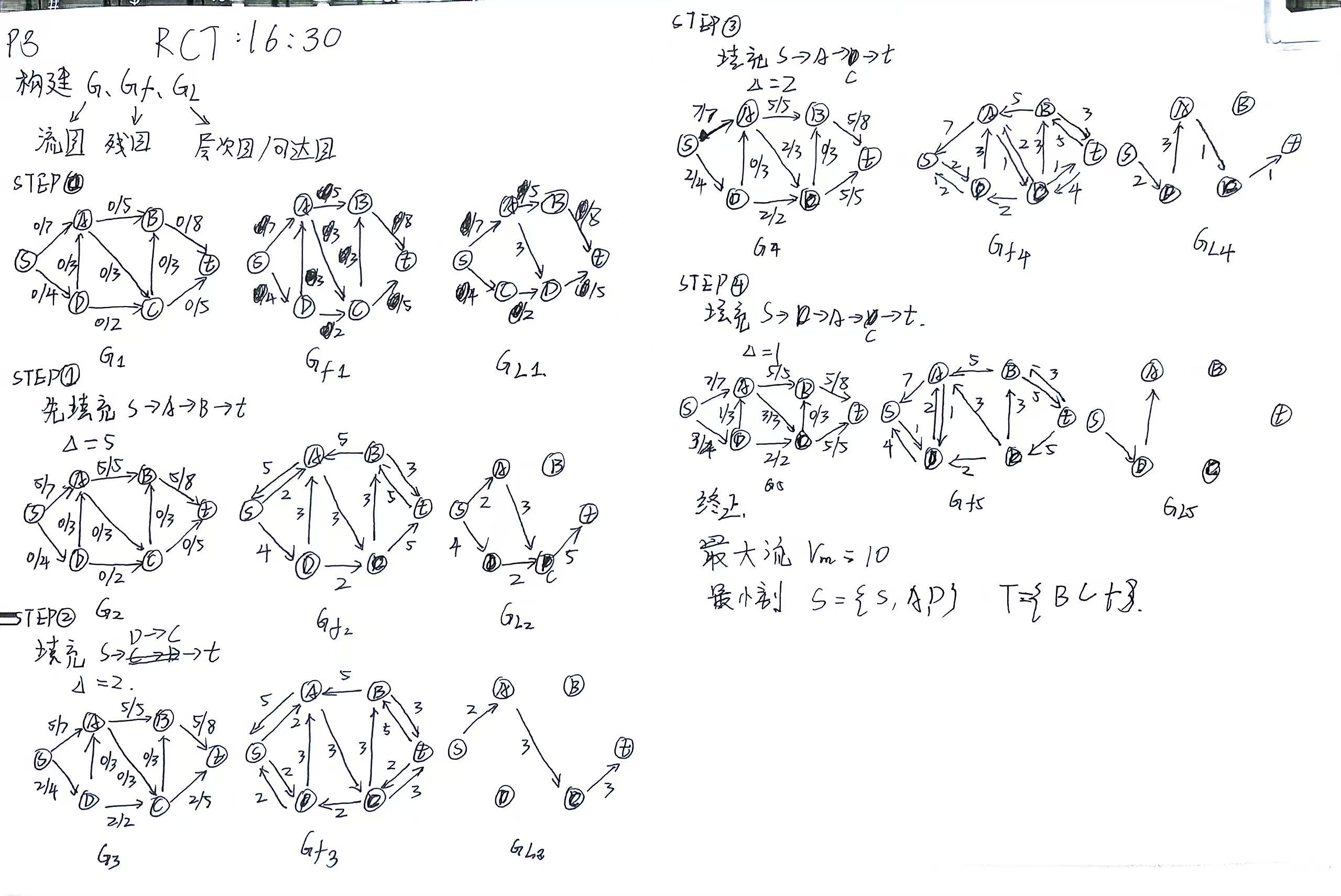
zn同学的答案 交叉验证通过
题目四------线性规划问题 考场标准时间25m

翻译:
给定以下线性规划问题 (LP),
最大化 z=x1+2x2
约束条件 (s.t.):
x2≤2x1+2
x1+3x2≤27
x1+x2≤15
2x1≤x2+18
x≥0
通过几何论证和单纯形法计算其最优解。
涉及考点
线性规划


常见定义

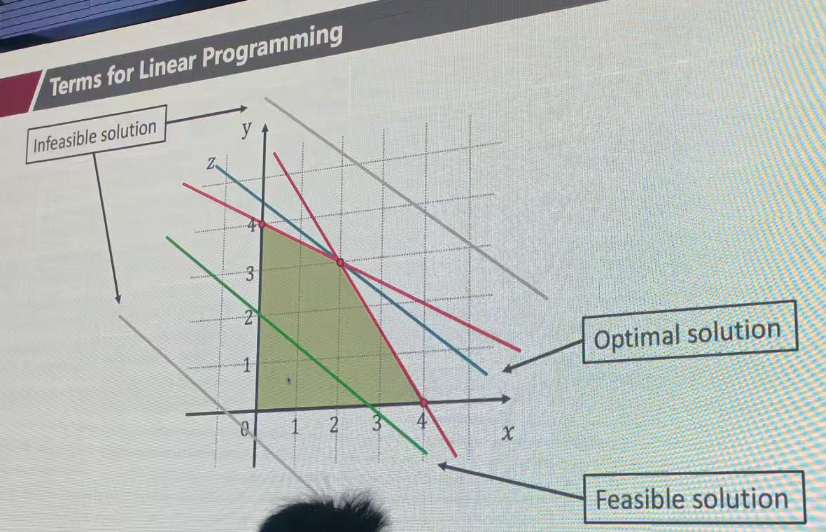
矩阵化表达

有m个约束 n个变量。
要标准化转为线性约束标准问题

要求:所有x大于0 Σax<=b max问题
要把min变成max
要把=改为<=
要把所有的x约束大于0
1 将min改为max问题

2 将等式变为两个不等式夹击

3 并通过同乘符号把大于等于>=改为小于等于<=

4 补充限制条件
将自由变量变为两个非负变量的差
要求xj xj都大于0,这样就可以表示任意的实数

算法希望处理等式约束。
松弛形式
1 引入松弛变量 将不等约束改为等号约束
s定义为冗余量,即满足条件的剩余空间
Ax<=b => Ax+s=b
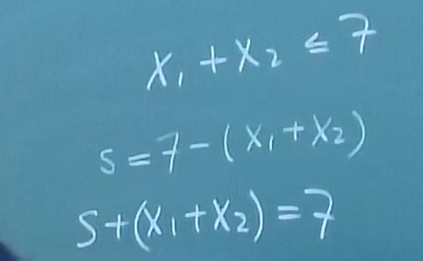
引入松弛变元------冗余量
引入后变量的总数会等于 不等号*2+等号 约束条件

basic nonbasic变量
约束等号左侧的变量x4 x5 x6是basic变量
x1 x2 x3是等号右边的,是nonbasic变量

2 将目标函数max也改为等号形式

将目标函数和下面的约束改为了等式。
这样等号左侧都是basic变量,右侧都是nonbasic变量。
(因为要分离BN变量,因此必须做将等号拆为不等式,再引入松弛变量转为等式的过程)
这样就可以转为矩阵形式运算。

A约束矩阵 b常数项 c目标项

如何解决LP问题------SImplex算法
初始化时所有NB变量都为0,此时可以计算出B变量的值 和 z的值

为了让Z最大,因此要增加x1 x2 x3
从三个NB变量中选一个,从零增加
这里选择x1
分别带入三个约束式子,看看在满足大于零1约束下要多少。
选择最少的x1.
x1《=9

然后把x1当作NB变量,把x6(交换过来的式子的NB变量)放到右侧(交换NB)
然后修改目标函数和约束条件(x1变为NB x6变为B变量)
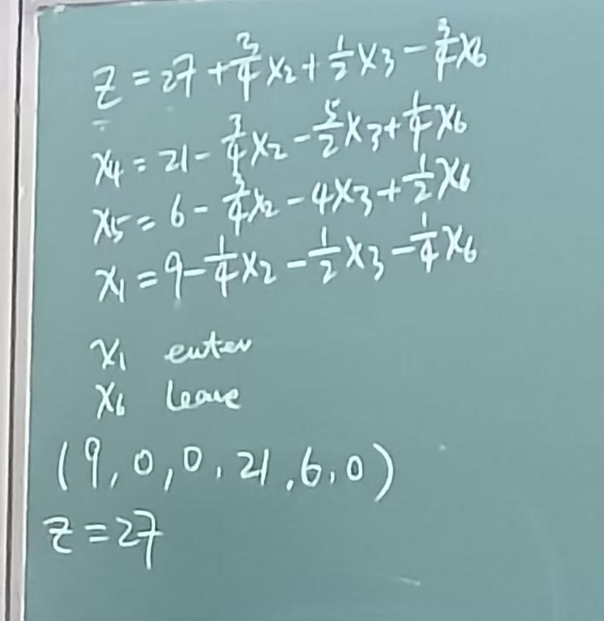
然后基于这个新问题继续做
增加x2或x3,这里增加x2



选择x3更新


更新x2,由于x4=x2,因此增加x2不会导致x4的约束被破坏。

当更新到z的式子后面的参数都是负号时,说明增加谁都无法增加z了,停止更新。

算法流程
STF+RLF
初始0,选正参。(初始化所有的参数,N参数为自己,B为0;对于z=+-+-中+的参数更新)
最小正满足(在满足N变量大于0的情况下,计算让B最小的条件)
交换NB(代入式)(根据这个约束行,计算B=xxxxN,交换NB;并带入其他涉及B的约束式)
更新所有的代入处(更新z后,看z=后面是否全负,全负停止)
解析
流程参考下面:
先进行STF和RLF验证,符合形式后再进行求解即可。
我的答案

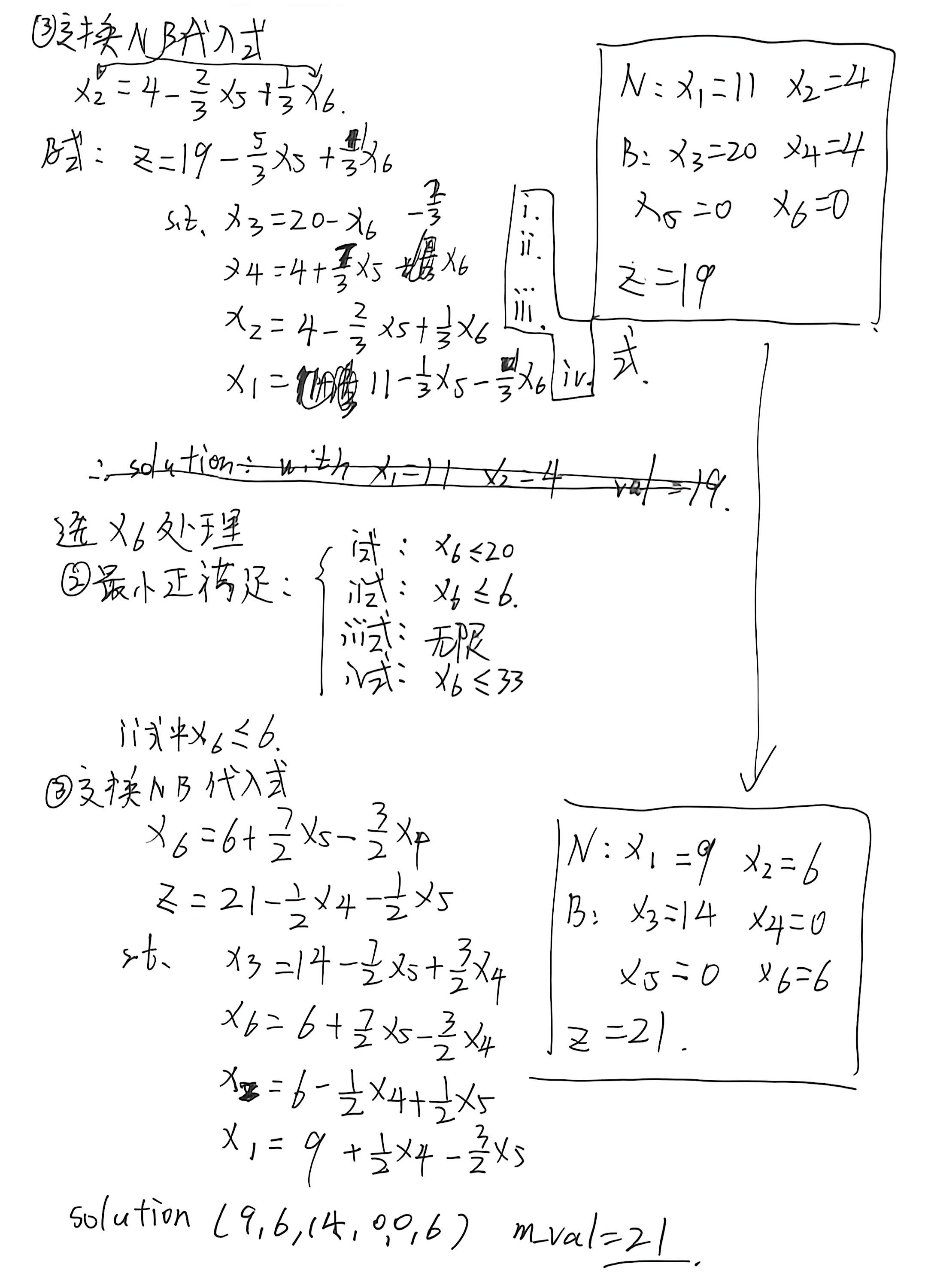
zn同学的答案 交叉验证通过 感谢多次指正!

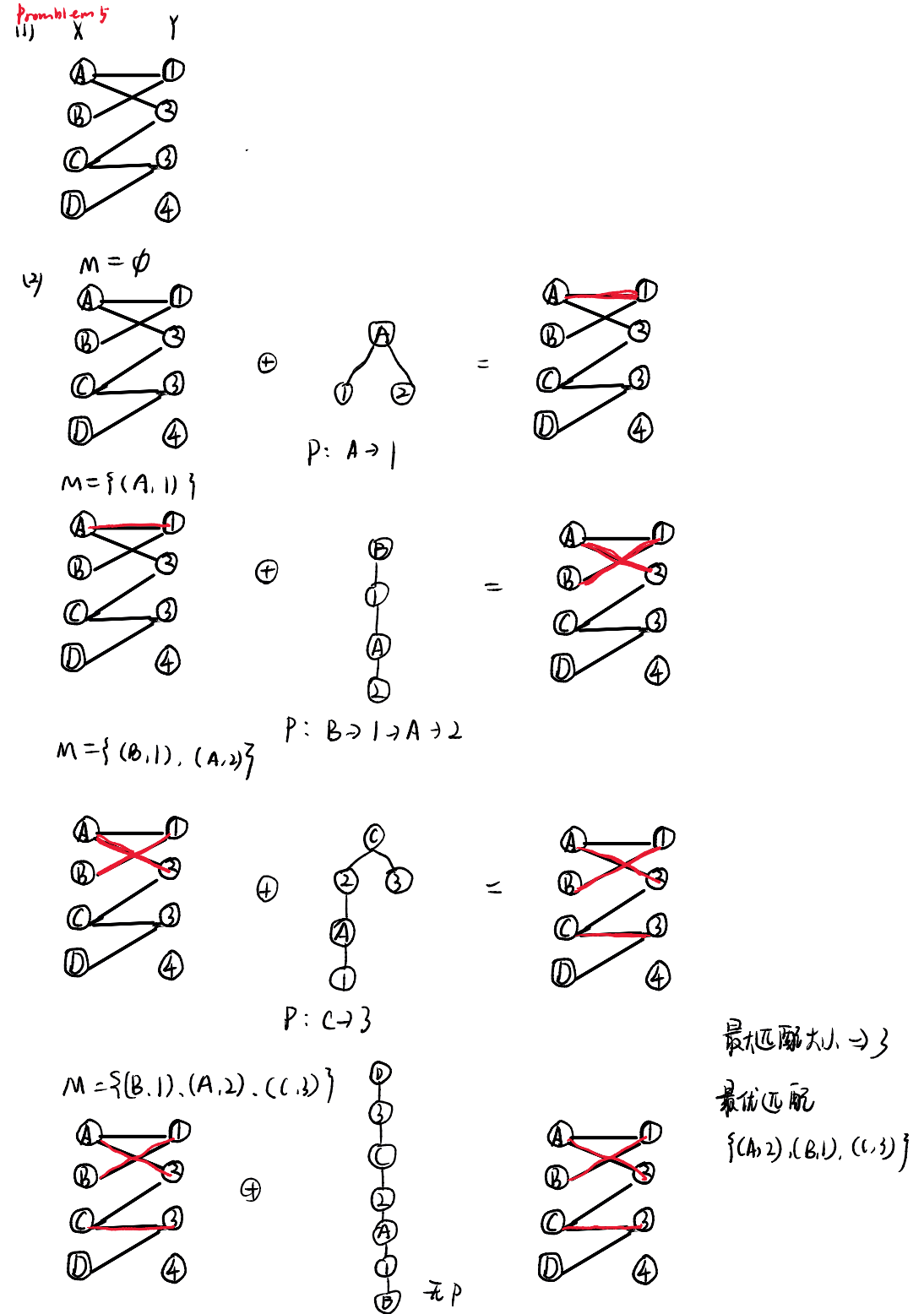
题目五------二分图匹配问题(匈牙利树算法) 考查标准时间12m

翻译:

涉及考点
匈牙利树算法
从左侧节点中找到一个未匹配的节点,以此生成多条augpath,要求终点是unmathced的,然后翻转,更新M={()()}(加一),
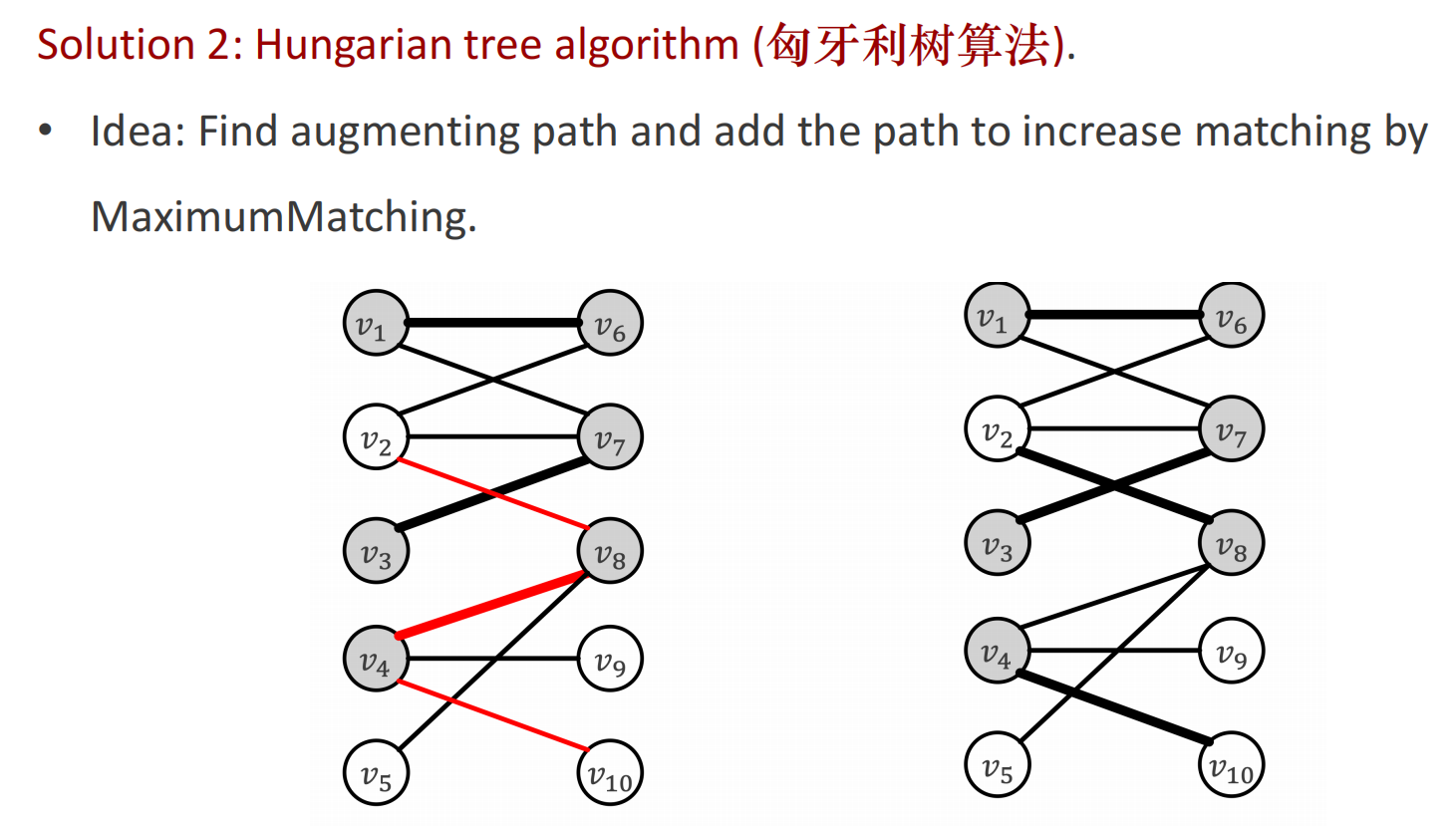
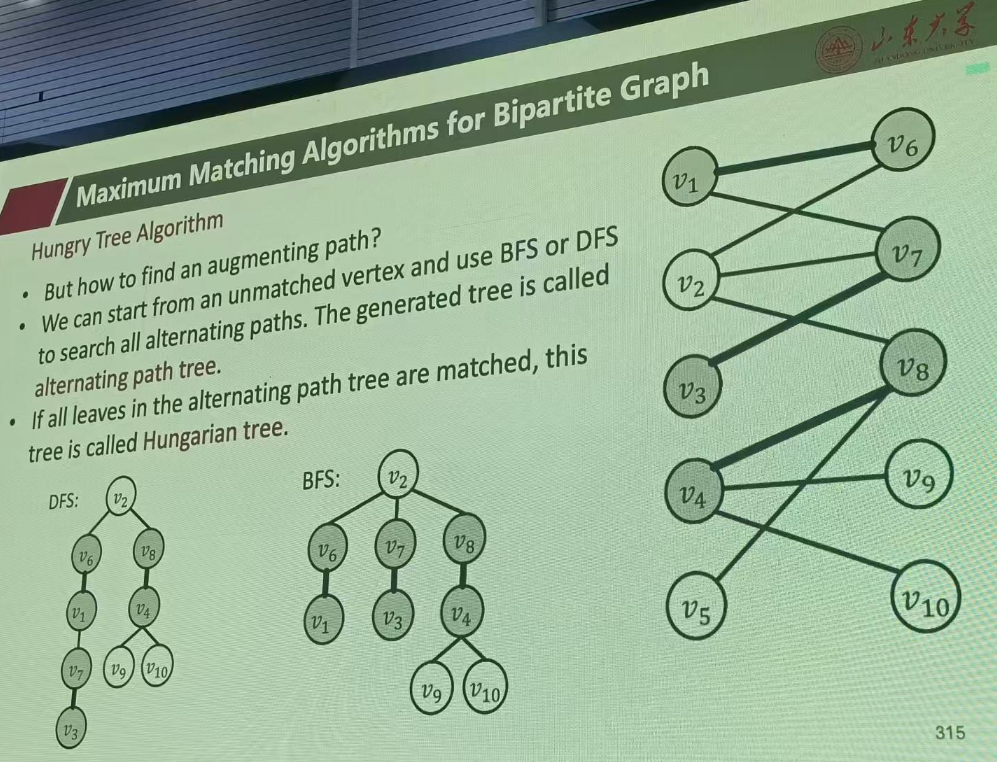
算法流程
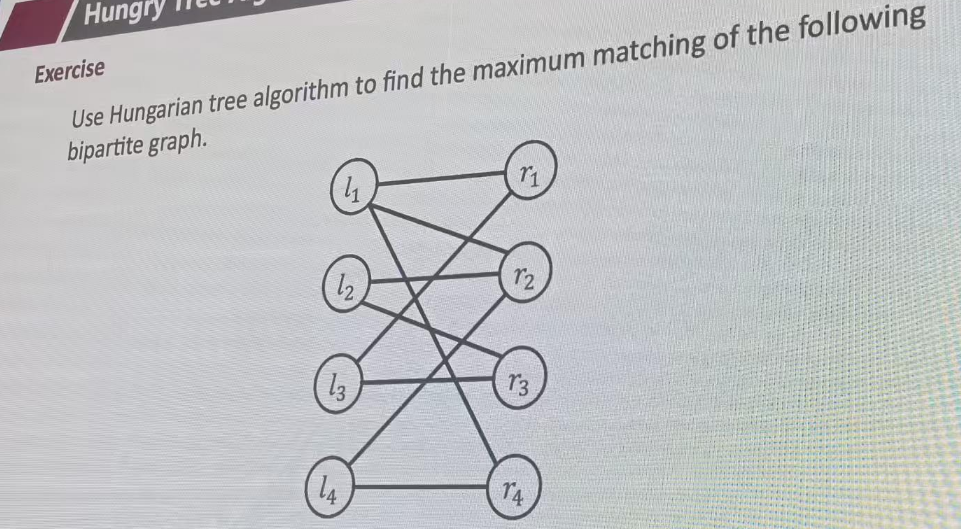
M={}
从空集开始,从l1开始匹配,找augpath,也就是找未匹配的终点,r1 r2 r4都可以。
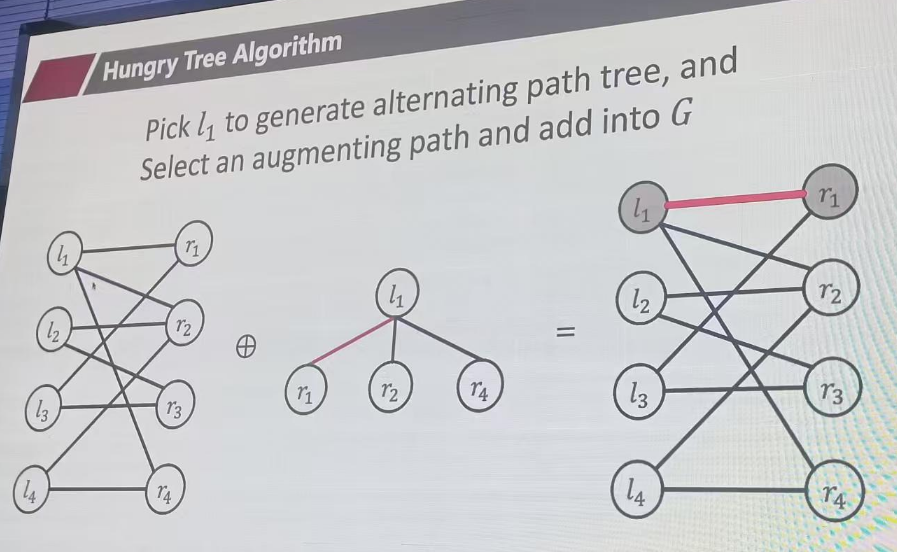
M={(l1,r1)}
从l2开始匹配,找augpath,也就是找未匹配的终点,r2 r3都可以。
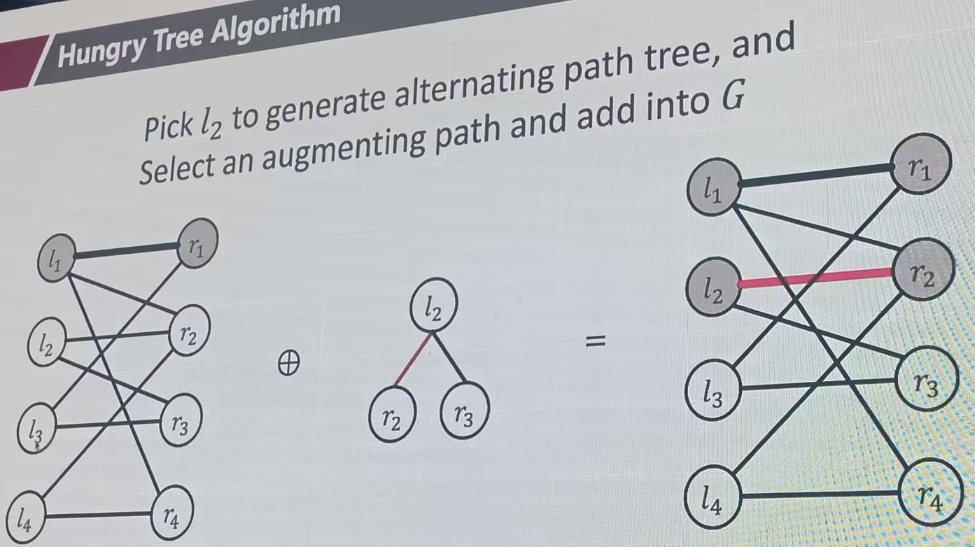
M={(l1,r1),(l2,r1)}
从l3开始匹配,找augpath,也就是找未匹配的终点,r3 r4都可以。
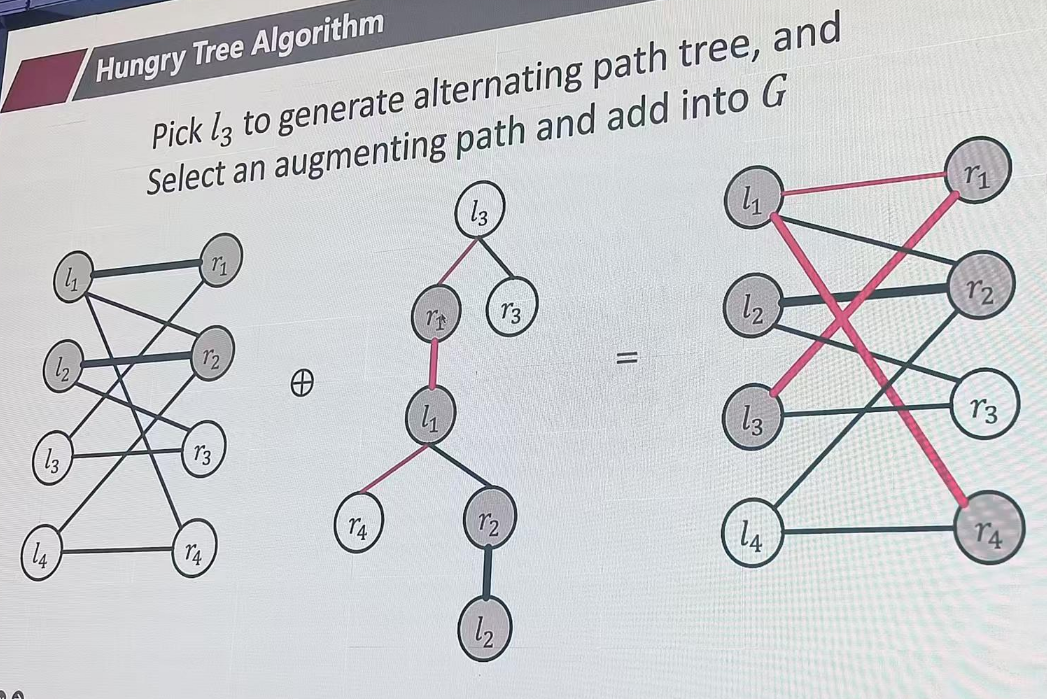
M={(l1,r1),(l3,r1),(l1,r4)}
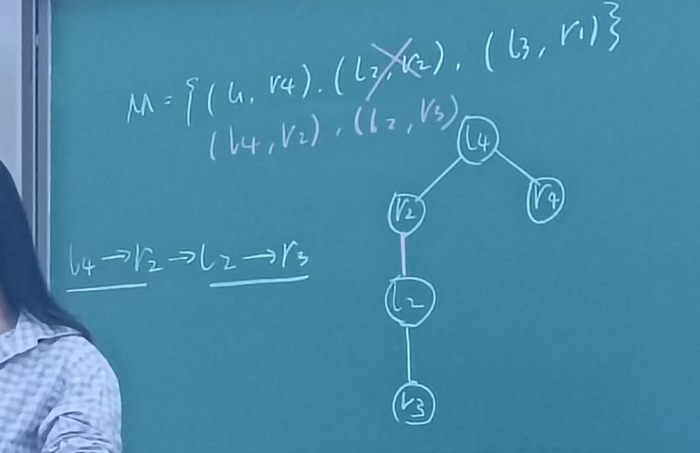
从l4开始匹配,找augpath,也就是找未匹配的终点,r3可以。
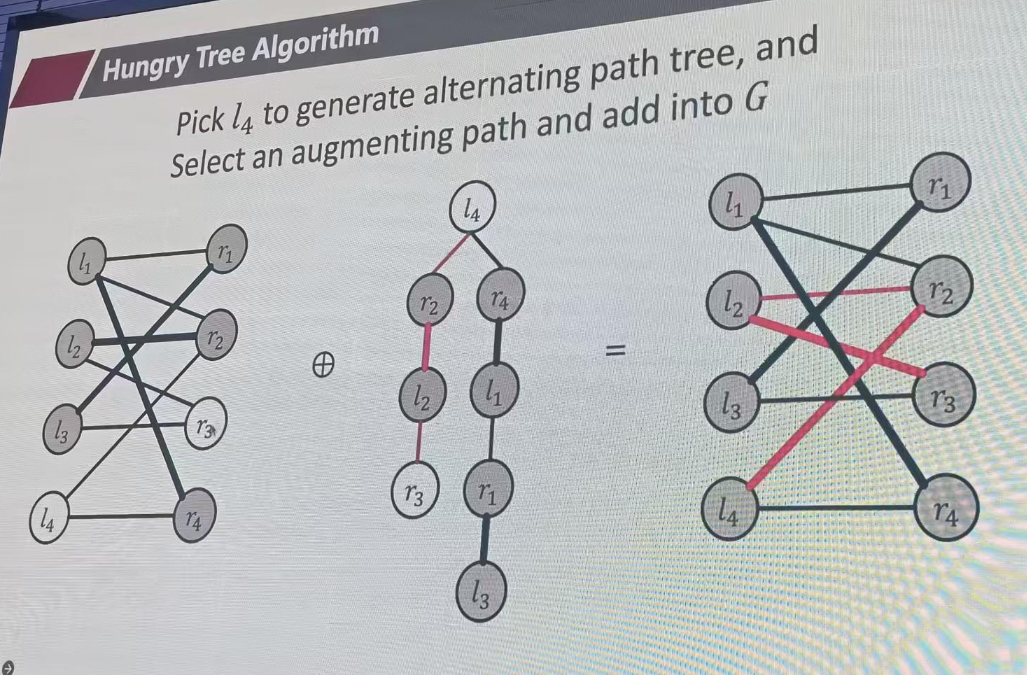
做小题怎么办
匈牙利算法既可以从空集(没有任何匹配边)开始,也可以从任意一个合法的初始匹配(只要这些边互不冲突)开始。无论你的起点是什么,只要按照算法逻辑不断寻找并反转增广路,最终都能达到最大匹配。
为什么可以从任意合法匹配开始?
这背后的根本原因依然是增广路定理(Berge 引理):一个匹配是最大匹配,当且仅当图中不存在任何增广路。
- 殊途同归:算法的终点是由"图中是否还存在增广路"决定的,而不是由"起点"决定的。
- 动态调整:如果你随机给定的初始匹配比较"笨拙"(占用了关键节点,导致后面的人没得选),匈牙利算法在后续为其他节点寻找增广路时,会通过递归回溯(也就是你提到的"匈牙利树"的生长过程)去尝试"腾位置"。如果当前占位的人能找到别的下家,他就会让出位置;如果实在腾不出来,算法才会放弃。这个过程会自动修正前期不合理的匹配,直到再也找不到增广路为止。
解析
我的答案
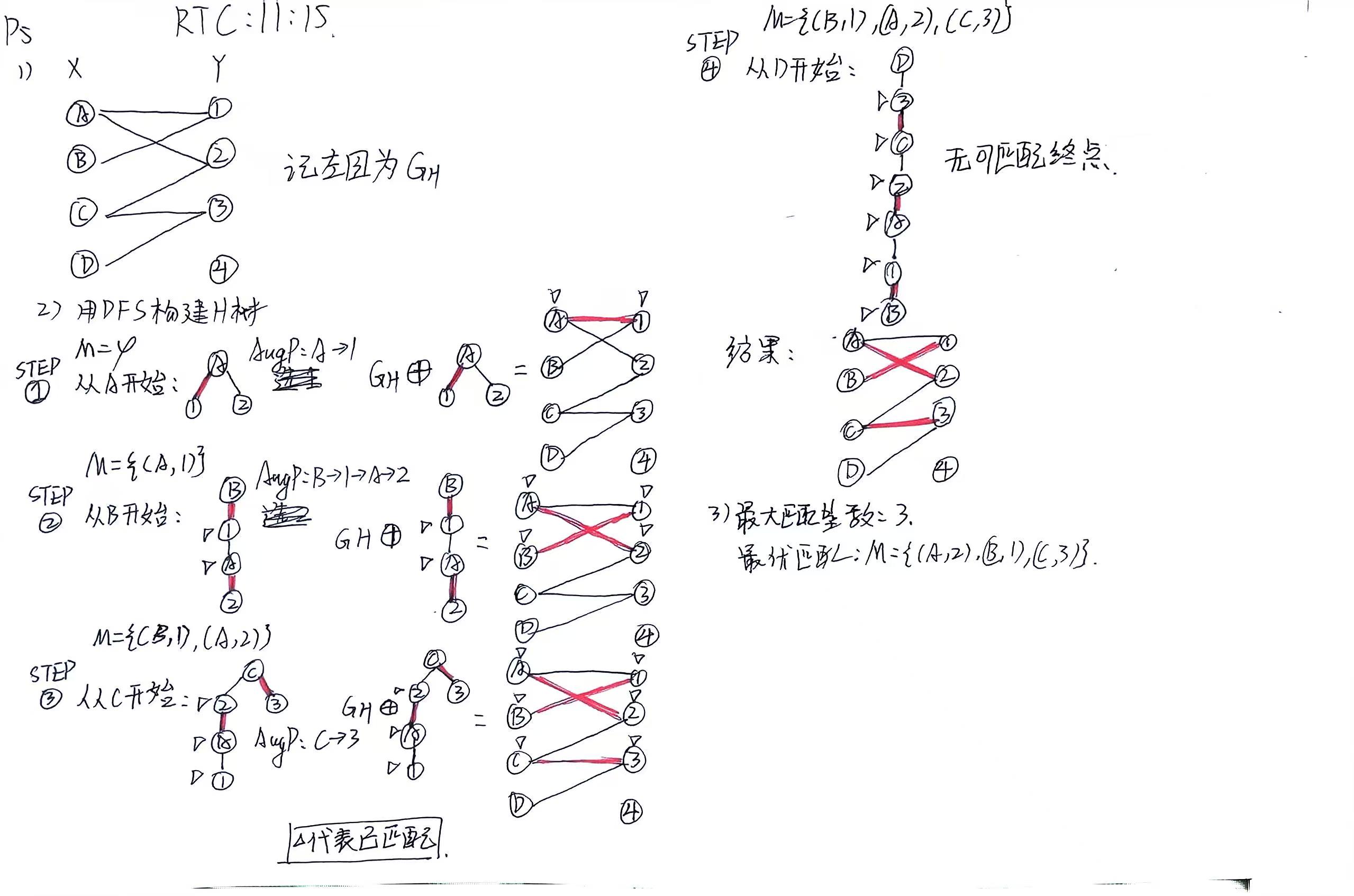
zn同学的答案 交叉验证通过