摘要
在车辆检测数据集中,人工标注框常见的问题包括框过大、框过小、车辆边界不贴合、不同标注人员尺度不一致等。这些问题会直接影响检测模型训练的收敛速度和边界框回归质量。文章的核心思想是:以人工 LabelMe 矩形框为先验,用 SAM3 在局部扩展区域内重新感知车辆实例,再通过置信度和 IoU 门控决定是否采用 SAM3 修正框,从而在保留人工标注稳定性的同时,提高标注尺度的一致性。
该方法不是完全替代人工标注,而是把 SAM3 作为"标注复核器":SAM3 只有在结果可信、且与原始标注差异合理时才更新框;否则保留原框。这样可以避免自动模型误检带来的标注污染。
1. 问题背景
车辆检测任务对标注框的一致性非常敏感。以固定摄像机场景为例,同一辆车在不同帧中可能由不同人工标注者处理,框的上下左右边界习惯会不同:
- 有些框包含较多阴影和路面背景;
- 有些框紧贴车身但漏掉后视镜、车轮或车尾;
- 小目标车辆容易被框得过大;
- 遮挡车辆容易出现边界尺度漂移;
- 类别相同但标注框风格不同,会让模型学习到不稳定的回归目标。
传统做法通常依赖人工返工或规则清洗,但效率低、主观性强。SAM3 具备较强的实例感知能力,可以在给定文本提示和图像区域的情况下生成车辆 mask,因此适合用于辅助修正已有矩形标注。
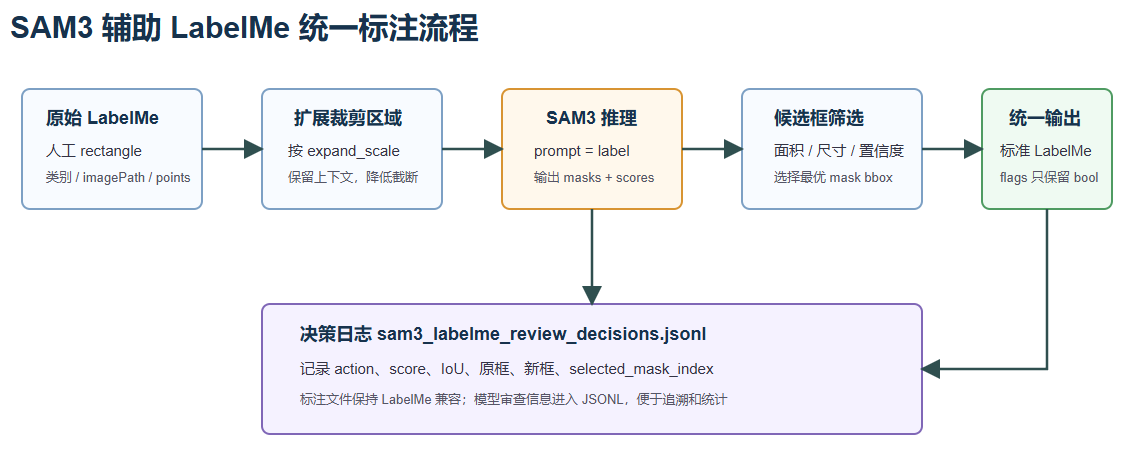
2. 方法核心思想
该脚本的输入是一批已有 LabelMe JSON 和对应图像。每个 rectangle shape 被视为一个候选车辆目标。算法不会直接在整图上搜索车辆,而是围绕原始人工框裁剪一个扩展区域,然后在局部区域内调用 SAM3。
这样做有三个好处:
- 人工框提供了强位置先验,减少 SAM3 被邻近车辆或背景干扰的概率。
- 扩展裁剪保留车辆周围上下文,避免原框过紧导致 SAM3 看不到完整轮廓。
- 最终仍通过原框 IoU 约束,避免 SAM3 结果偏离人工标注过远。
整体流程如下:
- 读取 LabelMe JSON;
- 遍历 rectangle 标注;
- 按
expand_scale扩展原框并裁剪图像区域; - 使用标签文本作为 SAM3 prompt;
- 从 SAM3 masks 中选择最优候选;
- 将候选 mask bbox 映射回原图坐标;
- 使用置信度和 IoU 规则判断是否更新;
- 保存标准 LabelMe JSON,同时写入决策日志。
3. SAM3 标注复核流程
对每一个人工矩形框,脚本先计算扩展裁剪框。假设原框为:
text
(x1, y1, x2, y2)扩展后得到局部 crop。SAM3 只在这个 crop 上推理,而不是整图推理。对于车辆类标注,prompt 通常就是 car、taxi 等标签文本,也可以通过 --prompt-map 单独指定。
SAM3 输出多个 mask 后,脚本会筛选候选:
- mask bbox 宽度必须大于
--min-w; - 高度必须大于
--min-h; - 面积必须大于
--min-area; - 如果存在 score,则优先选择 score 高的候选;
- score 相同或缺失时,倾向选择更靠近 crop 中心的候选。
最终得到一个 SAM3 候选框,并映射回原图坐标。
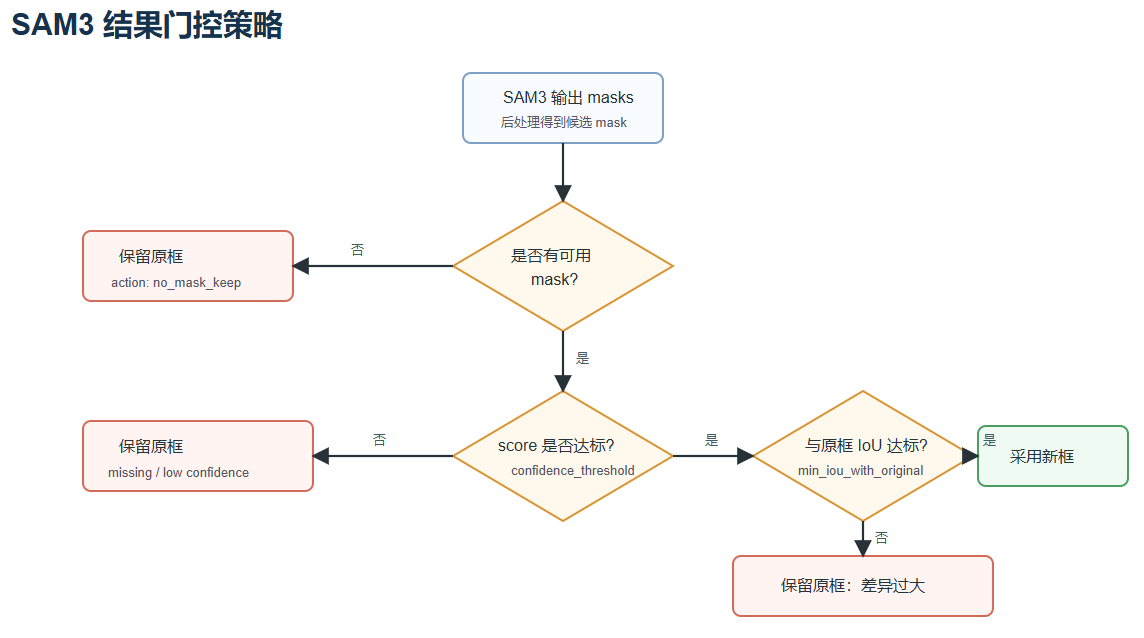
4. 决策门控:保守更新,而不是盲目覆盖
脚本并不会无条件采用 SAM3 的结果。它使用多级门控规则,确保自动修正足够稳健。
核心规则如下:
4.1 无可用 mask:保留原框
如果 SAM3 没有返回可用 mask,脚本不会修改原标注:
text
action = no_mask_keep这类情况常见于目标过小、遮挡严重、图像模糊或 prompt 与目标不匹配。
4.2 score 不可用或低于阈值:保留原框
如果返回结果没有置信度,默认保持谨慎,保留原框:
text
action = missing_score_keep如果 score 低于 --confidence-threshold,也保留原框:
text
action = low_confidence_keep只有当 score 足够高,才进入下一步。
4.3 与原框差异过大:保留原框
即便 SAM3 置信度高,也可能选中相邻车辆或背景中的其他物体。因此脚本会计算 SAM3 框与原始人工框的 IoU:
text
iou = area(intersection) / area(union)如果 IoU 低于 --min-iou-with-original,说明 SAM3 结果和人工框差异过大,脚本会保留原框:
text
action = large_difference_keep4.4 通过所有门控:采用 SAM3 新框
只有当候选 mask 质量合格、score 达标、且与原框 IoU 合理时,脚本才会更新 LabelMe points:
text
action = sam3_box这种保守策略适合批量清洗真实数据集,因为它优先保证不破坏原有标注。
5. 输出格式:保持 LabelMe 标准兼容
早期版本容易把 SAM3 审查信息写入 LabelMe shape 的 flags 字段,例如字符串、浮点数或数组。这会导致 LabelMe 在编辑标签时崩溃,因为 LabelMe 将 flags 作为复选框状态读取,只接受布尔值。
优化后的脚本遵循两个原则:
- LabelMe JSON 中的
flags只保留 bool; - SAM3 审查详情写入独立的 JSONL 决策日志。
LabelMe 输出保持标准结构:
json
{
"version": "5.0.1",
"flags": {},
"shapes": [
{
"label": "car",
"points": [[650.0, 394.0], [837.0, 539.0]],
"group_id": 1,
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "example.jpg",
"imageData": null,
"imageHeight": 1080,
"imageWidth": 1920
}决策日志保存更详细的信息,例如:
json
{
"action": "sam3_box",
"score": 0.9369,
"iou_with_original": 0.8174,
"original_box": [650.0, 394.0, 837.0, 539.0],
"new_box": [648.0, 397.0, 835.0, 537.0]
}这样既保证 LabelMe 可正常打开和保存,又保留了算法复核的可追溯性。
6. 多进程多 GPU 加速
SAM3 推理开销较大,单进程处理大量 LabelMe 文件会比较慢。脚本支持多进程和多 GPU 调度:
powershell
python review_labelme_with_sam3.py --gpus 2,3,4,5 --num-processes 8含义是:
- 使用 GPU
2,3,4,5; - 启动 8 个 worker;
- worker 按轮询方式分配到 GPU;
- 每个 worker 加载一份 SAM3 模型;
- 每个 worker 处理一部分 JSON 文件;
- worker 写独立日志,最后由主进程合并。
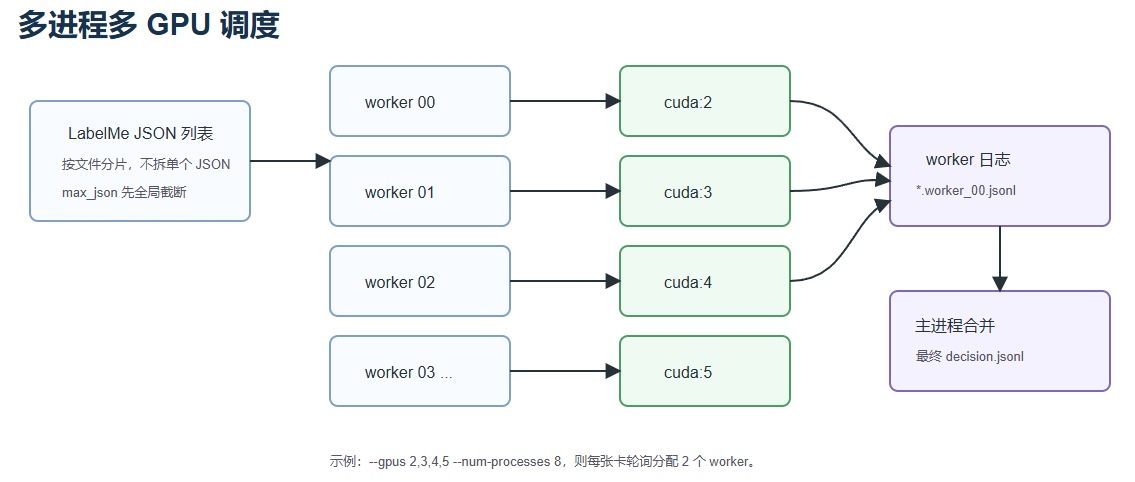
对于 --gpus 2,3,4,5 --num-processes 8,分配结果为:
text
worker 00 -> cuda:2
worker 01 -> cuda:3
worker 02 -> cuda:4
worker 03 -> cuda:5
worker 04 -> cuda:2
worker 05 -> cuda:3
worker 06 -> cuda:4
worker 07 -> cuda:5也就是每张卡两个进程。需要注意的是,每个进程都会加载一份 SAM3 模型,因此显存不足时应降低 --num-processes。
7. 推荐参数
可以从较保守的配置开始:
powershell
python review_labelme_with_sam3.py ^
--labelme-dir D:\dataset\labelme_car ^
--output-dir output\labelme_sam3_reviewed ^
--gpus 2,3,4,5 ^
--num-processes 8 ^
--expand-scale 1.5 ^
--confidence-threshold 0.8 ^
--min-iou-with-original 0.6如果希望 SAM3 更积极地修正框,可以降低:
text
--confidence-threshold
--min-iou-with-original如果希望更保守,可以提高这两个阈值。
8. 方法优势
8.1 标注风格更统一
SAM3 通过实例 mask 重新估计车辆边界,可以减少人工标注中"框大一点"或"框小一点"的个人差异。
8.2 风险可控
由于每次更新都要经过 score 和 IoU 门控,SAM3 不会轻易覆盖人工框。错误结果通常会被保守地丢弃。
8.3 兼容原始工作流
输出仍然是 LabelMe JSON,后续可以继续人工检查,也可以直接进入 YOLO、COCO 转换流程。
8.4 可追溯
每个 shape 的处理结果都会写入 JSONL,便于统计哪些框被更新、哪些框被保留,以及保留原因是什么。
9. 完整代码
python
from __future__ import annotations
import argparse
from concurrent.futures import ProcessPoolExecutor, as_completed
from dataclasses import dataclass
import json
import os
import shutil
from pathlib import Path
from typing import Any
import numpy as np
from PIL import Image
from synthcar.utils import IMAGE_EXTS
os.environ["KMP_DUPLICATE_LIB_OK"] = "True"
ROOT = Path(__file__).resolve().parent
DEFAULT_MODEL_DIR = ROOT / "facebook" / "sam3"
DEFAULT_OUTPUT_DIR = ROOT / "output" / "labelme_sam3_reviewed"
DEFAULT_DECISION_PATH = ROOT / "output" / "sam3_labelme_review_decisions.jsonl"
@dataclass
class ReviewStats:
json_files: int = 0
total_rectangles: int = 0
updated_count: int = 0
kept_count: int = 0
no_mask_count: int = 0
low_confidence_count: int = 0
missing_score_count: int = 0
large_difference_count: int = 0
def add_action(self, action: str) -> None:
if action == "sam3_box":
self.updated_count += 1
elif action == "no_mask_keep":
self.no_mask_count += 1
elif action == "missing_score_keep":
self.missing_score_count += 1
elif action == "low_confidence_keep":
self.low_confidence_count += 1
elif action == "large_difference_keep":
self.large_difference_count += 1
else:
self.kept_count += 1
def to_dict(self) -> dict[str, int]:
return {
"json_files": self.json_files,
"total_rectangles": self.total_rectangles,
"updated_count": self.updated_count,
"kept_count": self.kept_count,
"no_mask_count": self.no_mask_count,
"low_confidence_count": self.low_confidence_count,
"missing_score_count": self.missing_score_count,
"large_difference_count": self.large_difference_count,
}
@dataclass
class ShapeReviewResult:
action: str = "no_mask_keep"
score: float = 0.0
new_box: tuple[float, float, float, float] | None = None
selected_index: int | None = None
has_score: bool = False
iou_with_original: float = 1.0
score_key: str | None = None
expanded_crop_box: tuple[int, int, int, int] | None = None
def load_model(device: str, model_dir: Path):
try:
import torch
from transformers import Sam3Model, Sam3Processor
except ImportError as exc:
raise RuntimeError(
"Missing SAM3 runtime dependencies. Install/use a transformers version that provides "
"Sam3Model and Sam3Processor."
) from exc
model = Sam3Model.from_pretrained(str(model_dir), local_files_only=True).to(device)
processor = Sam3Processor.from_pretrained(str(model_dir), local_files_only=True)
model.eval()
return model, processor, torch
def tensor_to_numpy(value: Any) -> np.ndarray | None:
if value is None:
return None
if hasattr(value, "detach"):
return value.detach().cpu().numpy()
if hasattr(value, "cpu"):
return value.cpu().numpy()
if isinstance(value, list):
return np.asarray([tensor_to_numpy(v) if hasattr(v, "cpu") or hasattr(v, "detach") else v for v in value])
return np.asarray(value)
def run_sam3(
model: Any,
processor: Any,
torch_module: Any,
device: str,
image: Image.Image,
prompt: str,
sam_threshold: float,
mask_threshold: float,
) -> tuple[np.ndarray, np.ndarray | None, str | None]:
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device)
with torch_module.no_grad():
outputs = model(**inputs)
results = processor.post_process_instance_segmentation(
outputs,
threshold=sam_threshold,
mask_threshold=mask_threshold,
target_sizes=inputs.get("original_sizes").tolist(),
)[0]
masks = tensor_to_numpy(results.get("masks"))
if masks is None:
return np.empty((0, image.height, image.width), dtype=np.float32), None, None
if masks.ndim == 2:
masks = masks[np.newaxis, ...]
scores = None
score_key = None
for key in (
"scores",
"score",
"box_scores",
"bbox_scores",
"detection_scores",
"object_scores",
"confidence_scores",
"confidences",
"iou_scores",
):
if key in results:
scores = tensor_to_numpy(results[key])
score_key = key
break
if scores is not None:
scores = np.asarray(scores, dtype=np.float32).reshape(-1)
return masks, scores, score_key
def load_labelme(path: Path) -> dict[str, Any]:
with path.open("r", encoding="utf-8") as f:
data = json.load(f)
if not isinstance(data, dict):
raise ValueError(f"LabelMe JSON root is not an object: {path}")
return data
def save_labelme(path: Path, data: dict[str, Any]) -> None:
sanitize_labelme_flags(data)
path.parent.mkdir(parents=True, exist_ok=True)
with path.open("w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
f.write("\n")
def bool_flags(value: Any) -> dict[str, bool]:
if not isinstance(value, dict):
return {}
return {
str(key): val
for key, val in value.items()
if isinstance(val, bool) and not str(key).startswith("sam3_")
}
def sanitize_labelme_flags(data: dict[str, Any]) -> None:
data["flags"] = bool_flags(data.get("flags"))
shapes = data.get("shapes", [])
if not isinstance(shapes, list):
return
for shape in shapes:
if isinstance(shape, dict):
shape["flags"] = bool_flags(shape.get("flags"))
def copy_image_to_output(image_path: Path, out_json_path: Path) -> Path:
out_image_path = out_json_path.with_name(image_path.name)
out_image_path.parent.mkdir(parents=True, exist_ok=True)
if image_path.resolve() != out_image_path.resolve():
shutil.copy2(image_path, out_image_path)
return out_image_path
def find_image_path(json_path: Path, data: dict[str, Any]) -> Path | None:
image_path = data.get("imagePath")
candidates: list[Path] = []
if isinstance(image_path, str) and image_path.strip():
image_ref = Path(image_path)
if image_ref.is_absolute():
candidates.append(image_ref)
else:
candidates.append(json_path.parent / image_ref)
for ext in IMAGE_EXTS:
candidates.append(json_path.with_suffix(ext))
seen: set[Path] = set()
for candidate in candidates:
candidate = candidate.resolve()
if candidate in seen:
continue
seen.add(candidate)
if candidate.exists():
return candidate
return None
def rectangle_box(shape: dict[str, Any], image_size: tuple[int, int]) -> tuple[float, float, float, float] | None:
if shape.get("shape_type") != "rectangle":
return None
points = shape.get("points")
if not isinstance(points, list) or len(points) < 2:
return None
try:
xs = [float(point[0]) for point in points[:2]]
ys = [float(point[1]) for point in points[:2]]
except (TypeError, ValueError, IndexError):
return None
width, height = image_size
x1 = max(0.0, min(float(width), min(xs)))
y1 = max(0.0, min(float(height), min(ys)))
x2 = max(0.0, min(float(width), max(xs)))
y2 = max(0.0, min(float(height), max(ys)))
if x2 <= x1 or y2 <= y1:
return None
return x1, y1, x2, y2
def expand_box(
box: tuple[float, float, float, float],
image_size: tuple[int, int],
scale: float,
) -> tuple[int, int, int, int] | None:
x1, y1, x2, y2 = box
width, height = image_size
cx = (x1 + x2) / 2.0
cy = (y1 + y2) / 2.0
new_w = max(1.0, (x2 - x1) * scale)
new_h = max(1.0, (y2 - y1) * scale)
ex1 = max(0, int(np.floor(cx - new_w / 2.0)))
ey1 = max(0, int(np.floor(cy - new_h / 2.0)))
ex2 = min(width, int(np.ceil(cx + new_w / 2.0)))
ey2 = min(height, int(np.ceil(cy + new_h / 2.0)))
if ex2 <= ex1 or ey2 <= ey1:
return None
return ex1, ey1, ex2, ey2
def mask_bbox(mask: np.ndarray, threshold: float = 0.5) -> tuple[int, int, int, int] | None:
mask_bool = mask > threshold
if not np.any(mask_bool):
return None
ys, xs = np.where(mask_bool)
return int(xs.min()), int(ys.min()), int(xs.max()) + 1, int(ys.max()) + 1
def box_area(box: tuple[int, int, int, int]) -> int:
return max(0, box[2] - box[0]) * max(0, box[3] - box[1])
def box_iou(box_a: tuple[float, float, float, float], box_b: tuple[float, float, float, float]) -> float:
ax1, ay1, ax2, ay2 = box_a
bx1, by1, bx2, by2 = box_b
inter_x1 = max(ax1, bx1)
inter_y1 = max(ay1, by1)
inter_x2 = min(ax2, bx2)
inter_y2 = min(ay2, by2)
inter_w = max(0.0, inter_x2 - inter_x1)
inter_h = max(0.0, inter_y2 - inter_y1)
inter_area = inter_w * inter_h
area_a = max(0.0, ax2 - ax1) * max(0.0, ay2 - ay1)
area_b = max(0.0, bx2 - bx1) * max(0.0, by2 - by1)
union = area_a + area_b - inter_area
if union <= 0:
return 0.0
return inter_area / union
def select_best_mask(
masks: np.ndarray,
scores: np.ndarray | None,
crop_size: tuple[int, int],
min_w: int,
min_h: int,
min_area: int,
allow_missing_score: bool,
) -> tuple[tuple[int, int, int, int], float, int, bool] | None:
crop_w, crop_h = crop_size
center_x = crop_w / 2.0
center_y = crop_h / 2.0
diagonal = max(1.0, float((crop_w ** 2 + crop_h ** 2) ** 0.5))
candidates: list[tuple[float, float, int, tuple[int, int, int, int], int, bool]] = []
for index, mask in enumerate(masks):
bbox = mask_bbox(mask)
if bbox is None:
continue
x1, y1, x2, y2 = bbox
w = x2 - x1
h = y2 - y1
area = box_area(bbox)
if w < min_w or h < min_h or area < min_area:
continue
has_score = scores is not None and index < len(scores)
if has_score:
score = float(scores[index])
elif allow_missing_score:
score = 1.0
else:
score = 0.0
box_cx = (x1 + x2) / 2.0
box_cy = (y1 + y2) / 2.0
center_distance = ((box_cx - center_x) ** 2 + (box_cy - center_y) ** 2) ** 0.5 / diagonal
candidates.append((score, -center_distance, area, bbox, index, has_score))
if not candidates:
return None
score, _, _, bbox, index, has_score = max(candidates, key=lambda item: (item[0], item[1], item[2]))
return bbox, score, index, has_score
def crop_box_to_image_box(
bbox: tuple[int, int, int, int],
crop_box: tuple[int, int, int, int],
image_size: tuple[int, int],
pad: int,
) -> tuple[float, float, float, float] | None:
cx1, cy1, _, _ = crop_box
width, height = image_size
x1 = max(0, cx1 + bbox[0] - pad)
y1 = max(0, cy1 + bbox[1] - pad)
x2 = min(width, cx1 + bbox[2] + pad)
y2 = min(height, cy1 + bbox[3] + pad)
if x2 <= x1 or y2 <= y1:
return None
return float(x1), float(y1), float(x2), float(y2)
def parse_prompt_map(values: list[str] | None) -> dict[str, str]:
result: dict[str, str] = {}
for value in values or []:
if "=" in value:
label, prompt = value.split("=", 1)
elif ":" in value:
label, prompt = value.split(":", 1)
else:
continue
label = label.strip()
prompt = prompt.strip()
if label and prompt:
result[label] = prompt
return result
def prompt_for_label(label: str, prompt_map: dict[str, str], template: str) -> str:
if label in prompt_map:
return prompt_map[label]
return template.format(label=label)
def write_decision(decision_path: Path, record: dict[str, Any]) -> None:
decision_path.parent.mkdir(parents=True, exist_ok=True)
with decision_path.open("a", encoding="utf-8") as f:
json.dump(record, f, ensure_ascii=False)
f.write("\n")
def parse_gpu_ids(value: str | None) -> list[int]:
if value is None or not value.strip():
return []
gpu_ids: list[int] = []
for item in value.split(","):
item = item.strip()
if not item:
continue
try:
gpu_id = int(item)
except ValueError as exc:
raise ValueError(f"Invalid GPU id in --gpus: {item}") from exc
if gpu_id < 0:
raise ValueError("--gpus must contain non-negative GPU ids")
gpu_ids.append(gpu_id)
if not gpu_ids:
raise ValueError("--gpus did not contain any GPU ids")
return gpu_ids
def build_worker_devices(args: argparse.Namespace) -> list[str]:
gpu_ids = parse_gpu_ids(args.gpus)
if gpu_ids:
return [f"cuda:{gpu_id}" for gpu_id in gpu_ids]
if args.device:
return [args.device]
import torch
return ["cuda" if torch.cuda.is_available() else "cpu"]
def split_paths(paths: list[Path], num_chunks: int) -> list[list[Path]]:
chunks = [[] for _ in range(num_chunks)]
for index, path in enumerate(paths):
chunks[index % num_chunks].append(path)
return chunks
def worker_decision_path(decision_path: Path, worker_index: int) -> Path:
suffix = decision_path.suffix or ".jsonl"
stem = decision_path.stem if decision_path.suffix else decision_path.name
return decision_path.with_name(f"{stem}.worker_{worker_index:02d}{suffix}")
def merge_decision_logs(decision_path: Path, worker_paths: list[Path]) -> None:
decision_path.parent.mkdir(parents=True, exist_ok=True)
with decision_path.open("w", encoding="utf-8") as output:
for worker_path in worker_paths:
if not worker_path.exists():
continue
with worker_path.open("r", encoding="utf-8") as source:
shutil.copyfileobj(source, output)
def merge_stats(stats_items: list[dict[str, int]]) -> dict[str, int]:
merged: dict[str, int] = {}
for stats in stats_items:
for key, value in stats.items():
merged[key] = merged.get(key, 0) + int(value)
return merged
def review_shape_with_sam3(
args: argparse.Namespace,
model: Any,
processor: Any,
torch_module: Any,
device: str,
image: Image.Image,
original_box: tuple[float, float, float, float],
crop_box: tuple[int, int, int, int],
prompt: str,
) -> ShapeReviewResult:
crop = image.crop(crop_box).convert("RGB")
masks, scores, score_key = run_sam3(
model=model,
processor=processor,
torch_module=torch_module,
device=device,
image=crop,
prompt=prompt,
sam_threshold=args.sam_threshold,
mask_threshold=args.mask_threshold,
)
selected = select_best_mask(
masks=masks,
scores=scores,
crop_size=crop.size,
min_w=args.min_w,
min_h=args.min_h,
min_area=args.min_area,
allow_missing_score=args.allow_missing_score,
)
result = ShapeReviewResult(
action="no_mask_keep",
new_box=original_box,
score_key=score_key,
expanded_crop_box=crop_box,
)
if selected is None:
return result
bbox_crop, score, selected_index, has_score = selected
result.score = float(score)
result.selected_index = selected_index
result.has_score = bool(has_score)
if not has_score and not args.allow_missing_score:
result.action = "missing_score_keep"
return result
if score < args.confidence_threshold:
result.action = "low_confidence_keep"
return result
mapped_box = crop_box_to_image_box(bbox_crop, crop_box, image.size, args.pad)
if mapped_box is None:
result.action = "invalid_box_keep"
return result
result.iou_with_original = box_iou(mapped_box, original_box)
if result.iou_with_original < args.min_iou_with_original:
result.action = "large_difference_keep"
return result
result.action = "sam3_box"
result.new_box = mapped_box
return result
def save_debug_crop(
debug_crop_dir: Path | None,
image: Image.Image,
crop_box: tuple[int, int, int, int],
json_path: Path,
shape_index: int,
label: str,
) -> None:
if debug_crop_dir is None:
return
debug_crop_dir.mkdir(parents=True, exist_ok=True)
crop = image.crop(crop_box).convert("RGB")
crop.save(debug_crop_dir / f"{json_path.stem}_{shape_index:04d}_{label}.jpg", quality=95)
def apply_review_result(shape: dict[str, Any], result: ShapeReviewResult) -> None:
if result.action == "sam3_box" and result.new_box is not None:
shape["points"] = [
[round(result.new_box[0], 2), round(result.new_box[1], 2)],
[round(result.new_box[2], 2), round(result.new_box[3], 2)],
]
shape["flags"] = bool_flags(shape.get("flags"))
def make_decision_record(
args: argparse.Namespace,
json_path: Path,
image_path: Path,
shape_index: int,
label: str,
prompt: str,
original_box: tuple[float, float, float, float],
result: ShapeReviewResult,
) -> dict[str, Any]:
new_box = result.new_box or original_box
return {
"json": str(json_path),
"image": str(image_path),
"shape_index": shape_index,
"label": label,
"prompt": prompt,
"action": result.action,
"score": round(float(result.score), 4),
"score_key": result.score_key,
"score_available": bool(result.has_score),
"confidence_threshold": args.confidence_threshold,
"iou_with_original": round(float(result.iou_with_original), 4),
"min_iou_with_original": args.min_iou_with_original,
"selected_mask_index": result.selected_index,
"original_box": [round(v, 2) for v in original_box],
"expanded_crop_box": list(result.expanded_crop_box) if result.expanded_crop_box else None,
"new_box": [round(v, 2) for v in new_box],
}
def process_one_json(
args: argparse.Namespace,
model: Any,
processor: Any,
torch_module: Any,
device: str,
prompt_map: dict[str, str],
debug_crop_dir: Path | None,
json_path: Path,
json_index: int,
total_json: int,
labelme_dir: Path,
output_dir: Path,
decision_path: Path,
worker_name: str,
stats: ReviewStats,
) -> None:
data = load_labelme(json_path)
image_path = find_image_path(json_path, data)
out_json_path = output_dir / json_path.relative_to(labelme_dir)
if image_path is None:
print(f"[{worker_name} {json_index}/{total_json}] image not found: {json_path}")
save_labelme(out_json_path, data)
return
out_image_path = copy_image_to_output(image_path, out_json_path)
data["imagePath"] = out_image_path.name
with Image.open(image_path) as image:
image = image.convert("RGB")
shapes = data.get("shapes", [])
if not isinstance(shapes, list):
save_labelme(out_json_path, data)
return
for shape_index, shape in enumerate(shapes, start=1):
if args.max_shapes is not None and stats.total_rectangles >= args.max_shapes:
break
if not isinstance(shape, dict):
continue
original_box = rectangle_box(shape, image.size)
if original_box is None:
continue
stats.total_rectangles += 1
label = str(shape.get("label", "")).strip() or "object"
crop_box = expand_box(original_box, image.size, args.expand_scale)
if crop_box is None:
stats.kept_count += 1
continue
prompt = prompt_for_label(label, prompt_map, args.prompt_template)
result = review_shape_with_sam3(
args=args,
model=model,
processor=processor,
torch_module=torch_module,
device=device,
image=image,
original_box=original_box,
crop_box=crop_box,
prompt=prompt,
)
if result.expanded_crop_box is not None:
save_debug_crop(debug_crop_dir, image, result.expanded_crop_box, json_path, shape_index, label)
apply_review_result(shape, result)
stats.add_action(result.action)
record = make_decision_record(
args=args,
json_path=json_path,
image_path=image_path,
shape_index=shape_index,
label=label,
prompt=prompt,
original_box=original_box,
result=result,
)
write_decision(decision_path, record)
print(
f"[{worker_name} {json_index}/{total_json} #{shape_index}] "
f"{result.action} {json_path.name} {label} score={result.score:.3f}"
)
save_labelme(out_json_path, data)
def process_json_paths(
args: argparse.Namespace,
json_paths: list[Path],
worker_name: str,
device: str,
decision_path: Path,
) -> dict[str, int]:
model_dir = args.model_dir.resolve()
labelme_dir = args.labelme_dir.resolve()
output_dir = args.output_dir.resolve()
debug_crop_dir = args.debug_crop_dir.resolve() if args.debug_crop_dir else None
print(f"[{worker_name}] Using device: {device}")
print(f"[{worker_name}] Loading SAM3 from {model_dir}")
model, processor, torch_module = load_model(device, model_dir)
prompt_map = parse_prompt_map(args.prompt_map)
stats = ReviewStats(json_files=len(json_paths))
for json_index, json_path in enumerate(json_paths, start=1):
process_one_json(
args=args,
model=model,
processor=processor,
torch_module=torch_module,
device=device,
prompt_map=prompt_map,
debug_crop_dir=debug_crop_dir,
json_path=json_path,
json_index=json_index,
total_json=len(json_paths),
labelme_dir=labelme_dir,
output_dir=output_dir,
decision_path=decision_path,
worker_name=worker_name,
stats=stats,
)
print(
f"[{worker_name}] Done. Reviewed {stats.total_rectangles} rectangle(s), "
f"used SAM3 boxes {stats.updated_count}, no-mask-kept {stats.no_mask_count}, "
f"missing-score-kept {stats.missing_score_count}, "
f"low-confidence-kept {stats.low_confidence_count}, "
f"large-difference-kept {stats.large_difference_count}, other-kept {stats.kept_count}."
)
return stats.to_dict()
def process_worker(
args: argparse.Namespace,
json_paths: list[Path],
worker_index: int,
device: str,
decision_path: Path,
) -> dict[str, int]:
worker_name = f"worker-{worker_index:02d}/{device}"
return process_json_paths(args, json_paths, worker_name, device, decision_path)
def process_dataset(args: argparse.Namespace) -> None:
model_dir = args.model_dir.resolve()
labelme_dir = args.labelme_dir.resolve()
output_dir = args.output_dir.resolve()
decision_path = args.decision_jsonl.resolve()
if not model_dir.exists():
raise FileNotFoundError(f"SAM3 model directory does not exist: {model_dir}")
if not labelme_dir.exists():
raise FileNotFoundError(f"LabelMe directory does not exist: {labelme_dir}")
if args.num_processes < 1:
raise ValueError("--num-processes must be >= 1")
if args.gpus and args.device:
raise ValueError("Use either --gpus or --device, not both")
json_paths = sorted(labelme_dir.rglob("*.json"))
if args.max_json is not None:
json_paths = json_paths[: args.max_json]
if not json_paths:
print(f"No LabelMe JSON files found in {labelme_dir}")
return
if decision_path.exists():
decision_path.unlink()
output_dir.mkdir(parents=True, exist_ok=True)
devices = build_worker_devices(args)
worker_count = min(args.num_processes, len(json_paths))
chunks = split_paths(json_paths, worker_count)
worker_paths = [worker_decision_path(decision_path, index) for index in range(worker_count)]
for path in worker_paths:
if path.exists():
path.unlink()
print(f"LabelMe JSON files: {len(json_paths)}")
print(f"Output: {output_dir}")
print(f"Processes: {worker_count}")
print(f"Devices: {', '.join(devices)}")
if worker_count > len(devices):
per_device: dict[str, int] = {}
for index in range(worker_count):
device = devices[index % len(devices)]
per_device[device] = per_device.get(device, 0) + 1
print("Workers per device: " + ", ".join(f"{device}={count}" for device, count in per_device.items()))
if worker_count == 1:
stats_items = [
process_worker(args, chunks[0], 0, devices[0], worker_paths[0])
]
else:
stats_items = []
with ProcessPoolExecutor(max_workers=worker_count) as executor:
futures = []
for worker_index, chunk in enumerate(chunks):
device = devices[worker_index % len(devices)]
futures.append(
executor.submit(
process_worker,
args,
chunk,
worker_index,
device,
worker_paths[worker_index],
)
)
for future in as_completed(futures):
stats_items.append(future.result())
merge_decision_logs(decision_path, worker_paths)
stats = merge_stats(stats_items)
print(
f"Done. Reviewed {stats.get('total_rectangles', 0)} rectangle(s), "
f"used SAM3 boxes {stats.get('updated_count', 0)}, "
f"no-mask-kept {stats.get('no_mask_count', 0)}, "
f"missing-score-kept {stats.get('missing_score_count', 0)}, "
f"low-confidence-kept {stats.get('low_confidence_count', 0)}, "
f"large-difference-kept {stats.get('large_difference_count', 0)}, "
f"other-kept {stats.get('kept_count', 0)}."
)
print(f"Reviewed LabelMe output: {output_dir}")
print(f"Decision log: {decision_path}")
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description="Review LabelMe rectangles with local SAM3 masks.")
parser.add_argument("--model-dir", type=Path, default=DEFAULT_MODEL_DIR, help="Local SAM3 model directory.")
parser.add_argument("--labelme-dir", type=Path, default="./Labelme_VOC", help="Directory containing LabelMe JSON files.")
parser.add_argument("--output-dir", type=Path, default=DEFAULT_OUTPUT_DIR, help="Output LabelMe dataset directory.")
parser.add_argument("--decision-jsonl", type=Path, default=DEFAULT_DECISION_PATH, help="Path to JSONL decision log.")
parser.add_argument("--debug-crop-dir", type=Path, default=None, help="Optional directory to save expanded crops.")
parser.add_argument("--expand-scale", type=float, default=1.5, help="Scale factor used to expand each annotation box.")
parser.add_argument("--prompt-template", default="{label}", help="Prompt template for SAM3, e.g. '{label}' or '{label} vehicle'.")
parser.add_argument("--prompt-map", nargs="*", default=None, help="Optional label prompts, e.g. taxi='taxi' car='car'.")
parser.add_argument("--sam-threshold", type=float, default=0.7, help="SAM3 instance threshold.")
parser.add_argument("--mask-threshold", type=float, default=0.7, help="SAM3 mask threshold.")
parser.add_argument("--confidence-threshold", type=float, default=0.8, help="Use SAM3 box only when score is at least this value.")
parser.add_argument(
"--min-iou-with-original",
type=float,
default=0.6,
help="Keep original box when SAM3 box IoU with original is below this value.",
)
parser.add_argument(
"--allow-missing-score",
action="store_true",
help="Treat masks without returned box/detection score as confidence 1.0. Defaults to keeping them unchanged.",
)
parser.add_argument("--min-w", type=int, default=10, help="Minimum mask bbox width in expanded crop.")
parser.add_argument("--min-h", type=int, default=10, help="Minimum mask bbox height in expanded crop.")
parser.add_argument("--min-area", type=int, default=100, help="Minimum mask bbox area in expanded crop.")
parser.add_argument("--pad", type=int, default=0, help="Padding added to SAM3 mask bbox before writing LabelMe box.")
parser.add_argument("--device", default=None, help="Single-process device override, e.g. cuda, cuda:0, or cpu.")
parser.add_argument("--gpus", default="4,5,6,7", help="Comma-separated GPU ids for multiprocessing, e.g. '2,3,4,5'.")
parser.add_argument("--num-processes", type=int, default=16, help="Number of worker processes. With --gpus, workers are round-robin assigned to GPUs.")
parser.add_argument("--max-json", type=int, default=None, help="Optional JSON limit for testing.")
parser.add_argument("--max-shapes", type=int, default=None, help="Optional total rectangle limit for testing.")
return parser.parse_args()
def main() -> None:
process_dataset(parse_args())
if __name__ == "__main__":
main()10. 结论
review_labelme_with_sam3.py 提供了一种实用的半自动标注统一方案:它以人工 LabelMe 框为基础,用 SAM3 进行局部实例感知,再通过置信度和 IoU 门控保守更新标注。该方法兼顾了自动化效率和人工标注稳定性,适合固定摄像机场景下的大规模车辆检测数据清洗。
从工程角度看,这种方法的关键不是"让 SAM3 完全替代人工",而是让 SAM3 成为可控的标注复核工具:能改的地方自动统一,不确定的地方保留原框,并用日志记录每一次决策。