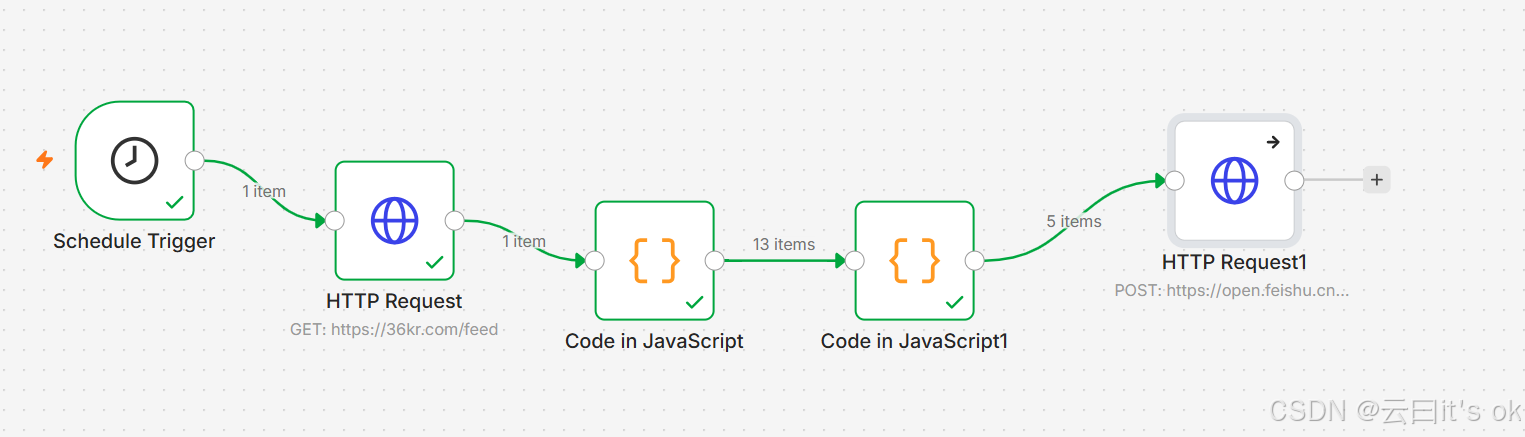
运行效果
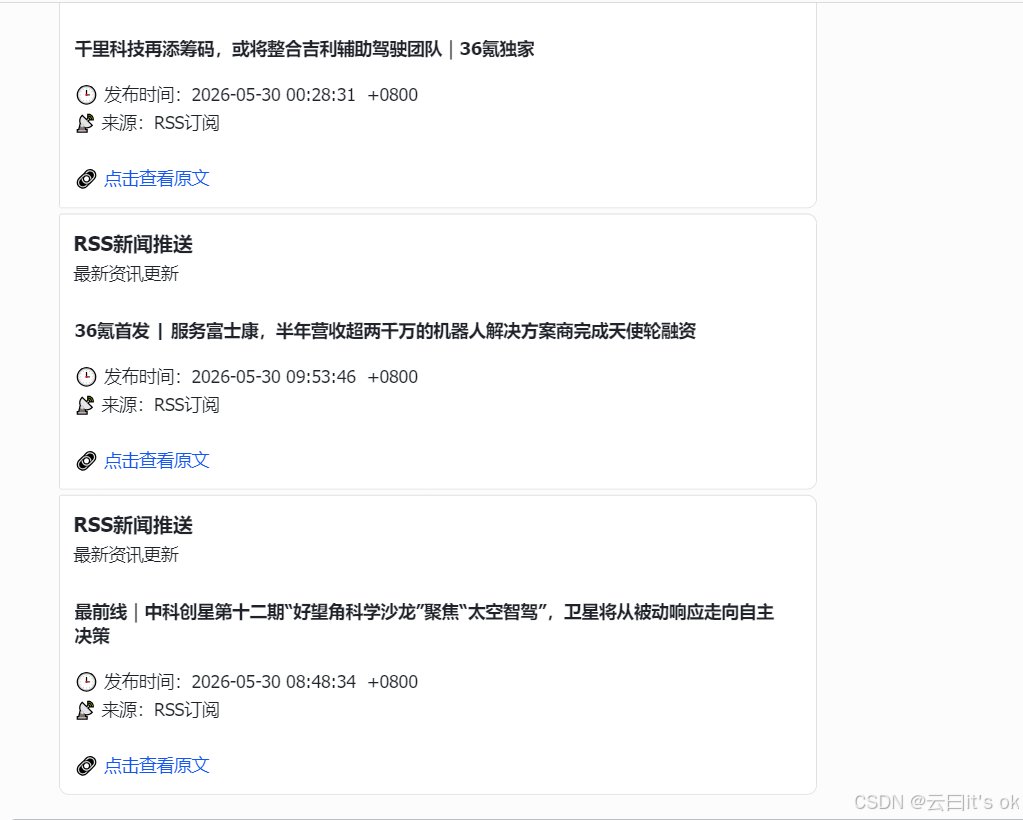
点击查看原文,可以跳转到新闻的36氪链接。
n8n工作流
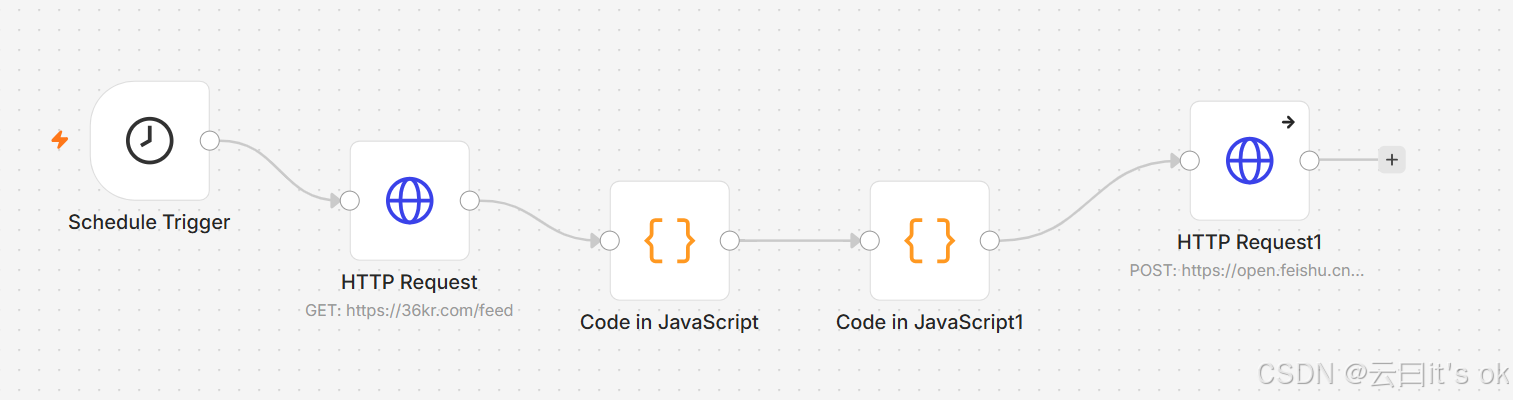
主要功能
实现从36氪上爬取新闻,并筛选和AI相关的AI类新闻,最终将新闻的结果,推送到手机端。
工作流搭建与配置
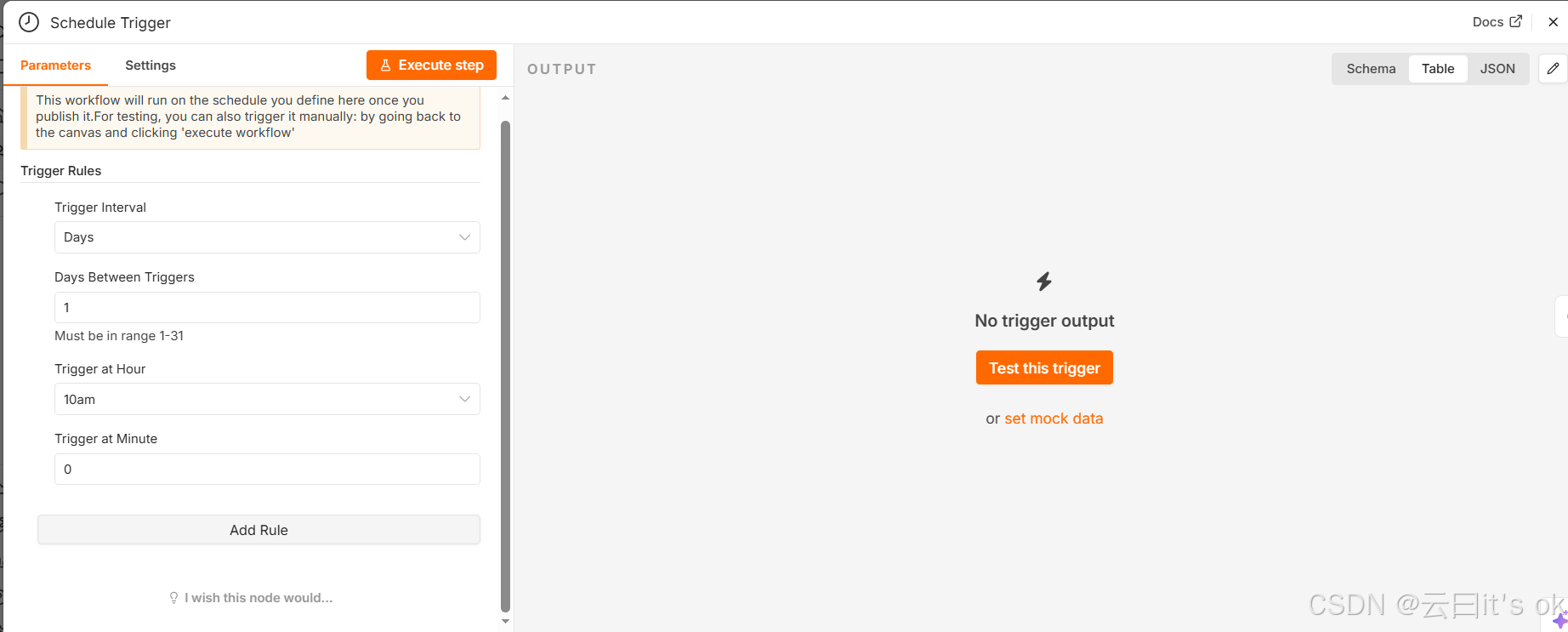
定时器
设置成定时触发流程,可以选择按日/分钟/月/周等等,选择范围还是很广的。我设置成了按天,每天触发一次,时间为上午10点。
Http请求节点
后面用http请求节点,主要是为了抓取36氪的新闻。RSS是一个能让你在一个地方订阅各种感兴趣网站的工具
这里网址需要填36氪新闻的RSS订阅网址,也就是https://36kr.com/feed
节点配置信息如下:
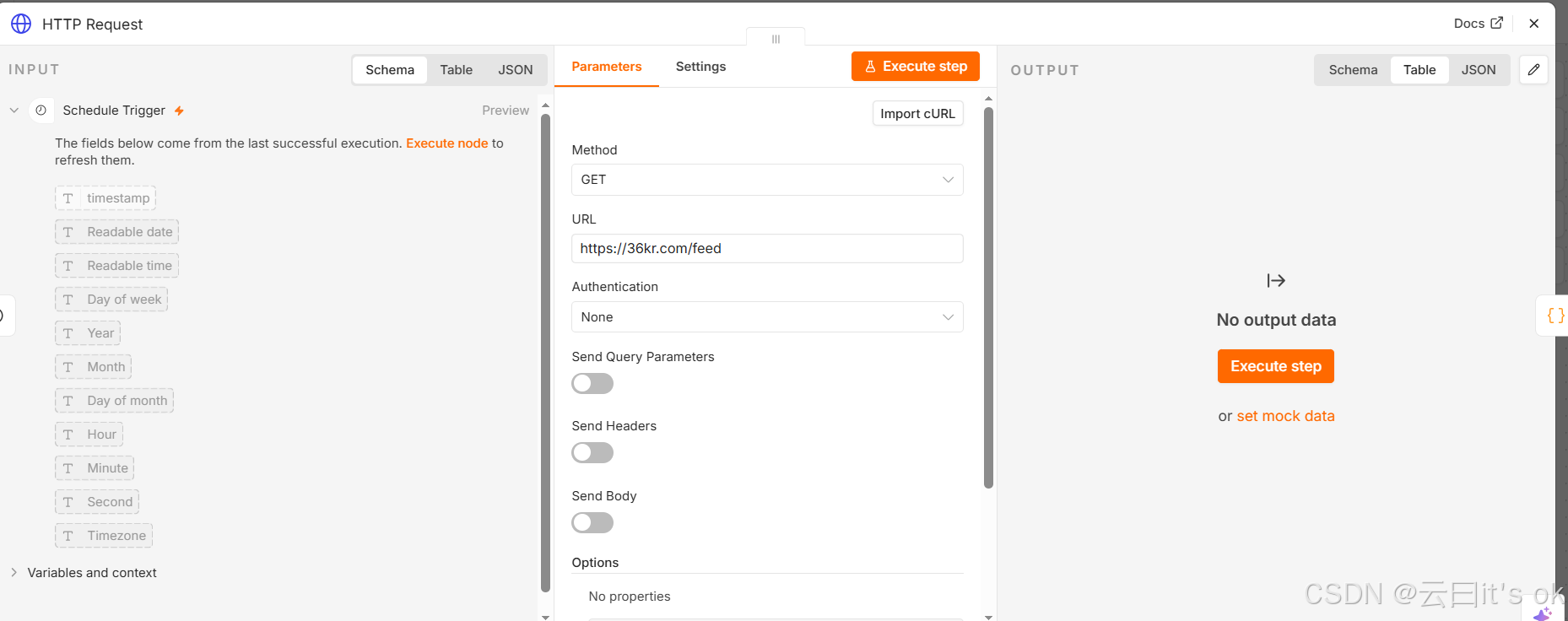
只需要将method设置为get,然后网址url设置成36氪新闻的RSS订阅地址就行啦。
可以点击Execute Step去测试一下,结果为:
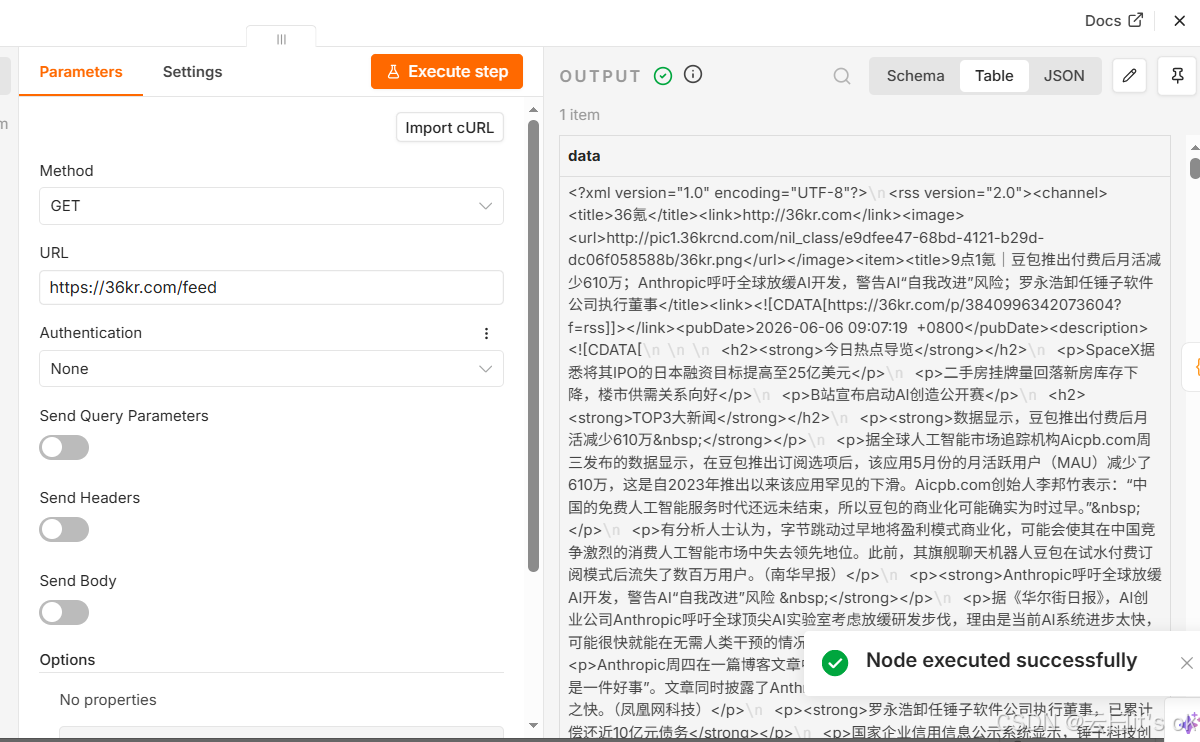
AI类新闻筛选
由于返回的数据有很多篇新闻,所以后面加了一个Code节点,来从中筛选数据。这里采用关键词匹配,也就是如果返回的结果中,在title标题、content内容中,如果包含'AI', '人工智能', '大模型', 'LLM', 'GPT', 'Claude', 'Gemini','通义千问', '文心一言', '豆包', '讯飞星火', 'AI Agent','机器学习', '深度学习', '神经网络', 'NLP', 'CV', 'AIGC'等词汇,就认为是AI类新闻。
这些关键词可以根据个人需求,再做一些增补。或者再增加一些语义相关的匹配去检索和AI相关的新闻,例如词向量的余弦相似度等。
代码选择使用JavaScript语言,对应的代码如下:
javascript
try {
const rssData = $input.item.json.data || $input.item.json;
if (!rssData) {
console.log('RSS数据为空');
return [];
}
function parseAndFilterRSS(xmlString) {
const items = [];
// 提取所有item
const itemMatches = xmlString.match(/<item[^>]*>[\s\S]*?<\/item>/gi);
if (!itemMatches) {
console.log('未找到RSS item');
return items;
}
const aiKeywords = [
'AI', '人工智能', '大模型', 'LLM', 'GPT', 'Claude', 'Gemini',
'通义千问', '文心一言', '豆包', '讯飞星火', 'AI Agent',
'机器学习', '深度学习', '神经网络', 'NLP', 'CV', 'AIGC'
];
const lowerKeywords = aiKeywords.map(k => k.toLowerCase());
for (const itemXml of itemMatches) {
const title = (itemXml.match(/<title[^>]*>([\s\S]*?)<\/title>/) || [])[1] || '';
const link = (itemXml.match(/<link[^>]*>([\s\S]*?)<\/link>/) || [])[1] || '';
const contentSnippet = (itemXml.match(/<description[^>]*>([\s\S]*?)<\/description>/) || [])[1] || '';
const pubDate = (itemXml.match(/<pubDate[^>]*>([\s\S]*?)<\/pubDate>/) || [])[1] || '';
const fullText = (title + ' ' + contentSnippet).toLowerCase();
const isAiRelated = lowerKeywords.some(keyword => fullText.includes(keyword));
if (isAiRelated) {
items.push({
title: title.trim(),
link: link.trim(),
contentSnippet: contentSnippet.trim(),
pubDate: pubDate.trim()
});
}
}
return items;
}
const result = parseAndFilterRSS(rssData);
console.log('AI相关新闻数量:', result.length);
return result;
} catch (e) {
console.error('RSS解析/过滤出错:', e.message);
return [];
}配置执行结果如下:
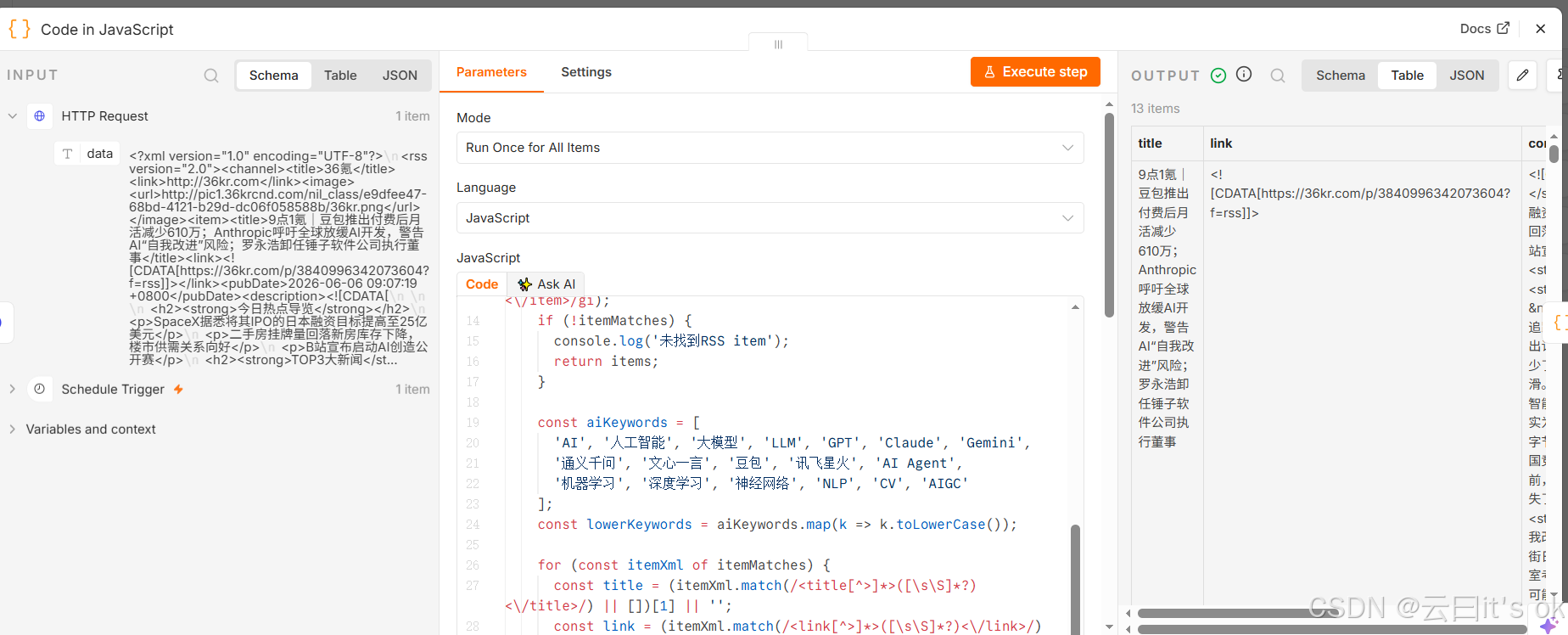
数据清洗节点
因为后面在飞书上,想要实现推送,并且用户可以点击推送的链接,跳转到对应的36氪新闻网址上。而我之前在实现的时候,如果不加数据清洗节点,则遇到两个问题:1)飞书的推送有数量限制,当短时间一次性推送数量过多时,会出现警告语限制。2)原来抓取的新闻数据中,link链接是类似于<!CDATA\[https://36kr.com/p/3840996342073604?f=rss]>这样的数据,需要再从中做一下处理,才能解析出网页。
所以,为了解决这两个问题,我又加了一个数据清洗节点,选择的是code节点,然后用JavaScript代码,对应代码如下:
javascript
// 拿到输入的所有数据
const items = $input.all();
// 定义清洗CDATA的函数(修复版)
const cleanCdata = (str) => {
if (!str) return '';
// 去掉 <![CDATA[ 和 ]]> 标签,保留内容
return str.replace(/<!\[CDATA\[/g, '').replace(/]]>/g, '').trim();
};
// 对每一条数据进行清洗
const processed = items.map(item => {
const title = cleanCdata(item.json.title);
const link = cleanCdata(item.json.link);
const pubDate = item.json.pubDate || '未知时间';
return {
title,
link,
pubDate
};
});
// 输出前5条
return processed.slice(0, 5);代码对每一条数据进行清洗,并且限制输出前5条。执行结果为:
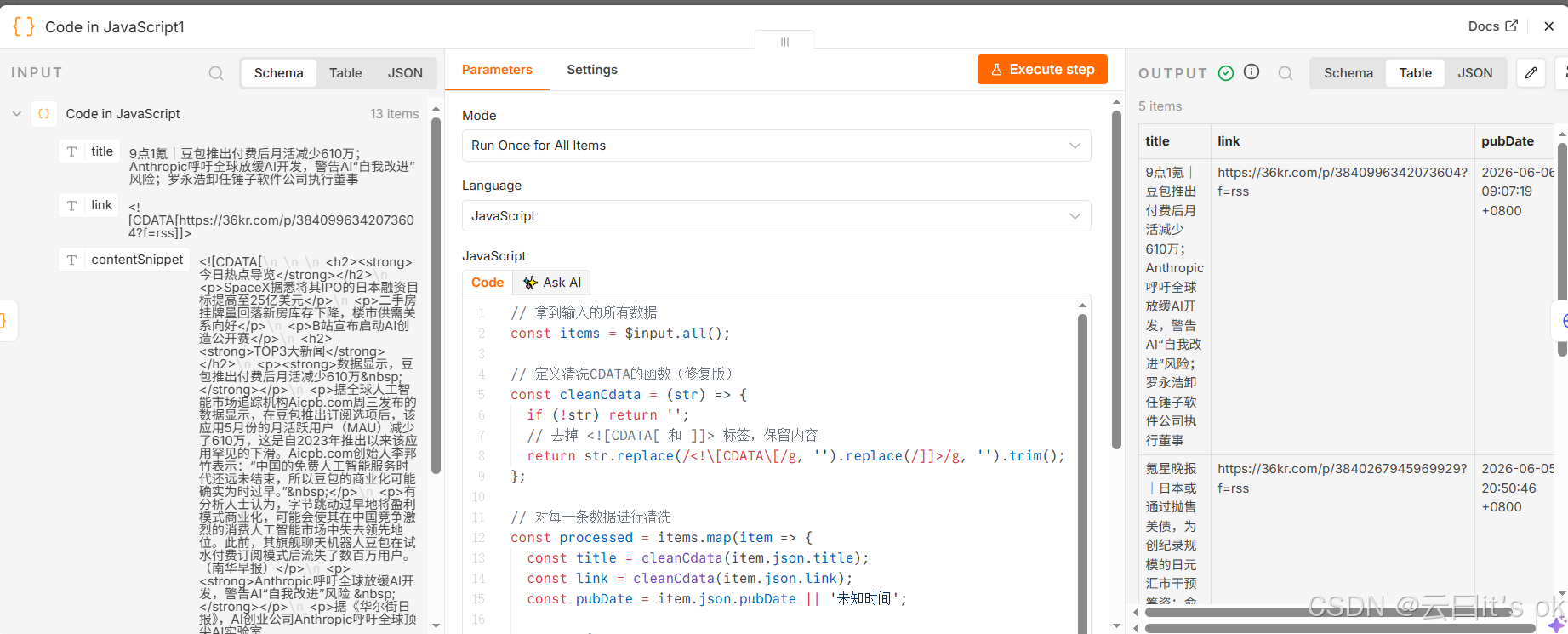
飞书推送
使用webhook来实现飞书的推送。获取webhook的步骤为:
- 创建飞书群组
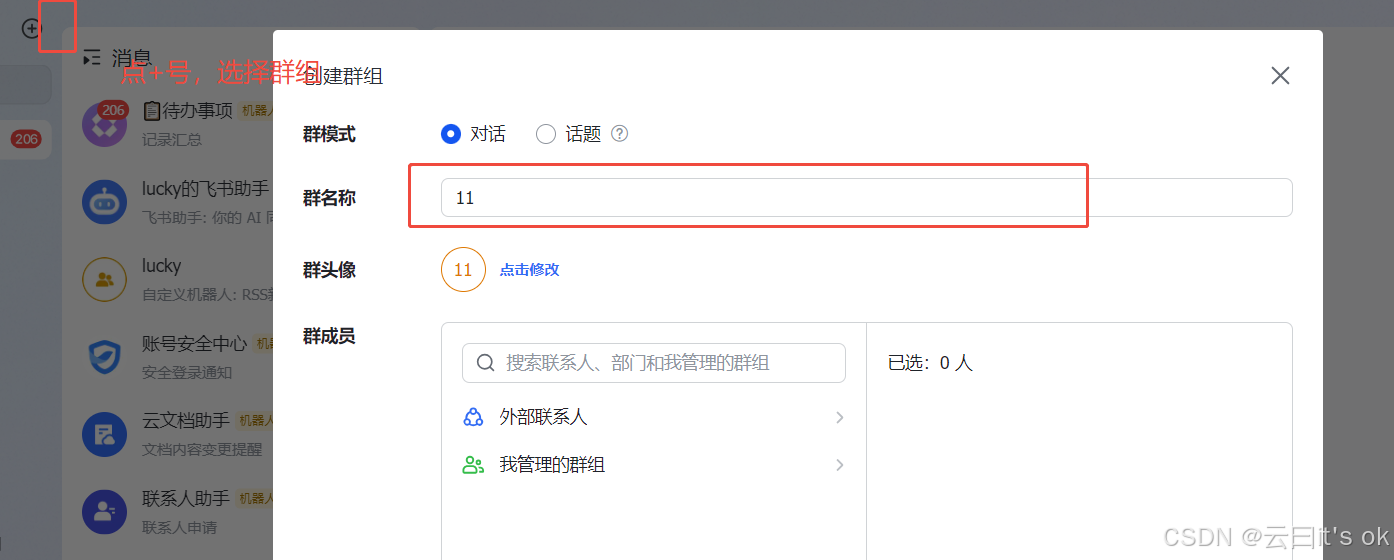
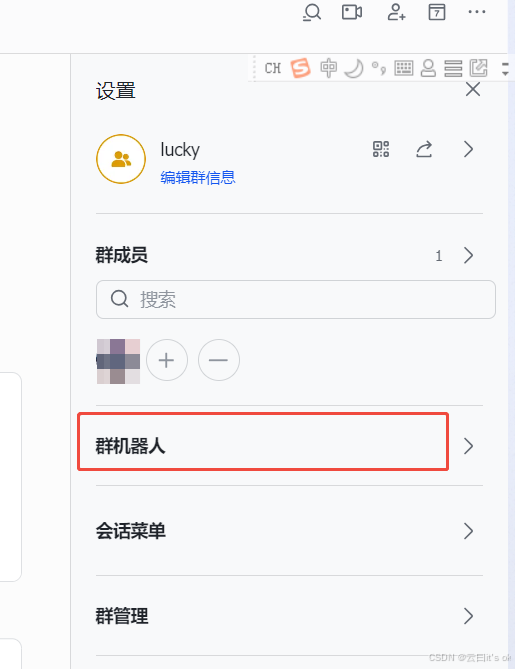
2、配置机器人
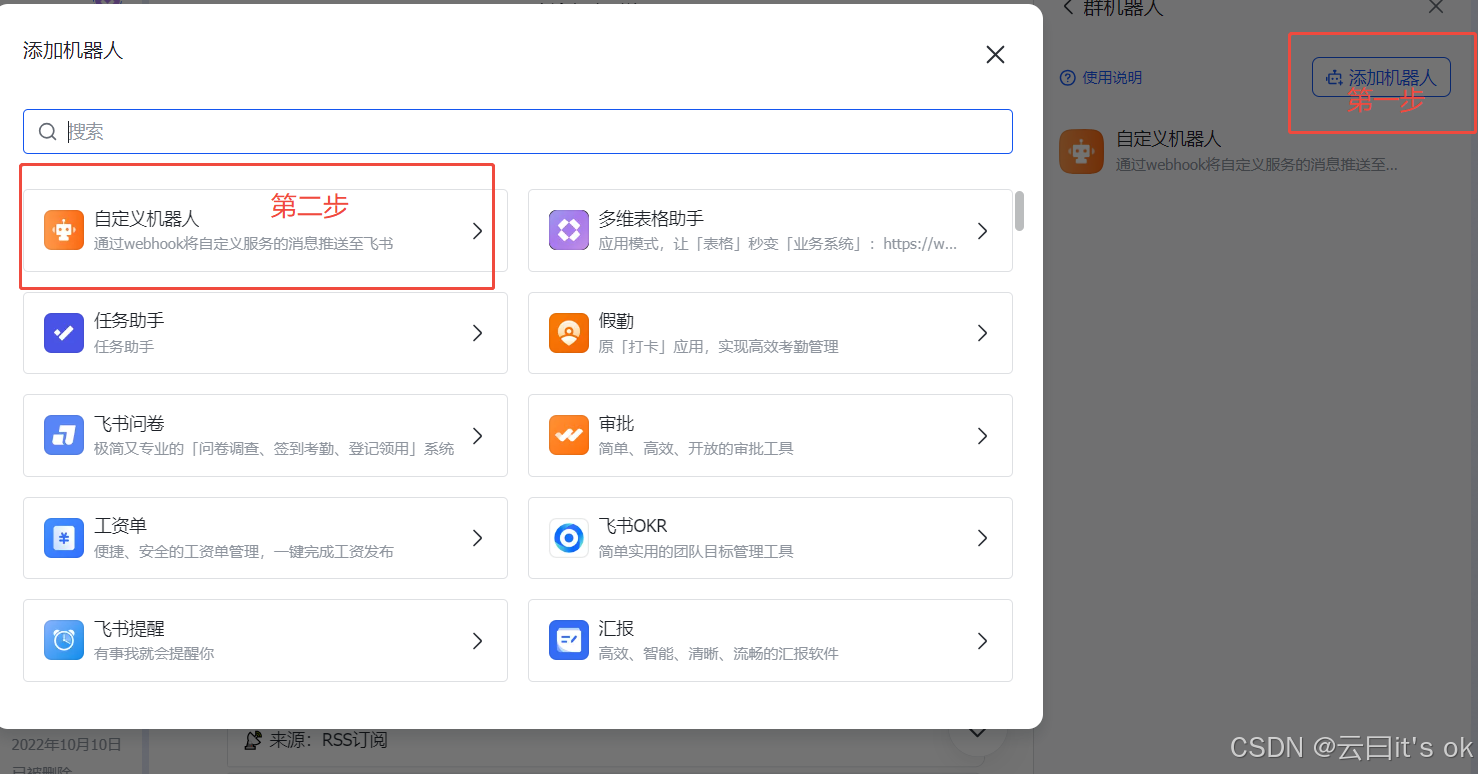
3、获取webhook地址
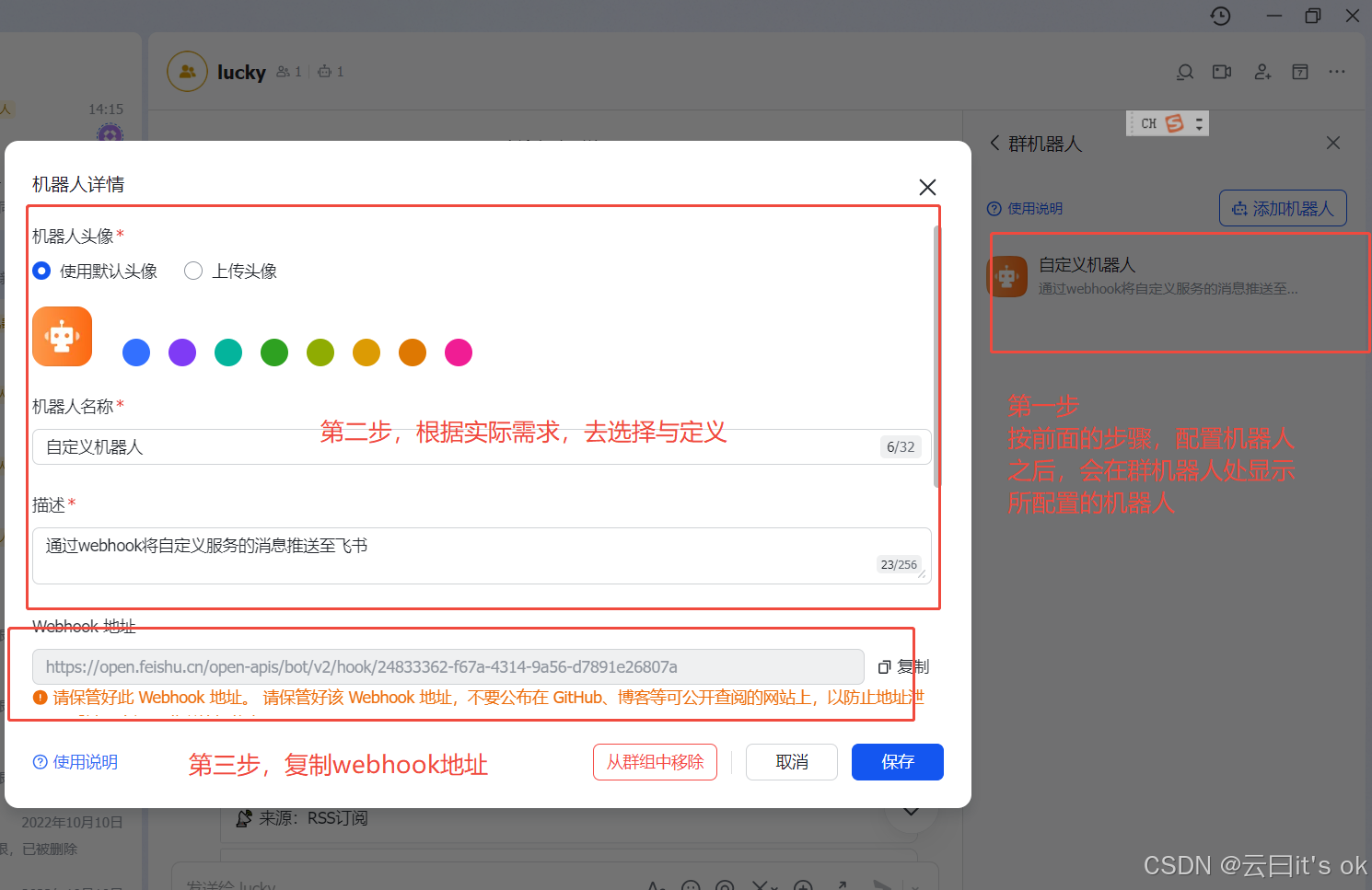
经过上面步骤,就可以获得飞书的webhook地址啦。然后在n8n的工作流中,加入http request节点。对应配置如下:
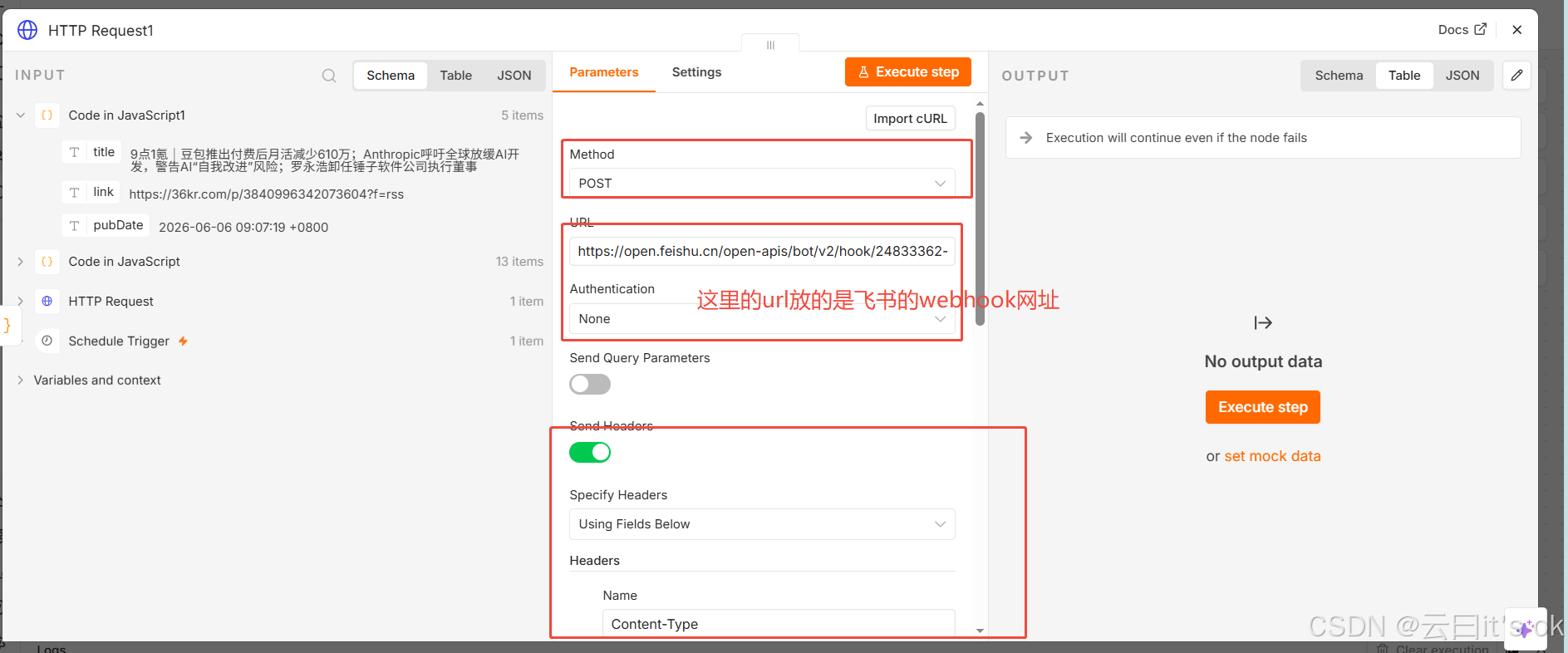
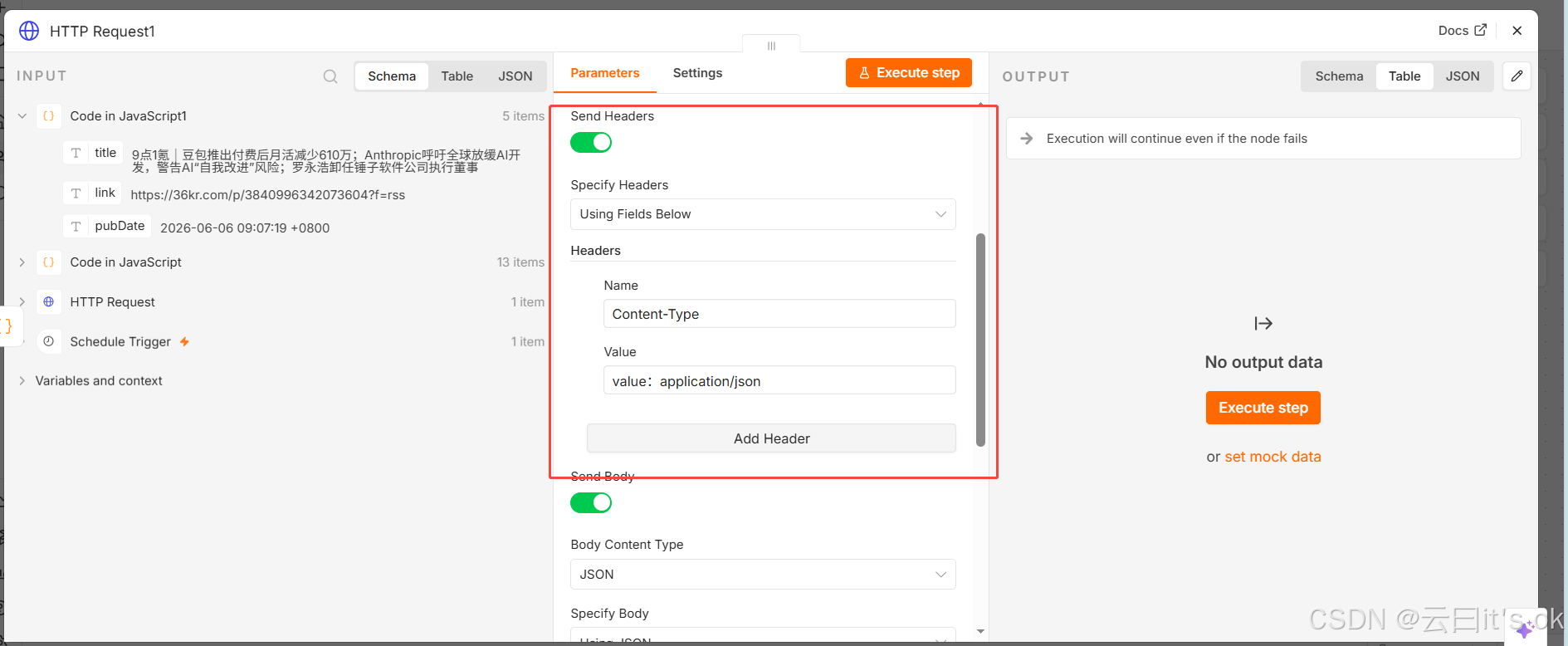
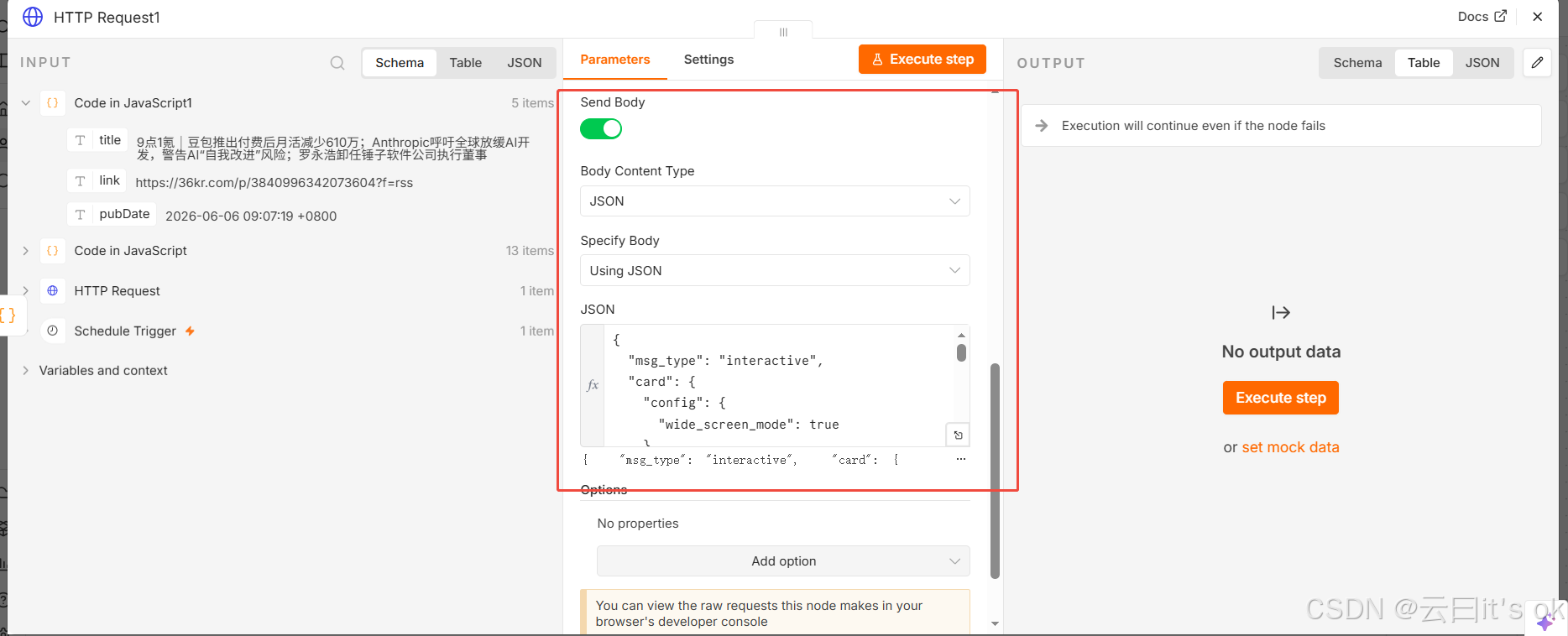
最后这一步,body主要是为了设置在飞书群组里面,推送的内容样式。例如下面的样式一:
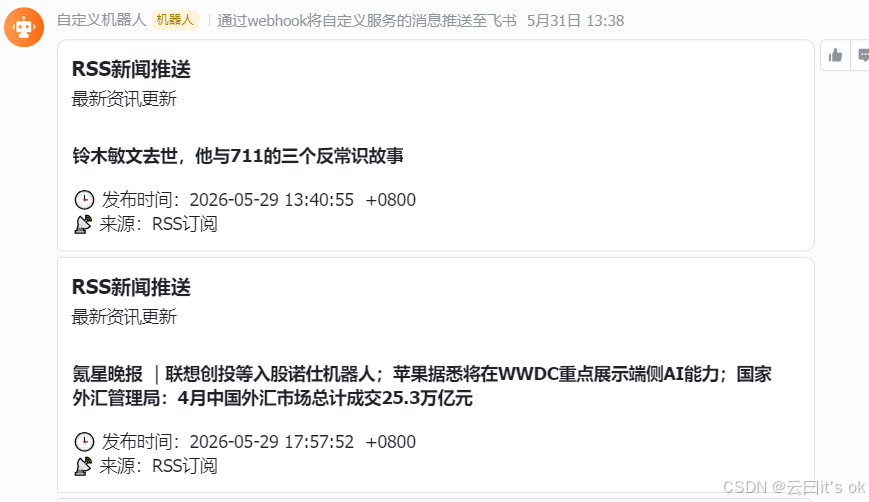
样式二:
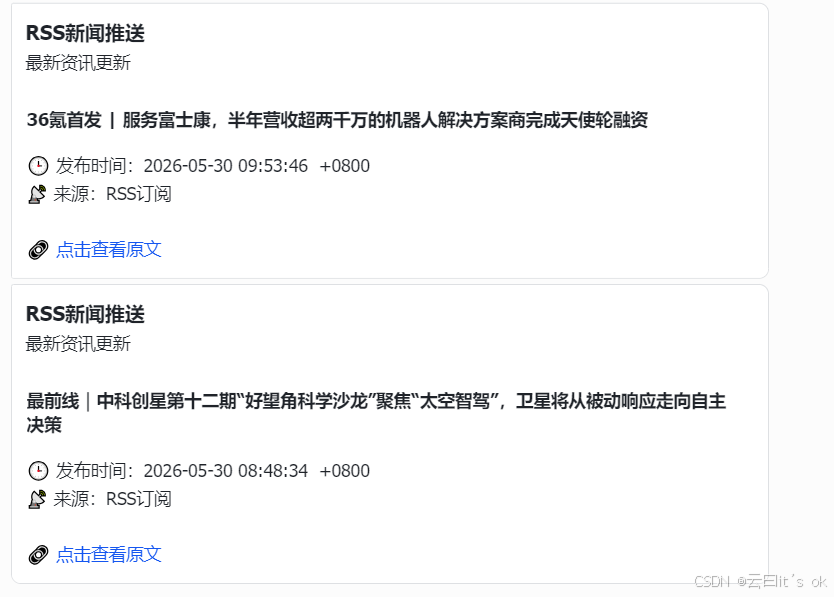
不同的推送样式,主要是在body里面,通过JSON代码来修改。分享下我的代码,为:
javascript
{
"msg_type": "interactive",
"card": {
"config": {
"wide_screen_mode": true
},
"header": {
"title": {
"tag": "plain_text",
"content": "RSS新闻推送"
},
"subtitle": {
"tag": "plain_text",
"content": "最新资讯更新"
}
},
"elements": [
{
"tag": "div",
"text": {
"tag": "lark_md",
"content": "**{{ ($json.title || '无标题').replace(/<!\\[CDATA\\[|\\]\\]>/g, '').trim() }}**"
}
},
{
"tag": "div",
"text": {
"tag": "lark_md",
"content": "🕒 发布时间:{{ $json.pubDate || '未知时间' }}\n📡 来源:RSS订阅\n\n🔗 [点击查看原文]({{ ($json.link || 'https://36kr.com').replace(/<!\\[CDATA\\[|\\]\\]>/g, '').trim() }})"
}
},
{
"tag": "button",
"text": {
"tag": "plain_text",
"content": "打开原文链接"
},
"type": "primary",
"url": "{{ ($json.link || 'https://36kr.com').replace(/<!\\[CDATA\\[|\\]\\]>/g, '').trim() }}"
}
]
}
}最终,点击execute 就可以执行整个工作流啦