无监督学习
无监督学习是一种基于未标注数据,自动发现数据模式和内在结构的机器学习方法,是机器学习三大核心范式之一。
一、定义与原理
无监督学习(Unsupervised Learning)的核心特点是训练数据无标签、无人工设定的目标值,模型不依赖人工提供的"标准答案",仅通过自主分析数据的内在分布、关联与结构,自动归纳潜在规律、完成数据分组与特征挖掘,本质是机器自主学习、探索数据的过程。
无监督学习典型流程
-
数据准备与预处理
-
选择适配的无监督学习算法
-
分析、解释并评估模型输出结果
二、核心任务
无监督学习核心聚焦数据探索与特征优化,四大核心任务如下:
1.聚类(Clustering)
聚类简介
常见聚类算法
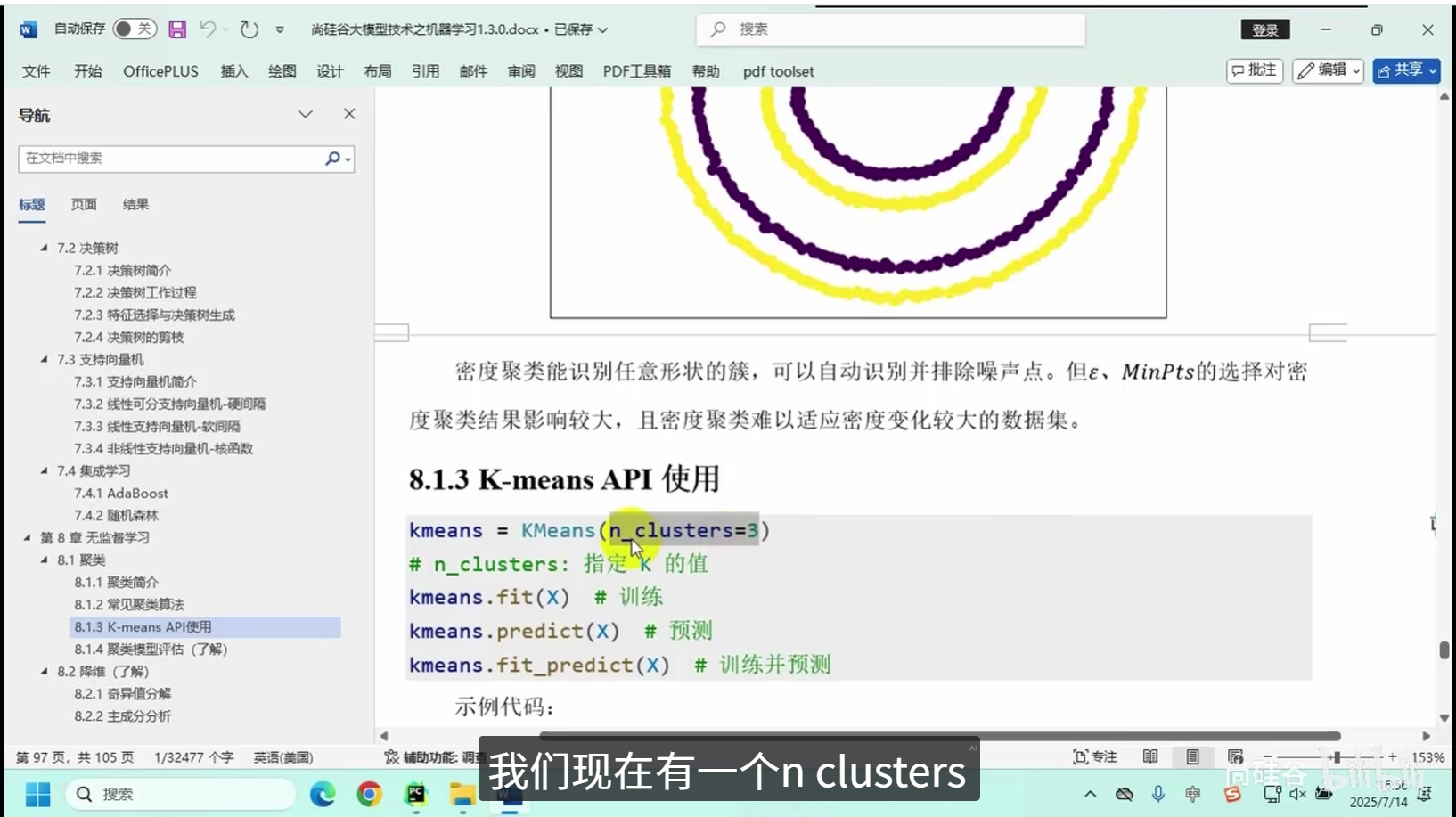
K-means API使用
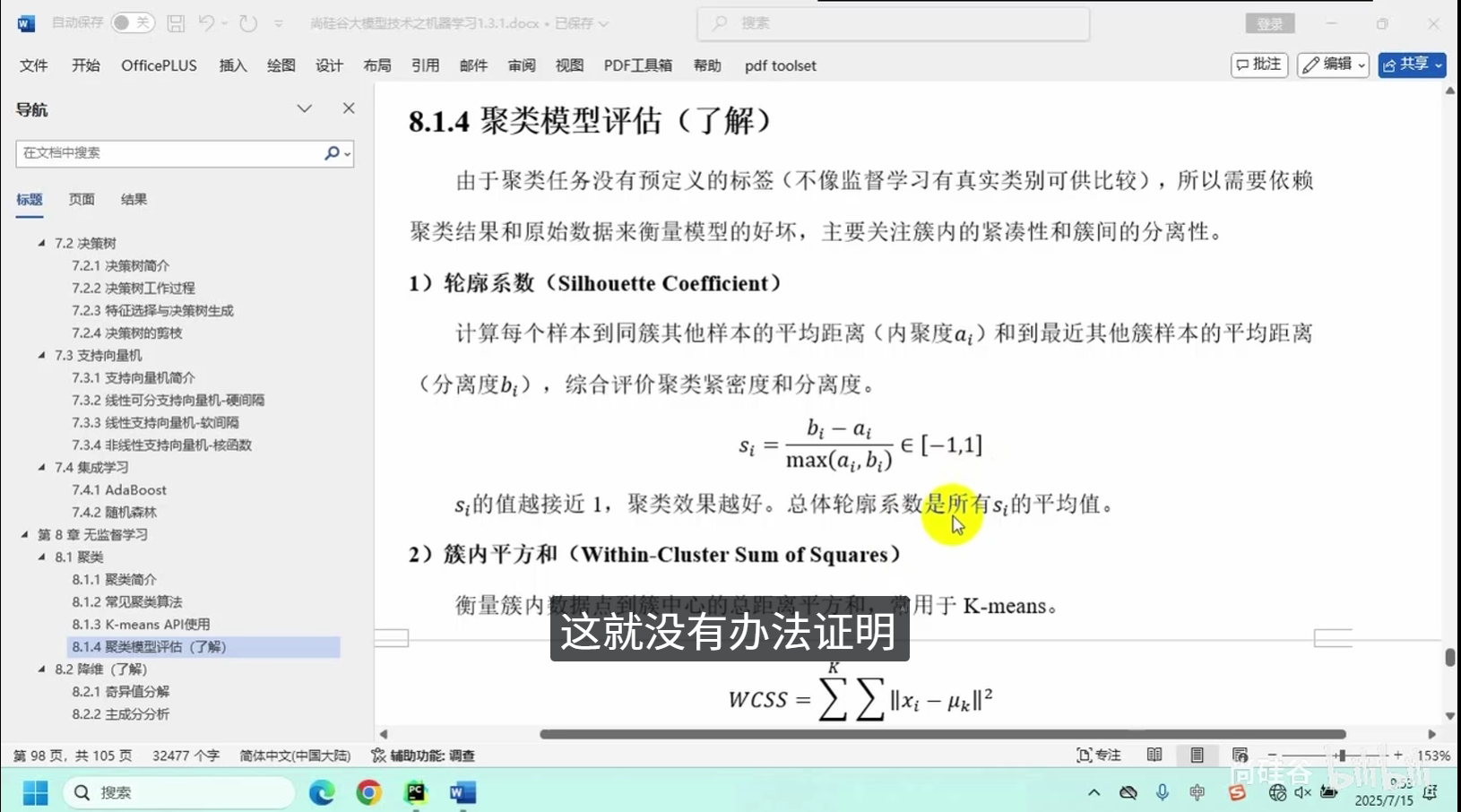
聚类模型评估(了解)
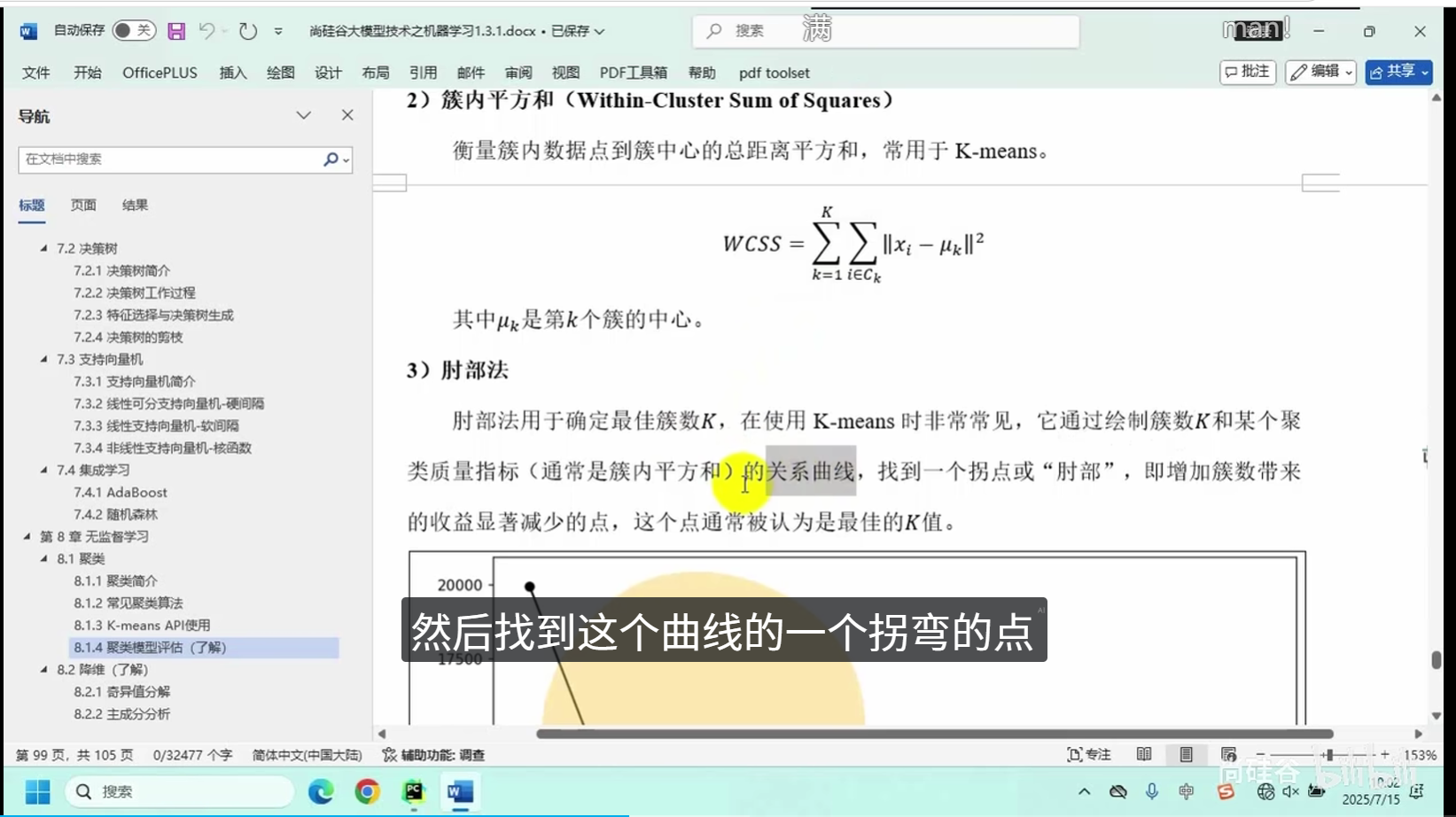
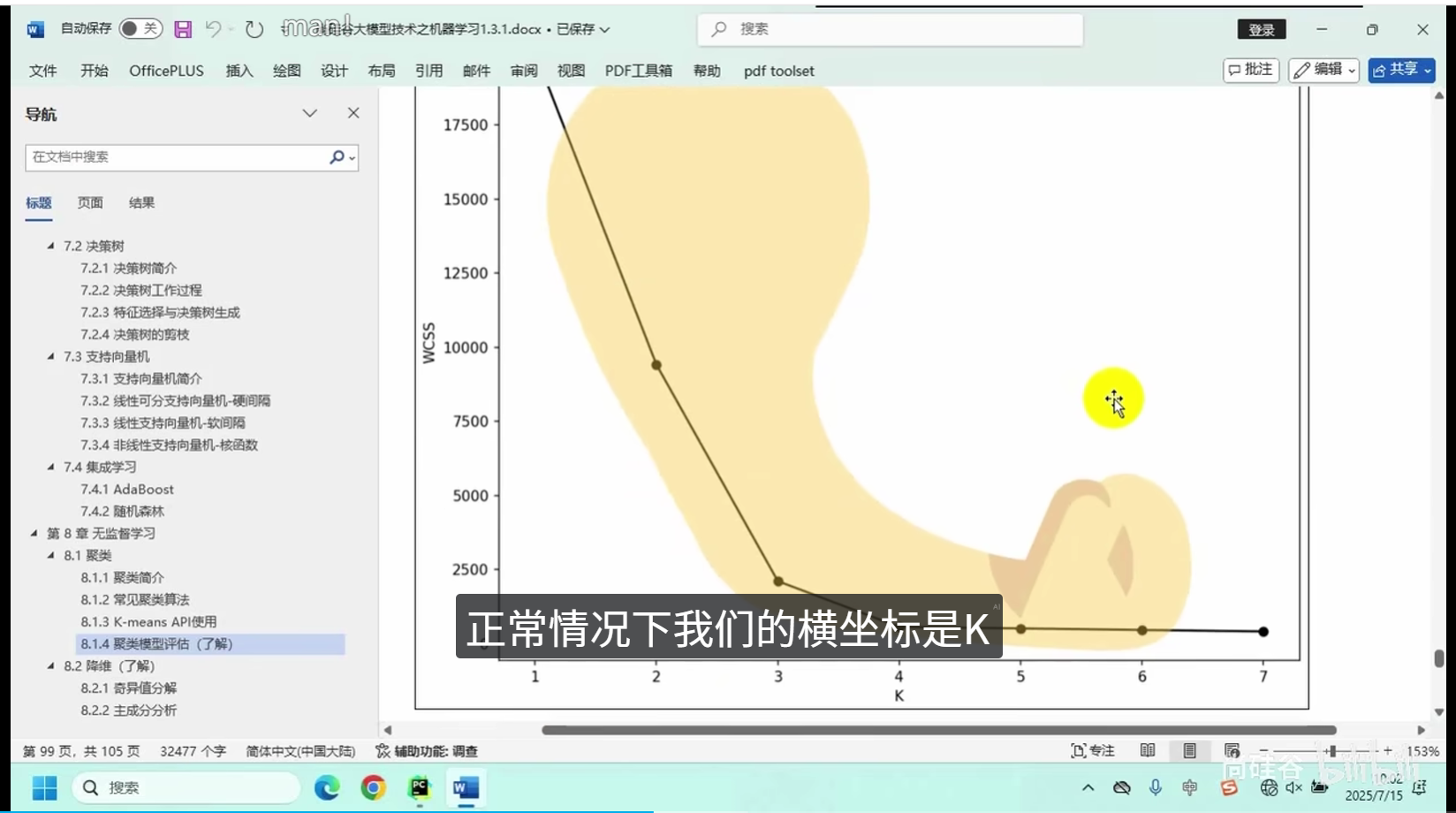
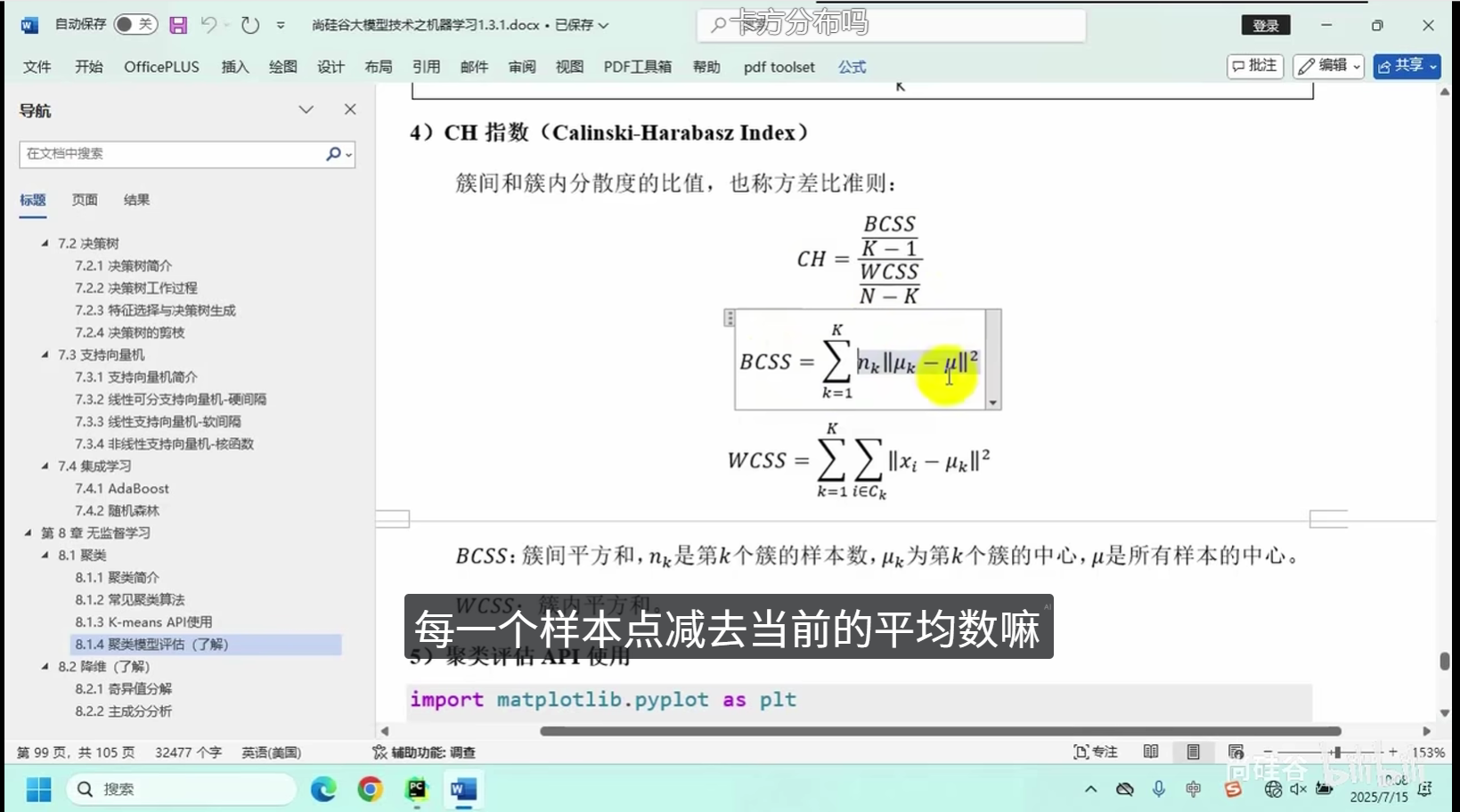
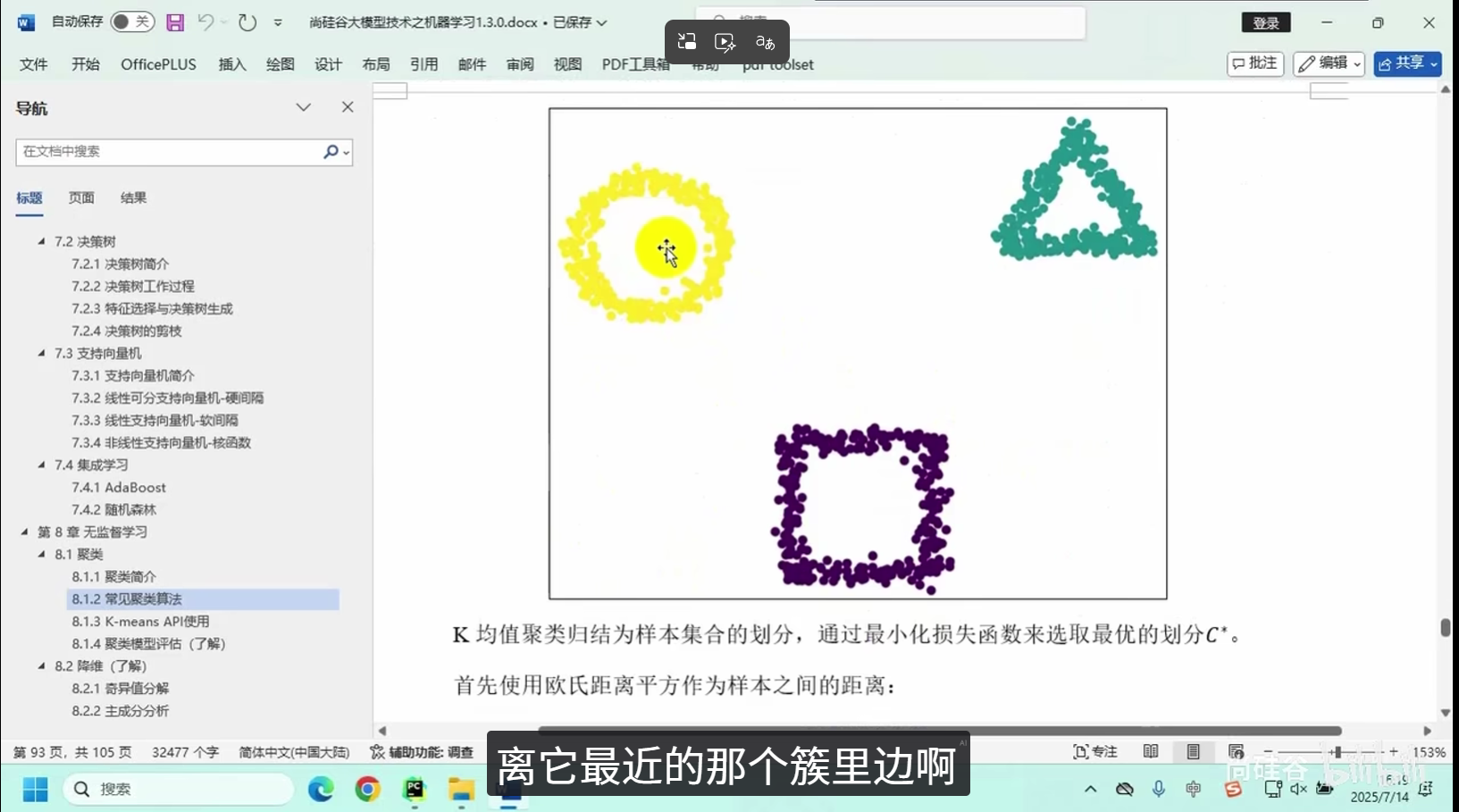
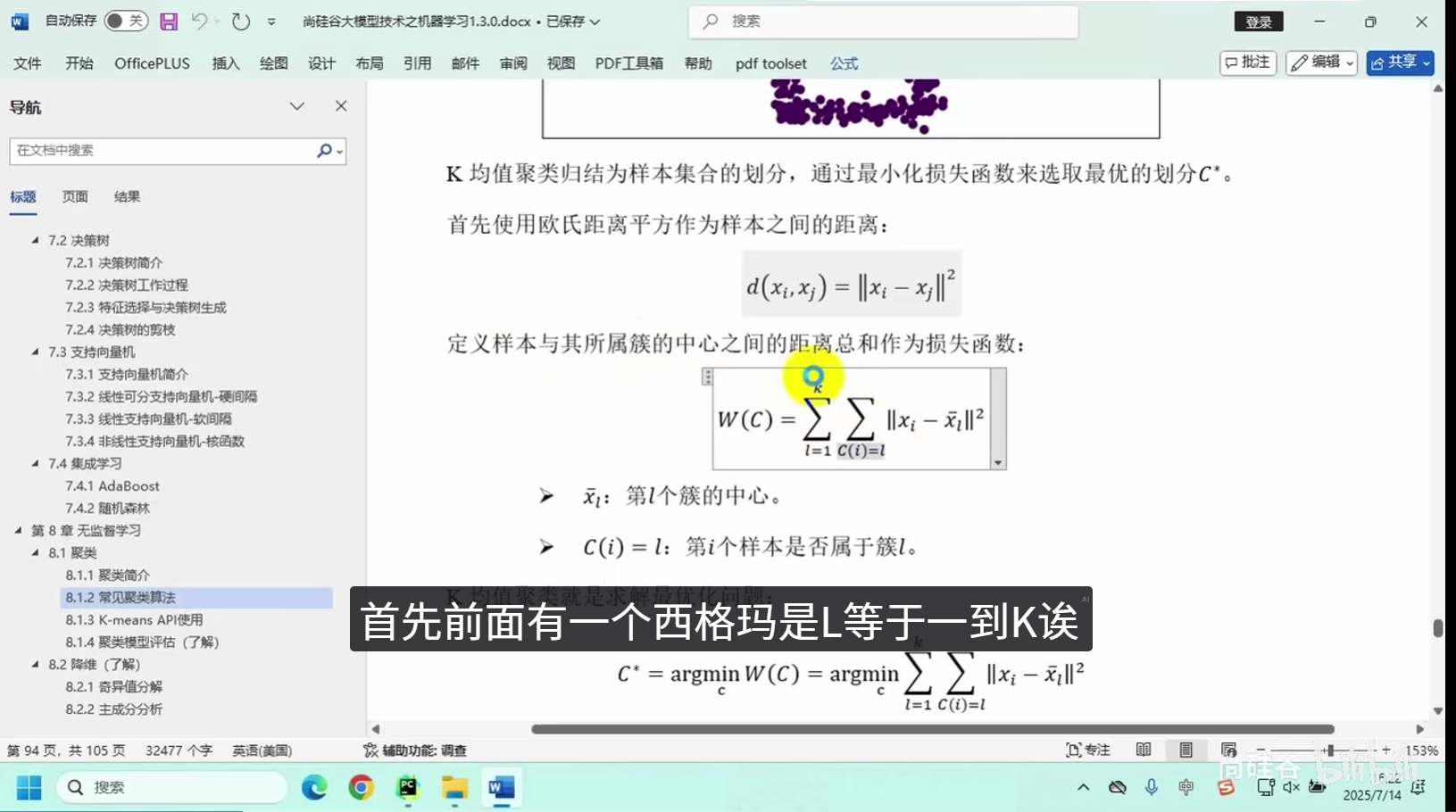
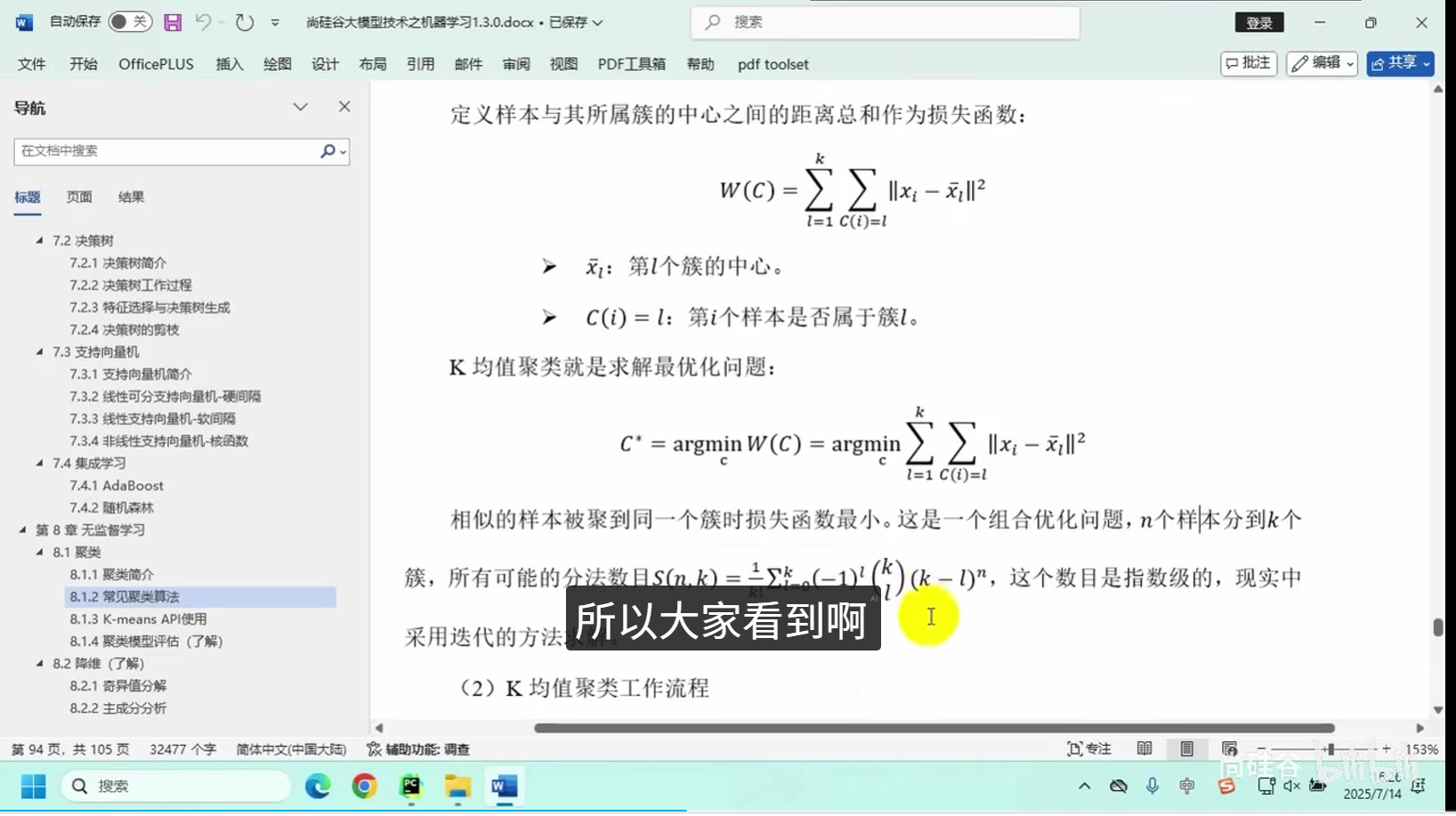
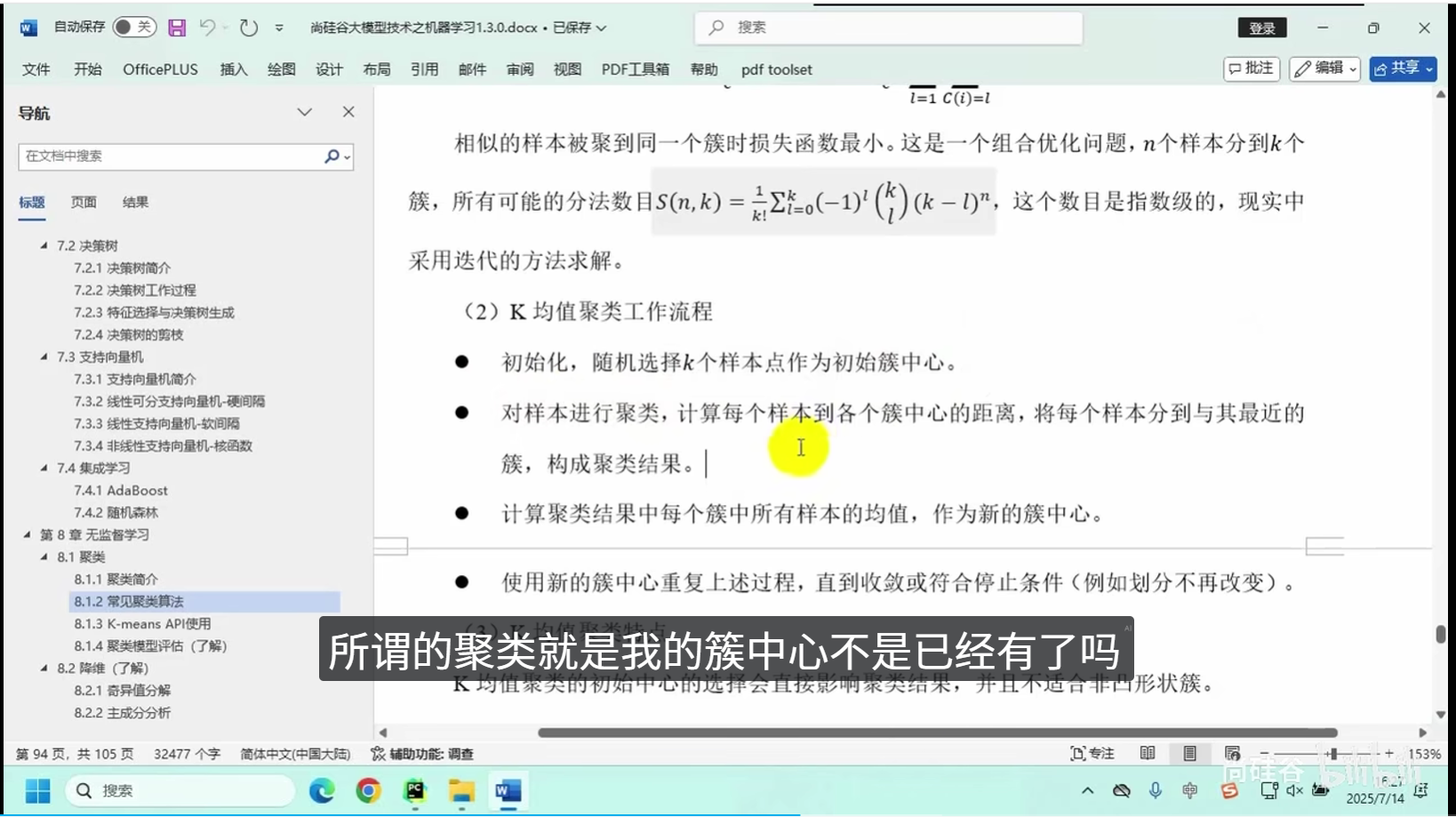
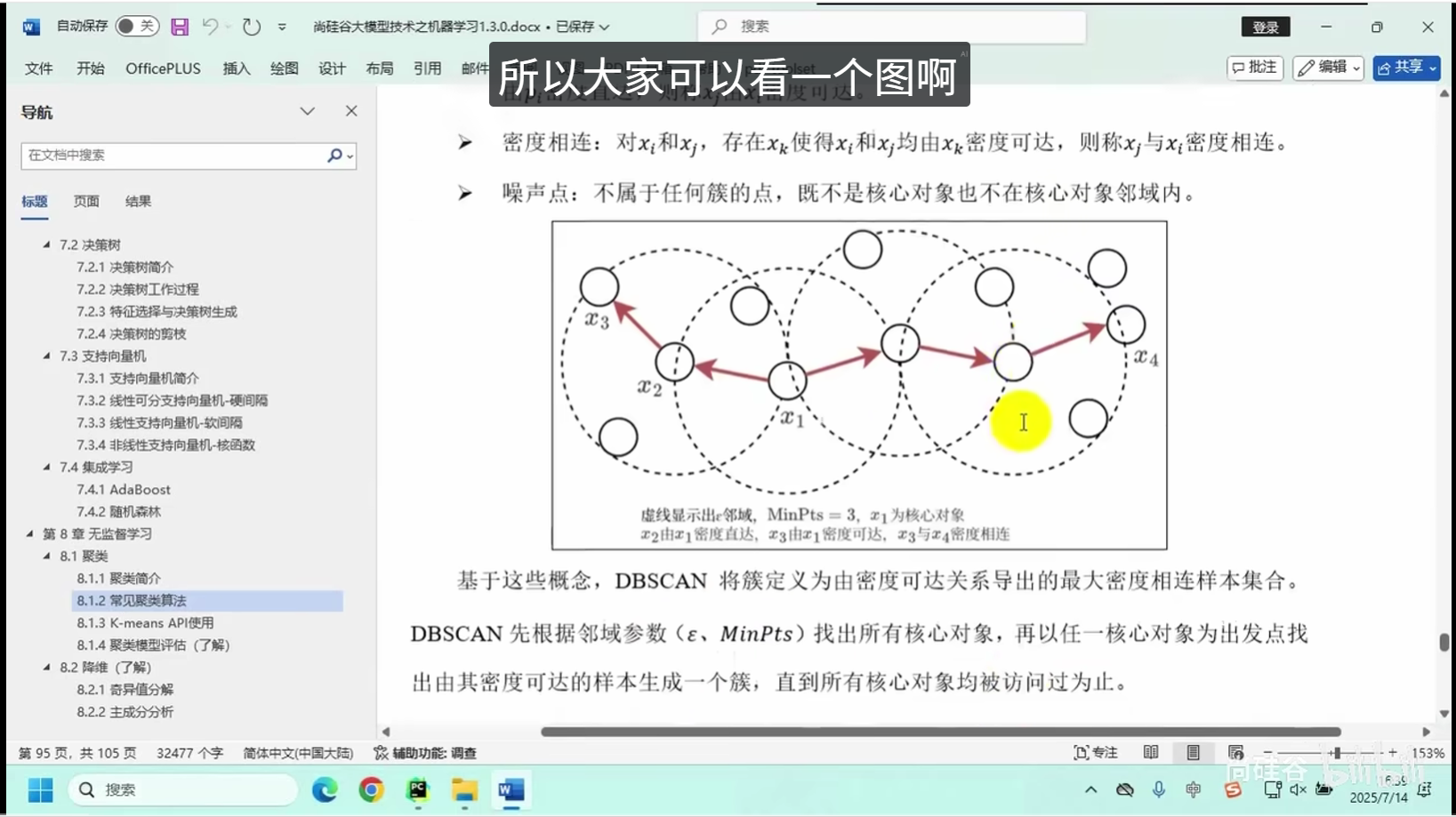
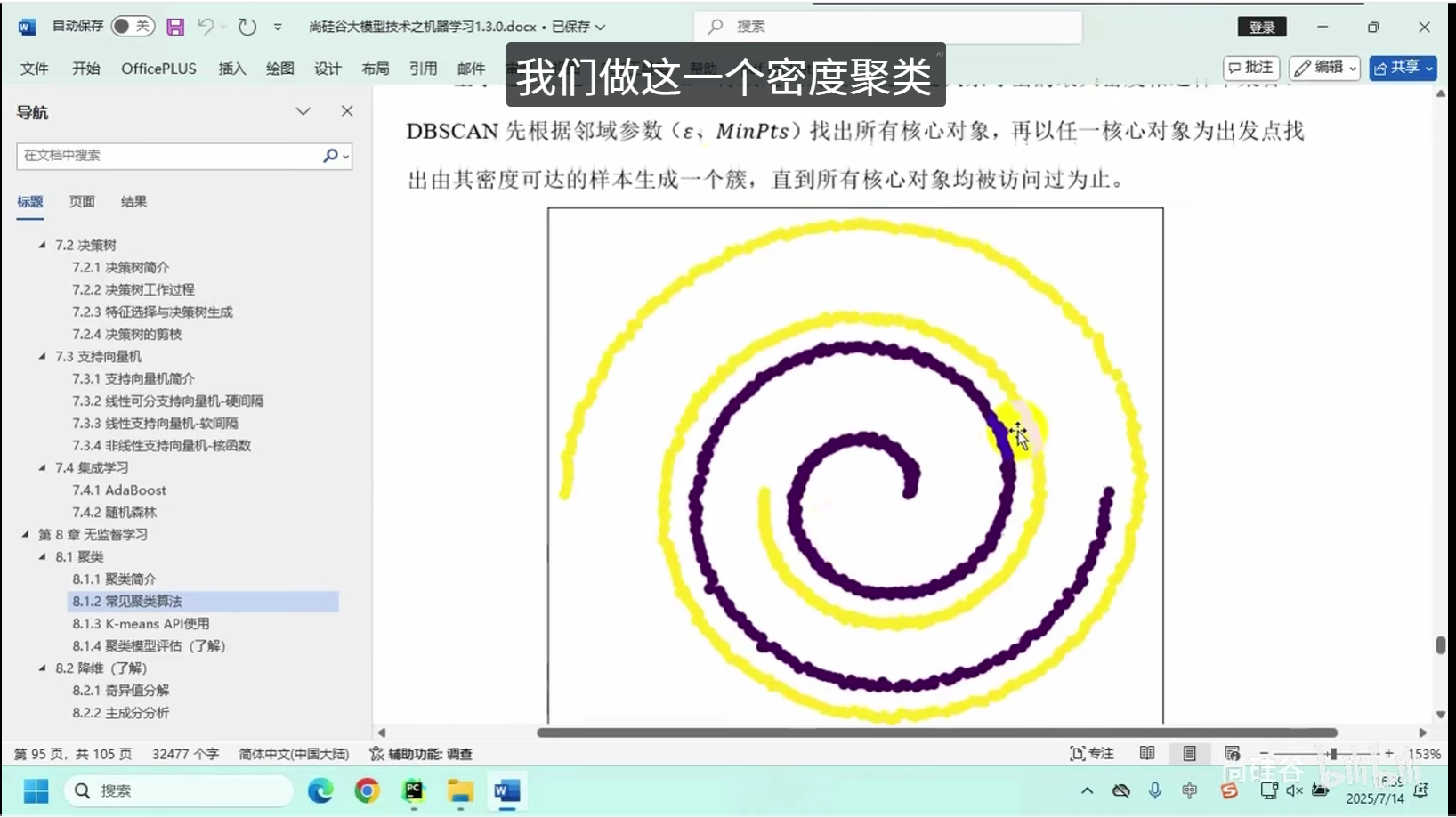
核心逻辑:将相似度高的数据点划分为同一组别,保证组内数据高度相似、组间数据差异显著。
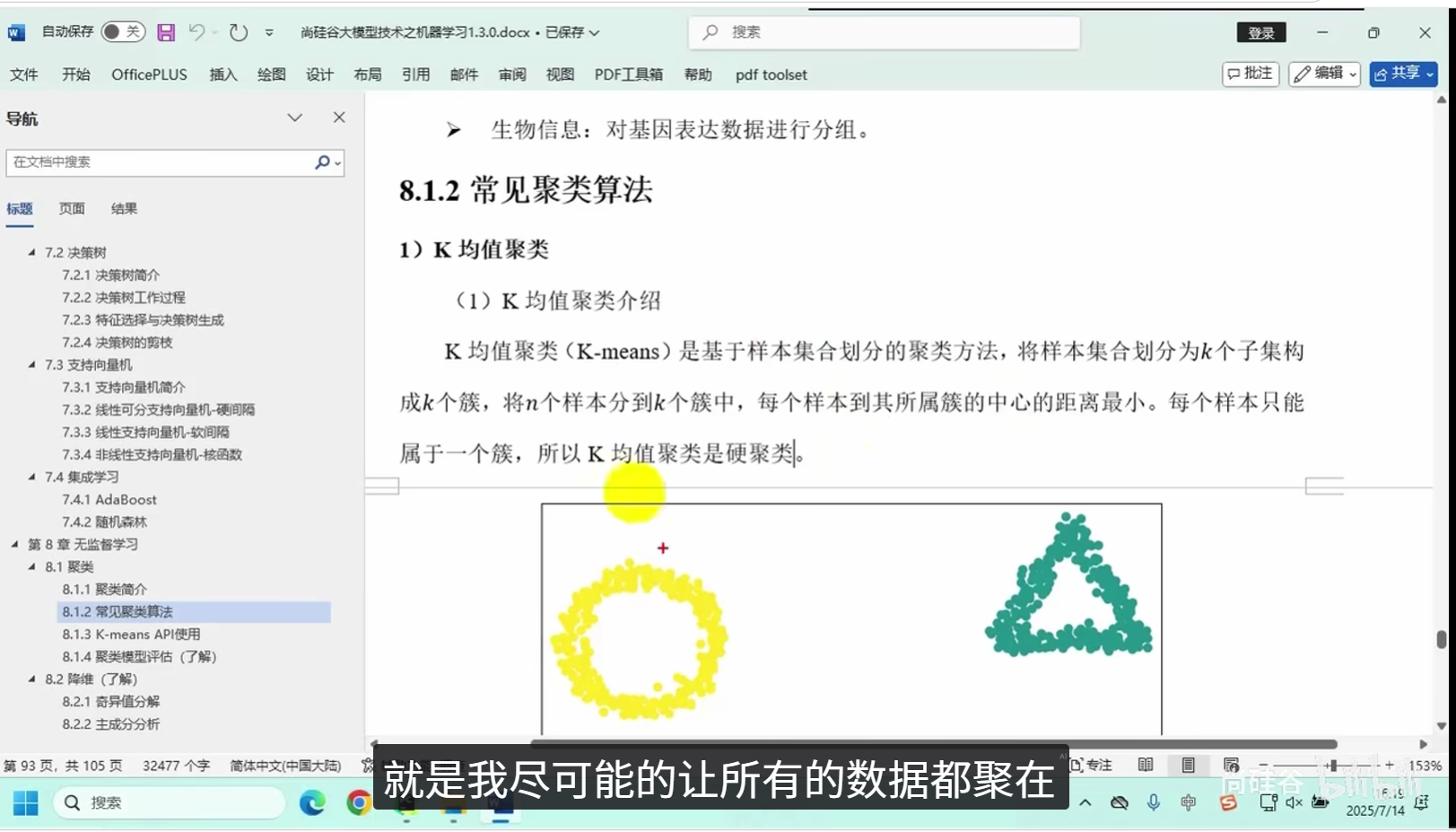
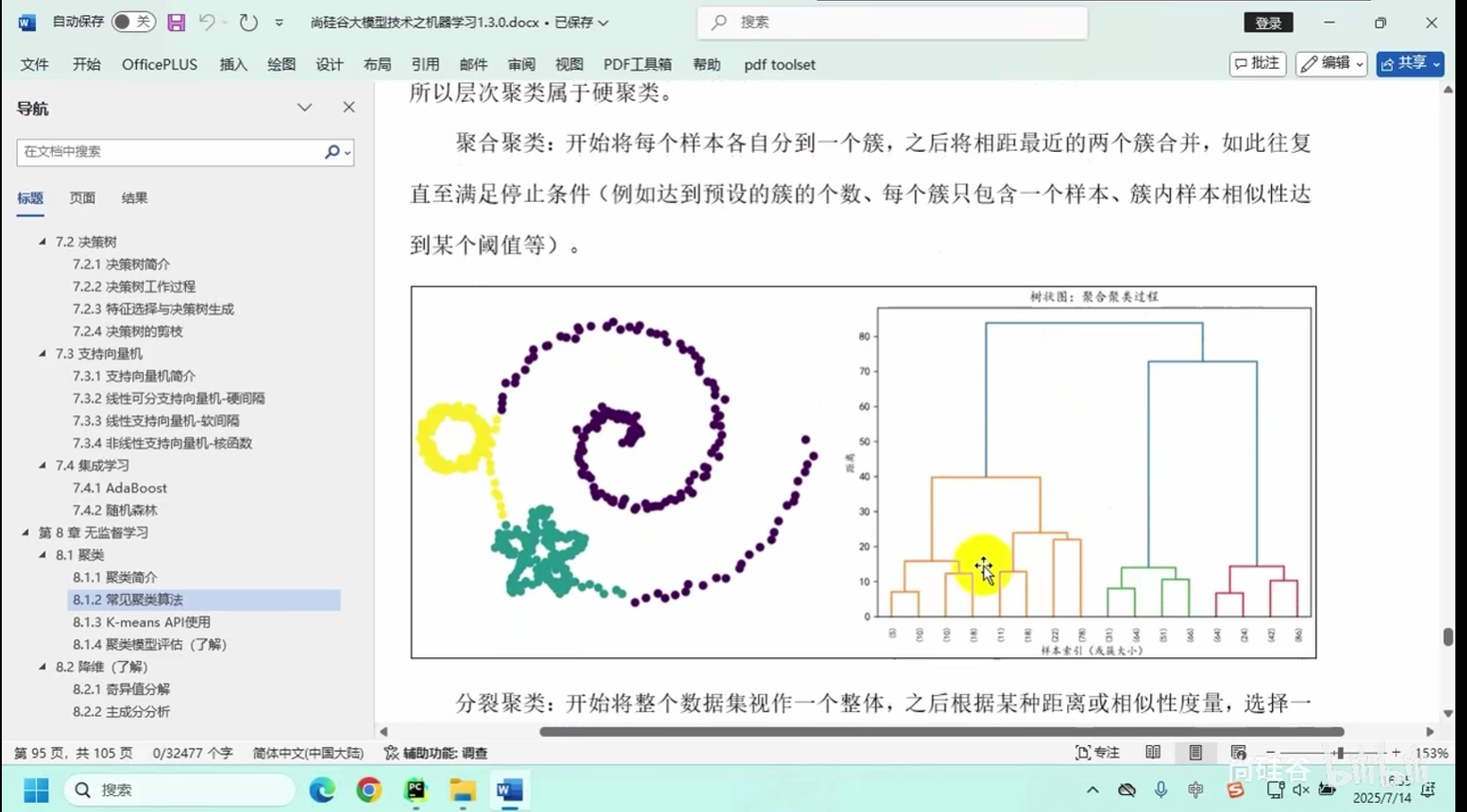
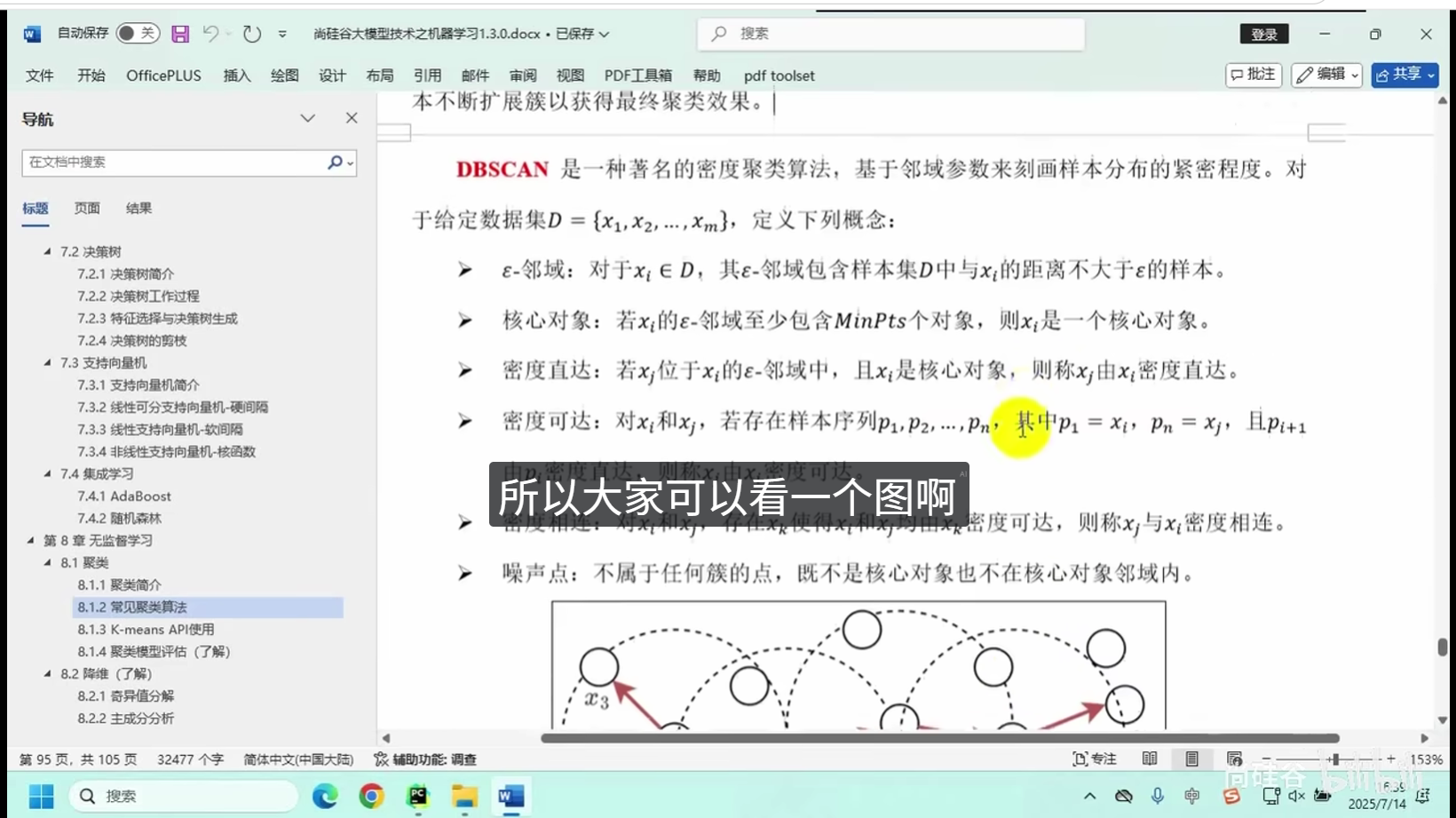
常用算法:K均值聚类、层次聚类等
应用场景:用户分群、图像分割、数据分层、异常初筛等
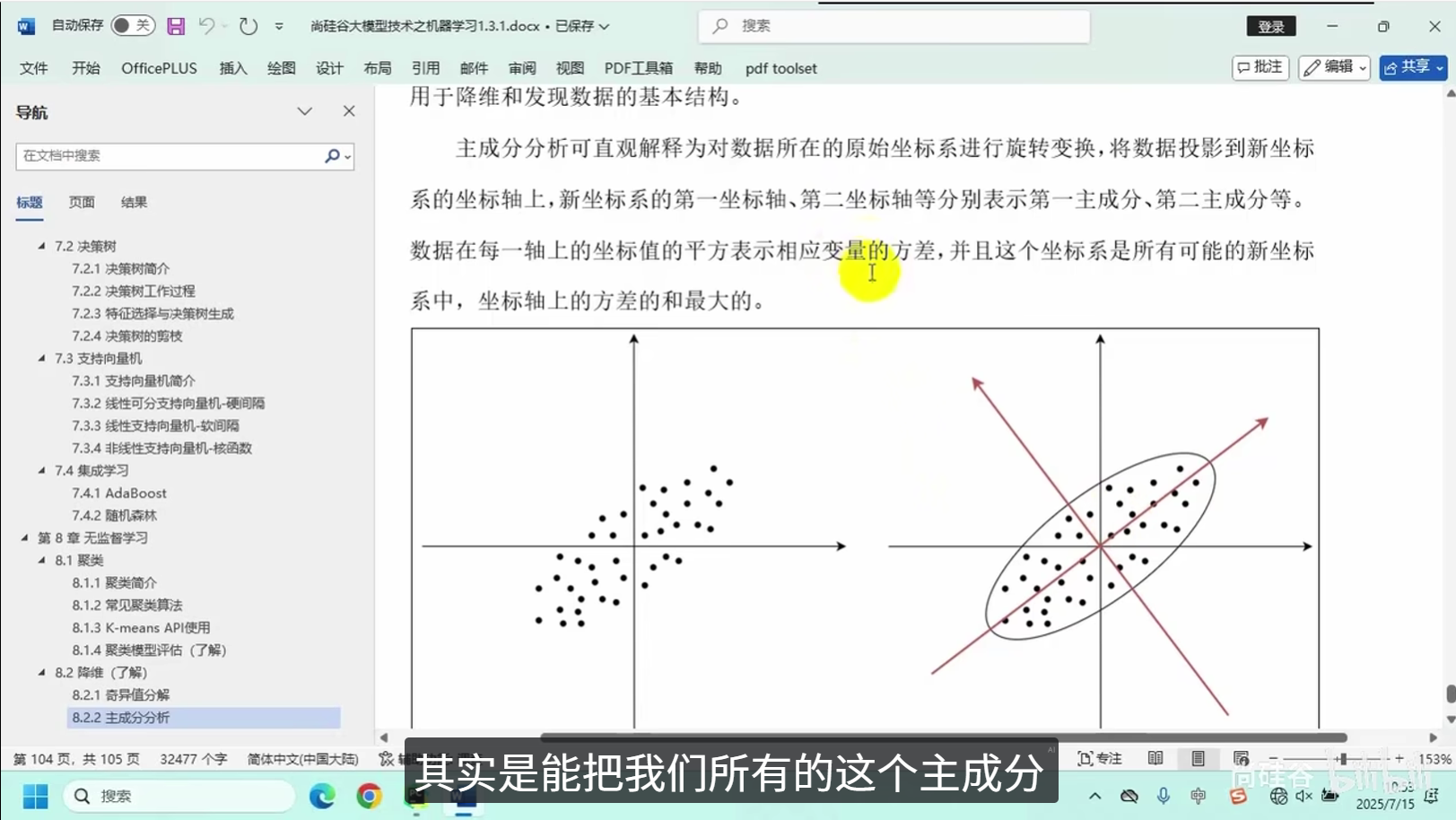
2.降维(了解)(Dimensionality Reduction)
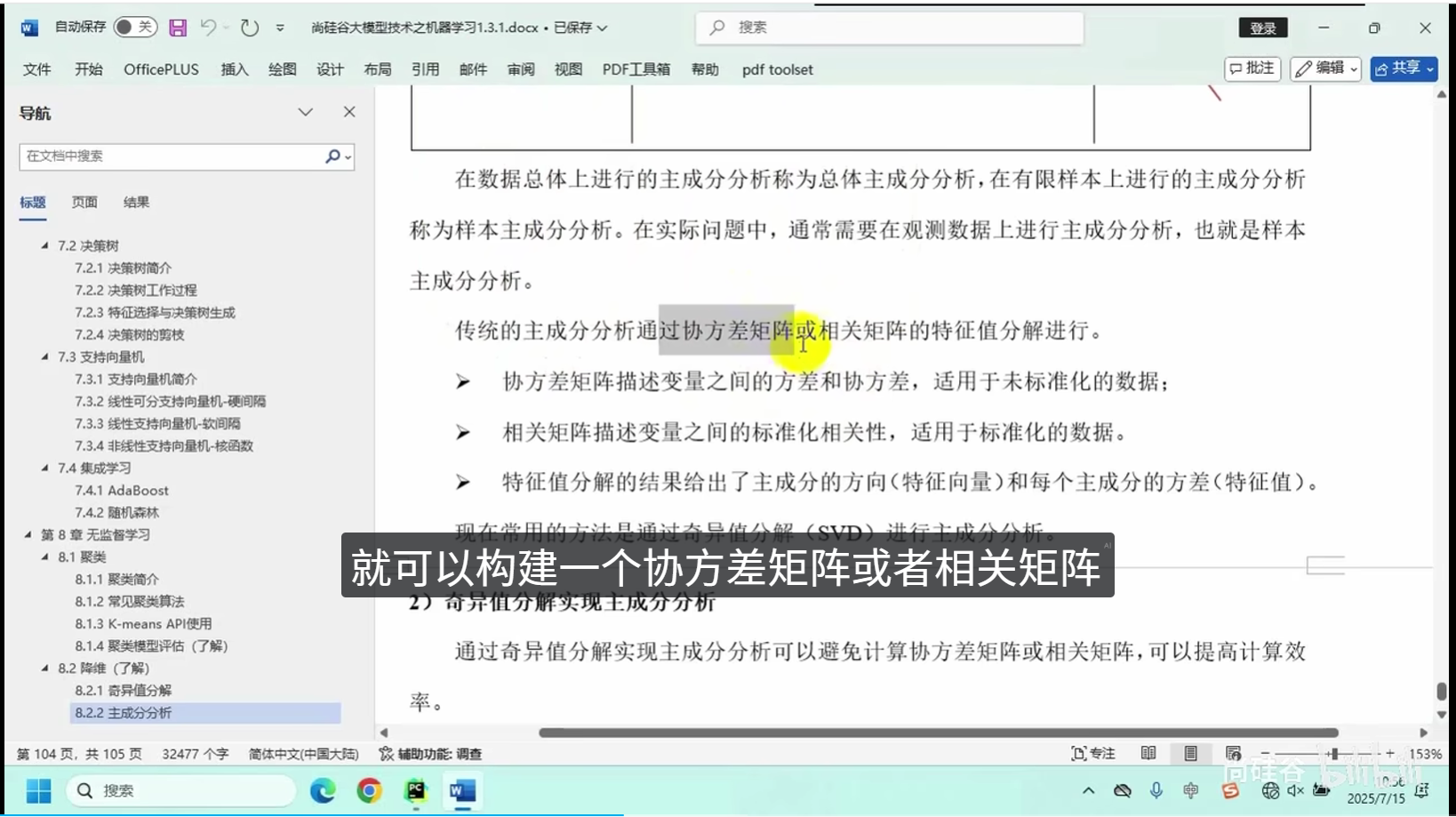
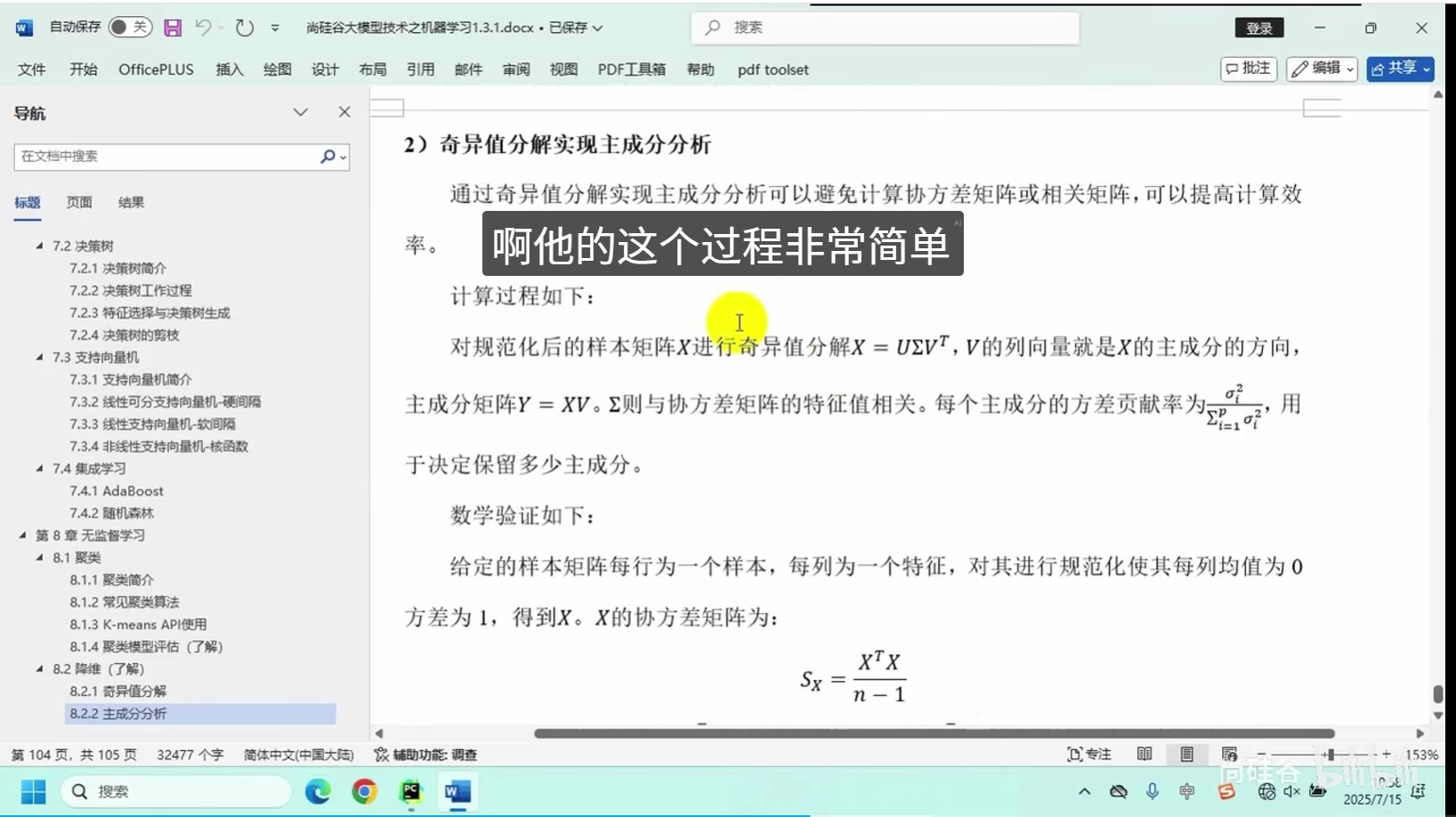
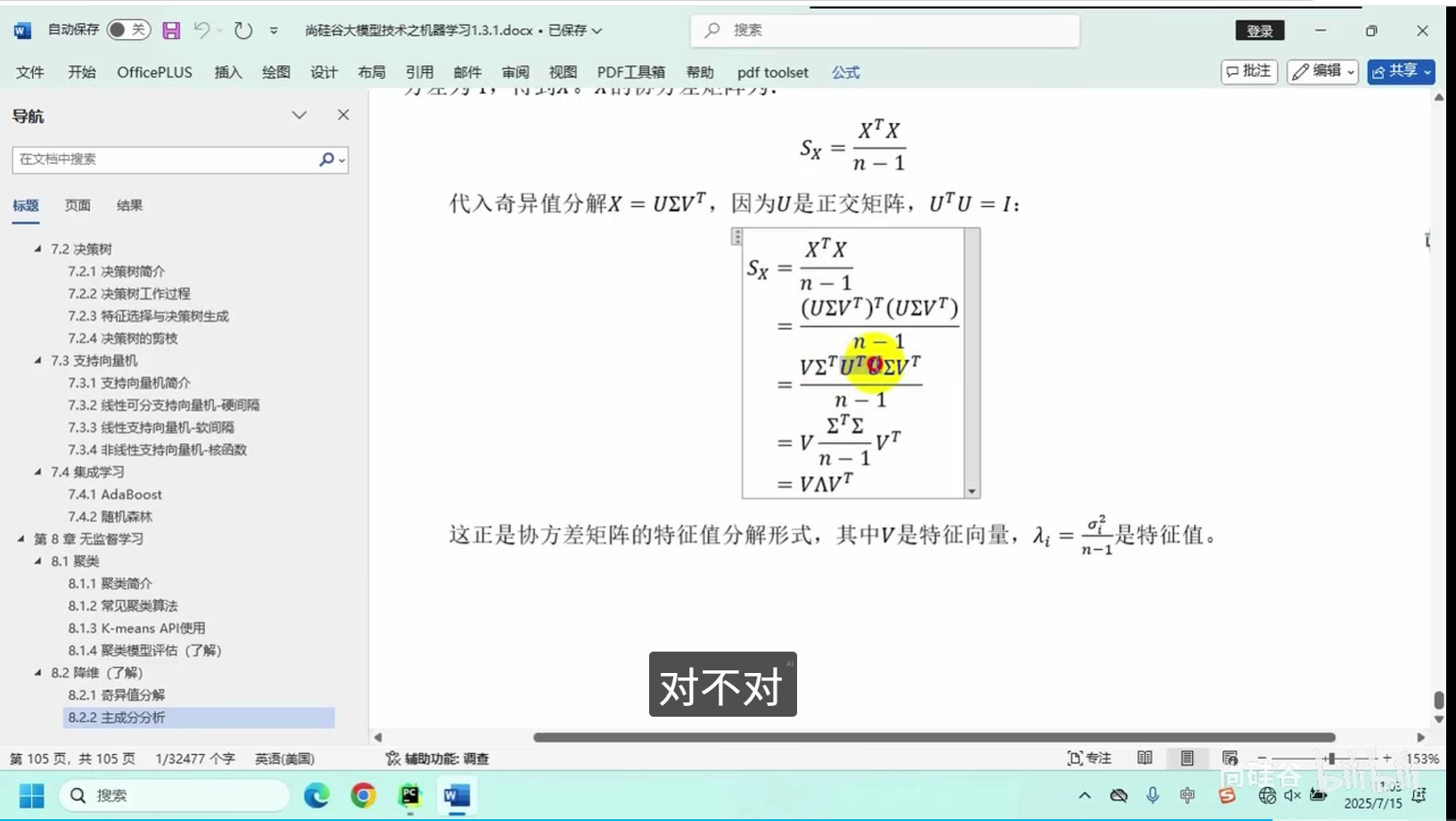
奇异值分解
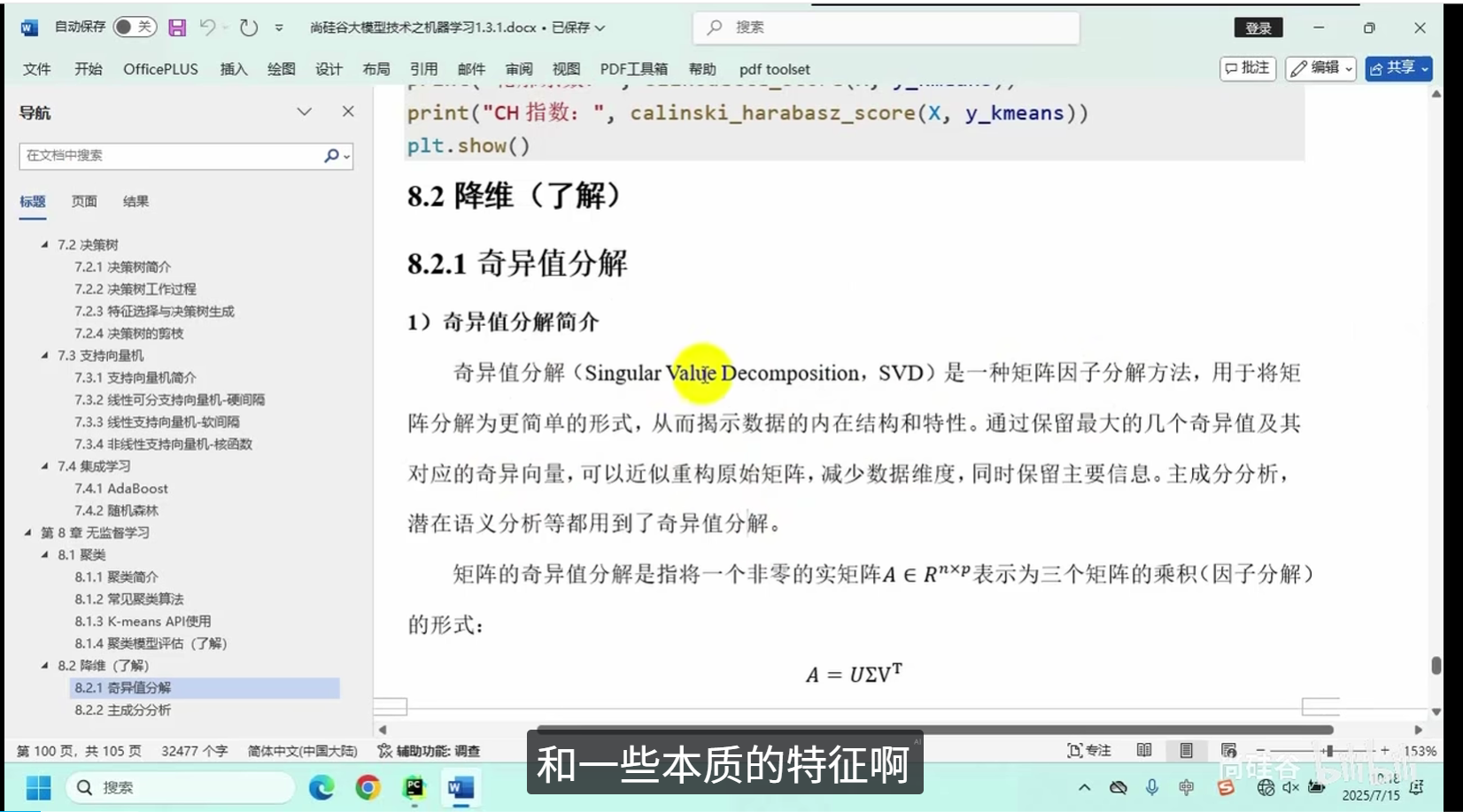
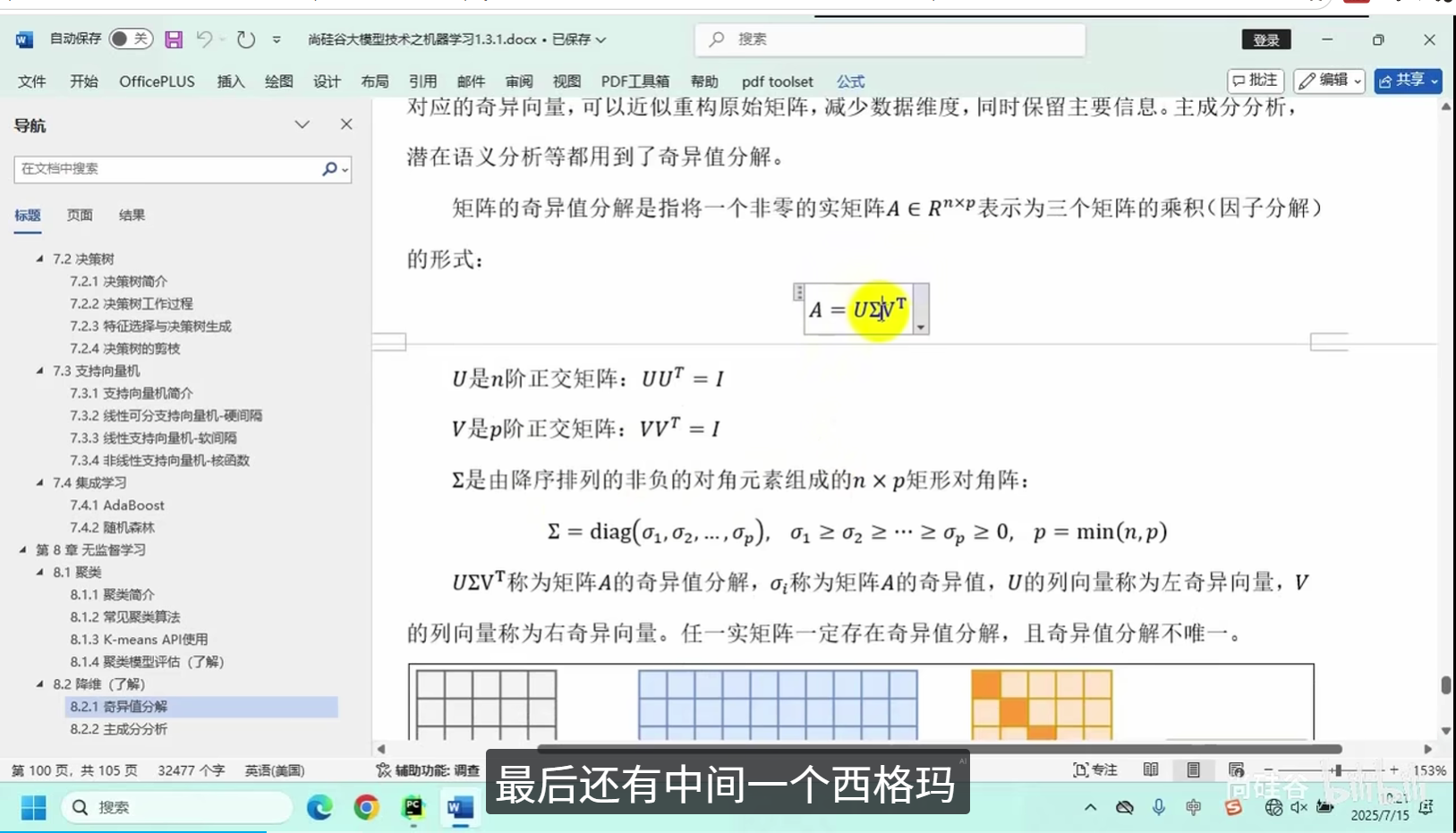
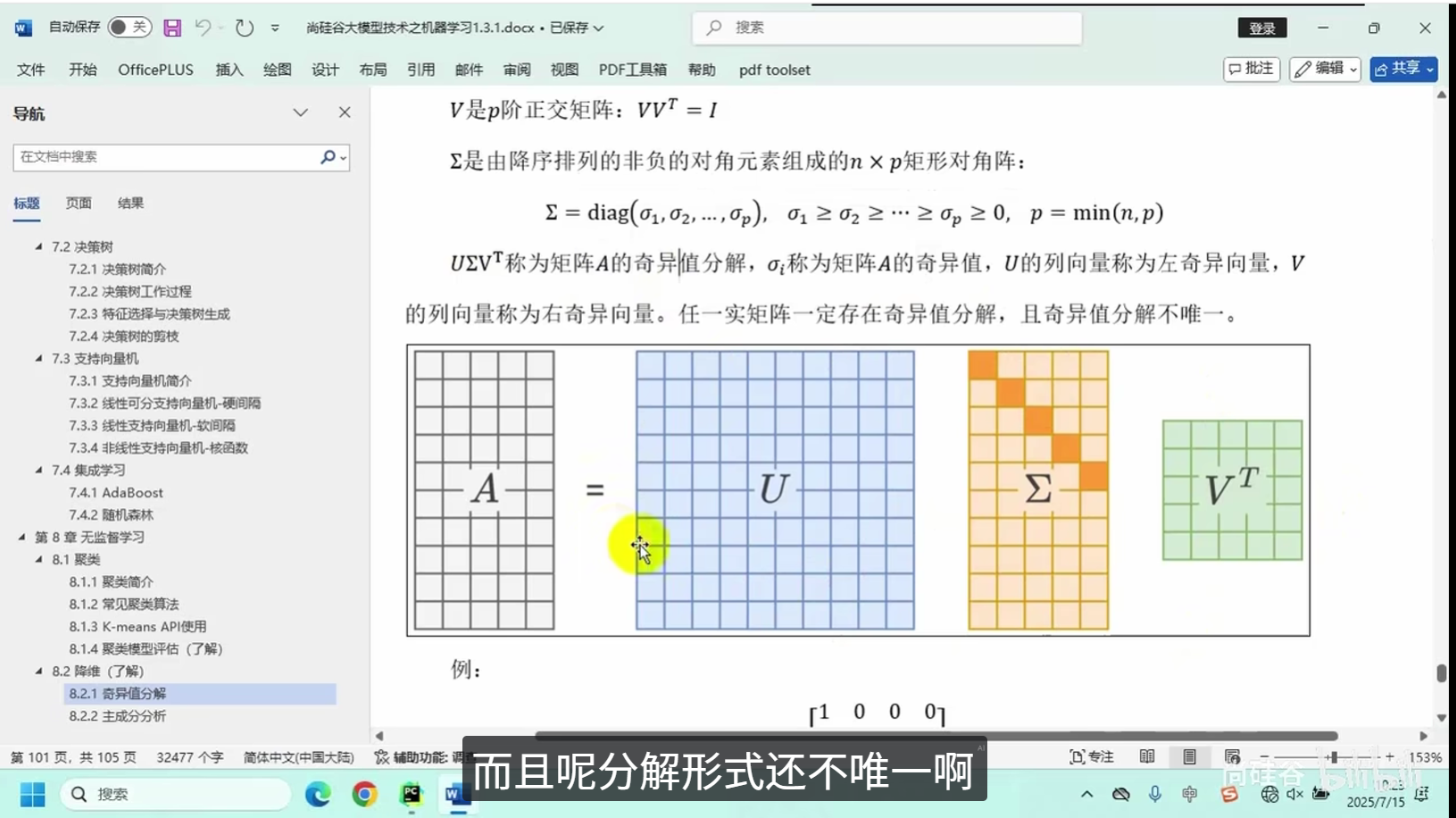
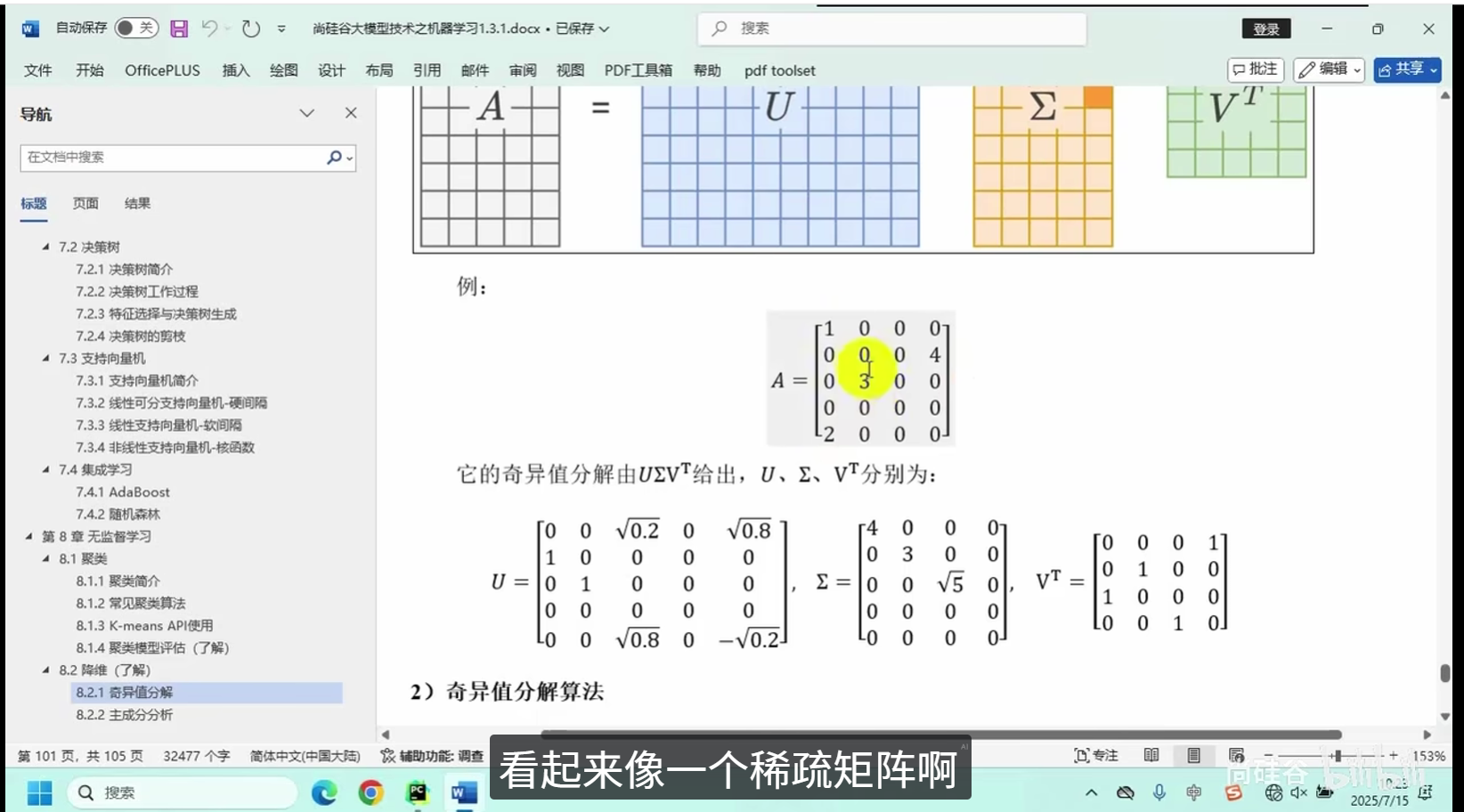
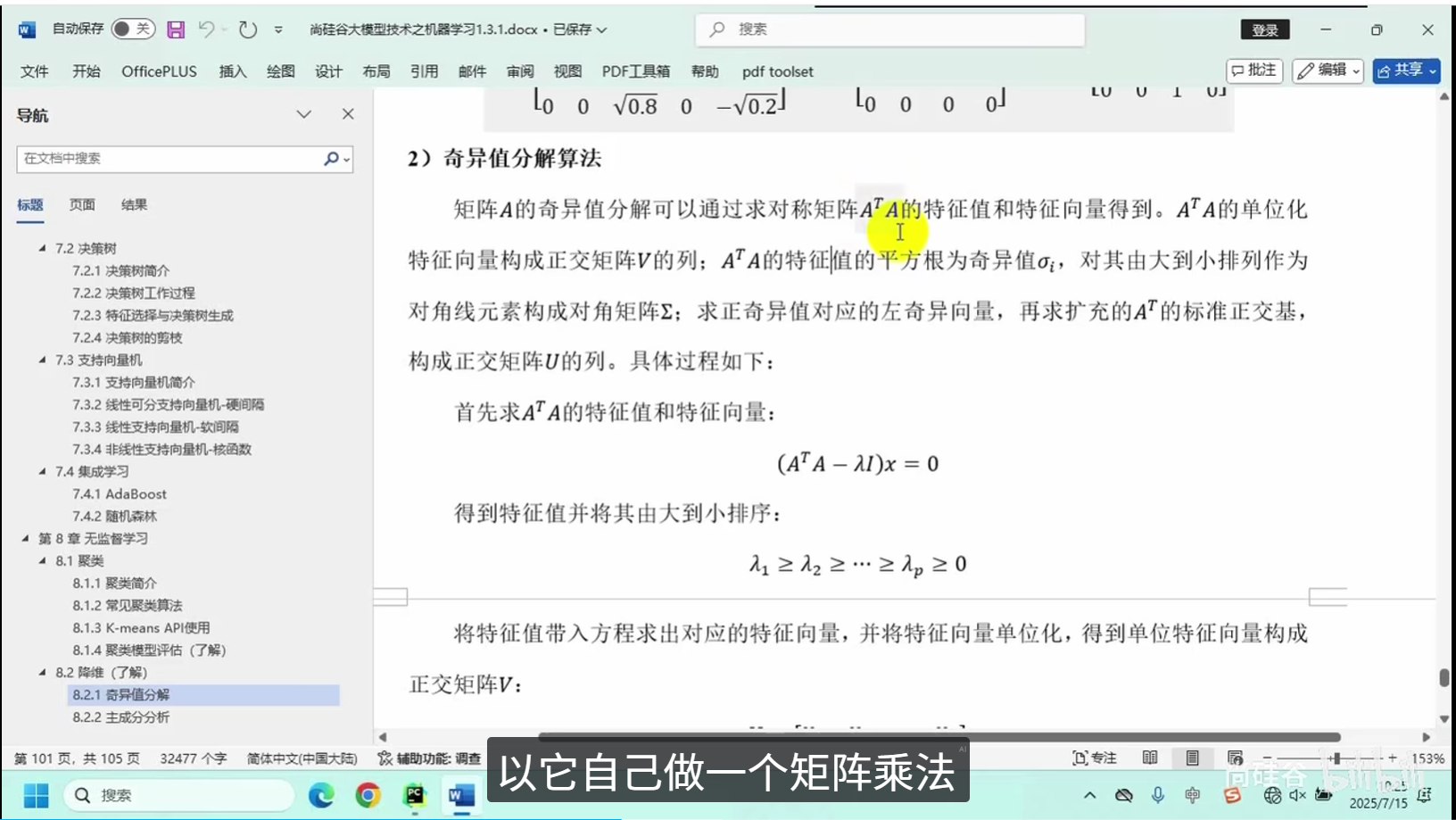
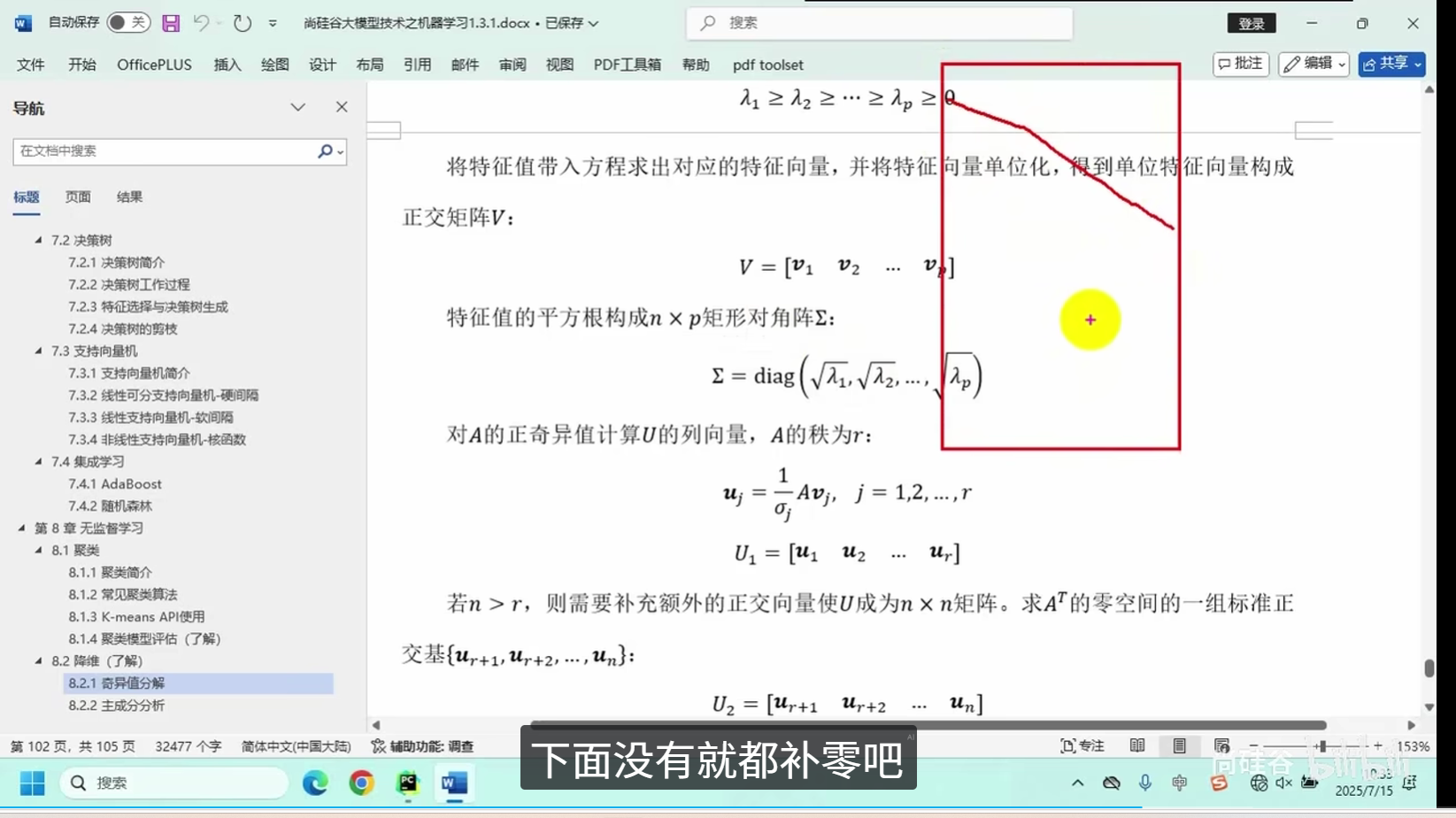
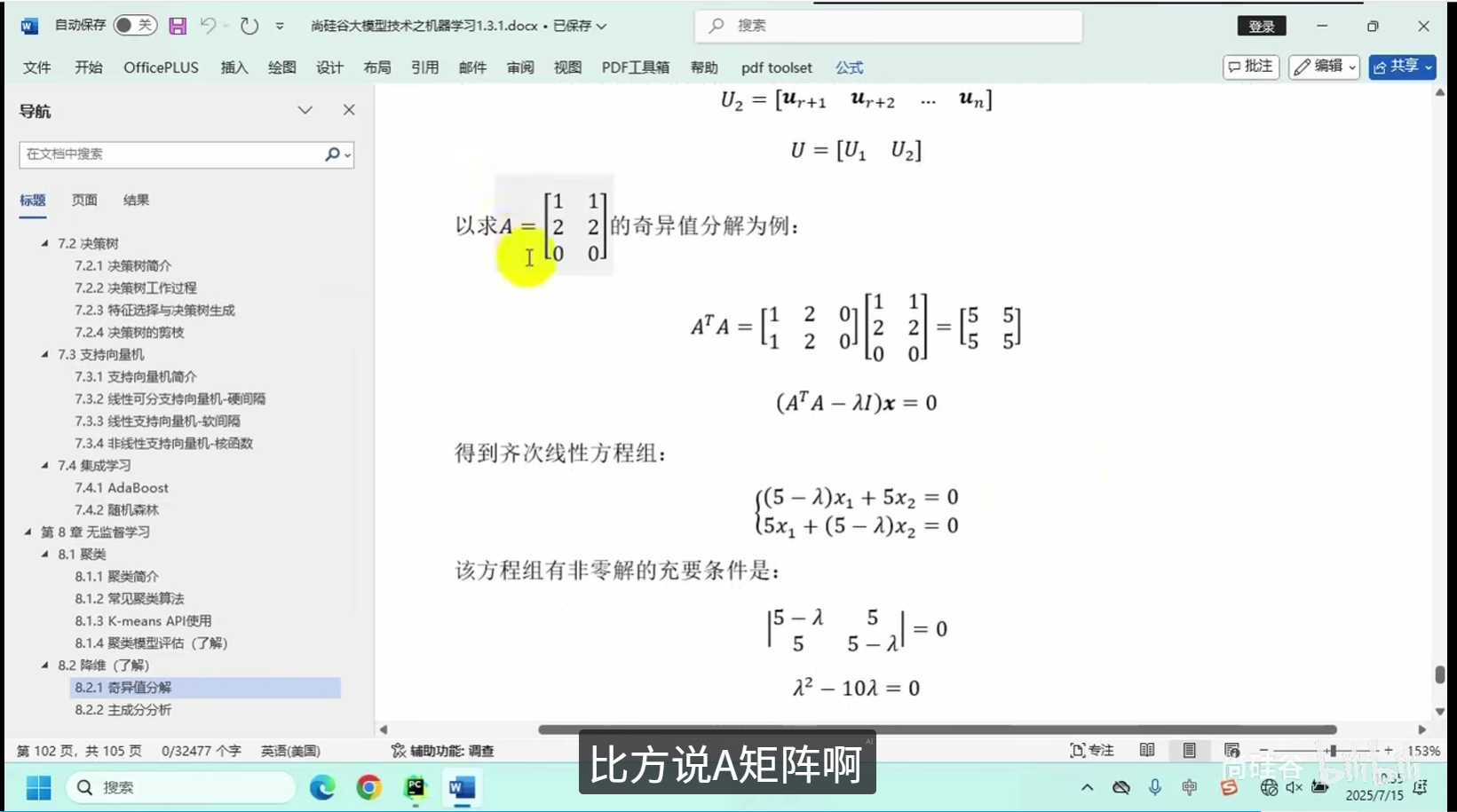
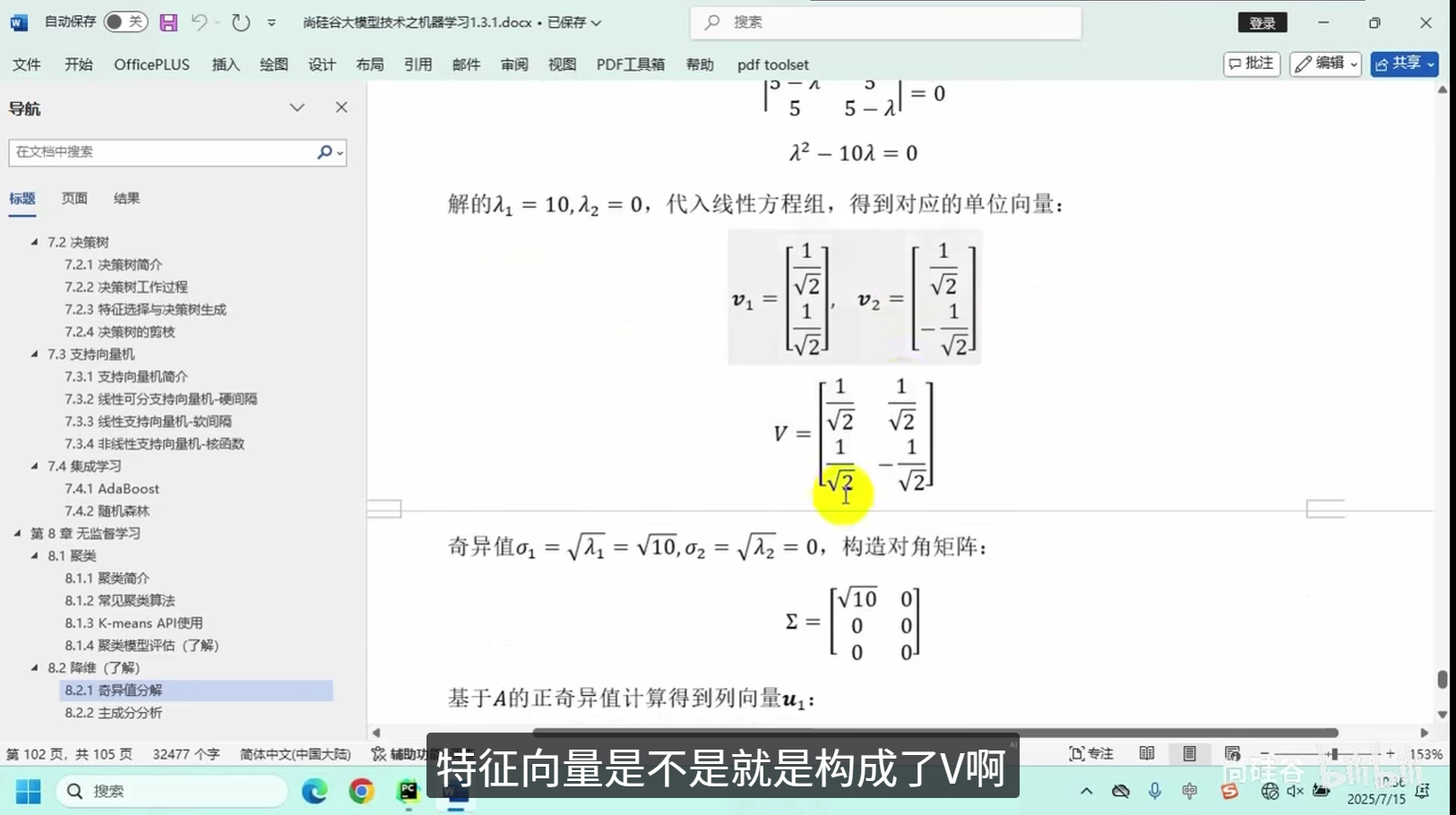
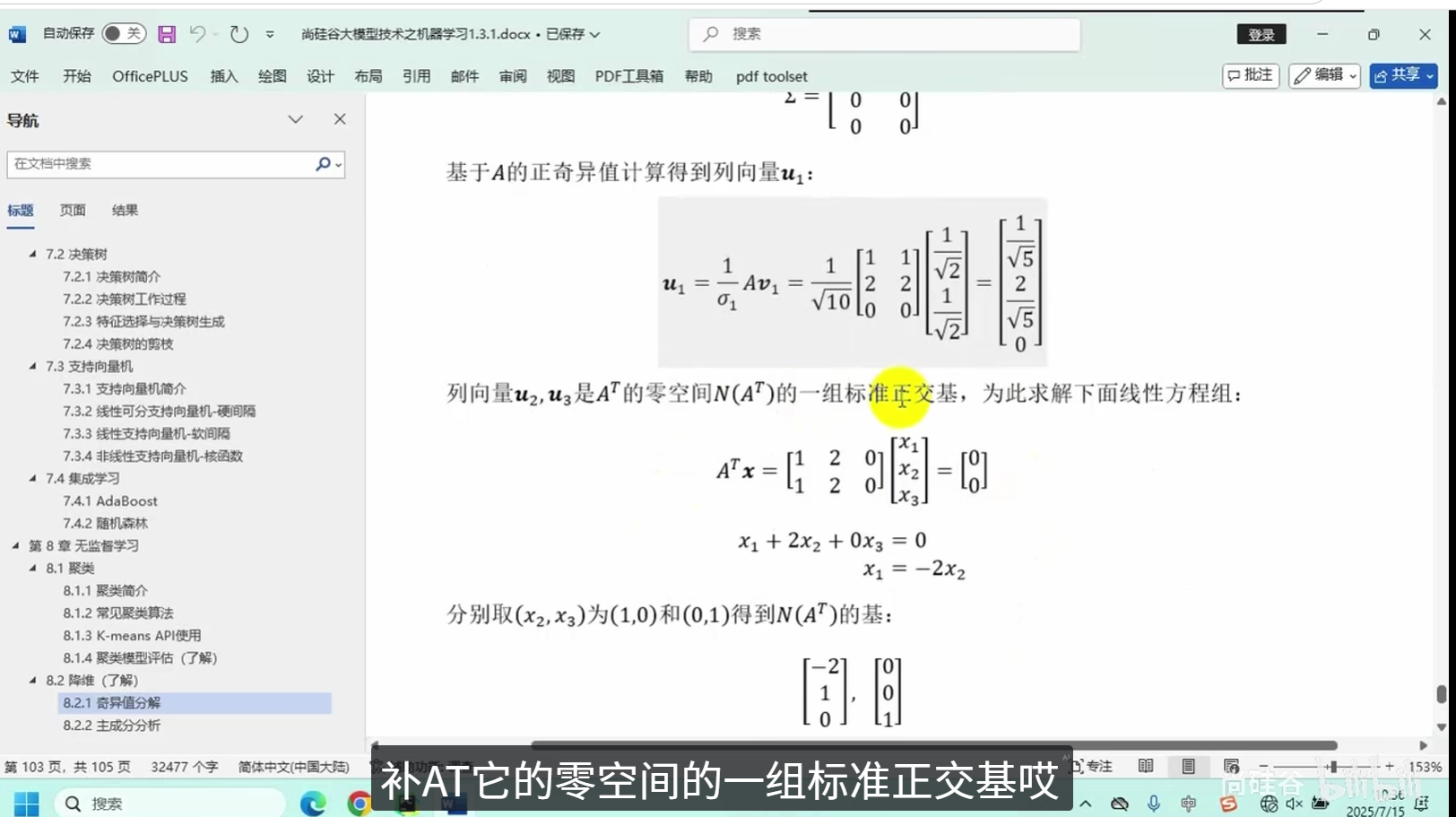
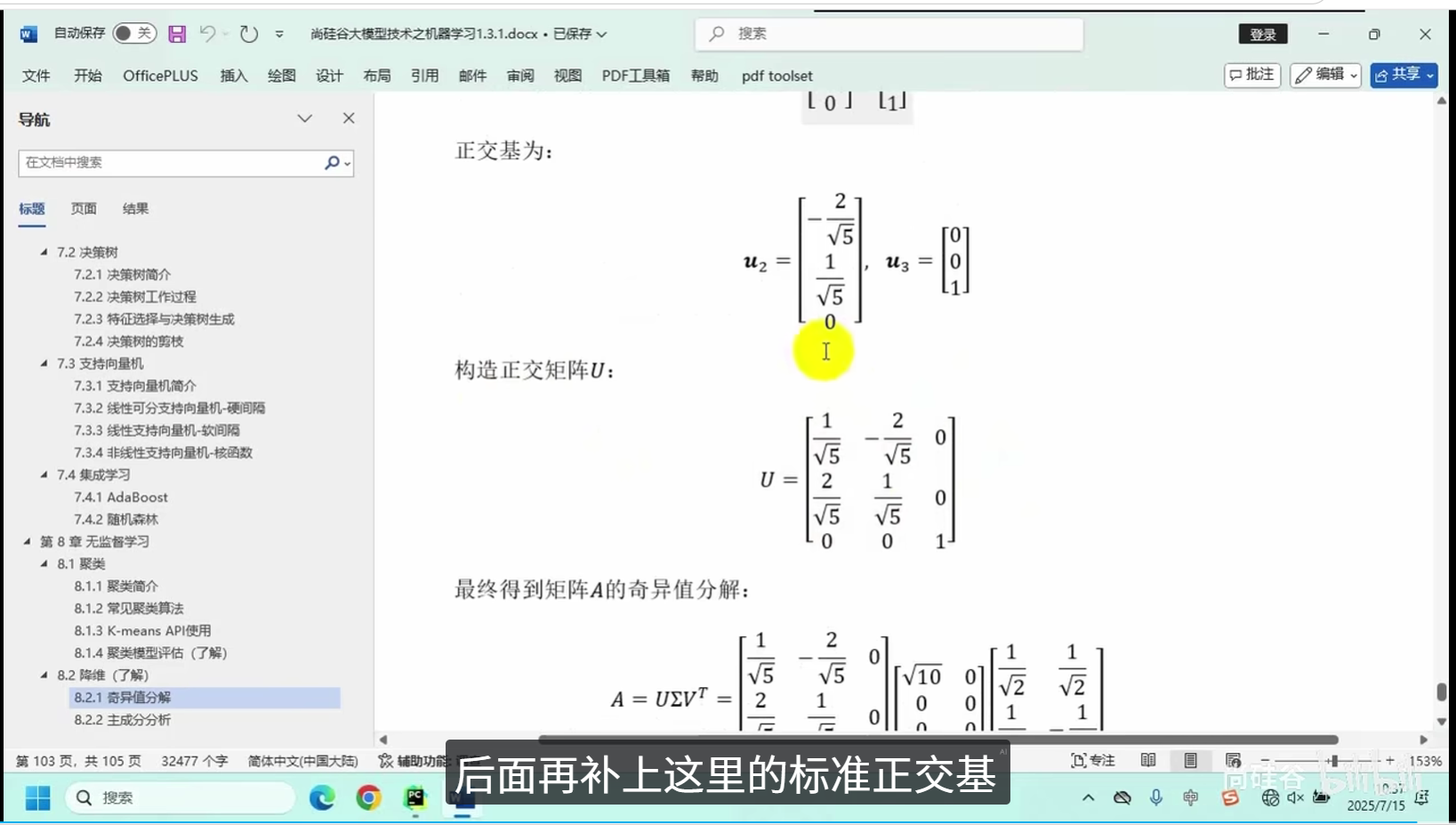
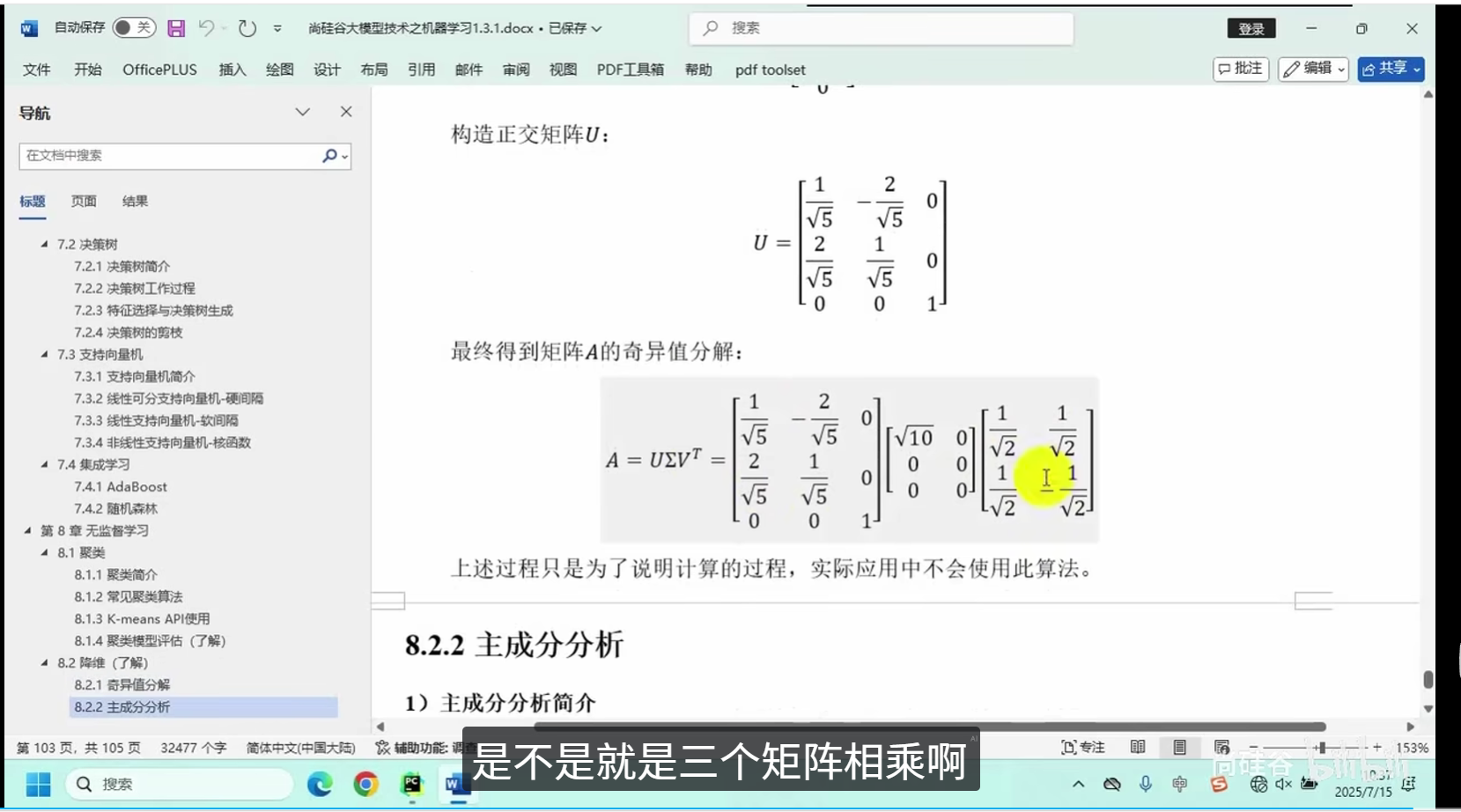
主成分分析
核心逻辑:将高维度复杂数据映射至低维空间,在最大限度保留原始数据核心特征的前提下,简化数据结构、减少冗余信息。
常用算法:主成分分析(PCA)、t-SNE等
应用场景:高维数据可视化、机器学习特征提取、简化模型、降低计算成本
3. 异常检测(Anomaly Detection)
核心逻辑:基于常规数据的分布规律,识别出偏离整体样本特征、不符合正常模式的异常数据点。
应用场景:金融欺诈检测、工业设备故障监控、网络异常流量识别等
4. 关联规则挖掘(Association Rule Mining)
核心逻辑:挖掘海量数据中不同数据项之间的潜在关联、共生关系。
应用场景:电商购物篮分析、个性化推荐系统、用户行为关联分析等
三、算法类型
无监督学习算法根据建模逻辑,可分为两大类别:
1. 确定型方法
代表算法:自编码器(含稀疏自编码器、降噪自编码器等改进算法)
核心目标:近乎无损地还原原始输入数据,精准学习数据固有特征。
2. 概率型方法
代表算法:受限玻尔兹曼机(RBM)
核心目标:通过概率模型拟合数据分布规律,让模型在稳定状态下的数据出现概率最大化。
四、应用场景
无监督学习主打无标签、探索性数据分析,广泛应用于以下场景:
-
数据探索与分析:挖掘数据集的自然分组、隐藏模式与分布规律
-
辅助特征工程:为监督学习、深度学习模型提炼优质特征,提升模型效果
-
用户与市场分析:基于用户行为数据自动分群,构建用户画像、完成市场细分
-
多媒体与文本处理:实现图像压缩、文本主题聚类、内容分层归类
五、与其他机器学习范式的区别
| 学习范式 | 数据特点 | 核心目标 |
|---|---|---|
| 监督学习 | 依赖大量人工标注数据 | 学习输入与标签的映射关系,完成分类、回归预测 |
| 无监督学习 | 全部为无标注原始数据 | 自主挖掘数据内在结构、模式与关联规律 |
| 半监督学习 | 少量标注数据 + 大量无标注数据 | 结合两类数据优势,兼顾数据探索与精准预测 |
总结
无监督学习无需人工标注成本,主打自主探索与数据挖掘,在数据分析、特征提取、未知场景探索研究中具备不可替代的核心价值,是机器学习体系中重要的基础学习范式。