这两天腾讯 AI 的信息量有点大。。。
6 月 5 日,腾讯云 AI 产业应用大会上,汤道生和姚顺雨做了一场公开对谈。
6 月 6 日,汤道生又接受了一轮媒体采访,把很多外界关心的问题继续摊开讲了一遍。
我看完之后的感受是:腾讯这次终于把自己对 AI 的想法说清楚了。
至于"腾讯终于要发力了"这种套话,反而没那么重要。每次大厂一开会都这么写,真没啥意思。
腾讯这次想说的其实很简单:模型只是一块。元宝、WorkBuddy、CodeBuddy、文档、会议这些产品和工具,得接到同一个任务流程里,让 AI 拿得到上下文、调得动工具,最后真的把事做完。

图源:腾讯官方大会资料。
这可能正是腾讯最适合走的那条路。
我觉得腾讯最该做的,也就是这件事。
先说个容易搞混的。
这次的主角是姚顺雨,别和姚顺宇混了。
姚顺雨是清华姚班、普林斯顿 CS 博士,做 ReAct、Tree of Thoughts、语言智能体这些方向,之前在 OpenAI,后来加入腾讯,任腾讯首席 AI 科学家。
姚顺宇是另一位,清华物理、斯坦福理论物理博士,之前在 Anthropic 和 Google DeepMind。
两个名字只差一个字,但路线完全不一样。

两个 Shunyu Yao 照片对比图。
先把这个捋清楚,不然后面全串台了。
外界问腾讯 AI,最爱问的就是一个问题:
腾讯在 AI 上的动作是不是变慢了?
ChatGPT 出来之后,OpenAI、Anthropic、Google、DeepSeek、KIMI、GLM、字节、阿里,都有过让外界记住的模型或产品。相比之下,腾讯过去一段时间确实不算最抢眼。
但姚顺雨这次没有直接回避。
他没有硬说腾讯动作一点都不慢。
他直接给大家抛出来了一个问题:
AI 到底是一个短期游戏,还是一个长期游戏?
如果 AI 是两年内决胜负的短跑,那产品推进慢、模型发布慢、市场反应慢,确实好像是大家认为的那样。
但如果 AI 更像 PC 刚出现时的 70 年代,那现在其实还有大量产品形态还没填满。
现在最容易被记住的是 ChatGPT 和 Claude Code。聊天和写代码只是其中两类产品形态。多模态、具身智能、办公协作、企业流程这些东西,现在还没有定型,未来几年还会有新的产品形态跑出来。
这话里确实有解释过去节奏的部分。
但它也讲到了腾讯自己的产品条件。
说到底,腾讯这种公司,本来就不擅长每三个月做一次惊艳全球的模型发布会。
它更擅长把 AI 能力放进真实产品里,让大量用户每天用,再根据反馈一轮一轮迭代。
如果 AI 下半场更看产品,这条路就还有机会。
如果 AI 下半场最后只看模型,那腾讯确实会很难受。这话说直白点,腾讯就不适合天天跟人拼发布会节奏。
所以我觉得,腾讯这次讲"长期游戏",是在把自己的想法讲清楚。
它确实更适合在产品里持续迭代。靠下一次模型发布会吸引注意力,对它来说没那么合适。
换句话说,这就是腾讯现在面对的取舍。
姚顺雨这次讲得最关键的一句话是:
过去 AI 更重要的是找方法,现在更难的是找问题。
以前做 AlphaGo,是为围棋设计一套方法。
做翻译,是为翻译设计一套模型。
方法和问题基本绑定。
但预训练、后训练、大模型出来以后,情况变了。模型能力变强了,于是产品团队得重新回答一个问题:
到底该先解决哪个具体问题?
腾讯能拿出来的东西,首先是具体需求和上下文。
它手里有大量真实产品,也就有大量真实问题。
社交、办公、会议、文档、游戏、金融、医疗、教育、企业协作,都是问题。
而这些问题背后,还有上下文。
用户过去怎么用产品,企业内部有哪些资料,会议里说了什么,文档里改过哪些内容,开发流程里哪些地方最容易卡住。
这些东西,不是 benchmark 里能长出来的。
所以姚顺雨反复提 context。
简单讲,就是模型干活前拿到的那些"前情提要"。
模型越来越强之后,产品差距开始落到具体材料上。用户手里的资料、会议记录、文档修改历史、代码仓库、企业权限,这些东西能不能被 AI 用上,变得很重要。
说白了,AI 下半场拼的,是谁更知道用户到底想解决什么问题。 这会直接影响产品能不能帮用户把事做完。
Co-Design 比刷榜更重要
这次访谈里还有一个关键词:Co-Design。
这个说的是模型和产品共同设计。
你可以理解成,模型团队别只顾着刷榜,产品团队也别等模型训完之后,再把它放进产品流程里。
两边要一起定目标、一起看数据、一起改体验。

图源:腾讯官方大会资料。
过去大家很容易盯着 benchmark。
数学多少分,代码多少分,长文本多少 token,排行榜第几名。
这些当然有用,但问题是,真实用户不会像 benchmark 一样提问。
真实用户经常会这么做:
先问一句话,然后聊着聊着又会追问、改口、补材料,还会把搜索、文档、会议、代码、表格混在一起。
这时候,模型能不能接住上下文,能不能把工具调起来,就比单次问答分数更接近用户体验。
所以汤道生在 6 月 6 日采访里提到,姚顺雨来了之后,推动混元从原来更在意外部 benchmark,转向以产品用户体验作为主要衡量标准。
这点我觉得比"某个榜单涨了多少分"更重要。
因为这代表模型团队终于要从给评测集交作业,转向给产品体验负责。
汤道生还说,训练 Hy3 之前,姚顺雨做了大量数据质量的工作,砍掉很多看起来很能堆数据量,但实际对模型训练没有帮助,甚至有害的数据。
这个动作说明了一件事。
很多人一谈模型训练,就默认数据越多越好。
但真实情况可能是,有些数据不是资产,是污染源。
敢砍数据,比敢堆数据更难。
这个决策其实挺狠的,也非常果断。
我觉得这比"混元某个榜单涨了几分"更说明问题。
因为榜单涨几分,普通用户可能根本感觉不到。
但如果元宝、WorkBuddy 里的回答更稳、任务跑得更快、用户愿意多用几次,这个变化才能吸引人持续使用。
目前看,Hy3 已经在元宝、CodeBuddy、WorkBuddy 这些产品里都接入了。
腾讯官方说,WorkBuddy 接入 Hy3 Preview 后,首次响应速度提升 54%,任务平均完成时间缩短 47%。汤道生也说,大概 80% 元宝用户已经在用 Hy3,留存率有明显提升。
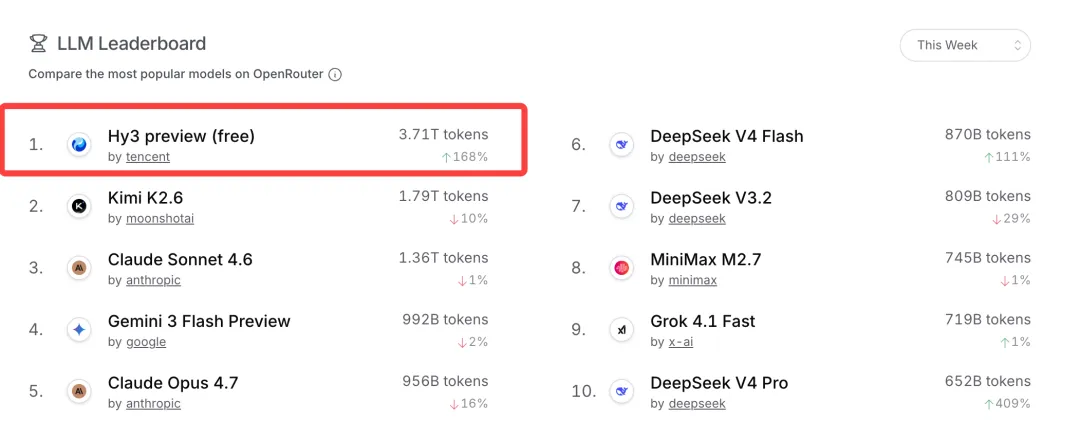
图源:腾讯云开发者社区。
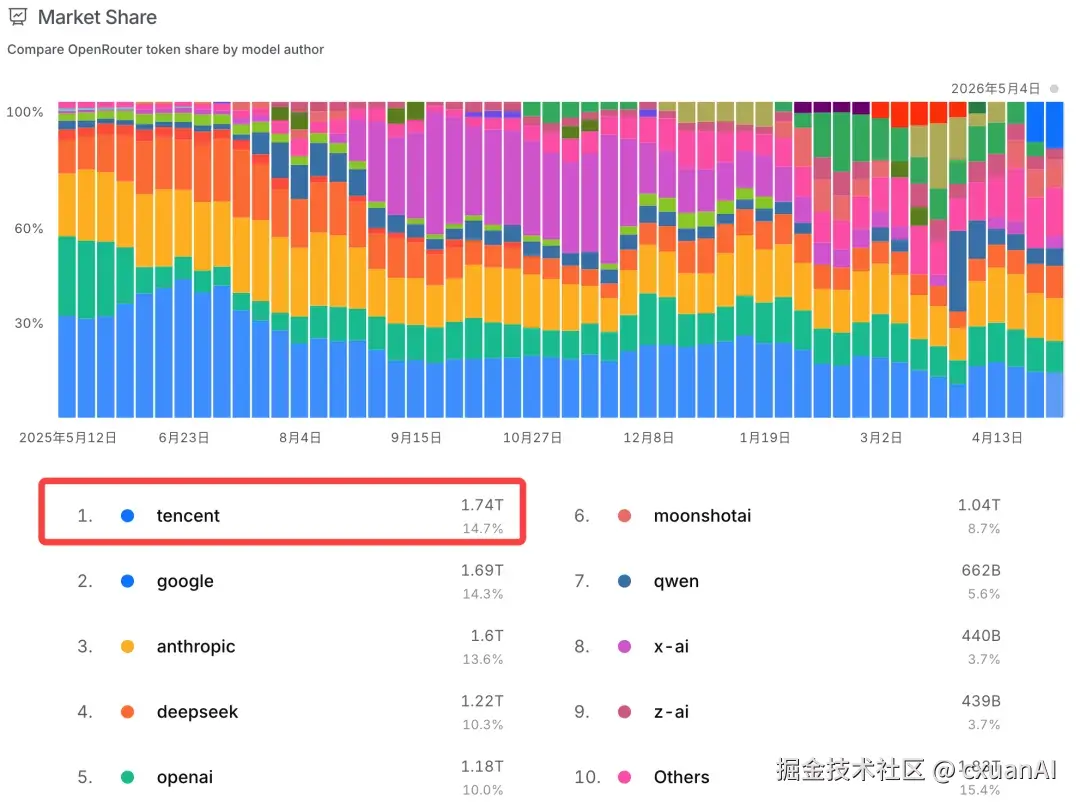
图源:腾讯云开发者社区。
这些数字不代表腾讯已经赢了,现在下结论还为时过早。
但至少可以这么认为:产品反馈开始进入模型训练、评测和产品迭代中。
腾讯这次还发布了"效率智能体工具集",覆盖 20 多个垂直场景。
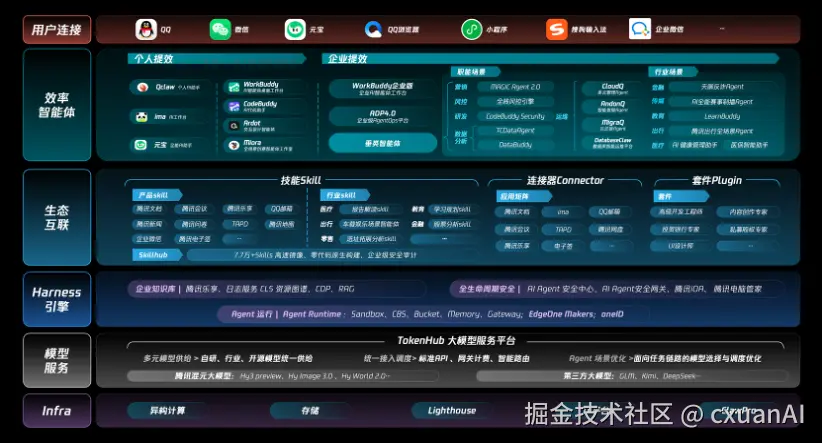
图源:腾讯官方大会资料。
个人侧有 QClaw、WorkBuddy、元宝、ima、腾讯文档。
企业侧有 WorkBuddy 企业版、ClawPro、腾讯云智能体开发平台 ADP 4.0、企点营销云。
看名字有点眼花。
但我觉得,这事儿别理解成腾讯突然发布了一堆 Agent。
更准确地说,是腾讯怎么把过去沉淀在各个产品里的能力,变成 Agent 能调用的工具。
腾讯文档要变成 WorkBuddy 能调用的 Skill。
腾讯会议沉淀会议上下文,让 Agent 理解、调用、生成纪要、提炼待办。
企业微信继续承担人与人、人与服务的连接。
WorkBuddy 则更像人和 AI 协作的工作台。

图源:新浪转载腾讯云相关稿件
图源:腾讯云 ADP 官网截图。
Agent 难就难在这里。
只套一个聊天框,然后让模型自己发挥,撑不起 Agent。
你得给它工具、记忆、权限、上下文和可执行环境。
没有这些,Agent 就是一个很会说话的客服。
有了这些,它才有机会真的干活。否则只能给一段看起来对的回答,任务还得留给人来做。
我觉得很多 Agent 产品现在的问题就在这。
聊天的时候看起来还行,一到执行任务,就能看出差距。
腾讯如果真有优势,也应该是在"动手环节"这里。再做一个更会聊天的入口,意义没那么大。
汤道生在访谈里提到一个细节,有点意思。
他说,过去产品研发是很典型的瀑布流:
产品经理写 PRD,交互设计师设计流程,视觉设计师做界面,前端后端实现,最后测试。
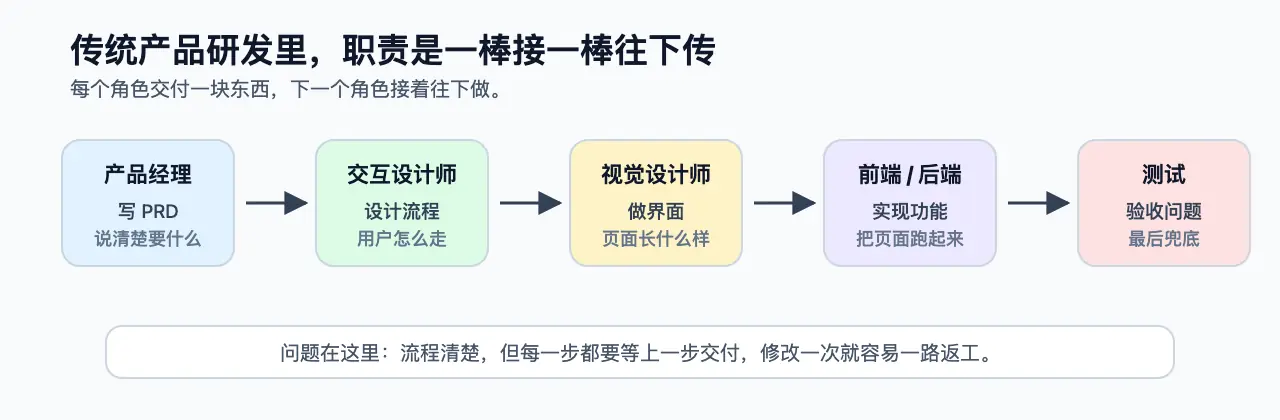
传统研发职责流转图。
AI 开始生成大量代码后,这条线不再这么一棒接一棒往下传。
很多工程师少敲一点键盘,把更多时间花在定义结果、架构设计、评测和测试上。
一个工程师甚至能像小组负责人一样,带着几个 Coding Agent 一起做需求、写代码、跑测试。这已经不是简单的"辅助写代码"了。。。
这和我最近用 Codex、Claude Code 的体验很相似。
等 AI 真能写很多代码,人最重要的能力就从"我能不能写出这一段",变成"我知不知道这一段该不该写"。
以前实现能力是门槛。
以后更重要的是判断需求该不该做、模块怎么拆、接口怎么定、最后怎么验收。
腾讯官方还提到,CodeBuddy 已覆盖腾讯超过 95% 的工程师,整体编码时间缩短 40%。
图源:WorkBuddy 官网截图。
图源:CodeBuddy 官网截图
这个数字不一定能直接外推到所有公司。
但至少方向摆清楚了。
程序员不会立刻消失。更大的变化,是从写代码的人,变成驱动 AI 写代码并负责结果的人。
这对普通工程师来说,是机会,也意味着压力。
这次访谈里,汤道生讲商业化讲得比较谨慎。
WorkBuddy 这类智能体目前仍处在战略投入期,腾讯没有给团队设商业化目标。
因为 AI 产品现在最大的问题变了。
用户想用只是第一步,用得越多成本越高才是真压力。
移动互联网时代,边际成本很低,广告、交易、带货都有机会覆盖成本。
但 AI 不一样,推理成本是真金白银。
每一次复杂任务都要消耗 token、算力、工具调用和存储。任务越复杂,成本越不可控。
所以汤道生说,AI 原生服务很难单纯靠广告覆盖推理成本,更适合先用在那些高商业价值、能算得过账的场景里。
这也是现在所有 Agent 产品必须面对的问题。
Demo 做得再好,也只是第一步。
一旦进了真实业务,企业就要算预算、计费方式、责任边界和成本分摊。每一项都会影响产品能不能长期跑下去。
腾讯还有一个更具体的压力:算力。
汤道生多次提到算力紧张,有限资源优先满足内部产品,比如混元训练、微信、腾讯会议、元宝等。把 GPU 租给外部客户,优先级相对靠后。
这也解释了为什么腾讯不急着把 AI 包装成一个高利润故事。
它现在更像是在做基础设施和产品试错。
先把使用量、产品留存、模型反馈和工具链跑起来。
等这些数据稳定下来,再谈收费方式和利润空间。
现在很多 AI 产品有需求。
麻烦在于,需求一上来,成本也跟着上来。
用户越活跃,公司越肉疼。。。这放以前移动互联网里没这么明显,但 AI 时代确是实实在在的问题。
这次姚顺雨和汤道生的访谈,不能证明腾讯 AI 已经赢了,瑶瑶领先了。
但腾讯终于把自己想怎么做说清楚了。
单纯追模型榜单,这条路不可行。
只做一个聊天机器人,更不可行。
把所有希望押在某个爆款 Agent 上,同样不够。
腾讯这次讲的是把模型、产品、上下文、工具、数据反馈和内部协作方式放在一起做。
这条路更符合腾讯过去做产品的方式。
腾讯的优势,是场景多、产品多、用户多、内部工具链复杂。
腾讯的麻烦,也恰好是这些东西太多、太复杂、太难协调。
所以我不觉得腾讯这条路会走的很容易。
它的优势和难点是同一个东西:产品太多,场景太多,组织也太大。
所以后面不用盯着腾讯下一次模型发布会能不能讲得更漂亮。
到最后,还是得看元宝、WorkBuddy、CodeBuddy、QClaw 这些产品,能不能用上上下文,调起工具,把任务跑完,并且让用户愿意继续用。
AI 下半场不能只看模型发布会。
AI 下半场,要看谁能把模型放进真实业务里,让它长期稳定地把任务做完。
这也是我觉得这次访谈有价值的原因。至少腾讯这次讲了产品、上下文、工具和成本,没有只喊口号。
资料来源:
- 新浪科技:《现场实录|汤道生对话姚顺雨:腾讯AI的下半场》
- 腾讯官方:《腾讯云首发效率智能体工具集,构建面向多元人群的AI生产力入口》
- 东方财富网转载界面新闻:《对话腾讯汤道生:AI业务还处于战略投入期 业务阶段性快慢很正常》
- 腾讯云开发者社区:《混元3 Preview 相关资料》
- 姚顺雨个人主页:ysymyth.github.io/
- 姚顺宇 Google Scholar:scholar.google.com/citations?u...
- WorkBuddy 官网:www.workbuddy.cn/
- CodeBuddy 官网:www.codebuddy.cn/
- 腾讯元宝官网:yuanbao.tencent.com/
- 腾讯云 ADP 官网:adp.tencentcloud.com/zh