文章目录
- 前言
- MySQL数据库初步认识
- MySQL体系的架构
- MySQL的基本使用
- SQL的分类
- 存储引擎
- 创建数据库
- 字符集和校验规则
- 查看MySQL的连接情况
- 使用数据库
- MySQL表的操作
- MySQL数据类型的分类
前言
MySQL 作为目前最主流的关系型数据库,是后端开发的基本功。本文聚焦 MySQL 最核心的基础内容,不搞花里胡哨,只讲实用干货。
文章涵盖 MySQL 基础概念、C/S 架构、数据库的创建 / 查看 / 修改 / 删除、数据表的全量操作、SQL 分类、存储引擎、字符集校验规则、数据库备份还原,以及MySQL 核心数据类型(数值、字符串、日期时间、enum/set 等)等关键知识点,搭配大量命令示例与原理说明,看完就能上手实操,帮你快速搭建起 MySQL 基础知识体系,少走弯路。
MySQL数据库初步认识
mysql(也就是MySQL):是数据库服务的客户端
mysqld:是数据库服务的服务器端(也叫做数据库服务)数据库:一般指的是再磁盘或者内存中存储特定结构组织的数据(也就是在磁盘上存储的一套数据库方案)
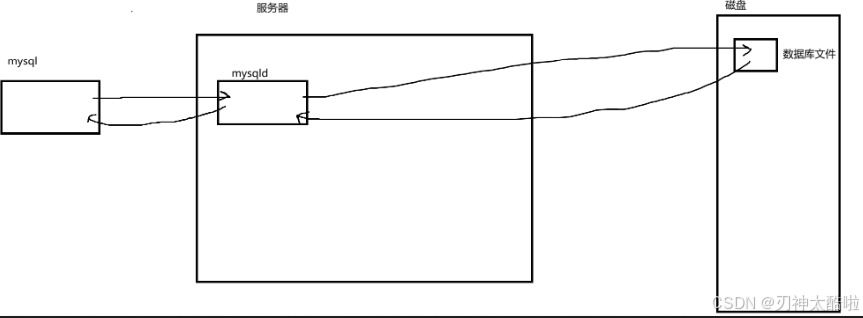
但是一般日常说
mysql或者mysql数据库或数据库通常指的是一整个mysql体系mysql体系的本质:基于C(mysql)S(mysqld)模式的一种网络服务
当然,除了MySQL以外,还要其他的数据库,比如:
SQL Sever
虽然一般的文件提供了数据的存储功能,但是对于用户来说,文件并没有提供非常好的数据内容的管理能力
引申:MySQL对SQL的关键字是不区分大小写的eg:
create database t1;和CREATE DATABASE t1;是一样的
服务器,数据库和表的关系
建立数据库,本质就是Linux下搞一个目录
在数据库内的目录里面建立表(表是二进制文件),本质就是在Linux下创建对应的文件而已
数据库的本质也是文件--只不过是数据库服务在帮忙进行管理
所谓的安装数据库服务器,其实就是装了一个数据库管理系统程序,这个程序可以管理多个数据库
MySQL体系的架构
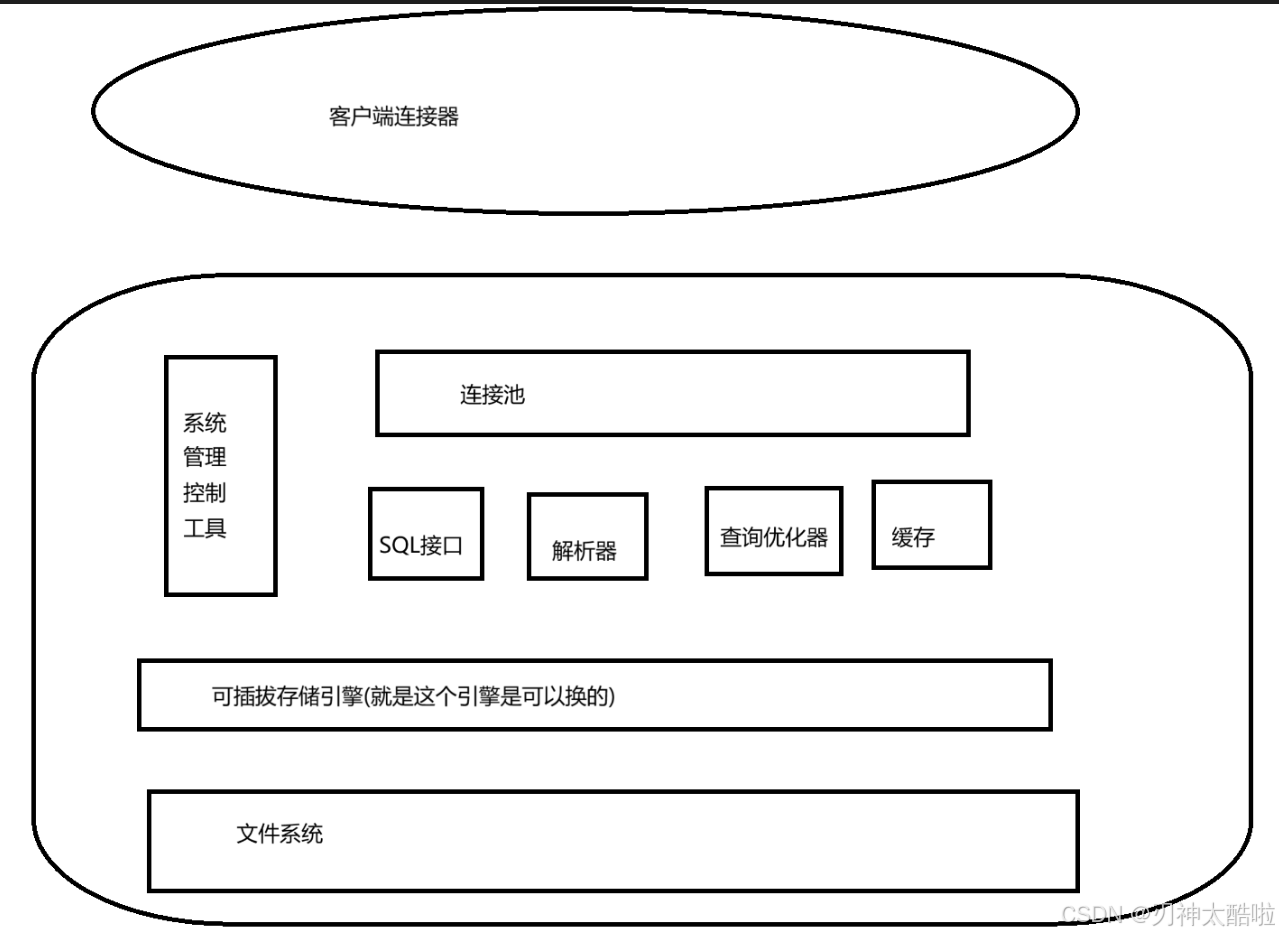
MySQL的基本使用
连接服务器
指令:
mysql -h 要连接的mysqld的主机地址 -P 端口号 -u 用户名 -peg:
mysql -h 127.0.0.1 -P 3306 -u root -p这个
-p是指明要输入密码(注意:密码输入时是不回显的)没有写
-h 要连接的mysqld的主机地址默认是连接本地没有写
-P 端口号默认是3306
mysql -uroot -p其实就是mysql -h 127.0.0.1 -P 3306 -u root -p的简写
SQL的分类
DDL(数据定义语言):用来维护存储数据的结构的 比如:
createDML(数据操纵语言):用来对数据进行操作的 比如:
insertDCL(数据控制语言):主要负责权限管理和事务的 比如:
grant
存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法
查看存储引擎的方法:show engines;用
show engines \G的话,显示的会不乱一些
存储引擎的话:主要用的是MylSAM和InnoDB(但是InnoDB用的又比MylSAM多很多)
创建数据库
格式:
create database [if not exists] db_name [create_specification...];
create_specification有character set charset_name(用charset=charset_name是一样的)和collate collation_name(用collate=collation_name也是一样的)
[]表示是可选项
if not exists表示 如果还没这个db_name就会创建数据库;如果已经存在的话,就会直接警告(不是报错)
db_name:数据库的名字
character set charset_name:指定数据库采用的字符集,没写就默认是配置文件里的值(配置文件里一般是utf8)
collate collation_name:指定数据库字符集的校验规则,没写就默认是配置文件里的值(配置文件里一般是utf8_general_ci)
bash
使用举例:
create database if not exists text1 charset=utf8 collate utf8_general_ci;
本质就是在/var/lib/mysql下创建一个目录不要尝试在没启动
mysql的情况下去在那个目录下去创建--虽然是可行的,但是是不符合规矩的
引申:mysql里面的关键字都是大小写不敏感的
字符集和校验规则
查看系统默认字符集和校验规则
bash
查看系统默认字符集:show variables like 'character_set_database';
查看系统默认校验规则:show variables like 'collation_database';引申:
%是MySQL 中LIKE语句的 "通配符"eg:
show variables like 'collation_%';会看到所有以 "collation_" 开头的变量名
查看数据库支持的字符集和校验规则
bash
查看数据库支持的字符集:show charset;
查看数据库支持的校验规则:show collation;数据库字符集(数据库编码集):决定可以存储什么类型的东西eg:
utf8支持存中文数据库校验集:决定这些字段怎么比较和排序的
数据库无论对数据做任何操作,都必须保证操作和编码是编码一致的!
校验规则对数据库的影响
一个字符集通常会有很多个校验规则
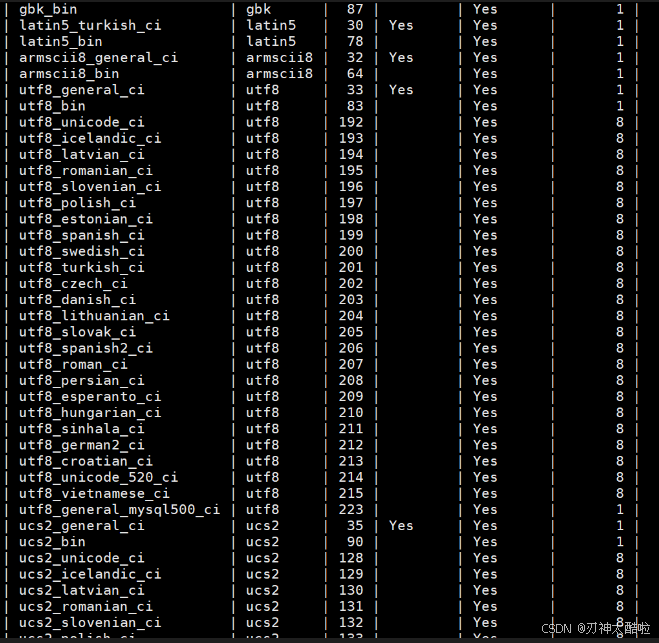
对应
utf8而言的话:在查找或者对查找的数据进行排序时如果使用的是
utf8_general_ci的话,是不会区分大小写的如果使用的是
utf8_bin的话,是会区分大小写的
查看MySQL的连接情况
bash
show processlist
可以查看当前都有哪些用户连接了本机的MySQL表的结构的增删查改都属于SQL里面的DDL
向表的具体数据的增删改属于SQL里面的DML,插属于SQL里面的DQL
使用数据库
数据库不能进行重命名--当然也不推荐随便改数据库的名字(因为这样的话,上层使用了这个库的也要改)
查看数据库
bash
show databases;显示创建语句
bash
show create database db_name;
/*!40100 default.... */表示的是如果当前mysql版本大于4.01版本,就执行这句话;不是注释!!!
修改数据库
bash
alter database db_name [alter_specification...];
这里的[alter_specification...]跟上面一样删除数据库
bash
drop database [if exists] db_name;
if exists:如果存在,那就删除;如果不存在,那就会警告
本质其实就是把那个/var/lib/mysql里的目录删除数据库的备份
bash
备份:就是把我们创建数据库,建表,导入数据的这些语句都装在到备份文件中
语法:mysqldump -P3306 -u root -p [-B] 数据库名 > 数据库备份存储的文件路径(包括文件名)
文件路径没说明的话,就是默认在当前路径下创建
-B:有这个表示带上创建数据库+切换到这个数据库;没有-B的话需要先自行创建数据库和切换到那个数据库才行
引申:备份文件推荐以.sql结尾
eg: mysql -P3306 -u root -p -B text1 > text1.sql
如果只想备份里面的几张表:
mysqldump -u root -p 数据库名 表名1 表名2 ... > 数据库备份存储的文件路径(包括文件名)
(这个必须要在)
如果想备份多个数据库
mysqldump -u root -p [-B] 数据库名1 数据库名2 ... > 数据库备份存储的文件路径(包括文件名)
还原数据库:mysql> source 备份文件的完整路径(包括文件名);引申:切换数据库:
use 数据库名;(不需要先退出当前数据库)
在MySQL里面用`system clear;`可以清空终端界面
MySQL表的操作
创建表
bash
create table [if not exists] table_name (
field1 datatype [其他属性eg:comment '注释'],
field2 datatype [其他属性eg:comment '注释'],
....//最后一个不加,
) [character set 字符集] [collate 校验规则] [engine 存储引擎];
//最后这行部分或全部搞成charset=字符集 collate=校验规则 engine=存储引擎也是一样的其他属性的写法是没有严格的要求固定顺序的
这是在当前数据库中创建表
table_name是表的名字
field是列名,datatype是列的类型
comment那个的话是最后一行那几个如果不选的话,都是采用的配置文件里面的(存储引擎的话配置文件里一般是
InnoDB)
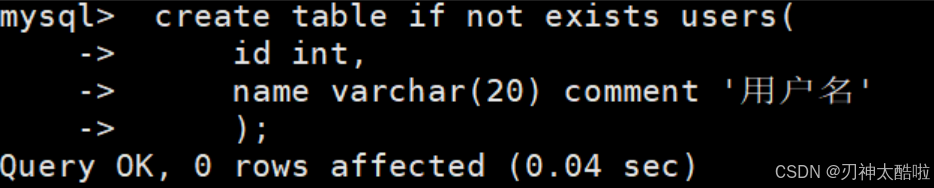
eg:
bashcreate table if not exists users(id int,name varchar(20) comment '用户名'); 这样也是一样的
注意:
使用的是不同的存储引擎的话,创建表时生成的文件是不一样的
比如:使用
MYISAM创建的表会有.frm(表结构).MYD.MYI文件(把数据和索引分开存了)
使用`InnoDB`创建的表就只有`.frm`(表结构) `.ibd`(把数据和索引合在一起存了)
查看表
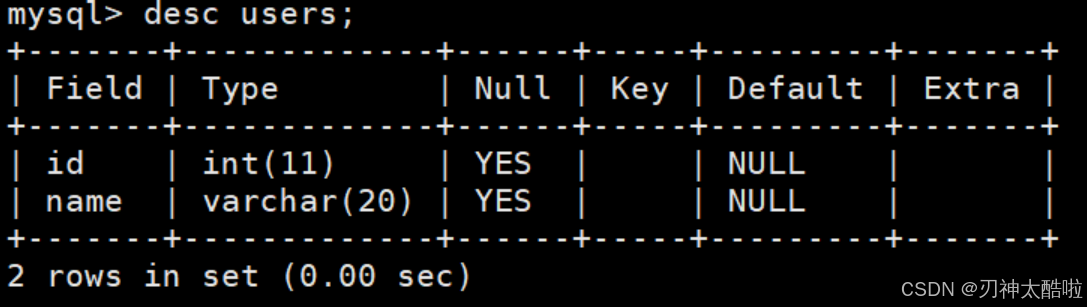
desc 表名;(会在当前数据库里去找)
Field:字段的名字
Type:字段的类型
NULL:是否允许为空
Key:索引类型
Default:默认值
Extra:扩充
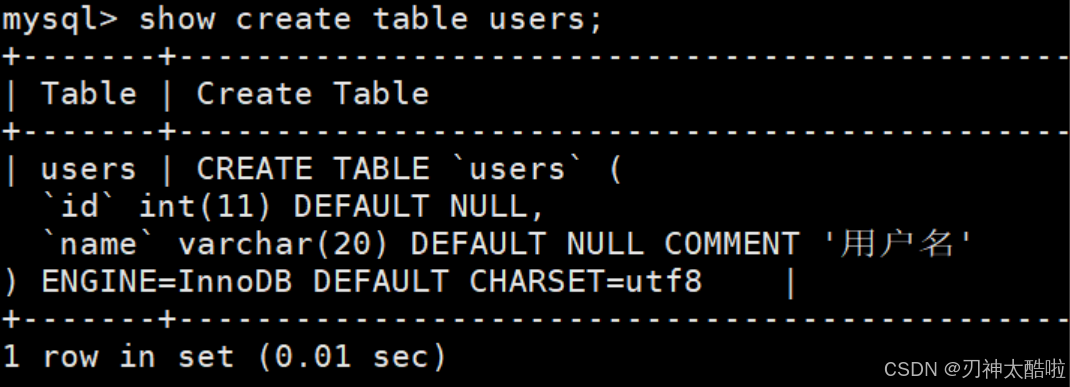
如果想知道创建表时的详细信息的话:show create table 表名;或者
show create table 表名 \G
修改表
bash
alter table table_name add(column datatype [其他属性][,...]);
//给table_name添加字段,这里的column是添加啥字段 datatype是字段类型
这个add默认是在末尾增加
如果要在column1的后面插入:()后加after column1;
如果要插入到头:()后面加first;
alter table table_name modify(column datatype [其他属性,eg:default][,...]);//修改字段属性
alter table table_name rename [to] now_table_name;//更改表名,有没有to都一样
rename还有种写法,可以更改多个表名:
rename table table_name to now_table_name,[...其他需要更改的表];//这里的to不能省略
alter table table_name change 原列名 新列名 新列名的datatype [其他属性];
注意:表名和列名不要随意修改,因为修改了的话自己封装的上层也必须跟着改
alter table table_name drop(column1[,...]);//删除字段
以上这几种,如果只对一个字段进行操作,可以把()去了
bash
向表中插入数据的话:
insert [into] 表名 values(字段的值[,...]);
如果只对表中的一些列插入,其他的用默认值的话:
insert [into] 表名 (列名1[,...]) values(字段的值[,...]);
查询表中数据
bash
select 要查询的列名1[,...] from table_name;
如果是查询所有列的话,可以:select * from table_name;
这个是看表内的具体数据,而
desc那个是看表的结构
删除表
bash
语法: drop [temporary] table [if exists] table_name1,table_name2 ...;
temporary:是只删除临时表(也就是由create temporary table那样创建的)
eg:
drop table if exists user1,user2;
当然,删除也可以只删除表里面的单个属性
eg:alter table 表名 drop primary key;--那个就是删除的主键如果我们向MySQL特定的类型里面插入不合法的数据,MySQL会直接拦截,不让我们这样做
--这样就可以保证我们插入到MySQL里面的数据一定是合法的
MySQL数据类型的分类

下面的话就只介绍几种常见的
数值类型
tinyint
数据类型: tinyint unsigned
占用空间为1个字节 可以存储的值最小是
-128,最大是127如果是
tinyint unsigned的话,那就是最小是0,最大是255
一般情况下unsigned没有,会选择去使用eg:tinyint存不下,就换一个更大的类型,而不是去搞个unsigned特例:年龄的话用
tinyint unsigned就不错
bit
bit (M) : 位字段类型
M:表示使用几个比特位 如果M被忽略,默认为1
eg:
bit(3)就表示有0-7这几个取值 插入时如果想插入3要直接3而不是11
小数类型
float
语法:
float[(m, d)] [unsigned] : m指定显示长度(可以<=),d指定小数位数,占用空间4个字节eg:
float(4,2)的话,取值可以是-99.99到99.99float(4,2) unsigned的话取值是0.00到99.99注意:如果精度不够,他会自己补;如果精度过高,他会四舍五入
--如果补和四舍五入完超过了
m,那就会不让这次操作成功如果不指定
m,d的话,可以任意长度和保留原小数位数(在不超过float范围的情况下)
decimal
语法:
decimal(m, d) [unsigned] : m指定长度,d表示小数点的位数这个跟
float的唯一不同点就是如果m被省略,默认是10;如果d被省略,默认为0
并且
decimal的精度比float高--eg:在MySQL5.0之后,float大概小数后7位左右,精度就开始不准了,但是decimal会比float强很多但是
float占用的字节数(固定4个字节)一般要比decimal(跟位数有关)小
字符串类型
定长和变长的选择:
定长比较浪费空间,但是效率高--变长则相反
定长的意义是,直接开辟好对应的空间
变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少
char
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255这个是定长,会提前开辟好空间
注意单位是字符,不是字节!--在MySQL里面,特殊符号比如:中文或者
,这些也是算一个字符
varchar
varchar(L): 可变长度字符串,L表示字符(不是字节)长度,最大长度65535个字节(不是字符)
总长度<=L的话都没事,所占用的空间是用了多少才开辟多少(但是预算会先跟表交流)
注意:L的最大值跟采用的什么编码集和表的总的待分配空间都有关系(注意65535的基础上要先减1-3个字节,因为有1-3个字节要用来记录数据大小数据量拉满的话肯定是要3个字节才够)
引申:utf8中一个字符要占3个字节
日期和时间的类型
常见的有三种类型:
1.
date:格式'yyyy-mm-dd',占用三字节2.
datetime:格式:'yyyy-mm-dd HH:ii:ss'表示范围从 1000 到 9999 ,占用八字节3.
timestamp:格式也是'yyyy-mm-dd HH:ii:ss',这个在插入时不用填,会自动成当前插入时的时间的
enum和set
这俩的区别就是
enum是多选一;set是可以多选多或者多选一
enum:enum('第一种选项'[,...])在选择的时候就直接填1,2这些或者填选项eg:比如
enum('男','女')的话,添加数据时,比如要男,就写'男'或者1
set:set('第一种选项'[,...])在选择的时候可以填选项(逗号隔开)或者用二进制表示开关eg:
set('手机','电脑','平板'),添加数据时:'手机,电脑'或者11(也就是011)
如果想查询set里面特定只喜欢...的人:(也就是严格匹配)用
select * from 表名 where 列名=...;eg:
select * from users where way='手机';如果想查询
set里面喜欢...的人(可以不单单喜欢这一个):用
select * from 表名 where find_in_set(..., 列名);eg:
find_in_set('电脑', way) and find_in_set)('手机', way);注意:这种要多个都符合的这种需要分开写才行