
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》 《MySQL数据库学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在学习 MySQL 数据库的过程中,查询语句是最基础、也是最常用的内容之一.无论是日常的数据检索、条件筛选,还是后续的数据分析与业务开发,都离不开对基本查询语法的熟练掌握.本篇文章将围绕 MySQL 的基本查询展开讲解,主要介绍
SELECT查询语句的基本使用方式,包括查询指定字段、设置查询条件、结果排序以及限制返回条数等内容.通过这些基础语法的学习,可以帮助我们逐步建立数据库查询思维,为后续学习多表查询、聚合函数、分组统计等进阶内容打下良好的基础.如果你和我一样刚开始接触 MySQL,或者想系统回顾 SQL 查询的基础用法,那么这篇文章将带你从最常见的查询场景入手,一步步掌握 MySQL 基本查询的核心知识.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!

目录
- 1.表的增删改查
- 2.Create
- 3.Retrieve
-
- 3.1SELECT列
- 3.2WHERE条件
-
- 3.2.1英语不及格的同学及英语成绩(<60)
- [3.2.2语文成绩在80, 90分的同学及语文成绩](#3.2.2语文成绩在[80, 90]分的同学及语文成绩)
- 3.2.3数学成绩是58或者59或者98或者99分的同学及数学成绩
- 3.2.4姓孙的同学及孙某同学
- 3.2.5语文成绩好于英语成绩的同学
- 3.2.6总分在200分以下的同学
- 3.2.7语文成绩>80并且不姓孙的同学
- 3.2.8孙某同学,否则要求总成绩>200并且语文成绩<数学成绩并且英语成绩>80
- 3.2.9NULL的查询
- 3.3结果排序
- 3.4筛选分页结果
-
- [3.4.1按id进行分页,每页3条记录,分别显示第 1、2、3页](#3.4.1按id进行分页,每页3条记录,分别显示第 1、2、3页)
1.表的增删改查
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除).
在 MySQL 数据库的学习过程中,表是存储数据的核心对象,而对表中数据进行增、删、改、查操作,则是数据库使用中最基础、最常见的内容.无论是添加新数据、删除无效数据,还是修改已有数据、查询目标数据,这些操作几乎贯穿了数据库应用开发的全过程.
下面将围绕 MySQL 表的增删改查展开讲解,主要介绍 INSERT、DELETE、UPDATE 和 SELECT 四类常用 SQL 语句的基本用法.通过对这些语句的学习,可以帮助我们掌握如何向表中插入数据、删除数据、修改数据以及查询数据,从而进一步理解数据库表与数据之间的操作关系.
对于初学者来说,熟练掌握表的增删改查是学习 MySQL 的重要基础.只有掌握了这些基本操作,后续学习条件查询、多表关联、事务处理以及项目中的数据库操作时,才能更加轻松地理解和应用.
2.Create
在 MySQL 中,CREATE 语句主要用于创建数据库对象,例如创建数据库、创建数据表等.在进行表的增删改查之前,首先需要创建一张表,用来存储对应的数据.
创建表时,需要指定表名、字段名、字段类型以及相关约束.常见的字段约束包括主键、自增、非空等.
基本语法如下:
sql
CREATE TABLE 表名 (
字段名1 数据类型 约束条件,
字段名2 数据类型 约束条件,
字段名3 数据类型 约束条件
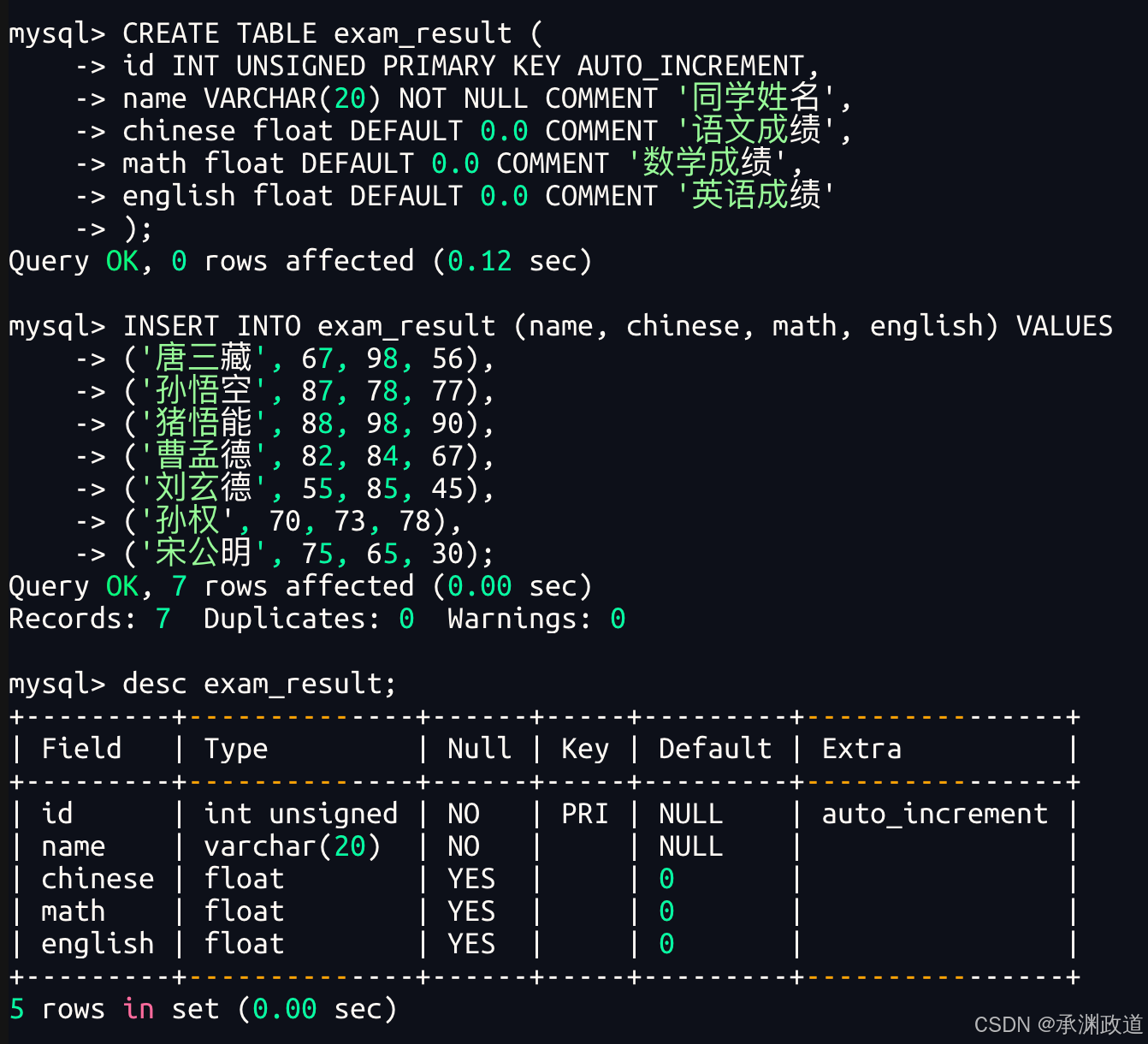
);例如,创建一张学生表 student:
sql
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
age INT,
gender VARCHAR(10)
);在上面的 SQL 语句中,student 是表名,id、name、age、gender 是表中的字段.其中,id 字段使用 PRIMARY KEY 设置为主键,并通过 AUTO_INCREMENT 实现自增;name 字段使用 NOT NULL 约束,表示该字段不能为空.
创建表成功后,就可以向表中插入数据,并进行后续的查询、修改和删除操作.
案例:创建一张学生表
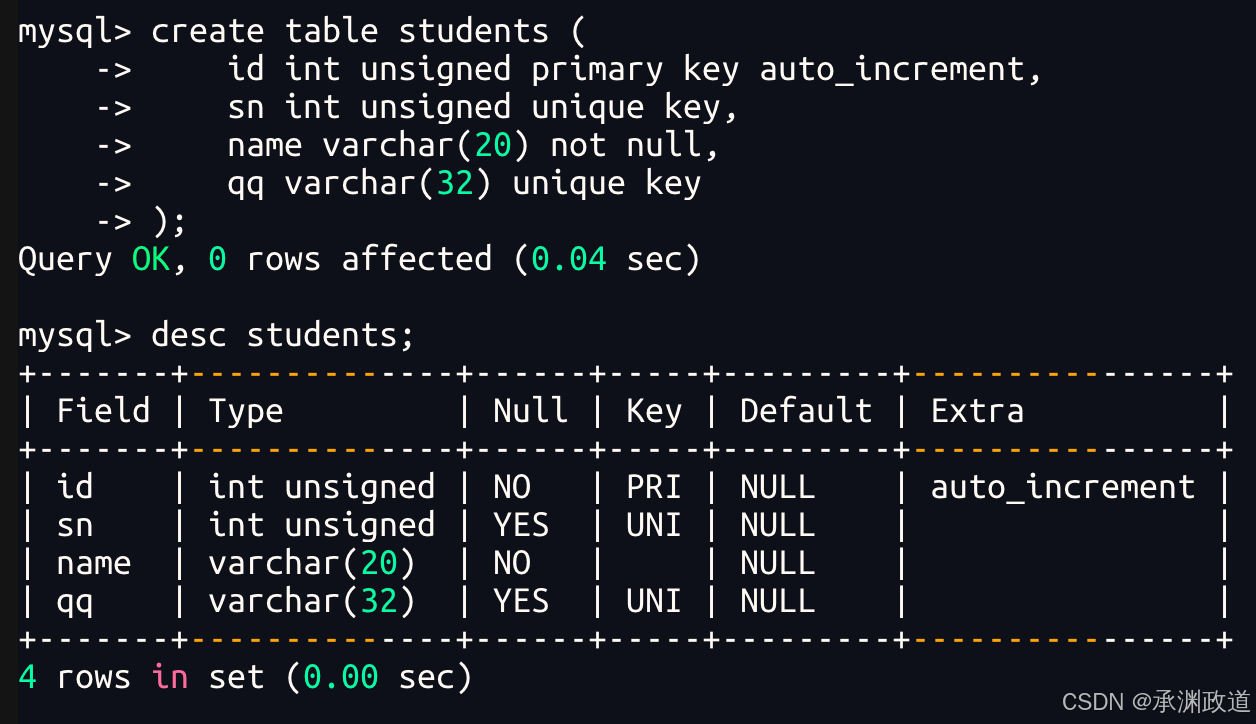
2.1单行数据+全列插入
插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致.
注意:这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增.
全列插入指的是在插入数据时,不指定字段名,而是按照表中字段的定义顺序,依次为每一个字段赋值.
基本语法如下:
sql
insert into 表名 values (值1, 值2, 值3, ...);例如,向 students 表中插入一条完整的学生数据:
sql
insert into students values (1, 123, '张飞', '4567890');在这条SQL语句中,students 表中的字段顺序为:
sql
id, sn, name, qq因此,插入数据时也需要按照这个顺序依次填写对应的值.
需要注意的是,如果某个字段设置了 auto_increment 自增属性,例如 id 字段,那么插入数据时可以使用 null 来占位,让数据库自动生成该字段的值:
sql
insert into students values (null, 124, '关羽', '1234567');这种方式适合字段较少、字段顺序明确的情况.但在实际开发中,为了提高 SQL 的可读性和安全性,更推荐使用指定列插入的方式.
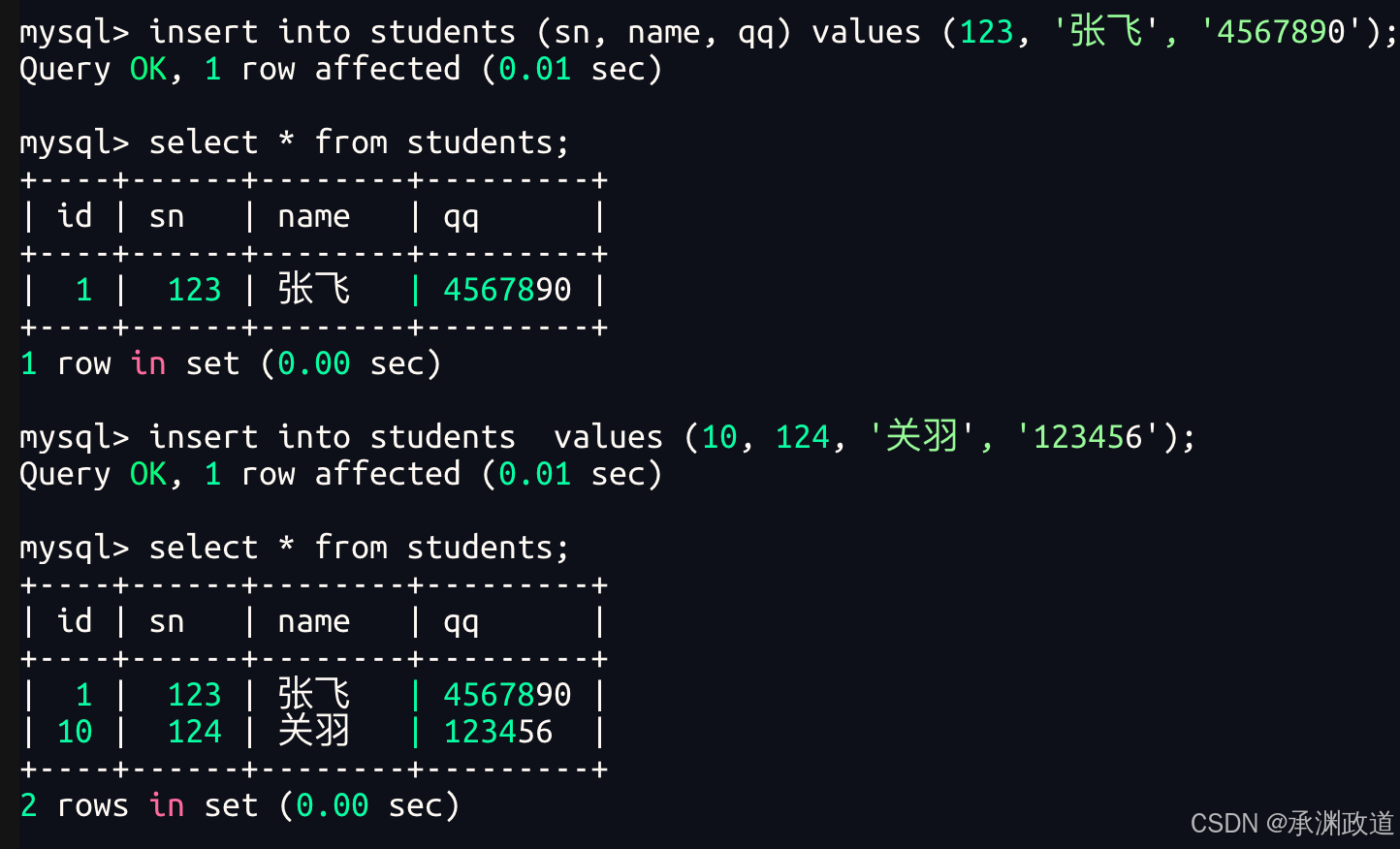
单行全列插入,我们可以省略字段名,'into'这个单词就可以试着省略不写.
2.2多行数据+指定列插入
指定列插入指的是在插入数据时,明确写出需要插入数据的字段名,然后按照字段顺序依次填写对应的值.相比全列插入,这种方式更加清晰,也更适合实际开发使用.
基本语法如下:
sql
insert into 表名 (字段名1, 字段名2, 字段名3, ...)
values
(值1, 值2, 值3, ...),
(值1, 值2, 值3, ...),
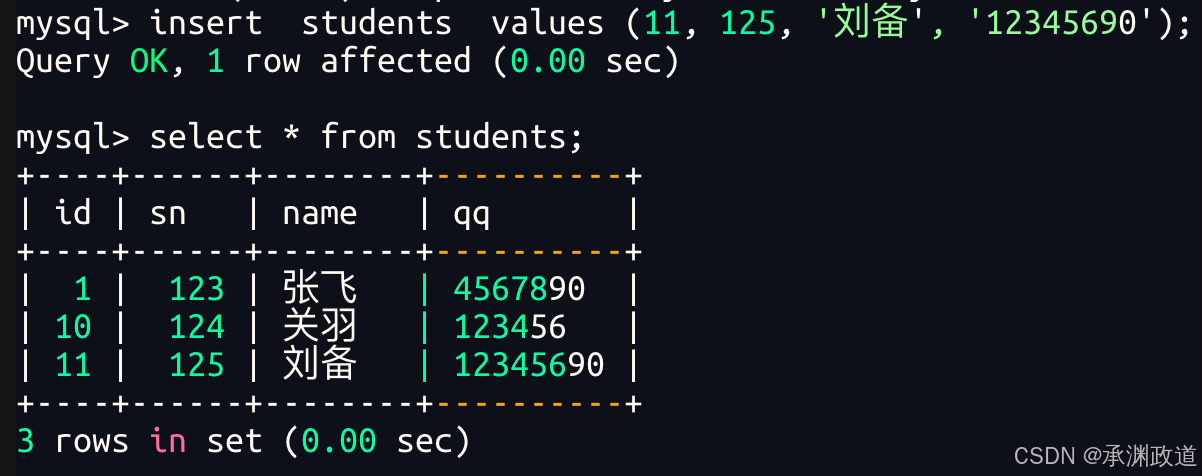
(值1, 值2, 值3, ...);例如,向 students 表中一次插入多条学生数据:
sql
insert into students (sn, name, qq) values
(124, '关羽', '1234567'),
(125, '刘备', '2345678'),
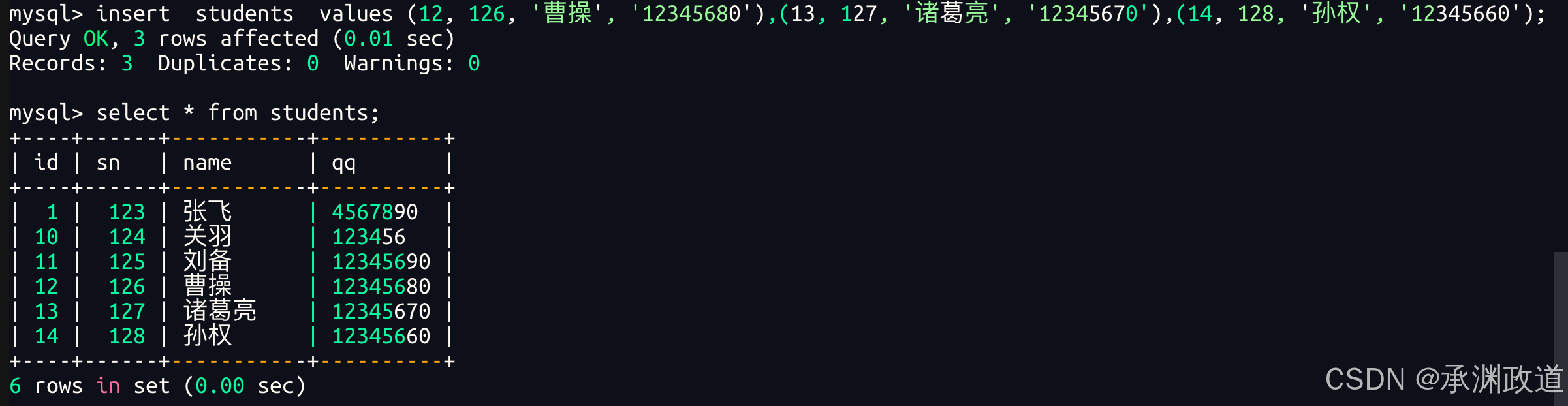
(126, '赵云', '3456789');在上面的SQL语句中,只指定了 sn、name 和 qq 三个字段,没有手动指定 id 字段.因为 id 字段在创建表时设置了 auto_increment 自增属性,所以 MySQL 会自动为每一条数据生成对应的 id 值.
多行插入的好处是可以在一条 SQL 语句中插入多条记录,减少多次执行 SQL 的开销,提高数据插入效率.实际开发中,当需要批量添加数据时,通常会优先使用这种方式.
插入两条记录,value_list 数量必须和指定列数量及顺序一致.
2.3插入否则更新
在向表中插入数据时,如果插入的数据和表中已有数据发生唯一键冲突,普通的 insert 语句会执行失败.
例如,在 students 表中,sn 字段和 qq 字段都设置了 unique key 唯一约束.如果插入的数据中 sn 或 qq 已经存在,就会触发唯一键冲突.
这时可以使用 on duplicate key update 语句,实现"如果数据不存在就插入,如果数据已经存在就更新"的效果.
基本语法如下:
sql
insert into 表名 (字段名1, 字段名2, 字段名3, ...)
values (值1, 值2, 值3, ...)
on duplicate key update
字段名1 = 新值1,
字段名2 = 新值2;例如,向 students 表中插入一条数据:
sql
insert into students (sn, name, qq) values (123, '张飞', '4567890')
on duplicate key update
name = '张飞',
qq = '4567890';如果 students 表中不存在 sn = 123 或 qq = '4567890' 的数据,那么这条 SQL 会正常执行插入操作.
如果表中已经存在相同的 sn 或 qq,则不会插入新数据,而是执行 update 后面的更新操作.
也可以结合 values() 获取本次准备插入的值:
sql
insert into students (sn, name, qq) values (123, '张飞', '4567890')
on duplicate key update
name = values(name),
qq = values(qq);这样写的好处是,如果发生唯一键冲突,就直接使用本次插入语句中的新值来更新原有记录,代码更加简洁.
需要注意的是,on duplicate key update 的触发条件是主键或唯一键发生冲突.如果表中没有设置主键或唯一键,那么即使数据内容相同,也不会触发更新,而是会继续插入新记录.
由于主键或者唯一键对应的值已经存在而导致插入失败
可以选择性的进行同步更新操作语法:
bash
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...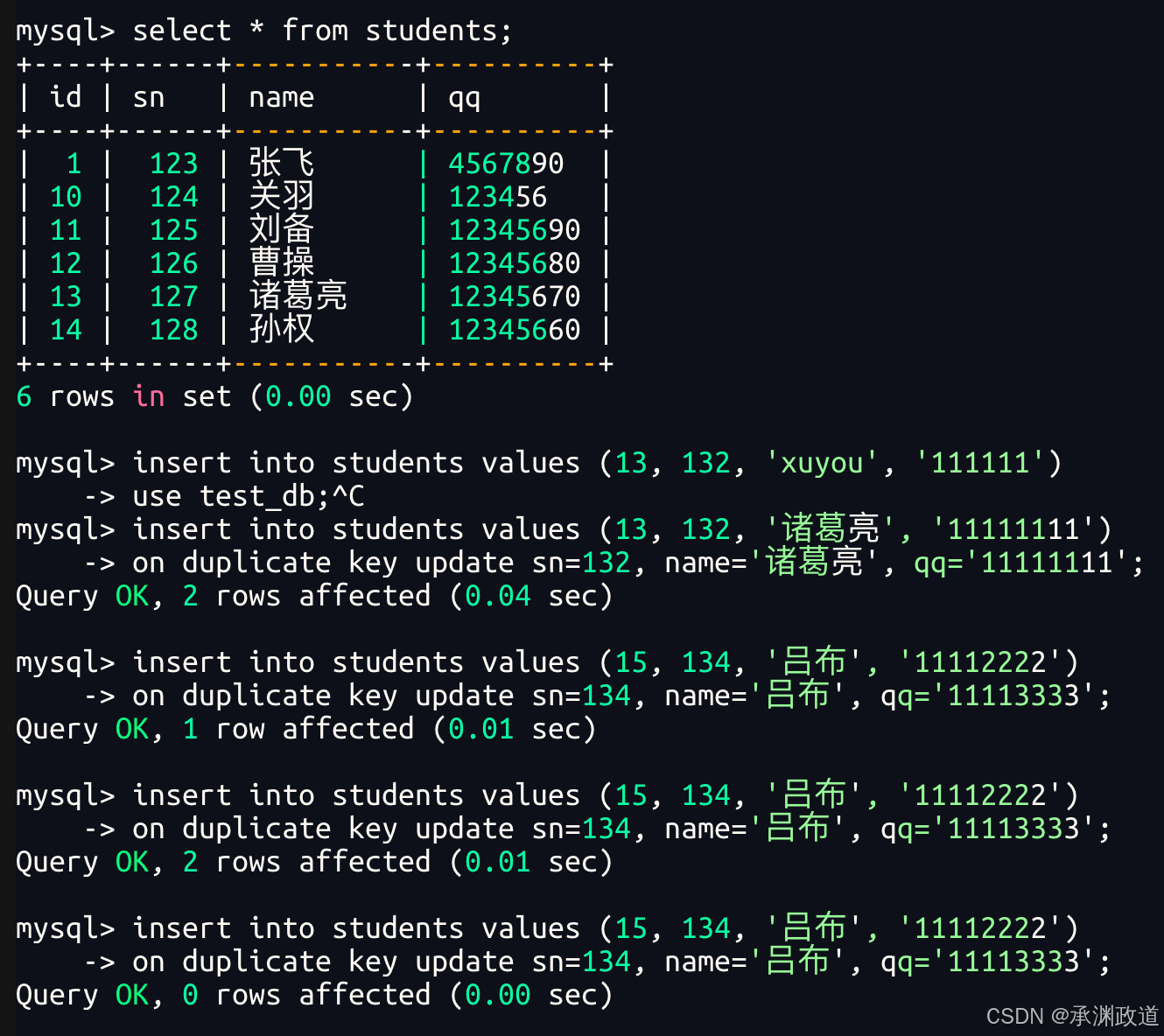
bash
-- ON DUPLICATE KEY 当发生重复key的时候
-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
-- 通过 MySQL 函数获取受到影响的数据行数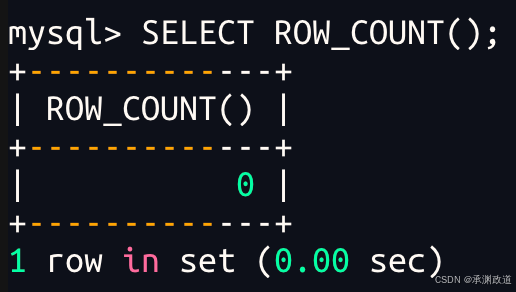
2.4替换
在MySQL 中,replace 语句可以用来实现"替换插入"的效果.它的使用方式和 insert 类似,但执行逻辑有所不同.
当插入的数据没有发生主键或唯一键冲突时,replace 会直接插入一条新记录;如果插入的数据与表中已有数据发生主键或唯一键冲突,MySQL 会先删除原来的记录,然后再插入新的记录.
基本语法如下:
sql
replace into 表名 (字段名1, 字段名2, 字段名3, ...)
values (值1, 值2, 值3, ...);例如,向 students 表中替换插入一条数据:
sql
replace into students values (13, 132, 'xuyou', '111111');如果 students 表中不存在与这条数据冲突的主键或唯一键,那么这条语句会直接插入新数据.
如果表中已经存在 id = 13,或者 sn = 132,又或者 qq = '111111' 的数据,那么就会触发唯一键冲突.此时 replace 会先删除原来的那条记录,然后再插入当前这条新记录.
需要注意的是,replace 并不是简单地修改原有数据,而是"先删除,再插入".因此,如果表中存在自增主键、外键关联或触发器等情况,使用 replace 时需要格外谨慎.
和 on duplicate key update 相比,replace 更适合直接用新数据整体替换旧数据的场景;而如果只是想在冲突时更新部分字段,通常更推荐使用 on duplicate key update.
bash
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入;
-- 1 row affected: 表中没有冲突数据,数据被插入;
-- 2 row affected: 表中有冲突数据,删除后重新插入;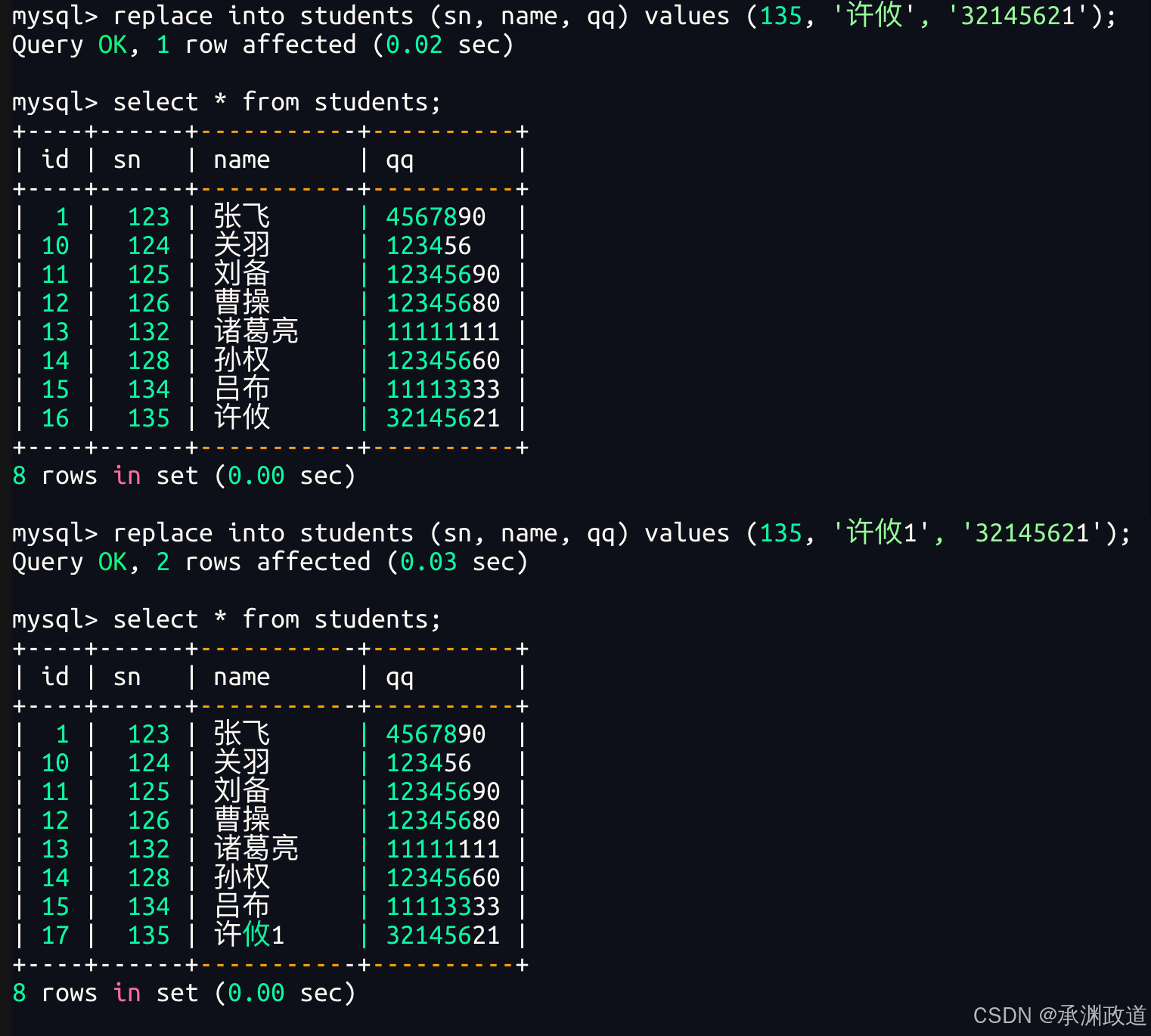
3.Retrieve
Retrieve 表示查询数据,也就是从表中获取需要的数据.在MySQL中,查询数据主要使用 select 语句.它是数据库操作中使用频率最高的语句之一,可以用来查询整张表的数据,也可以根据条件查询指定的数据.
基本语法如下:
sql
select 字段名1, 字段名2, ...
from 表名;如果想查询表中的所有字段,可以使用 * 表示全列查询:
sql
select * from students;例如,查询 students 表中的所有学生信息:
sql
select * from students;如果只想查询指定字段,可以在 select 后面写出对应的字段名:
sql
select id, name, qq from students;这条SQL表示只查询 students 表中的 id、name 和 qq 字段,而不会显示其他字段.
在实际使用中,我们通常还会配合 where 条件语句进行筛选,例如查询学号 sn 为 123 的学生信息:
sql
select * from students where sn = 123;查询语句可以帮助我们快速获取表中的目标数据,是后续学习条件查询、排序查询、分页查询以及多表查询的重要基础.
语法:
bash
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...案例:
3.1SELECT列
3.1.1全列查询
bash
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。(索引后面会讲解)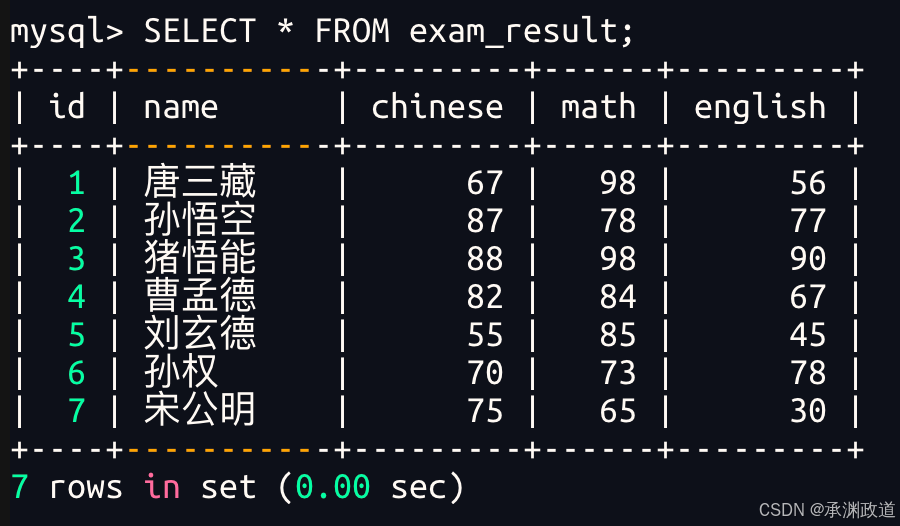
3.1.2指定列查询
bash
-- 指定列的顺序不需要按定义表的顺序来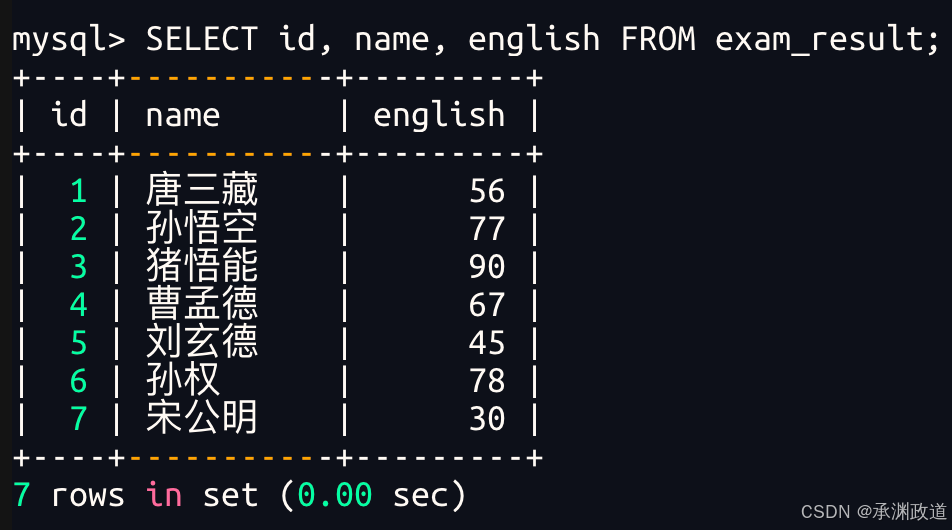
3.1.3查询字段为表达式
bash
表达式不包含字段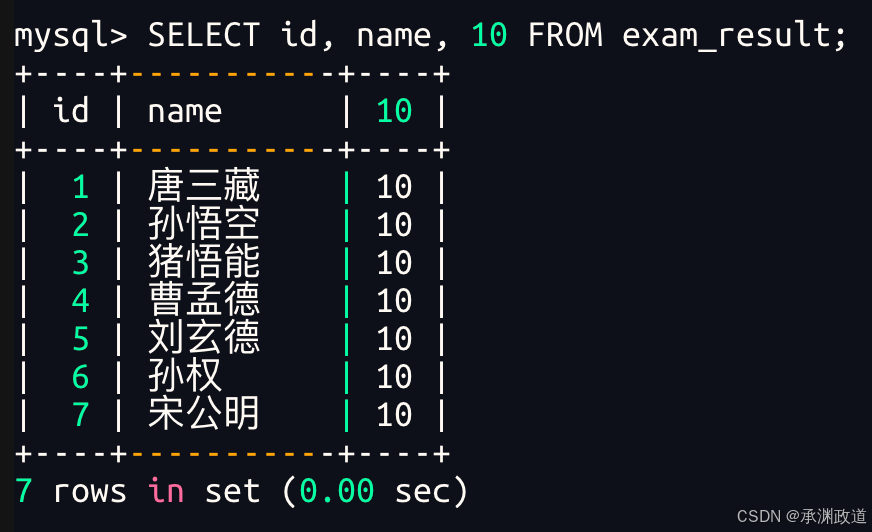
bash
表达式包含一个字段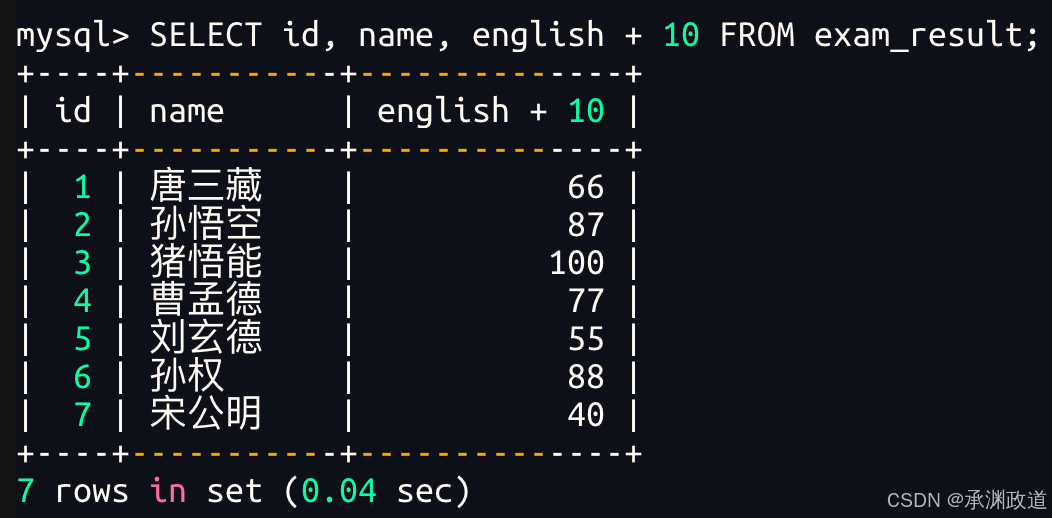
bash
表达式包含多个字段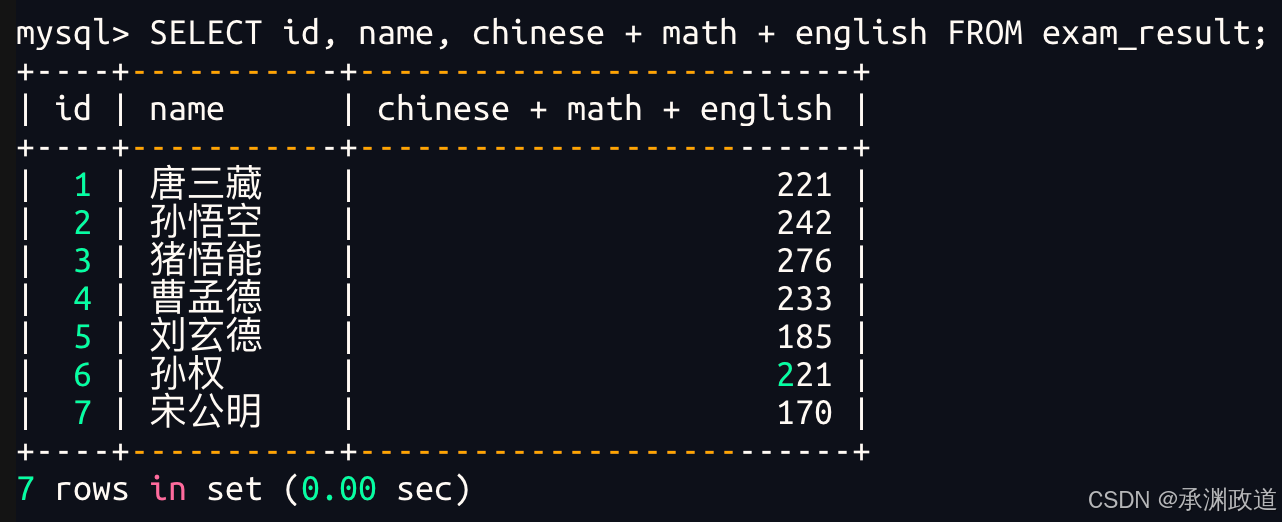
3.1.4为查询结果指定别名
bash
语法:SELECT column [AS] alias_name [...] FROM table_name;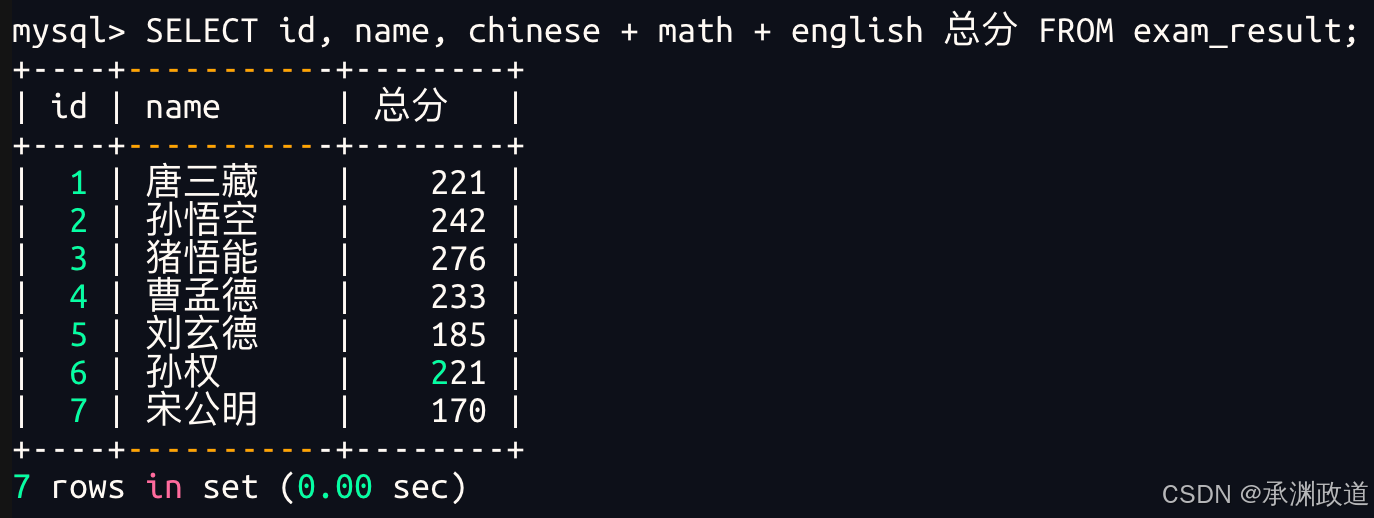
3.1.5结果去重
bash
98 分重复了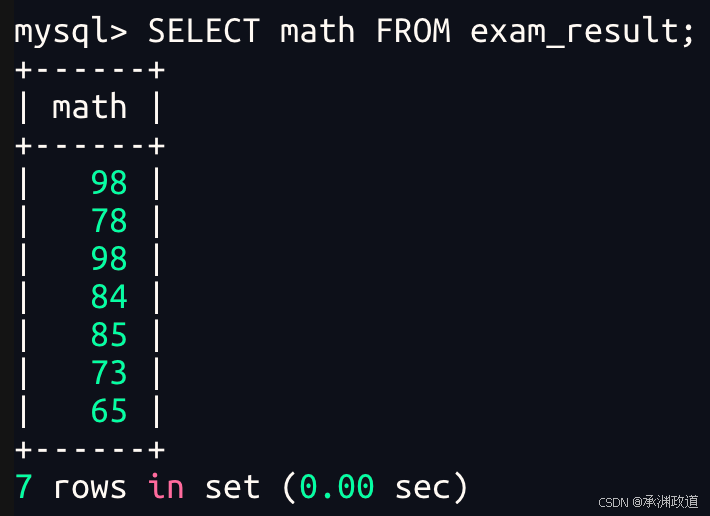
bash
去重结果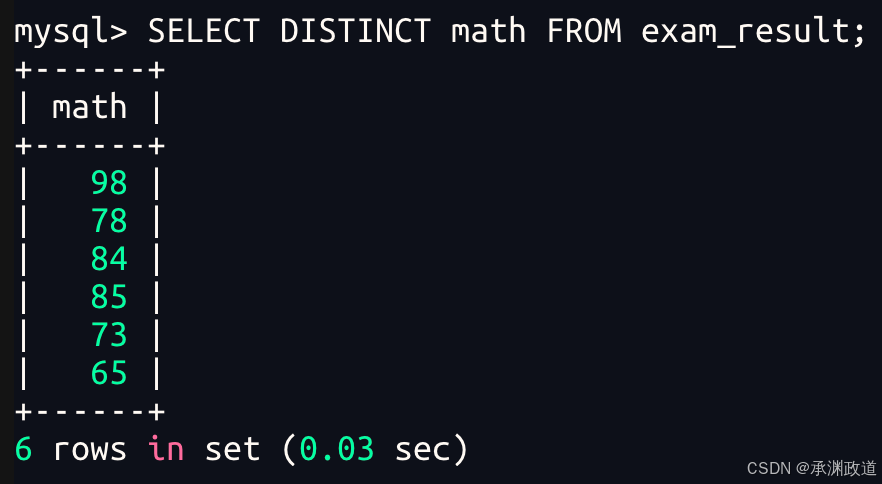
3.2WHERE条件
比较运算符:
| 运算符 | 说明 |
|---|---|
>, >=, <, <= |
大于,大于等于,小于,小于等于 |
= |
等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
<=> |
等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
!=, <> |
不等于 |
BETWEEN a0 AND a1 |
范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
IN (option, ...) |
如果是 option 中的任意一个,返回 TRUE(1) |
IS NULL |
是 NULL |
IS NOT NULL |
不是 NULL |
LIKE |
模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
AND |
多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
OR |
任意一个条件为 TRUE(1),结果为 TRUE(1) |
NOT |
条件为 TRUE(1),结果为 FALSE(0) |
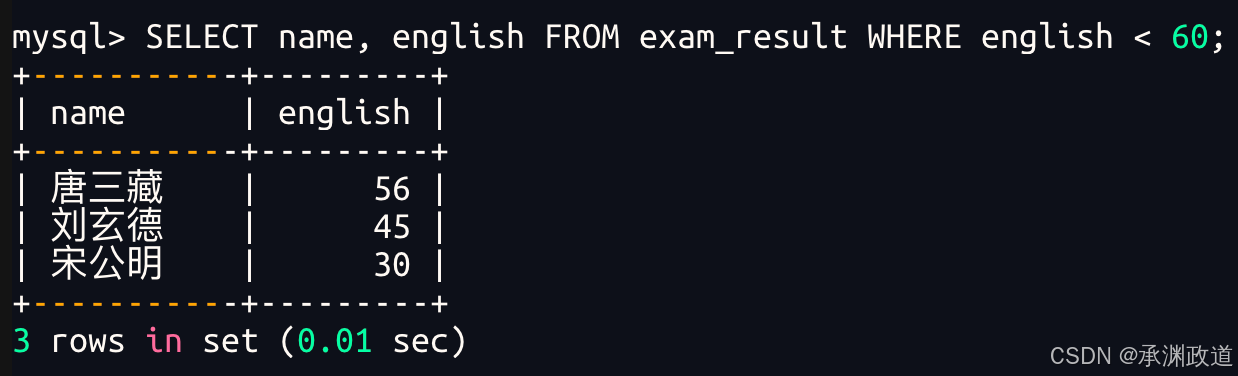
3.2.1英语不及格的同学及英语成绩(<60)
3.2.2语文成绩在80, 90分的同学及语文成绩
bash
使用 AND 进行条件连接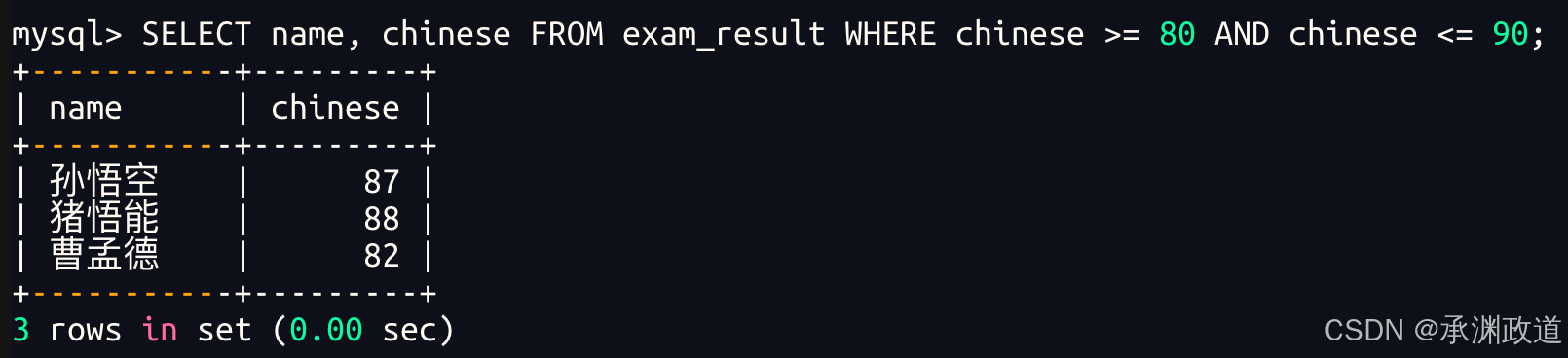
bash
使用 BETWEEN ... AND ... 条件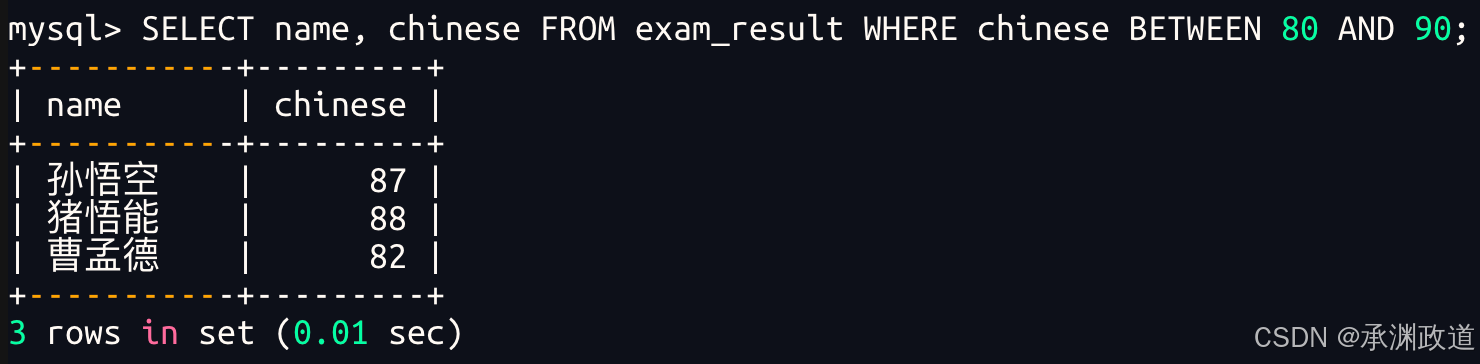
3.2.3数学成绩是58或者59或者98或者99分的同学及数学成绩
bash
使用 OR 进行条件连接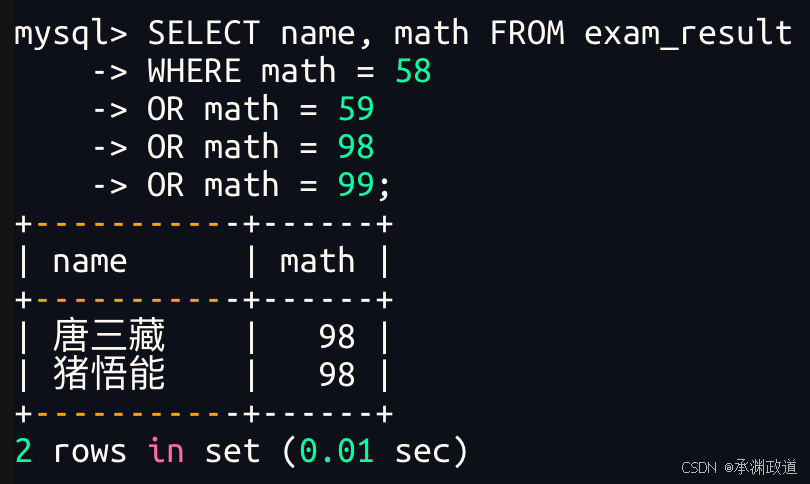
bash
使用 IN 条件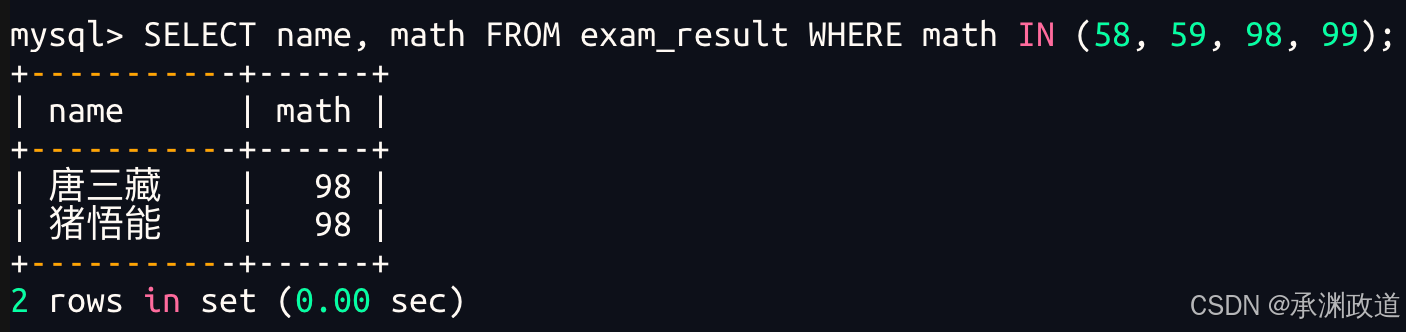
3.2.4姓孙的同学及孙某同学
bash
%匹配任意多个(包括 0 个)任意字符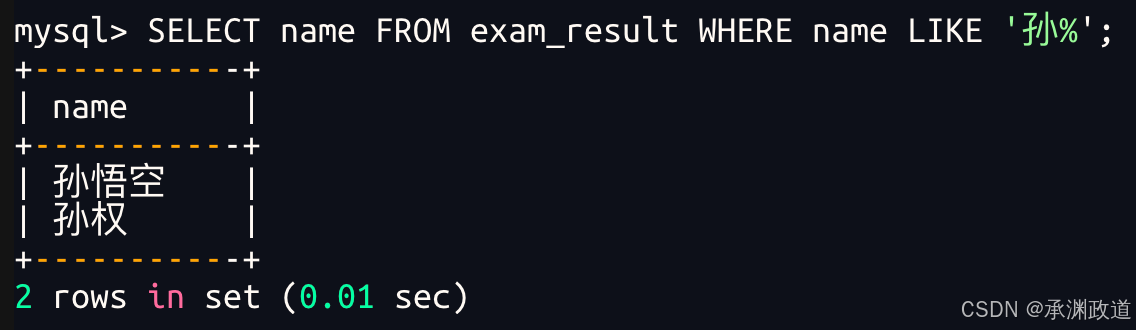
bash
_ 匹配严格的一个任意字符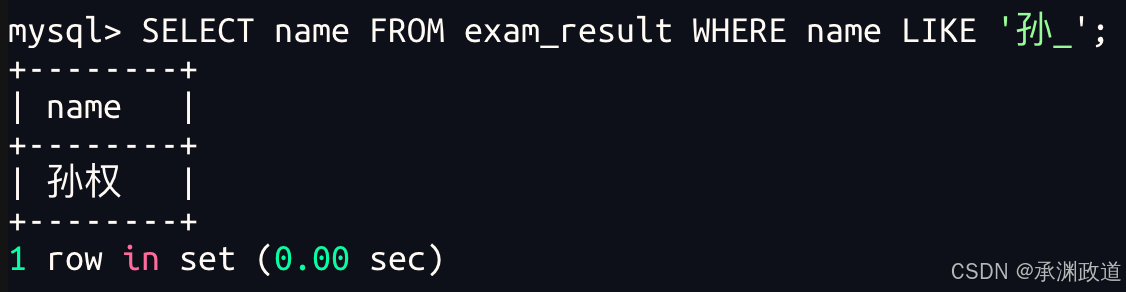
3.2.5语文成绩好于英语成绩的同学
bash
WHERE 条件中比较运算符两侧都是字段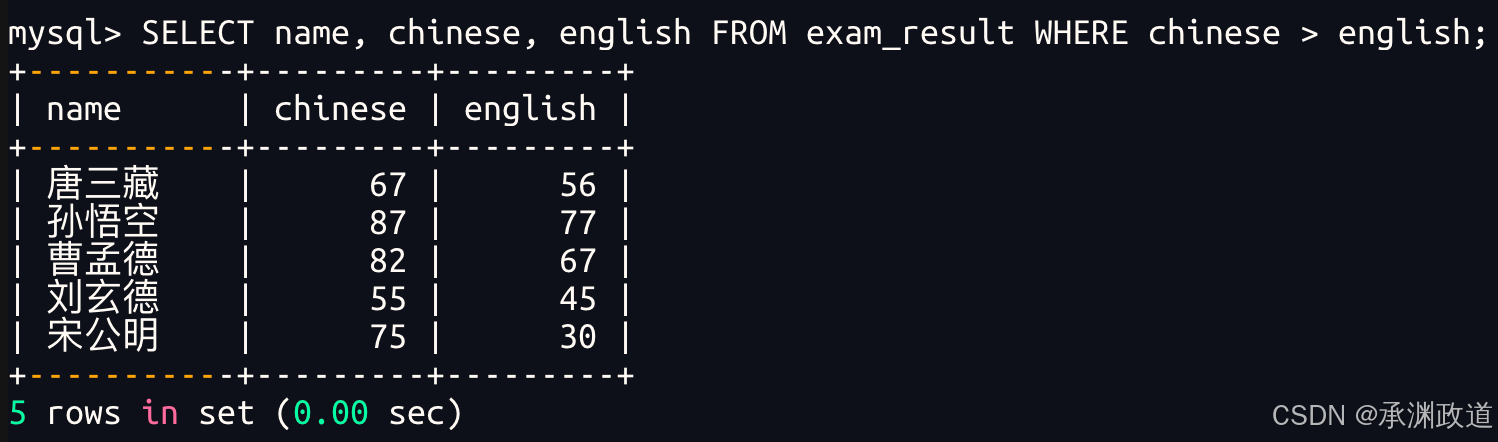
3.2.6总分在200分以下的同学
bash
WHERE 条件中使用表达式
别名不能用在 WHERE 条件中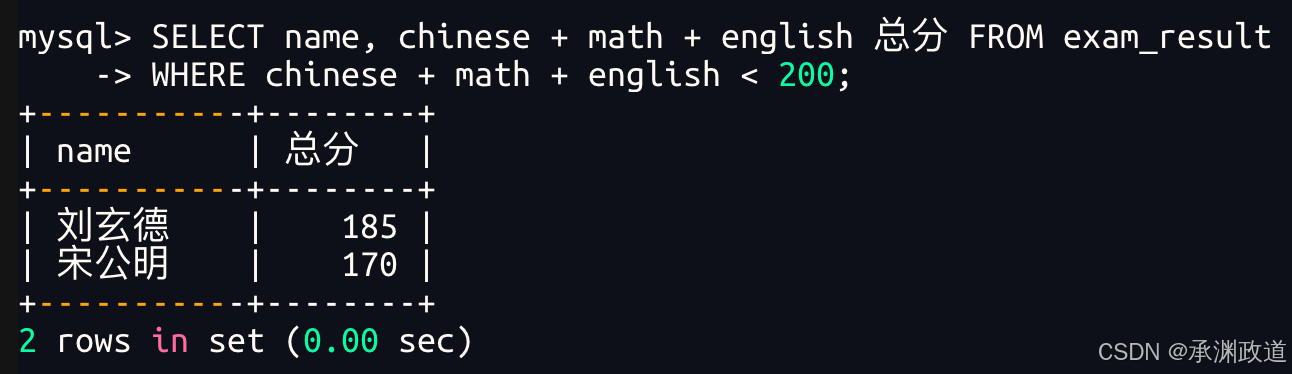
3.2.7语文成绩>80并且不姓孙的同学
bash
AND 与 NOT 的使用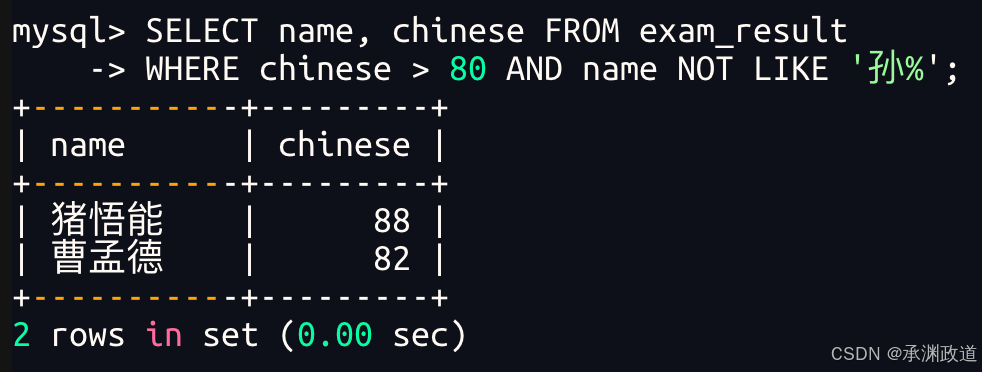
3.2.8孙某同学,否则要求总成绩>200并且语文成绩<数学成绩并且英语成绩>80
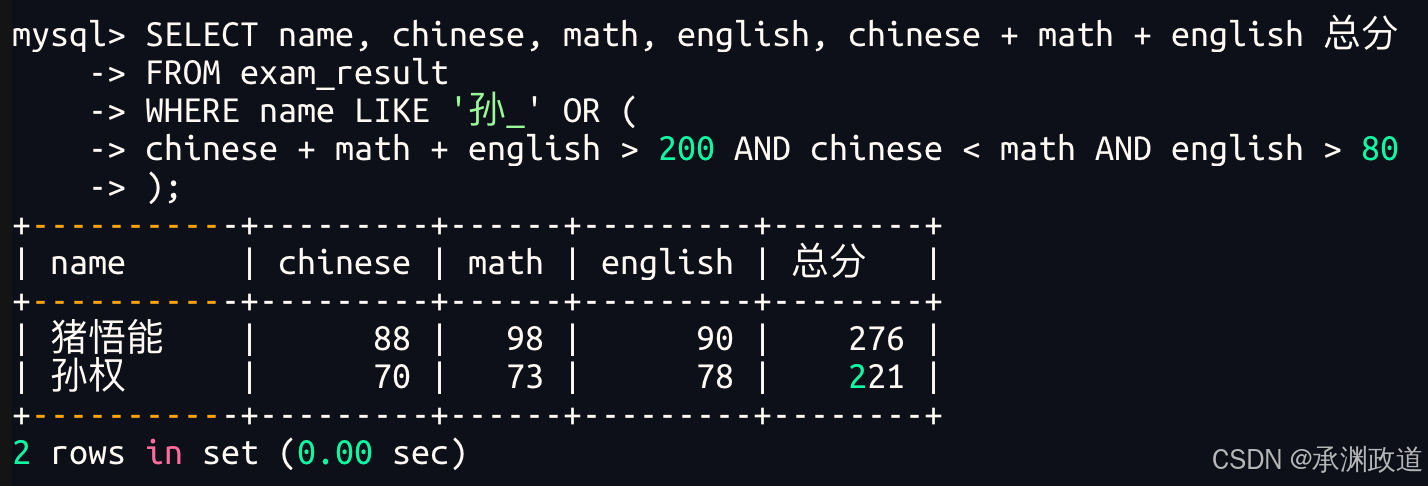
3.2.9NULL的查询
bash
查询 students 表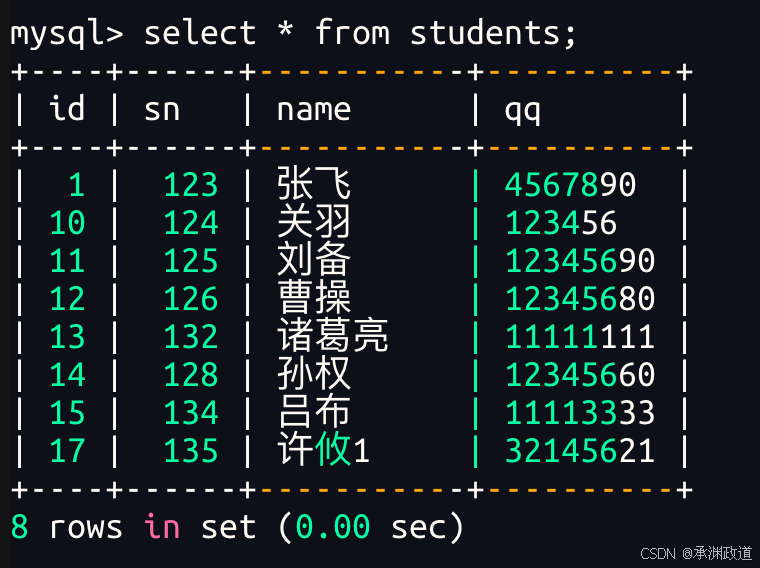
bash
查询 qq 号已知的同学姓名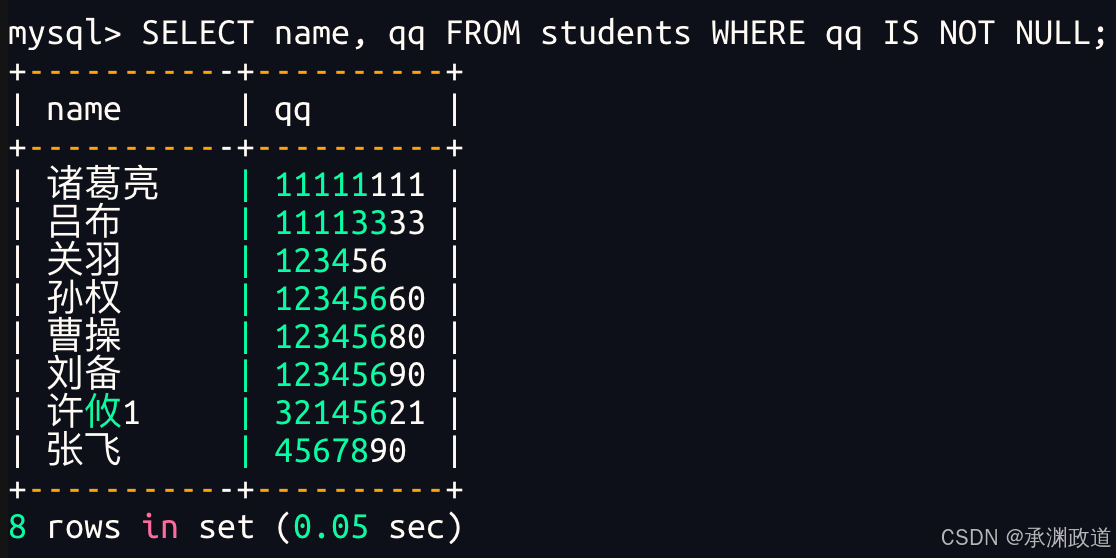
bash
NULL 和 NULL 的比较,= 和 <=> 的区别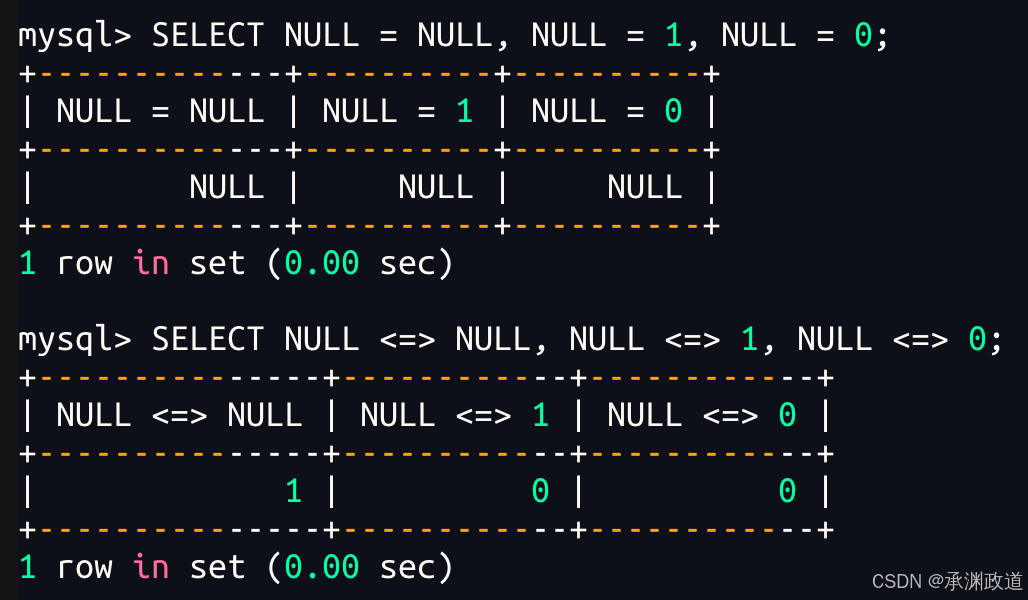
3.3结果排序
bash
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序3.3.1同学及数学成绩,按数学成绩升序显示
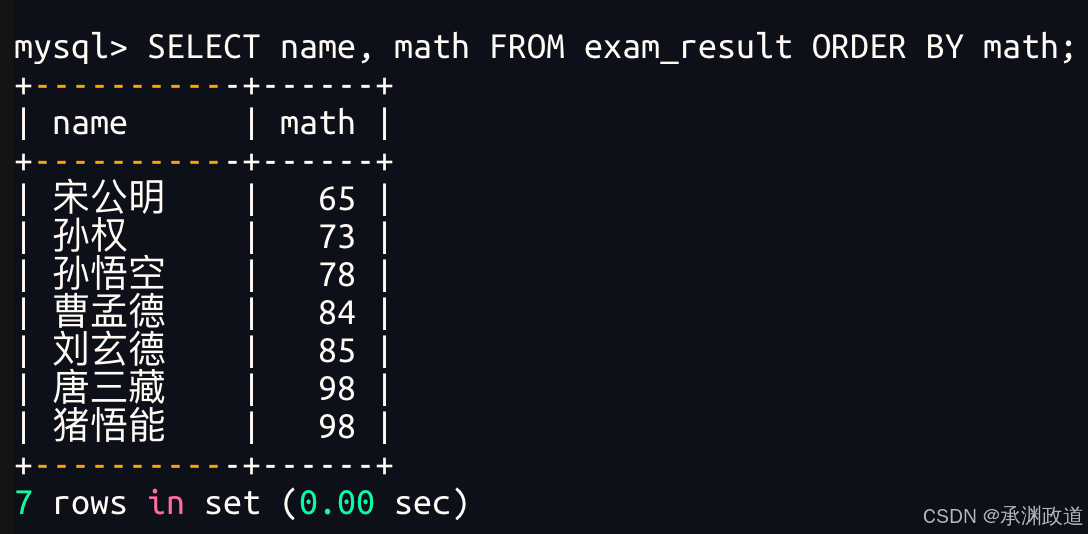
3.3.2同学及qq号,按qq号排序显示
bash
NULL 视为比任何值都小,升序出现在最上面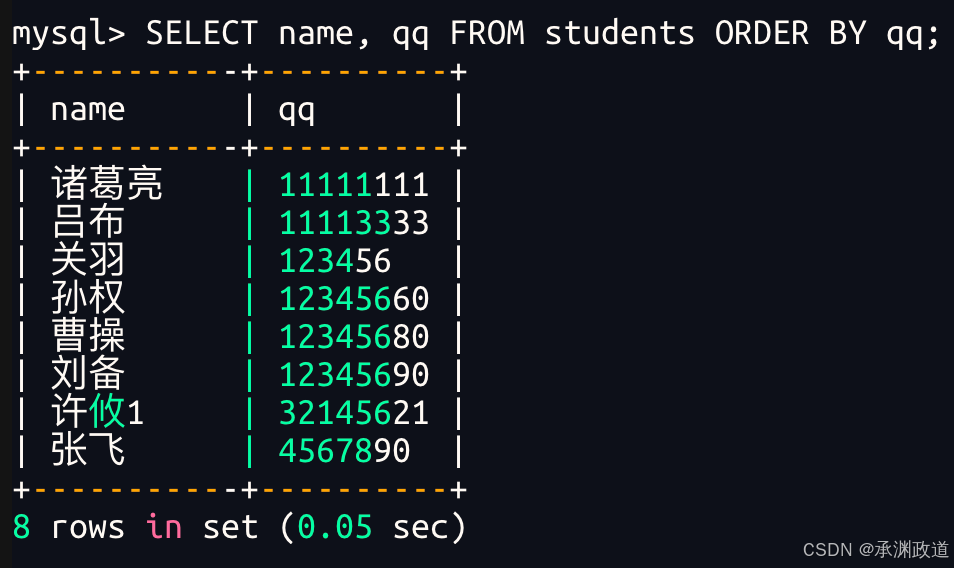
bash
NULL 视为比任何值都小,降序出现在最下面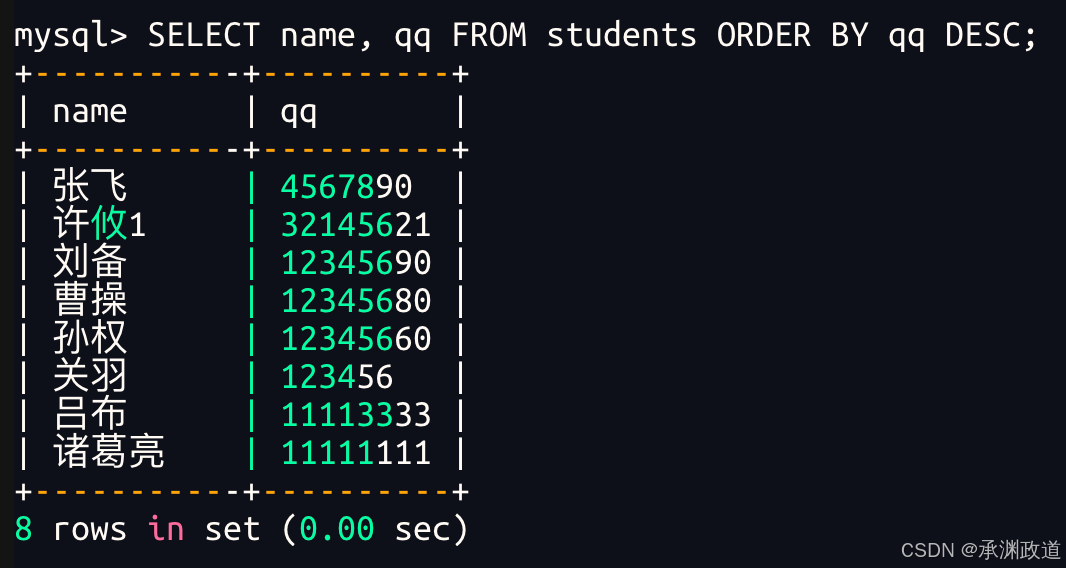
3.3.3查询同学各门成绩,依次按数学降序,英语升序,语文升序的方式显示
bash
多字段排序,排序优先级随书写顺序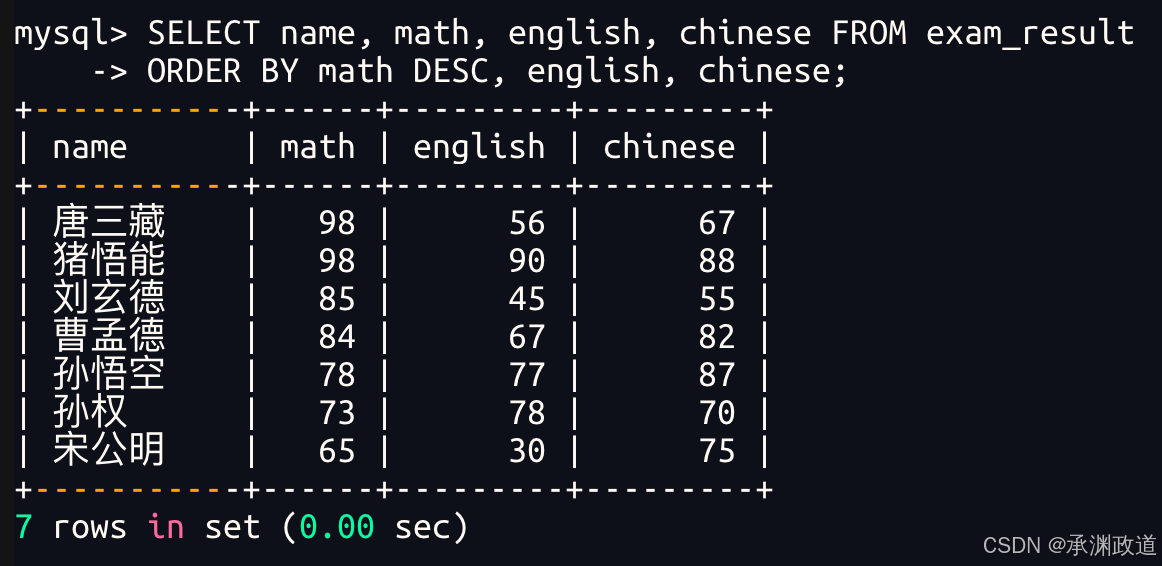
3.3.4查询同学及总分,由高到低
bash
ORDER BY 中可以使用表达式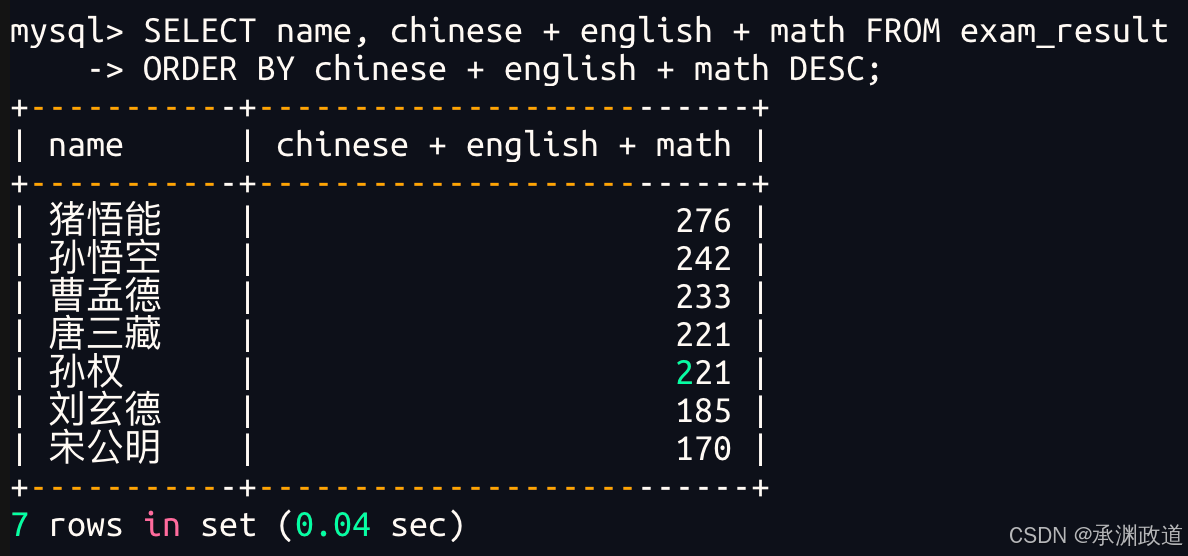
bash
ORDER BY 子句中可以使用列别名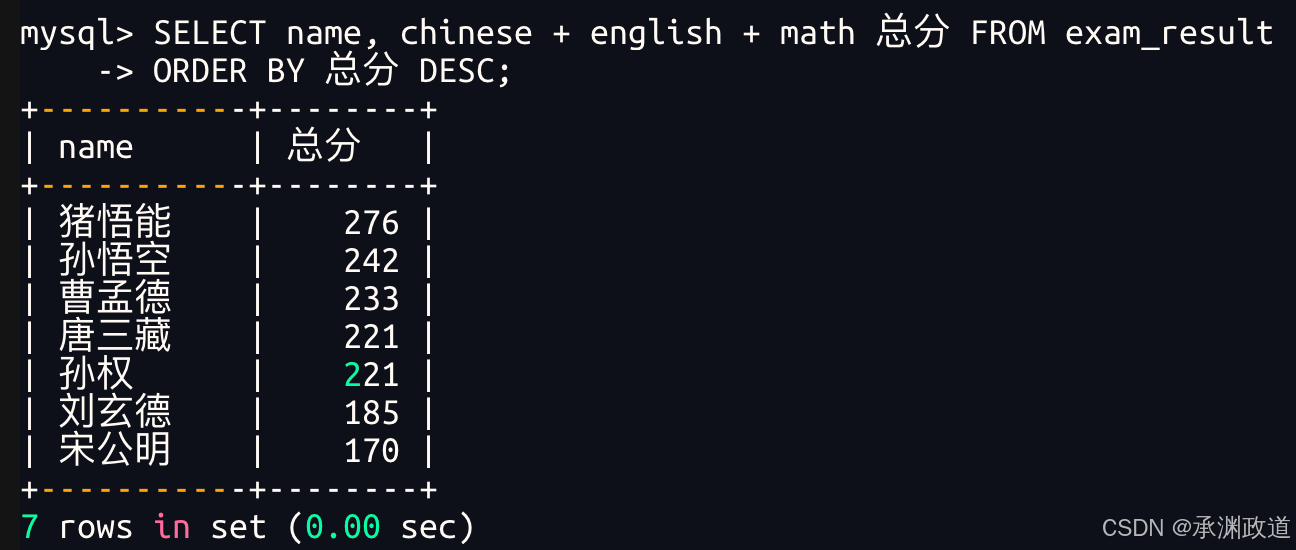
3.3.5查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
bash
结合 WHERE 子句 和 ORDER BY 子句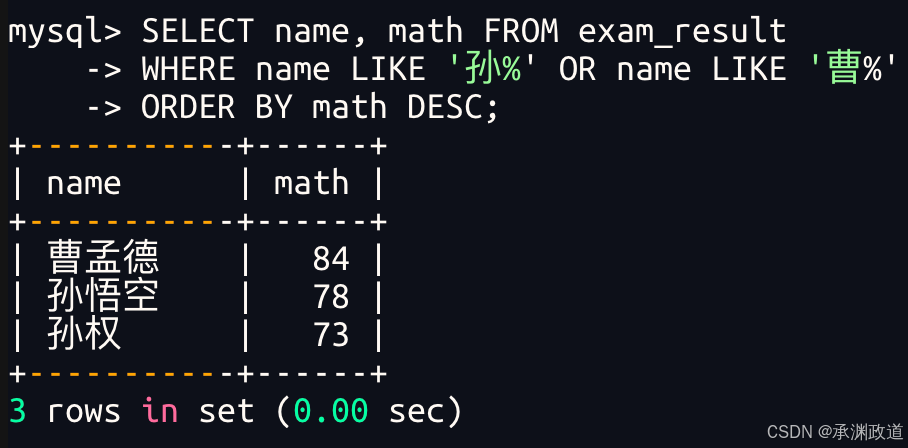
3.4筛选分页结果
bash
语法:
-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死3.4.1按id进行分页,每页3条记录,分别显示第 1、2、3页
bash
第 1 页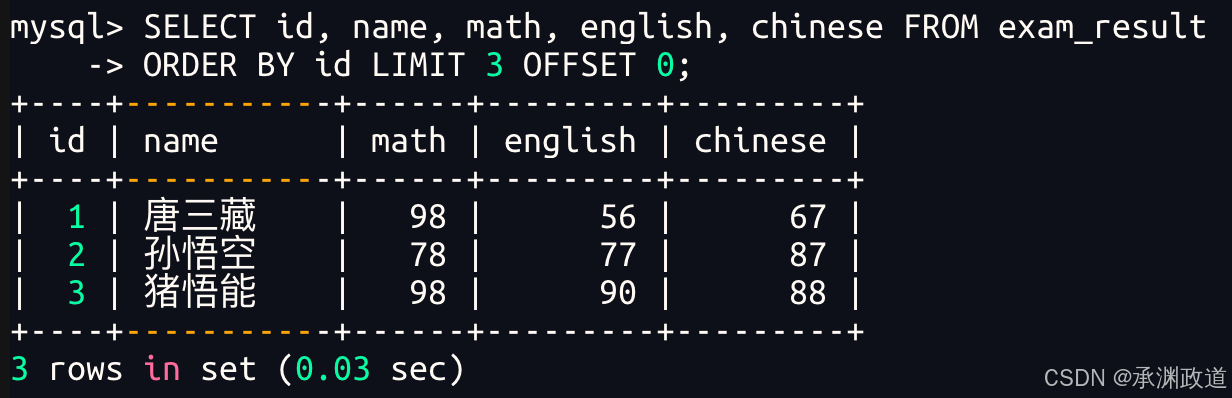
bash
第 2 页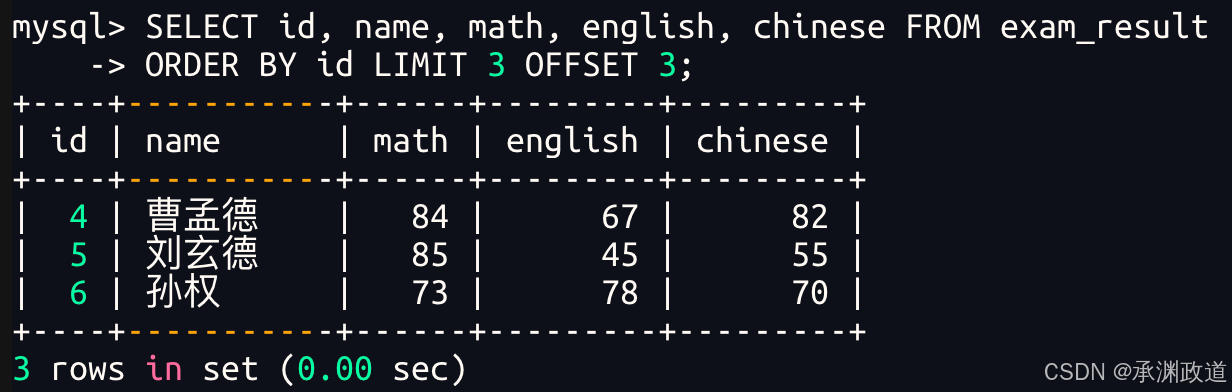
bash
第 3 页,如果结果不足 3 个,不会有影响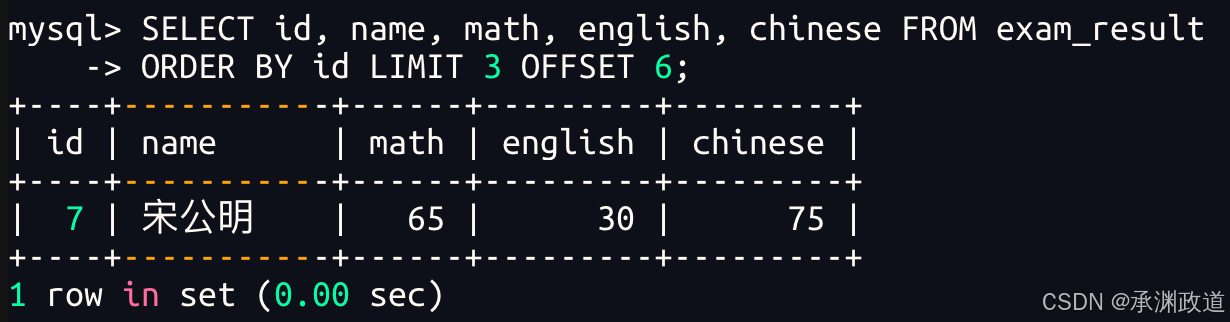

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容
每日心灵鸡汤: 流水不争先,争的是滔滔不绝!
流水不争先,争的是滔滔不绝.人生从非一时的锋芒毕露,而是长久的沉淀与坚守.不必急于求成,退逐片刻喧嚣,于沉静中蓄力,于坚持中前行,历经岁月奔涌,方能汇成奔流向海的磅礴力量,成就细水长流的人生华章.
