staet.dict()查看参数(重点)
state_dict()返回一个包含模块所有可学习参数的字典(比如权重和偏置),以及持久缓冲区。它保存的是模型当前的状态(参数值) ,而不是模型的结构定义。
关键特点
只包含参数:不包含模型结构,只有权重、偏置等数值
可序列化:可以轻松保存到磁盘或从磁盘加载
字典格式:键是参数名,值是参数张量
import torch.nn as nn
net = nn.Sequential(
nn.Linear(10, 20), # 第0层
nn.ReLU(), # 第1层
nn.Linear(20, 5) # 第2层
)
# 打印第2层(Linear层)的结构
print(net[2]) # 输出:Linear(in_features=20, out_features=5, bias=True)
# 打印第2层的参数
print(net[2].state_dict())结果:
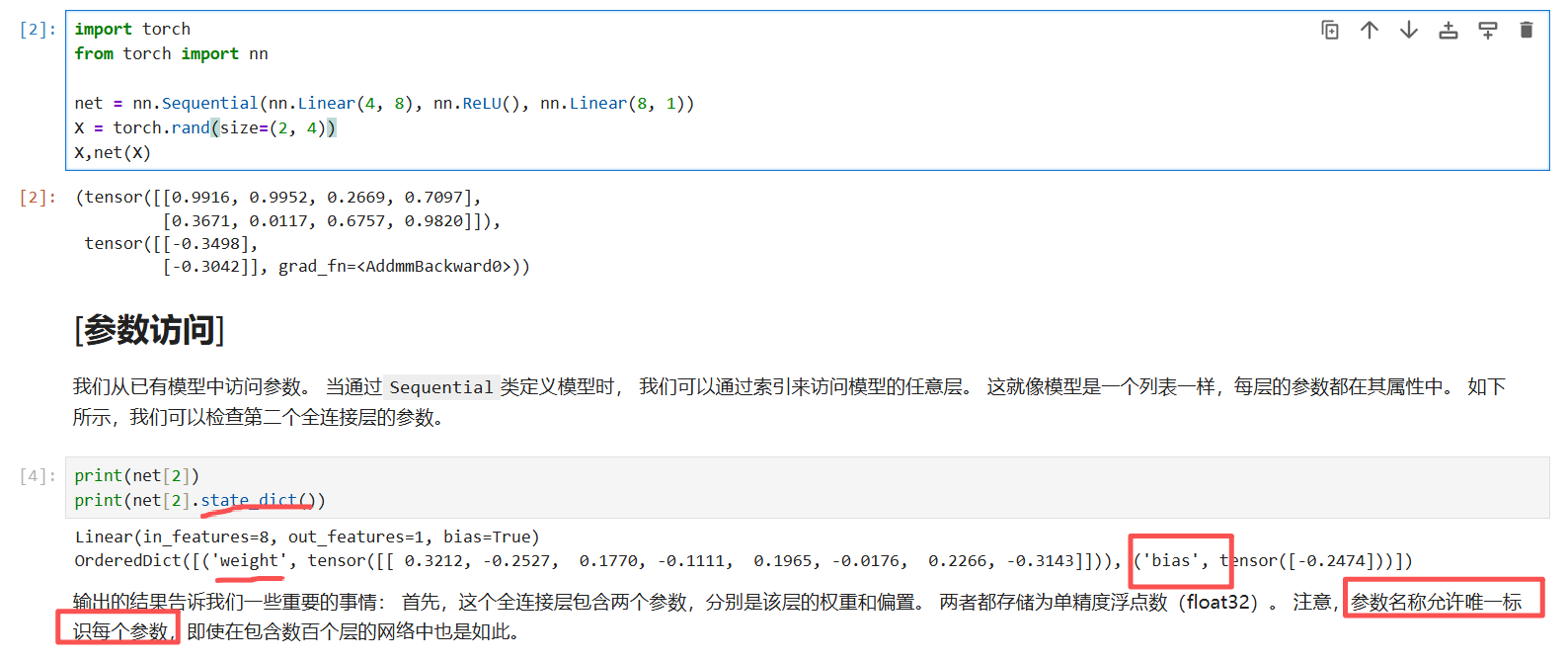
参数直接访问(****)
少用:
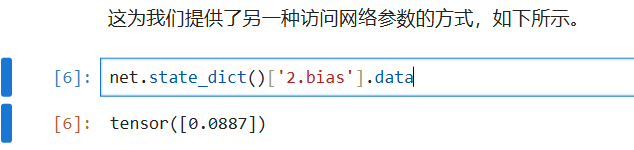
一次性访问所有参数:(重点)
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])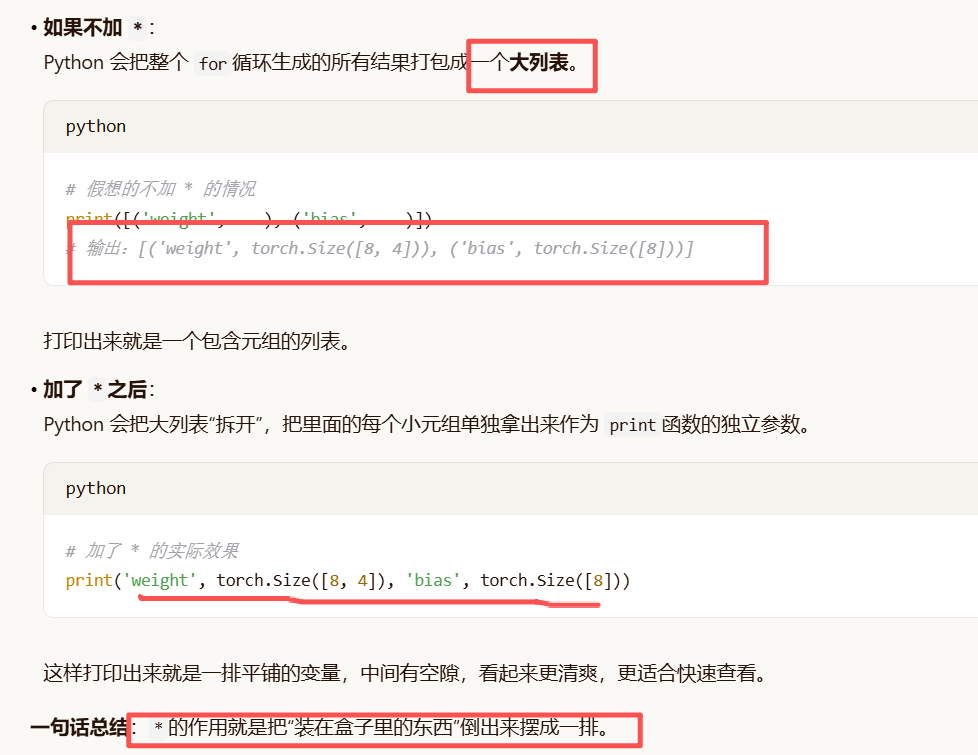
*:解包
结果:
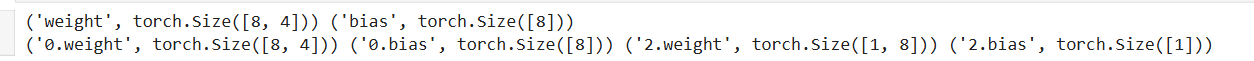
对比不加*号:

'0.weight', torch.Size(8, 4)
0:代表网络的第一层(net0) 。
weight:代表这层的权重矩阵。
8, 4:代表矩阵的形状。意思是输入是 4 维,输出是 8 维(对应了代码中第一层 nn.Linear(4, 8))。
'0.bias', torch.Size(8)
这是第一层的偏置项,有 8 个数值。
'2.weight', torch.Size(1, 8)
2:代表网络的第三层(net2,因为索引是从 0 开始的)。
1, 8:对应代码中最后一层 nn.Linear(8, 1),输入 8 维,输出 1 维。
上一篇文章例子:
python
# 对比两种写法:
# 写法A:参数共享(原始代码)
class SharedModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(20, 20) # 只有一组参数
self.rand_weight = torch.rand((20, 20), requires_grad=False)
def forward(self, x):
x = self.linear(x) # 第一次使用
x = F.relu(torch.mm(x, self.rand_weight) + 1)
x = self.linear(x) # 第二次使用相同的参数
return x
# 写法B:不共享参数
class SeparateModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(20, 20) # 第一组参数
self.linear2 = nn.Linear(20, 20) # 第二组参数(不同的参数)
self.rand_weight = torch.rand((20, 20), requires_grad=False)
def forward(self, x):
x = self.linear1(x) # 使用linear1
x = F.relu(torch.mm(x, self.rand_weight) + 1)
x = self.linear2(x) # 使用linear2
return x
# 写法C:参与梯度下降
class SeparateModel2(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(20, 20) # 第一组参数
self.linear2 = nn.Linear(20, 20) # 第二组参数(不同的参数)
self.rand_weight = torch.rand((20, 20), requires_grad=True)
def forward(self, x):
x = self.linear1(x) # 使用linear1
x = F.relu(torch.mm(x, self.rand_weight) + 1)
x = self.linear2(x) # 使用linear2
return x
# 参数量对比
shared_model = SharedModel()
separate_model = SeparateModel()
separate_model2 = SeparateModel2()
print(f"参数共享模型参数量: {sum(p.numel() for p in shared_model.parameters())}")
print(f"独立参数模型参数量: {sum(p.numel() for p in separate_model.parameters())}")
print(f"独立参数模型2参数量: {sum(p.numel() for p in separate_model2.parameters())}")
print('-----------------')
print([(name, param.shape) for name, param in shared_model.named_parameters()])
print([(name, param.shape) for name, param in separate_model.named_parameters()])
print([(name, param.shape) for name, param in separate_model2.named_parameters()])
# 输出:
# 参数共享模型参数量: 420 (20 * 20 + 20)
# 独立参数模型参数量: 840 (2*(20 * 20 + 20))
参数量是指模型"肚子里的存货"(有多少个权重矩阵),而梯度下降是指"学习过程"
2. 代码层面的真相(重点)
让我们看你定义的 SeparateModel2(写法C):
python
self.linear1 = nn.Linear(20, 20) # 定义了第1组参数
self.linear2 = nn.Linear(20, 20) # 定义了第2组参数
当你执行 nn.Linear(20, 20)时,PyTorch 立刻就在内存里创建了两个矩阵:一个大小为 20×20的权重矩阵,和一个长度为 20 的偏置向量。
-
第1组参数占用了:20×20+20=420个数字。
-
第2组参数占用了:20×20+20=420个数字。
-
总共占用:420+420=840个数字。
requires_grad=True的作用仅仅是给这 840 个数字打上一个标签,告诉计算机:"在反向传播的时候,别忘了给我算个导数更新一下"。它不会改变这 840 个数字的总数。
第一部分:self.rand_weight对参数量的影响
是的,self.rand_weight对参数量没有作用 ,因为它不是一个 nn.Parameter!
在 PyTorch 中,只有用以下两种方式创建的张量才会被计入参数量:
使用 nn.Parameter包装 :self.rand_weight = nn.Parameter(torch.rand(20, 20))
通过 nn.Module的子类 :self.linear = nn.Linear(20, 20)
self.rand_weight = torch.rand((20, 20), requires_grad=True)
这只是一个普通的 PyTorch 张量,不是模型参数,不会出现在 model.parameters()中。
所以不能在前向传播写这些:
反例1:


总结
-
参数量只包括用
nn.Parameter或nn.Module子类定义的部分 -
在前向传播中创建的张量不会被优化器识别为参数
-
如果你想让一个张量参与学习,必须在
__init__中声明为nn.Parameter
反例2:
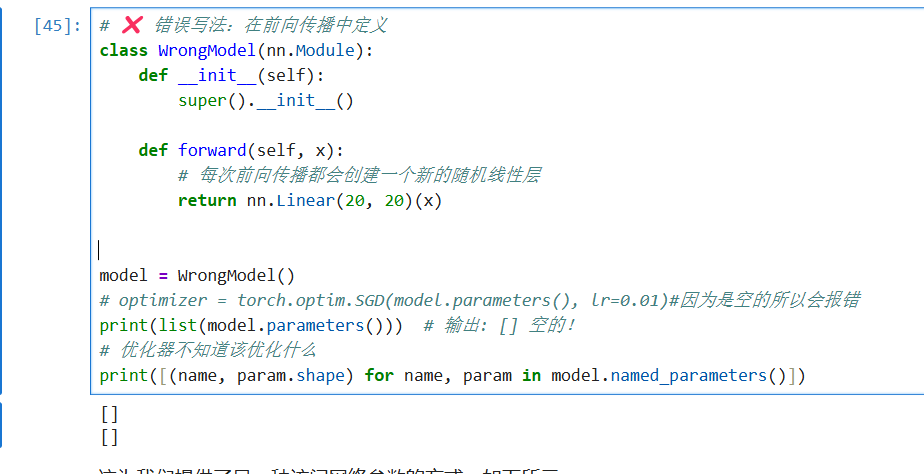
在 PyTorch 中,只有定义在 __init__方法中、并通过 nn.Module的内置方法(如 nn.Linear)注册到模型中的层,才会被自动识别并纳入 parameters()和 named_parameters()的管理列表中。
你截图中的代码之所以输出为空,是因为在 forward函数中直接使用 nn.Linear(20, 20)(x)属于动态计算 ,而不是模型结构的注册。具体分析如下:
-
注册机制缺失
nn.Module的子类需要在__init__中调用self.something = ...来将子模块挂载到模型对象上 。截图中的写法仅仅是调用了类的构造函数创建了一个临时的nn.Linear实例,并将其应用于输入x。这个过程非常短暂,计算完后该临时实例就脱离了作用域,模型本身并没有保存这个层。 -
参数归属问题
由于该
nn.Linear层没有被赋值给self,它的参数(weight 和 bias)也没有被添加到当前WrongModel对象的参数列表中 。因此,model.parameters()遍历不到任何东西,输出为空列表。 -
优化器的依赖
优化器(如 SGD)是通过读取模型的
parameters()列表来获取需要更新的张量的。既然列表为空,优化器就"无从下手"。
named_parameters()]和parameter有啥区别

嵌套块+看参数:(太复杂了 少见)
结果
对不同的块用/初始化不同参数:net.apply(重点)
python
def init_xavier(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
def init_42(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 42)
net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)tensor([ 0.5236, 0.0516, -0.3236, 0.3794])
tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])net.apply(my_init)是什么意思?
这是 PyTorch 的一个非常方便的工具方法。
作用:它会递归地去查看 net这个模型里面的所有子模块(比如 Layer1, Layer2...)。
过程:每找到一个子模块,就会把这个模块作为参数 m,传给上面的 my_init(m)函数处理一次。
为什么要用它?
这样就不用手动去写 net.layer1.weight = ...和 net.layer2.weight = ...了。不管你的网络有多深、有多少层,调用一次 apply,它就会自动把符合条件的层全部初始化一遍。
这一章的细节代码:
print("Init", *[(name, param.shape)
for name, param in m.named_parameters()]0)
等价于
1**. 列表推导式** :获取所有参数的名字和形状
params_info = (name, param.shape) for name, param in m.named_parameters()
2. 取第一个元素:0
first_param_info = params_info0 # 例如:('0.weight', torch.Size(8, 4))
3. 使用 * 解包
print("Init", *first_param_info)
等价于:print("Init", '0.weight', torch.Size(8, 4))
如果你想看所有参数,去掉 [0]
原代码只取第一个,如果你去掉 [0]:
# 查看所有参数
print("Init", *[(name, param.shape) for name, param in m.named_parameters()])这会输出:
Init 0.weight torch.Size([8, 4]) 0.bias torch.Size([8]) 2.weight torch.Size([1, 8]) 2.bias torch.Size([1])参数绑定-梯度累加:
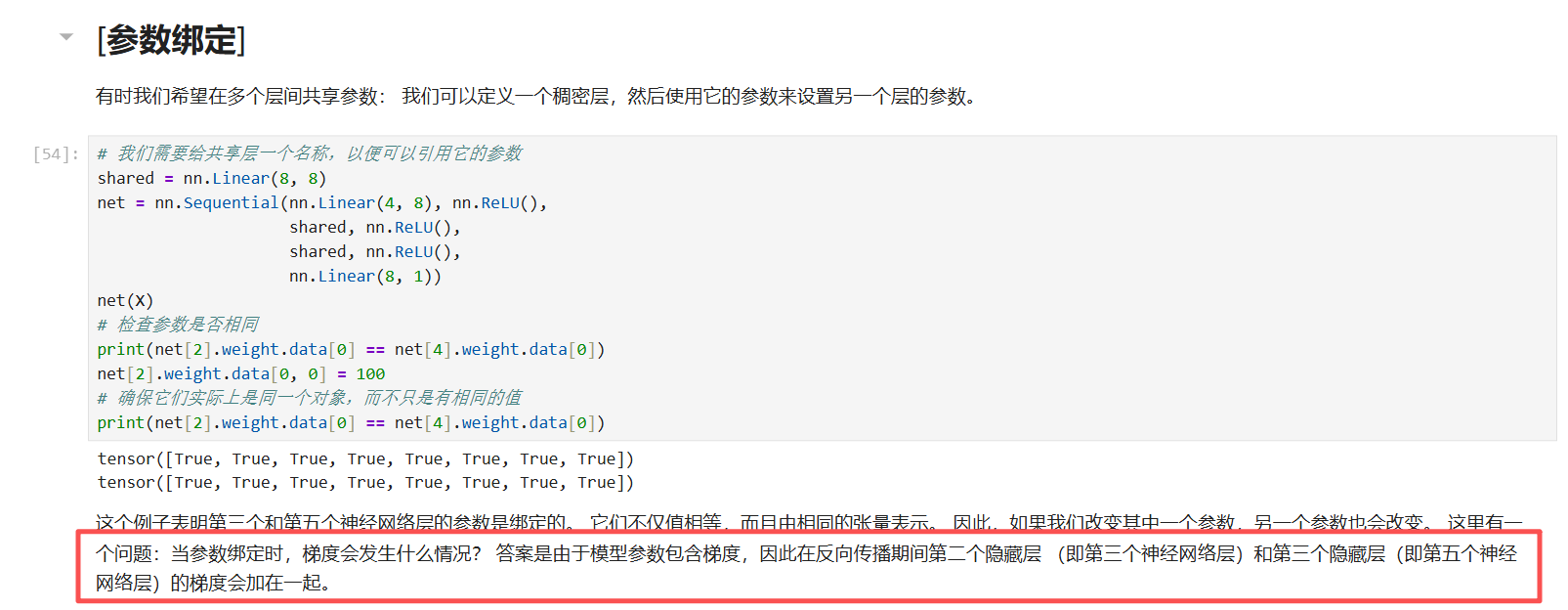
这正是参数绑定(Shared Parameters)在神经网络中最容易被忽视、但也最关键的细节:梯度不仅不会"不对",反而会"累加"。(人话就是正常 backward就得了,就是算了两次,因为你用了两次)
我们可以通过以下三个层面来拆解这个机制:
1. 核心逻辑:同一个对象
在 Python 中,net[2]和 net[4]指向的是内存中同一个 nn.Linear对象。
-
这意味着它们的
weight和bias是同一个张量。 -
当你执行
net[2].weight.data[0, 0] = 100时,你是在直接修改这块内存里的数据。因为net[4].weight也在这块内存上,所以它的值瞬间也变成了 100。
2. 正向传播:数值一致
因为两层使用的是同一块内存中的数据,所以正向传播(Forward Pass)时,这两层的计算结果自然是完全一样的。
3. 反向传播:梯度累加
这是你问题的重点。在反向传播时,PyTorch 的计算图会记录"谁用到了这个数据"。
假设损失函数是 L,两个绑定层分别是 Layer A 和 Layer B:
-
Layer A 的输出对损失有贡献,产生梯度 ∂A∂L。
-
Layer B 的输出对损失也有贡献,产生梯度 ∂B∂L。
-
因为 A 和 B 是同一个对象,它们对数据的导数必须合并。根据微积分的链式法则,总梯度 = ∂A∂L+∂B∂L。
结论: 在更新参数时(如 optimizer.step()),计算出的更新量会同时作用于这两个层,使得它们在下一次前向传播时都能使用更新后的权重。
验证:
python
# 创建一个有共享参数的神经网络
class SimpleSharedNet(nn.Module):
def __init__(self):
super().__init__()
# 只有一个线性层,但会被用两次
self.linear = nn.Linear(1, 1, bias=False) # 只有1个参数
def forward(self, x):
# 第一次使用
out1 = self.linear(x)
# 第二次使用(同一个线性层)
out2 = self.linear(out1)
return out2
# 创建模型
model = SimpleSharedNet()
# 为了简单,我们设置权重为2
model.linear.weight.data = torch.tensor([[2.0]])
# 输入
x = torch.tensor([[3.0]])
# 手动计算应该得到什么?
# 第一次线性变换: 3 * 2 = 6
# 第二次线性变换: 6 * 2 = 12
# 所以输出应该是 12
# 前向传播
with torch.no_grad():
output = model(x)
print(f"前向传播输出: {output.item()}") # 应该是 12
# 现在计算梯度
output = model(x)
target = torch.tensor([[20.0]]) # 假设目标是20
loss = (output - target) ** 2
loss.backward()
print(f"共享参数的梯度: {model.linear.weight.grad.item()}")手动验证这个梯度是否正确:
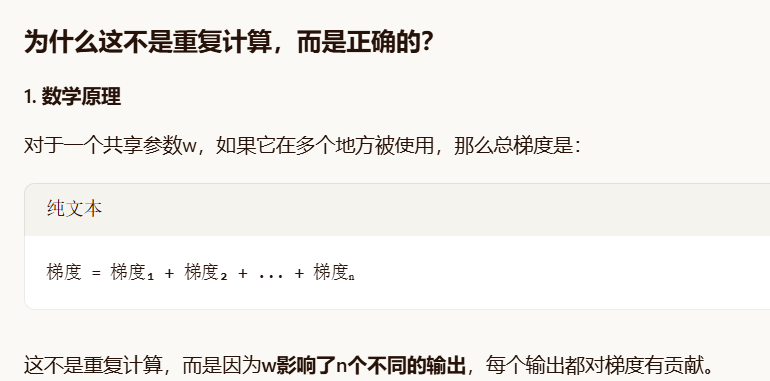
-
前向传播:
-
第一次:h = w × x = 2 × 3 = 6
-
第二次:y = w × h = 2 × 6 = 12
-
损失:L = (y - 20)² = (12 - 20)² = 64
-
-
反向传播(手动计算):
-
∂L/∂y = 2×(y-20) = 2×(12-20) = -16
-
∂y/∂w 有两部分:
a) 来自第二次使用的直接路径:∂y/∂w = h = 6
b) 来自第一次使用的间接路径:∂y/∂h × ∂h/∂w = w × x = 2 × 3 = 6
-
总梯度:∂L/∂w = ∂L/∂y × (∂y/∂w + ∂y/∂h × ∂h/∂w) = -16 × (6 + 6) = -192
-
