最近本地跑了Ollama,想拿Spring Boot接个聊天接口,没想到踩了一堆坑。Spring AI文档看着挺丰满,实操起来全是骨感:
OllamaModel居然是枚举,没法随便传模型名;SSE流式输出在MVC和WebFlux之间怎么选也大有学问......一路趟雷才把这套东西跑通。这篇文就当个复盘,记录下从零搭建"Spring Boot + Spring AI + Ollama + Vue3"对话系统的全过程,涵盖后端骨架、前端对话页、SSE流式输出,外加一份实打实的避坑指南。
一、后端骨架搭建
1.1 项目结构和依赖
项目是多模块的Maven结构,主模块叫medical-ai-service:
TypeScript
medical-triage-assistant/
├── pom.xml(父POM)
└── medical-ai-service/
├── pom.xml
└── src/main/java/com/medical/triage/ai/
├── MedicalAiApplication.java
├── controller/ChatController.java
├── service/ChatService.java
├── client/AiChatClient.java(接口)
├── client/OllamaAiChatClient.java(Ollama实现)
├── client/MockAiChatClient.java(Mock实现)
├── config/AiClientConfig.java
└── model/ChatRequest.java, ChatResponse.java父POM里关键就是Spring Boot 3.5的版本管理,子模块medical-ai-service的pom.xml才是重头戏:
TypeScript
<dependencies>
<!-- Spring Boot Web(包含SseEmitter) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI + Ollama -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<!-- Validation -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
</dependencies>注意这里没有 spring-boot-starter-webflux。项目是纯Servlet栈,流式输出用的是Spring MVC原生的SseEmitter,不需要引入WebFlux依赖。具体原因后面会详细分析。
1.2 SseEmitter vs WebFlux:为什么选SseEmitter?
这是搭建过程中最关键的技术选型决策。Spring生态里实现SSE流式输出有两种方式:
| 维度 | SseEmitter(Spring MVC) | Flux(Spring WebFlux) |
|---|---|---|
| 运行时容器 | Tomcat / Undertow(Servlet 容器) | Netty(响应式容器) |
| 编程模型 | 同步阻塞,传统MVC风格 | 异步非阻塞,响应式流 |
| 线程模型 | 请求线程立即释放,由Servlet异步线程池处理回调 | Event Loop事件循环,非阻塞全链路 |
| 背压支持 | 不支持,生产者无法感知消费者速率 | 原生支持(onBackpressureBuffer/Drop) |
| 依赖要求 | spring-boot-starter-web(已包含) |
需额外引入spring-boot-starter-webflux |
| 与JDBC/JPA兼容 | 天然兼容,阻塞调用无额外处理 | 需Schedulers.boundedElastic()包装每个阻塞调用 |
| 调试难度 | 低,同步思维,断点可打 | 高,异步堆栈难以追踪 |
本项目选择SseEmitter的理由:
-
架构一致性 :项目本身就是MVC架构(
@RestController+spring-boot-starter-web),SseEmitter是Spring MVC原生组件,零额外依赖。如果引入WebFlux,虽然Spring Boot检测到Servlet存在时仍以Tomcat启动,但代码中会出现两种编程范式并存(MVC的同步 + Flux的响应式),增加维护复杂度。 -
阻塞调用友好 :AI医疗分诊涉及大量阻塞IO------JDBC(
consultation_logs)、Redis缓存、Ollama HTTP调用。在WebFlux环境下,每个阻塞调用都必须用Schedulers.boundedElastic()包装,遗漏任何一个都会阻塞Event Loop,导致整个服务卡死。MVC模式下完全没有这个问题。 -
性能非瓶颈:AI推理延迟5-15秒/请求,Web层毫秒级的传输优化毫无意义。真正的瓶颈在GPU算力,不在Web框架。
-
Spring AI兼容 :
StreamingChatModel.stream()返回的Flux<ChatResponse>在MVC环境下通过.subscribe()消费即可,Flux类型由spring-ai传递依赖的reactor-core提供,不需要额外引入spring-boot-starter-webflux。 -
团队效率:MVC模式开发调试效率高,维护成本低。WebFlux的响应式编程范式学习曲线陡峭,团队需要额外培训成本。
什么场景该用WebFlux? 如果项目是高并发网关(如Spring Cloud Gateway)、纯非阻塞IO场景(无JDBC)、或需要支撑数万并发SSE连接,WebFlux才是正确选择。本项目后续规划中,Gateway层用WebFlux扛流量,业务服务用MVC稳扎稳打,这是微服务架构下的标准分工。
1.3 AiChatClient接口设计
我一开始是直接在Service里调Spring AI的ChatModel,写了两行就觉得不对劲------如果以后要换AI服务商呢?如果本地没装Ollama想用Mock跑测试呢?所以抽了个接口出来:
java
public interface AiChatClient {
// 普通对话,等AI全部回复完再返回
String chat(String message);
// 带系统提示词的对话(向AI模型发送消息并获取响应,不同agent的系统提示词是不同的)
String chat(String systemPrompt, String userMessage);
// 流式对话,通过回调逐字推送
void chatStream(String message, Consumer<String> onChunk, Runnable onComplete, Consumer<Throwable> onError);
}三个方法,覆盖了普通对话和流式对话两种场景。接口很薄,但有了它,后面切换实现就灵活多了。
注意chatStream的签名------没有返回Flux<String>,而是用了回调模式(Consumer<String> onChunk, Runnable onComplete, Consumer<Throwable> onError)。这是有意为之的设计:
-
与SseEmitter适配 :SseEmitter的核心操作就是
emitter.send()和emitter.complete(),回调模式天然对应------onChunk调emitter.send(),onComplete调emitter.complete() -
避免Flux暴露到Controller层 :如果接口返回
Flux<String>,Controller就必须处理响应式类型,与MVC编程模型冲突。回调模式让Controller只需关心SseEmitter,保持代码风格统一 -
Mock实现更简单 :Mock可以用普通线程 +
Thread.sleep()模拟流式输出,不需要理解Flux.create()的语义
1.4 OllamaAiChatClient实现
这是核心实现类,直接对接Spring AI的ChatModel:
java
/**通用聊天客户端:普通聊天模式
* Ollama AI聊天客户端实现
* 使用Spring AI Ollama集成进行模型通信
*/
@Component
@Primary
@ConditionalOnProperty(name = "ai.client.type", havingValue = "ollama", matchIfMissing = true)
public class OllamaAiChatClient implements AiChatClient {
private static final Logger log = LoggerFactory.getLogger(OllamaAiChatClient.class);
private final ChatModel chatModel;
private final StreamingChatModel streamingChatModel;
private final String systemPrompt;
private final String modelName;
public OllamaAiChatClient(ChatModel chatModel,
StreamingChatModel streamingChatModel,
@Qualifier("systemPrompt") String systemPrompt,
@org.springframework.beans.factory.annotation.Value("${spring.ai.ollama.chat.model:unknown}") String modelName) {
this.chatModel = chatModel;
this.streamingChatModel = streamingChatModel;
this.systemPrompt = systemPrompt;
this.modelName = modelName;
log.info("OllamaAiChatClient使用模型: {}", modelName);
}
@Override
public String chat(String message) {
log.info("[模型:{}] 发送消息", modelName);
try {
Prompt prompt = new Prompt(systemPrompt + "\n\n用户:" + message);
String response = chatModel.call(prompt)
.getResult()
.getOutput()
.getText();
log.info("[模型:{}] 收到响应", modelName);
return response;
} catch (Exception e) {
log.error("Error calling Ollama model: {}", e.getMessage(), e);
throw new RuntimeException("AI模型调用失败: " + e.getMessage(), e);
}
}
@Override
public String chat(String systemPrompt, String userMessage) {
log.info("[模型:{}] 发送消息(自定义提示词)", modelName);
try {
Prompt prompt = new Prompt(systemPrompt + "\n\n用户:" + userMessage);
String response = chatModel.call(prompt)
.getResult()
.getOutput()
.getText();
log.info("[模型:{}] 收到响应", modelName);
return response;
} catch (Exception e) {
log.error("Error calling Ollama model: {}", e.getMessage(), e);
throw new RuntimeException("AI模型调用失败: " + e.getMessage(), e);
}
}
// 这里可能会有疑问,为啥这里返回void,还能交互?后面会解答!!
@Override
public void chatStream(String message, Consumer<String> onChunk, Runnable onComplete, Consumer<Throwable> onError) {
log.info("[模型:{}] 发送流式消息", modelName);
try {
Prompt prompt = new Prompt(systemPrompt + "\n\n用户:" + message);
// 使用StreamingChatModel实现真正的流式输出
// streamingChatModel.stream()返回Flux<ChatResponse>(由spring-ai传递依赖的reactor-core提供)
// 通过subscribe()消费Flux,将每个chunk通过回调推送给SseEmitter
streamingChatModel.stream(prompt)
.subscribe(
response -> {
String text = response.getResult().getOutput().getText();
if (text != null && !text.isEmpty()) {
log.debug("Received chunk: {}", text);
onChunk.accept(text);
}
},
error -> {
log.error("Error calling Ollama streaming model: {}", error.getMessage(), error);
onError.accept(new RuntimeException("AI模型流式调用失败: " + error.getMessage(), error));
},
onComplete
);
} catch (Exception e) {
log.error("Error calling Ollama streaming model: {}", e.getMessage(), e);
onError.accept(new RuntimeException("AI模型流式调用失败: " + e.getMessage(), e));
}
}
}几个要点:
-
ChatModel和StreamingChatModel都是Spring AI自动配置好的,直接注入就行,不用自己创建Ollama的连接 -
@Primary标注它是默认实现,当不指定调用AiChatClient的哪个实现时,默认就会调用这个@Primary标记的bean -
@ConditionalOnProperty通过配置文件切换实现,后面会说 -
流式接口用
streamingChatModel.stream()返回Flux<ChatResponse>,通过.subscribe()消费,将每个chunk通过onChunk回调推送出去 -
为啥这里使用手写构造器的方式注入?
- 因为构造器里混了
@Qualifier和@Value,Lombok 生成的构造器没办法自动加这些注解 ,所以只能手写。如果只是普通的 Bean 依赖,用@RequiredArgsConstructor是最简洁的方式。
- 因为构造器里混了
关于Flux类型来源的说明 :streamingChatModel.stream()返回的Flux类型来自spring-ai-ollama-spring-boot-starter传递依赖的reactor-core,不需要额外引入spring-boot-starter-webflux 。这里只是消费Flux(.subscribe()),不涉及WebFlux的Server端能力(如Netty容器、响应式路由等)。
1.5 MockAiChatClient:没Ollama也能跑
不是所有时候本地都有Ollama在跑,写个Mock实现方便调试:
java
/**
* Mock AI聊天客户端实现
* 当Ollama不可用时用于本地测试
*/
@Component
@Primary
@ConditionalOnProperty(name = "ai.client.type", havingValue = "mock")
public class MockAiChatClient implements AiChatClient {
private static final Logger log = LoggerFactory.getLogger(MockAiChatClient.class);
@Override
public String chat(String message) {
log.info("Mock AI client received message: {}", message);
// 根据关键词模拟AI响应
String response;
if (message.contains("头痛") || message.contains("头疼")) {
response = "我了解您有头痛的症状。头痛可能有多种原因,建议您:\n\n" +
"1. 如果头痛持续时间较长或伴有恶心、呕吐、视力模糊等症状,建议尽快到神经内科就诊\n" +
"2. 如果是突发剧烈头痛,请立即就医\n" +
"3. 记录头痛发作的时间、部位和持续时间,有助于医生诊断";
} else if (message.contains("发烧") || message.contains("发热")) {
response = "我了解您有发热的症状。发热通常是身体对感染或炎症的反应。\n\n" +
"建议您:\n" +
"1. 测量体温,如果超过38.5°C,建议到发热门诊或内科就诊\n" +
"2. 多休息,多饮水\n" +
"3. 如果伴有其他严重症状(如呼吸困难、意识模糊等),请立即就医";
} else if (message.contains("胸痛") || message.contains("胸口疼")) {
response = "胸痛是一个需要重视的症状,可能涉及心脏、肺部或消化系统。\n\n" +
"⚠️ 重要提醒:\n" +
"1. 如果是突发剧烈胸痛、伴有呼吸困难、出汗、放射到手臂或下巴,请立即拨打120!\n" +
"2. 如果是持续性胸痛,建议尽快到心内科或急诊科就诊\n" +
"3. 记录胸痛的性质(刺痛、闷痛、压迫感)和持续时间";
} else if (message.contains("咳嗽")) {
response = "咳嗽是呼吸道常见的症状。\n\n" +
"建议您:\n" +
"1. 如果咳嗽超过2周未好转,建议到呼吸内科就诊\n" +
"2. 如果伴有咳痰、发热、呼吸困难等症状,建议尽快就医\n" +
"3. 注意观察痰的颜色和量";
} else {
response = "感谢您描述的症状。为了给您更准确的建议,能否请您补充以下信息:\n\n" +
"1. 症状持续多长时间了?\n" +
"2. 是否有其他伴随症状?\n" +
"3. 症状的严重程度如何?\n\n" +
"根据您提供的信息,我会为您推荐合适的就诊科室。";
}
return response;
}
@Override
public String chat(String systemPrompt, String userMessage) {
// Mock实现直接忽略systemPrompt,复用chat(message)逻辑
return chat(userMessage);
}
@Override
public void chatStream(String message, Consumer<String> onChunk, Runnable onComplete, Consumer<Throwable> onError) {
log.info("Mock AI client received stream message: {}", message);
String response = chat(message);
// 通过逐字符发送模拟流式输出
// 在新线程中执行,避免阻塞Servlet线程
new Thread(() -> {
try {
for (char c : response.toCharArray()) {
onChunk.accept(String.valueOf(c));
Thread.sleep(30); // 模拟延迟
}
onComplete.run();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
onError.accept(e);
}
}).start();
}
}chatStream这里有个小技巧------把字符串拆成单个字符,每个间隔30毫秒发送,这样前端看到的效果就跟真的一样,一个字一个字蹦出来。注意这里用新线程执行,避免阻塞Servlet请求线程。在生产环境的Ollama实现中不需要新线程,因为streamingChatModel.stream().subscribe()本身就是异步的。
1.6 @ConditionalOnProperty切换客户端
在application.yml里加一个配置就行:
TypeScript
server:
port: 8083
spring:
application:
name: medical-ai-service
ai:
ollama:
base-url: ${OLLAMA_BASE_URL:http://localhost:11434}
chat:
model: ${OLLAMA_MODEL:qwen3-coder:480b-cloud}
# AI Client Configuration
ai:
client:
# Client type: ollama or mock
type: ollama@ConditionalOnProperty会根据这个值决定加载哪个实现类。matchIfMissing = true表示如果没配这个属性,默认用Ollama实现。这样在测试环境或者没装Ollama的机器上,改个配置就能跑起来。
配置类里还定义了系统提示词的Bean:
java
@Configuration
public class AiClientConfig {
private static final Logger log = LoggerFactory.getLogger(AiClientConfig.class);
@Value("${ai.client.type:ollama}")
private String clientType;
@PostConstruct
public void logClientType() {
log.info("AI client type configured: {}", clientType);
}
// ==================== 通用提示词 ====================
/**
* 医疗分诊系统提示词
* 供ChatService等通用场景使用
*/
@Bean
public String systemPrompt() {
return """
你是一名专业的医疗分诊助手。请根据用户描述的症状,提供专业的建议。
要求:
1. 保持专业、客观的态度
2. 不要进行疾病诊断,只提供就诊方向建议
3. 建议用户前往合适的科室就诊
4. 如果症状紧急,提醒用户立即就医
5. 不要在回复末尾添加免责声明,系统会自动添加
请用中文回复。
""";
}
}1.7 踩坑记录
坑1:OllamaModel是枚举类,不能随便传模型名
我一开始想用OllamaModel.create("qwen3-coder:480b-cloud")来指定模型,结果发现OllamaModel是个枚举类,里面只有预定义的几个模型名。自定义模型名要用OllamaOptions:
TypeScript
// 错误写法,OllamaModel是枚举不能create
OllamaModel model = OllamaModel.create("qwen3-coder:480b-cloud");
// 正确写法,在配置文件里指定模型名
// application.yml:
spring.ai.ollama.chat.model: qwen3-coder:480b-cloud其实Spring AI的自动配置已经帮你处理好了,在yml里配spring.ai.ollama.chat.model就行,不用手动创建Options。
坑2:混用Web和WebFlux的陷阱
一开始我同时引入了spring-boot-starter-web和spring-boot-starter-webflux,用Flux<String>做流式返回。看起来能跑,实际上Spring Boot检测到Servlet存在时会默认以Tomcat(MVC模式)启动------此时你写的Flux<String>底层依然是Servlet异步线程在处理,并不是真正的Reactor Netty非阻塞模型。
更严重的问题是:如果项目中有JDBC、JPA等阻塞调用,在MVC模式下没问题,但如果将来想迁移到纯WebFlux,每个阻塞调用都必须用Schedulers.boundedElastic()包装,遗漏任何一个都会阻塞Event Loop导致服务卡死。
正确的做法是:业务服务用MVC + SseEmitter,网关服务用WebFlux + Netty,各司其职。不要在同一个服务里混用两种编程模型。
坑3:SseEmitter超时设置
SseEmitter默认超时30秒,但AI推理经常需要5-15秒甚至更长。如果超时设置太短,AI还没回复完连接就断了。必须手动设置超时时间:
java
SseEmitter emitter = new SseEmitter(300_000L); // 5分钟超时同时要注册错误处理回调,否则连接异常时可能抛出未捕获异常:
java
emitter.onTimeout(() -> log.warn("SSE connection timeout"));
emitter.onError(ex -> log.error("SSE connection error", ex));二、前端对话页
2.1 Vue3 + Vite项目搭建
前端项目叫medical-triage-web,用Vite创建的Vue3项目:
TypeScript
npm create vite@latest medical-triage-web -- --template vue-ts
npm install element-plus axios结构很简单:
TypeScript
medical-triage-web/
├── src/api/stream.ts(流式请求封装)
├── src/components/Consultation.vue(主对话页)
├── src/components/ChatBubble.vue(消息气泡)
├── src/components/ChatInput.vue(输入框)
└── src/types/chat.ts2.2 Consultation.vue对话页面
这是主页面,管理消息列表和发送逻辑:
TypeScript
<template>
<div class="consultation">
<div class="chat-header">
<h2>智能分诊助手</h2>
</div>
<div class="chat-messages" ref="messagesContainer">
<ChatBubble
v-for="msg in messages"
:key="msg.id"
:message="msg"
/>
</div>
<ChatInput
:loading="isLoading"
@send="handleSend"
@stop="handleStop"
/>
</div>
</template>核心逻辑在handleSend方法里,调用流式接口,逐字更新AI的回复:
TypeScript
const handleSend = async (content: string) => {
// 添加用户消息到列表
const userMsg = { id: Date.now(), role: 'user', content };
messages.value.push(userMsg);
// 添加AI占位消息
const aiMsg = { id: Date.now() + 1, role: 'assistant', content: '' };
messages.value.push(aiMsg);
isLoading.value = true;
try {
await streamChat(content, (chunk) => {
// 逐字追加AI回复
const target = messages.value.find(m => m.id === aiMsg.id);
if (target) target.content += chunk;
});
} finally {
isLoading.value = false;
}
};这段流式追加的逻辑值得多说两句。AI回复是一个字一个字蹦出来的,所以先在消息列表里占个位置(content: ''的空消息),然后每收到一个字就往里追加。为什么要先占位?因为如果等AI全部说完再添加消息,用户就会盯着空白屏幕等好几秒,体验很差。先放个空气泡在那,用户能看到AI正在"打字",心里就有底了。onChunk回调就是干这个事的------streamChat每从服务端收到一个字,就触发这个回调,把字追加到对应消息的content上,Vue的响应式系统会自动更新页面。
2.3 ChatBubble和ChatInput组件拆分
ChatBubble就是消息气泡,根据role区分样式------用户消息靠右蓝色,AI消息靠左白色。没什么复杂的,就是样式活。
ChatInput稍微有点东西,主要是支持Enter发送和Shift+Enter换行,还有个停止生成的按钮:
TypeScript
<template>
<div class="chat-input">
<el-input
v-model="inputText"
type="textarea"
:rows="2"
placeholder="请描述您的症状..."
@keydown.enter.exact.prevent="handleSend"
/>
<el-button v-if="!loading" @click="handleSend" :disabled="!inputText.trim()">
发送
</el-button>
<el-button v-else type="danger" @click="$emit('stop')">
停止
</el-button>
</div>
</template>三、流式输出(SSE)
这是整个项目里最折腾的部分。SSE(Server-Sent Events)和WebSocket经常被拿来比较,简单说:
-
WebSocket是双向通信,客户端和服务端都能主动发消息,适合聊天室这种场景
-
SSE是单向的,只有服务端往客户端推,当用户问ai还有,ai经过思考,然后将答案返回给用户,适合AI这种"你问我答、一个字一个字蹦"的场景
我们这个场景用SSE就够了,而且Spring MVC原生支持,不需要额外引入WebSocket的复杂度。
3.1 后端:SseEmitter + TEXT_EVENT_STREAM_VALUE
Controller里的流式接口:
java
@RestController
@RequestMapping("/api/v1")
@CrossOrigin(origins = "*")
public class ChatController {
private final ChatService chatService;
@PostMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter chatStream(@Valid @RequestBody ChatRequest request) {
SseEmitter emitter = new SseEmitter(300_000L); // 5分钟超时
chatService.processMessageStream(request.getMessage(), emitter);
return emitter;
}
}关键点:
-
produces = MediaType.TEXT_EVENT_STREAM_VALUE告诉浏览器这个接口返回的是SSE流 -
返回类型是
SseEmitter而不是Flux<String>,这是Spring MVC原生的SSE支持 -
new SseEmitter(300_000L)设置5分钟超时,AI推理慢,默认30秒不够用 -
方法立即返回
SseEmitter对象,Servlet线程被释放,后续数据推送由异步回调完成
Service层做两件事:转发AI调用、自动追加免责声明:
java
@Service
public class ChatService {
private static final String DISCLAIMER =
"\n\n---\n⚠️ 本系统提供的仅为就诊方向建议,不构成医疗诊断。\n" +
"请以医生的专业诊断为准。如有紧急健康问题,请立即拨打120。";
private final AiChatClient aiChatClient;
public void processMessageStream(String message, SseEmitter emitter) {
try {
aiChatClient.chatStream(message,
// onChunk: 每收到一个片段就推送给客户端
chunk -> {
try {
emitter.send(SseEmitter.event().data(chunk));
} catch (Exception e) {
emitter.completeWithError(e);
}
},
// onComplete: 流结束后追加免责声明,然后关闭连接
() -> {
try {
emitter.send(SseEmitter.event().data(DISCLAIMER));
} catch (Exception e) {
// 免责声明发送失败不影响主流程
}
emitter.complete();
},
// onError: 出错时关闭连接
error -> emitter.completeWithError(error)
);
} catch (Exception e) {
emitter.completeWithError(e);
}
}
}注意:免责声明是在Service层统一追加的,不是让AI模型自己加。这样不管用Ollama还是Mock,所有回复都带免责声明,符合验收标准。
SseEmitter的工作原理 :Controller方法返回SseEmitter后,Spring MVC会保持HTTP连接打开(基于Servlet 3.1异步IO),请求线程立即释放回Tomcat线程池。后续通过emitter.send()推送数据时,由Servlet容器的异步线程负责写入HTTP响应。emitter.complete()关闭连接,emitter.completeWithError()关闭并通知错误。
3.2 前端:fetch + ReadableStream解析
前端不能用axios,因为axios不支持ReadableStream。得用原生fetch:
TypeScript
// stream.ts
export async function streamChat(
message: string,
onChunk: (text: string) => void,
signal?: AbortSignal
): Promise<void> {
const abortController = new AbortController();
const response = await fetch('/api/v1/chat/stream', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message }),
signal: signal || abortController.signal
});
if (!response.ok) {
throw new Error(`请求失败: ${response.status}`);
}
const reader = response.body!.getReader();
const decoder = new TextDecoder();
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 解码当前数据块
const chunk = decoder.decode(value, { stream: true });
// 解析SSE格式:每条消息是 "data: xxx\n\n"
const lines = chunk.split('\n');
for (const line of lines) {
if (line.startsWith('data:')) {
const text = line.substring(5);
if (text.trim()) {
onChunk(text);
}
}
}
}
} finally {
reader.releaseLock();
}
}3.3 AbortController停止生成
用户点"停止"按钮时,需要中断SSE连接。用AbortController就行:
TypeScript
// Consultation.vue
let currentAbortController: AbortController | null = null;
const handleSend = async (content: string) => {
currentAbortController = new AbortController();
// ...省略其他逻辑
await streamChat(content, onChunk, currentAbortController.signal);
};
const handleStop = () => {
if (currentAbortController) {
currentAbortController.abort();
currentAbortController = null;
}
};调用abort()后,fetch请求会立即中断,reader.read()会抛出AbortError,SSE连接就断了。
3.4 踩坑记录
坑1:SseEmitter超时时间不够
SseEmitter默认超时30秒,AI推理动辄5-15秒,加上网络延迟,30秒很容易超时。必须手动设置足够长的超时时间(本项目设为5分钟)。如果部署了Nginx,还需要同步调整proxy_read_timeout。
坑2:SSE数据格式解析
SSE的标准格式是data: 内容\n\n,每个事件用两个换行分隔。但实际从服务端收到的数据块不一定按事件边界切分------可能一个chunk里包含半个事件,也可能一个chunk里包含多个事件。
我上面的解析代码做了简化处理,对于大多数场景够用了。如果要求严格,需要维护一个buffer,把收到的数据拼起来,按\n\n切分后再解析。
坑3:中文字符分块解码
这是最阴的坑。UTF-8编码下,一个中文字符占3个字节。如果网络传输时恰好在一个中文字符的中间切断了,decoder.decode()就会得到乱码。
解决办法是decoder.decode(value, { stream: true })------这个stream: true参数告诉解码器:如果当前数据块末尾有不完整的字符,先缓存起来,等下一个数据块到了再拼完整。这个参数不加,中文必出乱码。
坑4:MockAiChatClient的流式模拟
Mock实现里用Thread.sleep(30)逐字符发送,模拟流式效果。这个间隔不能太短------太短了看不出打字效果,太长了又觉得卡。30毫秒是我试下来比较舒服的值,一个字一个字蹦,速度刚好。注意Mock实现需要在新线程中执行,否则会阻塞Servlet请求线程。
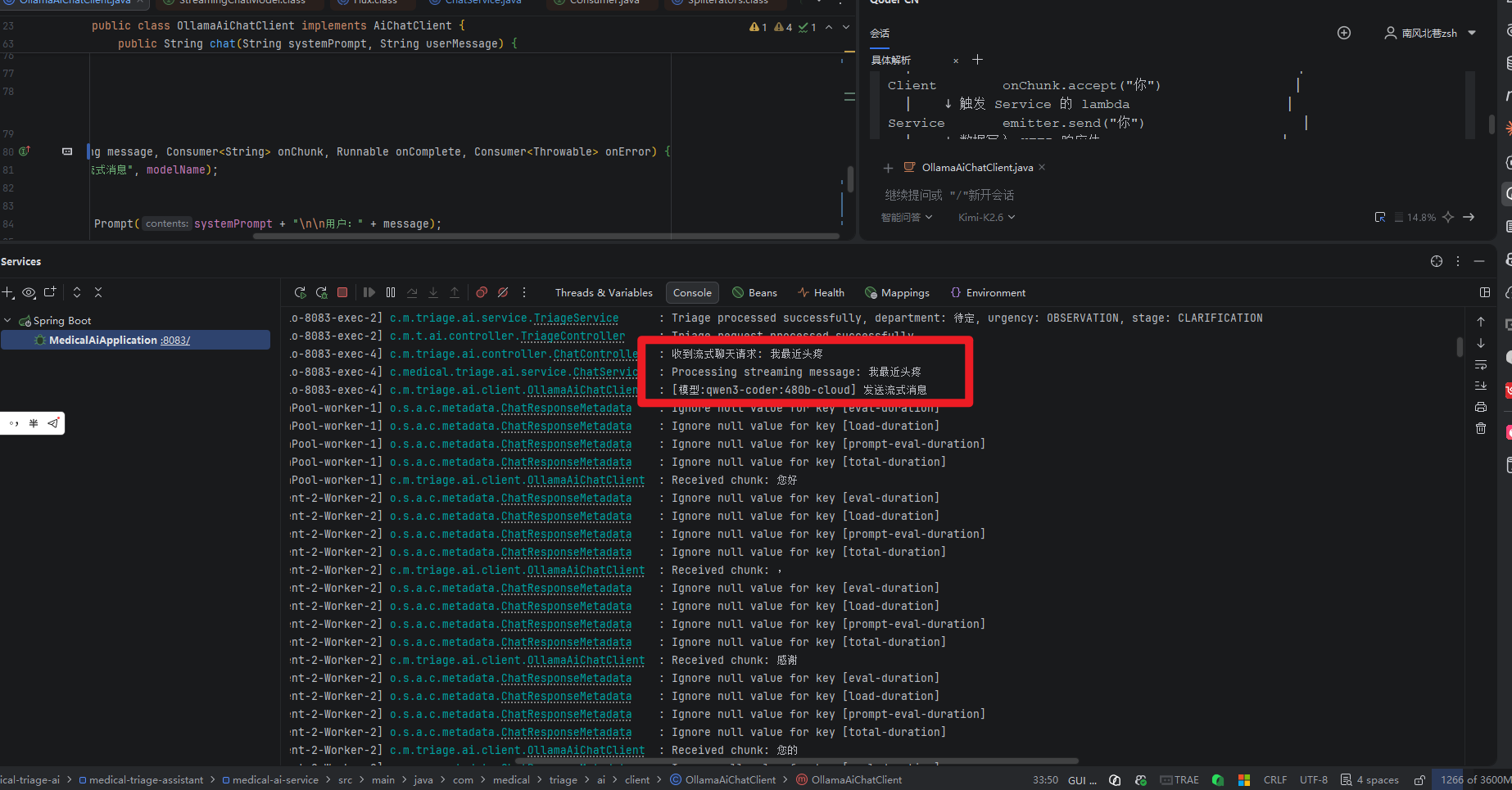
3.5 经典疑问,processMessageStream返回的参数是void,那chatStream怎么接收到返回值,然后传给前端了?
先做出总结:
-
chatStream 的 void 只是声明"我不通过返回值给你数据",真正的数据通过三个回调函数"反向注入"到了 Service 层的 SseEmitter 中,再由 SseEmitter 推送到前端浏览器。
-
如果把整个流式对话比作"打电话":
-
chatStream 是拨号(void,拨完就完)
-
onChunk 是对方每说一句你听到一句
-
SseEmitter 是电话线(保持连接,随时传声)
-
onComplete 是对方说"我说完了"
-
onError 是信号中断
-
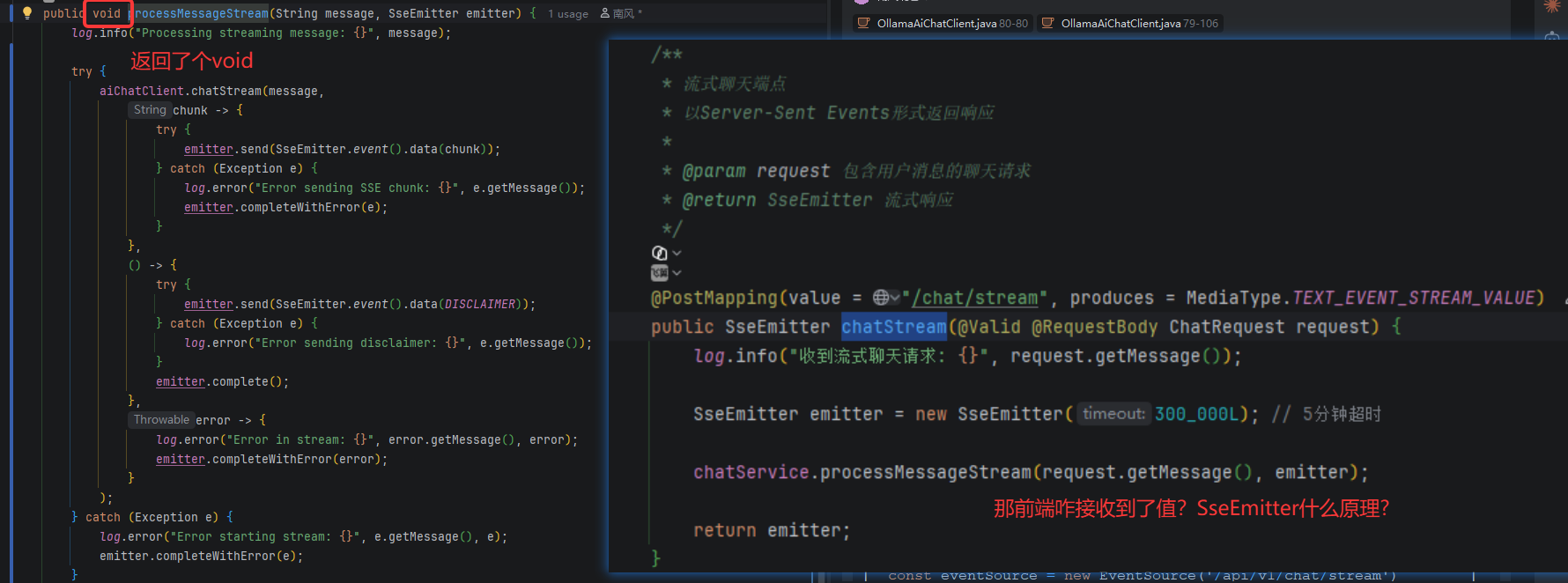
这是一个非常经典的"回调驱动 + SSE 推送"架构。数据不是通过返回值返回的,而是通过回调函数把数据"反向"推到了 SseEmitter 里。(1)三层联动的完整链
TypeScript
┌──────────────────────────────────────────────────────────────────────┐
│ 前端 (Vue) │
│ const eventSource = new EventSource('/api/v1/chat/stream') │
│ eventSource.onmessage = (e) => { this.messages += e.data } │
└───────────────────────────────────────┬──────────────────────────────┘
│ HTTP 长连接 (SSE)
┌───────────────────────────────────────▼──────────────────────────────┐
│ Controller (ChatController.java) │
│ @PostMapping(value = "/chat/stream", produces = TEXT_EVENT_STREAM) │
│ SseEmitter chatStream(ChatRequest request) { │
│ SseEmitter emitter = new SseEmitter(300_000L); │
│ chatService.processMessageStream(request.getMessage(), emitter);│
│ return emitter; ← 返回 SseEmitter,Spring 保持连接不关闭 │
│ } │
└───────────────────────────────────────┬──────────────────────────────┘
│ 把 emitter 传给 Service
┌───────────────────────────────────────▼──────────────────────────────┐
│ Service (ChatService.java) │
│ processMessageStream(String message, SseEmitter emitter) { │
│ aiChatClient.chatStream(message, │
│ // onChunk: AI 每吐一个字,就往 emitter 里塞 │
│ chunk -> emitter.send(SseEmitter.event().data(chunk)), │
│ │
│ // onComplete: AI 说完了,关闭连接 │
│ () -> { emitter.send(DISCLAIMER); emitter.complete(); }, │
│ │
│ // onError: 出错了,断开连接 │
│ error -> emitter.completeWithError(error) │
│ ); │
│ } │
└───────────────────────────────────────┬──────────────────────────────┘
│ 回调参数继续下传
┌───────────────────────────────────────▼──────────────────────────────┐
│ Client (OllamaAiChatClient.java) │
│ void chatStream(String message, │
│ Consumer<String> onChunk, │ ← Service 传进来的 lambda
│ Runnable onComplete, │ ← Service 传进来的 lambda
│ Consumer<Throwable> onError) { │ ← Service 传进来的 lambda
│ │
│ streamingChatModel.stream(prompt) │
│ .subscribe( │
│ response -> onChunk.accept(text), // AI 每吐一个 token │
│ error -> onError.accept(error), // AI 出错 │
│ onComplete // AI 说完了 │
│ ); │
│ } │
└──────────────────────────────────────────────────────────────────────┘
(2)那为啥OllamaAiChatClient中的chatStream返回 void 还能交互?
因为 void 不等于没有响应,而是"响应是异步推送的"。
- chatStream 的 void 只是"点火"
java
public void chatStream(String message, ...) {
// 发起请求,立即返回
streamingChatModel.stream(prompt)
.subscribe(...); // ← 订阅是异步的!不会阻塞
}
这里 .stream(prompt) 返回 Flux<ChatResponse>,.subscribe() 表示"你发你的,我不等你,有数据了叫我"。subscribe() 本身也是非阻塞的,所以 chatStream 方法几毫秒就执行完了,返回 void。
- 真正的数据"藏"在回调里
三个回调参数就是"有数据了叫我"的钩子:
| 参数 | 本质 | 触发时机 |
|---|---|---|
| Consumer<String> onChunk | 一个接收字符串的函数 | AI 每生成一个 token 时 |
| Runnable onComplete | 一个无参无返回的函数 | AI 全部说完时 |
| Consumer<Throwable> onError | 一个接收异常的函数 | 网络/模型出错时 |
- Service 层把回调和 SseEmitter 绑定
这是最关键的一步:
TypeScript
aiChatClient.chatStream(message,
// onChunk
chunk -> {
emitter.send(SseEmitter.event().data(chunk)); // ← 写到 HTTP 响应流
},
// onComplete
() -> {
emitter.send(SseEmitter.event().data(DISCLAIMER));
emitter.complete(); // ← 关闭 SSE 连接
},
// onError
error -> {
emitter.completeWithError(error); // ← 异常关闭
}
);这里用 Lambda 表达式创建了三个匿名函数传给 chatStream。当 AI 模型在后台推送数据时,这三个回调会被触发,进而操作 emitter.send() 把数据刷到前端的 HTTP 连接上。
(3)SseEmitter 的工作原理
SseEmitter 是 Spring MVC 提供的 Server-Sent Events (SSE) 工具 。它做了一件很简单的事:持有当前 HTTP 请求的 Response 输出流,让你随时往里写数据。
Controller 层的核心逻辑
java
@PostMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter chatStream(@Valid @RequestBody ChatRequest request) {
SseEmitter emitter = new SseEmitter(300_000L); // 5分钟超时
chatService.processMessageStream(request.getMessage(), emitter);
return emitter; // ← 返回后 Spring 不会关闭 Response!
}-
普通接口返回后,Spring 会关闭 HTTP 连接。但返回 SseEmitter 时,Spring 会:
-
设置响应头 Content-Type: text/event-stream
-
保持 TCP 连接不断开
-
等待你在其他线程里调用 emitter.send(...) 写入数据
-
-
SSE 数据格式
-
每次 emitter.send(SseEmitter.event().data("你好")),实际写到 HTTP 响应体的是:data: 你好
-
前端 EventSource 接收到后,e.data 就是 "你好"。
-
(4)时序图:一次流式请求的生命周期
TypeScript
时间轴 ──────────────────────────────────────────>
前端 POST /chat/stream
│──────────────────────────────────────────────>
│ │
Controller 创建 SseEmitter │
│ 调用 chatService.processMessageStream() │
│──────────────────────────────────────────> │
│ │
Service 调用 aiChatClient.chatStream() │
│ 传入三个 lambda (内部持有 emitter 引用) │
│──────────────────────────────────────────> │
│ │
Client streamingChatModel.stream() │
│ .subscribe(...) ← 非阻塞,立即返回 │
│──────────────────────────────────────────> │
│ │
│ │
│ ←──────────────────────────────────────────│ AI 模型逐 token 返回
│ │
Client onChunk.accept("你") │
│ ↓ 触发 Service 的 lambda │
Service emitter.send("你") │
│ ↓ 数据写入 HTTP 响应体 │
前端 ←───────────────────────────────────│ EventSource.onmessage
│ │
Client onChunk.accept("好") │
Service emitter.send("好") │
前端 ←───────────────────────────────────│
│ │
Client onComplete.run() │
│ ↓ 触发 Service 的 lambda │
Service emitter.send(DISCLAIMER) │
emitter.complete() │
│ │
前端 ←───────────────────────────────────│ 收到免责声明
前端 连接断开 (onclose) │
四、运行效果和验收
4.1 启动命令
先确保Ollama在本地跑着:
TypeScript
# 启动Ollama(如果还没启动)
ollama serve
# 看看有啥模型可用
ollama list
# 拉模型(如果还没拉)
ollama pull qwen3-coder:480b-cloud
其实你下一个ollama的桌面版,也能连:
然后启动后端:
bash
cd medical-triage-assistant/medical-ai-service
mvn spring-boot:run启动前端:
bash
cd medical-triage-web
npm run dev如果本地没Ollama,把application.yml里的ai.client.type改成mock就行。
4.2 测试接口
效果测试:
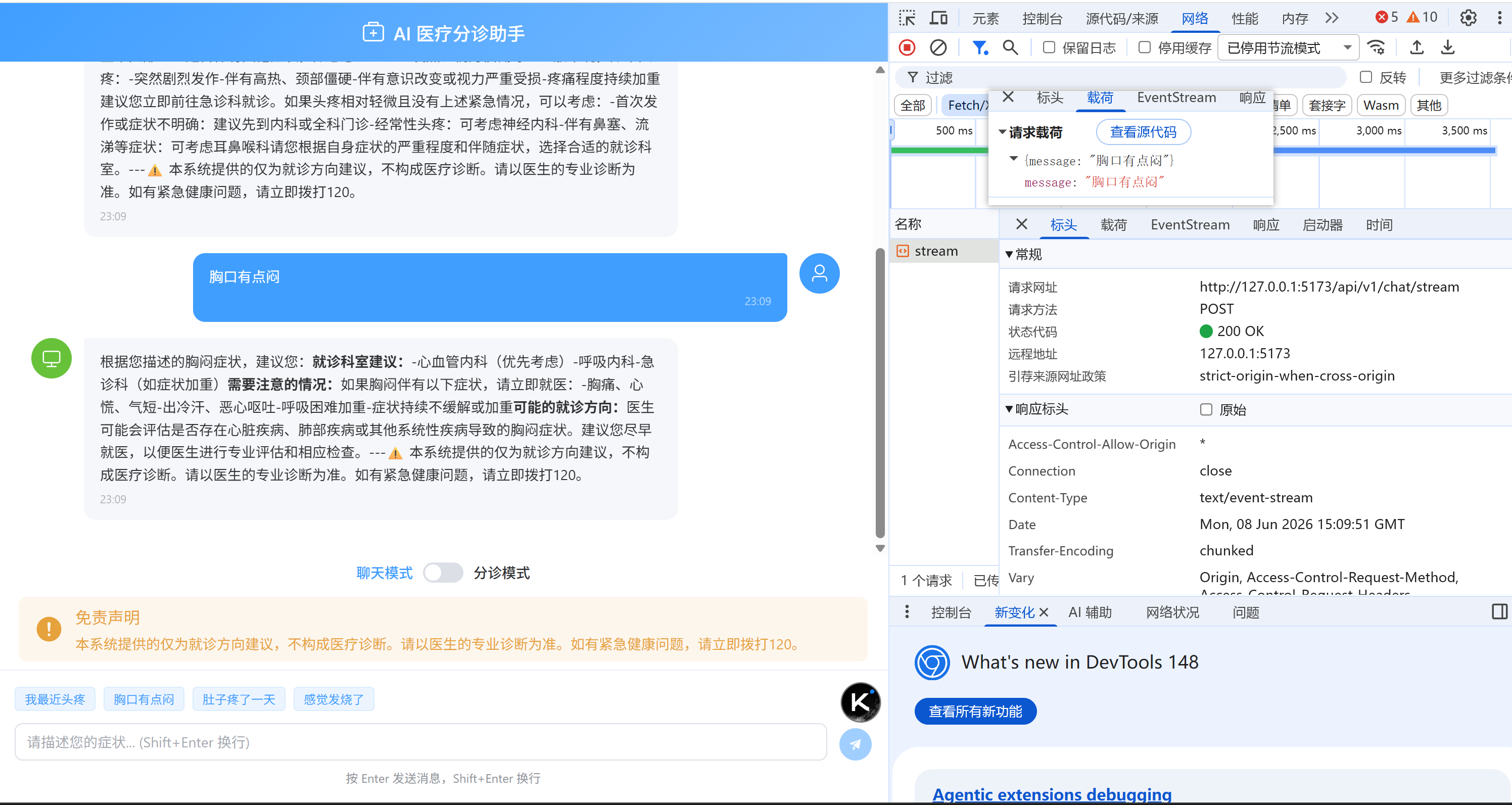
流式接口你会看到AI的回复一个字一个字地出来,而不是等全部生成完才返回。
ollama可以看到请求记录:
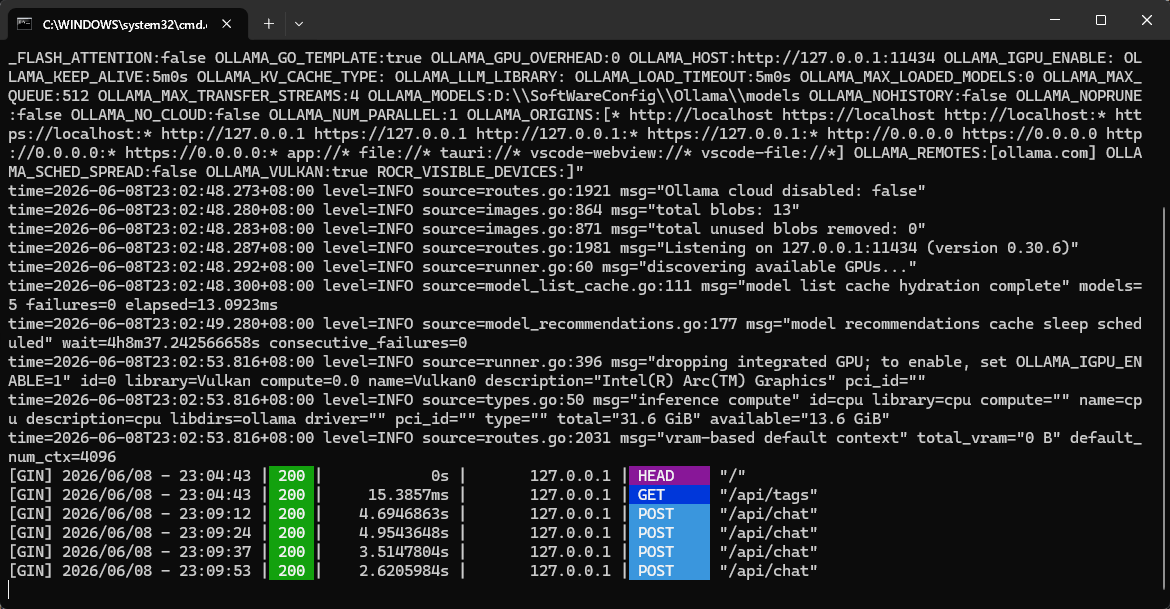
后端日志可以看到请求记录,以及用的啥模型:
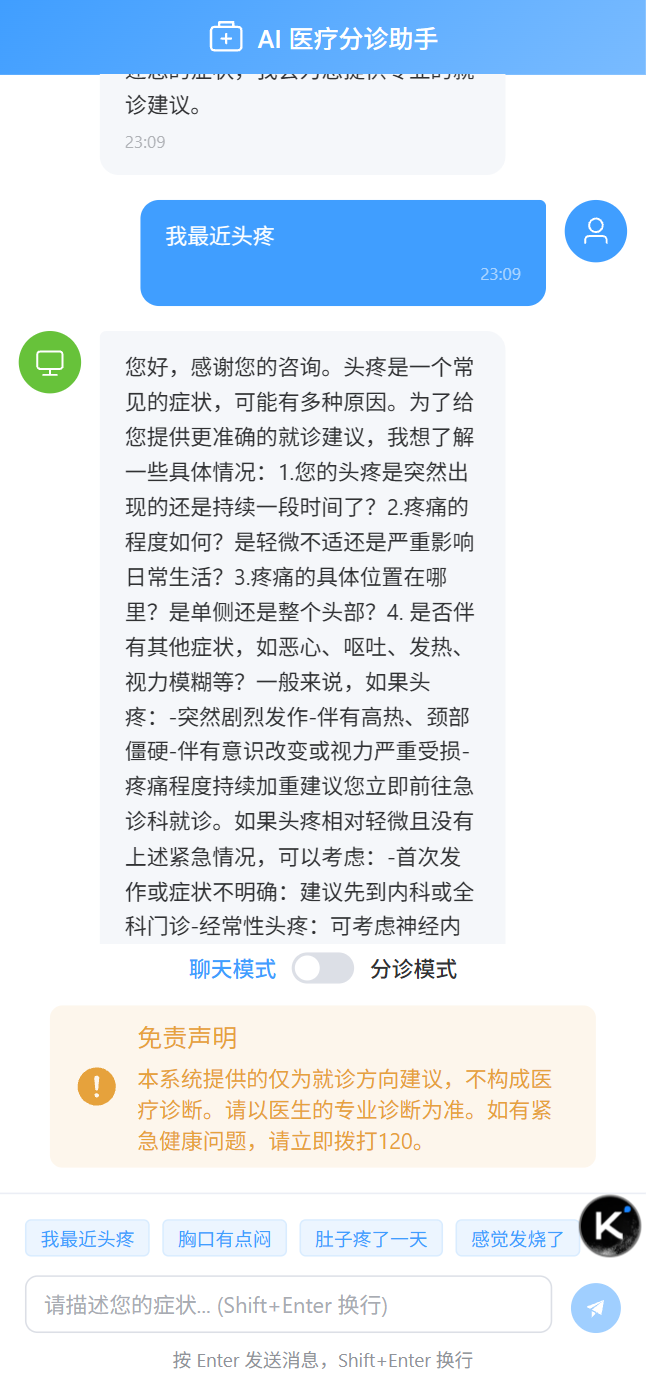
4.3 移动端适配
前端用了Element Plus的响应式布局,加上CSS媒体查询,在手机上也能正常使用。ChatInput在移动端会自动调整高度,ChatBubble的宽度也做了百分比适配。
总结
这篇文章覆盖了从后端骨架到前端对话页到SSE流式输出的完整链路。核心就几件事:
-
用Spring AI的
ChatModel和StreamingChatModel对接Ollama,不用自己处理HTTP连接 -
抽个
AiChatClient接口,用@ConditionalOnProperty在Ollama和Mock之间切换 -
SSE流式输出用
SseEmitter+TEXT_EVENT_STREAM_VALUE,不需要引入WebFlux依赖。StreamingChatModel.stream()返回的Flux通过.subscribe()消费,Flux类型由spring-ai传递依赖的reactor-core提供 -
前端处理时,中文字符分块解码一定要加
{ stream: true },不然必出乱码 -
SseEmitter超时时间必须手动设置,默认30秒对AI推理场景不够用
关于技术选型的最后总结:SseEmitter(MVC模式)和Flux(WebFlux模式)都能实现SSE流式输出,选择哪种取决于项目架构。本项目是MVC架构、有阻塞IO、AI推理是性能瓶颈,SseEmitter是更务实的选择。如果后续需要网关层扛高并发流量,Gateway服务用WebFlux,与业务服务的MVC架构互不冲突。
下一篇会讲怎么把对话历史存起来、加上上下文记忆,让AI能记住之前聊过什么。还有怎么把系统提示词做得更专业,让AI真正像一个分诊助手而不是通用聊天机器人。