1、子查询优化
子查询虽然能帮助我们通过一个SQL语句实现比较复杂的逻辑,但是他的执行效率不高:
- 执行子查询时,MySQL会为内层查询语句设置一个临时表,然后外部查询语句从临时表中查询记录。查询完毕后再撤销这些临时表。(会消耗过多的CPU以及IO资源,产生大量的慢查询);
- 子查询的结果集存储的临时表无论是内存临时表还是磁盘临时表都不会存在索引,因此查询性能有一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响越大。
- MySQL中可以使用连接JOIN查询来代替子查询,不用建立临时表,如果有索引的使用,性能会更好。
2、排序优化
在SQL语句中,可以在WHERE子句和ORDER BY子句中使用索引,目的是为了在WHERE子句中避免全表扫描,在ORDER BY子句中使用FileSort排序。
3、优先考虑覆盖索引
3.1 覆盖索引的定义
如果通过读取索引就能得到想要的数据,就不用读取整行了。也就是说一个索引包含了满足查询结果的数据就叫做覆盖索引。
案例:有一个联合索引idx_age_name
sql
EXPLAIN SELECT * FROM student WHERE age <> 20;此时根据索引失效的情况,该语句是不能使用索引的;
sql
EXPLAIN SELECT age,NAME FROM student WHERE age <> 20;虽然还是不等于条件,但是基于成本的考量,查询字段是age以及NAME,这是在覆盖索引的范畴内(无需回表),因此可以使用idx_age_name索引。
3.2 覆盖索引的优缺点
覆盖索引可以减少树的搜索次数,显著提升查询的性能,因此使用覆盖索引是常用的性能优化手段
优点:
(1)避免Innodb表进行索引的回表操作
覆盖索引中,二级索引的键值可以获取所要的数据,就能够避免对主键的二次查询,减少IO操作。
(2)把随机IO变为顺序IO加快查询效率✅️
覆盖索引按照键值的顺序存储,对于IO密集型的范围查找来说,对比随机从磁盘读取每一行的数据IO要少得多(回表后所要的数据就可能不在一个数据页里甚至不在磁盘的连续区域),因此使用覆盖索引在访问时可以将磁盘的随机读取IO转换为索引查找的顺序IO。
缺点:
索引字段的维护是有代价的,如果为了使用覆盖索引而建立了冗余索引就得考虑是否值得。
4、索引下推(ICP)
索引下推是一种在存储引擎层使用索引过滤数据的一种优化方式,它可以减少存储引擎访问基表的次数以及MySQL服务器访问存储引擎的次数。
使用ICP后直接就去掉了不满足index filter条件的记录,省去了回表所使用的成本,ICP的加速效果取决于在存储引擎内通过ICP筛选掉的数据比例。
4.1 ICP的使用条件
(1)explain显示的type类型是range、ref、eq_ref、或者ref_or_null;
(2)并非全部的where条件都能用ICP筛选,如果where条件的字段不在索引列中,还得读取整表记录到服务端进行where过滤;
(3)ICP可以用于InnoDB与MyISAM表,包括分区表InnoDB和MyISAM表;
(4)对于InnoDB表,ICP仅用于二级索引。ICP的目标是减少全行读取的次数,从而减少IO操作
(5)当SQL进行覆盖索引时,不支持ICP,因为这不会减少IO次数;
(6)相关子查询的条件不能使用ICP。
4.2 案例
sql
SELECT * FROM tuser
WHERE NAME LIKE '张%'
AND age = 10
AND ismale = 1;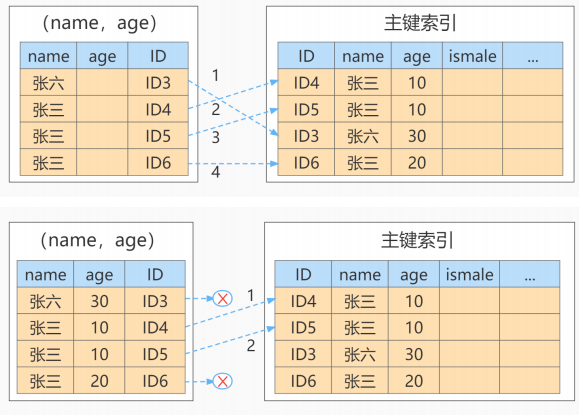
可以看到,该查询使用到了联合索引(name,age),并且where的第一个条件匹配到了四条数据,如果不使用ICP,就会直接根据这四条数据进行回表;如果使用ICP,就会在这四条的基础上过滤两条,用剩余的两条记录回表;因为ismale不在索引列,因此ismale条件不能使用ICP。
在没有索引下推(ICP)的年代,MySQL 存储引擎仅利用联合索引的最左前缀(如 `name LIKE '张%'`)定位范围,然后对该范围内的每一条索引记录(即使索引包含 `age`)都无条件回表,最后在 Server 层再判断 `age = 10` 等条件,导致大量无效回表。而 ICP 允许存储引擎在回表之前,直接基于索引中的 `age` 列进行过滤,只有同时满足 `name LIKE '张%'` 和 `age = 10` 的索引记录才会回表,从而显著减少回表次数。这种优化打破了原来 Server 与存储引擎之间严格的职责边界,将部分条件判断下推到更早的索引扫描阶段,是 MySQL 5.6 引入的重要性能改进。
5、COUNT(*)、COUNT(1)、COUNT(具体字段)的区别
COUNT(*)和COUNT(1)本质上并无区别,但是如果是在MyISAM中统计数据表的行数只要O(1)的复杂度(因为每张MyISAM数据表都有一个meta信息存储了row_count的值);如果是InnoDB存储引擎需要O(n)的复杂度,需要使用全表扫描完成统计。
在InnoDB存储引擎中,如果使用COUNT(具体字段)来统计行数,尽量使用二级索引。因为聚簇索引包含的信息多;如果有多个不同的二级索引,就选择占用空间更小(key_len)的来进行统计。如果选择联合索引作为具体的列,那么联合索引中的任何一列都可以被COUNT(具体字段)使用,不需要该列在最左边。优化器会在所有包含该字段的索引中选择一个代价最小的来执行统计。