Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第四章 Dictionaries(字典)
与 Python 中的列表和序列天然相辅相成的是一种名为字典的类型。字典用于存储映射到相应值的查找键(这通常被称为关联数组或哈希表)。其灵活性使得字典非常适合于簿记工作:能够动态追踪新增和变化的数据项以及它们彼此间的关系。在编写新程序时,使用字典是一种很好的开始方式,即便你尚未确定可能还需要哪些其他数据结构或类。
字典在添加和移除元素时能够提供持续时间(平均时间)的性能表现,这远远优于单纯使用列表所能达到的效果。因此,不难理解字典为何是 Python 用于实现其面向对象特性的核心数据结构。Python 还拥有特殊的语法及相关内置模块,这些模块能够赋予字典超出其他语言中简单哈希表类型所能具备的额外功能。
Item 27:优先使用 defaultdict 类而不是 setdefault 函数来处理内部状态中的缺失项
当使用非自定义字典时,有多种方法可以处理缺失的 key(参见 Item 26:"优先使用 get 方法而非 in 操作符和 KeyError 异常来处理缺失的字典键")。虽然使用 get 方法比使用 in 操作符和 KeyError 异常更好,但在某些情况下,setdefault 函数似乎是最简洁的选择。
例如,假设我想要记录我在全球各地所到访过的城市。为此,我会使用一个字典,它将国家名称映射到一个包含相应城市名称的集合实例上:
visits = {
"Mexico": {"Tulum", "Puerto Vallarta"},
"Japan": {"Hakone"},
}我可以通过使用 setdefault 函数来向集合中添加新城市,无论该国家名称是否已存在于字典中。相较于使用 get 函数和赋值表达式来实现相同功能而言,这段代码要简洁得多:
# Short
visits.setdefault("France", set()).add("Arles")
# Long
if (japan := visits.get("Japan")) is None:
visits["Japan"] = japan = set()
japan.add("Kyoto")
print(visits)
>>>
{'Mexico': {'Puerto Vallarta', 'Tulum'},
'Japan': {'Kyoto', 'Hakone'},
'France': {'Arles'}}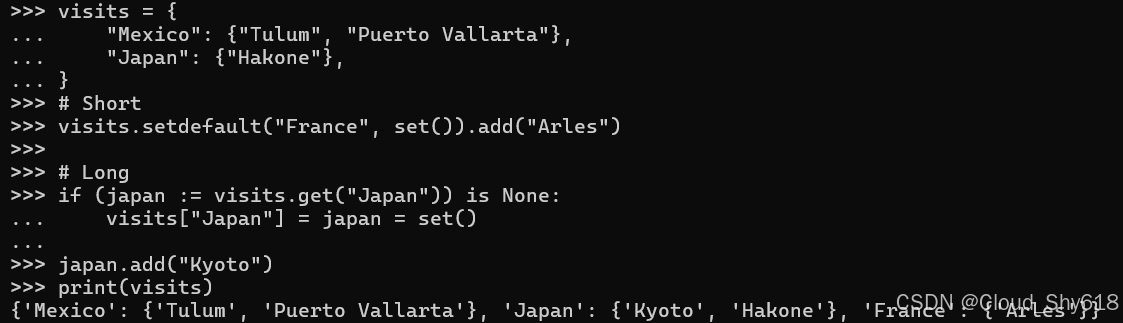
那么,当您无法控制所访问字典的创建情况时,情况会怎样呢?这通常发生在您使用字典实例来跟踪对象内部状态时。在此示例中,我将上述内容封装到一个类中,并附带了一些辅助方法,用于访问存储在字典中的动态内部状态:
class Visits:
def __init__(self):
self.data = {}
def add(self, country, city):
city_set = self.data.setdefault(country, set())
city_set.add(city)这一新类隐藏了调用 setdefault 函数时所需正确参数的复杂性,并为程序员提供了一个更为友好的接口:
visits = Visits()
visits.add("Russia", "Yekaterinburg")
visits.add("Tanzania", "Zanzibar")
print(visits.data)
>>>
{'Russia': {'Yekaterinburg'}, 'Tanzania': {'Zanzibar'}}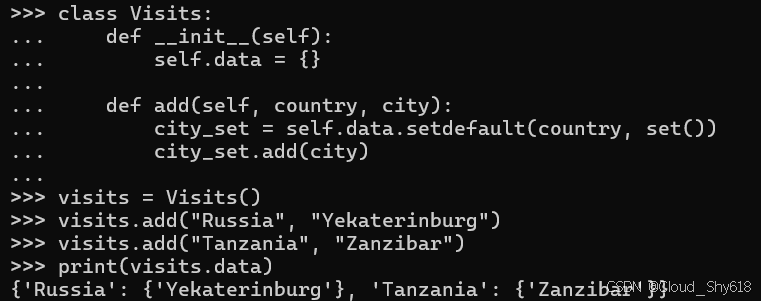
然而,Visits.add 方法的实现方式并不理想。setdefault 函数的命名仍令人困惑,这令新读者更难立即理解当前正在发生的情况。此外,这种实现方式并不高效,因为它每次调用时都会创建一个新的 set 实例,而无论所给定的国家是否已存在于数据字典中。
幸运的是,来自标准库模块 collections 中的 defaultdict 类简化了这一常见用例的处理过程,它会自动在某个键不存在时存储一个默认值。你所需要做的只是提供一个函数,每当遇到某个键缺失的情况时,该函数便会返回用于替代的默认值(请参阅 Item 48:"接受函数而非类来处理简单接口"的一个示例)。在此处,我将重写 Visits 类以使用 defaultdict:
from collections import defaultdict
class Visits:
def __init__(self):
self.data = defaultdict(set)
def add(self, country, city):
self.data[country].add(city)
visits = Visits()
visits.add("England", "Bath")
visits.add("England", "London")
print(visits.data)
>>>
defaultdict(<class 'set'>, {'England': {'Bath', 'London'}})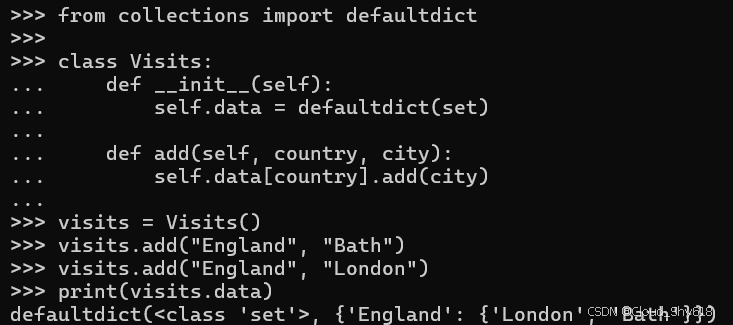
现在,add 的实现方式既简洁又高效。代码可以假定对 data 字典中任何键的访问始终都会导致一个已存在的 set 实例。不会分配多余的 set 实例,而如果 add 方法被调用大量次数的话,这种做法可能会造成高昂的成本。
对于这种情况,使用 defaultdict 类比使用 setdefault 函数好得多(参见 Item 29:"组合类而不是深度嵌套字典、列表和元组" 作为另一个示例)。在某些情况下,defaultdict 仍然无法解决您的问题,但 Python 中还有更多工具可以解决这些限制(请参阅 Item 28:"了解如何使用 __missing__ 构造键相关默认值" 和 Item 57:"从 Collections.abc 类继承自定义容器类型"以及 collections.Counter 内置类)。
注意:
- 如果你正打算创建一个字典来管理一组任意的可能键值对,如果契合你的问题需求,你应该优先选用来自内置模块 collections 中的 defaultdict 类。
- 如果有一份包含任意键值的字典给到你,而你对其创建过程并无控制权,那么你应该优先使用 get 方法来访问其中的元素。不过,在少数情况下,考虑使用 setdefault 方法可能会使代码更为简洁,且默认对象的分配成本也相对较低,这也是一个值得考虑的选择。
Item 28:了解如何使用 __missing__ 来构建依赖于键的默认值
在某些特定情况下处理丢失的键时,内置 dict 类型的 setdefault 函数会导致代码更短(请参阅 Item 26)。 对于许多这样的情况,更好的工具是来自 collections 内置模块的 defaultdict 类(请参阅 Item 27)。然而,有时 setdefault 和 defaultdict 都不合适。
例如,假设我正在编写一个程序,用于在文件系统中管理社交网络的个人资料图片。我需要一个字典来映射个人资料图片的路径名与打开的文件句柄之间的对应关系,以便我能够按需读取和写入这些图像。在此处,我通过使用一个普通的 dict 实例并借助 get 方法以及一个赋值表达式(参见 Item 8:"使用赋值表达式防止重复")来查找是否存在相应的键来实现这一目标:
pictures = {}
path = "profile_1234.png"
if (handle := pictures.get(path)) is None:
try:
handle = open(path, "a+b")
except OSError:
print(f"Failed to open path {path}")
raise
else:
pictures[path] = handle
handle.seek(0)
image_data = handle.read()当文件句柄已在字典中存在时,这段代码仅执行一次字典访问操作。若文件句柄不存在,则通过 get 方法进行一次字典访问,随后会在 try/except 语句的 else 子句中进行赋值(参见 Item 80:"充分利用 try/except/else/finally 中的每个块")。调用 read 方法的操作与调用 open 并处理异常的代码明显是分开的。
尽管可以使用 in 运算符或 KeyError 处理方法来实现相同的功能逻辑,但这些方法需要更多的字典访问操作和嵌套层级。考虑到这些其他方法能够奏效,你或许也会认为 setdefault 方法同样能够发挥作用:
try:
handle = pictures.setdefault(path, open(path, "a+b"))
except OSError:
print(f"Failed to open path {path}")
raise
else:
handle.seek(0)
image_data = handle.read()这段代码有很多问题。 即使路径已存在于字典中,始终会调用用于创建文件句柄的 open 内置函数。这会导致额外的文件句柄可能与同一程序中现有的打开句柄发生冲突。 异常可能由 open 调用引发并需要处理,但可能无法将它们与同一行上的 setdefault 调用引发的异常区分开来(这对于其他类似字典的实现是可能的;请参阅 Item 57:"从 Collections.abc 继承自定义容器类型的类")。
如果你正试图管理内部状态的话,你可能会做出的另一个假设是,可以使用 defaultdict 来跟踪这些用户资料图片。在此处,我尝试实现了与之前相同的逻辑,但这次采用了辅助函数和 defaultdict 类:
from collections import defaultdict
def open_picture(profile_path):
try:
return open(profile_path, "a+b")
except OSError:
print(f"Failed to open path {profile_path}")
raise
pictures = defaultdict(open_picture)
handle = pictures[path]
handle.seek(0)
image_data = handle.read()
>>>
Traceback ...
TypeError: open_picture() missing 1 required positional argument: 'profile_path'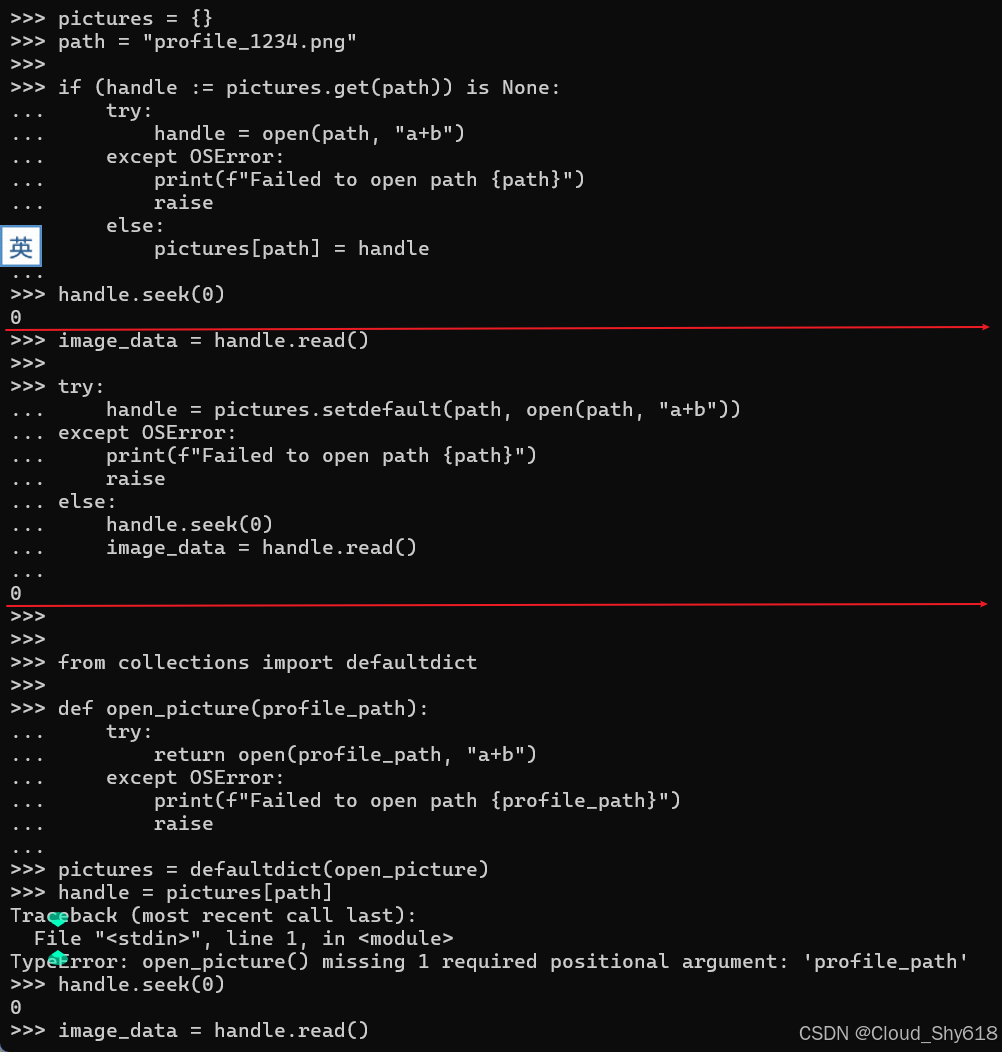
问题在于 defaultdict 本以为其构造函数所传递的函数无需任何参数。这意味着调用辅助函数 defaultdict 并不知道所访问的具体键是什么,这妨碍了我调用 open 的能力。在这种情况下,setdefault 和 defaultdict 都未能满足我的需求。
幸运的是,这种情况很常见,Python 有另一个内置的解决方案。您可以对 dict 进行子类化并实现 __missing__ 特殊方法来添加处理缺失键的自定义逻辑。在这里,我通过定义一个新类来实现此目的,该类利用上面定义的相同 open_picture 辅助方法:
class Pictures(dict):
def __missing__(self, key):
value = open_picture(key)
self[key] = value
return value
pictures = Pictures()
handle = pictures[path]
handle.seek(0)
image_data = handle.read()当图片【路径】字典访问器发现路径键并未存在于字典中时,便会调用 __missing__ 方法。该方法必须为该键创建新的默认值,并将其插入到字典中,然后将结果返回给调用者。同一路径的后续访问将不会调用 __missing__,因为相应的项已经存在(类似于 __getattr__ 的行为;请参阅 Item 61:"对惰性属性使用 __getattr__、__getattribute__ 和 __setattr__")。
注意:
- 当创建默认值时,dict 的 setdefault 方法不适合计算成本较高或可能引发异常。
- 传递给 defaultdict 的函数不能需要任何参数,这使得默认值不可能依赖于正在访问的键。
- 您可以使用
__missing__方法定义自己的 dict 子类,以便构造确定知道正在访问哪个键的默认值。
Item 29:组合使用类而不是深度嵌套字典、列表和元组
Python 的内置字典类型非常适合在对象的生命周期内维护动态内部状态。我所说的动态是指您需要对一组意外的标识符进行簿记的情况。例如,假设我想记录一组事先不知道姓名的学生的成绩。我可以定义一个类来将姓名存储在字典中,而不是为每个学生使用预定义的属性:
class SimpleGradebook:
def __init__(self):
self._grades = {}
def add_student(self, name):
self._grades[name] = []
def report_grade(self, name, score):
self._grades[name].append(score)
def average_grade(self, name):
grades = self._grades[name]
return sum(grades) / len(grades)使用该类很简单:
book = SimpleGradebook()
book.add_student("Isaac Newton")
book.report_grade("Isaac Newton", 90)
book.report_grade("Isaac Newton", 95)
book.report_grade("Isaac Newton", 85)
print(book.average_grade("Isaac Newton"))
>>>
90.0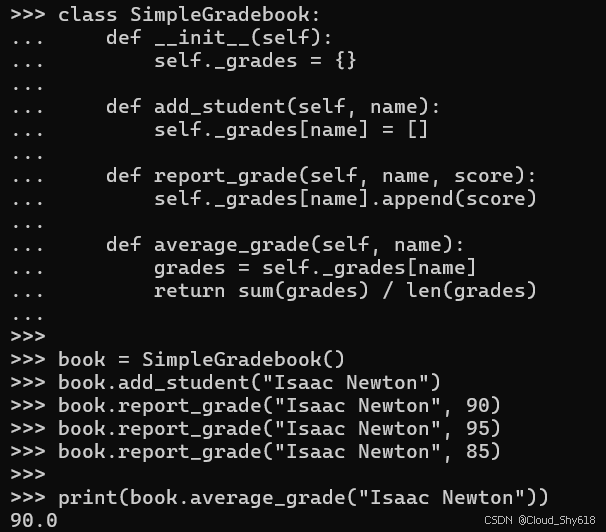
字典、列表、元组和集合非常容易使用,以至于存在导致您编写脆弱代码的危险。例如,假设我想扩展 Simple Gradebook 类来保留按科目列出的成绩列表,而不仅仅是总体成绩。我可以通过更改 _grades 字典将学生姓名(其键)映射到另一个字典(其值)来做到这一点。最里面的字典将把科目(它的键)映射到成绩列表(它的值)。在这里,我通过使用内部字典的 defaultdict 实例来处理缺失的主题来完成此操作(请参阅 Item 27:"优先使用 defaultdict 而非 setdefault 来处理内部状态中的缺失项目" 了解详情):
from collections import defaultdict
class BySubjectGradebook:
def __init__(self):
self._grades = {} # Outer dict
def add_student(self, name):
self._grades[name] = defaultdict(list) # Inner dict
def report_grade(self, name, subject, grade):
by_subject = self._grades[name]
grade_list = by_subject[subject]
grade_list.append(grade)
def average_grade(self, name):
by_subject = self._grades[name]
total, count = 0, 0
for grades in by_subject.values():
total += sum(grades)
count += len(grades)
return total / count这很简单。report_grade 和 average_grade 方法在处理多级字典时变得相当复杂,但看起来是可以管理的。使用该类仍然很简单:
book = BySubjectGradebook()
book.add_student("Albert Einstein")
book.report_grade("Albert Einstein", "Math", 75)
book.report_grade("Albert Einstein", "Math", 65)
book.report_grade("Albert Einstein", "Gym", 90)
book.report_grade("Albert Einstein", "Gym", 95)
print(book.average_grade("Albert Einstein"))
>>>
81.25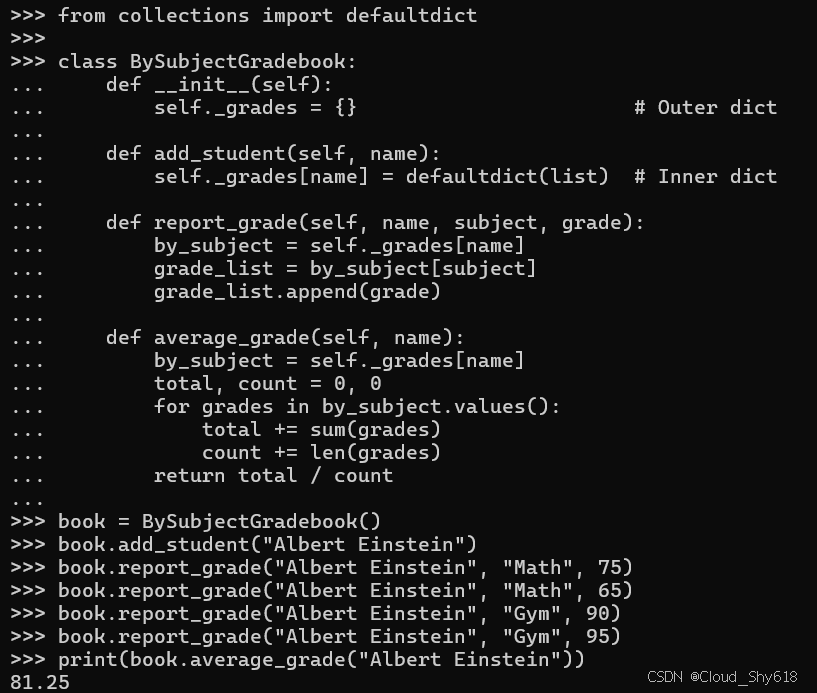
现在,想象一下需求再次发生变化。我还想跟踪每个分数相对于班级整体成绩的权重,以便期中考试和期末考试比突击测验更重要。实现此功能的一种方法是更改最里面的字典;我可以在每个键对应的值列表中使用(分数,权重)元组,而不是将科目(其键)映射到成绩列表(其值)。尽管对 report_grade 的更改看起来很简单------只需创建grade_list 保存元组实例------average_grade 方法现在有一个循环内的循环并且难以阅读:
class WeightedGradebook:
def __init__(self):
self._grades = {}
def add_student(self, name):
self._grades[name] = defaultdict(list)
def report_grade(self, name, subject, score, weight):
by_subject = self._grades[name]
grade_list = by_subject[subject]
grade_list.append((score, weight)) # Changed
def average_grade(self, name):
by_subject = self._grades[name]
score_sum, score_count = 0, 0
for scores in by_subject.values():
subject_avg, total_weight = 0, 0
for score, weight in scores: # Added inner loop
subject_avg += score * weight
total_weight += weight
score_sum += subject_avg / total_weight
score_count += 1
return score_sum / score_count使用该类也变得更加困难。目前尚不清楚位置参数中所有数字的含义:
book = WeightedGradebook()
book.add_student("Albert Einstein")
book.report_grade("Albert Einstein", "Math", 75, 0.05)
book.report_grade("Albert Einstein", "Math", 65, 0.15)
book.report_grade("Albert Einstein", "Math", 70, 0.80)
book.report_grade("Albert Einstein", "Gym", 100, 0.40)
book.report_grade("Albert Einstein", "Gym", 85, 0.60)
print(book.average_grade("Albert Einstein"))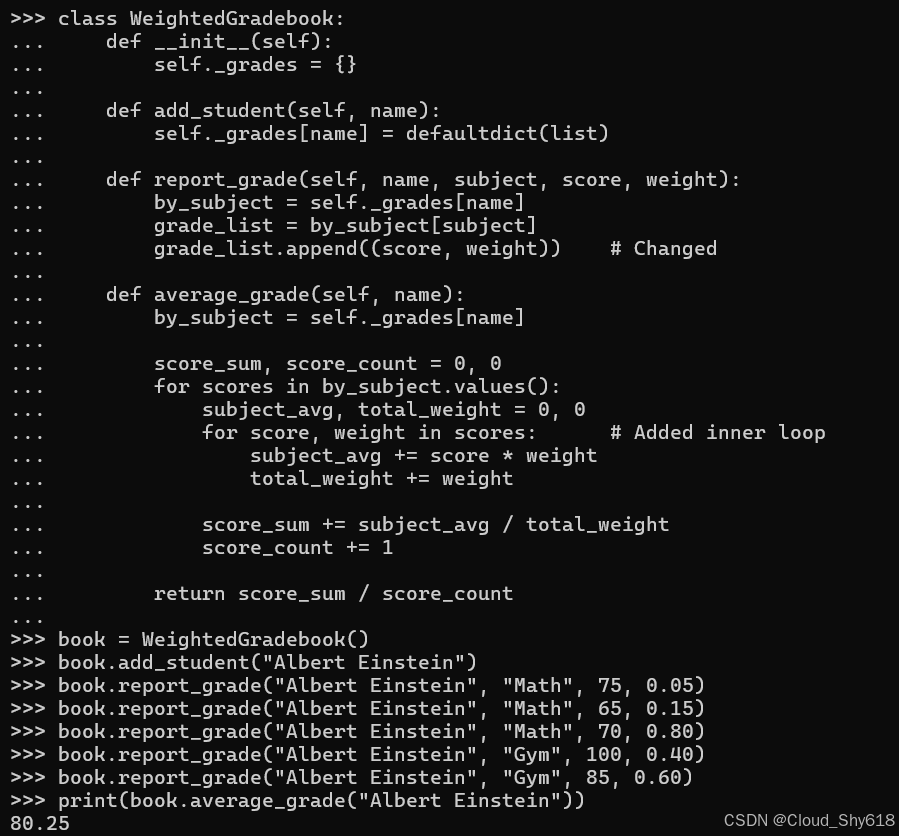
当您看到这样的复杂性时,是时候从字典、列表、元组和集合等内置类型跨越到类层次结构了。在成绩示例中,起初我不知道我需要支持加权成绩,因此创建其他类的复杂性似乎没有必要。Python 内置的字典和元组类型使继续下去变得容易,为内部簿记添加了一层又一层。但您应该避免对超过一层的嵌套执行此操作;使用包含字典的字典会使其他程序员难以阅读你的代码,并使你陷入维护噩梦(请参阅 Item 9 了解处理此问题的另一种方法)。
一旦您意识到簿记变得复杂,就将其全部分解为多个类。然后,您可以提供定义良好的接口来更好地封装您的数据。这种方法还使您能够在接口和具体实现之间创建一个抽象层。
重构类
重构的方法有很多(参见 Item 123:"考虑重构和迁移使用的警告" 作为示例)。在这种情况下,我可以开始转向依赖树底部的类:单个等级。对于如此简单的信息来说,一个类似乎太重量级了。不过,元组似乎很合适,因为成绩是不可变的。在这里,我使用(分数,体重)元组来跟踪列表中的成绩:
grades = []
grades.append((95, 0.45))
grades.append((85, 0.55))
total = sum(score * weight for score, weight in grades)
total_weight = sum(weight for _, weight in grades)
average_grade = total / total_weight
print(average_grade)我使用 _(下划线变量名,未使用变量的 Python 约定)来捕获每个年级元组中的第一个条目,并在计算 total_weight 时忽略它。这段代码的问题在于元组实例是位置性的。例如,如果我想将更多信息与成绩相关联,例如老师的一组笔记,我需要重写二元组的每个用法,以意识到现在存在三个项目而不是两个,这意味着我需要使用 _further 来忽略某些索引:
grades = []
grades.append((95, 0.45, "Great job"))
grades.append((85, 0.55, "Better next time"))
total = sum(score * weight for score, weight, _ in grades)
total_weight = sum(weight for _, weight, _ in grades)
average_grade = total / total_weight
print(average_grade)这种将元组延伸得越来越长的模式类似于加深字典的层数。一旦您发现自己的长度超过了二元组,就该考虑另一种方法了。dataclasses 内置模块正是我在这种情况下所需要的:它让我可以轻松地定义一个小的不可变类来存储属性中的值(请参阅 Item 56:"首选使用数据类创建不可变对象"):
from dataclasses import dataclass
@dataclass(frozen=True)
classGrade:
score: int
weight: float接下来,我可以编写一个类来表示包含一组成绩实例的单个主题:
class Subject:
def __init__(self):
self._grades = []
def report_grade(self, score, weight):
self._grades.append(Grade(score, weight))
def average_grade(self):
total, total_weight = 0, 0
for grade in self._grades:
total += grade.score * grade.weight
total_weight += grade.weight
return total / total_weight然后,我编写一个类来保存单个学生正在学习的一组科目:
class Student:
def __init__(self):
self._subjects = defaultdict(Subject)
def get_subject(self, name):
return self._subjects[name]
def average_grade(self):
total, count = 0, 0
for subject in self._subjects.values():
total += subject.average_grade()
count += 1
return total / count最后,我为所有学生编写一个容器,通过他们的名字动态键入:
class Gradebook:
def __init__(self):
self._students = defaultdict(Student)
def get_student(self, name):
return self._students[name]这些类的行数几乎是以前实现大小的两倍。但这段代码更容易阅读。驱动类的示例也更清晰且更具可扩展性:
book = Gradebook()
albert = book.get_student("Albert Einstein")
math = albert.get_subject("Math")
math.report_grade(75, 0.05)
math.report_grade(65, 0.15)
math.report_grade(70, 0.80)
gym = albert.get_subject("Gym")
gym.report_grade(100, 0.40)
gym.report_grade(85, 0.60)
print(albert.average_grade())
>>>
80.25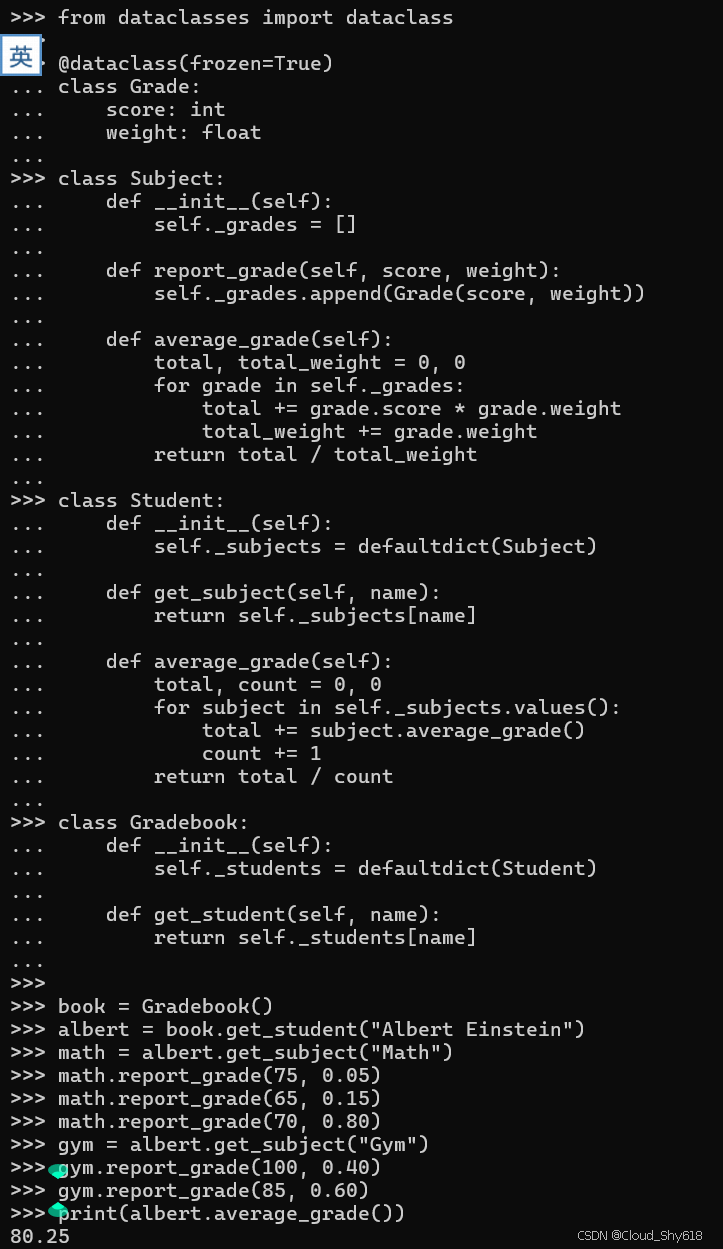
还可以编写向后兼容的方法来帮助将旧 API 样式的使用迁移到新的对象层次结构。
注意:
- 避免使用字典、长元组或其他内置类型的复杂嵌套值来创建字典。
- 在需要完整类的灵活性之前,请使用 dataclasses 内置模块作为轻量级、不可变的数据容器。
- 当内部状态字典变得复杂时,将簿记代码移至使用多个类。