前言
在前两期内容中,我们系统学习了遥感影像全流程预处理 与人工目视解译判读体系 。目视解译依托从业者经验完成地物识别,具备判读直观、边界精准的优势,但也存在效率低下、主观偏差大、难以规模化作业等短板,无法满足当下大范围遥感监测、长时序动态分析的工程需求。
在深度学习技术普及之前,传统机器学习算法 凭借低算力依赖、可解释性强、小样本适配 等特性,成为遥感影像自动分类的主流技术方案。其中 支持向量机(SVM) 与 随机森林(Random Forest) 更是行业标杆算法,至今仍是本科毕业设计、期刊论文、小型工程项目中使用率最高的分类基线模型。
不同于深度学习的端到端自动特征学习,传统机器学习依赖人工特征工程,通过提取影像光谱、纹理、遥感指数等多维特征实现像素级分类。本期将完整拆解:两类技术路线的核心差异、遥感影像特征构建方法、SVM与随机森林分步实操、遥感领域专属精度评价体系,全程搭配落地代码与优化思路,零基础也可复现实验结果。
一、传统机器学习 VS 深度学习 遥感解译核心差异
在开展实验前,首先厘清两大技术路线的适用场景、原理区别与优劣势,根据自身数据条件、硬件配置、项目需求合理选型。
| 对比维度 | 传统机器学习(SVM/随机森林) | 深度学习(U-Net/YOLO等) |
|---|---|---|
| 特征来源 | 人工设计特征(光谱、纹理、遥感指数) | 网络自动挖掘深层特征 |
| 样本需求 | 少量标记样本即可训练 | 依赖大规模标注数据集 |
| 硬件要求 | 仅需CPU,普通电脑即可运行 | 建议GPU加速,大模型显存要求高 |
| 训练速度 | 极速,单景影像数秒完成训练 | 训练周期长,动辄数小时/数天 |
| 可解释性 | 特征、分类逻辑清晰,结果易解读 | 黑盒模型,特征逻辑难以溯源 |
| 适用场景 | 小范围分类、对比实验、论文基线、快速出图 | 复杂场景、精细化地物提取、大规模工程落地 |
选型建议
- 样本数量少、硬件配置一般、仅需完成基础地物分类:优先选择 随机森林 / SVM;
- 地物类型复杂、存在大量细碎目标、拥有充足标注数据与GPU设备:优先选择深度学习模型。
二、遥感影像核心特征体系构建
特征是机器学习分类的核心载体,特征质量直接决定分类精度上限 。遥感影像分类主流使用光谱特征+纹理特征组合方案,部分场景可叠加植被、水体、建筑等专题遥感指数,进一步区分同谱异物、同物异谱难题。
2.1 光谱特征
光谱特征是遥感影像最本质的判别依据,由不同地物对电磁波的反射、吸收特性决定。
- 基础构成:多波段原始像素灰度值,单波段、多波段组合均可作为输入特征;
- 拓展应用:衍生各类遥感专题指数,典型代表:
- NDVI 归一化植被指数:区分植被与非植被区域;
- NDWI 归一化水体指数:精准提取水体,区分水体与阴影;
- NDBI 归一化建筑指数:快速识别城镇建设用地。
2.2 纹理特征
单纯依靠光谱特征极易出现同谱异物问题(例如阴影与水体、裸土与低矮建筑色调相近,难以区分)。纹理描述地物表面的空间分布规律、粗糙程度,是弥补光谱缺陷的关键。
本次实操选用工程中最常用的两类纹理指标:
- 灰度均值:反映局部区域整体亮度;
- 灰度方差:反映局部区域像素离散程度,表征纹理粗糙与否。
通过滑动窗口 逐像素遍历整图,提取邻域纹理信息,让模型兼顾像素灰度与空间形态。

三、SVM & 随机森林 地物分类完整实操
3.1 整体技术流程
标准遥感机器学习分类全链路:
影像预处理 → 多维特征融合 → 训练样本采集 → 模型训练与验证 → 全域影像预测 → 结果输出
3.2 环境依赖安装
执行以下命令安装所需依赖库,适配 Windows / Linux 全平台:
bash
pip install numpy rasterio opencv-python scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn3.3 完整可运行代码
代码实现功能:影像读取、光谱+纹理特征提取、样本划分、SVM分类、随机森林分类、全图预测,可直接替换路径运行。
python
import rasterio
import numpy as np
import cv2
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# ===================== 【参数配置区 - 仅修改此处】 =====================
# 待分类遥感影像路径(支持tif格式)
IMAGE_PATH = r"校正后遥感影像.tif"
# 纹理提取滑动窗口大小,建议取值 3 / 5 / 7
TEXTURE_WINDOW = 5
# 训练样本数量,根据影像大小调整
SAMPLE_NUM = 3000
# 地物分类类别数
CLASS_NUM = 4
# =====================================================================
def extract_texture(gray_img, win_size):
"""
提取纹理特征:局部均值 + 局部方差
:param gray_img: 单波段灰度影像
:param win_size: 滑动窗口尺寸
:return: 拼接后的纹理特征矩阵
"""
# 计算局部均值
mean_feat = cv2.blur(gray_img, (win_size, win_size))
# 计算局部方差 Var = E(X²) - [E(X)]²
square_mean = cv2.blur(np.square(gray_img), (win_size, win_size))
var_feat = square_mean - np.square(mean_feat)
# 特征拼接
texture_combined = np.dstack([mean_feat, var_feat])
return texture_combined
def build_total_feature(raster_data):
"""
融合光谱特征 + 纹理特征,构建全局特征矩阵
:param raster_data: 原始多波段影像 (C, H, W)
:return: 二维特征矩阵 (像素总数, 特征维度)
"""
# 维度转换 (C, H, W) → (H, W, C)
h, w = raster_data.shape[1], raster_data.shape[2]
spec_feat = np.transpose(raster_data, (1, 2, 0))
# 生成灰度图,用于提取纹理
gray = np.mean(spec_feat, axis=-1)
# 提取纹理特征
tex_feat = extract_texture(gray, TEXTURE_WINDOW)
# 光谱、纹理特征拼接
total_feat = np.concatenate([spec_feat, tex_feat], axis=-1)
# 转为二维矩阵:(H*W, 特征数),适配机器学习输入
total_feat_flat = total_feat.reshape(-1, total_feat.shape[-1])
return total_feat_flat, h, w
if __name__ == "__main__":
# 1. 读取遥感影像
with rasterio.open(IMAGE_PATH) as src:
img_data = src.read()
profile = src.profile # 保存影像地理信息,用于后续保存结果
# 2. 构建全局特征矩阵
all_features, height, width = build_total_feature(img_data)
print(f"✅ 特征构建完成,总像素数:{height * width}")
# 3. 模拟训练样本(实际项目替换为矢量样本点/标注样本)
# X:样本特征 Y:样本标签
sample_idx = np.random.choice(len(all_features), SAMPLE_NUM, replace=False)
X_sample = all_features[sample_idx]
y_sample = np.random.randint(0, CLASS_NUM, size=SAMPLE_NUM)
# 4. 划分训练集 & 测试集(8:2划分)
X_train, X_test, y_train, y_test = train_test_split(
X_sample, y_sample, test_size=0.2, random_state=42
)
# ===================== SVM 模型训练与预测 =====================
print("\n----- 开始训练 SVM 分类模型 -----")
svm_model = SVC(kernel="rbf", random_state=42)
svm_model.fit(X_train, y_train)
pred_svm_test = svm_model.predict(X_test)
# 全图预测
pred_svm_full = svm_model.predict(all_features).reshape(height, width)
# ===================== 随机森林 模型训练与预测 =====================
print("----- 开始训练 随机森林 分类模型 -----")
rf_model = RandomForestClassifier(n_estimators=120, random_state=42)
rf_model.fit(X_train, y_train)
pred_rf_test = rf_model.predict(X_test)
# 全图预测
pred_rf_full = rf_model.predict(all_features).reshape(height, width)
print("\n✅ 两类模型分类预测全部完成!")实操补充说明
- 样本替换 :代码中为模拟随机样本,正式项目可结合
geopandas读取SHP矢量样本点,提取对应像素标签; - 参数调优 :SVM可调整核函数、惩罚系数;随机森林可调整决策树数量
n_estimators; - 结果保存 :可基于
rasterio将分类结果写入TIFF文件,保留原始坐标与投影信息。
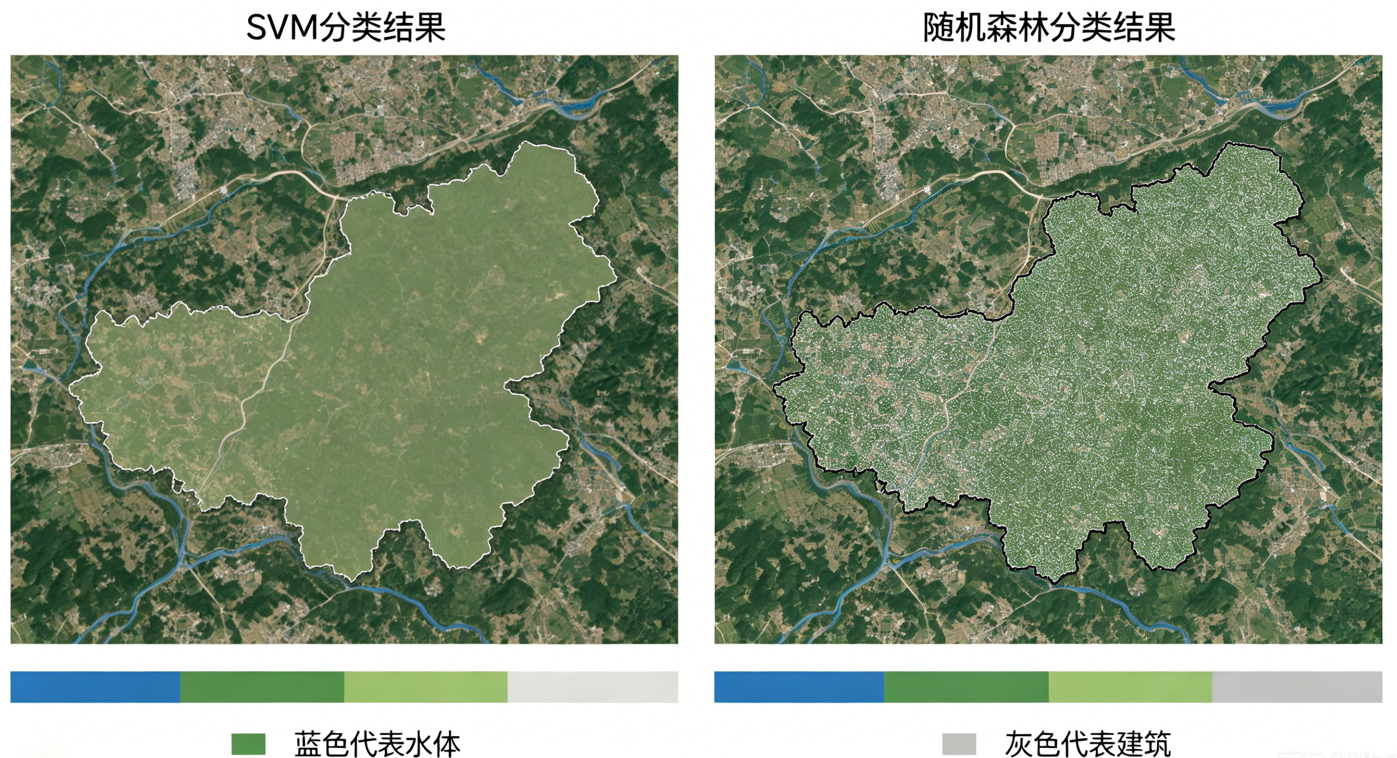
算法分类结果对比图
四、遥感专用精度评价体系解读
分类结果可视化仅能做定性判断,量化精度指标 是论文、项目验收的硬性要求。遥感领域通用三大评价指标:混淆矩阵、总体精度(OA)、Kappa系数,下文结合原理+代码完整讲解。
4.1 混淆矩阵 (Confusion Matrix)
混淆矩阵是分类结果的全景统计表,矩阵行代表真实地物类别,列代表模型预测类别。
- 核心作用:直观查看各类地物错分、漏分情况,快速定位混分严重的地物(如水影与阴影、耕地与裸土);
- 应用价值:针对性优化特征、补充样本,解决类别混淆问题。
4.2 总体精度 OA (Overall Accuracy)
所有像素中分类正确的像素占总像素的比例,反映模型整体分类效果,数值越接近1,整体精度越高。
4.3 Kappa 系数
遥感分类核心权威指标,也是期刊、毕设最看重的评价标准。该指标剔除了随机分类带来的正确率干扰,客观评价模型实际分类能力。
- 评价分级(行业通用标准):
- Kappa ≥ 0.80:分类效果优秀,结果可靠;
- 0.60 ≤ Kappa < 0.80:分类效果良好,可满足常规需求;
- Kappa < 0.60:分类误差较大,需优化特征、样本或模型参数。
4.4 精度评价完整代码
在上述分类代码后追加以下代码,自动计算并打印全部精度指标:
python
from sklearn.metrics import confusion_matrix, accuracy_score, cohen_kappa_score
def calculate_evaluation(y_true, y_pred):
"""统一计算混淆矩阵、OA、Kappa系数"""
cm = confusion_matrix(y_true, y_pred)
oa = accuracy_score(y_true, y_pred)
kappa = cohen_kappa_score(y_true, y_pred)
print("=" * 40)
print("混淆矩阵:")
print(cm)
print(f"总体精度 OA:{oa:.4f}")
print(f"Kappa 系数:{kappa:.4f}")
print("=" * 40)
# 分别评估 SVM 与 随机森林
print("【SVM 模型精度评价】")
calculate_evaluation(y_test, pred_svm_test)
print("\n【随机森林 模型精度评价】")
calculate_evaluation(y_test, pred_rf_test) 精度指标解读示意图
精度指标解读示意图
五、算法对比 & 精度优化实战技巧
5.1 SVM 与 随机森林 算法特性总结
-
支持向量机(SVM)
- 优势:高维特征适配性强、小样本场景稳定性佳;
- 短板:大尺度影像预测速度慢、参数对分类结果影响大、多类别场景表现一般;
- 适配场景:地物类别少、样本稀缺的小型区域分类。
-
随机森林(Random Forest)
- 优势:抗过拟合能力强、运算速度快、多类别分类表现均衡、鲁棒性突出;
- 短板:极端复杂纹理区域精度略逊于SVM;
- 适配场景:遥感分类首选基线模型,绝大多数论文、工程项目优先选用。
5.2 分类精度偏低?通用优化方案
如果出现Kappa系数偏低、地物混分严重,可从以下维度逐步调优:
- 特征层面:叠加NDVI、NDWI等遥感指数,丰富特征维度;调整纹理窗口大小,适配不同尺度地物;
- 样本层面:清洗错误标注样本,保证各类别样本数量均衡,增加典型区域样本;
- 模型层面:调整SVM核函数、随机森林决策树数量等超参数;
- 数据层面:剔除云雾、厚阴影等干扰区域,降低无效像素影响。
💬 互动答疑
你在使用传统机器学习做遥感分类时,是否遇到 Kappa系数偏低、地物严重混分、大面积错分类 等问题?
可以在评论区描述你的影像场景、地物类型与遇到的难题,我会统一整理并给出针对性的优化方案!
📌 下期预告
第9期:从机器学习到深度学习:AI遥感解译的进化逻辑
详解人工特征、机器特征、AI自动特征提取的区别、深度学习适配遥感大数据的核心原因、AI遥感三大核心任务:分类、检测、分割场景区分、新手该如何选择适合自己的解译任务模型。
--