文章目录
- HashMap特性
- 常用的相关函数
- put方法和get方法
-
- [put(K key, V value)](#put(K key, V value))
- get方法
- [底层结构(JDK 1.8+)](#底层结构(JDK 1.8+))
- [HashMap 扩容](#HashMap 扩容)
-
- [1.HashMap 扩容的时机](#1.HashMap 扩容的时机)
- 2.扩容步骤
- 线程安全
HashMap特性
基本概念,包含一下特性
- key-value
- 不可重复
常用的相关函数
| 方法 | 作用 | 时间复杂度(平均) |
|---|---|---|
| put(K key, V value) | 添加或覆盖键值对 | O(1) |
| get(Object key) | 根据 key 获取 value | O(1) |
| containsKey(Object key) | 判断 key 是否存在 | O(1) |
| containsValue(Object value) | 判断 value 是否存在(需遍历) | O(n) |
| remove(Object key) | 删除键值对 | O(1) |
| size() | 返回键值对个数 | O(1) |
| keySet() / values() / entrySet() | 获取视图集合 | O(1) |
put方法和get方法
put(K key, V value)
- 计算 hash 值:hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)
- 判断数组是否为空:如果 table == null 或长度为 0,先 resize() 初始化(默认容量 16)。
- 计算桶下标:index = (n - 1) & hash(n 为数组长度,利用 2 的幂优化)。
- 检查桶内第一个节点:
- 如果该位置为 null,直接创建新节点放入。
- 如果非 null,判断第一个节点的 hash 和 key 是否与当前相等:如果是 → 记录该节点,准备覆盖。
- 遍历链表或红黑树:
- 如果是红黑树节点,调用 putTreeVal 插入或覆盖。
- 如果是链表,遍历:
- 找到相同 key → 覆盖。
- 遍历到末尾 → 尾插法添加新节点。
- 添加后判断链表长度 > 8 → 调用 treeifyBin(内部会检查数组长度 < 64 则扩容,否则转红黑树)。
- 覆盖旧值:如果找到相同 key,替换 value,返回旧值。
- 模增加:modCount++(用于 fail-fast)。
- 判断扩容:size++ > threshold → resize()。
- 返回 null(新插入时)。
get方法
- 计算 hash:同 put 的 hash 算法。
- 定位桶:如果 table 不为空且长度 > 0,计算 index = (n - 1) & hash。
- 检查第一个节点:如果第一个节点 hash 和 key 匹配,直接返回该节点的 value。
- 遍历后续:
- 如果是红黑树,调用 getTreeNode 查找。
- 如果是链表,逐个比较 hash 和 key(用 equals),找到返回 value。
- 未找到:返回 null。
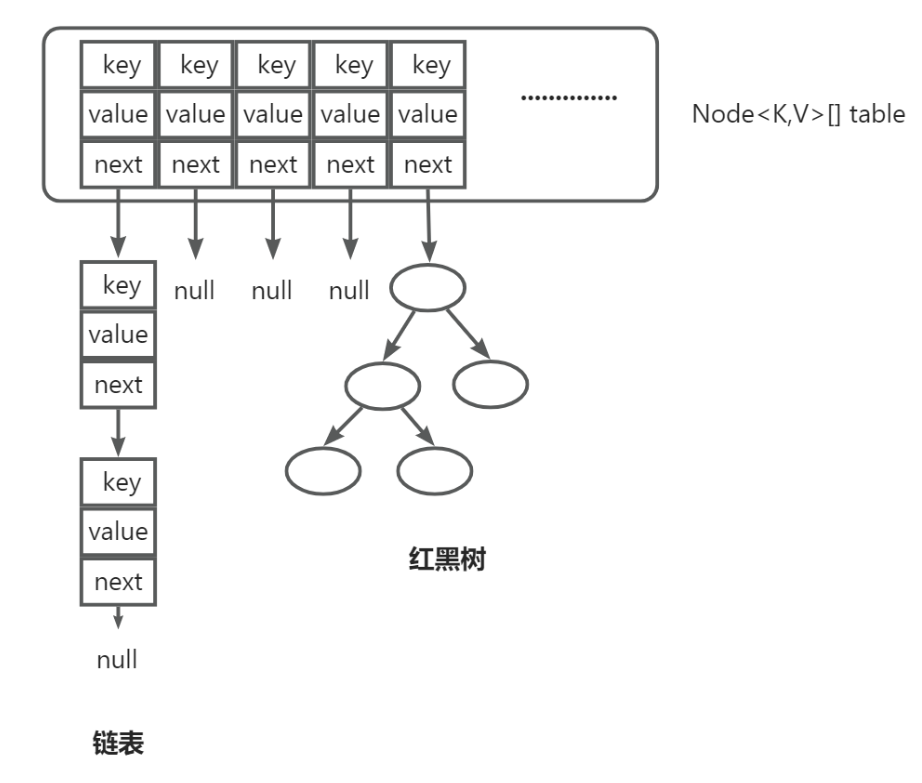
底层结构(JDK 1.8+)
1.8之前采用数组加链表的数据结构,1.8采用数组加链表加红黑树的数据结构
HashMap = 数组 + 链表 + 红黑树(JDK 1.8+)
- 数组:Node<K,V>\[\] table,每个位置称为一个桶(bucket)。
- 链表
- 当链表长度 > 8 且数组长度 ≥ 64 时,链表 → 红黑树;树节点数 < 6 时,会退化为链表。
为什么是8:源码注释里给了泊松分布的计算结果:在理想情况下(哈希随机性很好),一个桶中链表长度达到 8 的概率极低(小于千万分之一)。这说明一旦长度超过 8,往往是严重恶意的哈希冲突(比如有人故意构造相同 hashCode 的 key),此时必须用红黑树来防止性能崩溃。
退化阈值是 6 而不是 8? 避免频繁转换,留 2 的余量,防止在 7/8 之间反复切换造成性能抖动。
为什么是64 :64 是经验值:确保数组足够大,再考虑树化。如果数组很小(比如桶链表长度 > 8,但数组长度 < 64 ),大量冲突可能是因为容量不够,而不是 hash 算法差。此时优先扩容(resize)来分散元素,而不是盲目树化。
HashMap 扩容
1.HashMap 扩容的时机
- size > threshold(threshold = 容量 × 负载因子,默认 0.75)
- 当某个链表长度>=8,但是数组存储的结点数size() < 64时
size 表示元素个数,即节点node个数(数据节点的个数),非数组长度
threshold = 当前数组长度 * 负载因子
2.扩容步骤
扩容分为两步
- 创建一个新的数组,长度为原数组的两倍
- 遍历所有Node节点,将旧桶中的每个元素重新计算新下标,移到新数组
- 迁移过程中,如果 Node 桶的数据结构是链表会生成 low 和 high 两条链表,是红黑树则生成 low 和 high 两颗红黑树
- 判断 high 和 low 的条件:因为新容量是旧容量的2倍,元素的hash值高位多了一位,因此通过 hash & oldCap == 0 判断放低位还是高位。结果为 0 则留在原位置(低位),结果非 0 就移到 原索引 + oldCap(高位)
- 低位链表:留在原索引(index)
- 高位链表:移到原索引 + 旧容量(index + oldCap)
- 最后替换 table 为新数组,更新 threshold。
为什么HashMap数组长度是 2 的幂?
- 第一,计算桶下标时可以用 hash & (length-1) 代替取模运算,位运算效率更高。
- 第二,扩容时容量翻倍,元素的新位置要么不变,要么在旧位置的基础上加上旧容量,通过 hash & oldCap 就能判断,不需要重新计算 hash,迁移效率极高。
- 第三,length-1 的二进制全是 1,能让 hash 值的低位充分参与散列,减少冲突。
线程安全
HashMap
Hashtable
ConcurrentHashMap