解密Palantir系列二:1.Foundry · 数据操作系统
先回答一个问题
很多公司已经有数据库、ERP、CRM、数据湖、BI、机器学习平台,为什么还需要一个 Foundry?
第一性问题不是"企业有没有数据",而是:
当业务状态变化时,企业能不能把数据、规则、模型、人员判断和外部系统操作连成一个可追溯的闭环?
大多数企业的问题不在于"没数据",而在于:
- 数据接进来了,但业务对象没有统一语言;
- 模型训练出来了,但没有稳定进入一线工作流;
- 看板能展示问题,但不能安全地发起行动;
- 行动写回了 ERP、MES、CRM,但为什么这样做、谁批准、用了哪个模型,很难复盘;
- 每个系统都有权限和日志,但跨系统的决策血缘断裂。
Foundry 要解决的就是这个断裂。
它不是把 Snowflake、Databricks、Tableau、Airflow、低代码平台简单装进一个盒子里,而是试图提供一套"企业操作层":
数据能进来,模型能运行,业务对象能被统一描述,用户能在工作流里操作,决策能被写回外部系统,并且整条链路能被治理和追溯。
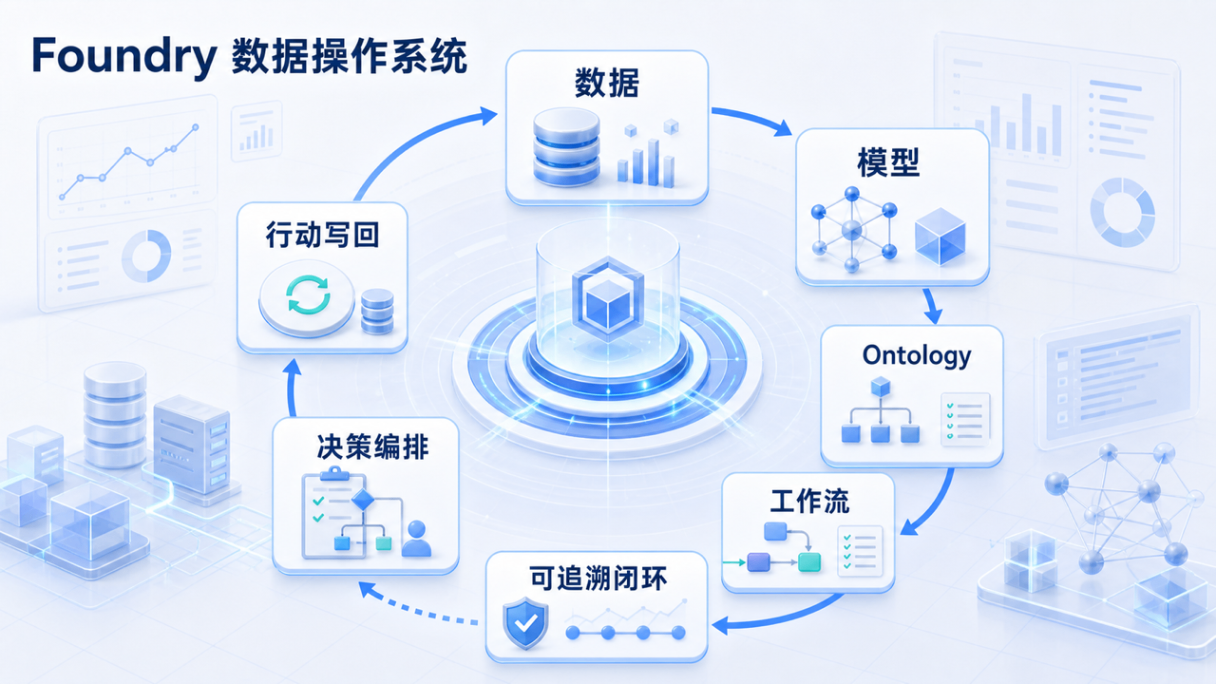
图:Foundry 的核心不是单点数据能力,而是把数据、模型、Ontology、工作流和行动写回接成闭环。
目标
- 用自己的话解释为什么 Foundry 自称是 enterprise operating system;
- 画出 Foundry 的五层架构:Data Integration、Model Integration、Ontology、Workflows、Decision Orchestration;
- 说清每一层解决的具体断裂,而不是只记产品名;
- 理解 Ontology 为什么是 Foundry 的中段脊柱;
- 用一个供应链、航空或制造案例解释 Foundry 如何把"看见问题"推进到"执行动作";
- 判断 Foundry 与现代数据栈、BI、低代码平台的根本差异。
一、从系列一到系列二
Palantir Ontology 的三层心智模型:
| 层 | 核心概念 | 回答的问题 |
|---|---|---|
| 名词层 | Object / Property / Link | 企业世界里有什么?它们如何连接? |
| 动词层 | Function / Action | 企业能计算什么?能做什么?谁能做? |
| 时间层 | Scenario / Decision Lineage / Time Travel | 如何安全试错?如何解释历史?如何形成学习? |
如果只看 Ontology,它像企业操作系统里的"语义内核"。但一个真正可运行的平台不能只有内核,还需要外围能力:
| 问题 | Foundry 需要提供的能力 |
|---|---|
| 外部系统的数据怎么进来? | 数据集成、转换、血缘、数据健康、权限传播 |
| 模型和业务规则怎么进入运营? | 模型集成、模型目标管理、业务函数绑定 |
| 业务对象怎么统一表达? | Ontology |
| 一线用户怎么真正使用? | Workshop、Slate、Object Explorer、Objects Gateway |
| 决策怎么被演练、审批、写回? | Scenario、Simulation、Action、Decision Lineage |
所以,Foundry 不是 Ontology 的替代品。更准确地说:
Foundry 是让 Ontology 真正落地运行的一整套企业操作系统。
二、Foundry 的一句话定义
Foundry 白皮书把它称为:
"Foundry is the operating system for the modern enterprise."
这里的关键词不是 system,而是 operating。Palantir 想强调的不是"我们有一个数据平台",而是业务可以在这个平台上运转。
一个普通数据平台通常回答:
- 数据在哪里?
- 数据能不能查?
- 数据能不能做分析?
Foundry 还要继续回答:
- 这些数据对应企业里的哪些业务对象?
- 哪些模型和规则可以作用在这些对象上?
- 谁有权限看、算、改?
- 业务用户如何在界面里发起动作?
- 动作写回哪些外部系统?
- 未来审计时,能不能解释当时为什么这样做?
这就是"数据平台"和"数据操作系统"的差别。
三、Foundry 的五层架构
先记住一张文字地图:
| 层级 | 英文名 | 中文理解 | 解决的断裂 |
|---|---|---|---|
| 5 | Decision Orchestration | 决策编排层 | 从分析到行动的断裂 |
| 4 | Workflows | 工作流与应用层 | 从平台到业务用户的断裂 |
| 3 | Ontology | 业务语义层 | 从数据表到业务对象的断裂 |
| 2 | Model Integration | 模型集成层 | 从离线模型到运营逻辑的断裂 |
| 1 | Data Integration | 数据集成层 | 从外部系统到可信数据资产的断裂 |
从下往上看,Foundry 是一套建设路径:
- 先把外部数据接进来;
- 再把模型、规则、算法接进来;
- 用 Ontology 把它们映射成业务对象和业务动作;
- 让业务用户通过应用和工作流使用它;
- 最后把决策编排、仿真、写回和血缘接成闭环。
从上往下看,Foundry 是一套行动路径:
- 业务用户看到一个问题;
- 在工作流里创建方案;
- 方案修改的是 Ontology 中的对象;
- 模型和规则计算方案影响;
- 数据层提供事实依据;
- 最终 Action 把被批准的决策写回外部系统。
这两条路径合起来,才是 Foundry 最核心的系统设计。
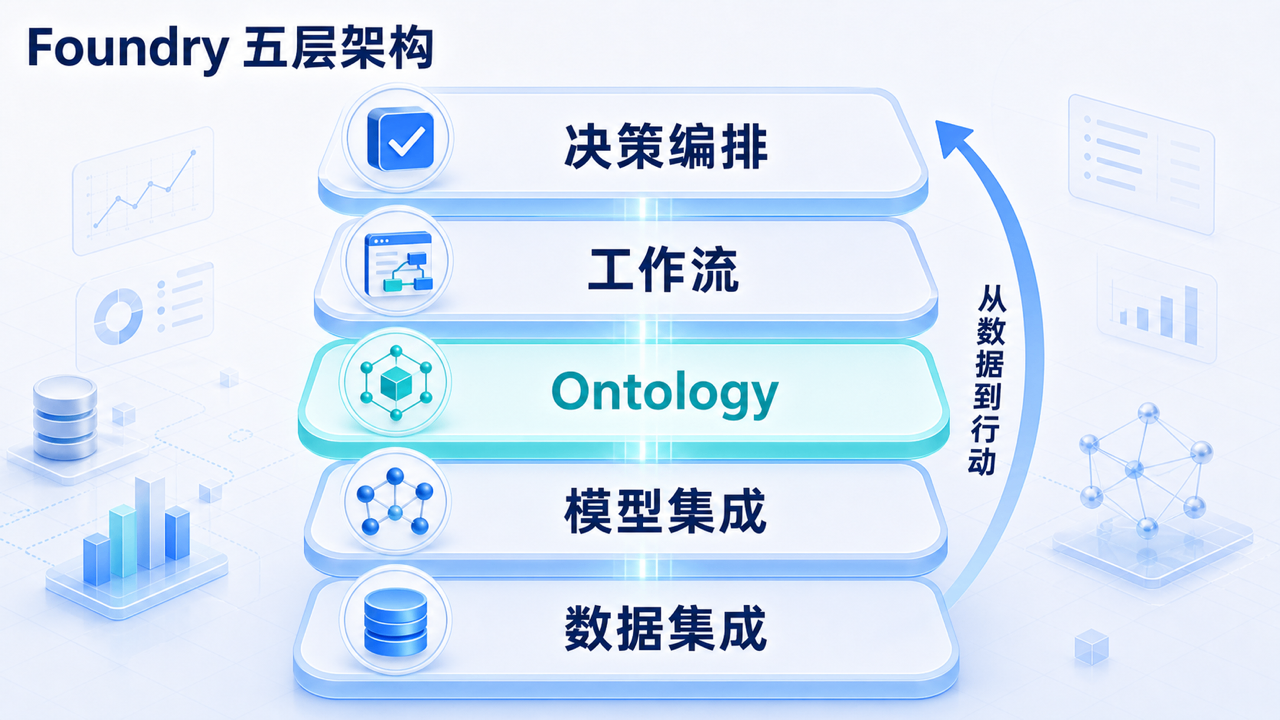
图:Foundry 五层从下到上把数据接入、模型、业务语义、应用和决策编排连起来。
四、用一个供应链场景看五层如何协同
假设一家食品制造企业遇到一个典型问题:
某种关键原料的供应商突然延迟交付 10 天。这个原料影响两个工厂、五条产线、二十多个客户订单。销售团队希望保住大客户订单,采购团队想找替代供应商,工厂担心换料会影响质量,财务团队担心临时采购成本过高。
如果企业只有 BI,看板可以告诉你:"原料缺口是多少,哪些订单受影响。"
但真正的问题是:
企业该怎么行动?
Foundry 五层在这个场景里的角色如下:
| Foundry 层 | 在供应链场景中做什么 |
|---|---|
| Data Integration | 接入 ERP 订单、WMS 库存、TMS 物流、供应商交付、质量检测和客户优先级数据 |
| Model Integration | 运行缺料预测、替代料风险评估、交付延误预测、成本影响模型 |
| Ontology | 把 Supplier、Material、Factory、ProductionLine、CustomerOrder、Shipment 建成可操作对象 |
| Workflows | 给采购、生产、销售、质量团队提供同一套操作界面 |
| Decision Orchestration | 创建多个 Scenario,比对收益和风险,审批后通过 Action 写回 ERP、排产系统和客户通知系统 |
三个候选方案可能是:
| Scenario | 方案 | 可能收益 | 主要风险 |
|---|---|---|---|
| A | 等原供应商交付 | 成本最低,质量风险低 | 大客户订单延迟 |
| B | 临时采购替代原料 | 交付风险下降 | 成本上升,质量验证压力变大 |
| C | 调整排产,优先满足高价值订单 | 关键客户影响最小 | 普通订单延期,需要销售协同 |
这不是"看板多几个筛选项"的问题,而是一个跨系统、跨部门、带风险权衡的决策问题。
Foundry 的价值就在这里:它试图让企业可以在同一套对象、权限、模型和工作流里评估方案,然后把被批准的动作写回系统,并保留完整 Decision Lineage。
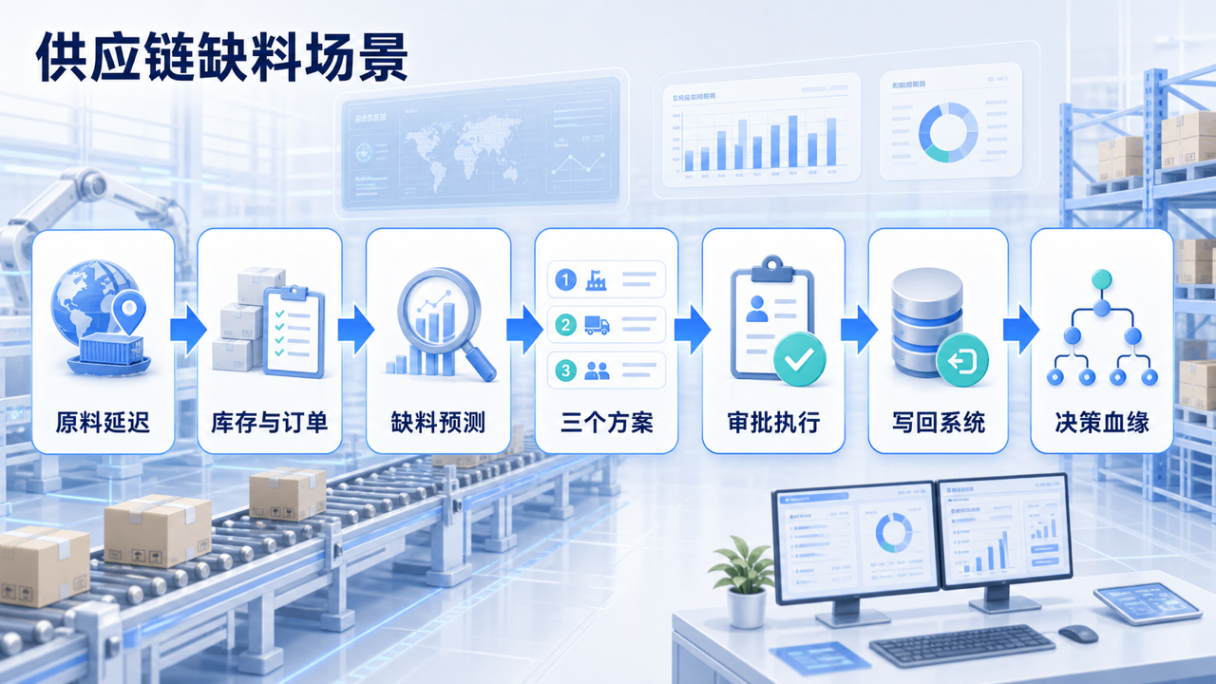
图:供应链缺料不是单纯报表问题,而是从事实、预测、方案、审批到写回的跨部门决策链。
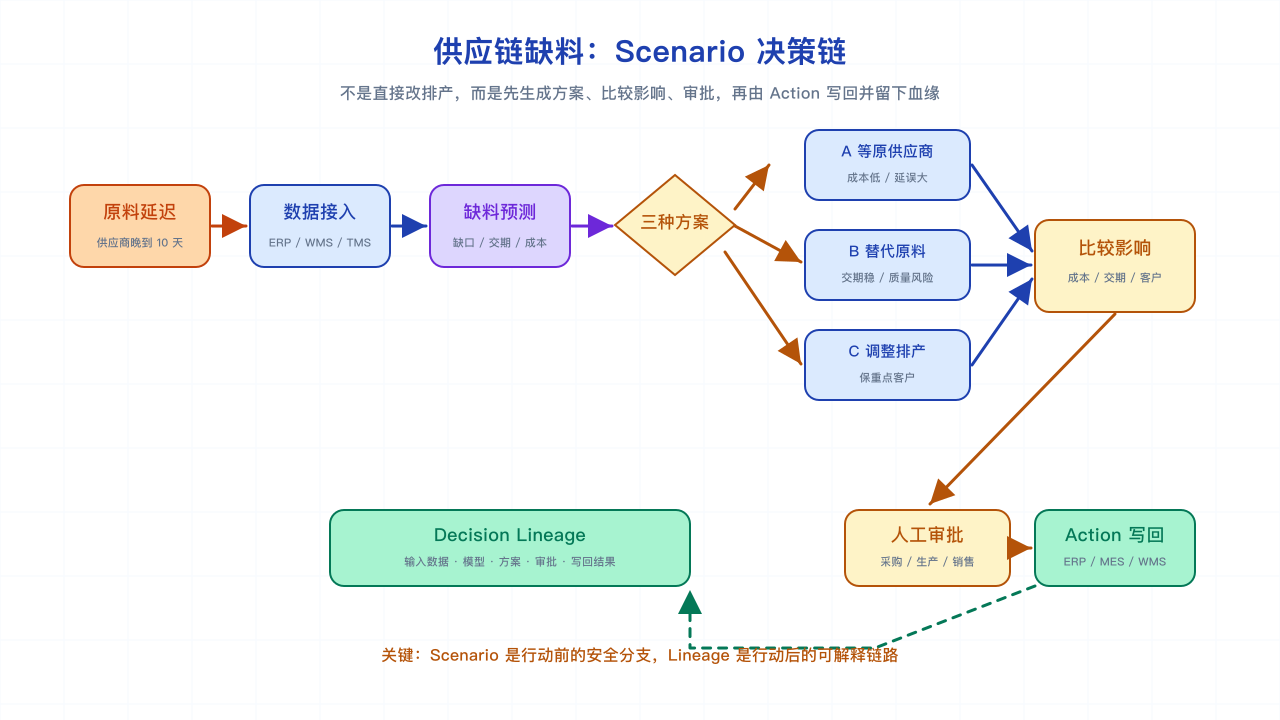
流程图:Scenario 是行动前的安全分支,Decision Lineage 是行动后的可解释链路。
五、第 1 层:Data Integration,不只是 ETL
Data Integration 的目标不是"把数据搬进湖里",而是把外部系统的数据变成可信、可治理、可追溯、可被 Ontology 使用的数据资产。
| 能力 | 初学者理解 |
|---|---|
| Data Connection | 连接数据库、文件、SaaS、流式数据、IoT、ERP、MES 等外部源 |
| Data Transformation | 清洗、转换、聚合、标准化,让原始数据变成可用数据集 |
| Pipeline Orchestration | 编排数据流水线,处理增量刷新和上下游依赖 |
| Lineage | 记录数据从哪里来、怎么变、被谁使用 |
| Data Health Monitoring | 监控数据质量,发现缺失、异常、延迟和规则违反 |
| Security | 在数据接入时就设置权限,并把权限约束传播到下游 |
很多传统数据项目会把这些能力拆散:
- 连接器归 ETL 工具管;
- 转换归 dbt 或 Spark 管;
- 调度归 Airflow 管;
- 数据质量归另一个平台管;
- 数据目录归 Catalog 管;
- 权限和审计又在安全平台里。
拆开当然能做,但代价是"每一层都知道一点,却没有一层能解释完整业务闭环"。
Foundry 的 Data Integration 不是只关心数据流,而是把数据流、血缘、健康、权限和后续 Ontology 映射放进同一套平台。这样做的意义是:当一个业务用户在上层看到某个对象、某个模型结果、某个 Action 时,平台仍然能追溯到最底层的数据来源和处理过程。
在供应链场景中,如果系统建议"改用替代原料",你必须知道:
- 替代料库存数据来自哪里;
- 供应商交付承诺是否最新;
- 质量检测数据是否完整;
- 哪些人有权查看成本和供应商价格;
- 模型用到的数据是否已经过期;
- 最终动作写回后,能不能追溯到原始数据依据。
这就是为什么数据集成层不能只做 ETL。
六、第 2 层:Model Integration,让模型进入运营
很多企业的模型停在"报告"和"Notebook"里。
数据科学家训练出一个预测模型,准确率不错,演示也漂亮。但一线业务真正决策时,仍然在 Excel、微信群、邮件和 ERP 页面之间切换。模型没有成为业务系统的一部分。
Foundry 的 Model Integration 试图解决这个问题。
| 能力 | 初学者理解 |
|---|---|
| Code Workbooks | 在 Foundry 内部写代码、做分析、开发模型 |
| External Model Integration | 把外部平台训练好的模型通过 API 或注册机制接进来 |
| Model Objectives | 围绕同一个业务目标管理多个候选模型,比较表现并推进生产化 |
| Ontology Binding | 把模型输入输出绑定到业务对象类型,而不是散落的数据表 |
最关键的是最后一项:模型要绑定到 Ontology。
如果一个模型叫 predict_material_shortage(material, factory),它不应该只是吃一堆表字段,吐出一个数字。它应该明确作用在:
Material对象;Factory对象;Supplier对象;ProductionLine对象;CustomerOrder对象。
这样,模型结果才能自然进入工作流:
- 采购经理看到某个
Material的短缺风险; - 工厂计划员看到某条
ProductionLine的停线概率; - 销售负责人看到某个
CustomerOrder的延迟风险; - 系统可以基于这些对象创建 Scenario;
- Action 可以把最终排产调整写回 ERP 或 MES。
这就是"模型集成"和"模型部署"的区别。
模型部署只回答:模型能不能上线推理?
模型集成还要回答:模型结果进入哪个业务对象?谁能看?谁能用?能触发什么动作?出了问题怎么追溯?
七、第 3 层:Ontology,Foundry 的中段脊柱
Ontology 是 Foundry 最核心的一层。它把底层数据和模型,翻译成业务用户能够理解和操作的世界。
模块 B 已经讲过,Palantir Ontology 不是哲学概念,也不是普通知识图谱。它至少包含三类东西:
| Ontology 内容 | 例子 | 作用 |
|---|---|---|
| 名词 | Object / Property / Link | 定义企业世界里有什么 |
| 动词 | Function / Action | 定义能计算什么、能改变什么 |
| 时间 | Scenario / Decision Lineage / Time Travel | 定义如何试错、追溯和学习 |
在 Foundry 里,Ontology 不是一个孤立模块,而是上下贯通:
- 向下,它连接 Dataset、模型、规则和权限;
- 向上,它支撑 Object Explorer、Quiver、Map、Workshop、Action 和 Scenario;
- 横向,它让采购、生产、销售、财务、安全和 IT 使用同一套业务语言。
以供应链为例,如果没有 Ontology,系统里可能只有这些表:
erp_po_headererp_po_itemwms_inventory_balancetms_shipment_statusmes_work_ordercrm_customer_priority
业务用户真正想问的却是:
- 哪个供应商影响了哪个客户订单?
- 哪个工厂会因为哪种原料停线?
- 哪些替代原料已经通过质量认证?
- 如果优先满足某个客户,哪些订单会被推迟?
Ontology 的作用,就是把表、字段、模型和规则翻译成:
SupplierMaterialFactoryProductionLineCustomerOrderShipmentQualityApprovalReplanProductionReserveInventory
这就是为什么它是 Foundry 的中段脊柱。
没有 Ontology,Foundry 只是更复杂的数据平台。
有了 Ontology,数据、模型、应用和动作才开始共享同一种业务语言。
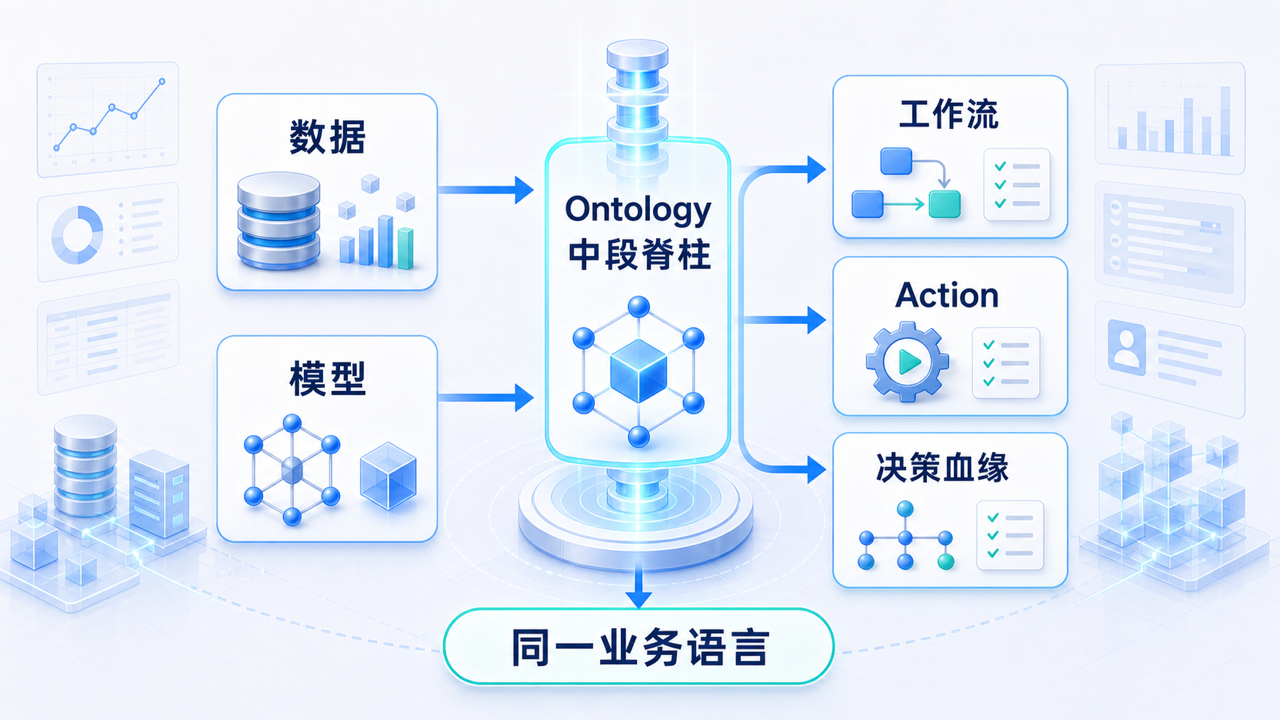
图:Ontology 是 Foundry 的中段脊柱,底层事实和模型通过它进入上层业务工作流。
八、第 4 层:Workflows,让业务用户真的能用
Foundry 不是只给数据工程师和数据科学家用的。如果平台不能进入业务用户的日常工作,它就很难成为"操作系统"。
Workflows 层解决的是"最后一公里"的应用问题。
| 组件 | 作用 |
|---|---|
| Workshop | 低代码应用构建器,基于 Ontology 快速构建业务应用 |
| Slate | 更偏前端和高级定制的应用构建能力 |
| Object Explorer | 浏览、搜索、筛选 Ontology 对象 |
| Quiver | 图表式探索和多维分析 |
| Map | 地理空间对象视图 |
| Objects Gateway | 把 Ontology 暴露给外部应用和 API |
这一层最容易被误解为"低代码"或"BI"。
但它和普通低代码、BI 的关键差异在于:
| 普通 BI / 低代码 | Foundry Workflows |
|---|---|
| 通常围绕数据表、图表或表单 | 围绕 Ontology 对象 |
| 展示和操作经常分离 | 展示、计算、Action 可以在同一对象上下文中发生 |
| 权限常常需要在应用层重做 | 继承 Foundry 的细粒度权限 |
| 写回需要额外开发 API | Action 和 writeback 是平台能力 |
| 应用之间语义可能不一致 | 应用共享同一套 Ontology |
回到供应链案例。
采购经理进入应用时,不应该看到一堆表名和字段名,而应该看到:
- 高风险
Material列表; - 每个
Material关联的Supplier、Factory、CustomerOrder; - 可选替代供应商和质量状态;
- 三个可比较 Scenario;
- 每个 Scenario 对成本、交期、客户影响和产线利用率的影响;
- 审批按钮和可执行 Action。
这才是工作流层的意义:让业务用户在统一语义中做决策,而不是让每个人在不同系统里拼碎片。
九、第 5 层:Decision Orchestration,把分析变成行动
Decision Orchestration 是 Foundry 五层里最能体现"operating"的一层。
它解决的问题是:企业不缺分析,缺的是把分析安全推进到行动。
白皮书里把这一层概括为几类能力:
| 能力 | 初学者理解 |
|---|---|
| Scenarios & Simulations | 像代码分支一样创建业务方案,在沙箱里演练 |
| Vertex | 面向关系、图谱和 what-if 的探索能力 |
| Democratizing Scenarios | 把复杂分析师场景包装成一线用户可用的操作 |
| Actions Framework | 用结构化、安全、可审计的方式把决策写回外部系统 |
这一层可以用一句话理解:
让企业在行动前先分支、仿真、比较、审批;行动后还能追溯、复盘、学习。
在供应链场景里,Decision Orchestration 应该能支撑:
- 创建
Scenario A:等待原供应商; - 创建
Scenario B:使用替代原料; - 创建
Scenario C:调整排产优先级; - 对每个 Scenario 运行成本、交期、质量、客户影响模型;
- 将复杂结果包装成业务用户能理解的比较界面;
- 经过采购、生产、质量、销售审批;
- 触发 Action 写回 ERP、MES、WMS、客户通知系统;
- 保存 Decision Lineage,记录数据、模型、审批、动作和结果。
这一步非常关键。
如果企业只能分析,不能行动,Foundry 就只是 BI 的升级版。
如果企业能行动,但不能演练、审批和追溯,那就是高风险自动化。
Foundry 的目标是在两者之间建立一条受控路径:从数据到行动,但行动不是黑箱。
十、为什么说 Foundry 像操作系统
操作系统不是因为有文件夹、窗口、按钮才叫操作系统,而是因为它管理资源、定义抽象、调度任务、控制权限,并提供应用运行环境。
把这个类比放到企业里:
| 计算机操作系统 | Foundry 中的对应 |
|---|---|
| 文件系统 | Dataset、Object、Media、文档和数据资产 |
| 进程调度 | Pipeline、Workflow、Automation、Action |
| 内存和资源管理 | 计算、存储、模型运行、数据刷新 |
| 权限系统 | 数据权限、对象权限、Action 权限、审计日志 |
| 驱动程序 | Data Connection、外部系统 API、Objects Gateway |
| 应用运行环境 | Workshop、Slate、Object Explorer、Quiver、Map |
| 系统日志 | Lineage、Decision Lineage、Audit Log |
这个类比的价值在于帮助你理解 Foundry 的定位:
- 它不只是存数据;
- 它不只是跑模型;
- 它不只是搭应用;
- 它不只是做自动化;
- 它试图提供一套让业务运行的共同底座。
但这个类比也有边界。
Foundry 不是企业所有系统的替代品。ERP、MES、CRM、WMS、TMS 仍然存在。Foundry 更像是在这些系统之上建立一层操作语义和决策编排层,让跨系统业务流程不再完全依赖人工协调。
十一、Foundry 和现代数据栈的差异
很多人会问:能不能用 Snowflake + Databricks + dbt + Airflow + Tableau + Power Apps 拼出一个 Foundry?
答案是:局部能力可以拼,整体一致性很难拼。
| 维度 | 现代数据栈常见做法 | Foundry 的目标 |
|---|---|---|
| 数据存储 | 数据湖、数仓、Lakehouse | 可连接和管理多源数据,但重点不止存储 |
| 数据转换 | dbt、Spark、Flink | 转换、血缘、权限、数据健康协同 |
| 调度编排 | Airflow、Dagster | Pipeline 和业务工作流进入同一平台上下文 |
| BI 分析 | Tableau、Looker、Power BI | 基于 Ontology 的对象探索和应用 |
| 模型管理 | MLflow、SageMaker、Vertex AI | 模型绑定业务对象,进入运营工作流 |
| 业务语义 | 常靠指标层、数据目录或人工约定 | Ontology 是一等公民 |
| 动作写回 | 额外开发 API 或 RPA | Action Framework 是核心能力 |
| 决策追溯 | 分散在日志、审批流和工单里 | Decision Lineage 贯穿数据、模型、动作和结果 |
| AI 接入 | 另建 LLM 应用层 | AIP 建在 Foundry/Ontology 之上 |
这个对比不是说现代数据栈不好。
如果一个企业只需要报表分析,现代数据栈更轻、更开放、更便宜。
Foundry 更适合另一类问题:
- 系统很多,语义混乱;
- 决策跨部门,责任链复杂;
- 模型必须进入业务操作;
- 行动需要审批、权限和审计;
- 结果需要写回多个系统;
- 失败成本高,需要 Scenario 和 Decision Lineage。
换句话说,Foundry 不是为了"看数据"而生,而是为了"用数据运营企业"而生。
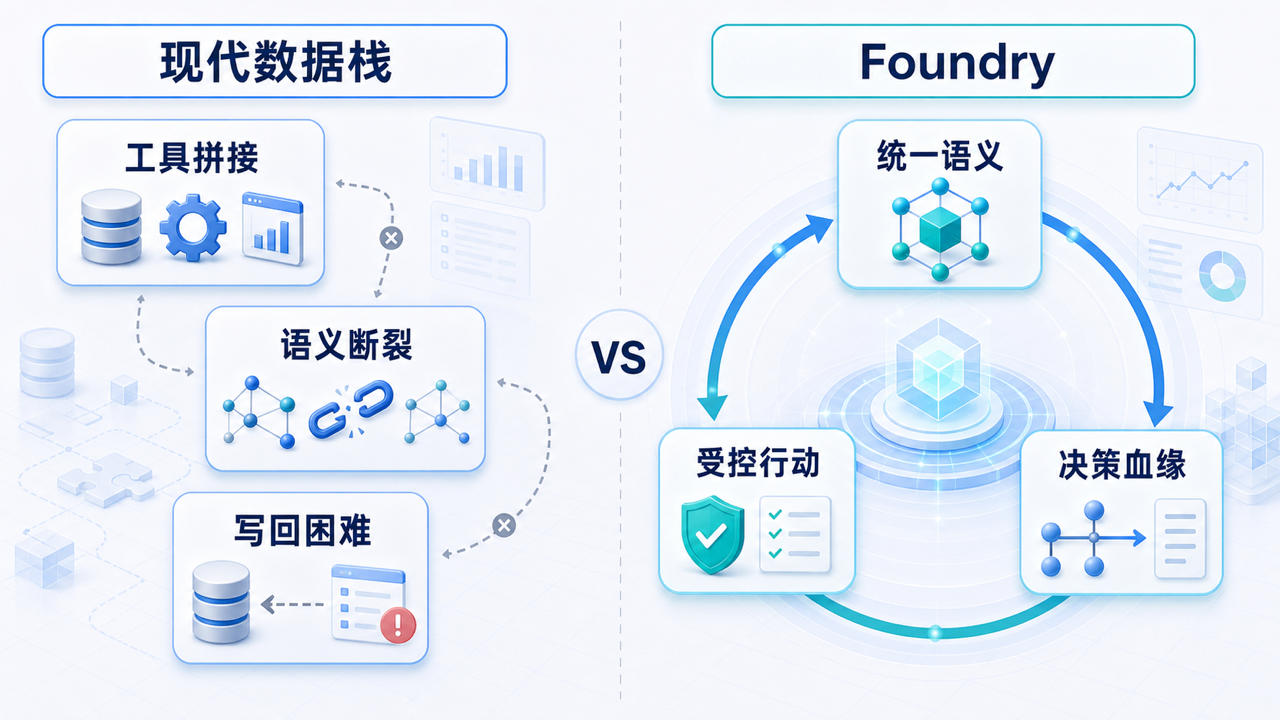
图:现代数据栈可以拼出局部能力,但 Foundry 更强调统一语义、受控行动和决策血缘。
十二、Foundry 不是这些东西
为了避免误解,可以用反面清单记住它。
| 误解 | 更准确的理解 |
|---|---|
| Foundry = 数据湖 | 数据湖只覆盖数据存储和处理的一部分 |
| Foundry = BI | BI 主要帮助看见问题,Foundry 还强调行动和写回 |
| Foundry = 低代码平台 | Workshop 是低代码能力,但底层依赖 Ontology、权限、Action 和 Lineage |
| Foundry = MDM | 它可以处理主数据问题,但不是只做主数据管理 |
| Foundry = 知识图谱 | Ontology 不只是关系图,还包含 Function、Action、Scenario、Lineage |
| Foundry = LLM 平台 | AIP 才是 LLM 编排层,但 AIP 依赖 Foundry 的业务底座 |
如果你把 Foundry 当成单点工具,就会觉得每一层都能找到替代品。
但 Palantir 真正要卖的是层与层之间的一致性:数据、模型、对象、应用、动作、权限、血缘都围绕同一套业务语义运行。
十三、客户案例应该怎么看
公开材料中经常出现不同客户的 Foundry / AIP 应用,例如矿山设备健康、电网计划、供应链运营、金融市场分析、原材料再平衡、铁路网络健康、前线操作等。
初学者容易困惑:
为什么同一个 Foundry,在每个客户那里长得完全不一样?
原因很简单:操作系统本来就不是最终应用。
同一个手机操作系统上可以运行地图、支付、相机、聊天、办公。它们界面不同,但共享权限、通知、文件、网络、身份和应用运行框架。
Foundry 也是类似逻辑:
| 行业场景 | 表面上看到的应用 | 背后的共同模式 |
|---|---|---|
| 矿山设备 | 设备健康监控、维修计划 | 设备对象、传感器数据、故障模型、维修 Action |
| 电网运营 | 停电计划、风险评估 | 电网资产、天气风险、服务区域、调度 Scenario |
| 食品供应链 | 库存、订单、排产、替代供应商 | 物料对象、订单对象、成本模型、排产 Action |
| 铁路网络 | 线路健康、维修窗口 | 轨道资产、列车计划、维修资源、调度决策 |
| 金融市场 | 市场分析、异常监控 | 交易对象、事件对象、风险模型、审计链路 |
所以,客户案例的重点不是"Foundry 有某个固定界面",而是:
不同客户在同一个操作底座上,构建了不同的业务应用和决策闭环。
这里需要谨慎:公开材料通常展示的是应用方向和业务效果,不等于披露客户内部全部架构细节。课程里引用这些案例,是为了帮助理解 Foundry 的通用模式,而不是推断具体实现。
十四、判断一个企业是否真的需要 Foundry
可以用下面这张清单自测。
如果你的企业数据平台已经能回答这些问题,Foundry 的必要性会下降:
| 问题 | 如果回答不了,说明缺什么 |
|---|---|
| 业务用户能不能用对象语言提问,而不是只用表和字段? | Ontology |
| 一个模型结果能不能直接挂到客户、设备、订单、物料等业务对象上? | Model Integration |
| 一线用户能不能在业务对象上下文中发起受控动作? | Workflows + Action |
| 动作写回 ERP、MES、CRM 后,能不能追溯数据和审批依据? | Decision Lineage |
| 权限能不能从数据源传播到下游数据集、对象和应用? | Propagating Security |
| 能不能在真正修改生产系统前创建 Scenario 并比较影响? | Decision Orchestration |
| AI 或模型建议能不能接受人类审批、反馈和持续改进? | AIP / Operational Feedback |
如果这些问题大多数都答不上来,企业可能并不是缺一个新的数据仓库,而是缺一套操作语义层和决策闭环平台。
一句话总结:
Foundry 是围绕 Ontology 建立的企业数据操作系统。它的核心价值不是某一层功能特别强,而是把数据、模型、对象、工作流、行动写回和决策血缘放进同一套业务语义闭环。