第1章 引 言
1.1 研究背景与意义
在软件工程领域,系统架构图作为传达设计意图、指导开发实施的关键载体,其绘制质量直接影响团队协作效率与系统演进能力。当前行业实践中,架构图的创建与维护主要依赖人工操作,开发人员借助通用绘图工具或专用建模软件,通过拖拽、连线等方式逐项构建架构元素。这一过程不仅耗时费力,还面临需求理解偏差导致的架构偏差风险,尤其在敏捷开发模式下,需求频繁变更使得架构图同步更新的成本进一步放大。据Stack Overflow开发者调查报告,约67%的开发团队仍以静态文档形式维护架构图,超过半数的受访者认为架构文档与实际系统之间存在不同程度的不一致。IDC的研究数据也表明,软件项目中因架构设计偏差引发的返工成本占项目总成本的15%至25%,反映出行业对架构自动化生成工具的隐性需求。
1.2 国内外研究现状
在国内,袁中锦等1针对UML活动图自动化生成问题,提出了一种融合中文需求文本语义特征的活动图自动生成方法。该研究聚焦于从自然语言需求文档中提取语义信息并映射至UML活动图元素,通过构建中文语义特征与活动图节点之间的关联规则实现自动化转换。此方法在中文需求文本的结构化分析方面取得了进展,但其技术路径高度依赖预定义的语义特征模板,面对多样化的系统架构描述时,模板覆盖度成为制约生成质量的主要瓶颈,且该方法仅针对活动图这一特定图表类型,在系统架构整体视图的生成方面尚未涉及。冯拓宇等2在大语言模型推理能力增强领域开展了探索,提出了基于外部子图生成的分步增强推理框架。该研究着眼于将结构化知识以子图形式引入大语言模型的推理过程,通过分步迭代的方式提升模型在复杂逻辑任务上的表现。实验验证了外部知识结构对模型推理能力的正向影响,为后续研究提供了将图结构数据与大语言模型相结合的技术思路。但该框架的设计目标定位于通用推理任务,并未针对软件工程中的架构图生成场景进行专门适配,其生成的子图结构与系统架构图在语义层级和表达形式上存在差异。于晗等3将检索增强生成技术引入基于模型的系统工程设计领域,提出了检索增强大语言模型的MBSE智能设计方法。该方法通过检索外部知识库中的设计模式与历史案例,为大语言模型提供领域上下文支持,从而提升系统设计方案的合理性与专业性。检索增强策略有效缓解了大语言模型在专业领域知识方面存在的覆盖不足问题,但对于知识库尚未收录的新型系统架构风格,检索命中率难以保证,且检索结果与生成目标的语义对齐仍需人工介入校验。
1.3 主要研究内容及章节安排
本研究围绕基于大语言模型的系统架构图自动生成平台展开,研究内容涵盖四个核心模块。第一,大语言模型驱动的架构图生成机制研究。设计面向架构图生成场景的提示工程策略,构建适配系统架构语义的提示词模板,引导大语言模型输出包含节点定义、边关系及分层信息的结构化JSON数据;同时研究流式生成与非流式生成相结合的响应机制,在提升用户交互体验的同时保障复杂场景下的生成可靠性,并建立关键词模板匹配的兜底策略以应对大语言模型输出异常或格式不符合预期的边界情况。第二,架构图的可视化呈现与交互式编辑技术研究。基于ECharts图形库实现架构图的网络拓扑视图与分层架构视图双模式渲染,利用JointJS框架构建支持组件拖拽添加、节点位置调整、连接线编辑、字体缩放及画布平移缩放等操作的交互式编辑器,使用户能够在自动生成结果基础上进行二次修改与精细化调整,形成"人工智能生成加人工编辑优化"的协同工作模式。第三,基于图论的架构图质量评估方法研究。从图连通性、有向无环图特性及节点度数均衡性三个维度建立评估指标体系,通过权重配置实现综合评分的灵活计算,并将评估结果应用于系统测试环节的自动评分与结果分析,为生成质量的量化衡量提供技术手段。第四,用户反馈与系统配置管理机制研究。构建包含错误标记与改进建议的分类反馈体系,引入星级评分机制收集用户对生成结果的满意度评价,同时设计管理员端的评分参数权重与模型参数动态配置功能,使平台在运行过程中能够持续积累评估数据并为后续模型优化与参数调优提供依据。上述四个模块相互衔接,共同构成从自然语言输入到架构图生成、可视化编辑、质量评估直至反馈闭环的完整技术链路。
本文围绕招聘信息采集与职业需求分析系统的设计与实现展开论述,全文共分为七章,各章内容安排如下。
第一章为绪论,阐述选题的研究背景与意义,分析当前招聘市场在信息过载、人才匹配效率方面的现实困境,在梳理国内外智能招聘、简历分析及推荐算法等领域研究现状的基础上,指出现有工作在数据采集系统性、分析可解释性及功能整合度方面的不足,进而明确本文的研究切入点与主要工作内容。
第二章为相关技术及理论,对系统开发所依赖的关键技术进行原理性说明,包括Flask轻量级Web框架与JWT认证机制、SQLAlchemy对象关系映射与SQLite数据持久化方案、DeepSeek大语言模型的流式调用与提示词工程、XGBoost梯度提升回归算法的数学基础与正则化策略,以及多策略融合推荐方法的权重模型,为后续章节的系统设计与实现提供理论支撑。
第三章为系统分析,从经济可行性、技术可行性和操作可行性三个维度论证系统开发的现实条件,通过业务流程图和用例图详细描述职位搜索与收藏、简历管理与AI分析、AI简历生成与优化、薪资预测及管理后台数据分析等核心业务流程,并依据角色权限对功能需求进行分类梳理,同时从性能、安全性、可用性和可维护性四个方面定义非功能性需求。
第四章为系统总体设计,采用分层架构思想描述数据从存储层到前端展示层的完整流动路径,绘制系统总体架构图与功能模块划分图,明确六大功能模块的边界与职责,在此基础上完成关系型数据库的实体关系建模,并以三线表形式逐一列出用户、简历、职位、收藏记录及分析记录五张核心数据表的结构定义。
第五章为系统开发与实现,首先以表格形式给出系统的软硬件开发环境配置,随后依次阐述数据采集模块的Selenium驱动策略与结构化提取方法、数据处理模块的CSV批量导入与首次启动初始化机制,以及六大功能模块的前后端协同实现过程,重点说明流式响应传输、提示词模板构建、评分动画渲染、模型推理调用和图表可视化等关键实现环节,并展示各模块的运行效果界面。
第六章为系统测试,明确黑盒测试的目的与方法,针对数据导入、职位搜索、简历管理、AI分析、薪资预测、职位推荐和管理后台七个模块编写四十二项测试用例,逐项验证功能逻辑与异常处理能力,对测试中发现的流式重连丢失、编码器未知标签异常和词云渲染超时三项问题进行修正,最终给出测试结论。
第七章为总结与展望,对系统在功能完整性、智能化水平和用户体验方面取得的成果进行归纳,客观分析在模型数据时效性、推荐算法鲁棒性、弱网环境稳定性及移动端适配方面存在的优化空间,并对后续研究方向进行展望。
第2章 相关技术及理论
2.1 大语言模型与提示工程
大语言模型(Large Language Model, LLM)是基于Transformer架构的大规模预训练语言模型,通过在海量文本语料上进行自监督学习,获得了强大的自然语言理解与生成能力。其核心机制为自回归生成,即在给定上文序列

的条件下,模型预测下一个词元
的条件概率分布。该过程可形式化表示为:
其中
为Transformer解码器在t−1时刻输出的隐藏状态向量,
与
分别为输出投影矩阵与偏置项。模型通过逐词元采样生成完整响应序列,该能力为将自然语言需求描述转化为结构化架构图数据提供了核心驱动力。
提示工程(Prompt Engineering)是引导大语言模型完成特定任务的关键技术。不同于传统的有监督微调,提示工程通过精心设计的输入模板为模型提供任务上下文、输出格式约束及领域知识提示,从而在不修改模型参数的前提下调控生成行为。在架构图生成场景中,系统提示词需要同时传达三层信息:任务定义(生成系统架构图JSON数据)、结构规范(包含nodes、edges、layers三字段的格式说明)、以及领域约束(组件分层原则与命名规则)。提示词设计质量直接影响生成结果的有效性,是连接用户需求与大语言模型能力的核心桥梁。
2.2 流式响应与实时通信机制
流式响应(Streaming Response)是一种服务端将生成内容以增量数据块形式逐步推送至客户端的通信模式。相较于传统的请求-完整响应模式,流式响应能够在生成过程尚未全部完成时即将已产出内容实时呈现给用户,显著降低用户的感知等待时间。在技术实现层面,大语言模型API通过开启stream参数,使服务端接口以Server-Sent Events(SSE)格式持续推送增量数据块,每个数据块包含当前生成片段的文本内容。
本平台在前端与后端之间采用SSE协议承载流式数据传输。SSE是HTTP协议之上的单向推送机制,服务端向客户端发送以"data:"为前缀的事件流,客户端通过EventSource接口或基于Fetch API的ReadableStream读取器逐块接收数据。流式传输过程中的数据格式需满足特定解析规则,即每一行若以"data: "开头,则提取后续JSON数据进行反序列化处理,空行表示事件分隔。本平台将流式数据分为两类事件:增量数据事件(is_complete为false,携带chunk字段)和生成完成事件(is_complete为true,携带完整graph_data与architecture_id),通过事件类型区分实现差异化的前端处理逻辑。
2.3 图论基础与有向图质量评估
系统架构图在数学本质上可建模为一个有向图G = (V, E),其中V表示架构组件节点集合,E ⊆ V × V表示组件间依赖或调用关系的有向边集合。对架构图的质量评估可转化为对有向图拓扑特性的量化分析。本平台选取三个评估维度构建指标体系。
连通性指标衡量图中任意两节点之间是否存在路径可达。对于有向图G,若其底图(忽略边方向后得到的无向图)满足连通性,则称G为弱连通图。弱连通性是架构图完整性的基本要求,非连通图意味着存在孤立组件或架构分割现象。连通性评分计算方式为:
无环性指标判断有向图中是否存在有向环。环结构在架构图中通常表示循环依赖,属于设计缺陷。拓扑排序算法可在O(|V| + |E|)时间复杂度内判定有向图是否含环:若存在合法拓扑序列则无环,否则含环。拓扑排序的存在性等价于有向图的无环性。无环性评分计算方式为:
度数均衡性指标评估图中各节点出入度的分布均衡程度。对于有向图G,节点v的出度d⁺(v)与入度d⁻(v)分别表示以v为起点和终点的边数。平均度数d̄定义为所有节点度数之和与节点数的比值。度数均衡性评分以平均度数与理想值2(每个节点平均连接两条边)之间的偏差为度量依据,其计算公式为:
综合评分
由上三项指标加权求和得出:
其中
、
、
分别为三项指标的权重系数,满足
= 1。用户可根据评估侧重点动态调整权重配置。
2.4 Web开发框架与前端可视化技术
Flask是基于Python的轻量级Web应用框架,其核心设计理念为微内核加扩展机制。Flask内置了基于Jinja2的模板引擎和基于Werkzeug的WSGI工具库,通过扩展插件体系支持对象关系映射(Flask-SQLAlchemy)、用户认证(Flask-Login)等功能组件的灵活集成。本平台选用Flask作为后端框架,一方面因其轻量特性适合中小规模Web应用的快速开发,另一方面其路由装饰器机制使API接口定义简洁直观,便于流式响应端点与SSE协议的结合实现。数据持久化层采用SQLite关系数据库,通过SQLAlchemy ORM将用户、架构图、反馈、测试结果及系统配置等实体映射为Python模型类,实现了数据操作的面向对象化。
前端可视化层面,本平台集成了ECharts与JointJS两个JavaScript图形库。ECharts作为声明式可视化库,通过配置option对象定义图表的节点数据、边连接、布局参数与样式属性,其内置的力导向布局算法可自动计算节点在图中的空间位置分布,适合生成网络拓扑视图。JointJS是基于SVG的交互式图形编辑框架,其核心抽象包括Graph(图数据模型)、Paper(画布渲染器)及预定义的形状元素(Element)与连接线(Link)。JointJS提供了完整的拖拽添加、节点移动、连线编辑、缩放平移等交互接口,为架构图的可视化编辑提供了工程化基础。两种可视化方案分别覆盖"只读查看"与"交互编辑"两种使用场景,通过视图切换机制实现技术互补。
第3章 系统架构设计
3.1 设计目标
本平台的设计目标围绕"自然语言驱动、智能生成、可视编辑、评估反馈"四个核心环节展开。具体包括:支持用户以自然语言文本输入系统需求描述,由大语言模型自动生成符合语义的架构图结构化数据;提供流式与非流式两种生成模式,兼顾实时交互体验与系统鲁棒性;支持架构图的可视化渲染,提供分层架构视图与网络拓扑视图双模式展示,并借助交互式编辑器实现组件拖拽添加、位置调整、连线编辑等操作,满足从自动生成到人工微调的工作流需求;实现历史记录持久化存储与回看,构建包含错误标记和改进建议的分类反馈体系,收集用户评分数据;为管理员提供基于图论的质量评估功能和系统参数动态配置能力,形成从生成、评估到优化迭代的闭环机制。系统整体遵循轻量级Web应用架构原则,以Python Flask作为后端核心,采用前后端分离的视图渲染模式,确保功能模块化、可维护性与可扩展性。
3.2 系统总体架构
系统采用分层架构设计,自上而下依次为表现层、业务逻辑层、数据访问层与AI服务层,如图3.1所示。
表现层负责与用户直接交互,包含基于Jinja2模板引擎渲染的Web页面(登录页、注册页、用户工作台、管理后台等)以及前端JavaScript交互逻辑。该层通过Bootstrap框架实现响应式布局,集成ECharts图形库用于架构图网络视图的渲染,集成JointJS库用于架构图的可视化编辑,并通过SSE协议接收流式生成数据块,实现打字机式实时进度展示。
业务逻辑层位于Flask应用核心,封装了用户认证、架构图生成、反馈管理、系统测试、配置管理等核心服务。该层以蓝图形式组织路由,通过Flask-Login管理用户会话,调用大语言模型接口完成架构图生成流程,并协调前端请求与数据持久化操作。架构图生成服务实现了"AI优先、模板兜底"策略:优先通过DeepSeek API流式获取生成结果,当AI返回无效数据或调用异常时,自动降级为基于关键词匹配与层分类规则的模板生成算法,确保系统在任何情况下均能返回有效架构图数据。
数据访问层基于SQLAlchemy ORM框架构建,向业务逻辑层提供面向对象的持久化接口。该层将用户、架构图、反馈记录、测试结果及系统配置等实体映射为Python模型类,屏蔽底层SQLite数据库的细节差异,并保证了数据库操作的会话一致性与事务完整性。
AI服务层封装了与大语言模型交互的完整流程,包括提示词构建、API请求发送、流式数据解析、JSON数据提取与格式校验等子功能。该层从数据库动态读取模型名称、温度参数、最大令牌数等配置,实现模型切换与参数调优的实时生效。各层之间通过明确的接口契约进行解耦,数据流转方向严格遵循自上而下的依赖原则。
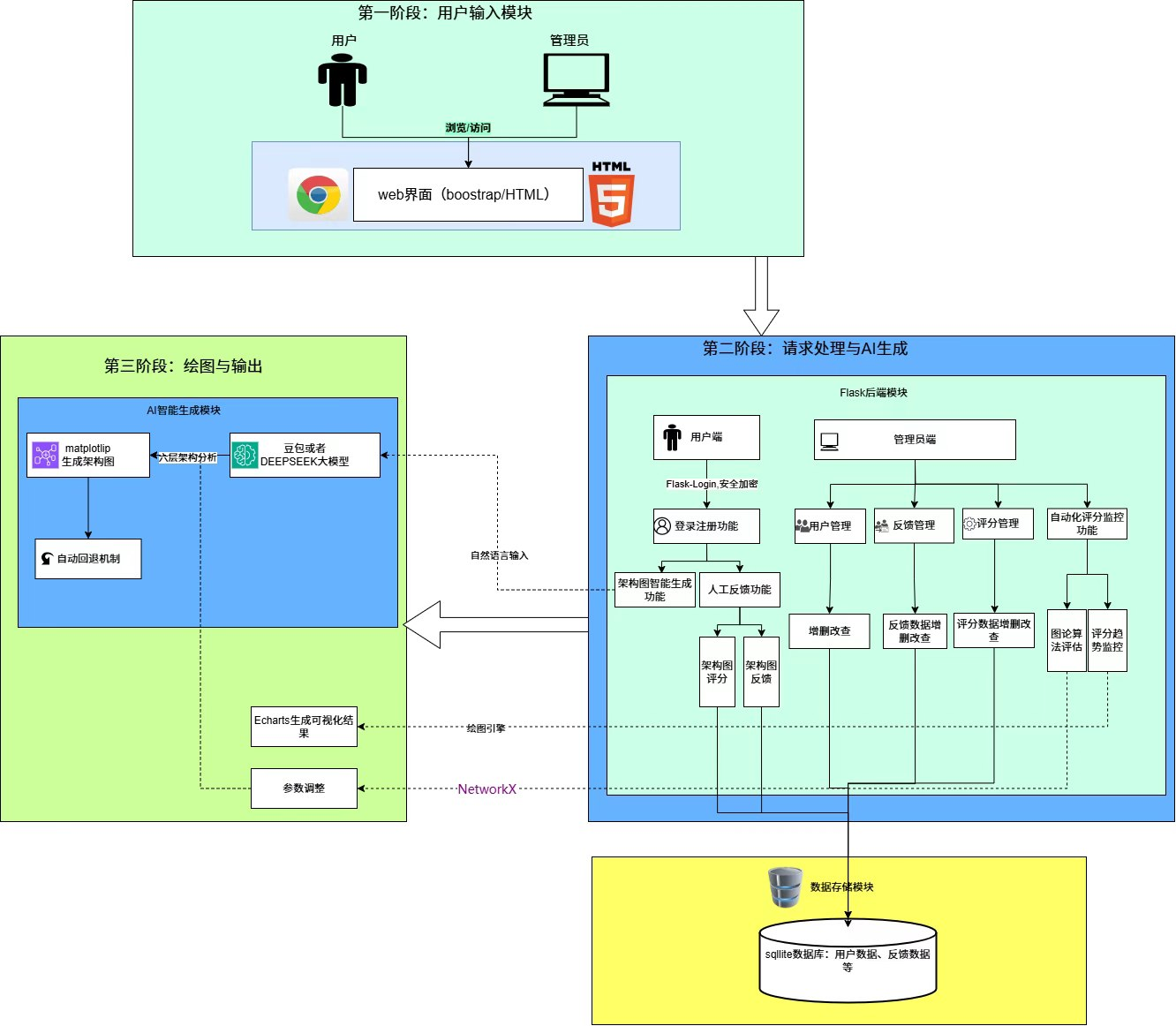
图3.1 系统总体架构图
3.3 数据库设计
3.3.1 数据库E-R图
系统数据库包含五个核心实体:用户(User)、架构图(Architecture)、反馈(Feedback)、测试结果(TestResult)及系统配置(SystemConfig)。用户实体与架构图实体为一对多关系,即一个用户可以创建多份架构图;用户与反馈之间同样为一对多关系;架构图与反馈之间为一对多关系,即一份架构图可接收多条反馈。测试结果与系统配置均为独立实体,不与其他实体产生外键关联。实体间关系如图3.2所示。
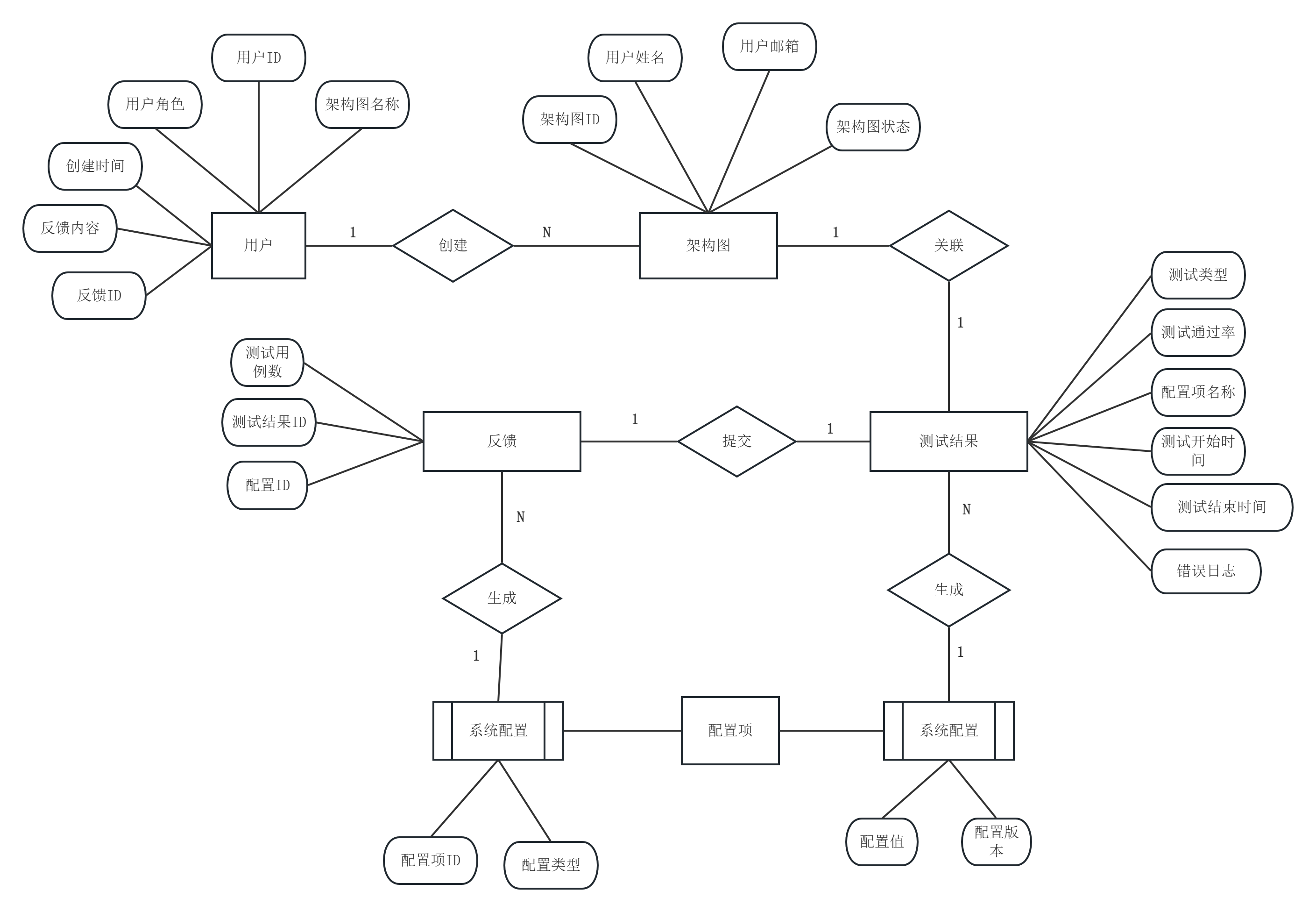
图3.2 数据库E-R图
3.3.2 数据表结构设计
各数据表的逻辑结构设计如下表3-1至表3-5所示。所有表均以id字段作为自增主键,时间相关字段采用DateTime类型存储UTC时间。
用户表(user)是平台账户体系的基础数据表,用于存储注册用户的身份信息与鉴权凭证。该表以自增整型字段id作为主键,保证用户标识的全局唯一性。username字段存储用户登录名,设置唯一约束以防止账号重复注册。password_hash字段记录密码经Werkzeug安全散列算法处理后的密文,避免明文存储带来的安全隐患。is_admin布尔字段用于区分普通用户与管理员角色,是实现路由级权限控制的判定依据。created_at字段自动记录用户注册时间,为后续用户行为分析和运营统计提供时间维度数据。用户表通过一对多关系关联架构图表与反馈表,构成用户行为数据的主实体。如表4.1所示
表4.1 用户表(user)
|---------------|-------------|-----------------------------|--------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | Integer | PRIMARY KEY, AUTO INCREMENT | 用户唯一标识 |
| username | String(80) | UNIQUE, NOT NULL | 用户名 |
| password_hash | String(120) | NOT NULL | 密码散列值 |
| is_admin | Boolean | DEFAULT False | 管理员标识 |
| created_at | DateTime | DEFAULT utcnow | 注册时间 |
架构图表(architecture)是平台核心业务数据的持久化载体,用于完整记录每一次架构图生成任务的结果与上下文。id字段为自增主键,user_id外键关联到用户表,建立架构图与创建者之间的归属关系。requirement字段以Text长文本类型存储用户输入的原始需求描述,便于后续回溯与复用。graph_data字段保存大语言模型生成或模板算法兜底产生的完整JSON数据结构,涵盖节点、边及分层信息,是前端可视化渲染的数据源。created_at字段标记生成时间,支持历史记录按降序排列。该表通过一对多关系与反馈表关联,使得每份架构图可累积多条评价意见,为质量分析提供数据支撑。如表4.2所示
表4.2 架构图表
|-------------|----------|--------------------------------|-----------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | Integer | PRIMARY KEY, AUTO INCREMENT | 架构图唯一标识 |
| user_id | Integer | FOREIGN KEY(user.id), NOT NULL | 所属用户ID |
| requirement | Text | NOT NULL | 原始需求描述文本 |
| graph_data | Text | NOT NULL | 架构图JSON数据 |
| created_at | DateTime | DEFAULT utcnow | 生成时间 |
反馈表(feedback)用于收集用户对生成结果的评价与纠错信息,是平台质量改进闭环机制的关键数据节点。表内设置architecture_id和user_id两个外键,分别关联到架构图表与用户表,确保每条反馈都能追溯到具体的架构图与提交者。feedback_type字段采用限定枚举值"error"或"improvement",区分错误标记与改进建议两种反馈意图。feedback_content字段存储用户撰写的详细意见文本。rating字段允许取值为1-5的整数评分或空值,为生成质量提供量化维度。created_at字段记录反馈提交时间。该表为后台管理模块的评分统计分析与生成质量趋势监控提供了原始数据基础。如表4.3所示
表4.3 反馈表
|---------------|-------------|-----------------------------|--------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | Integer | PRIMARY KEY, AUTO INCREMENT | 用户唯一标识 |
| username | String(80) | UNIQUE, NOT NULL | 用户名 |
| password_hash | String(120) | NOT NULL | 密码散列值 |
| is_admin | Boolean | DEFAULT False | 管理员标识 |
| created_at | DateTime | DEFAULT utcnow | 注册时间 |
测试结果表(test_result)用于存储系统测试环节中各项测试用例的执行结果与性能指标,面向管理员评估生成算法质量提供定量依据。id字段为自增主键,requirement字段记录测试用例的输入需求文本,complexity字段将测试用例按简单、中等、复杂三级分类标注。generation_time字段以浮点型记录架构图生成过程的实际耗时,用于衡量系统响应性能。score字段存储基于图论评估算法计算的综合质量评分。error_type字段在检测到架构图存在连通性缺陷或循环依赖等问题时记录具体错误类型,无异常时取值"无"。created_at字段标记测试执行时间,支持按时间维度追踪系统性能变化趋势。如表4.4所示
表4.4 测试结果表
|-----------------|-------------|-----------------------------|----------------------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | Integer | PRIMARY KEY, AUTO INCREMENT | 测试记录ID |
| requirement | Text | NOT NULL | 测试用例需求文本 |
| complexity | String(20) | NOT NULL | 复杂度(simple/medium/complex) |
| generation_time | Float | NOT NULL | 生成耗时(秒) |
| score | Float | NOT NULL | 质量评分 |
| error_type | String(100) | NULL | 错误类型描述 |
| created_at | DateTime | DEFAULT utcnow | 测试时间 |
系统配置表(system_config)是平台可调参数的集中管理存储,采用单例记录设计,即全局仅存在一条配置记录。该表不仅包含评分评估算法的三项权重字段------connectivity_weight(连通性权重)、cycle_weight(无环性权重)和degree_weight(度数均衡性权重),三者默认值之和为1.0,保证综合评分计算的归一化;还包含大语言模型调用参数------model_name指定模型版本,temperature控制生成随机性,max_tokens限制单次输出上限。updated_at字段在每次配置更新时自动刷新为当前时间,便于追踪参数变更历史。业务逻辑层通过get_config()静态方法读取该表数据,实现参数修改后的实时生效。如表4.5所示
表4.5 系统配置表
|---------------------|-------------|----------------------------------|---------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | Integer | PRIMARY KEY, AUTO INCREMENT | 配置记录ID |
| connectivity_weight | Float | DEFAULT 0.3 | 连通性权重 |
| cycle_weight | Float | DEFAULT 0.4 | 无环性权重 |
| degree_weight | Float | DEFAULT 0.3 | 度数均衡性权重 |
| model_name | String(100) | DEFAULT 'deepseek-chat' | 大语言模型名称 |
| temperature | Float | DEFAULT 0.7 | 模型温度参数 |
| max_tokens | Integer | DEFAULT 4096 | 最大输出令牌数 |
| updated_at | DateTime | DEFAULT utcnow, ON UPDATE utcnow | 最后更新时间 |
3.4 功能模块设计
3.4.1 用户管理模块设计
用户管理模块负责平台的账户生命周期管理和访问控制。模块提供用户注册功能,对用户名唯一性和两次密码输入一致性进行前端与后端双重校验,密码经Werkzeug安全散列算法处理后存入数据库。登录功能通过验证密码散列值确认用户身份,成功后由Flask-Login创建用户会话并设置持久化Cookie,会话有效期默认1小时。模块区分普通用户与管理员两种角色,管理员标志在注册时通过勾选框设定,登录后根据is_admin字段进行路由级权限校验,普通用户无法访问管理后台路由。用户登出调用logout_user()方法清除会话状态并重定向至登录页。模块通过login_required装饰器保护所有需要身份认证的路由端点,未登录请求自动重定向至登录页,保证功能入口的安全性。
3.4.2 架构图生成模块设计
架构图生成模块是平台的核心功能单元,其处理流程如图3.3所示。用户在前端输入自然语言需求描述后,模块优先调用大语言模型流式生成接口。在流式生成路径中,后端向DeepSeek API发送带有系统提示词的请求(提示词定义了JSON输出格式规范,要求层次信息根据需求动态确定),并开启stream标志。API返回的SSE数据流经后端逐块转发至前端,前端通过ReadableStream读取器实时更新进度条和思考过程文本。当数据流结束后端从完整响应文本中提取JSON数据并进行格式校验,若JSON解析失败或缺少必要字段(nodes、edges、layers),则判定AI生成无效,自动触发模板兜底机制。
兜底机制采用关键词匹配与层次分类算法实现。算法扫描需求文本中预定义的关键词集合,将匹配到的中文组件名按层次归类:含"前端"、"页面"等关键词的归入客户端层,含"网关"、"代理"等关键词的归入接入层,含"服务"、"订单"等关键词的归入服务层,含"数据库"、"缓存"等关键词的归入数据层。随后根据连通性要求自动补全缺失的基础组件,按逐层向下的规则生成组件间连接边,并填充层级描述。最终生成的graph_data对象包含nodes、edges和layers三个顶层字段,其中layers对象按层键值对组织,每层包含层名、颜色、职责描述及组件功能列表。
生成成功后,架构图JSON字符串随用户需求文本一同持久化至architecture表,并返回前端。前端据此渲染分层架构视图或网络拓扑视图,同时激活交互式编辑器将组件按分层布局绘制于画布上,用户可拖拽新组件、移动现有组件、调整连线、修改字体大小、缩放平移画布,实现二次编辑。模块还支持从历史记录加载已保存架构图,自动回填需求框并重新渲染视图。
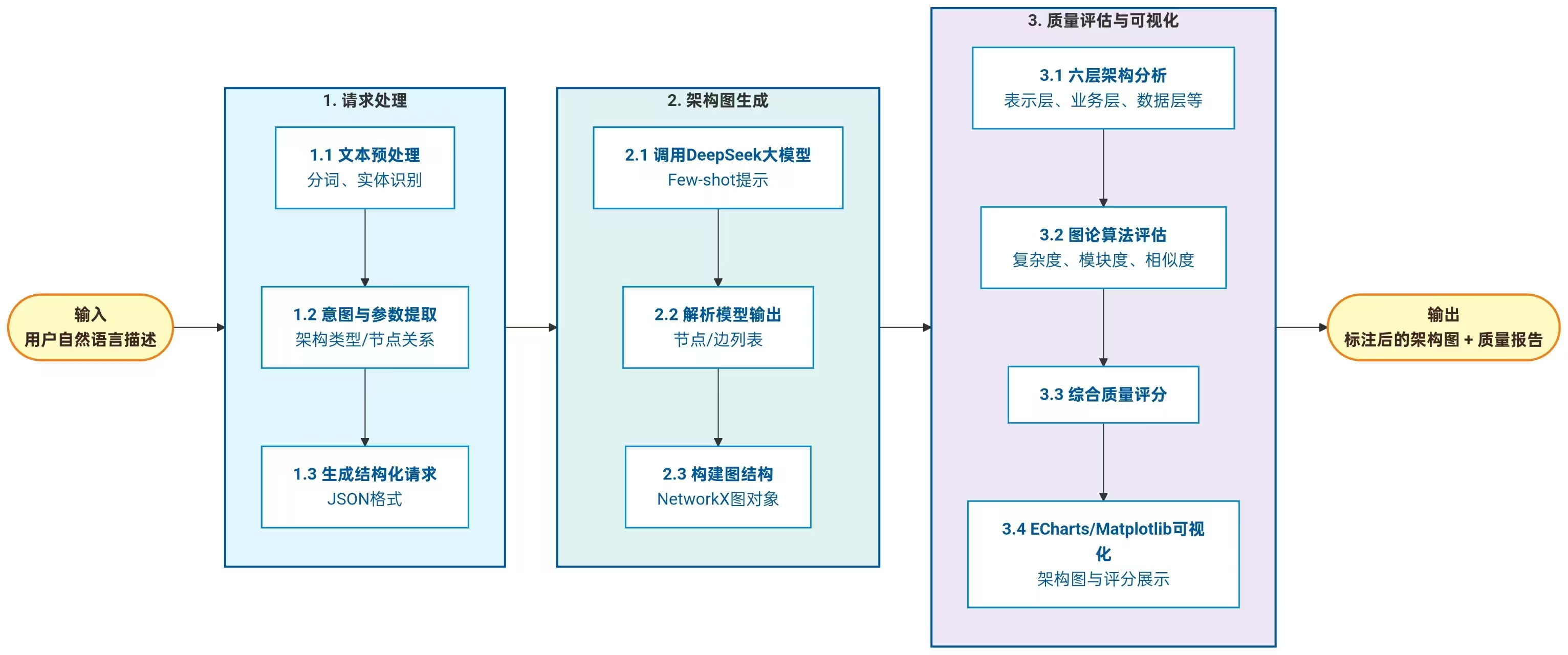
图3.3 架构图生成流程图
3.4.3 反馈管理模块设计
反馈管理模块为用户提供对生成结果进行评价的渠道。当架构图成功生成后,前端界面下方自动展示反馈表单,包含反馈类型(错误标记或改进建议)、星级评分控件(1-5星)及文本输入框。星级评分通过JavaScript动态捕捉悬停状态,点击设定分值后同步更新隐藏表单域。提交时,前端通过AJAX请求将architecture_id、feedback_type、feedback_content及rating字段发送至后端,后端验证数据完整性与权限(反馈者必须为架构图所属用户),校验通过后写入feedback表。反馈数据供后台管理系统收集分析,为质量评估与模型优化提供依据。
3.4.4 后台管理模块设计
后台管理模块面向管理员提供平台监控与运维功能。管理仪表盘聚合展示用户总数、架构图总数、反馈总数三项核心指标,并列出最近10条反馈记录和最近5次测试结果的摘要信息。反馈管理子模块通过AJAX异步加载全部反馈数据,以表格形式呈现发起用户、反馈类型、评分星级、反馈内容及时间戳,并自动计算平均评分、评分分布柱状图等统计数据。系统测试子模块允许管理员一键触发包含简单、中等、复杂三个典型用例的自动测试流程,测试过程依次调用架构图生成模块,记录生成耗时与质量评分,并将结果写入test_result表后实时刷新前端表格。配置管理子模块提供评分权重(连通性、循环检测、度数平衡)和AI模型参数(模型名称、温度、最大令牌数)的可视化配置表单,通过输入校验确保权重总和为1.0、温度取值在0-2之间等,提交后更新system_config表,后续生成流程通过get_config()方法动态读取生效。
3.4.5 质量评估模块设计
质量评估模块实现了一套基于有向图拓扑特性的量化评分算法,用于衡量生成架构图的结构质量。模块从数据库获取架构图JSON数据,使用NetworkX库构建有向图模型。评估过程分为三个步骤:首先调用nx.is_weakly_connected()检查有向图的弱连通性,若连通则连通性得分S_conn为100,否则为50;其次尝试执行拓扑排序,若排序成功则无有向环,无环性得分S_cycle为100,若排序失败(抛出NetworkXUnfeasible异常)则判定存在循环依赖,得分为60;最后计算所有节点的平均入度与出度总和除以节点数得到平均度数d̄,按公式S_degree = min(100, max(60, 100 − |d̄ − 2| × 10))计算度数均衡性得分。最终综合分数由三项得分与从system_config表读取的权重系数加权求和得出,公式为S_total = w_conn×S_conn + w_cycle×S_cycle + w_degree×S_degree。评估结果与详细指标(节点数、边数、各子项得分等)一并返回,用于系统测试报告和架构图质量分析。模块设计体现了可配置性,权重参数的动态调整使得质量评估标准能够根据实际业务需求灵活适配。
第4章 系统核心模块实现
4.1 开发环境与工具
本平台的开发环境基于Windows 11操作系统,选用了Python 3.10作为后端编程语言,前端采用HTML5、CSS3及ECMAScript 6标准JavaScript。后端框架选用Flask 2.3,其轻量级与可扩展特性适配中小规模Web应用的快速构建。数据库采用SQLite 3,通过Flask-SQLAlchemy 3.0对象关系映射框架实现数据操作,避免了编写原生SQL语句的复杂性。大语言模型接入层依赖DeepSeek官方提供的Chat Completions API,HTTP通信使用Python requests库。图论分析模块集成了NetworkX 3.1库,用于构建有向图并计算拓扑指标。前端可视化以ECharts 5.4.3实现声明式图表渲染,以JointJS 3.7.6实现交互式图形编辑,辅以Bootstrap 5.3与Bootstrap Icons 1.11构建响应式界面和图标体系。开发工具选用Visual Studio Code,并配合Git进行版本控制,Python虚拟环境用于依赖隔离。前后端数据交互主要采用AJAX异步请求与Server-Sent Events流式推送,会话管理依赖于Flask-Login扩展和Werkzeug安全模块。该技术栈在保障开发效率的同时,兼顾了系统各层的松耦合与可维护性。
4.2 关键技术实现
4.2.1 基于DeepSeek的自然语言解析
自然语言解析模块的核心职责是将用户输入的文本需求描述转化为深度语义表示,为后续架构图生成提供语义基础。该模块通过封装DeepSeek API实现,调用入口为llm_utils.py中的generate_architecture_stream和generate_architecture_by_llm两个函数。后端接收来自前端的生成请求后,从system_config表中读取当前生效的模型参数,包括model_name、temperature和max_tokens。请求体以messages数组形式组织,其中system消息承载系统提示词,user消息承载用户需求。系统提示词严格定义了输出JSON的结构规范,要求模型直接返回包含nodes、edges、layers三个字段的完整数据,并强调层次信息需根据系统特征自主确定,避免千篇一律的四层模板。提示词中还明确了组件命名须使用中文、关系类型使用英文动词等约束。
当采用流式模式时,API请求中设置stream=true,服务端返回SSE格式数据流。后端通过response.iter_lines()逐行解析,过滤"data:"前缀后提取chunk文本,通过Python生成器yield关键字将数据块实时推送至前端。前端以Fetch API的ReadableStream读取器接收分块,解析后动态渲染到进度提示区域,形成打字机效果,缓解了用户等待焦虑。当流式传输结束后,后端调用extract_json_from_text函数从完整文本中提取JSON数据。该函数优先尝试json.loads直接解析,失败后采用正则表达式匹配首个完整JSON对象,若仍失败则返回默认的三节点基础结构作为兜底。这一机制确保了在模型返回格式不符合预期或包含额外说明文字的情况下,系统仍能获得有效的结构化数据。
前后端关联方面,流式端点/generate/stream的响应以SSE格式发送,前端通过监听data事件完成视图更新与最终结果渲染。非流式端点/generate作为备选,当流式传输异常时前端自动降级调用,保证功能可用性。这种双模式设计平衡了交互体验与系统鲁棒性。
4.2.2 架构图生成算法实现
架构图生成算法由"AI优先、模板兜底"双路径构成,其流程如图4.1所示。当大语言模型返回的JSON数据经校验后发现nodes字段为空或缺失关键结构时,系统自动触发模板兜底算法。模板算法位于utils.py的generate_architecture函数中,核心步骤包括关键词匹配、层次分类、组件补全、边生成及分层信息组装五个阶段。
首先,函数扫描用户需求文本,在预定义的关键词-组件映射表(COMPONENT_MAPPING)中匹配,将识别到的关键词映射为中文组件名称。映射表涵盖前端层、网关层、服务层和数据层四类,部分示例如表4-1所示。若未匹配到任何组件,则默认添加"前端应用""业务服务""数据库"三个基础节点。
表4.1 关键词-组件映射表(部分)
|-----|---------------|---------------------|
| 层级 | 关键词示例 | 映射组件 |
| 前端层 | 登录、页面、应用、移动 | 登录页面、前端应用、移动应用 |
| 网关层 | 网关、负载均衡、nginx | API网关、负载均衡器、Nginx服务 |
| 网关层 | 网关、负载均衡、nginx | API网关、负载均衡器、Nginx服务 |
然后,调用classify_component函数将每个组件按名称归类到frontend、gateway、service、data四层之一。分类依据为组件名中包含的层次特征词,如含"前端""页面"归类为frontend。分类完成后,算法检查各层是否为空:若frontend层为空则添加"前端应用";若service层组件多于1个且gateway层为空则添加"API网关";若data层为空则添加"数据库"。这一步骤保证了架构图的连通性基础。
接着进入边生成阶段。算法遵循自上而下的调用链路:frontend层所有组件连接到gateway层首个组件(若无gateway则直接连service层首个组件);gateway层组件连接到所有service层组件;service层每个组件连接到data层首个组件;service层内部以链式结构串联以保证服务间连通;各层内部多余组件以星型拓扑连接至本层第一个组件。最后,系统遍历层间检查是否已有边存在,若无则添加桥接边。
最终生成的数据结构包含nodes列表(每个节点含id、name)、edges列表(含source、target、relation)以及layers字典。layers对象为每个有节点的层赋予中文名称、颜色、职责描述和组件功能列表,组件功能描述取自COMPONENT_DESCRIPTIONS字典。该数据经json.dumps序列化后持久化至数据库,并返回前端进行可视化渲染。
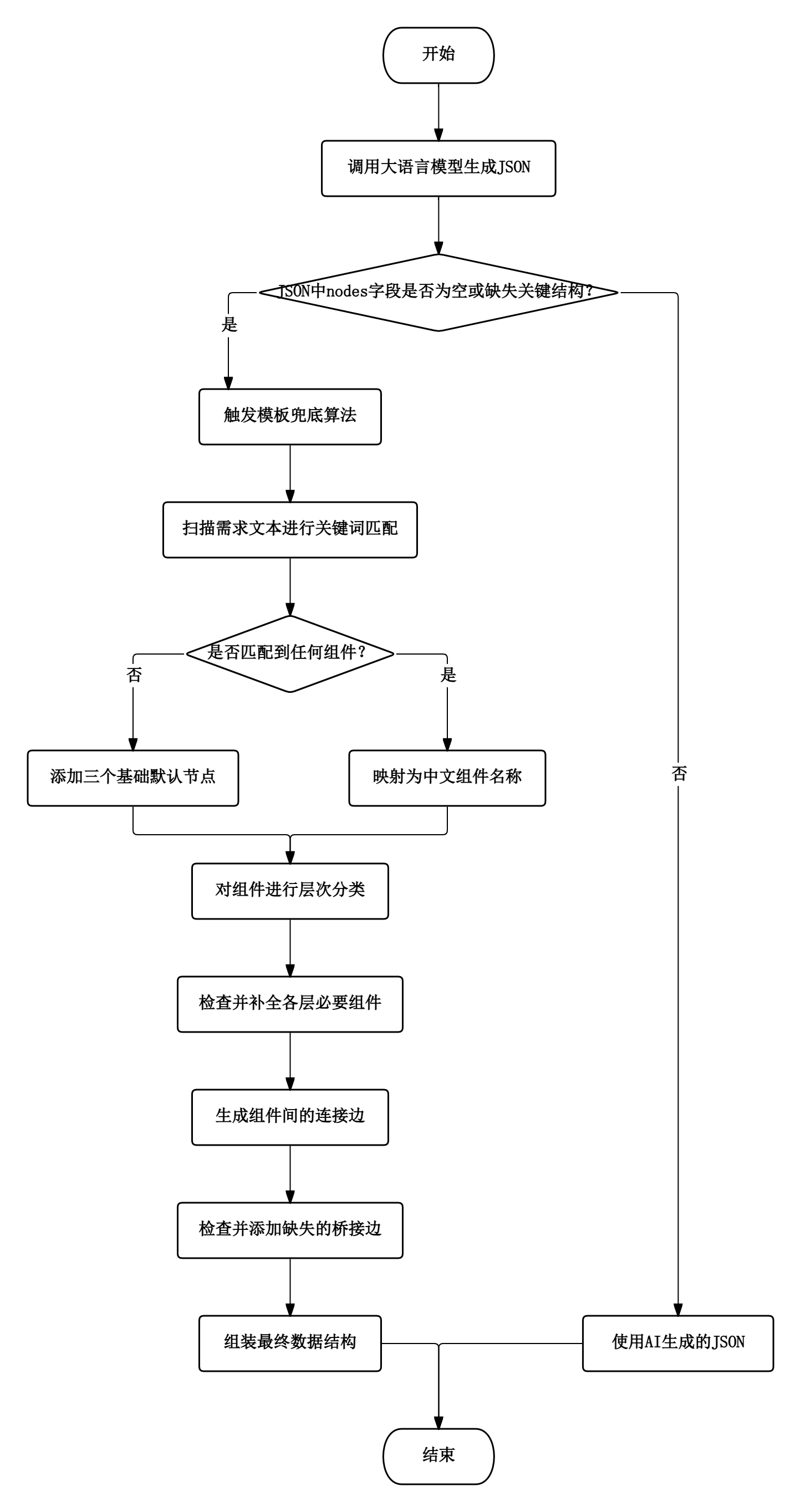
图4.1 架构图生成算法流程图
4.2.3 基于ECharts的可视化渲染
可视化渲染模块负责将JSON格式的架构图数据转化为用户可读的图形界面,支持分层架构视图和网络拓扑视图两种展示模式,以及基于JointJS的交互式编辑器视图,三者通过按钮切换,如图4.2所示。
分层架构视图的实现在于renderLayeredArchitecture函数。该函数遍历graph_data.layers对象,按层键顺序依次生成HTML结构。每层渲染一个层级标题块和一个组件网格。标题块以层颜色为背景渐变,展示层名称与职责描述。组件网格采用CSS Grid布局自动填充,每个组件以卡片形式呈现,包含以层颜色为背景的组件名称栏和以列表排列的功能描述项。层与层之间插入带有渐变样式和向下箭头的"数据流向"指示器,直观表达了层间调用关系。该视图完全通过DOM操作构建,无需依赖图形库。
网络拓扑视图基于ECharts的graph系列实现。renderGraphArchitecture函数首先将nodes数据按节点名称中的特征词进行层次分类,为每层分配不同的y轴位置和颜色。节点以圆角矩形符号表示,尺寸设定为120,50以容纳中文标签。边以带曲度的箭头连接,并标注关系类型。通过predefined layout of 'none'和手动指定节点的x、y坐标实现分层布局效果,节点的y坐标由所在层的预设比例值确定,x坐标在层内均匀分布。ECharts配置中开启roam和draggable选项,允许用户缩放平移画布和拖拽节点。该视图可将架构图导出为图片,适合用于方案汇报与文档嵌入。
交互式编辑器基于JointJS框架构建。初始化时创建joint.dia.Graph模型和joint.dia.Paper画布,Paper配置了网格背景、元素移动、连接线编辑等交互能力。loadArchitectureToEditor函数将graph_data中的layers数据转换为分层的矩形节点,组件以特定颜色渲染,层间添加箭头连线表示数据流向。工具栏提供了多种组件类型(前端、网关、服务、数据)的拖拽添加功能,通过HTML5 Drag and Drop API实现从组件面板到画布的拖放,监听paper的drop事件后调用addComponentToCanvas创建新节点。选中节点后可以实现移动、删除、文本编辑、字体大小调整等操作,画布整体支持缩放与自适应。编辑器视图实现了"AI生成骨架+人工精修"的协作模式。
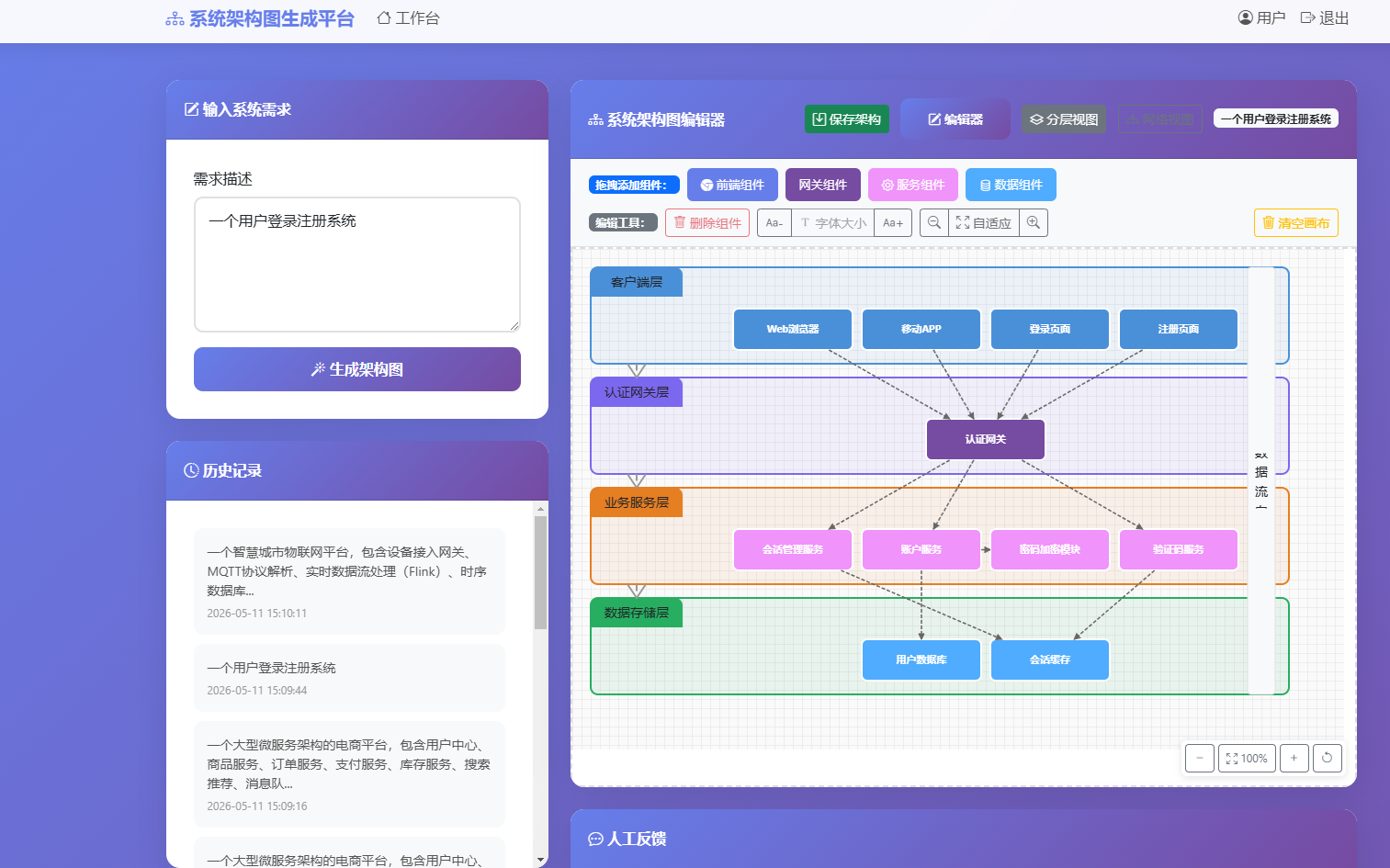
图4.2 可视化视图切换示意图
4.2.4 质量评估算法实现
质量评估算法是管理员端系统测试与评分功能的核心,其目标是量化衡量架构图的结构合理性。算法基于图论原理,将架构图JSON数据转换为NetworkX有向图对象后进行计算,整体流程如图4.3所示。
首先,算法从graph_data中提取节点列表和边列表,调用nx.DiGraph()构建有向图G。随后依次计算三个维度的评分。
连通性评估:利用nx.is_weakly_connected(G)判断有向图底图的连通性。若图中有孤立节点或割裂子图,返回False,连通性得分S_conn取50;否则取100。这是架构图完整性的兜底检查,确保所有组件至少通过一条路径可达。
无环性评估:尝试调用nx.topological_sort(G)进行拓扑排序。若排序成功则说明图中不存在有向环,S_cycle取100;若抛出NetworkXUnfeasible异常则判定存在循环依赖,S_cycle取60。架构图中的环往往意味着不合理的双向依赖,应予以扣分。
度数均衡性评估:计算每个节点的出入度之和,再求所有节点的平均度数d̄ = (∑ᵥ (d⁺(v) + d⁻(v))) / |V|。以2作为理想平均度数,偏差越大得分越低。度数均衡性得分按公式S_degree = min(100, max(60, 100 − |d̄ − 2| × 10))计算,将得分限制在60至100区间内,避免极端值过度影响总分。
综合评分由三项子得分加权求和,权重从system_config表中读取,公式为S_total = w_conn·S_conn + w_cycle·S_cycle + w_degree·S_degree,权重默认值如表4-2所示。管理员可通过后台界面调整权重,实现评估标准的灵活配置。
表4.2 质量评估权重默认值
|----------|---------|-----|
| 权重参数 | 对应指标 | 默认值 |
| w_conn | 连通性得分 | 0.3 |
| w_cycle | 无环性得分 | 0.4 |
| w_degree | 度数均衡性得分 | 0.3 |
最终,evaluate_graph_quality函数返回总得分和包含节点数、边数、是否连通、是否含环、平均度数及各子项得分的details字典。该结果既用于系统测试报告的生成,也为反馈驱动的模型调优提供了数据支撑。评估算法的实现位于utils.py中,与性能测试流程集成后,管理员点击"运行系统测试"按钮即可自动完成一组用例的批量评估,结果以表格形式展示。
图4.3 质量评估算法流程图
4.2.5 用户会话管理实现
会话管理模块基于Flask-Login扩展构建,实现了用户身份认证、会话维持与权限校验的全流程闭环。在应用初始化阶段,auth.py中的init_login_manager函数创建LoginManager实例并绑定Flask应用,配置login_view为'login'端点,使得未认证用户访问受保护路由时自动重定向至登录页。用户加载回调load_user通过传入的user_id查询User模型返回用户对象,其内部调用了Flask-SQLAlchemy的Query.get方法。
注册功能中,表单提交的用户名经唯一性校验后,密码通过generate_password_hash函数进行散列处理,该函数底层调用Werkzeug的scrypt算法,以密文形式存储于user表的password_hash字段。登录验证时,check_password_hash函数比对用户输入密码的散列值与数据库中存储值,匹配成功后调用login_user函数创建用户会话。login_user接受remember参数,本平台未开启"记住我"选项,会话在浏览器关闭或超时后自动失效。会话过期时间通过PERMANENT_SESSION_LIFETIME配置项设置为3600秒。
权限控制采用双角色模型。User模型中的is_admin布尔字段在注册时根据复选框状态赋值,数据库默认值为False。在视图函数层,普通用户访问管理后台路由时,代码直接判断current_user.is_admin属性,若为False则重定向至用户工作台,同时API端点返回403禁止访问错误。前端管理后台页面加载时额外发送/api/check-session请求验证当前用户身份,若检测到非管理员身份则弹出提示并自动跳转。
登录状态检查端点/api/check-session直接返回当前会话的authenticated、user_id、username和is_admin字段,为前端会话测试页面和管理后台的会话预警提供接口。用户登出时调用logout_user()清除服务端会话,并删除客户端Cookie中的会话标识。CONFIG中SESSION_COOKIE_NAME设置为'arch_session',SESSION_COOKIE_HTTPONLY设为True以防止客户端脚本读取,SESSION_COOKIE_SAMESITE设置为'Lax'限制跨站请求携带Cookie,保障会话安全性。前端的AJAX请求统一携带credentials: 'same-origin'确保跨页面请求附验证凭据,避免出现会话丢失问题。
4.3 主要功能界面展示
4.3.1 用户注册登录界面
用户注册界面如图4.4所示,页面以居中卡片形式呈现,包含用户名、密码、确认密码三个文本输入框和一个"注册为管理员"复选框。点击注册按钮后,前端对两次密码输入进行一致比较,若不匹配则通过Flash消息提示错误,服务器端同样执行校验并检查用户名唯一性。登录界面如图4.5所示,仅需用户名和密码两个字段,提供"立即注册"链接引导新用户。两个界面均继承base.html模板的导航栏和渐变背景,导航栏在未登录状态下隐藏,登录后在页面顶部显示用户名和退出按钮。表单采用Bootstrap样式,输入框聚焦时呈现紫色边框阴影效果,响应式布局支持移动端自适应显示。
图4.4 用户注册界面
图4.5 用户登录界面
4.3.2 架构图生成界面
架构图生成界面是用户工作台的核心区域,如图4.6所示。左侧为需求输入卡,内置一个多行文本框和"生成架构图"按钮。点击按钮后,按钮状态切换为旋转加载图标并禁用,同时进度区域显示AI思考过程的实时文本流。右侧主区域默认为空状态提示,生成完成后自动激活JointJS交互式编辑器视图,显示按分层布局的架构图。顶部工具栏提供了"编辑器""分层视图""网络视图"三个切换按钮、组件拖拽面板(前端、网关、服务、数据四种类型)和编辑工具组(删除、字体缩放、画布缩放、自适应、清空按钮)。架构图的下方会自动出现反馈表单,包含错误/改进类型选择、五星评分组件和反馈内容文本框。整个界面的所有操作均在同一页面完成,避免页面跳转带来的上下文丢失。
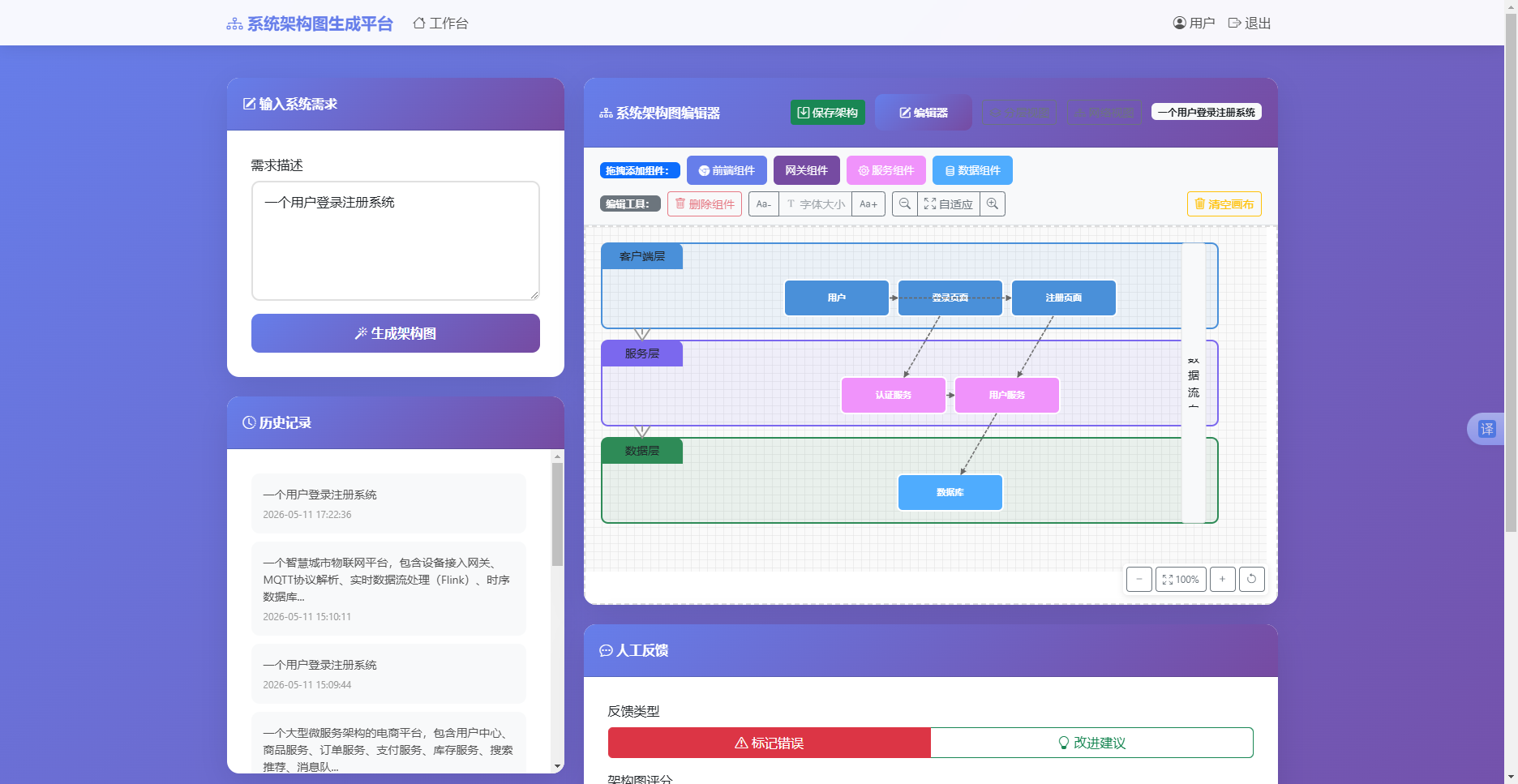
图4.6 架构图生成界面
4.3.3 历史记录界面
历史记录模块嵌入在工作台左侧区域的下方,如图4.7所示。记录以列表形式展示最近10条生成过的架构图,每条记录显示截断后的前50字符需求文本和生成日期时间,背景为浅灰色圆角块。鼠标悬停时记录块右移,点击后自动将对应需求文本回填到输入框,并重新触发架构图生成与渲染,实现了历史方案的快速回溯。该模块通过Jinja2模板循环architectures变量渲染,首次请求由Flask视图函数从architecture表按创建时间倒序查询并传递到模板。架构图数据本身以JSON格式存储于数据库,重新加载时直接从数据库读取,没有额外的文件依赖。
图4.7 历史记录界面
4.3.4 管理后台界面
管理后台仪表盘如图4.8所示,顶部以三张统计卡片分别展示注册用户总数、架构图生成总数和反馈总数,每个数字采用渐变色文字效果。中部左侧为"用户反馈管理"卡片,嵌入"刷新反馈"按钮和可滚动表格,表格每行显示用户、反馈类型标签(红色错误或绿色改进)、星级评分、反馈内容和时间。表格下方有评分统计区域,动态计算平均评分星星、评分分布柱状图和已评分比例。中部右侧为"系统测试"卡片,包含"运行系统测试"按钮和测试结果表格,表格展示复杂度标签、生成耗时、综合评分和错误类型。下方为最近反馈详情表,列出所有反馈的完整信息。仪表盘的数据均通过AJAX请求异步获取,首次加载时由服务端渲染一部分初始数据以提高首屏速度。
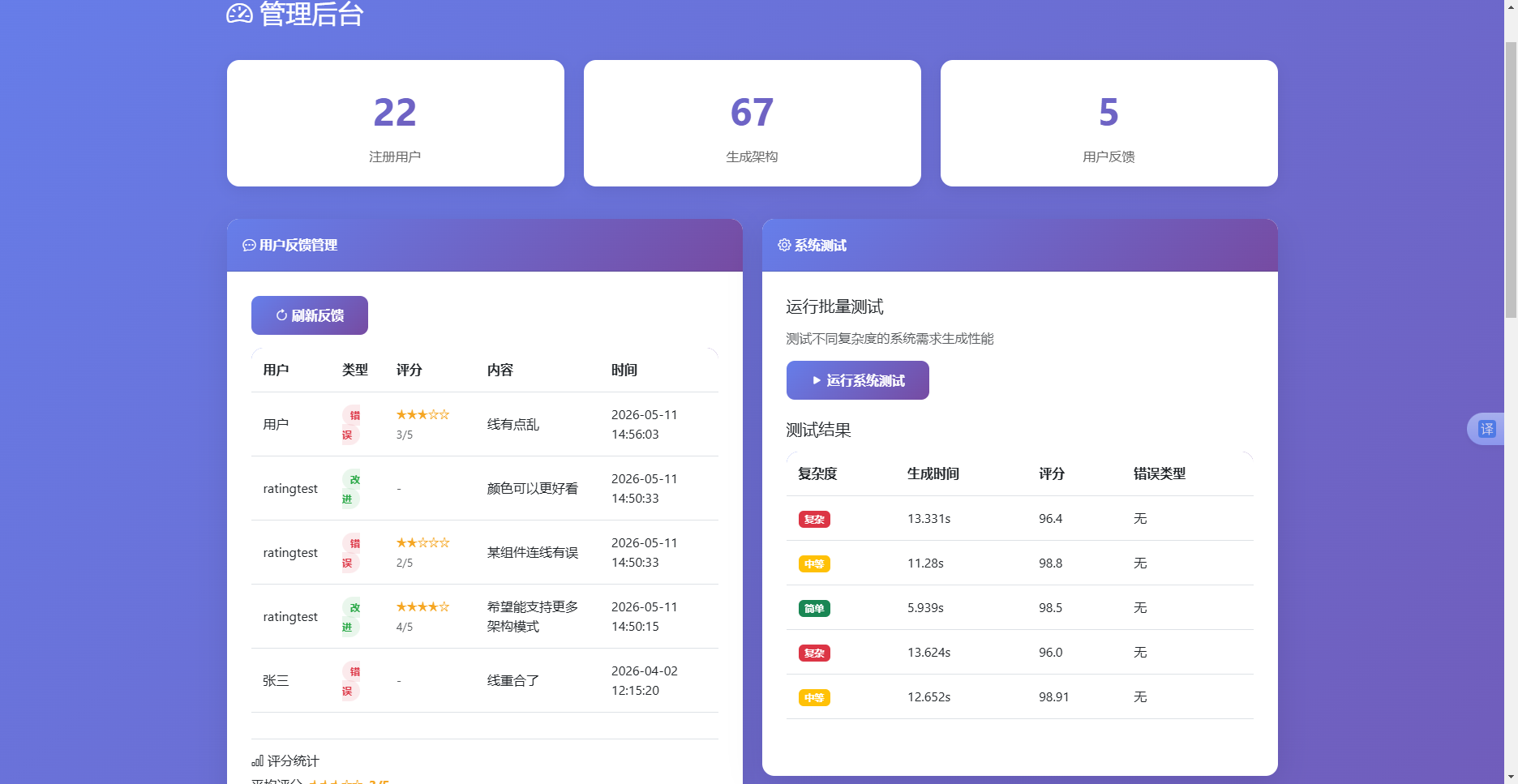
图4.8 管理后台仪表盘
4.3.5 反馈管理界面
反馈管理界面实际上是管理后台仪表盘的一个子区域,在点击"刷新反馈"按钮后动态加载全部反馈记录。如图4.9所示,表格列包括了用户、反馈类型、评分、内容、时间。评分列以橙色星标符号渲染,非常直观。表格上方的评分统计区域以柱状图形式展示1-5星的数量分布,鼠标悬停可见具体数值。管理员可通过这一界面了解用户对生成结果的满意度分布,从而有针对性地调整模型参数或提示词策略。
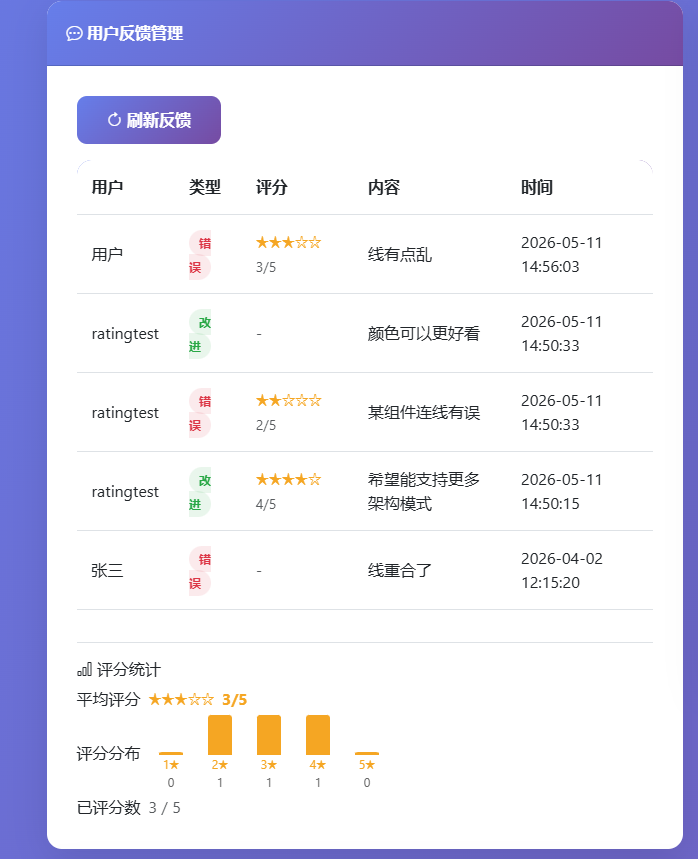
图4.9 反馈管理界面局部
4.3.6 系统测试界面
系统测试界面集成于管理后台卡片中,操作区仅一个按钮"运行系统测试"。点击后按钮变为加载状态,后端依次对简单、中等、复杂三个预设需求用例调用生成与评估流程,每条用例的生成耗时、综合评分、节点数、边数、调用方法(AI或模板兜底)实时汇总并以表格展示。测试结果同时写入test_result表,供后续在管理后台查看历史结果。该界面为管理员提供了系统生成能力和质量水平的可视化快照,便于对比不同模型配置或代码版本下的性能差异,如图4.10所示。
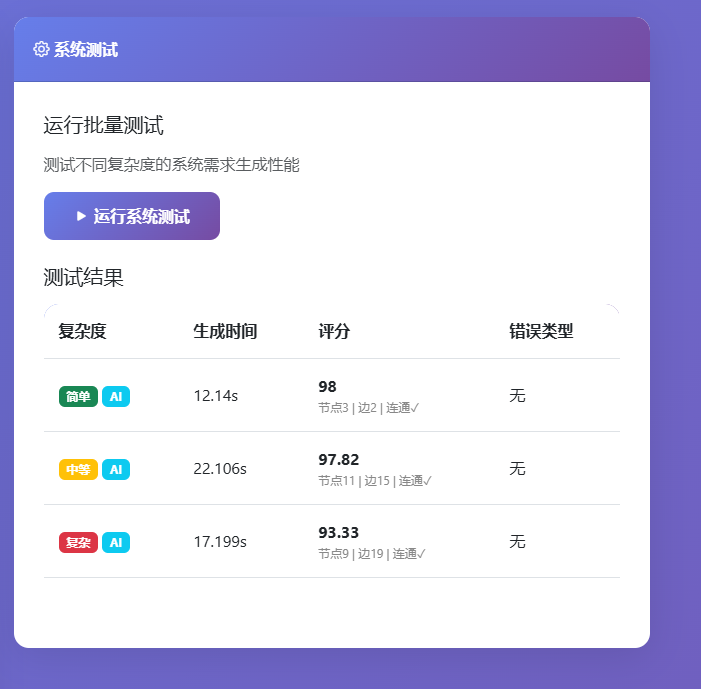
图4.10 系统测试结果展示
4.3.7 参数配置界面
参数配置界面位于管理后台下部的两个并排卡片中,如图4.11所示。左侧为"评分参数配置",提供三个数值输入框分别对应连通性权重、循环检测权重和度数平衡权重,下方实时显示权重总和,若总和偏离1.0则数字变色提醒。右侧为"AI模型配置",包含模型选择下拉框(可选DeepSeek Chat或DeepSeek Reasoner)、Temperature滑块输入和Max Tokens数字输入,所有控件都设定了值域限制。点击保存按钮后,前端发送POST请求至/admin/config端点,后端接收JSON数据后更新system_config表中对应字段,并立即生效于后续的生成或评估流程。该设计使得管理员无需重启服务即可调整系统运行参数,提升了运维效率。
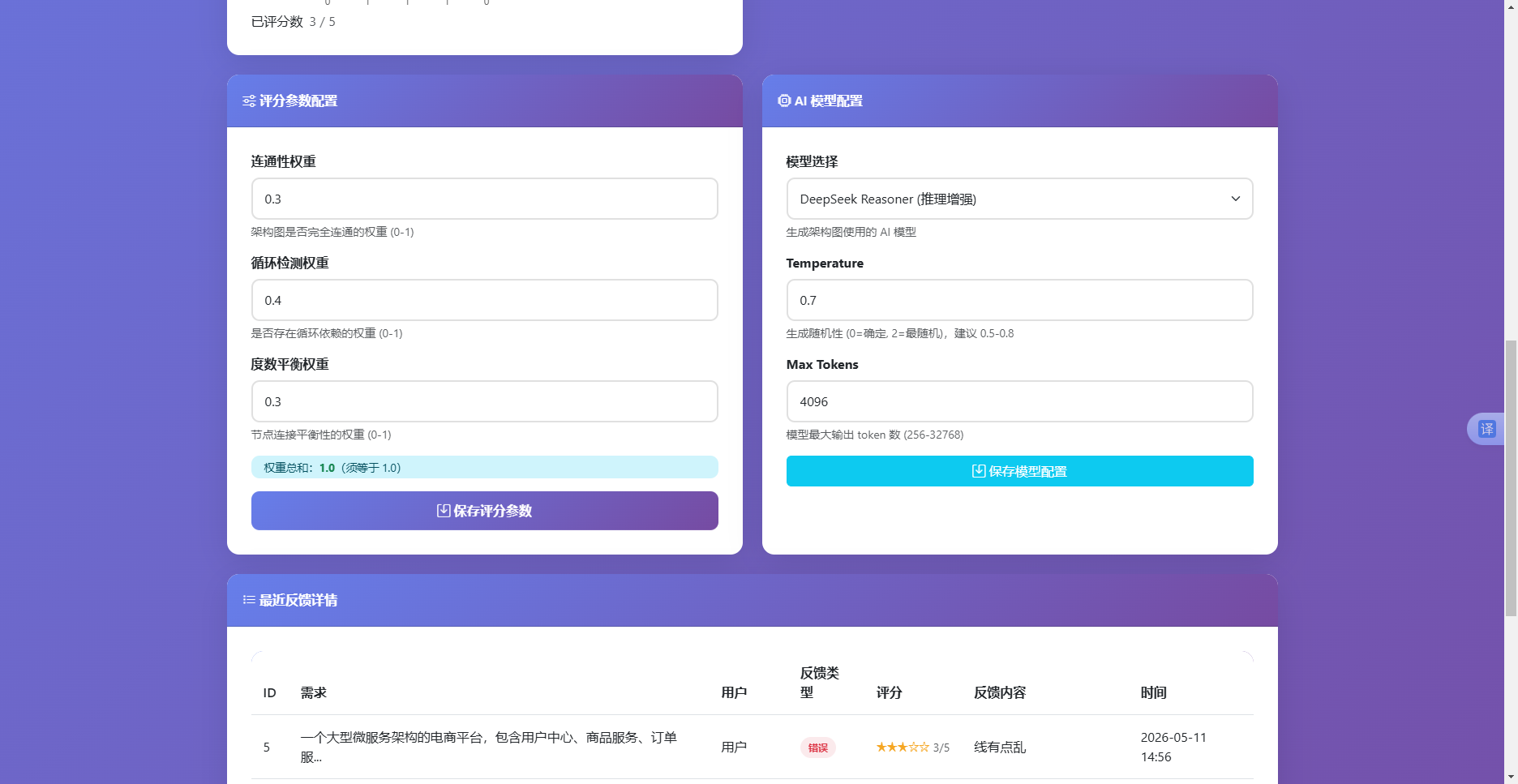
图4.11 参数配置界面