作者:卢建晖 - 微软高级云技术布道师
排版:Alan Wang
当账单到来的那一刻
在 2024 年和 2025 年的大部分时间里,"Agent"更多还是一个演示概念。而到了 2026 年,它已经成为云账单中的一个独立成本项。
如今,几乎所有主流模型提供商------包括 OpenAI、Anthropic、Google、Mistral、DeepSeek,甚至是部署在 Kubernetes 集群内部的开源权重推理服务------都采用按 Token 计费的模式。输入 Token、输出 Token、缓存 Token、推理 Token、工具调用 Token......统统都要计费。虽然单位 Token 的价格已经下降,但自主智能体消耗的 Token 数量却增长了一个数量级。
我反复参考的一份资料,是 Enterprise Agent Workshop 的第二个模块------《Token 经济学与成本控制》。其核心观点可以简单概括为:智能体系统并不是聊天应用。聊天应用中,用户每进行一次交互,通常只会触发一次模型调用。而智能体则不同:一次调用用于制定计划,一次调用用于选择工具,一次调用用于解释工具返回结果,一次调用用于决定下一步行动,一次调用用于生成总结------然后它还会不断循环。如果工具本身又会调用模型,成本还会继续放大。再加上重试和反思机制,调用次数进一步增加。
因此,现在需要思考的问题已经不再是:"模型每百万 Token 的价格是多少?"而是:"我的系统架构,每处理一次用户请求到底要花多少钱?"
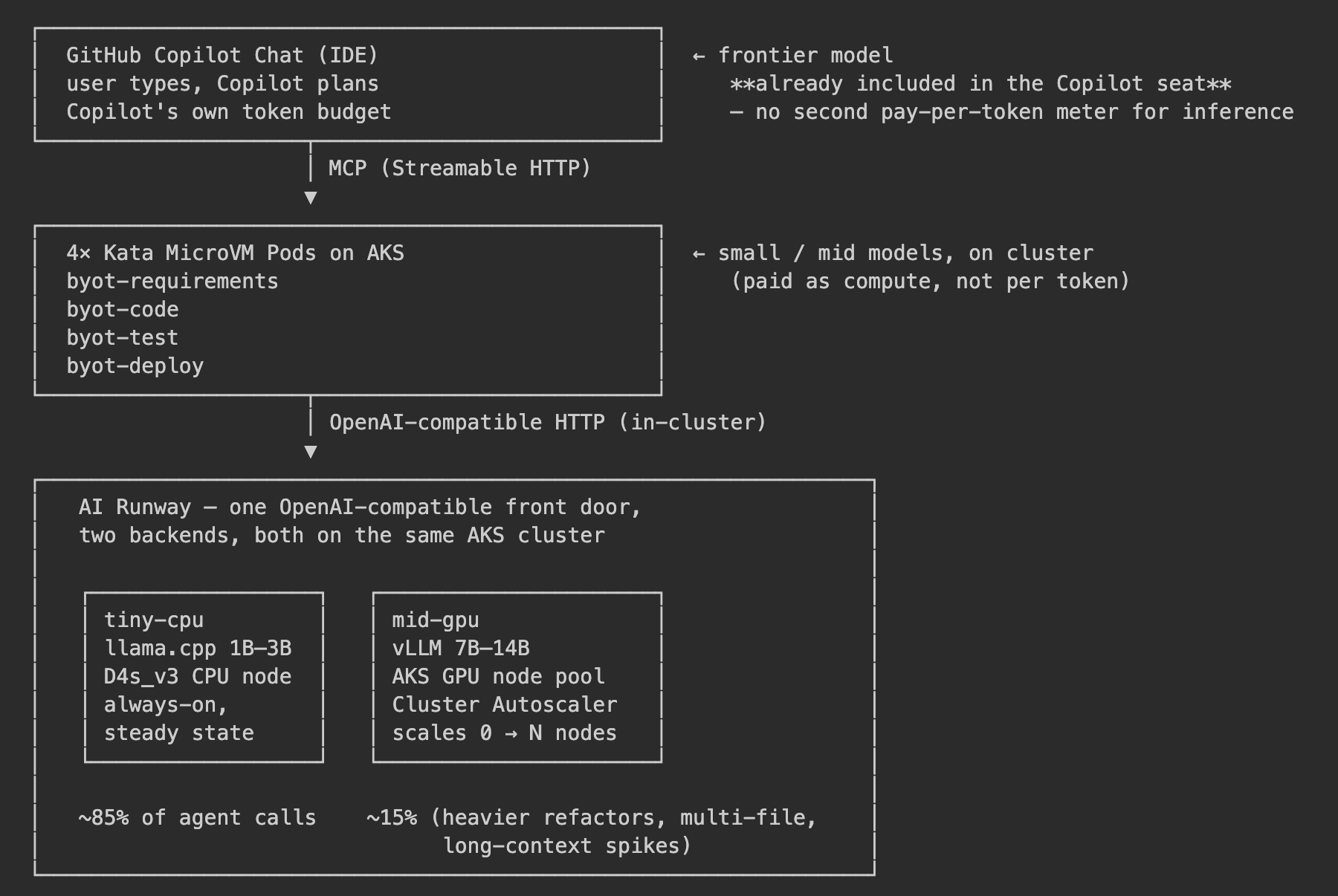
本文要介绍的,正是一套专门为回答这个问题而设计的架构。同时,它也不会牺牲企业级场景真正需要的安全能力。这套参考架构来自 BYOT_Dev 项目仓库:一个由四个智能体组成的软件开发生命周期(SDLC)流水线:需求分析 → 代码生成 → 测试 → 部署 ,它运行在 AKS 之上,每个 Agent 都被隔离在独立的 Kata MicroVM 中,每个 Agent 通过 MCP 向 GitHub Copilot Chat 暴露工具能力,所有 Agent 共享一个运行在集群内部的小语言模型服务端点,模型服务由 AI Runway 提供。
为什么 Agent 工作负载会迅速推高 Token 成本
有三个因素会叠加放大成本。
-
自主性导致调用次数激增。 当用户在 IDE 中输入:"帮我构建一个 URL 缩短服务",看起来只是一次简单请求,但对于一个由四个 Agent 组成的流水线来说:澄清需求、生成代码、编写测试、生成 Kubernetes 部署清单,整个过程中可能已经发生了:30~200 次模型调用,而其中大多数调用对用户来说是完全不可见的。
-
推理能力会消耗大量输出 Token。 现代推理模型在回答之前会先"思考"。这些隐藏的推理过程同样需要计费。因此:一个最终只输出 5 行内容的回答,背后可能已经消耗了:3000 个推理 Token。
-
上下文膨胀。 每一次工具执行的结果,都会被重新注入到下一轮模型调用中。例如:一次代码审查产生了一个 50 KB 的结果。接下来进行代码重构时,这 50 KB 内容又会成为新的上下文。随着会话不断深入,成本增长速度往往不是线性的,而是超线性的。
你无法通过提示词优化突破这些限制。唯一可持续的解决方案是:架构优化。 而这种优化主要依赖三个杠杆。
| 杠杆 | 实际含义 |
|---|---|
| 模型分层 | 小任务使用便宜的小模型;只有编排与判断任务才使用前沿模型 |
| 部署分层 | 根据成本选择运行位置:CPU、GPU 或云端 API |
| 协议分层 | 使用 MCP 等标准协议,让昂贵的大模型将子任务交给廉价模型执行 |
本文介绍的架构同时利用了这三个杠杆。
心智模型:前沿模型负责思考,小模型负责执行
我们看这张图:
plain
spec:
image: ghcr.io/kaito-project/aikit/llama3.2:1b
model:
id: "kaito/llama3.2-1b"
source: huggingface
engine:
type: llamacpp
provider:
name: kaito
overrides:
resource:
instanceType: Standard_D4s_v3
resources:
cpu: "2"
memory: "4Gi"随后,AI Runway 会自动完成以下工作:
-
选择推理引擎
-
CPU 场景使用 llama.cpp
-
GPU 场景使用 vLLM 或 Dynamo
-
-
选择模型提供方
-
当前支持 KAITO
-
后续将支持更多 Provider
-
-
从 AIKit 模型目录拉取镜像
-
在 http://llama3-2-1b-cpu.airunway-models.svc:80/v1 开放兼容 OpenAI 规范的服务。
关于仅使用 CPU 示例的说明。 需要特别说明的是,本仓库刻意采用了 CPU + Llama-3.2-1B 的组合,目的是证明这套架构能够运行在成本最低的节点规格上。但在生产环境中,你不应该默认认为 CPU 一定是最佳选择。真正合理的部署方案,应当根据具体场景来决定:
| 场景 | 推荐部署方式 |
|---|---|
| 高并发、任务范围明确且对延迟要求不高(例如"将需求扩展为要点列表") | 集群内 CPU 小语言模型(SLM,1B--3B 参数规模)------这正是本仓库所展示的场景 |
| 代码生成、代码重构、多文件推理等开发任务 | 通过 KAITO + vLLM 在集群内部部署 7B--14B 参数规模的 GPU 中型模型,并运行在支持从零自动扩缩容的 AKS GPU 节点池上 |
| 包含敏感企业数据且数据不能离开集群 | 集群内 GPU 部署,必要时结合机密计算能力 |
| 高级推理、任务规划、工具结果评估与决策 | 使用 GitHub Copilot 订阅已包含的前沿模型,通过 MCP 按需调用,而不是额外部署和维护一个按 Token 计费的推理服务端点 |
AI Runway 将这些部署选择简化为一次 YAML 配置修改,而不是一次系统重构。这种抽象层设计的核心价值在于 可选择性------它赋予你根据不同阶段的 Token 成本策略灵活调整架构的能力,而无需重写已有的 Agent 系统。
混合扩展:推理运行在 AKS 上,规划使用你已经付费的 Copilot Token
当前企业在 Token 成本控制方面最容易犯的一个错误,就是将模型部署方式视为非此即彼的选择:"全部部署在集群内部"或者"全部使用按 Token 计费的云端 API"。而真实世界的工作负载并非如此。真正能够节省成本的模式包含两个组成部分,而且这两部分其实都已经出现在你的账单中:
-
你已经部署好的 AKS。 一个用于承载常驻工作负载的小型 CPU 节点池。再加上一个能够从零自动扩容的 GPU 节点池,用于在 CPU 池无法满足需求时提供额外算力。它们运行在同一个 Kubernetes 集群,相同的 Kata 隔离机制,以及同一份 Azure 账单中。
-
开发者已经购买的 Copilot 订阅席位。 Copilot Chat 所使用的前沿模型已经包含在 Copilot Seat 的 Token 配额之中。因此:不要再额外部署一个新的推理服务来负责规划任务,而应该利用这部分已经付费的 Token 配额,通过 MCP 驱动运行在 AKS 上的廉价 Worker Agent。
这就是所谓的"混合模式"。不需要:额外的 Azure AI Foundry Endpoint,第二套按 Token 计费的推理服务,只需要:按需扩缩容的 AKS 计算资源,以及一个你已经为其付费的前沿模型"大脑"。
Agent 的调用流量大致如下:
-
大约 85% 的调用 通常:简短、范围明确、行为可预测。例如:"扩展这个需求","格式化这段 YAML","总结这个代码差异"。对于这些任务:部署在 CPU 节点上的 1B~3B 小模型即可在数秒内完成。此时成本来自节点费用,而不是 Token 费用。
-
大约 15% 的调用 属于更重型任务:多文件代码重构、长上下文推理、生成数百行代码(例如 400 行 FastAPI 应用)。这些场景需要 7B~14B 参数规模的 GPU 模型。
-
整个流程中的规划和决策工作,都由 Copilot 订阅席位所包含的前沿模型完成------无论你是否构建 BYOT,这部分费用其实都已经包含在用户已经支付的 Copilot 订阅中。
杠杆 A ------ 在同一个 AKS 集群中部署可从 0 扩展到 N 的 GPU 节点池
保持原有的始终运行的 tiny-cpu ModelDeployment。同时增加一个运行在 GPU 节点池上的中型模型部署。GPU 节点池创建时大小为 0,并由 AKS Cluster Autoscaler 管理。
plain
az aks nodepool add \
--cluster-name $CLUSTER \
--resource-group $RG \
--name gpupool \
--node-vm-size Standard_NC24ads_A100_v4 \
--node-count 0 \
--min-count 0 \
--max-count 4 \
--enable-cluster-autoscaler \
--node-taints sku=gpu:NoSchedule \
--workload-runtime KataVmIsolation
plain
# airunway/modeldeployment-mid-gpu.yaml (sketch)
spec:
image: ghcr.io/kaito-project/aikit/qwen2.5:7b
engine: { type: vllm }
provider:
name: kaito
overrides:
resource:
instanceType: Standard_NC24ads_A100_v4
nodeSelector: { agentpool: gpupool }
tolerations: [{ key: sku, operator: Equal, value: gpu, effect: NoSchedule }]
resources: { cpu: "4", memory: "32Gi", nvidia.com/gpu: "1" }
scaling: { replicas: 0, maxReplicas: 4 }这里最关键的技巧是:replicas: 0 ,配合 autoscaler min-count = 0。意味着当没有任何请求需要使用中型模型时,GPU Pod 不运行,GPU 节点不存在,GPU 不产生任何费用。当第一条请求到来时,AI Runway 将副本数扩展到 1,Cluster Autoscaler 创建 GPU 节点,Kata Sandbox Pod 被调度到该节点。当流量消失后,Replica 再次缩容到 0,GPU 节点回收至 0。整个过程全部发生在 AKS 内部。Agent 不需要离开集群寻找 GPU 资源。
杠杆 B ------ 复用你已经付费购买的 Copilot Frontier Token
这是大多数 Token 成本分析文章忽略的关键点。所有使用 BYOT 的开发者本身已经拥有 Copilot Seat 。而 Copilot Seat 已经包含 Frontier Model 的 Token 配额。用户在 Copilot Chat 中输入内容时,这些 Token 已经开始被消费。例如 docs/workflow.md 中的编排循环------决定调用哪个工具,读取工具输出,汇总结果。这些操作消耗的 Token 全部来自 Copilot Seat 配额,而不是来自新的推理服务。
这意味着:
-
无需额外部署 OpenAI 或 Foundry 云端 Endpoint 作为"智能模型"。负责规划与决策的 Frontier Model 已经集成在开发者正在使用的 Copilot 中。
-
无需在 Agent → Frontier 的调用路径上引入新的按 Token 计费机制。实际上,调用方向恰恰相反:Frontier Model 位于整个工作流的上游,通过 MCP 调用各个 Agent 完成任务,而不是 Agent 去请求 Frontier Model。
-
这套架构唯一新增的 Token 消耗来自 Copilot Seat 自身的使用,而这一成本不会随着部署 BYOT Agent 数量的增加而增加。
最终的效果是:那些按 Token 计费成本较高的任务(如规划与决策),运行在企业已经购买的 Copilot Token 配额上;而那些计算成本较低但生成内容较长的任务,则运行在企业已经按节点时长付费的 AKS 计算资源上。
Agent 如何在两个 AKS 后端之间进行选择
位于 https://github.com/kinfey/Multi-AI-Agents-Cloud-Native/blob/main/code/BYOT_Dev/agents/app/airunway_client.py 的 Agent Framework 客户端,会从 ConfigMap 中读取 base_url 和 model 配置。这里提供了三种策略,复杂度依次递增:
-
按角色进行静态绑定。
byot-requirements和byot-test(成本低、任务单一)使用AIRUNWAY_BASE_URL=tiny-cpu。byot-code和byot-deploy(生成任务更重)使用AIRUNWAY_BASE_URL=mid-gpu。只需要修改一个 ConfigMap,再执行一次 Rollout 即可完成切换。 -
在工具内部采用"先尝试,再升级"策略。 每个工具都会首先尝试调用
tiny-cpu;如果回答过短、未通过质量检查,或者发生超时,则自动重试mid-gpu。小模型负责处理简单的 85% 请求;GPU 资源池只处理真正需要更强能力的 15% 请求。 -
在两者前面增加 AI Gateway。 将 Azure API Management 作为 AI Gateway 部署在两个 AI Runway 服务之前。Agent 始终只访问一个 URL;Gateway 负责执行语义缓存、Token 预算控制以及根据负载情况在
tiny-cpu与mid-gpu之间进行智能路由。两个后端始终运行在你的 AKS 集群中------Gateway 只负责路由,不参与推理。
一个粗略的 Token 成本估算
假设一次 Copilot Chat 会话,通过 BYOT Tower 触发了底层 Agent 共 30 次模型调用。如果这 30 次调用全部发送到外部 Frontier API,例如按照 每百万输出 Token 收费 5 美元 ,并且每次调用平均输出 2K Token ,那么:每次会话将额外产生约 0.30 美元 的底层模型成本------而这还要叠加在 Copilot Chat 已经为规划所消耗的 Seat Token 成本之上。
采用 AKS + Seat Tokens 混合模式之后:
-
25~26 次调用(约 85%) → 由已经为常驻 Agent 持续运行的 CPU 节点上的
tiny-cpu模型处理 → 边际成本约为 0 美元 -
4~5 次调用(约 15%) → 由
mid-gpu模型处理,仅在 AI Runway 扩容后按 GPU 节点运行时长计费,并且该成本会被落到同一节点上的所有并发 BYOT 用户共同分摊 → 成本约为 0.02~0.05 美元 -
规划 / 判断 → 已经包含在开发者已经购买的 Copilot Seat Token 配额之中 → 新增成本为 0 美元
原本每次会话约 0.30 美元 的按 Token 计费成本,将下降到约 0.02~0.05 美元 的纯 AKS 计算成本。同时,当没有人提出复杂问题时,GPU 节点会自动缩容到零,因此 GPU 成本也会回归为零。这就是整个架构的关键杠杆。之所以能够做到这一点,是因为:AI Runway 为所有 Agent 提供了统一的集群内部入口;AKS 提供了闲置时无需付费的弹性 GPU 计算能力;Copilot Chat 自带开发者已经预付费用的 Frontier"大脑"。
Kata MicroVM:为 Agent 代码戴上一顶"硬件级安全头盔"
成本只是 Agent 工作负载问题的一半。另一半,则是 Agent 所运行的那个"盒子"里面到底发生了什么。
今年早些时候,我发表了一篇文章:《使用 AKS 上的 Kata MicroVM,为 Copilot SDK Agent 戴上一顶"硬件级安全头盔"》。其核心观点可以概括如下:
传统容器就像一间共享屋顶的公寓------那个屋顶就是宿主机的 Linux 内核。对于一个由人工编写的服务而言,租户是可预测的。但对于一个 Agent 来说,真正的住户是模型本身,它会在运行时决定:执行哪个 Shell 命令,读取哪个文件,安装哪个 npx 包。这构成了一种全新的威胁模型。容器 Namespace 并不是为这种场景设计的。你真正需要的是:每个 Pod 都拥有自己独立的 Guest Kernel------也就是一个 MicroVM。
Kata Containers 是 Kubernetes 获得 MicroVM 能力的集成层。AKS 通过基于 Hyper-V 的 kata-vm-isolation RuntimeClass,将其以 Pod Sandboxing 的形式提供出来。当 Node Pool 使用 --workload-runtime KataVmIsolation 创建时,这一能力会自动启用。
在 BYOT_Dev 中,每一个 Agent Pod 都配置了:
plain
spec:
runtimeClassName: kata-vm-isolation
containers:
- name: agent
securityContext:
runAsNonRoot: true
readOnlyRootFilesystem: true
capabilities:
drop: ["ALL"]
seccompProfile:
type: RuntimeDefault随后,其余工作全部由 AKS 完成。Pod 会在容器真正启动之前,先启动一个真正的 Hyper-V MicroVM,并拥有自己独立的 Guest Kernel。验证方式只需要一条命令:
plain
kubectl -n agents exec deploy/byot-requirements -- uname -r
# compare with the kernel on the node --- they differ → microVM confirmed该仓库还通过 kubernetes.io/hostname 上的 podAntiAffinity 策略,实现了每个节点只部署一个 Agent。因此,这四个 Agent 分别运行在四台物理隔离的 Kata Host 上。即使其中一个 Agent 发生了模型逃逸,它也无法通过共享宿主机 Kernel 影响其他 Agent------因为这里根本不存在共享的宿主机 Kernel。
这与 Token 经济学的联系在于:当你开始信任一个廉价的集群内模型,让它去执行真实客户代码上的 Agent 循环时,你的安全边界必须比普通容器更强,而不是更弱。Kata 正是那个让"低成本"与"高安全"不再互相冲突的关键技术。同时,由于 AKS Pod Sandboxing 在 CPU Pool、GPU Pool,以及未来新增的任何 Burst Node Pool 上都采用完全一致的机制,因此,上文介绍的混合部署策略并不会削弱整体隔离能力。无论 Pod 部署在哪一个层级,它始终都会启动属于自己的 Guest Kernel。
MCP:GitHub Copilot Chat 如何真正驱动这座 Agent Tower
最后一块拼图是协议。运行在 Kata MicroVM 中的 Agent,如果没有外部能够调用它们,就毫无意义。而这个已经存在于用户工作流中的"调用者",就是 VS Code 中的 GitHub Copilot Chat 。Model Context Protocol(MCP) 是 Copilot Chat(以及几乎所有成熟的 Agent IDE)用于与远程工具服务器通信的标准协议。在本仓库中,每一个角色都通过 FastMCP over Streamable HTTP 对外暴露自己的工具能力,具体实现可以参考 agents/app/main.py 和 agents/app/roles/ 下各个角色对应的工具集合。
服务暴露虽然只是一个小细节,却非常重要。本仓库为每个角色对应的 Service 都采用了 type: LoadBalancer(见 k8s/services.yaml),原因如下:
-
kubectl port-forward无法用于 Kata Pod(监听器运行在 MicroVM 内部,而不是宿主机 Sandbox 的网络命名空间中)。 -
kubectl proxy虽然可以工作,但会把 Copilot 固定到 localhost,并且需要持续运行一个本地进程。 -
LoadBalancer可以为每个 Agent 分配一个公网 Azure IP,使 IDE 能够直接访问。
当四个 LoadBalancer 的 IP 地址写入 .vscode/mcp.json 之后,Copilot Chat 在 Agent 模式下就会识别出四个 MCP Server:
-
byot-requirements -
byot-code -
byot-test -
byot-deploy
此时,用户只需要输入:
"使用 byot tower,将这个想法------一个带点击统计功能的短链接服务------从需求分析一直完成到部署。"
背后实际发生了什么(docs/workflow.md)
-
Copilot 的 Frontier 模型负责规划整个执行流程。 消耗 Frontier Token:很少,但承担的是高价值推理。
-
它首先通过 MCP 调用:
plain
byot-requirements.gather_requirements({
"idea": "URL shortener..."
})这里不会消耗 Frontier 推理资源,真正执行工作的,是集群内运行的 Llama-3.2-1B 小模型 。
- 随后调用:
plain
byot-code.implement_from_requirements({...})同样如此------由集群内部的小模型完成代码生成。
- 接着调用:
plain
byot-test.generate_test_plan({...})依旧由集群内的小模型执行。
- 最后调用:
plain
byot-deploy.generate_k8s_manifest({...})同样由集群侧的小模型完成。
- 最后,Copilot 的 Frontier 模型读取四个 Agent 返回的结果,并向用户输出一份完整、一致的总结。消耗 Frontier Token 仍然很少。
昂贵的大模型一共只负责了 5 次决策。廉价的小模型则完成了 4 次长文本生成。这正是 Token Economics 所带来的收益,也是这种架构能够避免厂商锁定的原因------MCP 是开放标准。
将架构看作一份成本预算表
把整张架构图转换成一张单位成本表,并明确混合部署的成本来源:
| 层级 | 成本来源 | 控制因素 |
|---|---|---|
| 用户输入 + IDE 规划 | Copilot Seat(按用户订阅) | 已经支付,固定费用 |
| Frontier 编排 Token | Copilot Seat 自带 Token 配额,用于 MCP 规划,无需单独 Endpoint | Copilot 发起 Agent 循环次数 |
| Tool Call 流量 | Azure LoadBalancer 出站流量 | 在该规模下几乎可以忽略 |
| tiny-cpu 推理(稳定态,约 85%) | AKS CPU 节点小时费用(本 Demo 使用 1× D4s_v3) | Replica 数量、模型大小、Batch Size |
| mid-gpu 推理(自动扩缩,约 15%) | 同一 AKS 集群中的 GPU 节点小时费用,仅在 Replica > 0 时计费 | Cluster Autoscaler / Karpenter(min=0、max=N、Scale-to-zero) |
| 硬件隔离 | AKS Pod Sandboxing(Kata),与节点费用相同 | 是否启用(建议始终开启) |
| Provider 切换 | AI Runway YAML 配置 | 一次 kubectl apply |
这里有三个值得注意的地方。
第一,大部分按请求变化的成本已经从 Token 计费转移到了节点计费。CPU 节点小时数,比按调用 Token 消耗更容易预测、更容易做成本分摊,也更容易设置预算上限。你知道自己购买了多少个 D4s_v3 CPU 核心。但你无法提前知道,一个 Frontier 模型最终会决定消耗多少 Token。
第二,GPU 容量不再是一项固定投入,而且始终留在 AKS 内部。GPU Node Pool 默认保持 0 个节点。只有 AI Runway 真正需要时,它才会自动扩容,并且是在同一个集群、同一个 Kata RuntimeClass 下完成调度。无需第二个 Region。无需第二个租户。也无需第二份按 Token 计费的账单。
第三,Frontier Brain 被复用了,而不是重新购买。驱动整个 Agent Tower 的规划和判断全部运行在开发者已经购买的 Copilot Seat Token 配额之上。BYOT 并没有额外部署一个"智能模型"云端 Endpoint。因此,也就不存在第二个需要持续关注的按 Token 收费计量器。
另外,由于 Kata AKS Pod Sandboxing 已经包含在 AKS 中 ,并且对 CPU Pool 与 GPU Pool 的工作方式完全一致,因此,在计算成本之外,额外增加的安全成本为 零。
这正是为什么,这套架构能够同时做到:成本可感知,弹性可扩展,安全可保障。而过去,这三者通常只能三选二。如今,它们可以同时成立。
六条命令,完成全部部署
为了完整起见,下面是仓库 README.md 中给出的部署顺序。
plain
# 0. 一次性准备:az login、kubectl、helm、docker、aks-preview
az login
# 1. 创建启用 Kata、ACR、AzureLinux 的 AKS 集群
bash infra/01-create-aks-kata.sh
# 2. 安装 AI Runway Controller 与 KAITO Provider(固定 v0.5.0)
bash infra/02-install-airunway.sh
# 3. 通过 AI Runway ModelDeployment 在 CPU 上部署 Llama-3.2-1B
bash infra/03-deploy-qwen.sh
# 4. 构建并推送统一 Agent 镜像到 ACR
bash infra/04-build-push-agents.sh
# 5. 部署 4 个采用 Kata 隔离的 MCP Agent
bash infra/05-deploy-agents.sh
# 6. 输出 GitHub Copilot 使用的 MCP 公网 Endpoint
bash infra/06-show-mcp-endpoints.sh将输出的 IP 地址写入 .vscode/mcp.json,打开 Copilot Chat,你就拥有了一套完整可运行的 Agent Tower:
-
采用硬件级隔离
-
具备成本感知能力
-
由 CPU 上的小模型提供推理
-
由开发者已经购买 Seat 的 Frontier 模型负责整体驱动
当业务规模增长时,只需在旁边增加一个支持 Scale-to-zero 的 mid-gpu ModelDeployment 即可。Agent 本身无需修改。Copilot 集成无需修改。整个推理过程依然全部留在 AKS 集群内部。
总结:贯穿始终的设计思路
让我们再把整条思路梳理一遍:
-
Token 经济学已经成为新的 SLO(服务等级目标)。 Agent 化工作负载会成倍增加模型调用次数,而每一次调用都有成本。真正能够改变成本曲线的,不是 Prompt,而是架构设计。
-
对模型进行分层,对部署位置进行分层。 将 Frontier 模型用于最高层的推理与决策;将小模型用于绝大多数实际工作;稳定态任务运行在集群内 CPU 上,而较重的约 15% 工作负载则运行在集群内 GPU 上。
-
将 AKS 的计算资源与已经购买的 Copilot Token 配额结合起来使用。 不要为了推理能力再额外增加一个按 Token 计费的云端推理 Endpoint。真正需要大量计算的任务应该交给支持 Scale-from-zero 的 AKS GPU 节点池;而规划工作则交给开发者已经拥有的 Copilot Seat Token 配额。这种组合既节省了 Token(无需新增按 Token 计费器),又具备弹性扩展能力(只有 AI Runway 发出请求时,集群才会扩容)。
-
AI Runway 将模型部署位置的切换变成了一次 YAML 修改。 今天运行的是 CPU 上的 Llama,明天可以切换成同一集群 GPU 上的 Qwen。Agent 代码完全无需修改。
-
对于 Agent 代码来说,Kata MicroVM 是不可妥协的。 租户已经不再是应用,而是模型本身。屋顶必须属于自己。AKS Pod Sandboxing 将这一能力变成开箱即用,并且对 CPU Pool 与 GPU Pool 的工作方式完全一致。
-
MCP 是连接两端的桥梁。 GitHub Copilot Chat 本身已经是一个 MCP Client。只需要将那些成本低廉的小模型 Worker 作为 MCP Tool 暴露出来,Frontier Brain 就能够直接调用它们------消耗的是 Copilot Seat 已经包含的 Token,而不是新增的 Token。
-
本文介绍的参考实现已经全部包含在这个仓库中。 仅需六条命令,即可完成:四个 Agent,一个运行在 CPU 上的小模型,完整的 MicroVM 硬件级隔离,真正可用的 GitHub Copilot Chat 集成。同时,还预留了一条无需修改 Agent、无需离开 AKS 即可逐步扩展的混合部署路径。
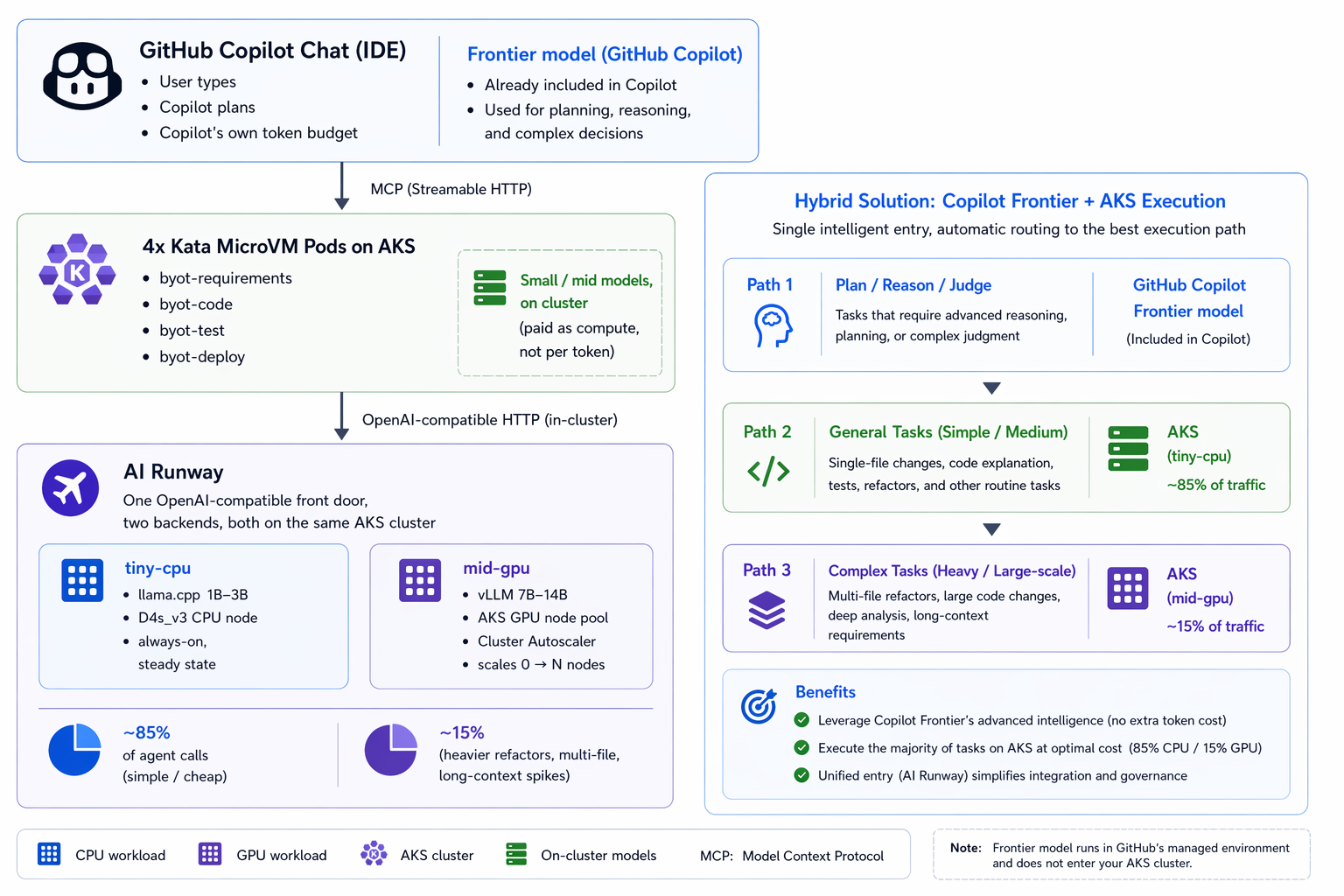
在 Agent 时代,一个容器不再只是应用程序的运行盒子。它同时也是一个承载不确定性和 Token 成本的盒子。MicroVM 负责加固这个盒子;AI Runway 负责让模型能够在同一个集群内的 CPU 节点与 GPU 节点之间自由切换,而无需重写任何代码;MCP 则让用户所使用的昂贵 IDE,从盒子外部驱动这个低成本 Worker,并且消耗的是已经预付费用的 Token。这就是整篇文章贯穿始终的核心思路。
构建属于你的 Agent Tower,也持续关注它的成本账单。