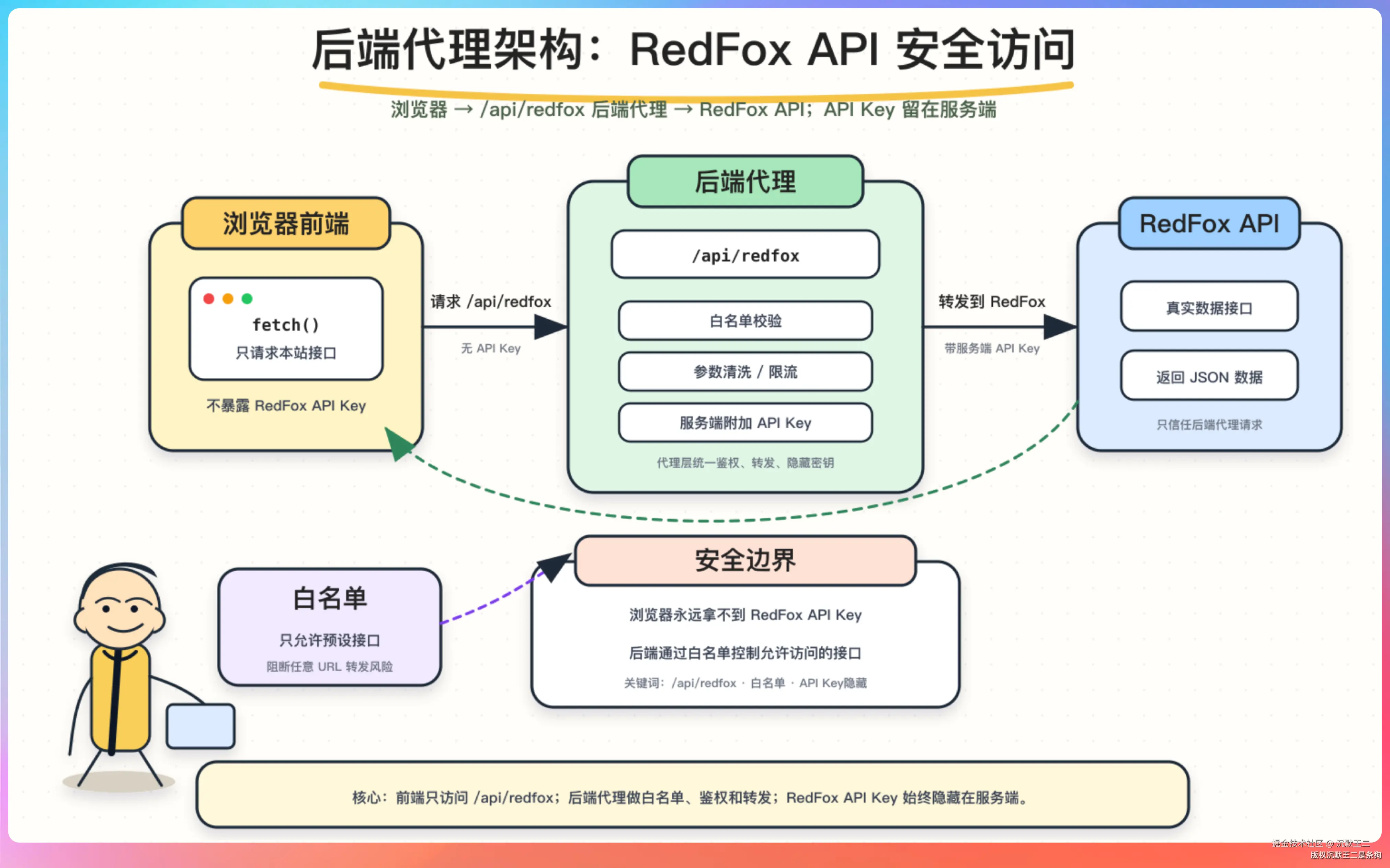
基于 Codex+红狐数据 Skill 和 API 搭了一个 AI 热点雷达,直接上网址和录屏,大家看一眼。
【视频】
每天凌晨自动跑一遍,把抖音、小红书、公众号三个平台上和AI相关的热点数据全部抓下来,扔给 LLM 做一轮结构化分析,给每条内容的算个评分。
打开页面,5分钟就能知道今天有哪些 AI 话题值得聊,非常方便。
这个项目用 Codex 前后也就是俩小时的调试,包括上线部署。
01、红狐数据 是什么?
红狐数据 是一个面向开发者的新媒体数据平台,提供了抖音、小红书、公众号、视频号、快手、微博、今日头条等多个平台的内容数据 API,覆盖账号信息、文章详情、作品列表、搜索查询等多个维度。
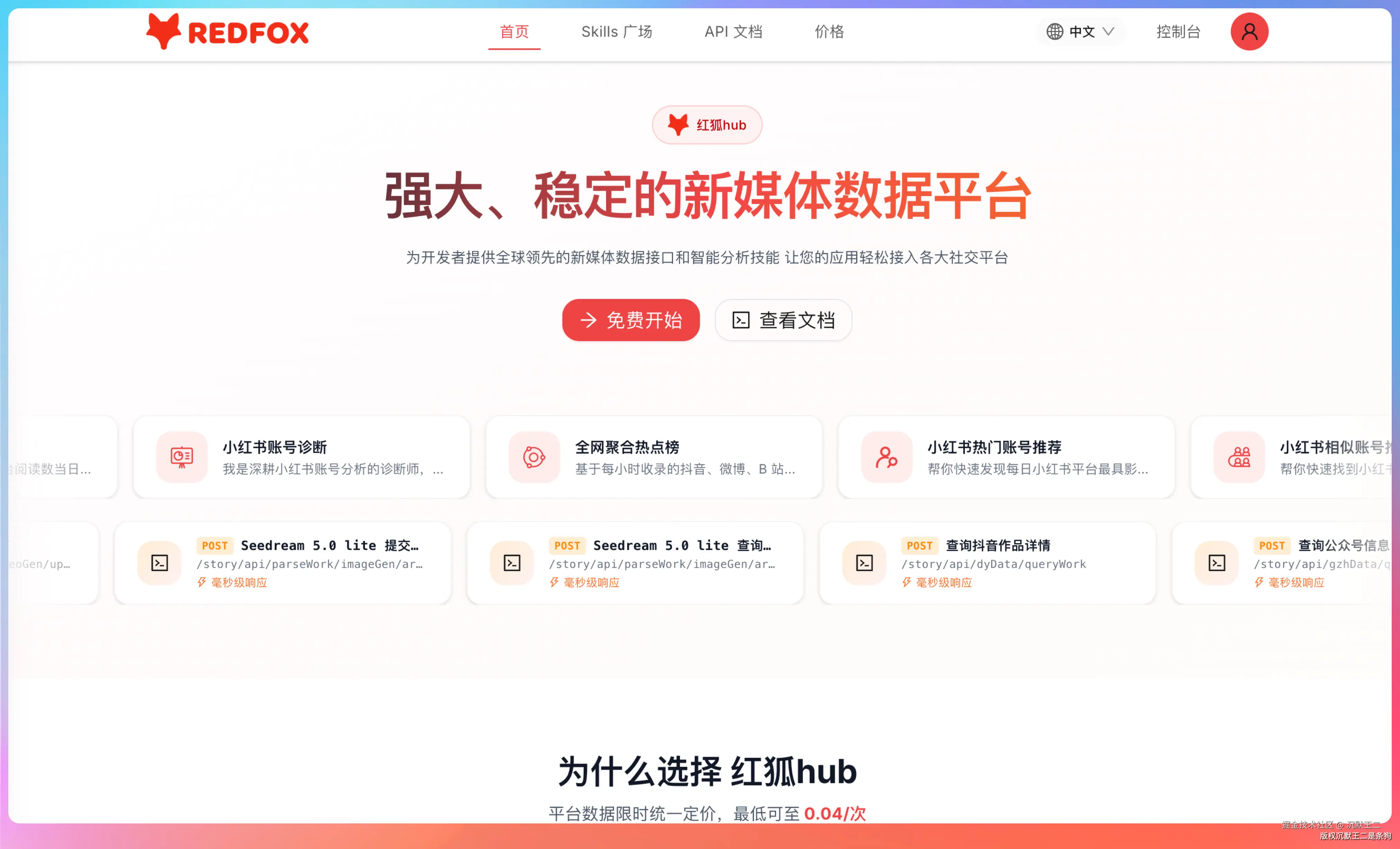
还有一个 Skills 广场,提供了 40 多个开箱即用的数据分析技能。
几个热门的调用量很高,公众号10w+文章推荐 3.6 万次,抖音热门账号推荐 2.5 万次,全网热点追踪 2.1 万次。
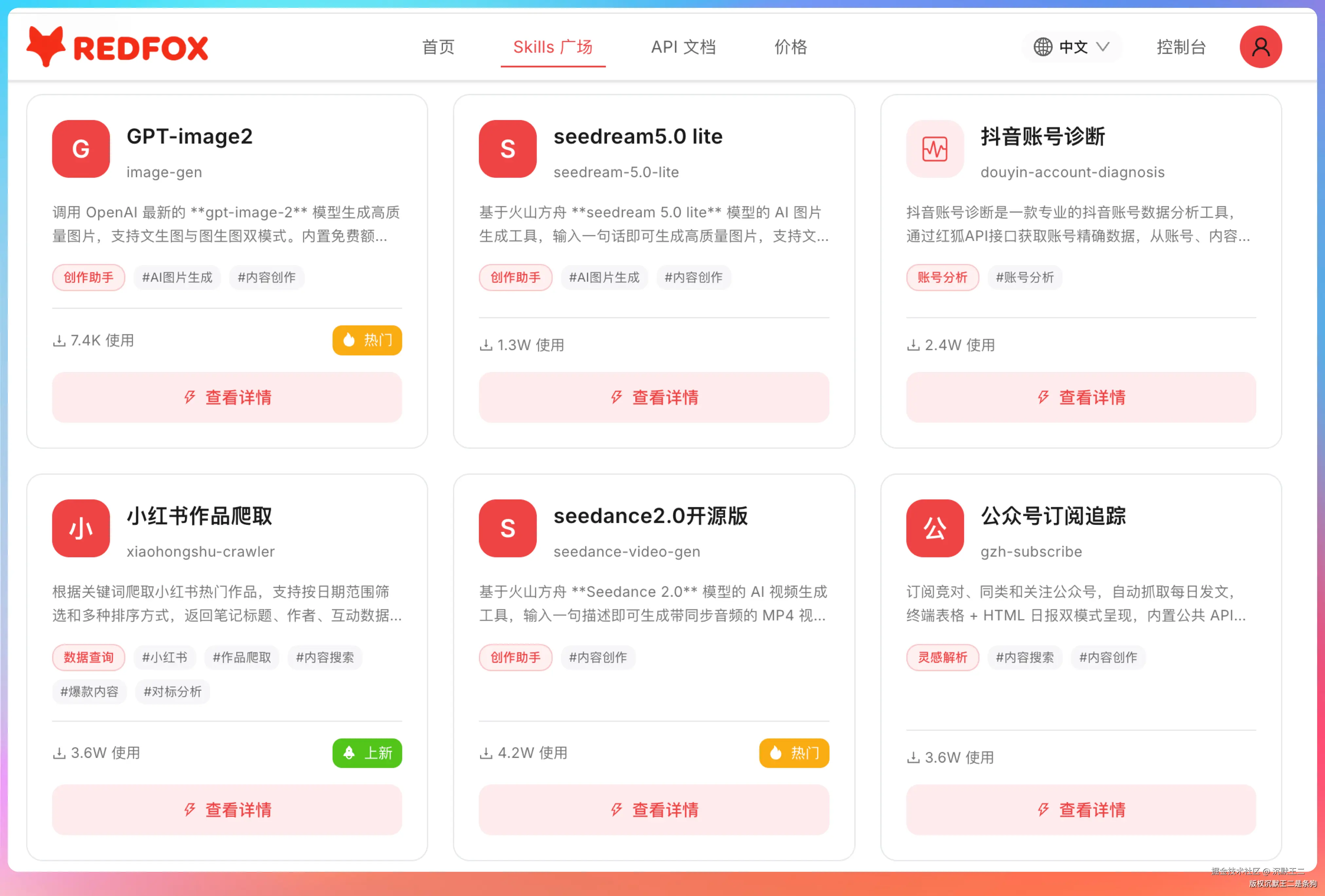
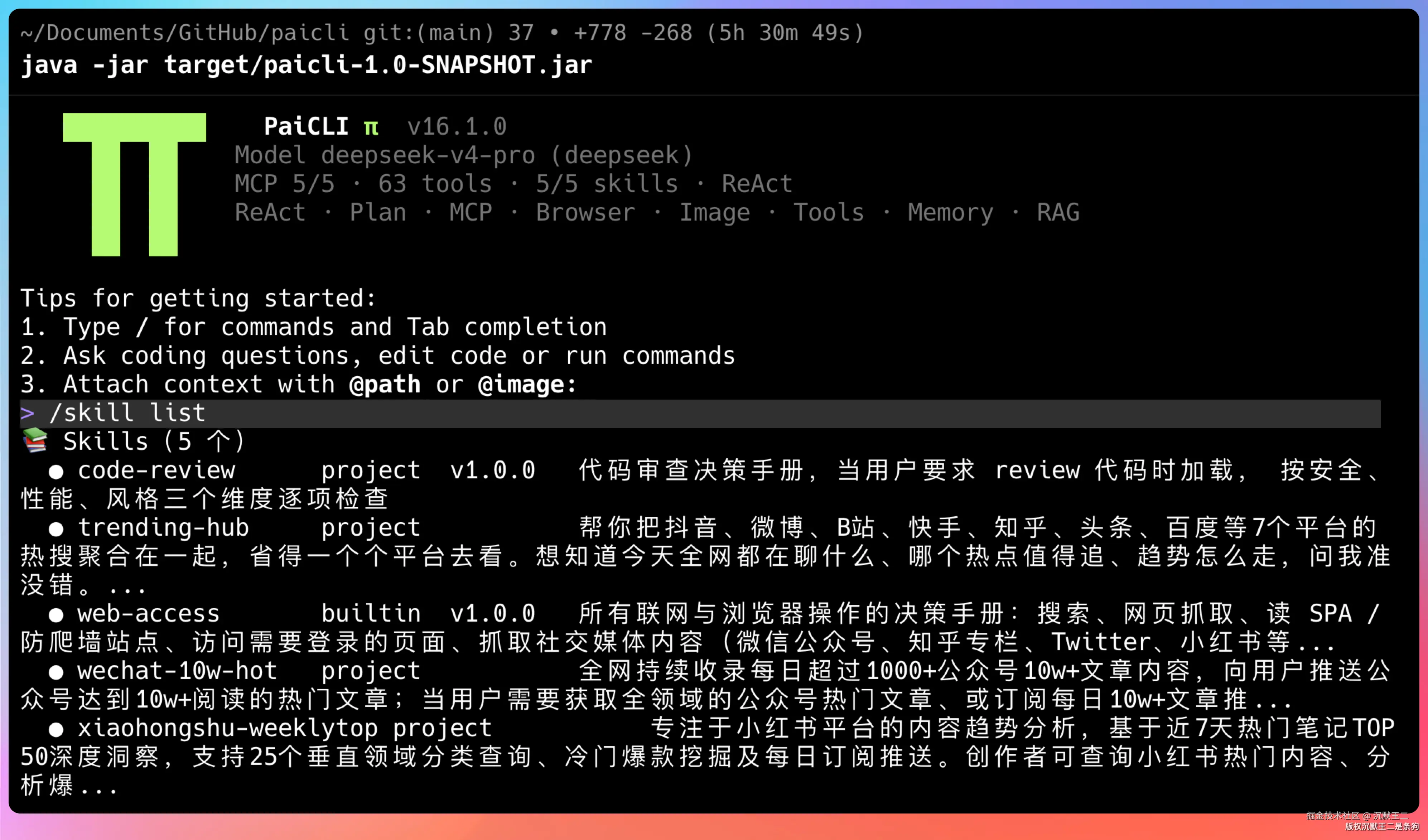
这些 Skill 可以下载到本地 Agent 工具里运行,Codex、Claude Code 都能用。
除了 Skill,还有四个大类的 API:
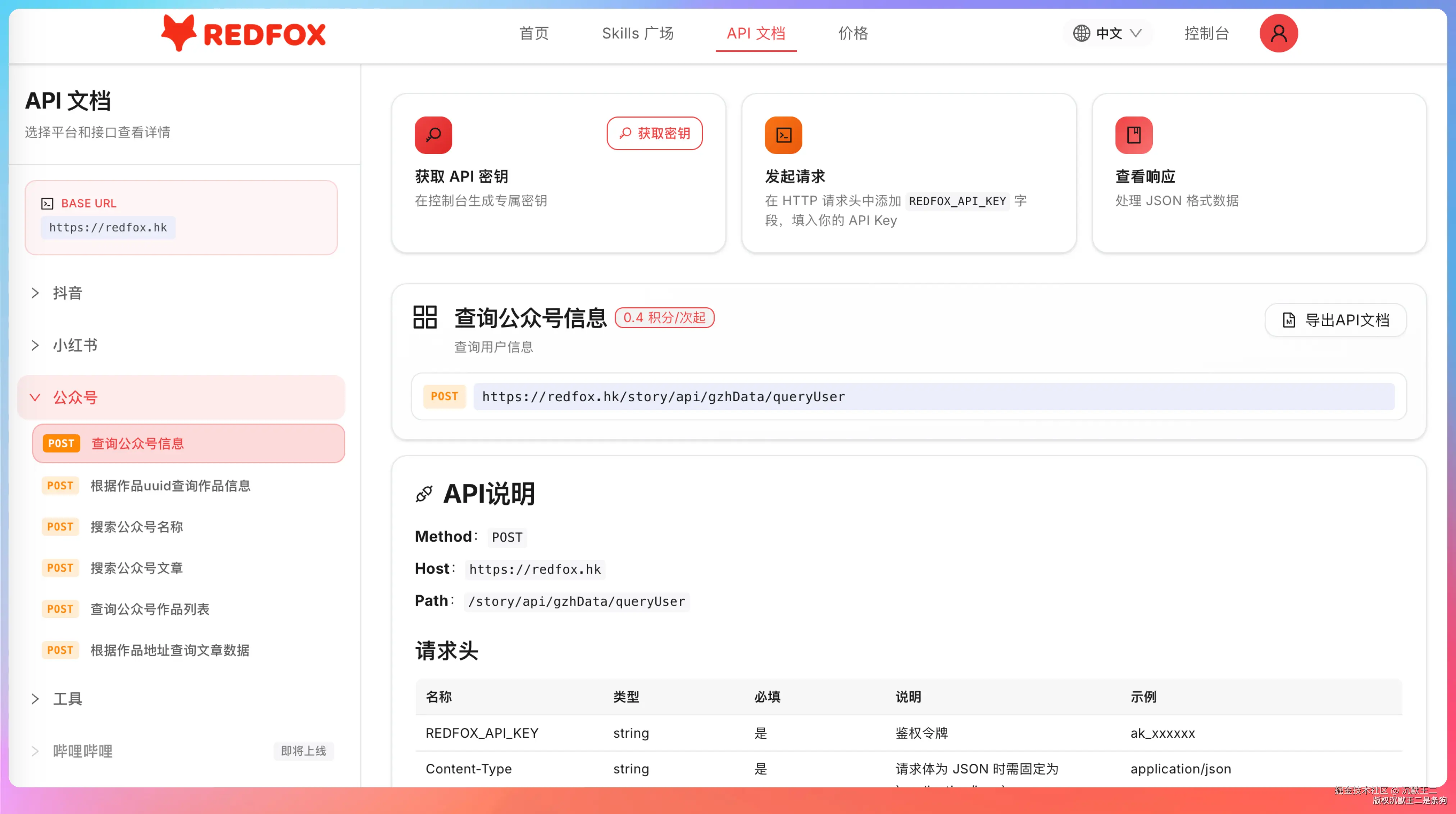
- 公众号:6个接口,覆盖账号搜索、文章搜索、账号信息查询、文章详情查询、作品列表查询、URL直查
- 小红书:2个接口,支持账号详情和作品详情查询
- 抖音:2个接口,账号和作品的基础信息查询
- 工具类:AI 图片生成(image2-GPT)、视频生成(Seendance 2.0)、图片生成(Seedream 5.0 lite)
对于开发者来说,红狐数据 的价值在于拿到 API 之后想怎么用就怎么用,搭看板、写脚本、接Agent、做自动化,都行。
AI 热点雷达就是这么搭出来的。
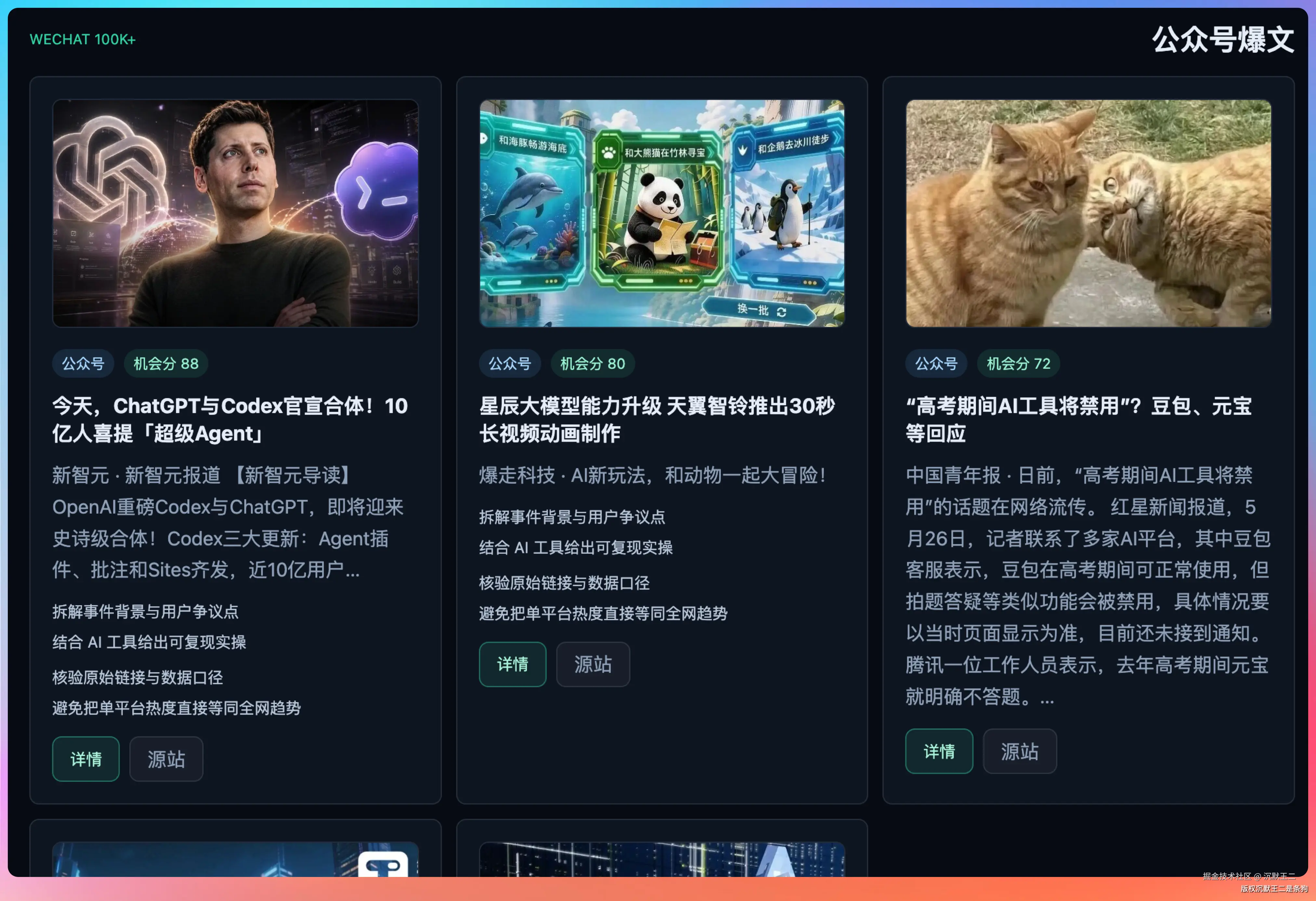
02、AI 热点雷达长什么样
打开 aihot.paicoding.com,整个页面分成几个核心区域。
每日摘要
页面顶部是 Agent 生成的每日摘要,今天总共采集了多少条数据、哪些话题值得关注。
分别显示抖音样本数量、小红书灵感数量、公众号爆文数量、以及 Agent 推荐条数。
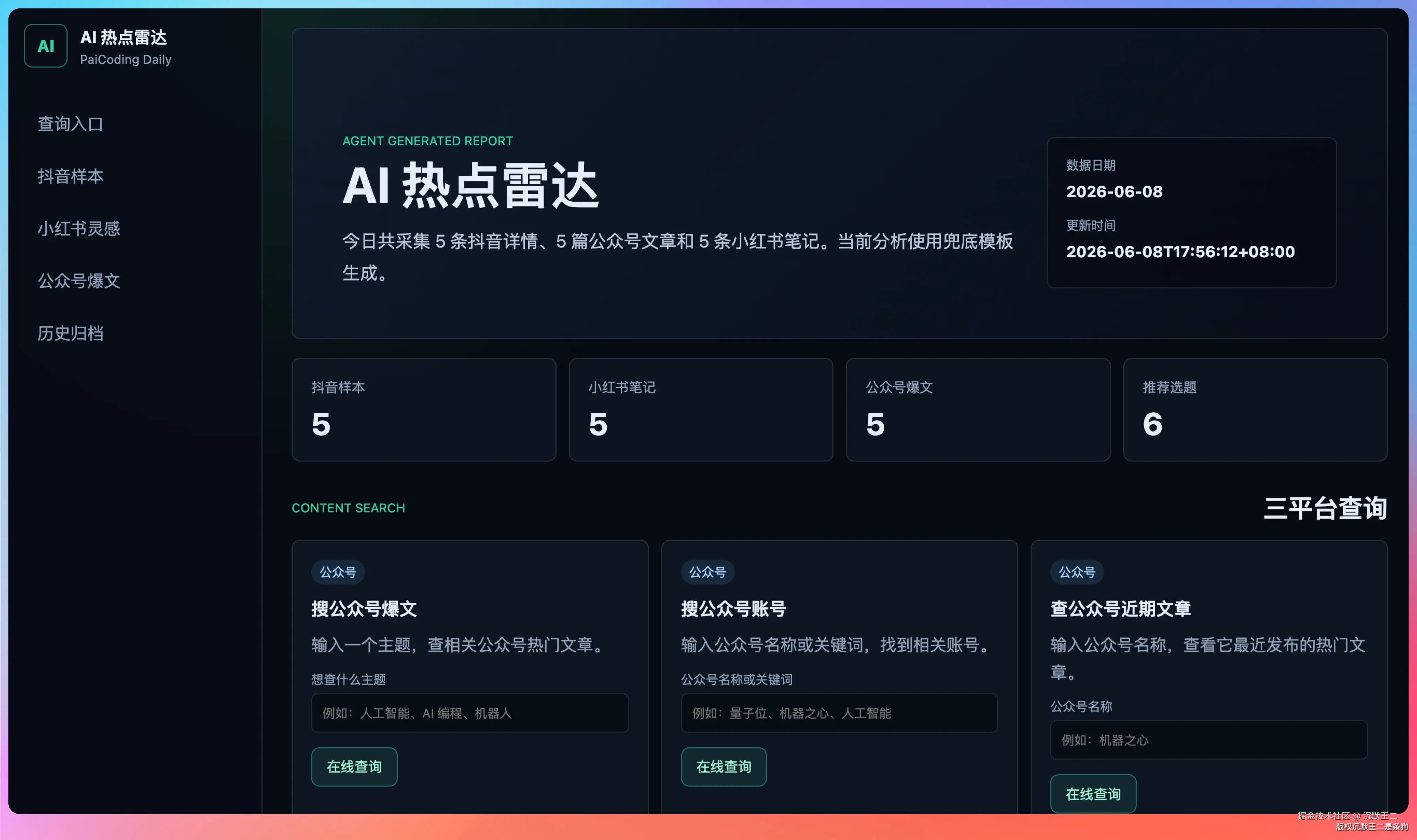
Agent 精选推荐
LLM 会从三个平台的数据里挑出最值得关注的内容,按机会评分(opportunityScore)排序。
拿 6 月 8 号的数据来说,评分最高的是新智元那篇《ChatGPT与Codex》,88分。Agent 给出的内容角度是"拆解事件背景与用户争议点"和"结合AI工具给出可复现实操"。
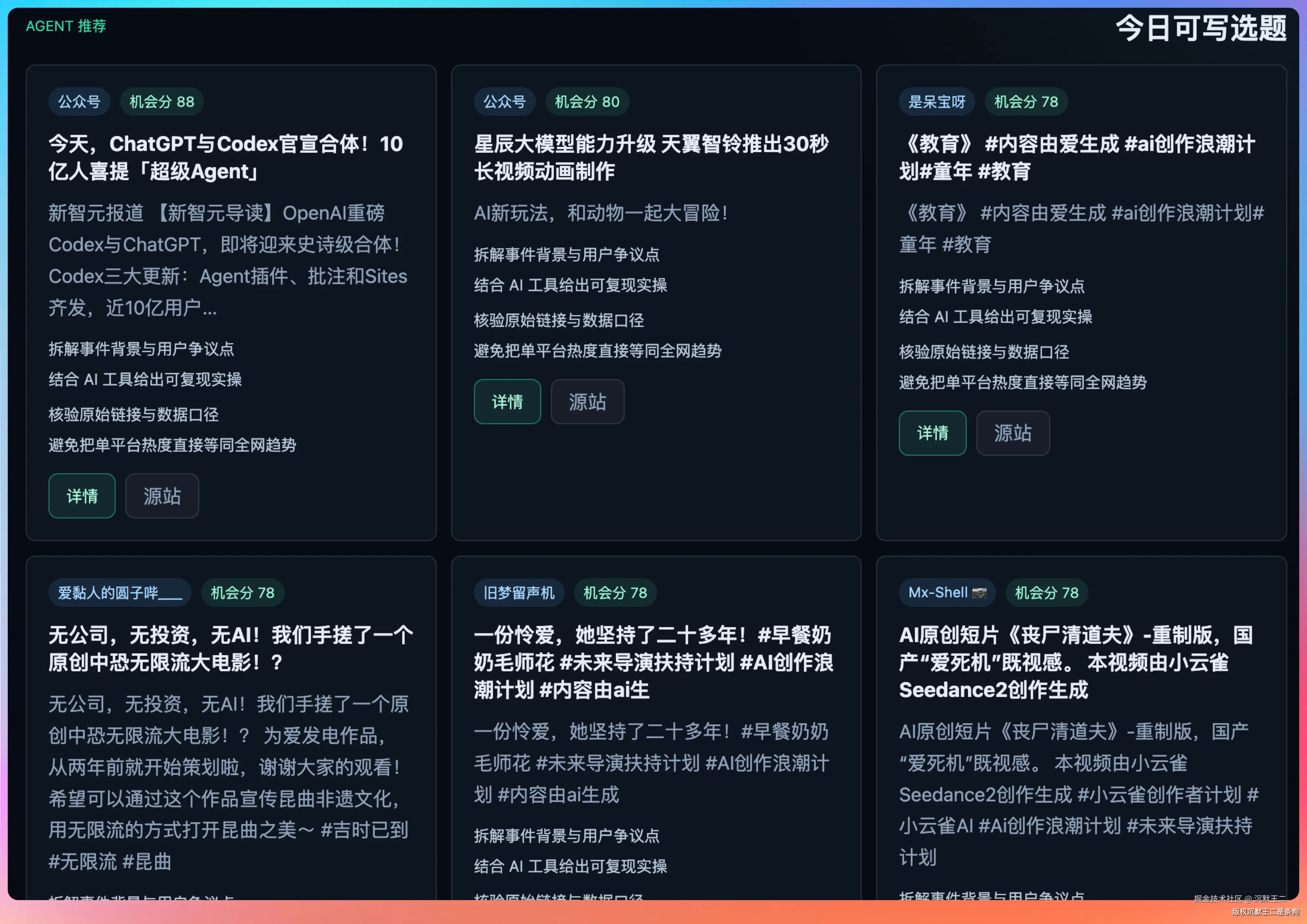
三平台数据面板
分三个区域展示各平台的原始数据。
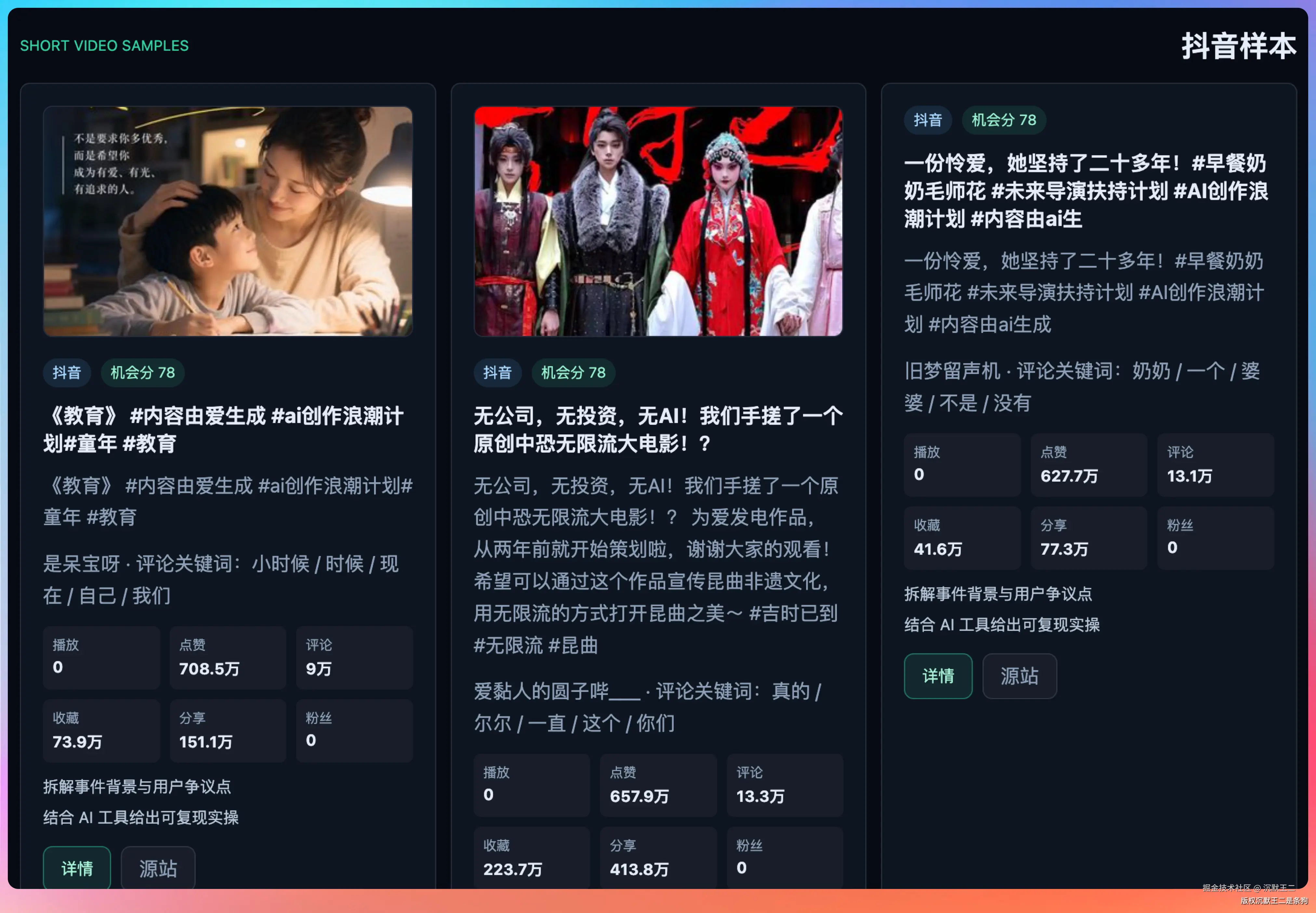
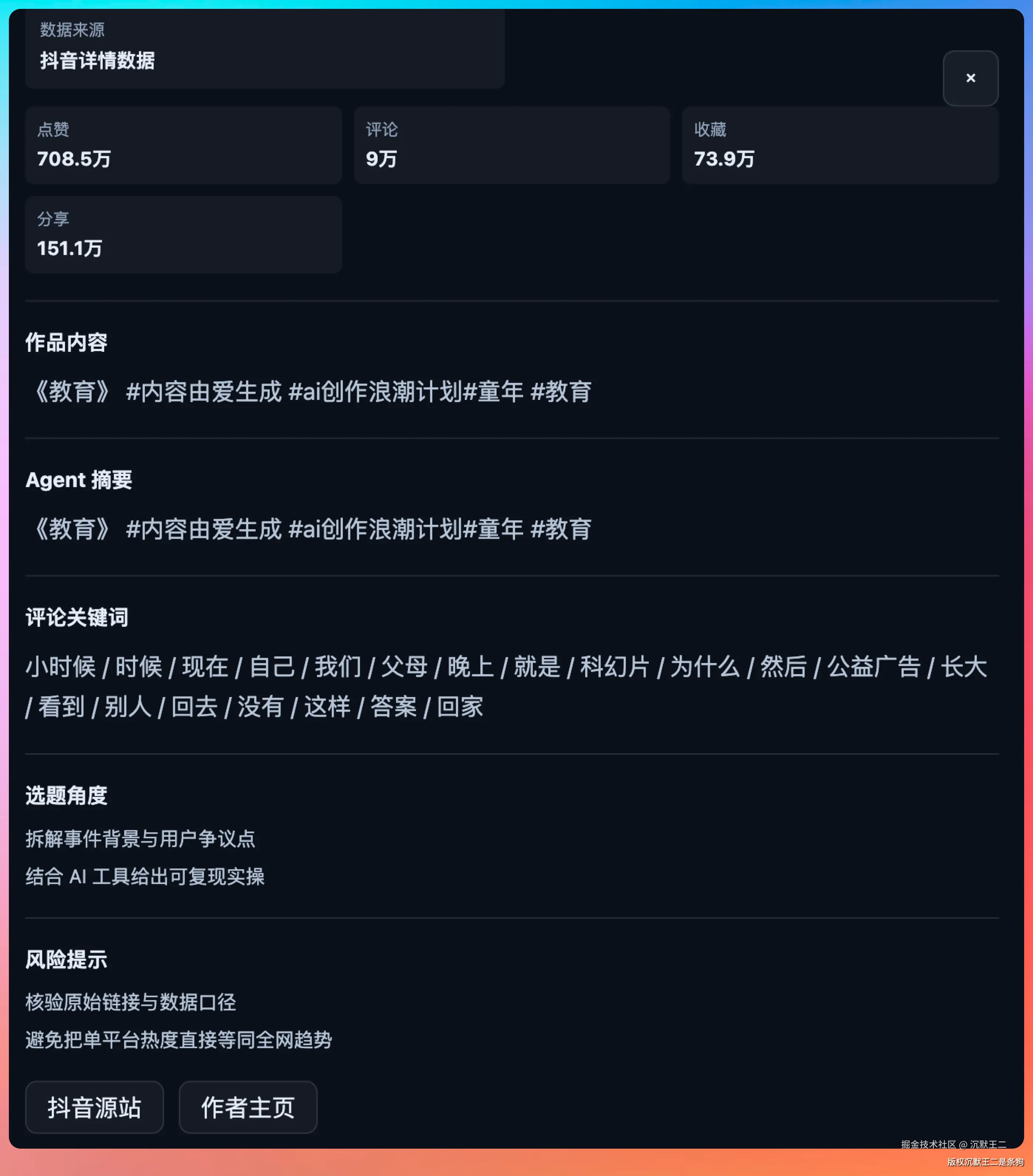
抖音样本:展示5条AI相关的热门视频,每条都带着点赞数、评论数、分享数、收藏数、评论热词。
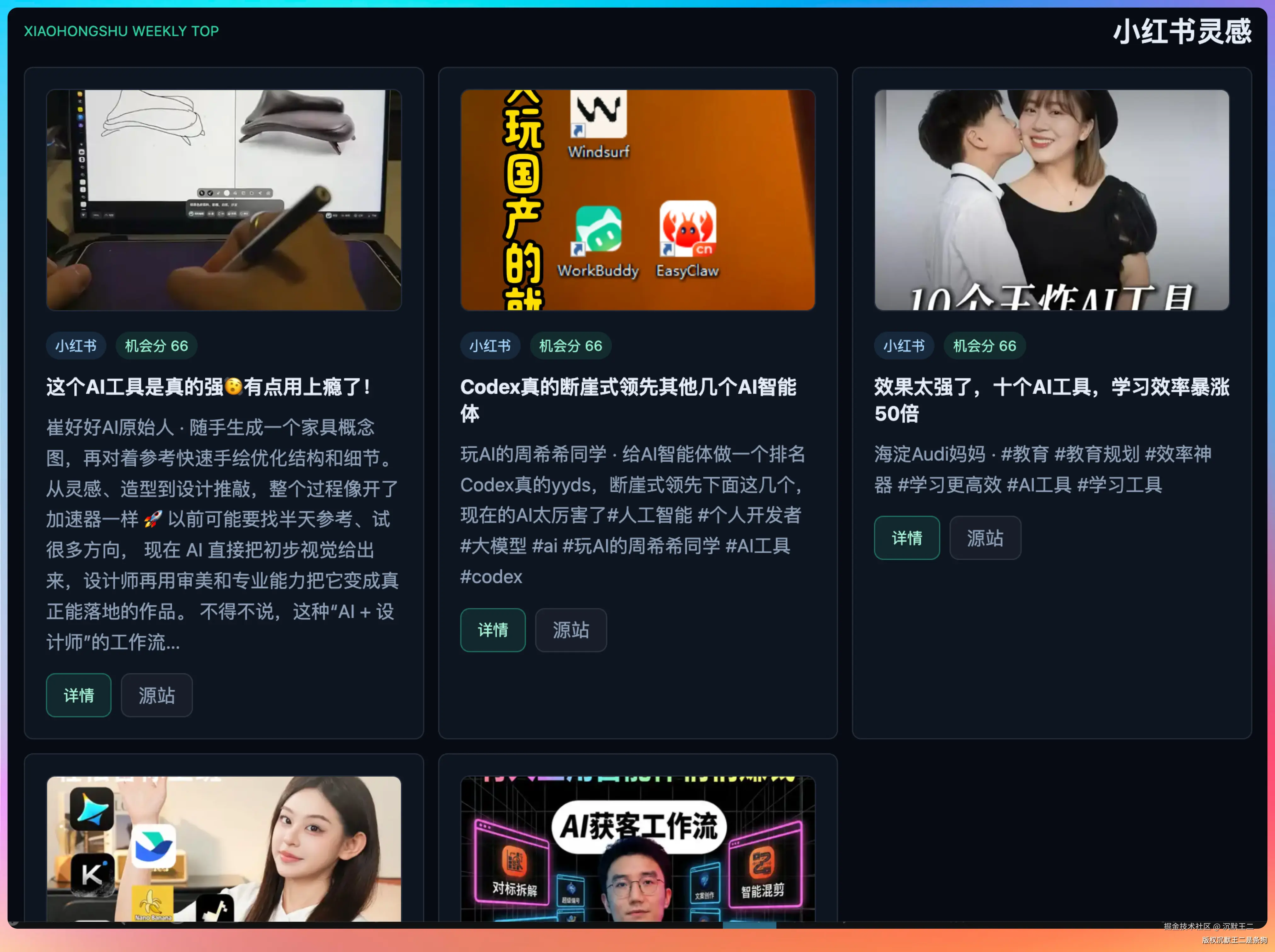
小红书灵感:5条AI相关的爆款笔记。
公众号爆文:5篇10w+阅读的公众号文章。每篇文章除了阅读数,还有点赞、在看、评论、分享的完整互动数据。
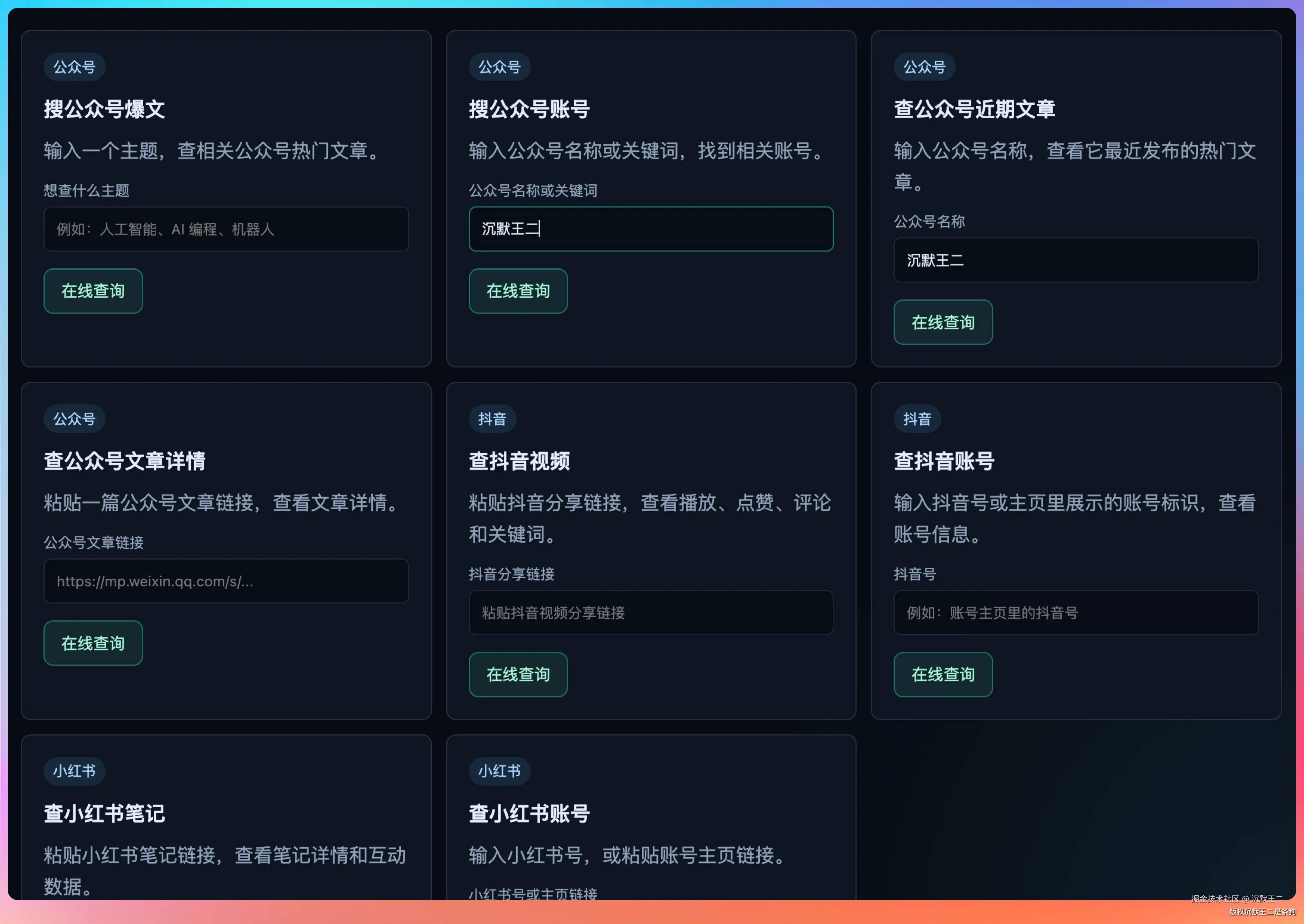
在线查询
页面上还嵌入了9个 RedFox API 查询卡片,可以直接在网页上输入关键词查询三平台的数据。
03、数据从哪来的?
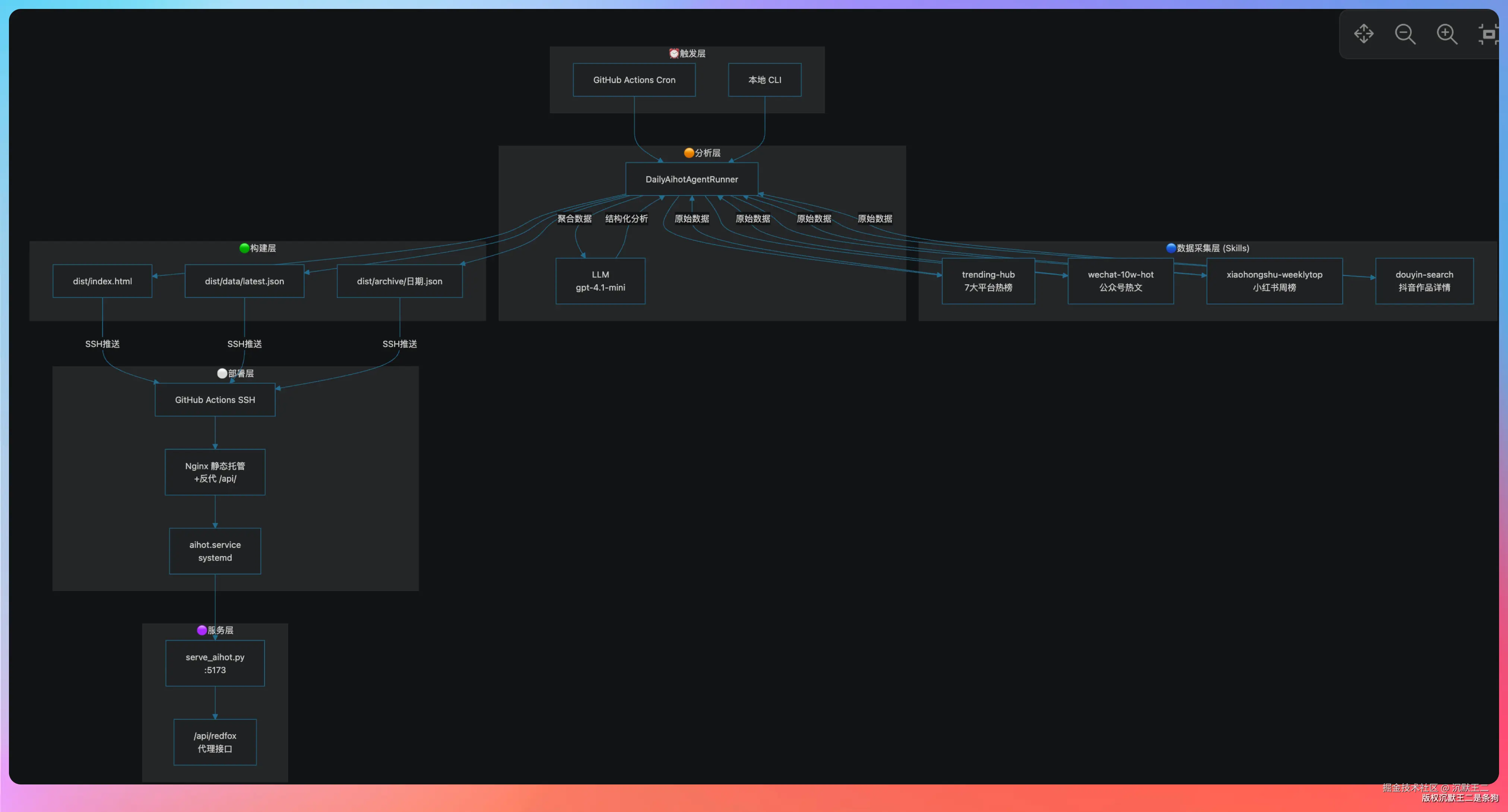
AI 热点雷达的数据全部来自红狐数据,整个采集流程如下所示。
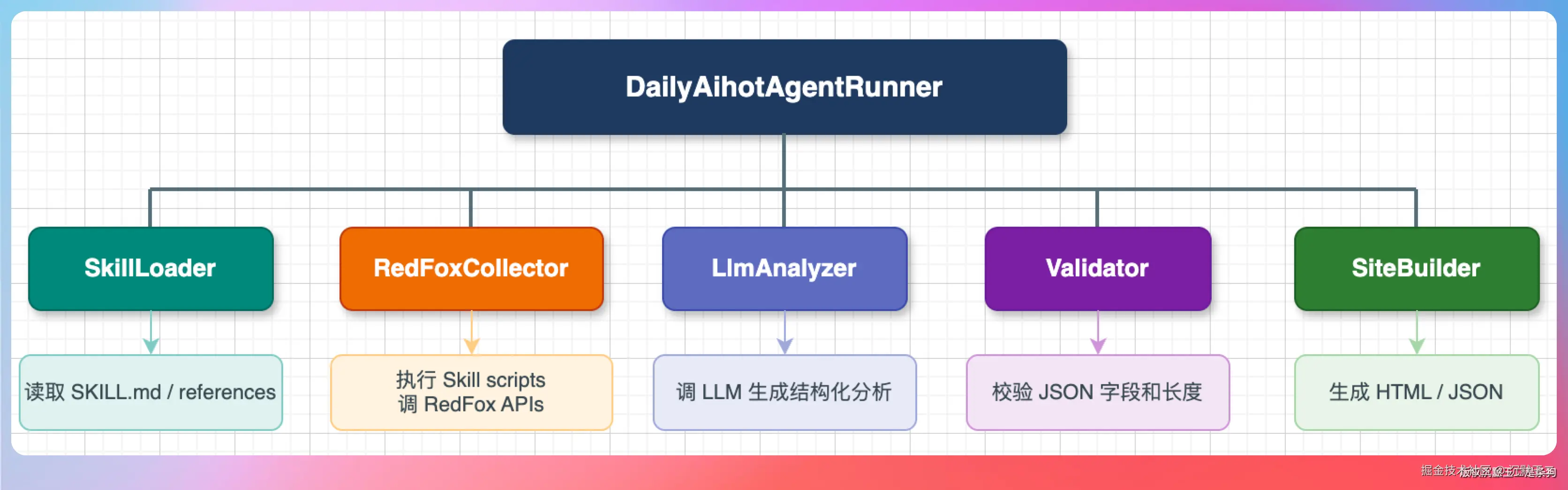
通过 GitHub Actions 每天凌晨自动执行。
采集流程
脚本启动后按固定顺序执行:
第一步,加载 Skills。脚本会读取 skills/ 目录下的 SKILL.md 文件,获取每个平台的采集策略、API 参数和关键词配置。
第二步,并行采集三个平台的数据。每个平台有独立的采集逻辑:
| 平台 | 采集方式 | 关键词 | 数据量 |
|---|---|---|---|
| 抖音 | 关键词搜索 + 作品详情补全 | AI | 5条(含完整互动数据) |
| 小红书 | 爆款笔记查询 | AI工具、AI编程、AI智能体、Agent、大模型 | 5条 |
| 公众号 | 热门文章查询 | AI工具、AI编程、AI智能体、Agent、大模型 | 5条 |
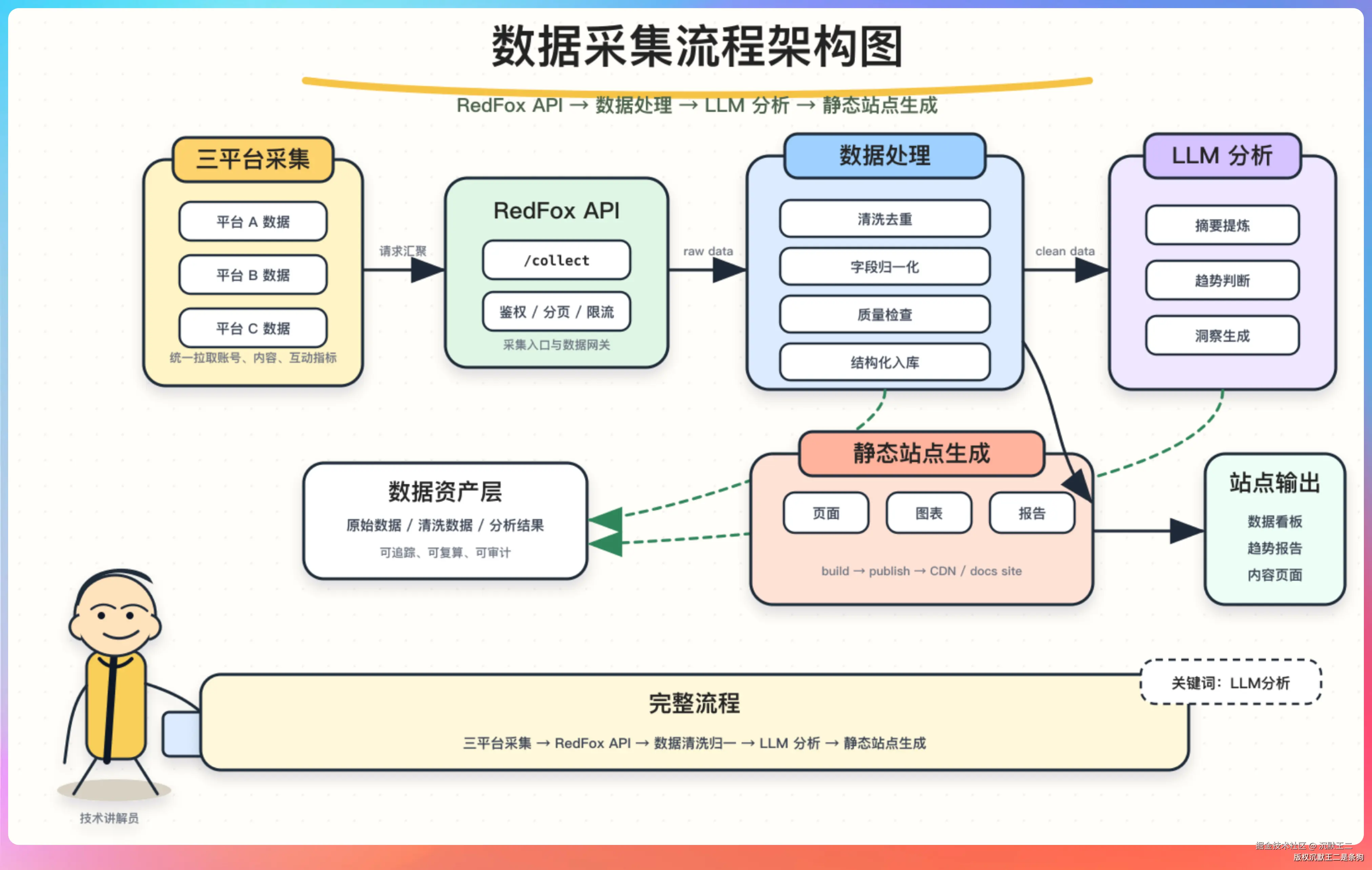
第三步,补全抖音作品详情。搜索接口返回的数据比较简略,脚本会对排名靠前的5条作品再调一次 queryWork 接口,拿到完整的点赞数、评论热词、封面图、作者信息。
第四步,交给 LLM 做结构化分析。
第五步,生成站点文件。把所有数据和分析结果嵌入 HTML,输出到 dist/ 目录。
API 调用示例
以公众号文章搜索为例,实际的 API 调用长这样:
bash
curl -X POST "https://redfox.hk/story/api/gzhData/searchArticle" \
-H "Content-Type: application/json" \
-H "X-API-KEY: ak_your_api_key" \
-d '{"keyword": "AI智能体", "offset": 0, "sortType": "_4"}'sortType 设为 _4 是按阅读数倒序,_2 是按发布时间倒序。响应是标准的 JSON 结构:
json
{
"code": 2000,
"msg": "成功",
"data": {
"total": 100,
"hasMore": true,
"list": [
{
"title": "文章标题",
"author": "作者",
"readCount": 100001,
"likeCount": 606,
"commentCount": 3,
"shareCount": 2613,
"publishTime": "2026-06-07 18:00:00",
"workUrl": "https://mp.weixin.qq.com/s/xxx"
}
]
}
}所有接口统一用 POST + JSON,认证用 X-API-KEY 请求头。Python 的 urllib、requests,Node.js 的 fetch,甚至直接 curl 都能调。
容错设计
采集过程做了多层容错:单个平台失败不影响其他平台;每个平台有备用 Skill,主 Skill 超时后会降级到备用方案;API 调用之间有 0.15 到 0.25 秒的延迟,避免触发频率限制;最终输出的 JSON 里有 errors 数组,记录了所有异常信息,方便排查。
04、LLM 分析与机会评分
数据采集完之后,脚本会把三个平台的样本数据打包发给 LLM,请求结构化分析。
默认用的是 DeepSeek v4-pro。Prompt 里会带上 Skill 的元数据和参考资料,让 LLM 理解每个平台的数据结构和评判标准。
javascript
DailyAihotAgentRunner
├── SkillLoader
│ └── 读取 SKILL.md / references
├── RedFoxCollector
│ └── 执行 Skill scripts / 调 RedFox APIs
├── LlmAnalyzer
│ └── 调 LLM 生成结构化分析
├── Validator
│ └── 校验 JSON 字段和长度
└── SiteBuilder
└── 生成 HTML / JSONLLM 需要返回一个严格的 JSON 结构,包含五个部分:
- dailySummary:当天数据的整体概述
- topPicks:跨平台精选推荐,每条带机会评分(0-100)、内容角度建议、风险提示
- platformInsights:各平台的策略洞察
- contentAngles:整体内容切入角度
- riskNotes:整体风险提醒
机会评分的计算不是 LLM 随意打的。脚本在发给 LLM 之前,会先根据关键词匹配度和互动数据(点赞、评论、分享、收藏)算出一个 40-96 分的基础分。LLM 在此基础上做微调,确保评分有数据支撑。

如果 LLM 调用失败(比如 API 超时或者额度不足),脚本会用模板生成基础的分析结果。
05、在线查询9个 API
AI 热点雷达不光展示每天的自动化报告,还嵌入了 9 个 RedFox API 的在线查询卡片。
公众号(6个查询):
- 搜索文章:输入关键词搜索公众号文章
- 搜索公众号:按名称搜索公众号账号
- 查询文章列表:输入公众号名称拉取最近文章
- 查询文章详情:输入文章URL查看完整数据
- 查询公众号信息:输入微信号查看账号详情
- 查询作品详情:按UUID查询作品数据
抖音(2个查询):查询作品详情、查询账号详情
小红书(2个查询):查询账号详情、查询作品详情
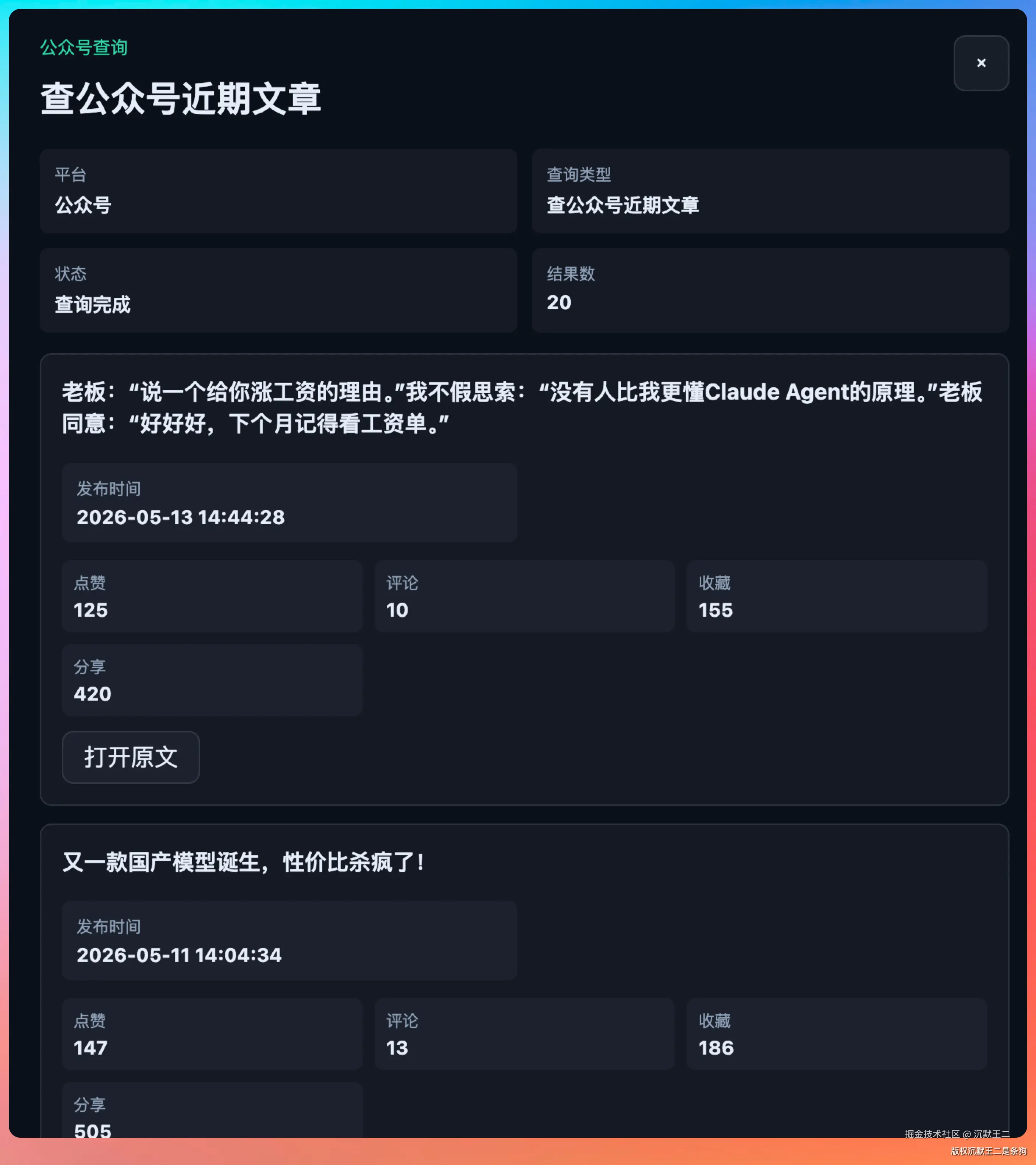
比如想查某个公众号数据,在查询文章列表卡片里输入公众号名称,可以拉到最近的文章列表,每篇文章都有阅读量、点赞数、评论数、分享数的完整互动数据。
06、Codex 里用 Skills
红狐数据 里的 Skills 也可以直接装进 Codex 或者其他Agent用。
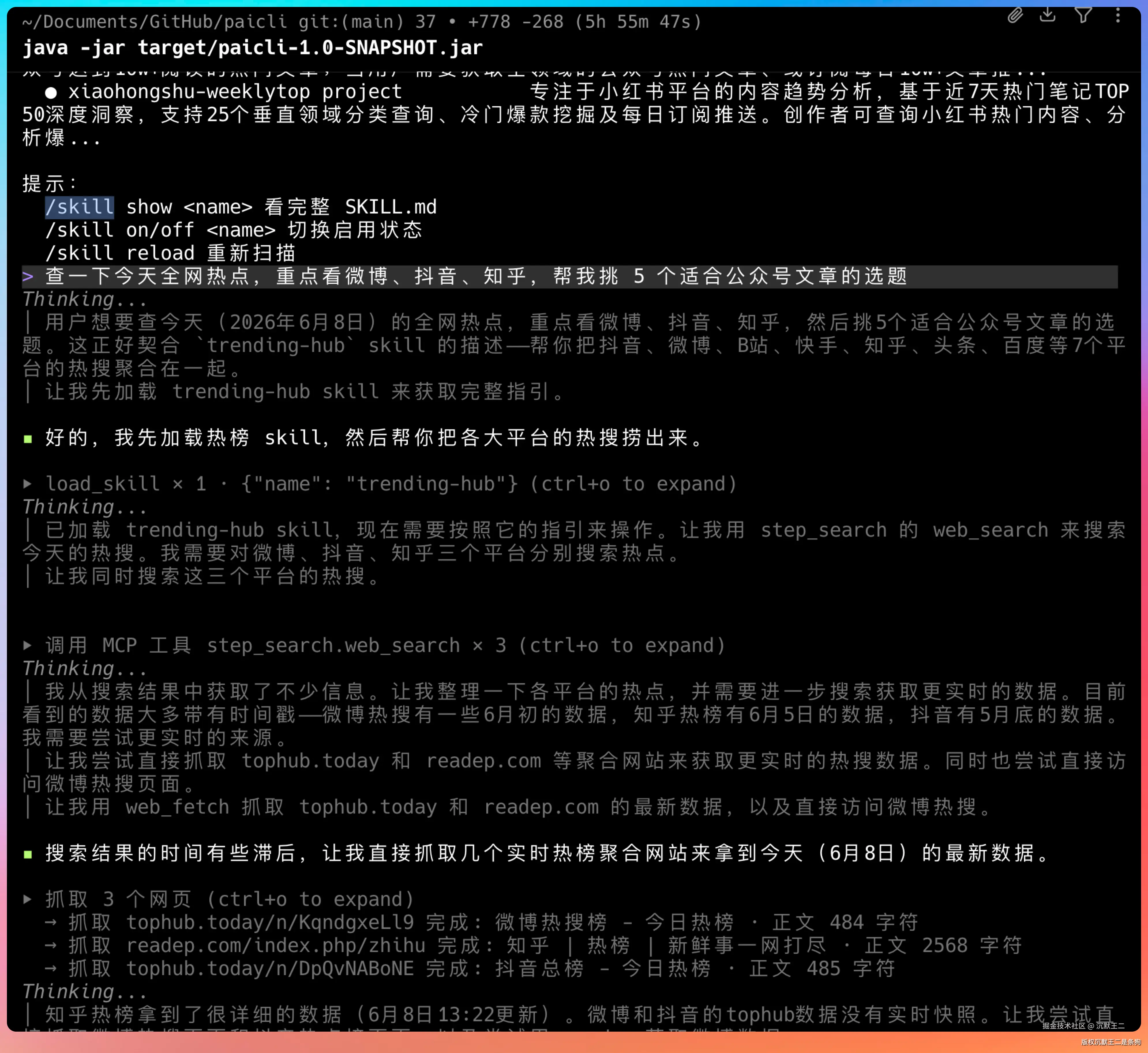
bash
skills/
├── douyin-search/ # 抖音爆款作品搜索
├── wechat-10w-hot/ # 公众号10w+文章推荐
├── xiaohongshu-weeklytop/ # 小红书七日爆款笔记
└── trending-hub/ # 全网热点追踪(7平台聚合)每个 Skill 的结构都是标准的三件套:SKILL.md(决策手册)+ scripts/(Python 脚本)+ references/(参考资料)。
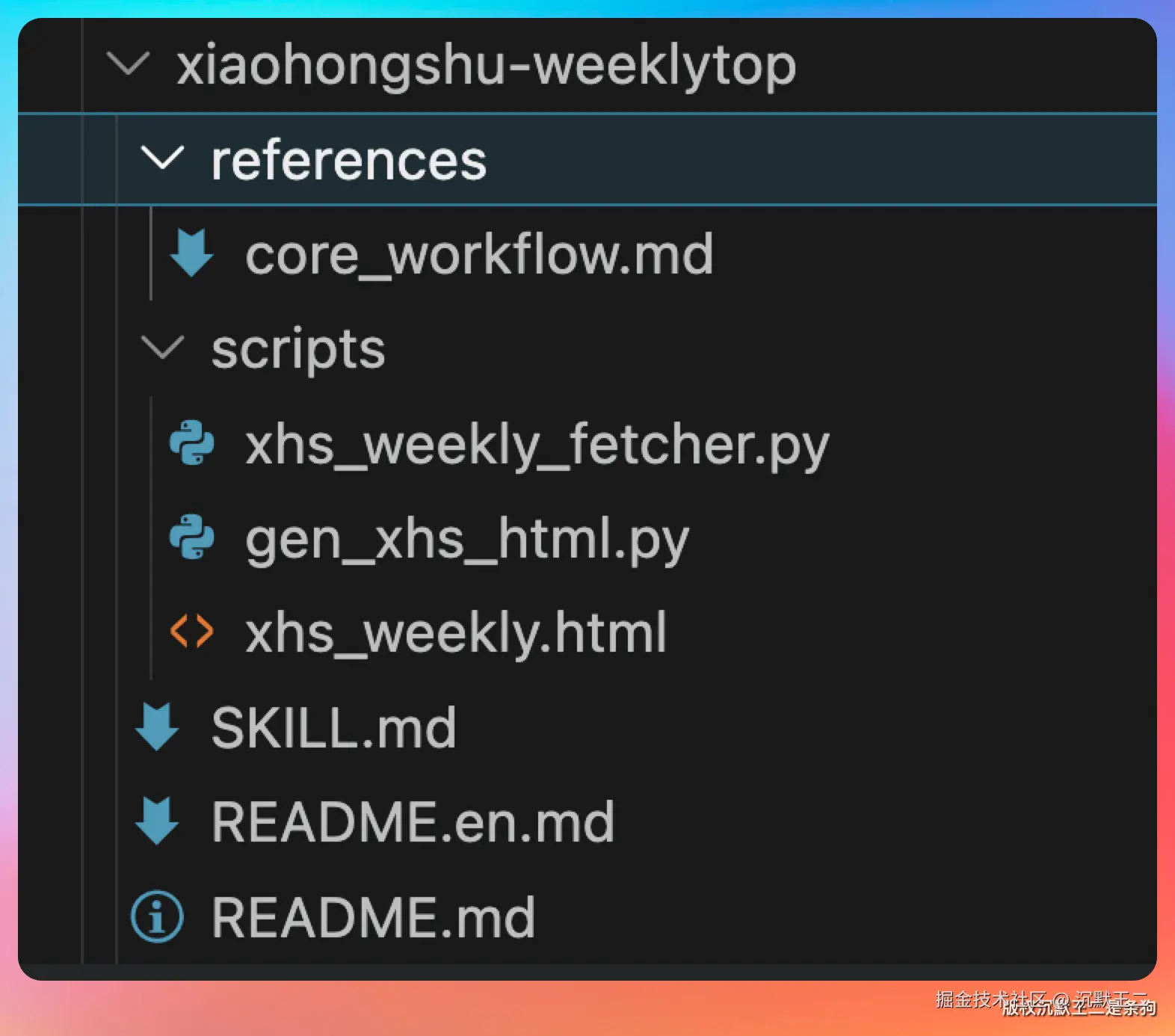
安装到 Codex
方法很简单。
我想装这几个Skills:redfox.hk/skills 包括全网热点追踪 小红书爆款笔记 公众号10万+爆款文章推荐。
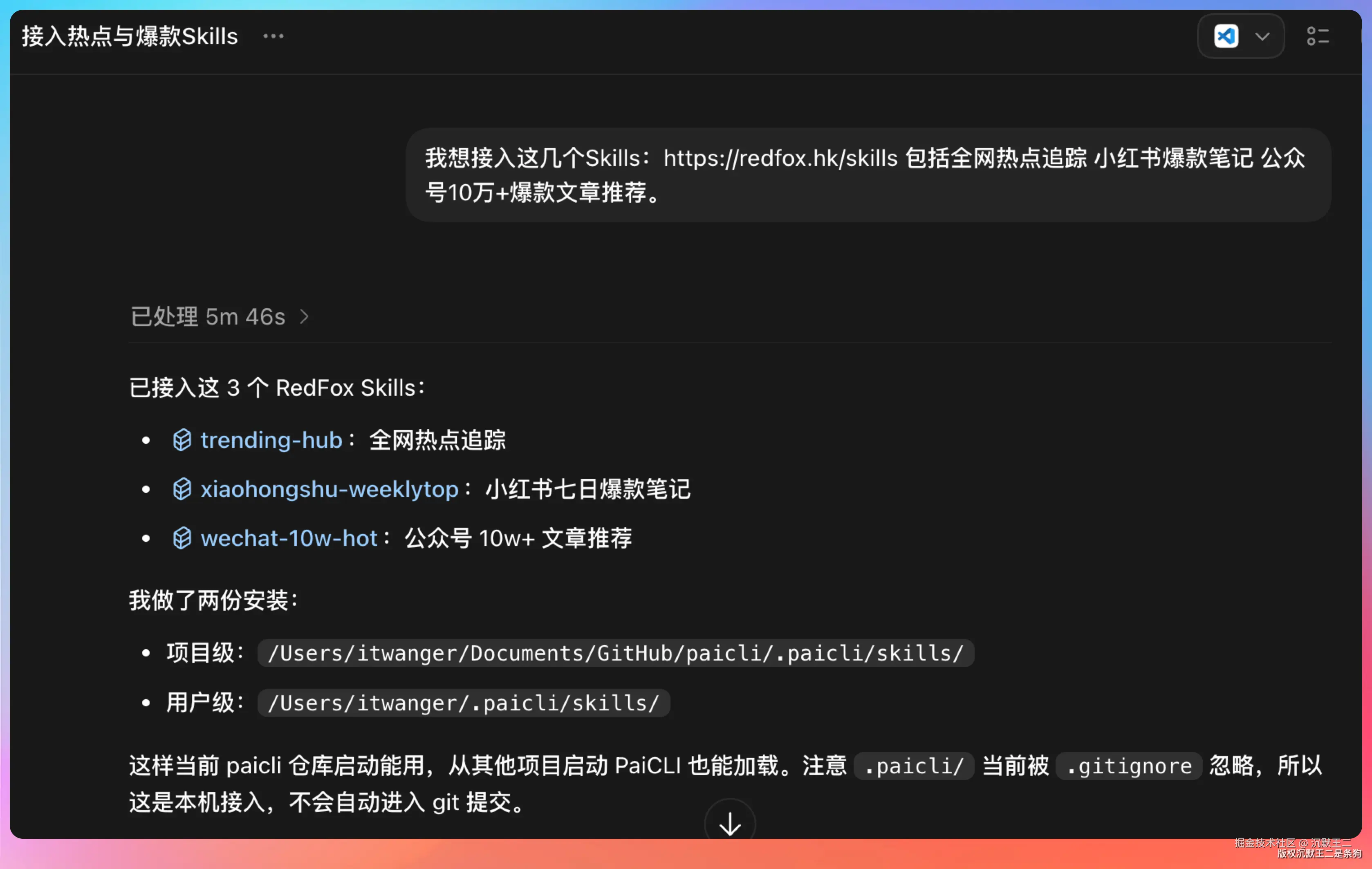
然后在红狐数据 申请一个 API Key:
实测效果
装完之后,在 Agent 里直接说"帮我看看最新的公众号10w+文章",Agent 会自动加载 wechat-10w-hot Skill,调用 fetch_hot_articles.py 脚本去红狐数据拉数据。
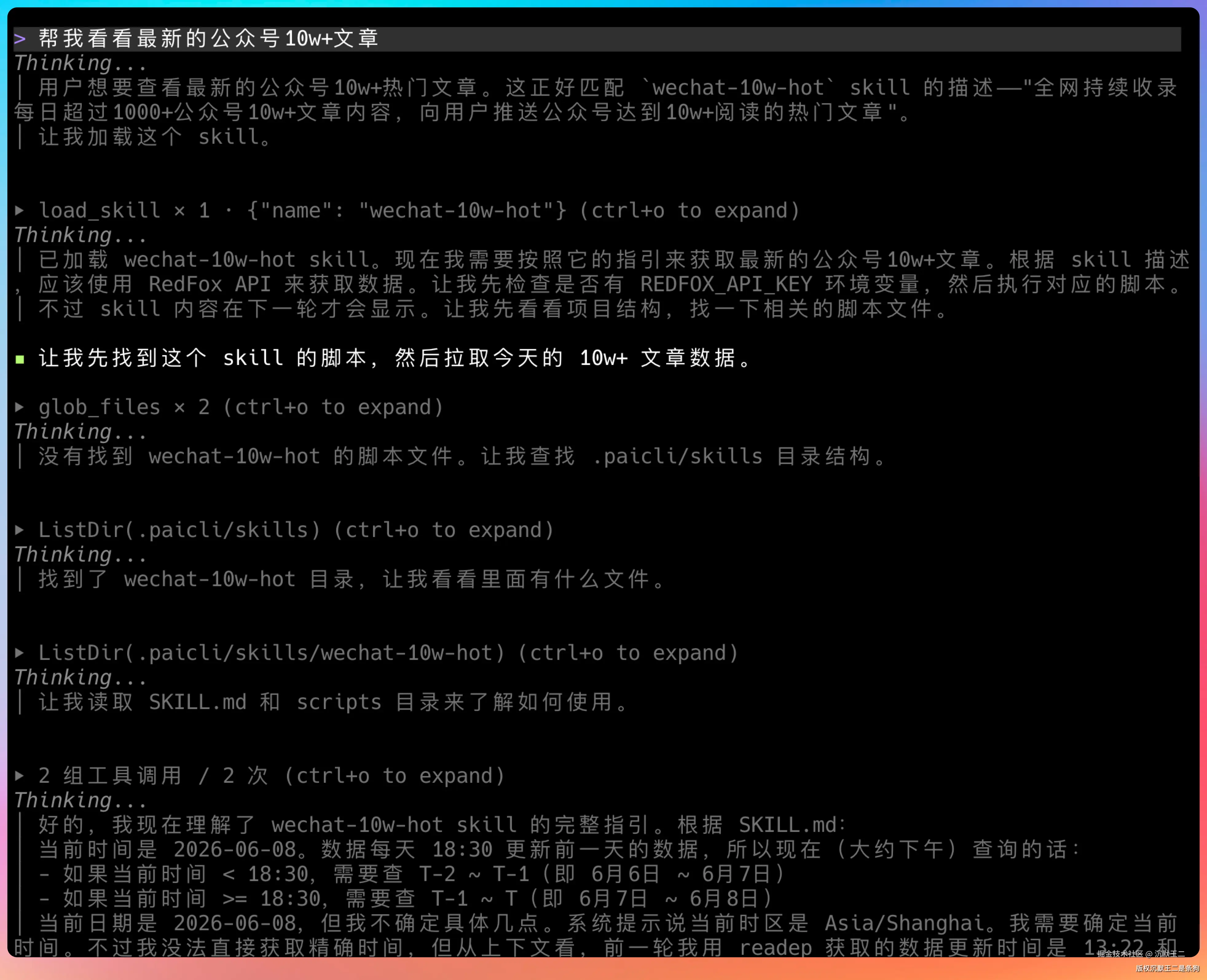
Codex、Claude Code或者PaiCLI都可以。

小红书和抖音的 Skill 类似。
xiaohongshu-weeklytop 可以查过去7天各领域的爆款笔记 TOP50,覆盖 25 个垂直分类。douyin-search 支持关键词搜索抖音热门作品,还能对泛化词自动扩展为 10 个细分关键词。
trending-hub 是全网热点追踪,聚合百度、知乎、微博、抖音、B站、快手、今日头条 7 个平台的热搜数据,按小时更新。
07、技术架构与部署
聊聊整个 AI-Hot 的技术实现,给想自己搭一个的小伙伴做参考。
技术栈
| 组件 | 技术选型 | 说明 |
|---|---|---|
| 数据采集 | Python 3.11+ | 标准库 urllib,无重度依赖 |
| LLM 分析 | OpenAI-compatible API | 默认 DeepSeek v4-pro,可切换 |
| 前端 | 纯 HTML/CSS/JS | 无框架,单页面应用 |
| 站点生成 | Python 静态输出 | 数据嵌入 HTML,输出到 dist/ |
| 自动化 | GitHub Actions | 每天 00:30 定时执行 |
| 部署 | Nginx + systemd | 静态文件 + API 代理服务 |
没有数据库。
每天的数据生成后写入 dist/data/latest.json,同时归档到 dist/archive/YYYY-MM-DD.json。前端页面直接读取 JSON 渲染,架构非常简单。
GitHub Actions 自动化
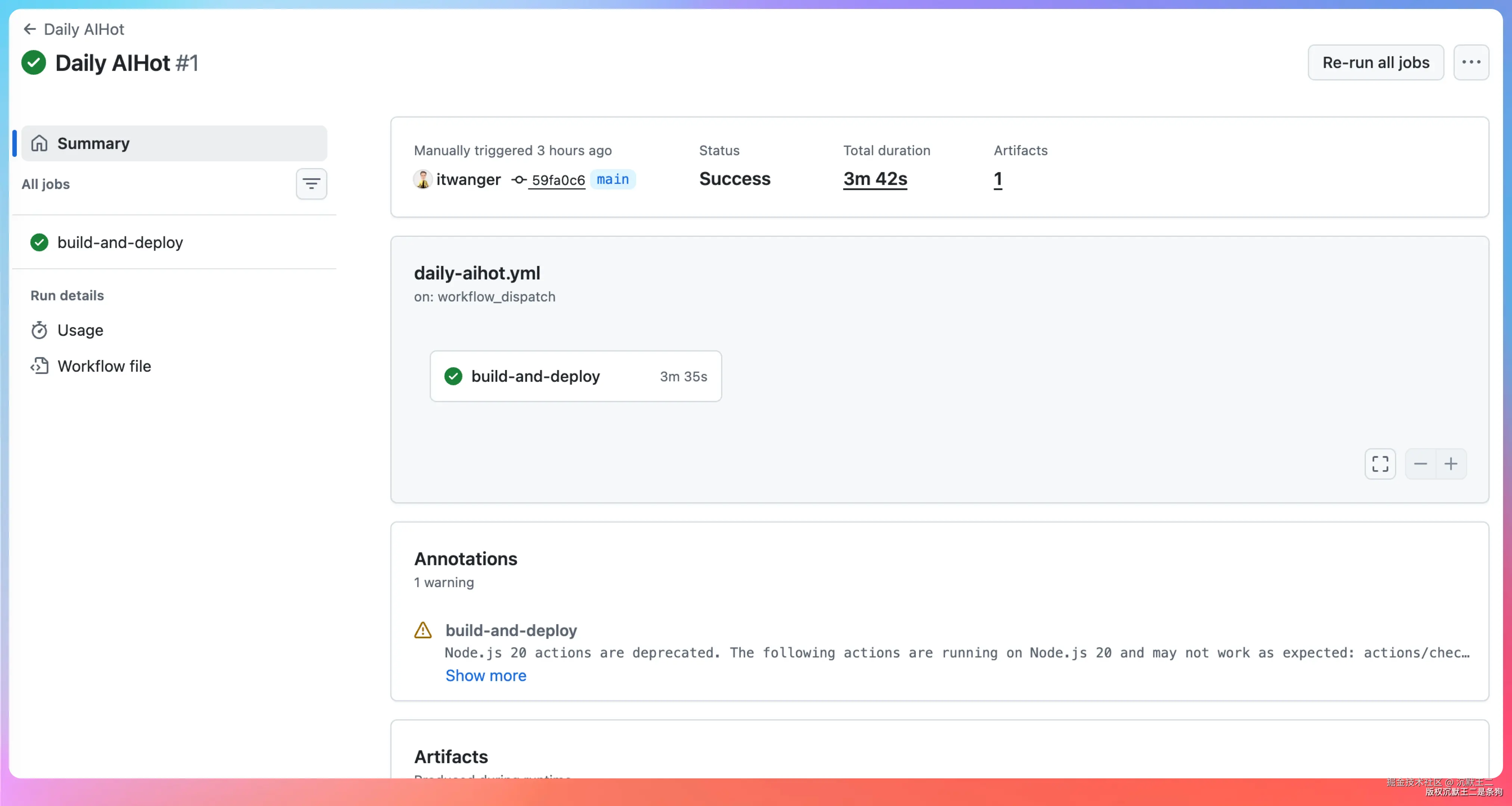
.github/workflows/daily-aihot.yml 定义了每日构建流程:
- 触发:每天 00:30 自动触发,也支持手动触发(workflow_dispatch)
- 构建 :安装 Python 3.11,执行
run_daily_agent.py,验证输出(任何一个平台返回 0 条数据就标记失败) - 部署 :通过 SSH 把
dist/同步到服务器,更新 systemd 服务
环境变量通过 GitHub Secrets 注入,API Key 不会出现在代码仓库里。
yaml
env:
REDFOX_API_KEY: ${{ secrets.REDFOX_API_KEY }}
LLM_API_KEY: ${{ secrets.LLM_API_KEY }}
LLM_BASE_URL: ${{ secrets.LLM_BASE_URL }}
LLM_MODEL: ${{ secrets.LLM_MODEL }}
Nginx 配置
生产环境用 Nginx 做静态文件服务和 API 代理。静态页面直接从部署目录读取,API 请求转发到本地的 Python 代理服务(端口 5173):
nginx
location / {
root /home/www/aihot;
try_files $uri $uri/ /index.html;
}
location ^~ /api/ {
proxy_pass http://127.0.0.1:5173/api/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}微信公众号的封面图有防盗链,Nginx 里还加了一层图片代理,带上正确的 Referer 头:
nginx
location ^~ /wechat-img/ {
proxy_pass https://mmbiz.qpic.cn/;
proxy_set_header Host mmbiz.qpic.cn;
proxy_set_header Referer "https://mp.weixin.qq.com/";
}
成本控制
这个项目每天的运行成本很低:
- 红狐数据 API:每天大约调 15-20 次(三平台搜索 + 抖音详情补全)
- LLM:一次结构化分析,token 消耗在 2000-3000 左右
- 服务器:和其他项目共用一台,不额外增加成本
08、如何写到简历上?
项目名称:AI 热点雷达
项目简介:基于红狐数据 新媒体数据 API,设计并实现了 4 个 Agent Skills,驱动 AI 热点聚合与分析平台自动采集抖音、小红书、公众号三大平台数据,结合 LLM 结构化分析生成每日热点报告和机会评分。
技术栈:Python + Agent Skills + RESTful API + OpenAI-compatible LLM + 静态站点生成 + GitHub Actions + Nginx
核心职责:
- 设计并实现了 4 个标准化 Agent Skills,覆盖全网热点追踪、小红书爆款笔记、公众号10w+文章推荐、抖音热门作品搜索四个方向
- 实现了 Skill 三层加载机制,支持同名 Skill 覆盖和热重载,Skills 可跨 Codex、Claude Code 等多个 Agent 平台复用
- 基于红狐数据 REST API 封装三个平台的数据采集,Skill 脚本内置了时间参数自动计算、分类关键词泛化映射、分页展示策略等决策逻辑,日均处理有效数据超过 500 条
- 实现了 LLM 结构化分析引擎,输出跨平台精选推荐、机会评分、内容角度建议;基于 GitHub Actions 实现每日全自动构建和部署流水线
而且整个项目从开发到部署,满打满算用了半天时间。数据源用红狐数据的API,不用自己写爬虫。LLM分析用DeepSeek或者其他国产模型都可以。部署用GitHub Actions,不用自己搭CI/CD。
【开发者最大的优势是,别人用工具,我们造工具。】
我们下期见。