automl介绍
AutoGluon背后的技术_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1F84y1F7Ps/?from=search&seid=1218935720421021430&spm_id_from=333.788.comment.all.click&vd_source=5252d3cdd5246bf9326ccfc5acb90644AutoGluon背后的技术_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1F84y1F7Ps/?from=search&seid=1218935720421021430&spm_id_from=333.788.comment.all.click&vd_source=5252d3cdd5246bf9326ccfc5acb90644AutoGluon背后的技术_哔哩哔哩_bilibili
论文:https://arxiv.org/abs/2003.06505
代码:https://github.com/awslabs/autogluon
之前房子竞赛:
竞赛地址:https://www.kaggle.com/c/california-house-prices/overview autogluon
文档:https://auto.gluon.ai/ autogluon
代码:https://github.com/awslabs/autogluon
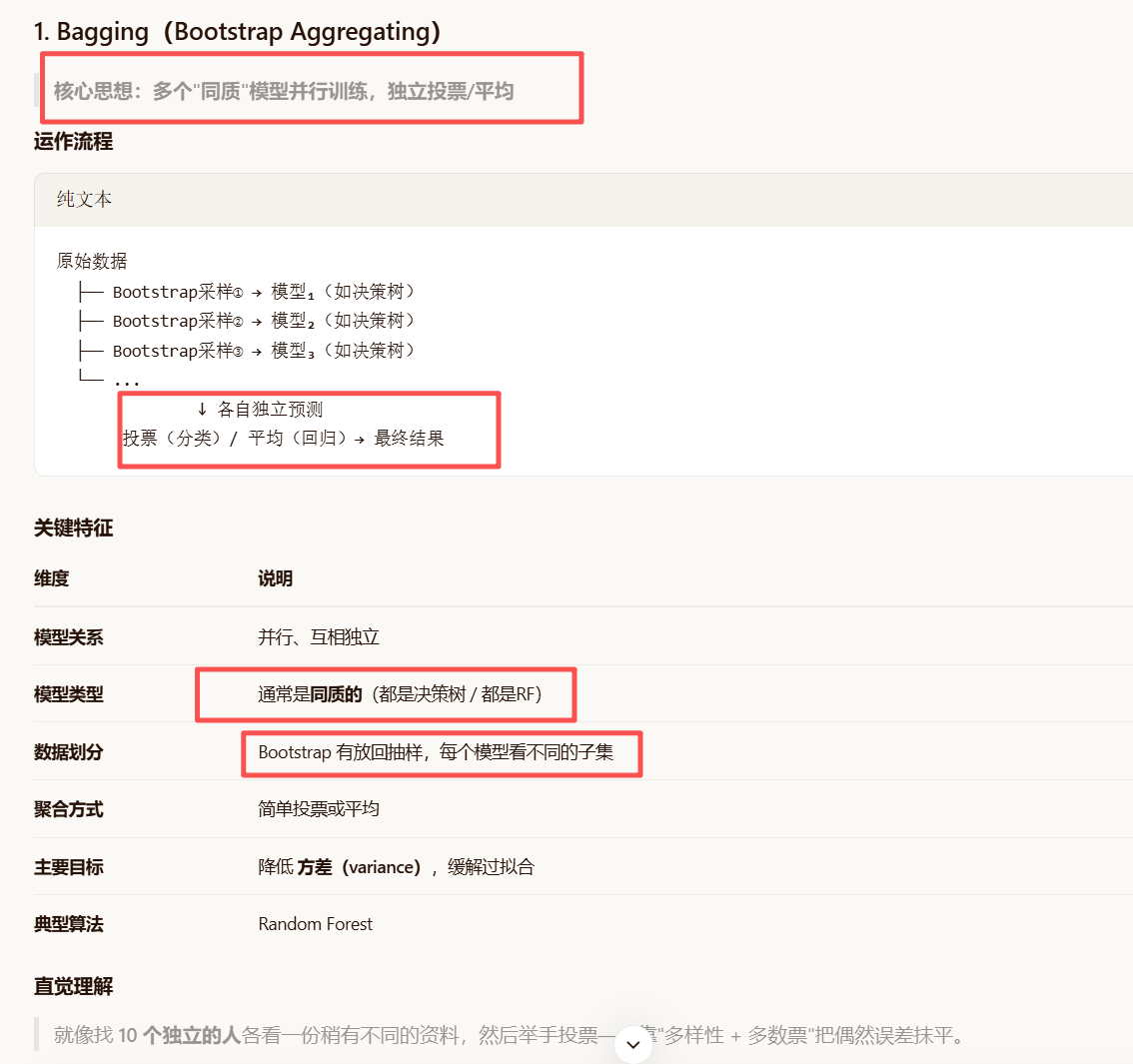
集成学习

bagging的主要效果是能够并行,降低方差 eg:随机森林
特别是当整个用来做bagging的模型是不稳定的模型的时候效果最佳(随机森林) 之后求平均后软投票(推荐)/硬投票
boosting 它是说将多个弱一点的模型(偏差比较大)组合起来变成强一点的模型(偏差比较小),主要是为了去降低偏差而不是方差【Bagging 把多个不那么稳定的模型把它们放在一起得到一个相对稳定的模型】
Boosting是要按顺序的学习【bagging是每个模型是独立的】降低偏差
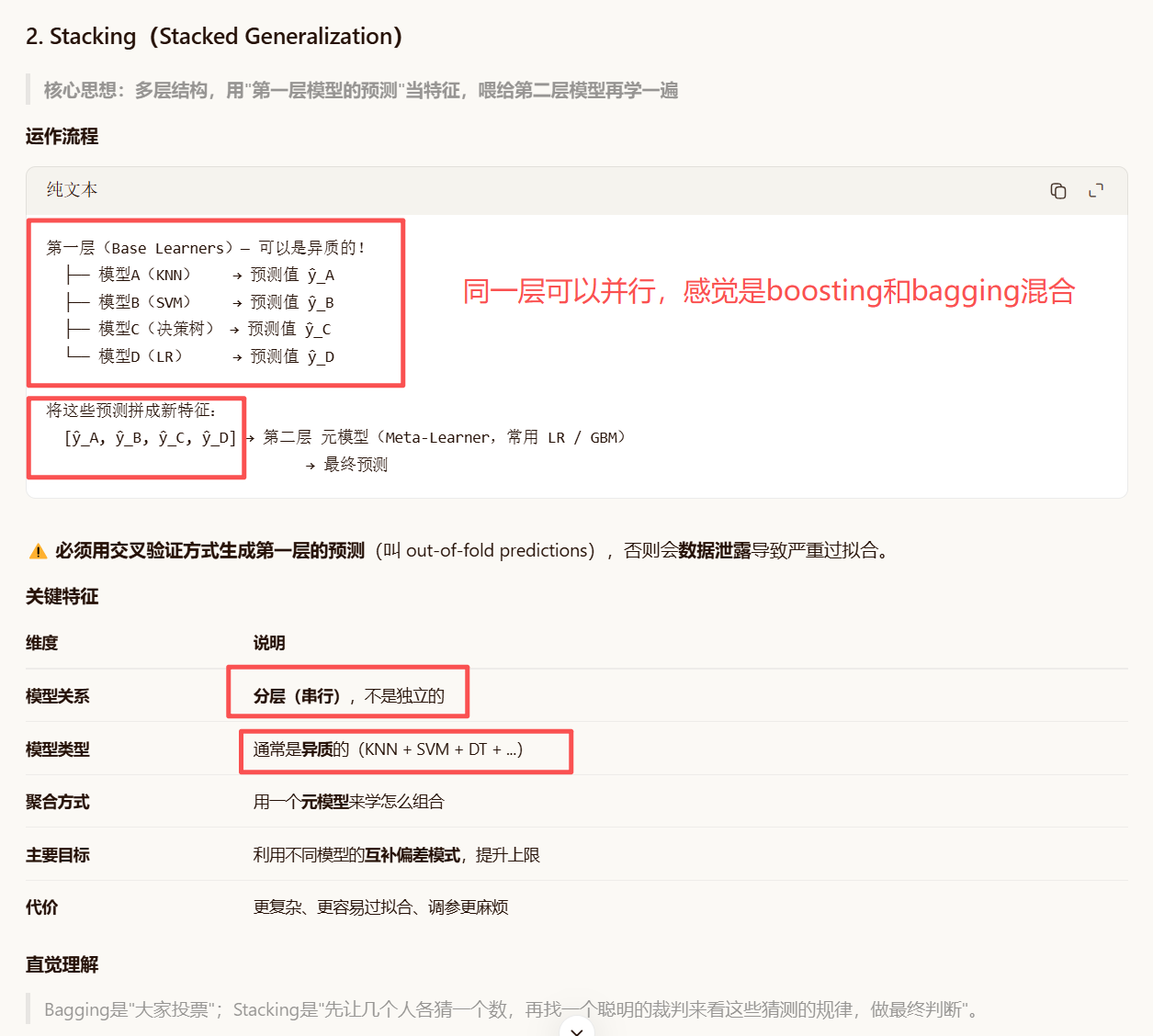
stacking:和bagging有点像 降低方差

多层stacking(常用):降低偏差


Bagging和stacking区别(重点)
Layer 0(基模型层)--- 三者完全并行,互不影响
├── Model A (KNN) ──┐
├── Model B (SVM) ──┼── 各自做 out-of-fold 预测
└── Model C (DT) ──┘ │
▼ 拼接 → ŷ_A, ŷ_B, ŷ_C ← 新特征
Layer 1(元模型层)─────────── 拿新特征训练 LR → 最终结果
| Bagging | Stacking | |
|---|---|---|
| 结构 | 扁平、并行 | 分层、串行 |
| 模型种类 | 同质为主 | 异质为主 |
| 聚合 | 硬投票 / 简单平均 | 元模型学习如何加权组合 |
| 降低什么 | 主要是 方差 | 同时优化 偏差 + 方差 |
| 训练成本 | 低~中,易并行 | 高,需 CV 防泄漏 |
| 风险 | 模型类型单一,天花板受限 | 容易过拟合,工程复杂度高 |
| 经典代表 | Random Forest | Kaggle 竞赛常用套路 |
多层 Stacking 怎么实现?
核心原则(最重要)
每一层生成训练集上的预测时,都必须用 cross-validation 的 out-of-fold 方式,不可以直接 fit整个训练集再predict训练集自己------那叫数据泄露,会让多层 stacking 变成过拟合灾难。
例子:假设我们有训练集 X_train, y_train,测试集 X_test。
python
from sklearn.model_selection import KFold
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import Ridge
from sklearn.tree import DecisionTreeRegressor
# ---------- 工具函数:生成 out-of-fold 预测 ----------
def get_oof_predictions(model, X_train, y_train, X_test, n_folds=5):
"""
返回:
train_pred_oof : 和 y_train 一样长的向量, 每个样本的预测来自
没见过它的那个 fold 的模型
test_pred : 对 X_test 的预测, 取 k 个 fold 模型的平均
"""
kf = KFold(n_splits=n_folds, shuffle=True, random_state=42)
train_pred_oof = np.zeros(len(X_train))
test_pred_folds = np.zeros((n_folds, len(X_test)))
for i, (train_idx, val_idx) in enumerate(kf.split(X_train)):
m = model.__class__(**model.get_params()) # 重新实例化
m.fit(X_train[train_idx], y_train[train_idx])
train_pred_oof[val_idx] = m.predict(X_train[val_idx])
test_pred_folds[i] = m.predict(X_test)
test_pred = test_pred_folds.mean(axis=0)
return train_pred_oof, test_pred
# ---------- Layer 0 的三个基模型 ----------
models_l0 = [
KNeighborsRegressor(n_neighbors=5),
Ridge(alpha=1.0),
DecisionTreeRegressor(max_depth=5, random_state=42),
]
# 收集每个模型的 OOF 预测 → 组成 Layer 0 的新特征
train_meta_0 = []
test_meta_0 = []
for m in models_l0:
tr_p, te_p = get_oof_predictions(m, X_train, y_train, X_test)
train_meta_0.append(tr_p)
test_meta_0.append(te_p)
# 拼成新特征矩阵:(n_samples, 3)
X_train_l1 = np.column_stack(train_meta_0)
X_test_l1 = np.column_stack(test_meta_0)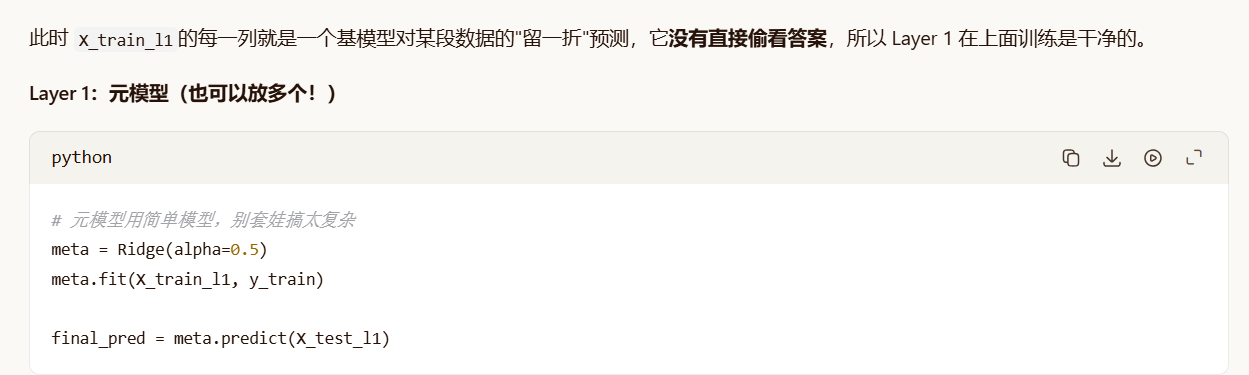
第二层:
python
# ===== Layer 1:多个元模型,也要走 OOF!=====
models_l1 = [
Ridge(alpha=0.5),
DecisionTreeRegressor(max_depth=3, random_state=42),
]
train_meta_1 = []
test_meta_1 = []
for m in models_l1:
tr_p, te_p = get_oof_predictions(m, X_train_l1, y_train, X_test_l1)
train_meta_1.append(tr_p)
test_meta_1.append(te_p)
X_train_l2 = np.column_stack(train_meta_1)
X_test_l2 = np.column_stack(test_meta_1)
# ===== Layer 2:最终模型 =====
final_model = Ridge(alpha=0.1)
final_model.fit(X_train_l2, y_train)
y_pred = final_model.predict(X_test_l2)kaggle竞赛:autogluon介绍特点
- 核心理念:从"单打独斗"到"全民公投"
-
图片 1 的含义:
-
传统 AutoML(左图诸葛亮):很多框架只是在做"超参数搜索",就像诸葛亮一个人想办法,累得半死调参,上限受限于人的经验。
-
AutoGluon 模式(右图十个臭皮匠) :它的核心不是调参,而是融合多个开箱即用的模型。它不依赖某一个模型的最优参数,而是把 LightGBM、CatBoost、神经网络、随机森林等几十个模型直接拉过来一起干活。
-
-
对你的启发:
在房价竞赛中,不要迷信某一个"神级特征"或"神级参数"。多模型融合(Blending/Stacking) 才是上分的最稳路径。哪怕你的特征工程很普通,只要模型够多、相关性够低,把它们的预测结果平均一下,分数往往就能涨。
- 技术一:Stacking(特征层面的"借力打力")
-
图片 2 的含义:
-
这是 Ensemble(集成学习)的第一层。底层是多个不同的基模型(齿轮),它们各自对"数据"进行预测。
-
顶层的"线性模型"不再是原始特征,而是吃进了这些基模型的预测结果。它学习的是"当模型A预测偏高、模型B预测偏低时,如何修正得到最终答案"。
-
-
对你的启发:
在 Kaggle 中,这通常用于融合不同类型的模型。比如,你可以用 XGBoost 处理数值特征,用 NLP 模型处理文本特征,然后把这两者的预测值作为新特征,喂给一个逻辑回归(LR)做最后的校准。
- 技术二:K-折交叉 Bagging(样本层面的"自我纠错")
-
图片 3 的含义:
-
这是对同一个模型的增强。为了防止某个模型只记住了某一部分数据(过拟合),将数据切成 K 份(如 3 折)。
-
轮流用其中 2 份训练,去预测剩下的 1 份(验证集)。最后把 K 次的预测结果**"平均"**起来。
-
-
对你的启发:
这能极大提升模型的稳定性。如果你的 LightGBM 在训练集上 RMSE 很低,但在验证集上很高,用 Bagging 策略(配合 Out-of-Fold 预测)能有效缓解这个问题。
- 技术三:多层 Stacking(深度的"连环套娃")
-
图片 4 的含义:
-
这是 Stacking 的进阶版。第一层的模型(下排齿轮)输出的预测结果,不仅给顶层模型用,还会再往下流,和第二层的数据结合,去训练更上层的模型。
-
形成了一个多层的"金字塔"结构,不断提炼数据的深层规律。
-
-
对你的启发:
AutoGluon 之所以强,就是因为它默认构建了这种多层结构。它自动做了:原始数据 -> 基模型预测 -> 次级模型预测 -> 最终结果。
💡 实战建议:如何用这些思路打赢房价竞赛?
结合你之前提到的"文本特征"和"时间序列切分",你可以搭建一个简易版的"AutoML 思路"流程:
-
基模型层(臭皮匠军团):
-
模型 A:LightGBM(处理数值特征 + 你提取的地址正则特征)。
-
模型 B:CatBoost(专门处理类别特征,如城市、小区)。
-
模型 C:NLP 模型(提取文本描述的 Embedding 向量,作为特征输入一个简单的 NN 或 XGBoost)。
-
-
融合层(诸葛亮拍板):
-
不要用简单的加权平均,而是把这些基模型的 Out-of-Fold (OOF) 预测结果 拼在一起,训练一个逻辑回归(LR) 或者 Ridge 回归。
-
注意:一定要用 OOF 预测,不能用测试集预测值,否则会有过拟合风险。
-
-
时间切分是底线:
- 无论你做多少层 Stacking,在做 K-Fold 的时候,千万不要打乱时间顺序 (Shuffle=False)。必须按时间先后切分,这样才能保证你在私榜(未来数据)上的泛化能力。