面试速记:
一、仅编码器(BERT)
核心 :双向自注意力 ✅ 优点:上下文信息利用充分,语义理解能力强 ;理解类任务推理快,适配分类、实体识别、语义匹配等。 ❌ 缺点:无文本生成能力;长序列计算开销大。
二、仅解码器(GPT)
核心 :单向掩码自注意力、自回归生成 ✅ 优点:原生支持文本生成、对话、续写;架构简单,易部署,支持流式输出。 ❌ 缺点:只能看上文,理解能力偏弱;逐词生成推理慢,易出现幻觉、重复。
三、编码器 - 解码器(原始 Transformer/T5)
核心 :编码做理解、解码做生成,Seq2Seq 结构 ✅ 优点:兼顾理解与生成,擅长输入输出不等长任务(翻译、摘要、改写)。 ❌ 缺点:结构最复杂,算力、显存成本高;推理链路长、延迟高,训练部署难度大。
理解:
一、先搞懂核心前提:Transformer 两大基础组件
先分清 ** 编码器(Encoder)和解码器(Decoder)** 各自的 "本职工作":
- 编码器 :只做「读文本、理解意思」,能同时看整段文字的前面 + 后面(双向阅读)。 就像是做阅读理解的学生,读一句话时,前后内容一起参考。
- 解码器 :只做「接着往下写文字」,只能看已经写好的前文,看不到后面内容(单向续写)。 就像写作文的人,动笔时只能参考前面写的内容,还没写出的文字自然看不到。
基于这两个组件,就分出三种架构:只用编码器、只用解码器、编码器 + 解码器组合。
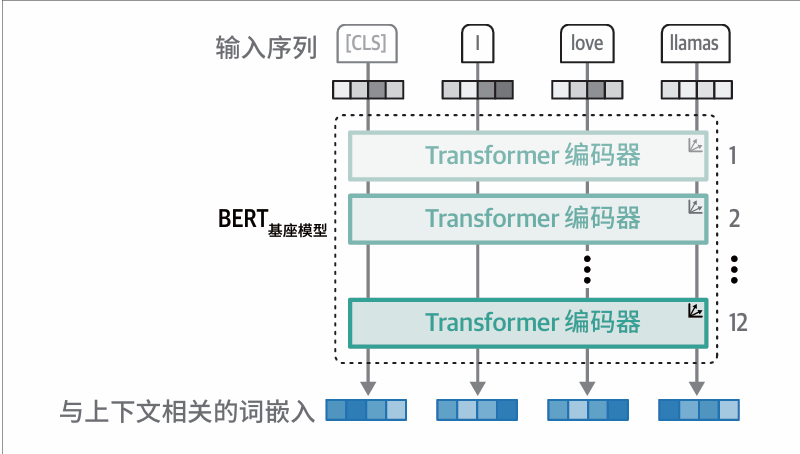
二、第一种:仅编码器 代表:BERT (bidirectional encoder representations from Transformers, 基于Transformer 的双向编码器表示)
1. 工作模式
全程只有「阅读理解模块」,不会写字、不会续写。
举个例子:
句子:这只小狗很可爱
模型读这句话时,每个字都能看到左右所有字:读「小狗」,能同时看前面「这只」、后面「很可爱」,完整理解整句话含义。
2. 优点
- 理解能力最强
前后文一起看,抓语义、情绪、语法、指代最准。比如判断评论是好评还是差评、识别句子里的人名地名,它最擅长。
- 干活速度快
整段文字可以一次性全部读完处理,不用一个字慢慢抠,适合高并发的线上服务。
3. 缺点
完全不会主动写新内容。
你让它 "接着这句话往下写""帮我写文案""陪你聊天",它做不到。它天生只是 "阅读理解工具",不是 "写作工具"。
4. 适用场景
只做文字理解类工作:情感分析、文本分类、人名 / 地名识别、文章聚类、语义检索。
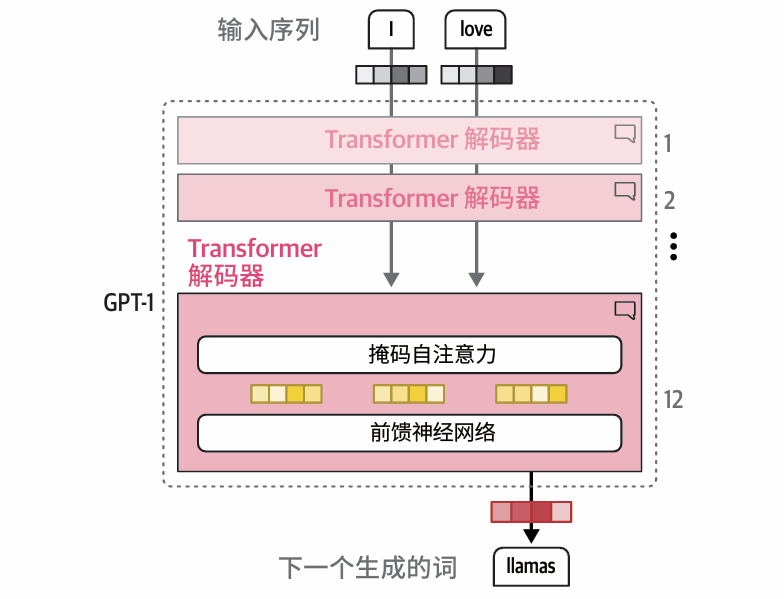
三、第二种:仅解码器(代表:GPT、LLaMA、ChatGLM)
1. 工作模式
全程只有「写作续写模块」,主打写字、对话、创作,只能看前文,看不到后文。
举个例子:
你输入:今天天气很好
模型开始逐字续写:
第一步看「今天天气很好」→ 写下「我打算出门」
第二步看「今天天气很好 我打算出门」→ 写下「去公园散步」
......
每写一个字,都只能参考已经写好的内容,看不到还没写的部分。
2. 优点
- 天生擅长写内容 聊天、写文章、写代码、续写句子、回答问题全都拿手,这就是现在主流聊天大模型的架构。
- 功能全能 虽然只能单向看前文,但依靠海量数据训练,也能兼顾基础理解,一个模型能干大部分 NLP 活。
- 结构简单,开发、部署省事。
3. 缺点
- 理解能力不如 BERT 遇到需要结合整段上下文(尤其是后半句)判断的复杂语义,表现会弱一些。
- 写字慢 必须一个字一个往外蹦,不能一次性生成整段,并发量大的时候延迟更高。
- 容易 "胡说八道"(幻觉) 它是按概率猜下一个字,不是真的 "懂知识",偶尔会编造不存在的事实。
4. 适用场景
所有文字生成类工作:人机对话、文案创作、代码生成、问答、小说续写、总结内容。
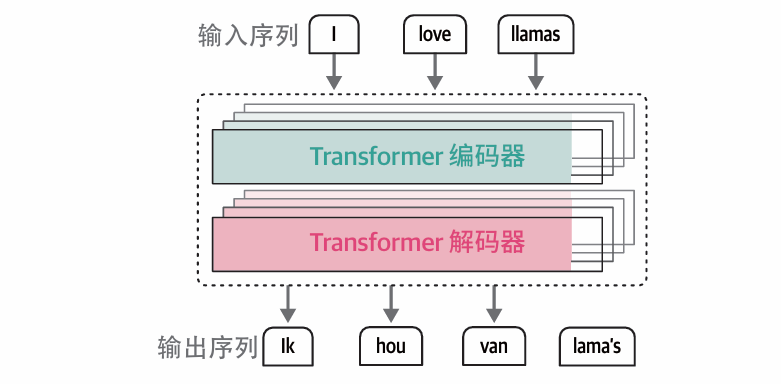
四、第三种:编码器 + 解码器(组合架构,代表:T5、原始 Transformer)
1. 工作模式
分工合作:
- 编码器(阅读理解):先完整读懂你输入的整段文字;
- 解码器(写作):基于编码器理解的结果,逐字生成新内容。
经典例子:机器翻译
输入中文:我爱吃苹果
- 编码器:完整读懂这句话的含义;
- 解码器:根据理解结果,逐字写出英文
I like eating apples。
2. 优点
- 分工明确:读得准 + 写得顺,同时拥有强理解 + 强生成能力。
- 特别适合「输入一段、输出另一段」的转换任务:翻译、长文缩写、句式改写。 比如长文章缩成短摘要、把书面语改成口语,这种场景它适配度最高。
3. 缺点
- 结构最复杂,相当于 "两套系统拼在一起",训练、调试、维护难度最大。
- 速度偏慢:先要完整读完内容,再开始写字,多一道流程。
- 单项能力不如专用模型: 论 "阅读理解",干不过纯 BERT;论 "自由创作聊天",干不过纯 GPT。 现在通用聊天大模型基本不用这种架构了。
4. 适用场景
文本转换类任务:机器翻译、文本摘要、句式改写、问答生成。
本文所用图片均引自:《图解大模型:生成式 AI 原理与实战》(沙特 杰伊・阿拉马尔、荷 马尔滕・格鲁滕多斯特 著,李博杰 译,人民邮电出版社,2025)