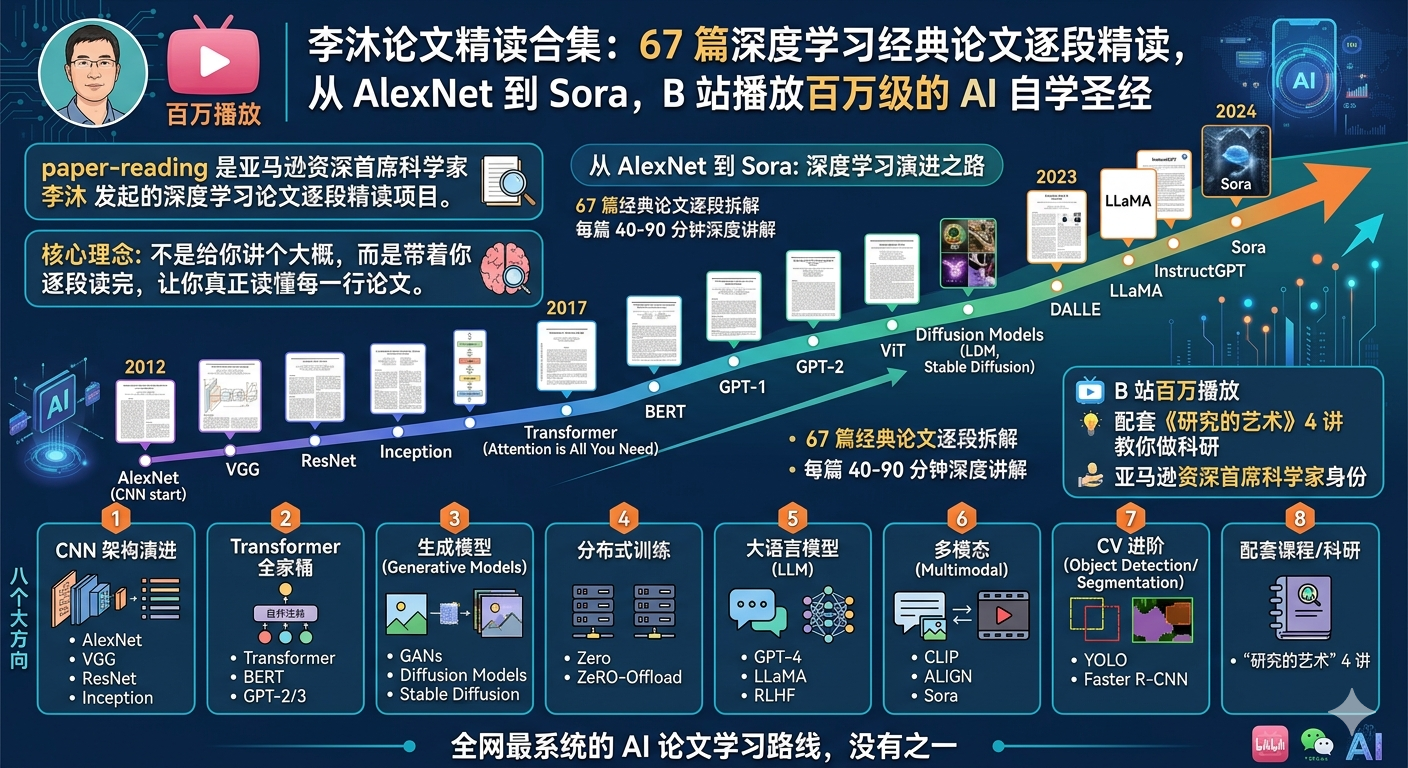
李沐论文精读合集:67 篇深度学习经典论文逐段精读,从 AlexNet 到 Sora,B 站播放百万级的 AI 自学圣经
💡 学深度学习读不懂论文?跟着李沐逐段精读!从 AlexNet 到 Sora,从 Transformer 到 GPT-4,67 篇经典论文逐段拆解,每篇 40-90 分钟深度讲解,B 站百万播放量的论文精读项目。涵盖 CNN 架构演进、Transformer 全家桶、生成模型、分布式训练、大语言模型、多模态等 8 大方向,配套《研究的艺术》4 讲教你做科研。全网最系统的 AI 论文学习路线,没有之一。
📌 目录
- [1. 项目是什么?](#1. 项目是什么?)
- [2. 为什么你需要它?](#2. 为什么你需要它?)
- [3. 8 大方向论文路线图](#3. 8 大方向论文路线图)
- [4. 精读论文完整清单](#4. 精读论文完整清单)
- [5. 特色:不只读论文,还教做科研](#5. 特色:不只读论文,还教做科研)
- [6. 如何使用这个项目?](#6. 如何使用这个项目?)
- [7. 优缺点与学习建议](#7. 优缺点与学习建议)
- [8. 总结](#8. 总结)
1. 项目是什么?
paper-reading 是亚马逊资深首席科学家 李沐 (Mu Li)发起的深度学习论文逐段精读项目。
核心理念:不是给你讲个大概,而是带着你逐段读完,让你真正读懂每一行论文。
- 🔗 项目地址:https://github.com/mli/paper-reading
- 📺 B 站频道:跟李沐学AI
- 🌐 YouTube:Mu Li
- 📖 配套教材:《动手学深度学习》d2l.ai
- ⭐ GitHub Star:26K+
- 📊 总论文数:67 篇
- 🎬 已录制:32+ 期
李沐是谁?
| 身份 | 说明 |
|---|---|
| 亚马逊资深首席科学家 | 从事 AI 研究与系统开发 |
| 《动手学深度学习》作者 | 全球最畅销的中文深度学习教材 |
| Parameter Server 作者 | 分布式训练经典论文(OSDI'14) |
| MXNet 联合创始人 | 深度学习框架 |
| B 站百万粉丝 UP 主 | 论文精读播放量累计过亿 |
一个既做过系统、又做过算法、还写得了教材、讲得了课的 AI 全栈大佬。
2. 为什么你需要它?
读论文的三个层次
| 层次 | 说明 | 你可能在哪 |
|---|---|---|
| ❶ 知道名字 | 听说过 Transformer、BERT,但不清楚细节 | 入门 |
| ❷ 读过摘要 | 知道做了什么、结果多好,但没看实现 | 初级 |
| ❸ 逐段精读 | 每一行公式都理解,知道为什么这么设计 | 进阶 |
李沐的精读带你从 ❶ 直达 ❸。
传统读论文的痛点
| 痛点 | 李沐精读的解法 |
|---|---|
| 英文论文读不下去 | 中文逐段讲解,不用查词典 |
| 公式看不懂 | 逐步推导,从直觉到形式化 |
| 不知道为什么这么设计 | 讲设计思路,不只讲是什么还讲为什么 |
| 不知道论文之间的关系 | 串讲,讲清楚前后文脉络 |
| 读完了还是不会做科研 | 《研究的艺术》4 讲,教方法论 |
| 没有系统学习路线 | 8 大方向分类,从基础到前沿 |
3. 8 大方向论文路线图
路线一:CNN 架构演进 🏗️
从 AlexNet 到 EfficientNet,看 CNN 架构十年进化史:
AlexNet (2012) 深度学习奠基作
↓
VGG (2014) 用 3×3 卷积堆叠更深网络
GoogleNet (2014) 并行架构 Inception
↓
ResNet (2015) 残差连接,撑起 CV 半边天 ⭐
↓
MobileNet (2017) 终端设备轻量 CNN
EfficientNet (2019) 架构搜索 SOTA
Non-deep Networks (2021) 不深的网络也能刷 SOTA必读:AlexNet → ResNet,这两篇理解了,CNN 架构演进的主线就通了。
路线二:Vision Transformer 🎯
Transformer 从 NLP 杀入 CV 的完整路径:
Transformer (2017) Attention Is All You Need ⭐
↓
ViT (2020) 图像当 16×16 words ⭐
↓
Swin Transformer (2021) 层次化 ViT ⭐
MLP-Mixer (2021) 用 MLP 替代 Attention
↓
MAE (2021) BERT 的 CV 版 ⭐必读:Transformer → ViT → MAE,理解 ViT 的来龙去脉。
路线三:生成模型 🎨
从 GAN 到 Diffusion 到 DALL·E 2,生成模型十年演进:
GAN (2014) 生成模型开创工作 ⭐
↓
DCGAN → WGAN → CycleGAN → StyleGAN → StyleGAN2 → StyleGAN3
↓
DDPM (2020) Diffusion Models ⭐
Improved DDPM → Guided Diffusion
↓
DALL·E 2 (2022) CLIP + Diffusion ⭐
↓
Sora (2024) 视频生成 ⭐
Movie Gen (2024) 精确视频编辑
HunyuanVideo (2025) 开源视频生成必读:GAN → DDPM → DALL·E 2 → Sora,这条线串起来就是生成模型的全部精华。
路线四:目标检测 🔍
从 R-CNN 到 DETR,检测范式演进:
R-CNN (2014) Two-stage 开山
Fast R-CNN (2015)
Faster R-CNN (2015) RPN + ROI Pooling ⭐
↓
SSD (2016) Single stage
YOLO (2016) You Only Look Once
↓
DETR (2020) Transformer 检测 ⭐路线五:大语言模型 💬
从 GPT-1 到 Llama 3.1,大模型演进完整路线:
GPT → GPT-2 → GPT-3 (2020) 自回归语言模型 ⭐
↓
InstructGPT (2022) RLHF 对齐 ⭐
↓
GPT-4 (2023) 多模态大模型 ⭐
↓
Llama 3.1 (2024) 开源大模型 ⭐
· 1. 导言
· 2. 预训练数据
· 3. 模型架构
· 4. 训练 Infra
· 5. 训练过程
↓
Anthropic LLM 安全对齐
HELM 全面评测
Chain of Thought 思维链 ⭐必读:GPT-3 → InstructGPT → GPT-4 → Llama 3.1,这是理解大模型的核心路线。
路线六:多模态 🌈
CLIP → ViLT → CLIP 改进串讲 → 多模态论文串讲:
CLIP (2021) 对比学习图文对齐 ⭐
↓
ViLT (2021) 极简多模态 Transformer
↓
CLIP 改进串讲(上/下) CLIP 生态全景
↓
多模态串讲(上/下) 多模态论文全景路线七:分布式训练 ⚡
大规模训练的核心系统工作:
Parameter Server (2014) 分布式训练奠基 ⭐
↓
GPipe (2019) 流水线并行
↓
Megatron LM (2019) 张量并行 ⭐
↓
ZeRO (2020) 零冗余优化 ⭐
↓
Pathways (2022) 谷歌分布式架构路线八:视频理解 🎬
Two-Stream (2014) 双流网络
↓
I3D (2017) 3D 卷积
↓
视频理解串讲(上/下) 视频理解综述
↓
Whisper (2022) 语音识别 ⭐4. 精读论文完整清单
已录制视频(32+ 期)
| # | 日期 | 论文 | 时长 | 亮点 |
|---|---|---|---|---|
| 1 | 10/06/21 | 如何读论文 | 6:39 | 方法论 |
| 2 | 10/14/21 | AlexNet(9 年后重读) | 19:59 | 奠基作回顾 |
| 3 | 10/15/21 | AlexNet 逐段精读 | 55:21 | 深度学习起源 |
| 4 | 10/21/21 | ResNet(撑起 CV 半边天) | 11:50 | 直觉版 |
| 5 | 10/22/21 | ResNet 逐段精读 | 53:46 | 公式版 |
| 6 | 10/27/21 | Transformer 逐段精读 | 1:27:05 | ⭐ 必读 |
| 7 | 11/03/21 | GNN/GCN 零基础详解 | 1:06:19 | 图神经网络 |
| 8 | 11/09/21 | GAN 逐段精读 | 46:16 | 生成模型起源 |
| 9 | 11/18/21 | BERT 逐段精读 | 45:49 | NLM 里程碑 |
| 10 | 11/29/21 | ViT 逐段精读 | 1:11:30 | Transformer 进 CV |
| 11 | 12/08/21 | MAE 逐段精读 | 47:04 | BERT 的 CV 版 |
| 12 | 12/15/21 | MoCo 逐段精读 | 1:24:11 | 对比学习经典 |
| 13 | 12/20/21 | 对比学习论文综述 | 1:32:01 | ⭐ 全景梳理 |
| 14 | 01/15/22 | Swin Transformer 精读 | 1:00:21 | 层次化 ViT |
| 15 | 01/23/22 | AlphaFold 2 精读 | 1:15:28 | AI+生物 |
| 16 | 02/10/22 | CLIP 逐段精读 | 1:38:25 | ⭐ 多模态里程碑 |
| 17 | 03/03/22 | GPT/GPT-2/GPT-3 精读 | 1:29:58 | ⭐ LLM 起源 |
| 18 | 03/10/22 | OpenAI Codex 精读 | 47:58 | 代码生成 |
| 19 | 03/17/22 | AlphaCode 精读 | 44:00 | 竞赛级编程 |
| 20 | 04/21/22 | Parameter Server 精读 | 1:37:40 | 分布式奠基 |
| 21 | 05/27/22 | GPipe 逐段精读 | 58:47 | 流水线并行 |
| 22 | 06/03/22 | Megatron LM 精读 | 56:07 | 张量并行 |
| 23 | 06/10/22 | DETR 逐段精读 | 54:22 | Transformer 检测 |
| 24 | 06/17/22 | ZeRO 逐段精读 | 52:21 | 零冗余优化 |
| 25 | 07/08/22 | DALL·E 2 逐段精读 | 1:27:54 | ⭐ 文生图 |
| 26 | 09/02/22 | CLIP 改进串讲(上) | 1:14:43 | CLIP 生态 |
| 27 | 10/23/22 | Chain of Thought | 33:21 | ⭐ 思维链 |
| 28 | 11/14/22 | Whisper 精读 | 1:12:16 | 语音识别 |
| 29 | 12/29/22 | InstructGPT | 1:07:10 | ⭐ RLHF |
| 30 | 03/30/23 | GPT-4 | 1:20:38 | ⭐ 多模态大模型 |
| 31 | 7-9/24 | Llama 3.1(5 期连载) | ~2h | ⭐ 开源大模型 |
| 32 | 01/10/25 | Sora + Movie Gen + HunyuanVideo | 1:04:18 | ⭐ 视频生成 |
💡 标注 ⭐ 的是强烈推荐的必读视频,每期都是百万级播放量。
5. 特色:不只读论文,还教做科研
《研究的艺术》4 讲
李沐不仅教读论文,还教你做科研 。基于芝加哥大学经典教材 The Craft of Research,录制了 4 期特别节目:
| 期数 | 主题 | 时长 | 核心内容 |
|---|---|---|---|
| 一 | 跟读者建立联系 | 45:01 | 你的研究写给谁看?如何建立与读者的连接 |
| 二 | 明白问题的重要性 | 1:03:40 | 什么才是值得研究的问题?如何论证重要性 |
| 三 | 如何讲好故事、论点 | 43:56 | 研究写作的叙事结构,如何构建论点 |
| 四 | 理由、论据和担保 | 44:14 | 如何用证据支撑论点,如何回应质疑 |
其他特别节目
| 标题 | 时长 | 主题 |
|---|---|---|
| 如何读论文 | 6:39 | 论文阅读方法论 |
| 如何判断研究工作的价值 | 9:59 | 选题与评估 |
| 如何找研究想法 | 5:34 | 发现研究 gap |
| 论文不够 novel? | 14:11 | 关于新颖性的思考 |
| 大模型时代做科研的四个思路 | 1:06:29 | ⭐ 穷人怎么做研究 |
6. 如何使用这个项目?
学习路径建议
🟢 入门路径(0 基础)
1. 如何读论文(6 分钟)
2. AlexNet 重读 → AlexNet 精读
3. ResNet 重读 → ResNet 精读
4. Transformer 精读
5. BERT 精读🟡 进阶路径(有基础)
1. Transformer 精读(复习)
2. GPT/GPT-2/GPT-3 精读
3. InstructGPT 精读
4. GPT-4 精读
5. Llama 3.1(5 期连载)
6. 大模型时代做科研的四个思路🔴 前沿路径(看最新进展)
1. CLIP 精读 → CLIP 改进串讲
2. MAE 精读 → ViT 精读 → Swin Transformer
3. DDPM → DALL·E 2 → Sora
4. Chain of Thought
5. Llama 3.1 全 5 期观看渠道
| 平台 | 链接 | 特点 |
|---|---|---|
| B 站 | 跟李沐学AI | 中文字幕,弹幕互动 |
| YouTube | Mu Li | 无地区限制 |
| 知乎 | 李沐知乎号 | 部分视频同步 |
配套资源
| 资源 | 链接 | 说明 |
|---|---|---|
| 《动手学深度学习》 | d2l.ai | 系统教材 |
| 直播课 | c.d2l.ai/zh-v2 | 视频课程 |
| GitHub 讨论 | Discussions | 建议选题 |
7. 优缺点与学习建议
✅ 优点
| 维度 | 评分 | 说明 |
|---|---|---|
| 深度 | ⭐⭐⭐⭐⭐ | 真正逐段精读,不是泛泛而谈 |
| 广度 | ⭐⭐⭐⭐⭐ | 67 篇论文,8 大方向全覆盖 |
| 中文讲解 | ⭐⭐⭐⭐⭐ | 中文 AI 社区最高质量论文精读 |
| 设计思路 | ⭐⭐⭐⭐⭐ | 不只讲是什么,更讲为什么 |
| 串讲 | ⭐⭐⭐⭐ | 论文之间的脉络讲得清楚 |
| 更新频率 | ⭐⭐⭐⭐ | 持续更新到 2025 年 Sora |
⚠️ 注意事项
| 事项 | 说明 |
|---|---|
| 视频较长 | 单期 40-90 分钟,需要专注时间 |
| 更新不固定 | 非定期更新,取决于作者时间 |
| 部分方向未录制 | 67 篇中已录制 32+ 期,约一半 |
| 前置知识 | 需要一定 ML/DL 基础,纯小白建议先看 d2l |
| 代码实操少 | 以论文讲解为主,实操参考 d2l 教材 |
💡 学习建议
- 不要贪多:一次精读一篇,比泛读十篇更有价值
- 先看直觉版:如 ResNet 先看 11 分钟的直觉版,再看 53 分钟的公式版
- 边看边记:每期看完写 3 句话总结------做了什么、为什么这么做、效果如何
- 配合 d2l:论文精读是"为什么",d2l 是"怎么做",两条线并行
- 参与讨论:在 GitHub Discussions 建议选题、提问讨论
8. 总结
李沐论文精读项目是中文 AI 社区的无价之宝:
- 📚 67 篇经典论文:从 AlexNet 到 Sora,深度学习十年精华
- 🎯 逐段精读:不是讲个大概,是带你每一行都读懂
- 🧭 8 大方向路线图:CNN / ViT / 生成模型 / 检测 / LLM / 多模态 / 分布式 / 视频理解
- 📖 《研究的艺术》4 讲:不只教读论文,还教做科研
- 🎬 B 站百万播放:每期都是精打细磨的精品内容
- 👨🏫 作者背景:Parameter Server 作者、d2l 作者、亚马逊首席科学家
推荐指数:⭐⭐⭐⭐⭐
无论你是刚入门的 AI 学生,还是想系统补课的工程师,这个项目都是你最好的论文学习伙伴。花 50 分钟看一期精读,胜过自己啃 5 小时论文。
标签:#论文精读 #李沐 #Transformer #GPT #大模型 #AI学习路线