一、前言:AI、机器学习与深度学习的从属关系
深度学习(DL)隶属于机器学习(ML),机器学习又是人工智能(AI)落地实现的重要分支,三者是包含关系 :人工智能>机器学习>深度学习。
- 人工智能:目标是让机器模拟人类思考、感知、决策;
- 机器学习:不用硬编码规则,让机器从数据中自动学习规律;
- 深度学习:基于多层人工神经网络的机器学习分支,模仿人脑神经元结构,也是当前大模型(ChatGPT等)底层核心技术(ChatGPT依托百亿级参数深度神经网络训练)。
图1:AI-机器学习-深度学习层级关系图

人类大脑依靠亿万个生物神经元传递神经冲动完成信息处理,人工神经网络就是模仿生物神经元结构诞生,下文从单个神经元开始逐层拆解。
二、基础单元:人工神经元(MP神经元)与激活函数
2.1 单个神经元数学由来
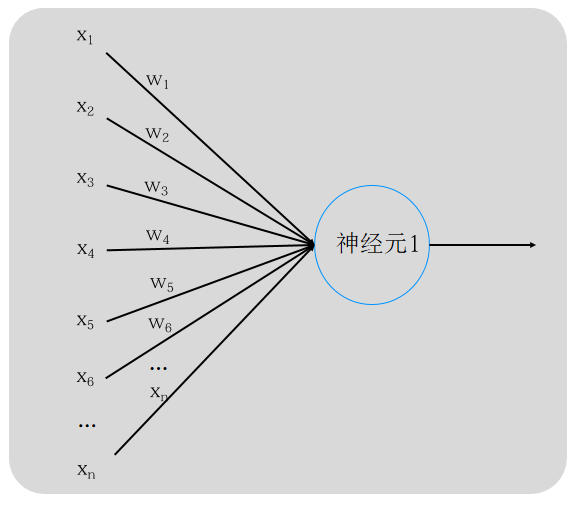
线性方程:y=kx+by=kx+by=kx+b,拓展至多特征:w1x1+w2x2+b=0w_1x_1+w_2x_2+b=0w1x1+w2x2+b=0,把偏置bbb改写为w3×1w_3×1w3×1,公式统一:
z=w1x1+w2x2+w3×1=∑i=1nwixiz = w_1x_1+w_2x_2+w_3×1=\sum_{i=1}^n w_ix_iz=w1x1+w2x2+w3×1=i=1∑nwixi
- x1,x2...xnx_1,x_2...x_nx1,x2...xn:输入特征;
- w1,w2...wnw_1,w_2...w_nw1,w2...wn:权重(模型待训练参数,相当于神经元突触连接强度);
- 常数1:偏置项(b),固定为1,用于平移线性函数、提升模型拟合能力。
图2:单个神经元结构示意图
2.2 激活函数Sigmoid:引入非线性
单纯加权求和z=∑wixiz=\sum w_ix_iz=∑wixi仍是线性运算 ,无法拟合非线性数据;因此神经元输出必须接入非线性激活函数Sigmoid :
σ(z)=11+e−z\sigma(z)=\frac1{1+e^{-z}}σ(z)=1+e−z1
Sigmoid可以把任意实数映射到0,10,10,1区间,完成数值归一化,是早期神经网络最常用激活函数。
核心结论:权重做线性加权 + 激活函数做非线性变换 = 完整人工神经元。
三、单层网络:感知器(Perceptron)原理与局限
3.1 感知器结构
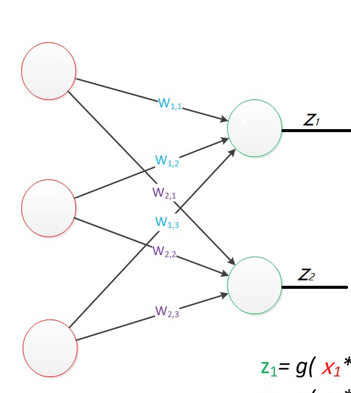
由输入层+输出层两层神经元 组成,无中间隐藏层,是最原始神经网络:
z=g(W⋅X)z=g(W·X)z=g(W⋅X)
矩阵形式:输入向量XXX × 权重矩阵WWW → 加权和zzz → 激活g()g()g()得到输出。
图3:单层感知器结构图(输入3节点+输出2节点)
。
3.2 感知器致命缺陷
仅能实现线性分类 ,无法处理异或(XOR)等非线性数据。想要解决非线性分类,必须新增隐藏层,也就是多层感知器(MLP)。
四、进阶网络:多层感知器MLP(含隐藏层+偏置节点)
4.1 引入隐藏层实现非线性拟合
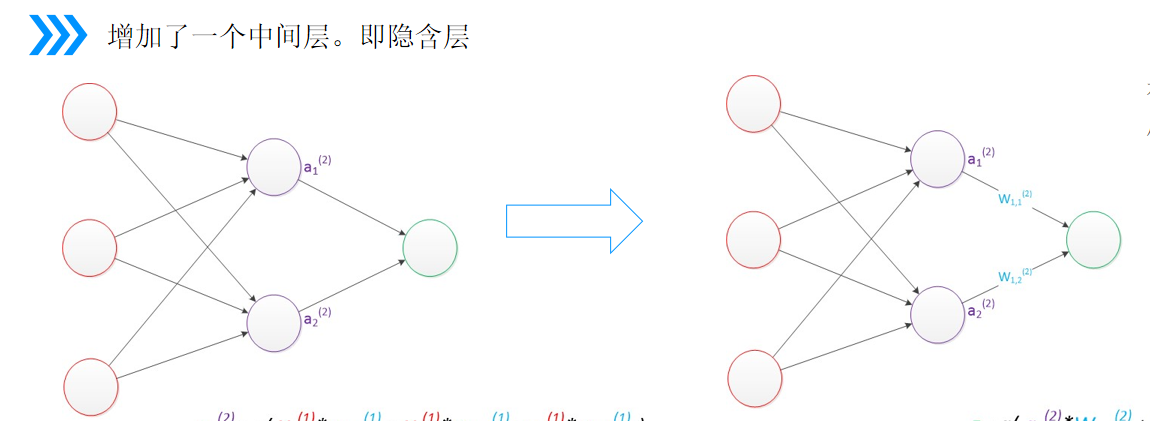
在输入、输出层中间新增隐藏层(隐含层),是神经网络实现非线性分类的关键:
- 数据流向:输入层→隐藏层(加权+激活)→输出层(加权+激活);
- 每一层除输出层外,默认自带偏置神经元 :节点值永久=1,无上层输入连线,用于补充偏置bbb,画图时常省略不画。
图4:三层MLP结构图(输入-隐藏-输出+偏置节点标注)
4.2 神经网络节点数设计经验(必记3条)
- 输入层节点数 = 样本特征维度:比如6维特征,输入层设6个神经元;
- 输出层节点数 = 预测目标维度:二分类1个节点、三分类3个节点;
- 隐藏层节点无权威公式:靠实验调参,多设置几组数值,对比测试集效果择优选用。
一句话总结:隐藏层+激活函数 = 神经网络万能拟合能力的来源。
五、神经网络训练核心1:损失函数(衡量预测误差)
5.1 训练目标
随机初始化权重WWW,前向传播得到预测值ypredy_{pred}ypred,用损失函数Loss 计算预测值和真实标签ytruey_{true}ytrue的差距,损失越小代表模型越准,训练本质就是不断优化权重最小化Loss。
常用损失:0-1损失、均方误差MSE、平均绝对误差MAE、交叉熵CrossEntropy(分类首选)、合页损失。
5.2 多分类任务:交叉熵损失详解
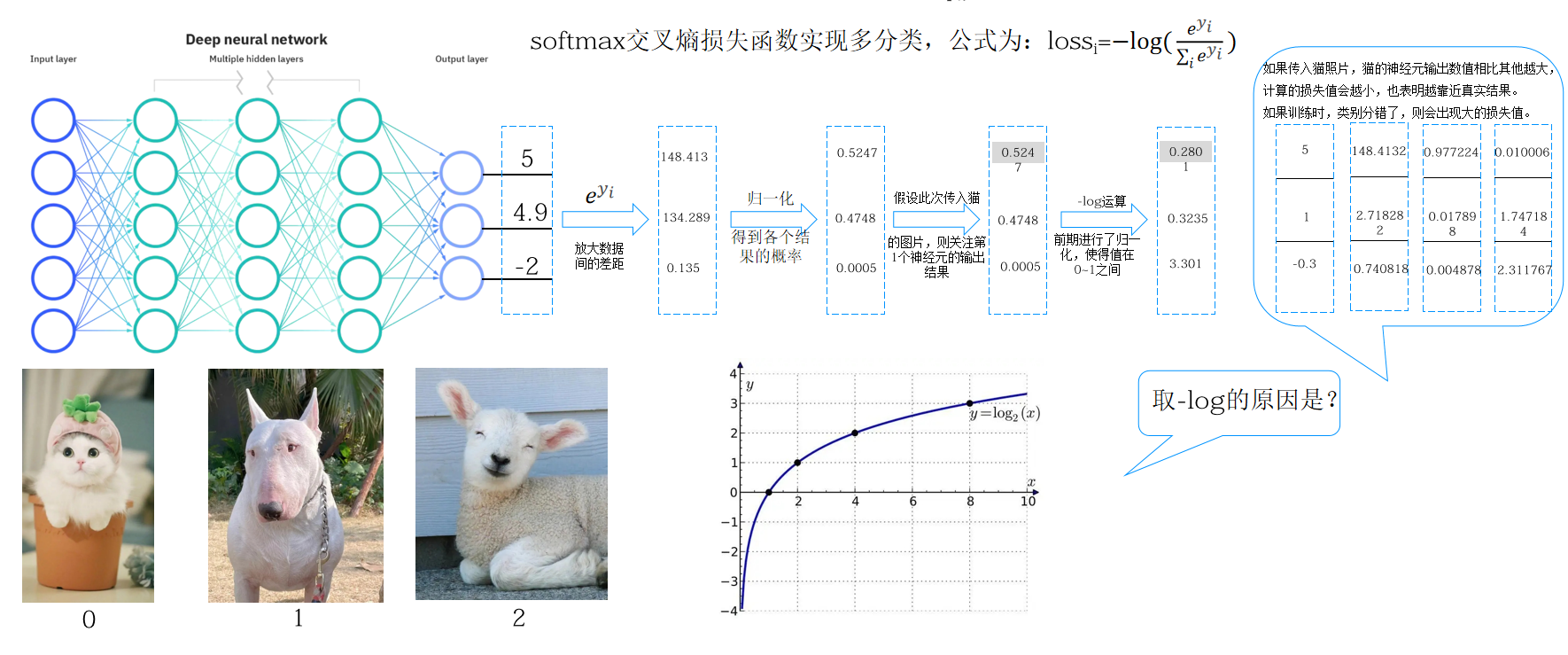
多分类场景先用Softmax把网络输出转为0~1概率(所有类别概率和=1),再用负对数交叉熵:
Loss=−∑c=1Myic⋅log(pic)Loss=-\sum_{c=1}^M y_{ic}\cdot log(p_{ic})Loss=−c=1∑Myic⋅log(pic)
- yicy_{ic}yic:真实标签独热编码(正确类别=1,其余=0);
- picp_{ic}pic:模型预测样本属于类别c的概率。
图5:Softmax+交叉熵计算流程图(猫/狗/鸟三分类示例)
。
为什么用负对数(-log)?
- 模型预测正确类别概率越大,−log(p)-log(p)−log(p)数值越小(损失小);
- 预测概率趋近0时,−log(p)-log(p)−log(p)急剧变大(严厉惩罚错误分类),优化导向更精准。
六、神经网络训练核心2:正则化(解决过拟合)
6.1 过拟合现象举例
权重w1=1,0,0,0w_1=1,0,0,0w1=1,0,0,0只依赖第一个特征,极易死记训练数据、测试效果差;
权重w2=0.25,0.25,0.25,0.25w_2=0.25,0.25,0.25,0.25w2=0.25,0.25,0.25,0.25均分所有特征权重,泛化性更好。
过拟合:模型在训练集损失极低,陌生测试集损失很高,正则化通过惩罚权重抑制过拟合。
6.2 L1、L2正则化原理
- L1正则:L1=∑∣wi∣L1=\sum|w_i|L1=∑∣wi∣:权重绝对值求和,几何约束为菱形,易让部分权重压缩至0,实现自动特征筛选(稀疏化参数);
- L2正则:L2=∑wi2L2=\sum w_i^2L2=∑wi2:权重平方和,几何约束为圆形,所有权重均匀缩小、趋近于0但不为0,权重雨露均沾、充分利用所有特征。
七、神经网络训练核心3:梯度下降(权重更新算法)
7.1 梯度与偏导数
- 偏导数:多变量函数固定其余变量,只对单个参数求导;
- 梯度 :所有参数偏导数组成的向量,指向损失函数上升最快方向;
- 梯度下降 :参数沿着梯度反方向移动,不断降低损失,类比下山找山谷最低点。
参数更新公式:
Wnew=Wold−η⋅∇Loss(Wold)W_{new}=W_{old}-\eta·\nabla Loss(W_{old})Wnew=Wold−η⋅∇Loss(Wold)
- η\etaη:学习率(步长),太大震荡不收敛、太小收敛极慢;
- ∇Loss\nabla Loss∇Loss:损失对权重的梯度。
配图6:梯度下降下山示意图(二维损失曲面)
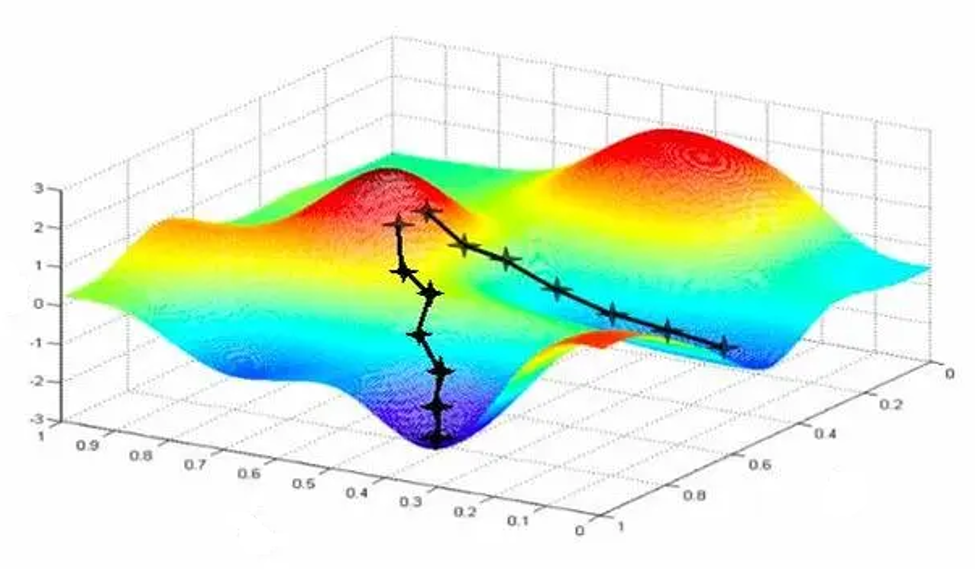
八、完整训练链路:BP反向传播算法(前向+反向闭环)
BP(Back Propagation)反向传播是多层神经网络标准训练流程,分为前向传播算预测、反向传播调权重两大阶段,循环迭代至损失达标。
BP五步完整流程
- 前向传播 :输入数据逐层加权+激活,从输入→隐藏→输出,得到预测值yp=g(W⋅X)y_p=g(W·X)yp=g(W⋅X);
- 计算总损失:结合交叉熵+正则项,算出当前批次Loss;
- 反向求梯度 :链式法则从输出层倒推,逐层计算损失对每层权重WWW的梯度;
- 梯度下降更新权重:用学习率和梯度,全层权重统一更新;
- 循环迭代:反复前向+反向,直到整体损失低于设定阈值,模型训练完成。