
预定子图 -- 人工介入的预定系统
接下来我们一起完成预定子图的开发。在正式写代码之前,我们先回顾房源预定的整体业务需求,梳理完整的业务逻辑。
结合之前实现的推荐子图来看,目前推荐子图的功能,是根据用户需求筛选并推送匹配的房源。当系统完成房源推荐后,会向用户发起询问:"已为您推荐合适的房源,是否需要帮您预定?"。需要注意的是,询问用户是否预定这一步,属于主图的逻辑,并非预定子图的功能。
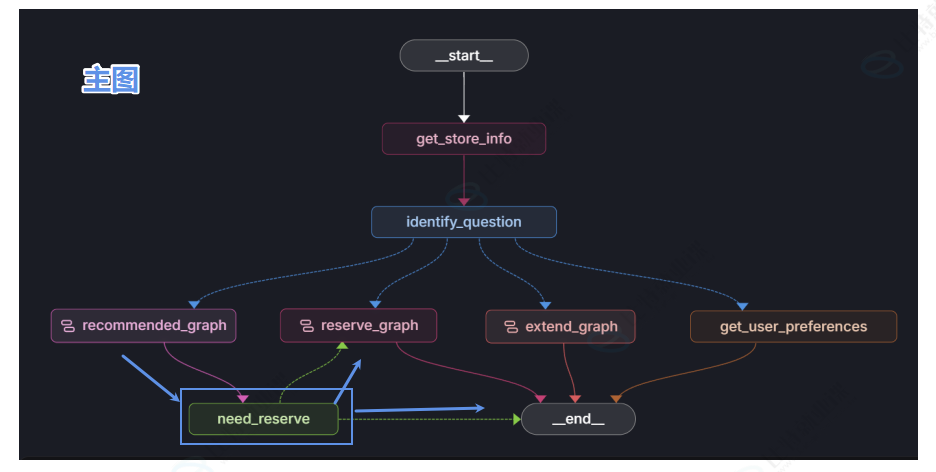
我们把整体业务流程拆分为三大模块,方便大家理解:第一部分是推荐子图 ,负责为用户筛选、推荐房源;推荐子图执行完毕后,流程回到主图 ,主图中有一个专门的节点[need_reserver],作用是询问用户是否要进行房源预定,这个节点会触发流程中断,等待用户指令。
状态定义
明确整体架构后,我们聚焦预定子图本身。预定子图的入口,是引导用户输入需要预定的房源名称,这一步我们会用到interrupt中断机制。具体逻辑为:预定子图启动后,首先进入第一个节点 ------ 获取房源名称[get_title],在这个节点中循环使用中断功能,反复收集用户输入,直到拿到合法有效的房源名称为止。
接下来我们逐个拆解预定子图的节点功能、输入输出,再根据节点逻辑定义子图对应的state状态。 整个流程的初始输入,依然是用户发出的HumanMessage,比如用户发送 "我要预定房源"。主图会通过智能路由,识别到用户的预定诉求,将流程转发至预定子图。子图启动后,第一个节点开始收集信息:
-
获取房源名称
[get_title]:通过中断拿到用户输入的房源名称title,该字段会存入状态中,不再单独放在消息列表里; -
获取预定手机号
[get_phone]:逻辑和第一个节点一致,依靠中断收集用户手机号phone_number,同步更新状态字段; -
获取身份证号码
[get_id]:同样使用中断收集身份证号id_card,完成第三个状态字段的赋值。
以上三个节点,核心逻辑都是借助中断交互、循环校验,确保收集到合规的用户信息。当这三个节点全部执行完成后,房源名称、手机号、身份证号这三组核心预定信息就全部收集完毕。
收集完基础信息后,我们的最终目标是生成预定工单 ,工单的结果最终会以AIMessage的形式返回给用户,展示类似 "预定成功 + 工单号" 的内容。而工单号的生成,必须依赖前面收集的房源名称、手机号、身份证号三组数据,三者存在强依赖关系,无法单独生成。
生成工单号的逻辑,我们会封装成独立工具 ,工具执行后会返回ToolMessage,这条消息会回流到call_orders节点。这里也符合我们之前讲过的标准调用流程:AIMessage(携带工具调用指令)→ ToolMessage(工具执行结果)→ 最终AIMessage(业务结果)。其中,判断是否调用工具、接收工具返回结果,都由call_orders节点负责,图中的虚线也代表这一层判断逻辑。
这里有一个关键细节:初始的HumanMessage只有 "我要预定房源" 这一句话,缺少手机号、身份证、房源名称等核心数据,大模型无法直接调用工具生成工单。因此我们需要新增一个节点[get_reserver_message],专门拼接构建新的 HumanMessage,把前面收集到的三组预定信息,整合进消息内容中,为后续工具调用提供完整数据支撑。
综合所有字段可以确定预定子图的状态结构:继承基础的MessagesState(自带消息列表),再额外定义三个自定义字段:title(预定房源名称)、phone_number(预定手机号)、id_card(身份证号码)。这就是预定子图完整的状态,整体结构比推荐子图简单,整个子图的核心难点,就是使用中断机制循环收集用户信息。
state/reserve.py
python
from langgraph.graph import MessagesState
# 预定状态
class ReserveState(MessagesState):
title: str # 预定的房源
phone_number: str # 预定电话
id_card: str # 身份证节点实现
状态定义完成后,我们开始逐个实现业务节点,节点统一放在node目录的reserve.py下。
第一个节点get_title,功能是通过中断获取房源名称。
节点内设置提示语 "请输入要预定的房源名称",调用interrupt接收用户输入的内容并赋值给title。
基础校验逻辑判断title是否为空:如果不为空,直接将数据更新到状态并退出当前节点;如果为空,代表校验失败,需要重新引导用户输入。为了实现循环交互,我们使用while循环包裹整个逻辑,校验失败后动态修改提示语,告知用户 "输入的内容不是有效房源名称,请更正",直到收集到合法内容为止。后面也可以扩展校验规则,比如对接数据库,判断输入的房源名称是否真实存在。
python
# 节点:获取用户预定房源
def get_title(state: ReserveState):
prompt = "请输入要预定的房源名称"
while True:
title = interrupt(prompt)
if title: # 可以进行验证
return {"title": title}
# 每次验证失败后,提示信息会更新
prompt = f"'{title}' 不是一个有效的房源名称,请更正。"第二个节点get_phone,作用是获取用户预定手机号,整体逻辑和get_title完全一致。仅修改提示语为 "请输入要预定的手机号",校验手机号是否为空,校验失败则提示 "输入内容不是有效电话,请更正",同样依靠循环 + 中断反复收集信息。
python
# 节点:获取用户预定电话
def get_phone(state: ReserveState):
prompt = "请输入要预定的手机号"
while True:
phone_number = interrupt(prompt)
if phone_number: # 可以进行验证
return {"phone_number": phone_number}
# 每次验证失败后,提示信息会更新
prompt = f"'{phone_number}' 不是一个有效的电话,请更正。"第三个节点get_id,用于获取身份证号码,逻辑保持统一。提示语改为 "请输入要预定的身份证号码",空值校验失败后提示 "输入内容不是有效身份证,请更正"。在正式的企业项目中,手机号、身份证都可以对接第三方接口做格式、真实性校验,这里我们只实现基础的循环收集流程。
python
# 节点:获取用户身份证
def get_id(state: ReserveState):
prompt = "请输入要预定的身份证号码"
while True:
id_card = interrupt(prompt)
if id_card: # 可以进行验证
return {"id_card": id_card}
# 每次验证失败后,提示信息会更新
prompt = f"'{id_card}' 不是一个有效的身份证,请更正。"完成三个信息收集节点后,接下来实现拼接消息的节点 。这个节点的作用,是把状态中已收集的title、phone_number、id_card三组数据,整合为一条新的HumanMessage。我们先编写消息模板,内容为 "根据提供的信息,帮我预定房源",并预留房源标题、预定号码、身份证号码三个占位符;再读取状态中的对应字段,填充模板生成完整消息,最后将这条新的HumanMessage更新到状态的消息列表中。只有构建出这条包含完整预定信息的消息,后续大模型才能正常调用工具生成工单。
python
# 节点:新增预定消息
def add_reserve_message(state: ReserveState):
reserve_prompt = """根据提供的信息,帮我预定房源。
- 预定的房源标题:{title}
- 用户的预定号码:{phone_number}
- 用户身份证号码:{id_card}"""
reserve_message = HumanMessage(content=reserve_prompt.format(
title=state['title'],
phone_number=state['phone_number'],
id_card=state['id_card']
))
return {"messages": [reserve_message]}下一个核心节点命名为call_orders,它有两大核心功能:
python
一是让大模型判断是否调用生成工单的工具;
二是接收工具的返回结果,整理后输出最终回复。编码时,首先将之前定义的生成工单工具 与大模型进行绑定,接着调用模型执行逻辑。同时配置SystemMessage作为系统提示词,内容为 "你是一个工单生成的助手,支持调用工具进行房源预定工单生成,可查看查询结果并返回最终答案"。系统提示词配合状态中的消息列表,共同传入大模型执行,最终将模型返回的AIMessage更新到状态中。
python
# 节点:生成工单结果
def call_orders(state: ReserveState):
response = model.bind_tools([generate_orders]).invoke(
[SystemMessage(content="你是一个工单生成的助手,支持调用工具进行房源预定工单生成。支持查看查询的结果并返回最终答案")]
+ state["messages"]
)
return {"messages": [response]}这里补充一个设计思路:能不能把 "拼接 HumanMessage" 和 "调用模型" 合并为一个节点?其实不建议这样做。因为工具执行完成后,结果会回流到call_orders节点,如果两个逻辑合并,每次回流都会重复拼接新的HumanMessage,造成逻辑冗余。因此拆分两个节点是更合理的写法。
最后我们来实现生成工单的工具,这也是整个预定子图的工具节点。这个工具主要完成两件事:
-
第一,根据用户信息生成唯一工单号;
-
第二,将预定信息持久化存储。【重点】
首先我们需要了解工具的参数配置: 在 LangGraph 的工具中,如果需要使用运行上下文ToolRuntime和持久化存储InjectedStore,必须使用框架规定的注解方式注入,这是固定写法。ToolRuntime可以拿到上下文里的user_id,InjectedStore则用来操作持久化存储空间,这两个参数的注入方式和普通节点直接调用有明显区别,大家一定要牢记。工具的入参还包括phone_number、id_card、house_title三组预定信息,工具最终返回字符串类型的执行结果。
python
# 工具:生成订单
# store: Annotated[Any, InjectedStore()] 参考:
# https://python.langchain.com/docs/how_to/tools_injected_state/#langgraph
# 工具:生成订单
@tool
def generate_orders(phone_number: str, id_card: str, house_title: str,
runtime: ToolRuntime, store: Annotated[Any, InjectedStore()]) -> str:
"""根据用户电话,身份证,预定房源。
Args:
phone_number: 用户电话
id_card: 用户身份证
house_title: 用户要预定的房源标题
store: 注入工具的持久存储
"""
# 1. 生成工单号(先造ID,再传给模型,解决必填项报错)
order_id = str(uuid.uuid4())
# 2. 构建预定信息:补齐必填 order_id
reserved_house = ReservedInfo(
order_id=order_id,
title=house_title,
phone_number=phone_number
)
# 3. 持久化用户偏好(预定信息)
user_id = runtime.context.get("user_id")
namespace = (user_id, "preferences")
prefs_result = store.search(namespace)
# 固定 key,用于覆盖更新,不再随机生成
fixed_key = "user_reserve_prefs"
if len(prefs_result) == 0:
# 没有持久化信息,新增:字段名和模型保持 reserved_info
prefs = UserPreferences(reserved_info=[reserved_house])
store.put(
namespace,
fixed_key,
prefs.model_dump(exclude_none=True)
)
else:
# 读出字典 → 转回模型操作,保证类型统一
item = prefs_result[0]
prefs_dict = item.value or {}
prefs = UserPreferences(**prefs_dict)
# 处理 Optional 空值,确保列表可追加
if prefs.reserved_info is None:
prefs.reserved_info = []
prefs.reserved_info.append(reserved_house)
# 模型转字典写回
store.put(
namespace,
item.key,
prefs.model_dump(exclude_none=True)
)
return f"已成功预定房源: {house_title}, 预定工单号为: {order_id}"工具内部逻辑分步实现:
第一步,生成工单号。我们使用uuid模拟生成唯一工单号,在真实项目中,可以对接数据库,从订单表中生成正式工单编号。
第二步,构建预定信息实体。提取房源名称、手机号、工单号等关键数据,封装为预定信息对象。这里注意隐私保护原则:身份证属于敏感隐私数据,不需要存入持久化的用户偏好中。
第三步,数据持久化。先通过ToolRuntime获取当前用户的user_id,再拼接出对应的存储命名空间namespace。
先调用store.search查询该用户已有的偏好数据:
-
如果查询结果为空,说明该用户暂无任何预定记录,直接新建用户偏好对象,把当前预定信息加入列表,再通过store.put完成新增存储;
-
如果查询结果不为空,说明用户已有历史偏好数据,取出原有数据,利用setdefault为预定房源列表设置默认值,再将本次新的预定信息追加到列表末尾,最后调用store.put更新存储空间。
工具执行完成后,拼接 "预定成功 + 房源名称 + 工单号" 的文本内容作为返回值,这条结果会以ToolMessage的形式回流到call_orders节点,再由大模型整理成最终回复展示给用户。
拓展一下功能:目前我们只把预定信息存入了用户偏好存储中,我们后面可以继续扩展,对接 MySQL 数据库,单独设计订单表,将每一条预定工单完整落地到数据库里,完善真实业务链路。
至此,预定子图的所有节点、工具、状态逻辑就全部开发完毕。所有代码编写完成后,最后一步就是整合所有节点,构建完整的图结构,再进行整体功能测试。
工作流定义
接下来我们开始正式搭建预定子图的整体图结构,并完成代码编写,最后借助 LangSmith 平台对子图进行全流程测试。
首先回到项目目录,在顶层的 agent 文件夹下新建文件,专门用来构建预定子图。我们先初始化图结构,引入之前定义好的 ReserveState 状态类,同时把运行上下文也一并传入,按照 LangGraph 标准写法创建图构造器。
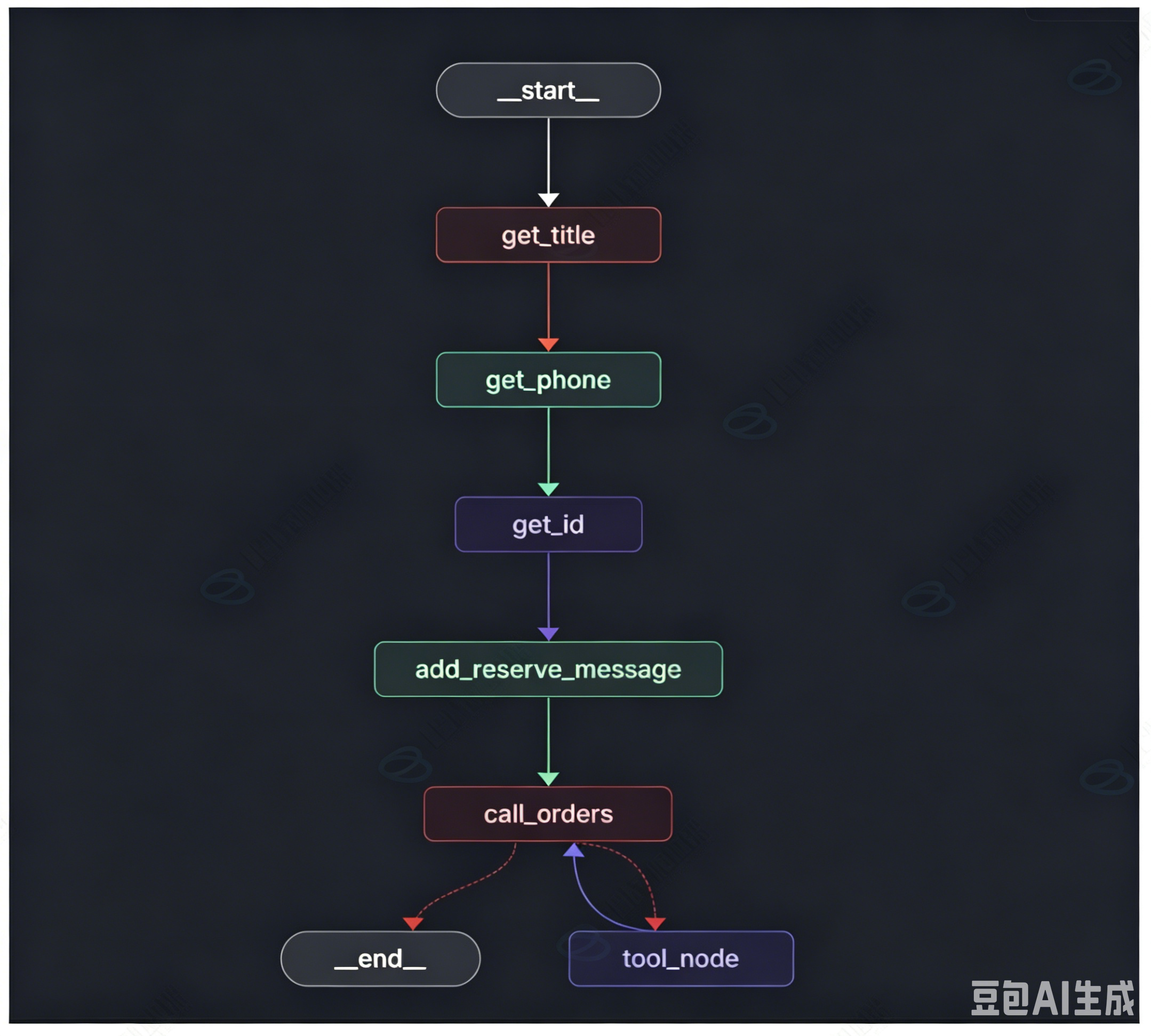
准备工作完成后,开始向图中逐个添加节点。本次用到的节点数量较多,且前序节点都是按固定顺序串行执行,这种场景适合使用 add_sequence 方法批量添加顺序节点。我们依次导入并添加节点:第一个是get_title、第二个是get_phone、第三个是get_id,紧接着是拼接消息的节点add_reserve_message,最后串行节点收尾为call_orders。
顺序节点添加完毕后,还有一个工具节点tool_node没有配置,这个节点无法加入串行流程,需要单独调用add_node方法进行添加。所有节点全部注册完成后,下一步开始配置节点之间的连线。
首先设置图的起始边,将入口START指向串行流程的第一个节点get_title。由于add_sequence会自动帮我们完成内部节点的前后连线,所以中间节点的边不需要手动配置。整个图里还剩下条件边 需要处理,条件边的起点是call_orders节点。
这里我们直接使用框架内置的tools_condition来做路由判断,它会自动识别call_orders输出的消息中是否携带工具调用指令。同时配置路由映射规则: 如果判定需要调用工具,就流转到tool_node工具节点;如果不需要调用工具,就直接走到流程终点END。除此之外,还要补充一条固定连线:工具节点tool_node执行完成后,流程需要再次回到call_orders节点,形成闭环调用逻辑。
所有节点和连线配置完成,调用compile()方法编译图,得到最终可运行的预定子图实例。
agent/reserve.py
python
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
from src.agent.node.reserve import (
get_title,
get_phone,
get_id,
add_reserve_message,
call_orders,
generate_orders
)
from src.agent.state.reserve import ReserveState
builder = StateGraph(ReserveState)
builder.add_sequence([get_title, get_phone, get_id, add_reserve_message, call_orders])
builder.add_node("tool_node", ToolNode([generate_orders]))
builder.add_edge(START, "get_title")
builder.add_conditional_edges(
"call_orders",
tools_condition,
{
"tools": "tool_node",
"__end__": END,
},
)
builder.add_edge("tool_node", "call_orders")
reserve_graph = builder.compile()编写完成后,我们先打印并可视化图结构,检查节点、连线是否符合预期。
python
print(reserve_graph.get_graph().draw_mermaid())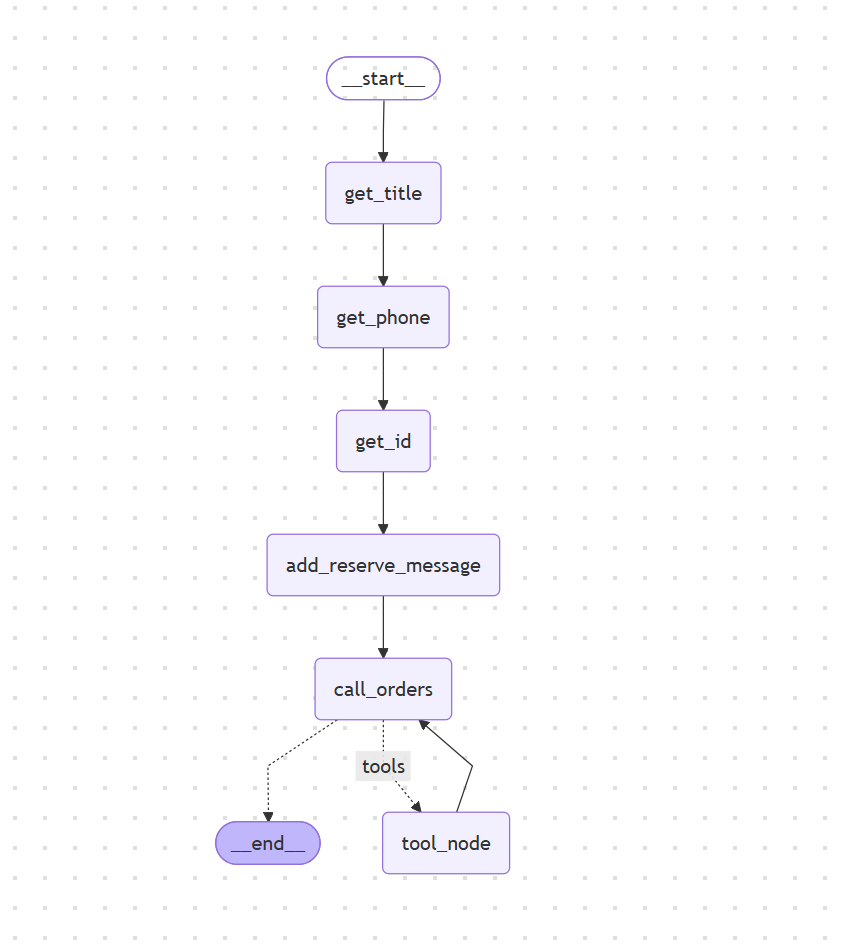
从可视化结果能清晰看到完整流程:获取房源名称→获取手机号→获取身份证→拼接预定消息→调用模型判断工具调用,整体逻辑和我们前期设计完全一致。
图结构校验通过后,接下来要把子图整合到整个项目中,分为两处配置修改。第一处是在项目初始化文件里引入并注册预定子图;第二处是在项目配置文件中补充对应配置,统一命名格式、填写文件路径与子图实例名称,保证项目能够正常识别加载该子图。
python
{
"$schema": "https://langgra.ph/schema.json",
"dependencies": ["."],
"graphs": {
"agent": "./src/agent/graph.py:graph",
"recommended_agent": "./src/agent/recommend.py:recommended_graph",
"reserved_agent": "./src/agent/reserve.py:reserve_graph"
},
"env": ".env",
"image_distro": "wolfi"
}
python
"""New LangGraph Agent.
This module defines a custom graph.
"""
from src.agent.graph import graph
from src.agent.recommend import recommended_graph
from src.agent.reserve import reserve_graph
__all__ = ["graph", "recommended_graph", "reserve_graph"]全部配置修改完成,启动项目服务。这里提醒大家一个常见问题:如果此前已经启动过 Python 服务,直接重启项目可能看不到最新的预定子图。原因是旧的 Python 进程没有彻底关闭,新请求依然会指向旧服务。解决办法是打开任务管理器,找到所有 Python 相关进程并结束任务,之后再重新执行启动命令,就能正常加载最新代码和子图了。
服务正常运行后,进入 LangSmith 平台开始交互式测试。首先在交互界面输入指令 "我要预定房子" 并提交,流程会进入第一个节点,触发中断并提示输入房源名称。我们输入 "别墅" 作为测试房源,接着按照提示依次填写手机号、身份证号,这里暂时只做非空校验,不做格式合法性校验。
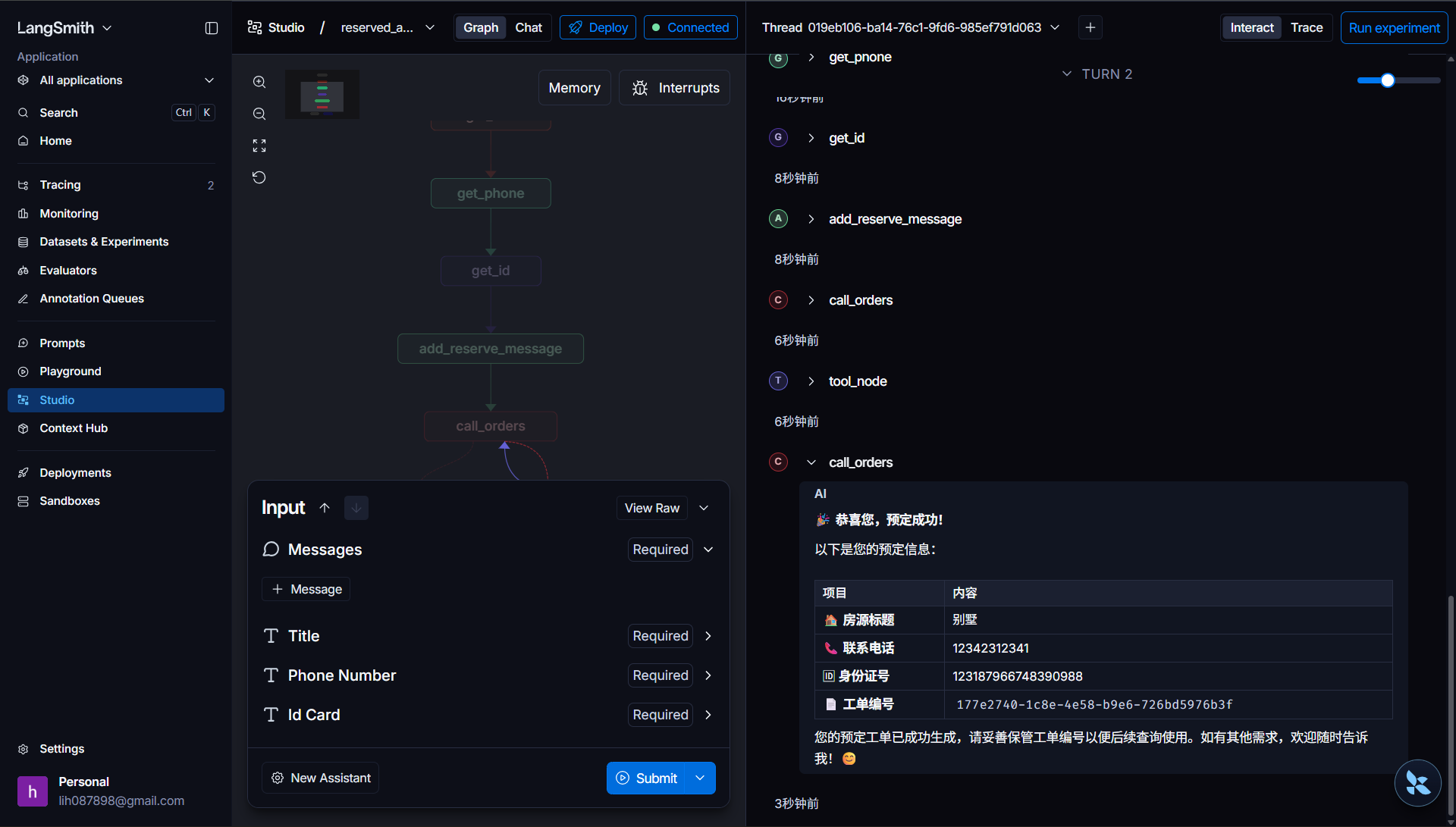
提交信息后,流程自动执行消息拼接节点,系统把房源名称、手机号、身份证号整合为一条完整的HumanMessage,再流转到call_orders节点。此时大模型识别到需要调用工具,生成携带工具调用指令的AIMessage,随后进入tool_node执行生成工单的工具逻辑。
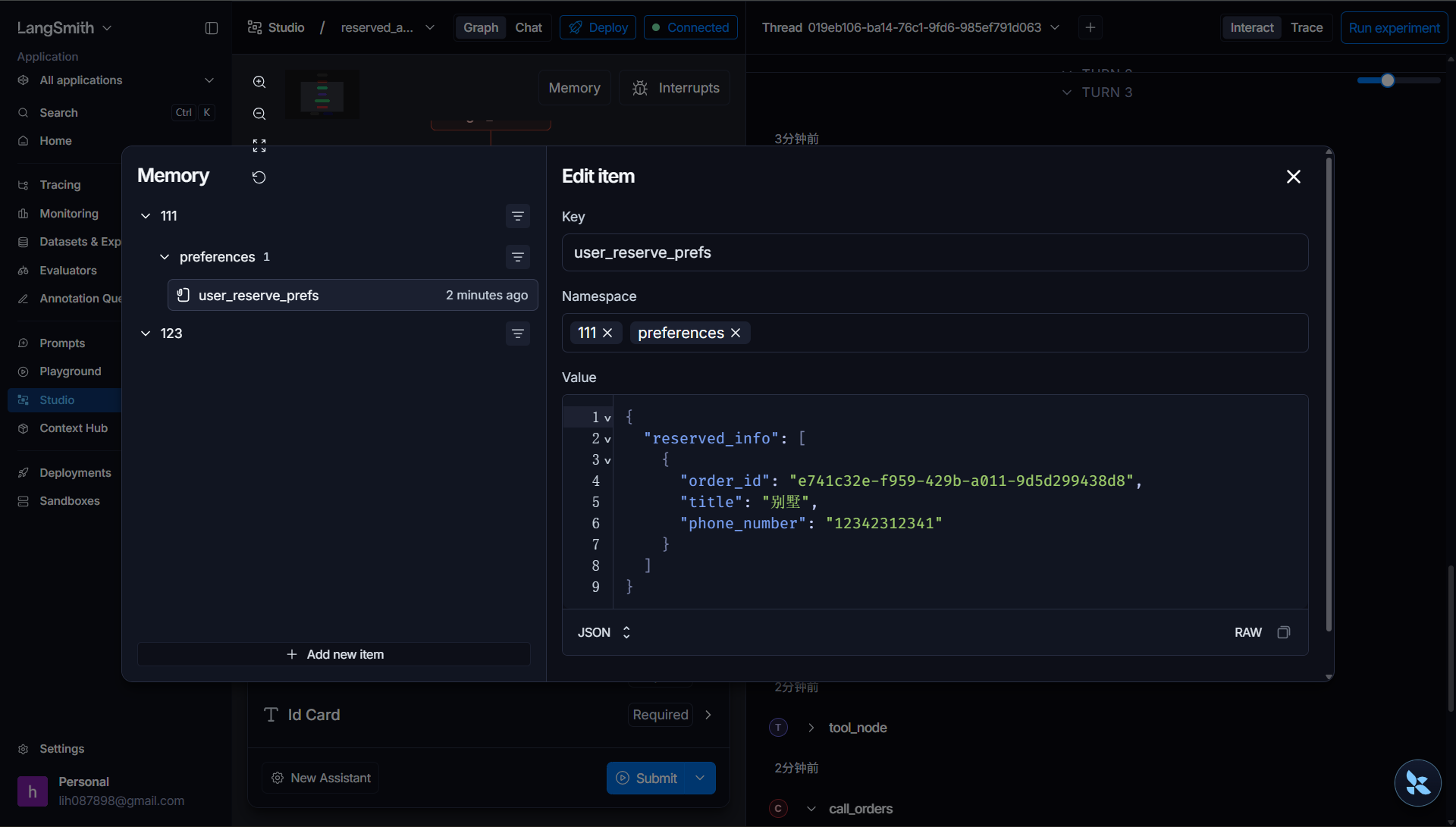
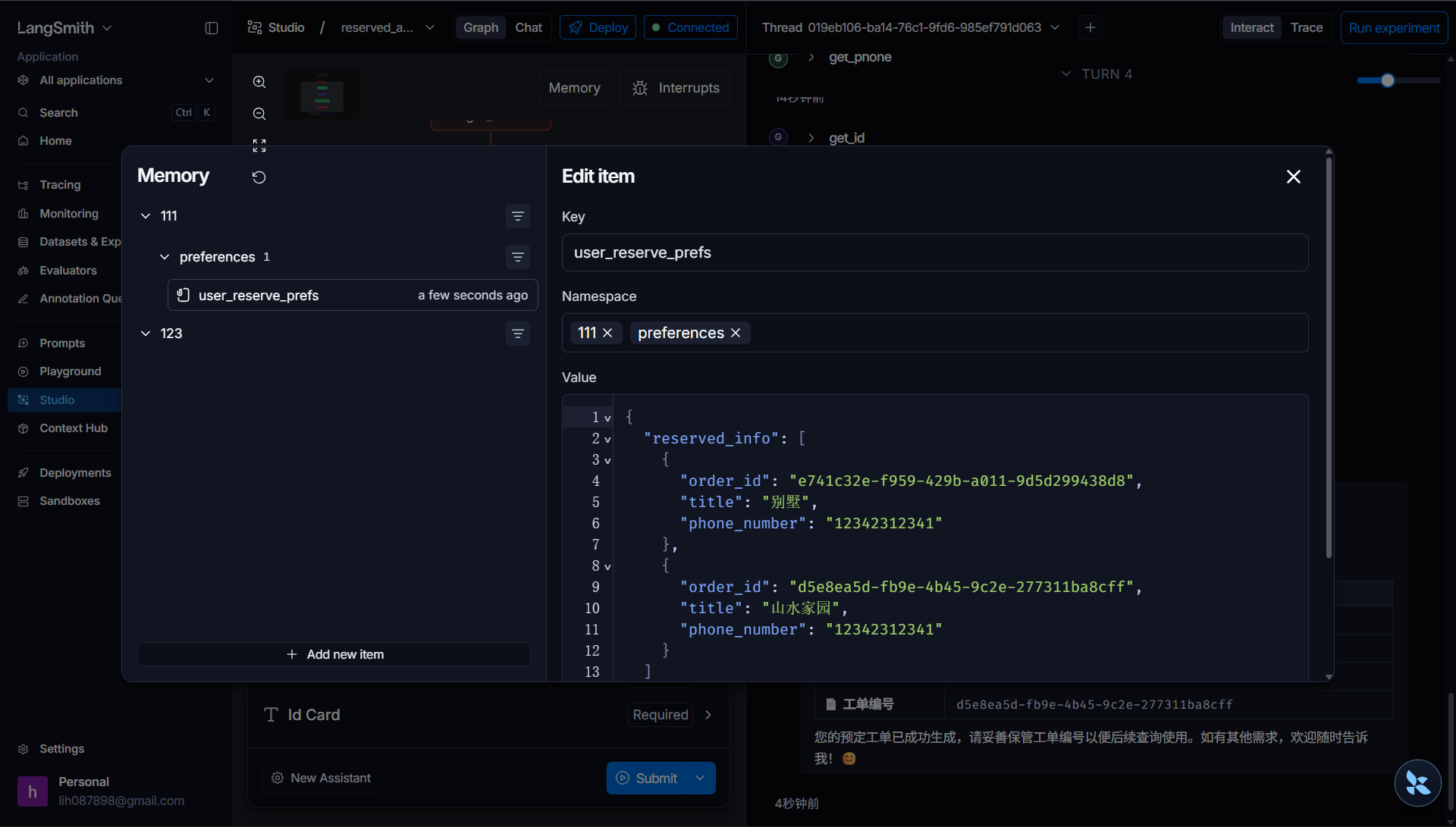
为了验证数据持久化的追加效果,我们继续做第二轮测试。新建会话,再次发起预定请求,本次房源填写 "山水家园",同样补充手机号和身份证信息。操作完成后查看持久化存储内容,可以看到用户名下已经存在两条预定记录,分别对应 "别墅" 和 "山水家园",新的预定信息成功追加到历史列表中。这也意味着后续开发查询历史订单的功能时,就可以从这份持久化数据中读取用户所有预定记录。
借助 LangSmith 平台,我们完整验证了中断交互、节点流转、工具调用、数据持久化等全部核心能力。到这里,房源预定子图的代码编写、结构搭建、项目部署以及功能测试就全部完成了。
扩展子图 -- 除业务外的智能问答助手
接下来我们一起实现扩展子图。
在项目整体架构中,除了房源推荐、预定这类业务相关的功能外,智能助手还需要支持通用问答,比如讲笑话、解答基础题目等非业务问题。这类通用问答逻辑,我们统一封装成一个独立的扩展子图来实现。
扩展子图的逻辑非常简单:输入是用户的问题消息,输出是大模型生成的回答消息,整个子图只包含一个节点,核心逻辑就是调用大模型进行对话回复。
按照项目的代码规范,我们先把节点实现单独放到 node 目录的extend.py下,创建对应的扩展节点文件。
节点实现
首先定义扩展节点 extend_node。 因为整个子图的输入和输出都只是消息,所以我们不需要单独定义状态类,直接使用 LangGraph 提供的 MessagesState 即可,它自带消息列表,完全满足需求。
节点内部逻辑很清晰:
-
调用我们项目中已经封装好的大模型
model; -
传入系统提示词
SystemMessage,给助手设定身份:"你是一个乐于助人的助手,可以根据历史对话进行回复"; -
拼接状态中的历史消息
state["messages"],一起传入模型; -
将模型返回的结果,以列表形式更新到状态的
messages字段中。
这样,扩展节点就实现完成了。
node/extend.py:
python
from langchain_core.messages import AIMessage, SystemMessage
from langgraph.graph import StateGraph, MessagesState
from src.agent.common.llm import model
def extend_node(state: MessagesState):
response = model.invoke(
[SystemMessage(content="你是一个乐于助人的助手,可以根据历史对话进行回复。")]
+ state["messages"]
)
return {
"messages": [response]
}图结构定义
接下来我们在 agent 目录下创建扩展子图的构建文件,定义完整的图结构。
- 初始化
StateGraph,状态类型使用MessagesState; - 调用
add_node,把刚才实现的extend_node添加到图中; - 调用
add_edge,设置从START入口直接指向extend_node; - 调用
compile()方法编译图,得到可运行的extend_graph实例。
这里补充说明一下,扩展子图中我们没有额外配置上下文参数,因为它不需要用户 ID、持久化存储这类业务相关信息,仅靠消息列表就能完成通用对话。
agent/extend.py:
python
from langgraph.graph import StateGraph, MessagesState
from langgraph.constants import START
from src.agent.node.extend import extend_node
extend_graph = (
StateGraph(MessagesState)
.add_node(extend_node)
.add_edge(START, "extend_node")
.compile()
)配置与测试
图定义完成后,我们需要把它注册到项目中:
- 在项目初始化文件中引入并注册扩展子图;
python
"""New LangGraph Agent.
This module defines a custom graph.
"""
from src.agent.graph import graph
from src.agent.recommend import recommended_graph
from src.agent.reserve import reserve_graph
from src.agent.extend import extend_graph
__all__ = ["graph", "recommended_graph", "reserve_graph", "extend_graph"]- 在项目的 JSON 配置文件中,添加扩展子图的配置项,填写文件路径和图实例名称,保证项目能正常加载。
python
{
"$schema": "https://langgra.ph/schema.json",
"dependencies": ["."],
"graphs": {
"agent": "./src/agent/graph.py:graph",
"recommended_agent": "./src/agent/recommend.py:recommended_graph",
"reserve_agent": "./src/agent/reserve.py:reserve_graph",
"extend_agent": "./src/agent/extend.py:extend_graph"
},
"env": ".env",
"image_distro": "wolfi"
}配置完成后启动项目,在 LangSmith 平台找到扩展子图进行测试:输入 "给我讲一个关于程序员的笑话",发送后可以看到,请求从入口流转到 extend_node 节点,大模型正常生成并返回了笑话内容,整个流程执行顺畅。
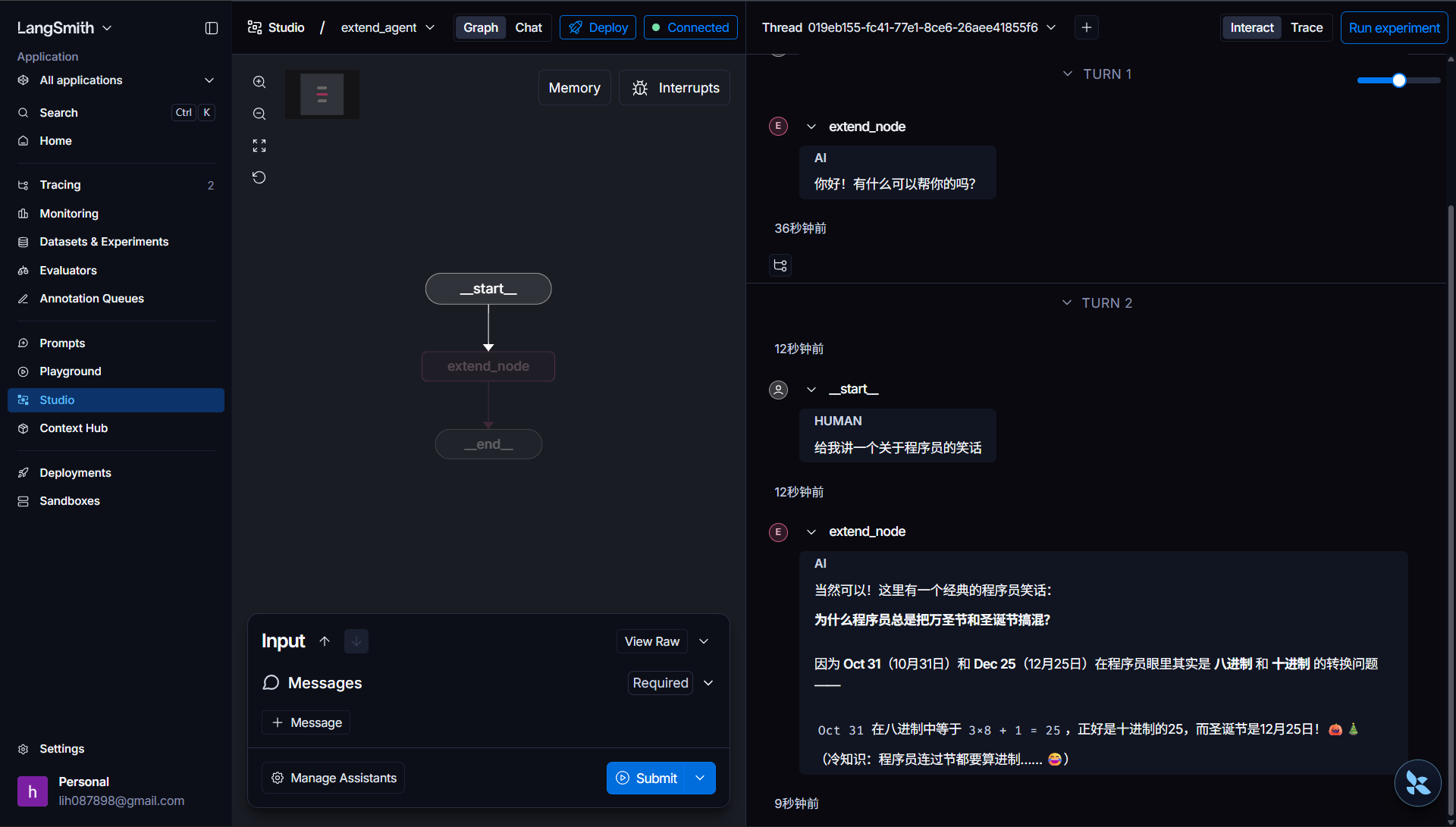
扩展子图实现完成后,我们的三个核心子图(推荐子图、预定子图、扩展子图)就全部开发完毕了。接下来的重头戏,就是实现项目的主图,把这三个子图串联起来,完成整体的智能路由逻辑。同时,还有一个遗留功能 ------"查询我的历史预定信息",也会在主图中一并实现。