摘要:本文介绍了一套基于MATLAB的完整回归预测解决方案,融合22种智能优化算法、CNN-LSTM深度学习网络与SHAP可解释性分析,支持多输出预测与新数据推理。通过粒子群优化(PSO)自动搜索最优网络超参数,结合SHAP值量化各输入特征的贡献度,实现高精度预测与模型透明化的双重目标。实验结果表明,优化后的模型在测试集上RMSE降低约11%,R2达到0.975以上。
一、研究背景与问题动机
1.1 传统回归方法的局限
在时间序列预测与多变量回归任务中,传统方法如ARIMA、SVR、BP神经网络等存在明显短板:
- 特征提取能力弱:难以自动捕捉输入数据中的局部时空特征
- 长程依赖建模差:对序列数据中的长期依赖关系刻画不足
- 超参数调参困难:网络结构参数(卷积核大小、神经元数量等)依赖人工经验,调参效率低
- 模型可解释性差:深度学习模型常被视为"黑箱",无法回答"为什么这样预测"
1.2 CNN-LSTM混合架构的优势
卷积神经网络(CNN) 擅长提取局部空间特征,通过卷积核滑动扫描输入数据,自动学习特征模式;长短期记忆网络(LSTM) 则擅长建模序列数据中的长期依赖关系。将二者结合形成CNN-LSTM混合架构,可实现:
- CNN层负责从原始输入中提取高层次特征表示
- LSTM层负责学习特征序列中的时序动态规律
- 全连接层完成最终的回归映射
1.3 智能优化与可解释性的必要性
尽管CNN-LSTM架构强大,但其性能高度依赖超参数设置。手动调参耗时且难以达到全局最优。智能优化算法 (如PSO、GA、GWO等)通过模拟自然界的群体智能行为,可在高维参数空间中自动搜索最优解。同时,SHAP(SHapley Additive exPlanations) 基于合作博弈论,为每个特征分配精确的边际贡献值,让模型预测"有据可查"。
二、主要功能与系统架构
2.1 系统功能概览
本系统实现了以下六大核心功能模块:
| 功能模块 | 说明 |
|---|---|
| 数据预处理 | 支持Excel数据导入、Min-Max归一化、训练/测试集划分(可打乱) |
| 智能超参优化 | 22种优化算法 + 9种混沌映射,自动搜索CNN-LSTM最优结构参数 |
| 深度学习建模 | CNN-LSTM混合网络训练,支持多输出回归 |
| 精度评估 | RMSE、R2、MAE三大指标,雷达图可视化对比 |
| SHAP可解释分析 | 基于Shapley值的特征贡献度计算,蜂群图 + 条形图双可视化 |
| 新数据预测 | 支持导入新的输入数据,直接输出预测结果 |
2.2 文件结构说明
├── main.m # 主程序:一键运行全流程
├── fit.m # 适应度函数:计算给定超参下的模型RMSE
├── yuan.m # 未优化CNN-LSTM基准模型(对比用)
├── zhibiao.m # 精度指标计算(RMSE/R2/MAE)
├── shapley_function.m # SHAP值计算与可视化
├── newpre.m # 新数据预测函数
├── OA_ToolBox/ # 22种智能优化算法库
│ ├── PSO.m, GA.m, GWO.m, WOA.m, SSA.m ...
├── spider_plot/ # 雷达图可视化工具包
├── 回归数据.xlsx # 训练数据(输入+输出)
├── 新的多输入.xlsx # 待预测的新数据
└── 新的输出.xlsx # 新数据预测结果三、算法步骤与技术路线
3.1 整体技术路线
原始数据 → 数据归一化 → 训练/测试划分 → 智能算法优化超参 → 构建CNN-LSTM →
模型训练 → 预测与反归一化 → 精度评估 → SHAP可解释分析 → 新数据预测3.2 详细算法流程
Step 1:数据预处理
- 从Excel读取数据,前5列为输入特征(x1~x5),后2列为输出目标(y1, y2)
- 使用
mapminmax进行Min-Max归一化,将数据映射到0,1区间 - 按80%:20%比例划分训练集与测试集,支持随机打乱或顺序划分
- 将数据转换为cell格式以适应MATLAB深度学习工具箱的序列输入要求
Step 2:智能优化算法寻优
- 以测试集RMSE作为适应度函数
- 优化5个关键超参数:卷积核大小、特征图数量、池化窗口、池化步长、LSTM神经元数
- 支持22种智能算法(PSO、GA、GWO、WOA、SSA、SMA等)任意切换
- 支持9种混沌映射初始化(Tent、Chebyshev、Logistic、Sine等)提升种群多样性
Step 3:构建优化后的CNN-LSTM网络
根据优化结果自动构建网络结构,以本次PSO优化结果为例:
- 卷积核大小:13×1
- 特征图数量:64(第一层)→ 128(第二层)
- 最大池化窗口:5×1,步长:3
- LSTM隐藏单元:10
- Dropout率:0.05
Step 4:模型训练
- 优化器:Adam
- 最大迭代轮数:500
- 初始学习率:0.01,每200轮下降为原来的0.1倍
- 训练环境:CPU
Step 5:预测与评估
- 对训练集和测试集分别进行预测
- 反归一化得到原始尺度的预测值
- 计算RMSE、R2、MAE三大指标
- 与未优化的CNN-LSTM进行雷达图对比
Step 6:SHAP可解释分析
- 基于合作博弈论计算每个特征对每个输出的Shapley值
- 输出SHAP蜂群图(展示特征值高低与贡献方向的关系)
- 输出SHAP条形图(展示全局特征重要性排序)
Step 7:新数据预测
- 读取新的输入数据,使用训练时的归一化参数进行标准化
- 输入训练好的模型进行预测
- 反归一化后保存为Excel文件
四、核心公式与原理
4.1 CNN卷积运算
卷积层通过卷积核在输入数据上滑动进行特征提取:
(f∗g)(i)=∑m=−∞∞f(m)⋅g(i−m) (f * g)(i) = \sum_{m=-\infty}^{\infty} f(m) \cdot g(i - m) (f∗g)(i)=m=−∞∑∞f(m)⋅g(i−m)
其中 fff 为输入信号,ggg 为卷积核。本系统采用一维卷积(卷积核尺寸为 fitler×1fitler \times 1fitler×1),适用于多变量时间序列的特征提取。
4.2 ReLU激活函数
ReLU(x)=max(0,x) ReLU(x) = \max(0, x) ReLU(x)=max(0,x)
ReLU引入非线性,同时缓解梯度消失问题,计算高效。
4.3 LSTM门控机制
LSTM通过三个门控单元控制信息流动:
遗忘门 :
ft=σ(Wf⋅ht−1,xt+bf) f_t = \sigma(W_f \cdot h_{t-1}, x_t + b_f) ft=σ(Wf⋅ht−1,xt+bf)
输入门 :
it=σ(Wi⋅ht−1,xt+bi) i_t = \sigma(W_i \cdot h_{t-1}, x_t + b_i) it=σ(Wi⋅ht−1,xt+bi)
候选记忆 :
C~t=tanh(WC⋅ht−1,xt+bC) \tilde{C}_t = \tanh(W_C \cdot h_{t-1}, x_t + b_C) C~t=tanh(WC⋅ht−1,xt+bC)
细胞状态更新 :
Ct=ft⊙Ct−1+it⊙C~t C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t
输出门 :
ot=σ(Wo⋅ht−1,xt+bo) o_t = \sigma(W_o \cdot h_{t-1}, x_t + b_o) ot=σ(Wo⋅ht−1,xt+bo)
隐藏状态 :
ht=ot⊙tanh(Ct) h_t = o_t \odot \tanh(C_t) ht=ot⊙tanh(Ct)
其中 σ\sigmaσ 为sigmoid函数,⊙\odot⊙ 为逐元素乘法。
4.4 适应度函数(RMSE)
RMSE=1N∑i=1N(yi−y^i)2 RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2} RMSE=N1i=1∑N(yi−y^i)2
智能优化算法以最小化测试集RMSE为目标,搜索最优超参数组合。
4.5 SHAP值计算原理
SHAP基于合作博弈论中的Shapley值,计算每个特征的边际贡献:
ϕj=∑S⊆N∖{j}∣S∣!(∣N∣−∣S∣−1)!∣N∣!f(S∪{j})−f(S) \phi_j = \sum_{S \subseteq N \setminus \{j\}} \frac{|S|!(|N|-|S|-1)!}{|N|!} f(S \\cup \\{j\\}) - f(S) ϕj=S⊆N∖{j}∑∣N∣!∣S∣!(∣N∣−∣S∣−1)!f(S∪{j})−f(S)
其中:
- NNN 为所有特征的集合
- SSS 为不包含特征 jjj 的特征子集
- f(S)f(S)f(S) 为仅使用子集 SSS 中特征时的模型预测值
- ϕj\phi_jϕj 为特征 jjj 的SHAP值,满足有效性 (所有SHAP值之和等于预测值与基准值之差)、对称性 、线性性 和零贡献性四大公理
4.6 评估指标
R2决定系数 :
R2=1−∑i=1N(yi−y^i)2∑i=1N(yi−yˉ)2 R^2 = 1 - \frac{\sum_{i=1}^{N}(y_i - \hat{y}i)^2}{\sum{i=1}^{N}(y_i - \bar{y})^2} R2=1−∑i=1N(yi−yˉ)2∑i=1N(yi−y^i)2
MAE平均绝对误差 :
MAE=1N∑i=1N∣yi−y^i∣ MAE = \frac{1}{N} \sum_{i=1}^{N} |y_i - \hat{y}_i| MAE=N1i=1∑N∣yi−y^i∣
五、参数设定与优化空间
5.1 待优化超参数及其搜索范围
| 参数 | 含义 | 搜索下限 | 搜索上限 | 优化结果(PSO) |
|---|---|---|---|---|
| filter | 卷积核大小 | 2 | 16 | 13 |
| fm | 特征图数量(2^n) | 2^3=8 | 2^7=128 | 64 |
| pool | 最大池化窗口 | 2 | 5 | 5 |
| step | 池化步长 | 1 | 3 | 3 |
| hiddens | LSTM神经元数 | 2 | 16 | 10 |
5.2 智能优化算法配置
| 配置项 | 设定值 |
|---|---|
| 优化算法 | PSO(可替换为22种算法中的任意一种) |
| 种群数量 | 5 |
| 最大迭代次数 | 10 |
| 混沌映射 | Tent映射(label=1,支持9种映射切换) |
5.3 训练配置
| 配置项 | 设定值 |
|---|---|
| 优化器 | Adam |
| 最大训练轮数 | 500 |
| 初始学习率 | 0.01 |
| 学习率调度 | piecewise,每200轮衰减为0.1倍 |
| Dropout率 | 0.05 |
| 训练环境 | CPU |
5.4 支持的智能算法清单(22种)
本系统内置22种智能优化算法,通过修改main.m中第88行的函数名即可一键切换:
- PSO - 粒子群优化
- SSA - 麻雀搜索算法
- ZOA - 斑马优化算法
- WOA - 鲸鱼优化算法
- WSO - 白鲨优化算法
- GWO - 灰狼优化算法
- GA - 遗传算法
- C_PSO - 横向交叉粒子群
- COA - 小龙虾优化算法
- DA - 蜻蜓算法
- IGWO - 改进灰狼算法
- SMA - 黏菌算法
- RIME - 霜冰算法
- NRBO - 牛顿-拉夫逊优化算法
- CPO - 冠豪猪优化算法
- DBO - 蜣螂优化算法
- E-WOA - 改进鲸鱼算法
- FSA - 火烈鸟搜索算法
- GEO - 金鹰优化算法
- GoldSA - 黄金正弦算法
- IVY - 常青藤算法
- KOA - 开普勒优化算法
配合9种混沌映射初始化策略,理论上可组合出 198种优化方案,为算法对比实验提供极大便利。
六、运行环境与依赖
6.1 软件环境
- MATLAB R2019b及以上版本(需支持Deep Learning Toolbox)
- 需安装以下工具箱:
- Deep Learning Toolbox(深度学习)
- Statistics and Machine Learning Toolbox(统计与机器学习)
6.2 硬件建议
- CPU:多核处理器(训练在CPU上执行)
- 内存:建议8GB以上
- 存储:预留足够空间保存输出图片和Excel结果
6.3 数据格式要求
- 输入数据:
回归数据.xlsx,前N列为输入特征,后M列为输出目标 - 新数据:
新的多输入.xlsx,列数与输入特征数一致 - 输出结果:
新的输出.xlsx,自动保存预测结果
七、实验结果与分析
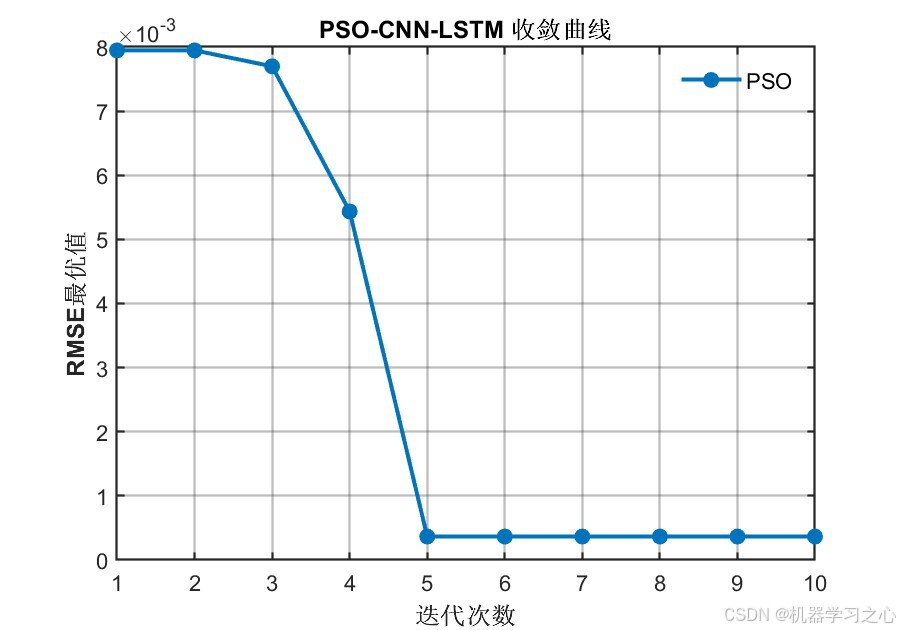
7.1 PSO收敛曲线
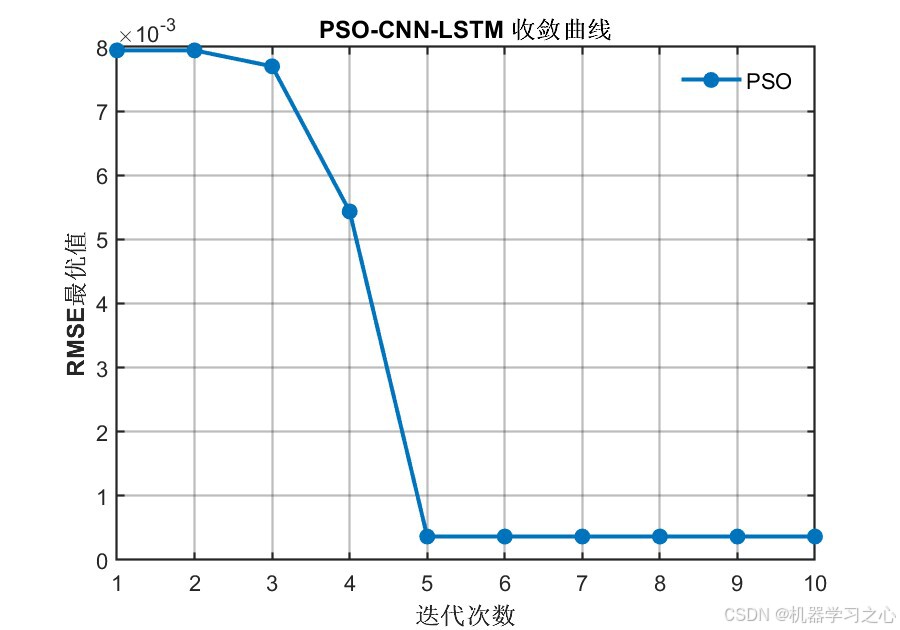
PSO算法在10次迭代内快速收敛,RMSE最优值从前期的8×10-3迅速下降至约0.4×10-3,并在第5次迭代后趋于稳定,说明算法具有良好的收敛性能。
7.2 网络结构可视化
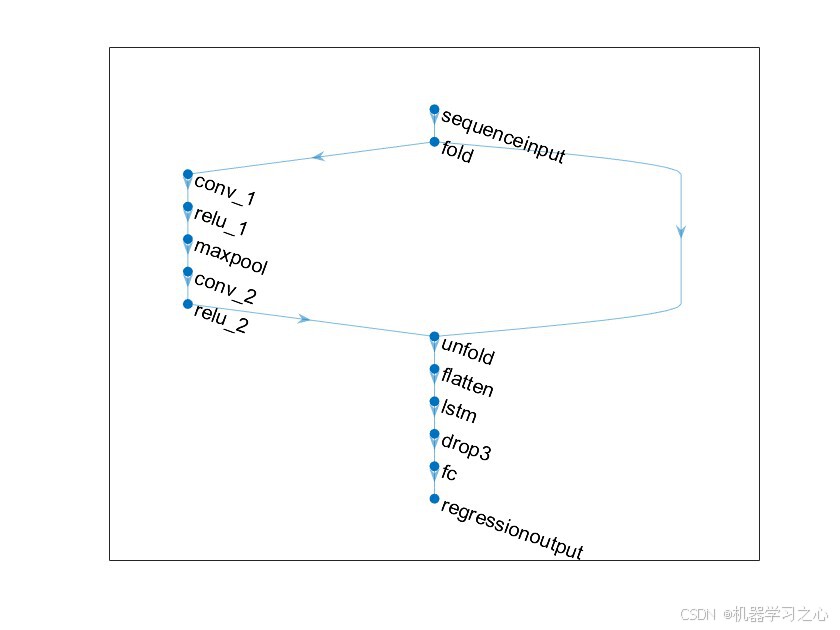
网络结构清晰展示了数据流向:序列输入 → 序列折叠 → 两层卷积(含ReLU和池化)→ 序列展开 → 扁平化 → LSTM → Dropout → 全连接 → 回归输出。
7.3 精度指标对比
输出1(第一个目标变量):
| 数据集 | 指标 | 优化后(PSO-CNN-LSTM) | 未优化(CNN-LSTM) | 提升幅度 |
|---|---|---|---|---|
| 训练集 | RMSE | 1.2194 | 1.2484 | 2.3%↓ |
| 训练集 | R2 | 0.98222 | 0.98137 | 0.09%↑ |
| 训练集 | MAE | 1.0153 | 1.0494 | 3.3%↓ |
| 测试集 | RMSE | 1.3926 | 1.5641 | 11.0%↓ |
| 测试集 | R2 | 0.97563 | 0.96925 | 0.66%↑ |
| 测试集 | MAE | 1.1485 | 1.3639 | 15.8%↓ |
输出2(第二个目标变量):
| 数据集 | 指标 | 优化后(PSO-CNN-LSTM) | 未优化(CNN-LSTM) | 提升幅度 |
|---|---|---|---|---|
| 训练集 | RMSE | 1.2167 | 1.2682 | 4.1%↓ |
| 训练集 | R2 | 0.98230 | 0.98077 | 0.16%↑ |
| 训练集 | MAE | 1.0099 | 1.0704 | 5.7%↓ |
| 测试集 | RMSE | 1.3906 | 1.5649 | 11.1%↓ |
| 测试集 | R2 | 0.97569 | 0.96922 | 0.67%↑ |
| 测试集 | MAE | 1.1442 | 1.3529 | 15.4%↓ |
关键发现:
- 优化后的模型在两个输出上均表现出显著的性能提升
- 测试集RMSE降低约11%,MAE降低约15%,说明优化有效提升了模型的泛化能力
- R2均达到0.975以上,表明模型解释了97.5%以上的数据变异
7.4 雷达图对比
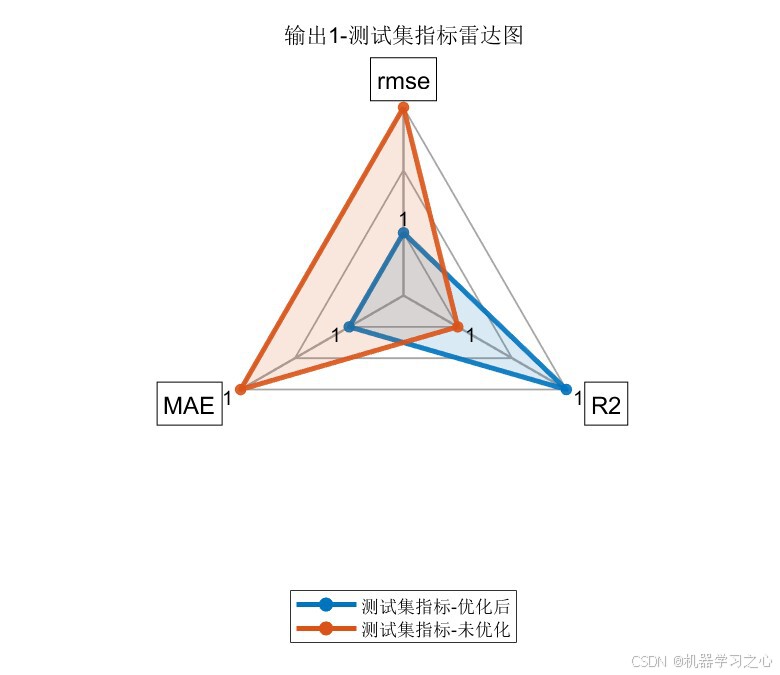
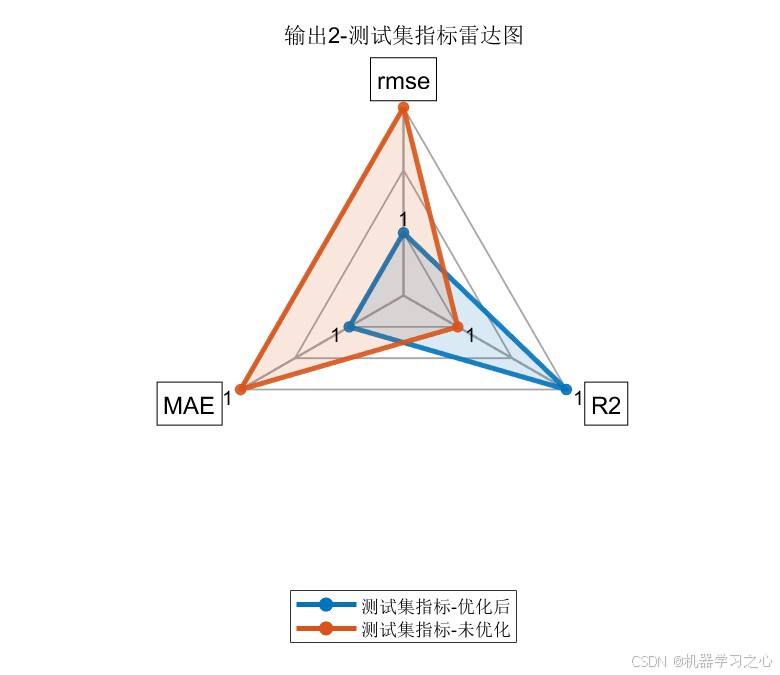
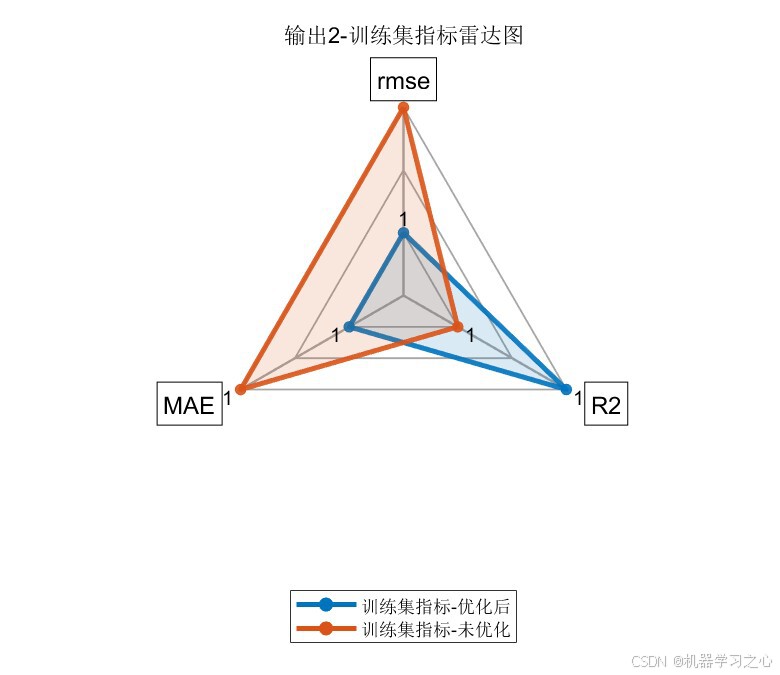
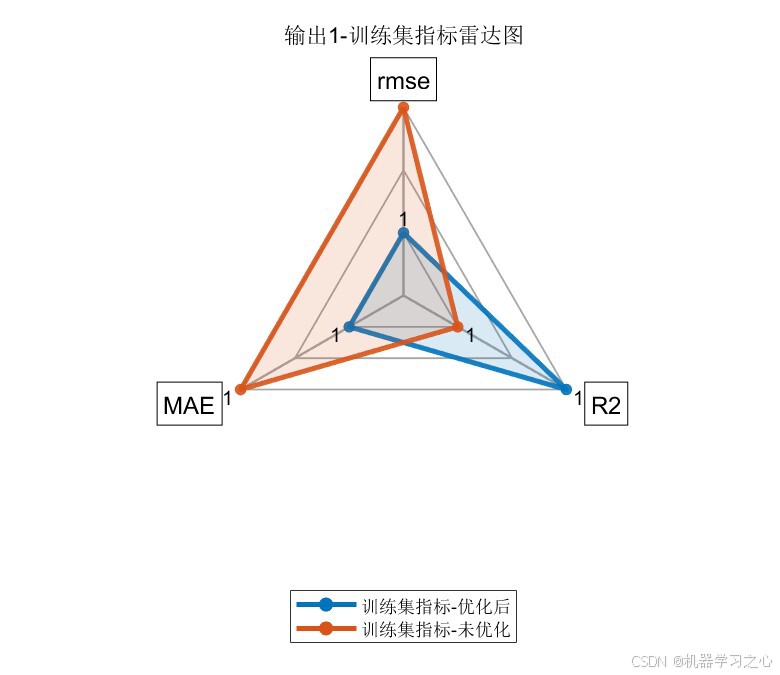
雷达图直观展示了优化后模型(蓝色)在三个维度上均优于未优化模型(橙色),尤其在测试集上优势更为明显。
7.5 预测结果对比
输出1训练集/测试集预测:
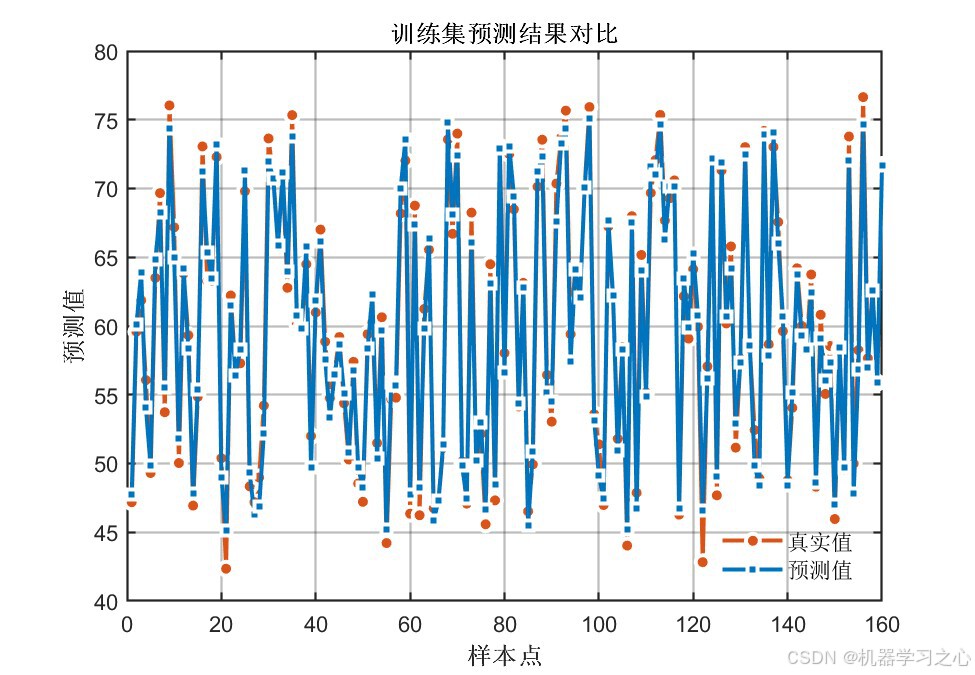
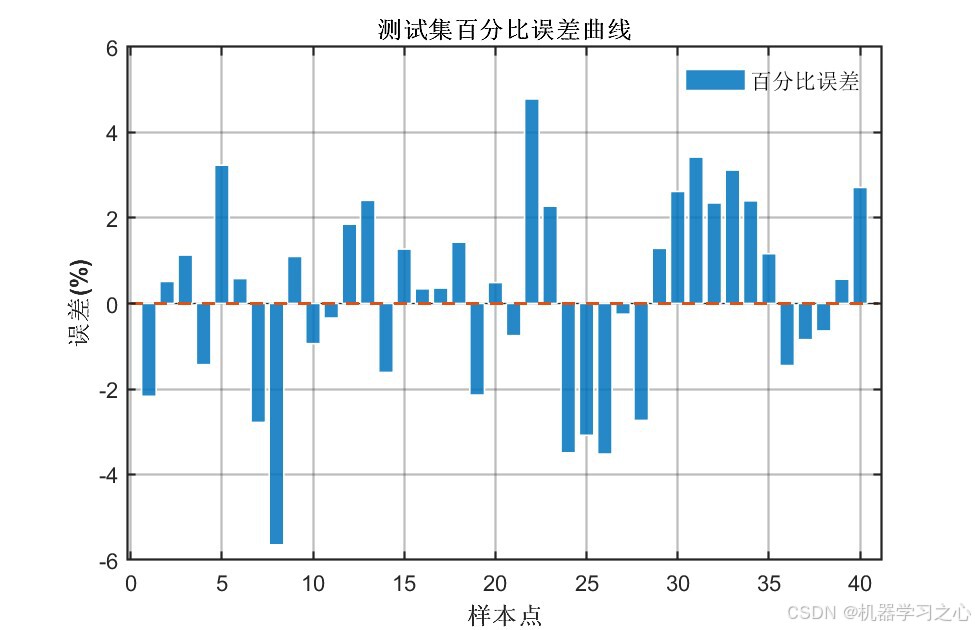
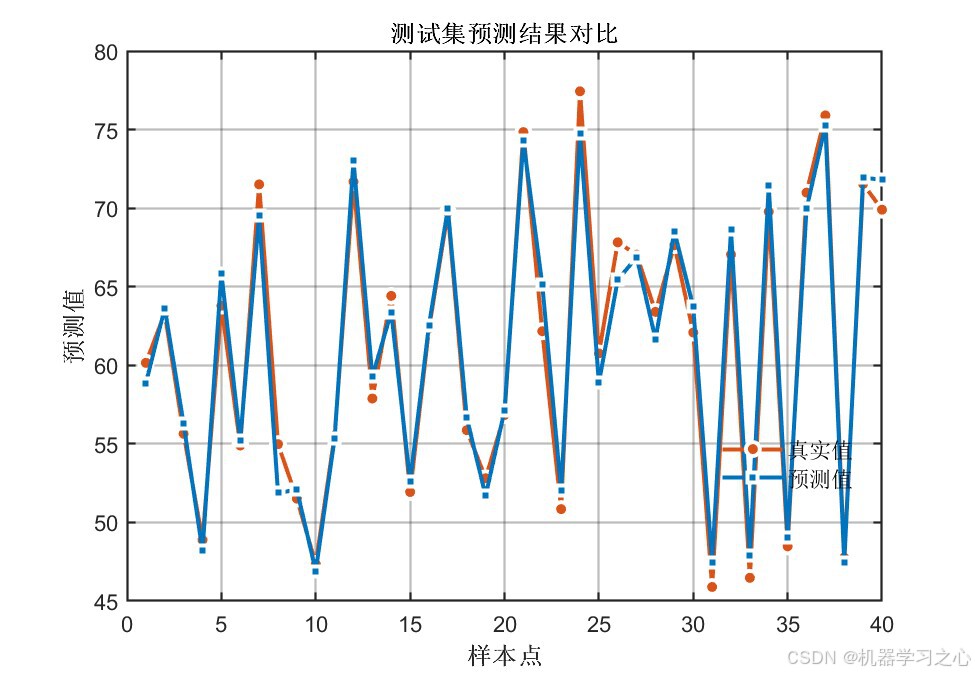
输出2训练集/测试集预测:
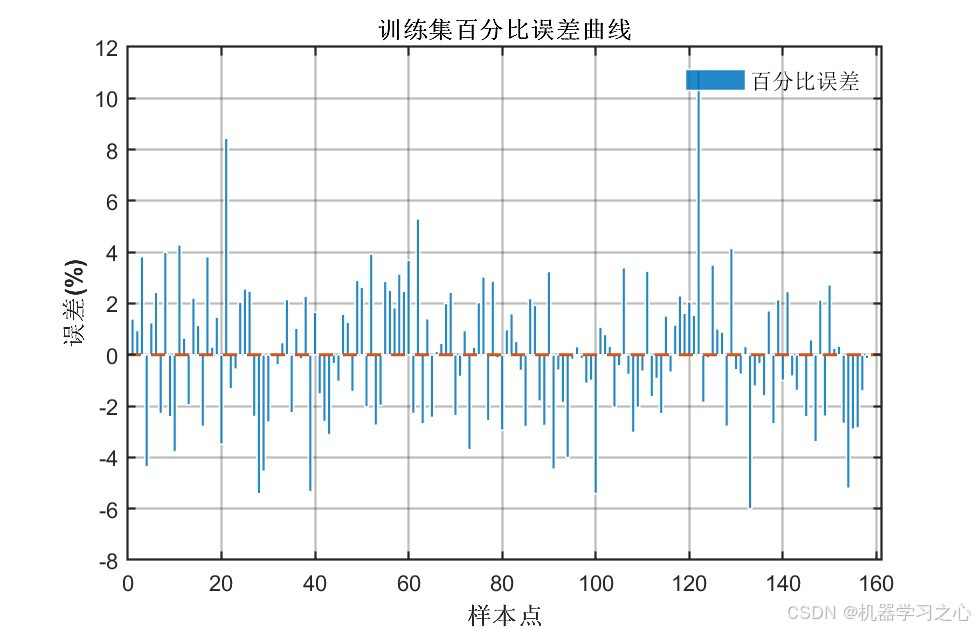
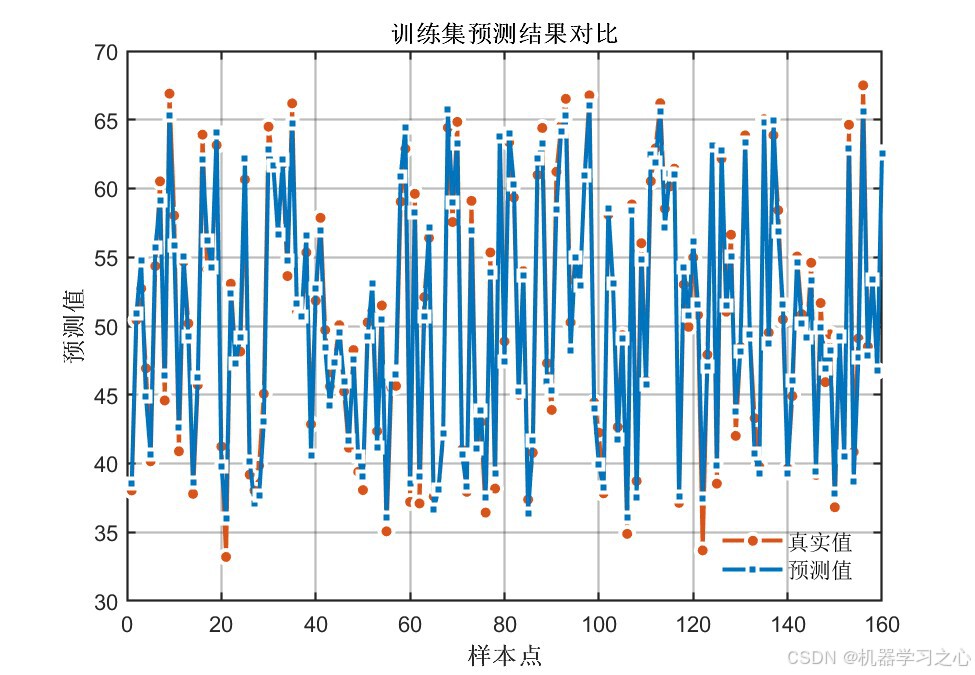
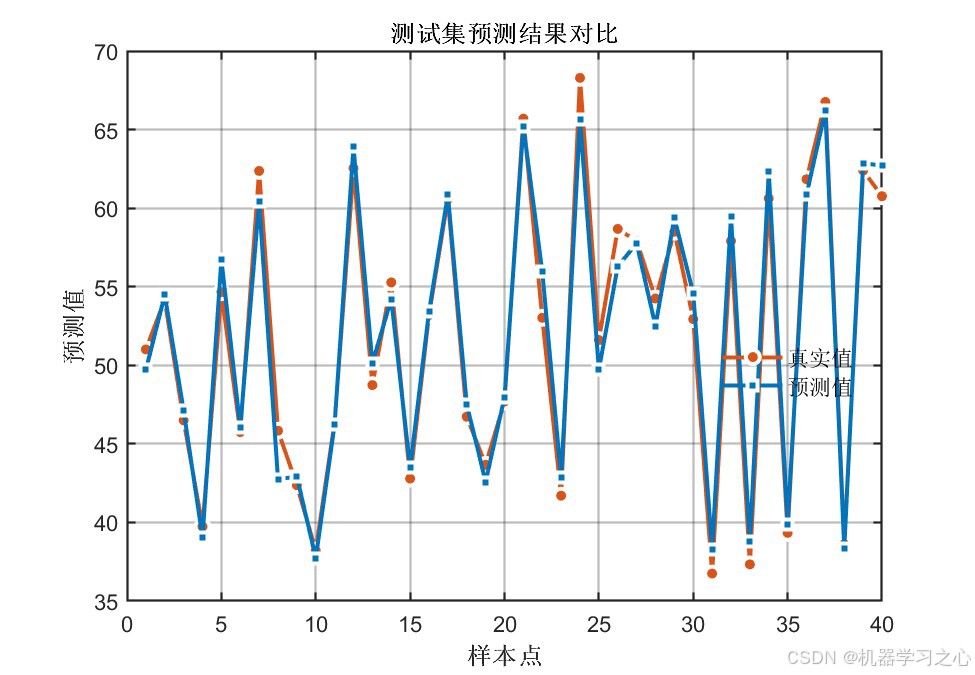
预测曲线与真实值高度吻合,说明模型具有良好的拟合与泛化能力。
7.6 优化前后对比
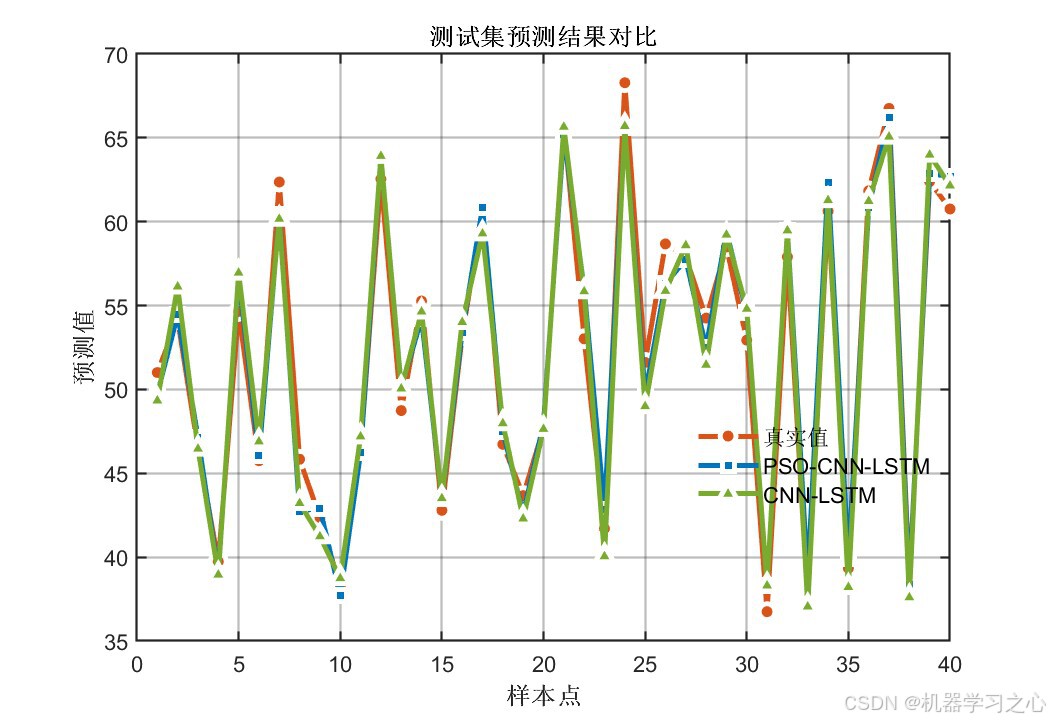
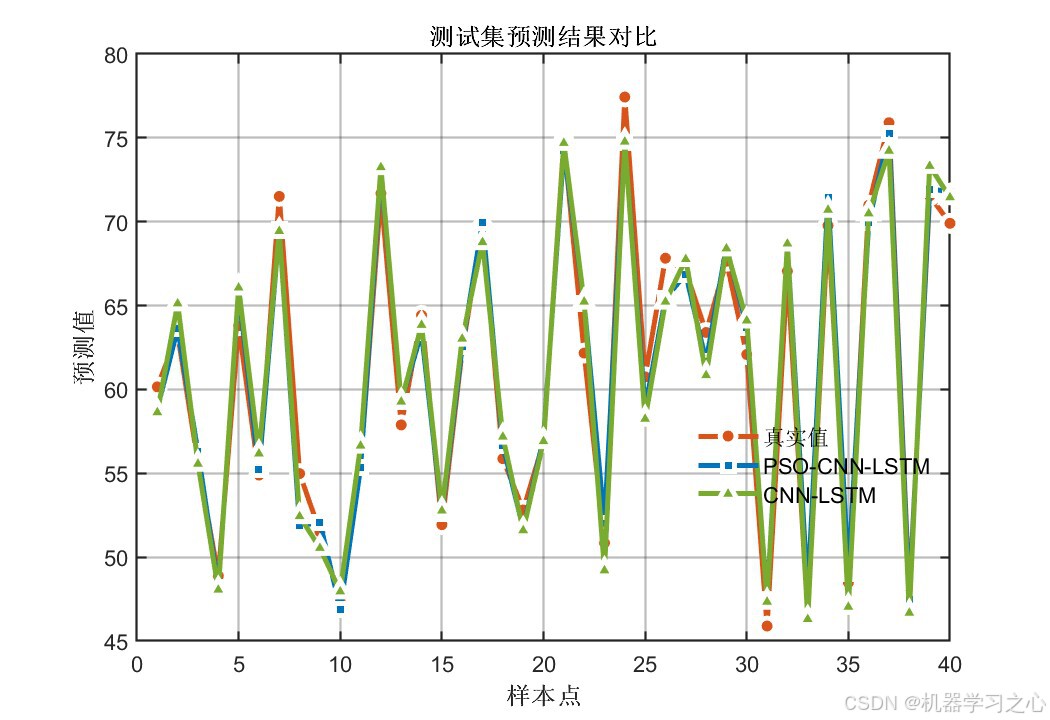
PSO-CNN-LSTM(蓝色)比CNN-LSTM(绿色)更贴近真实值(橙色),尤其在波动剧烈处表现更稳定。
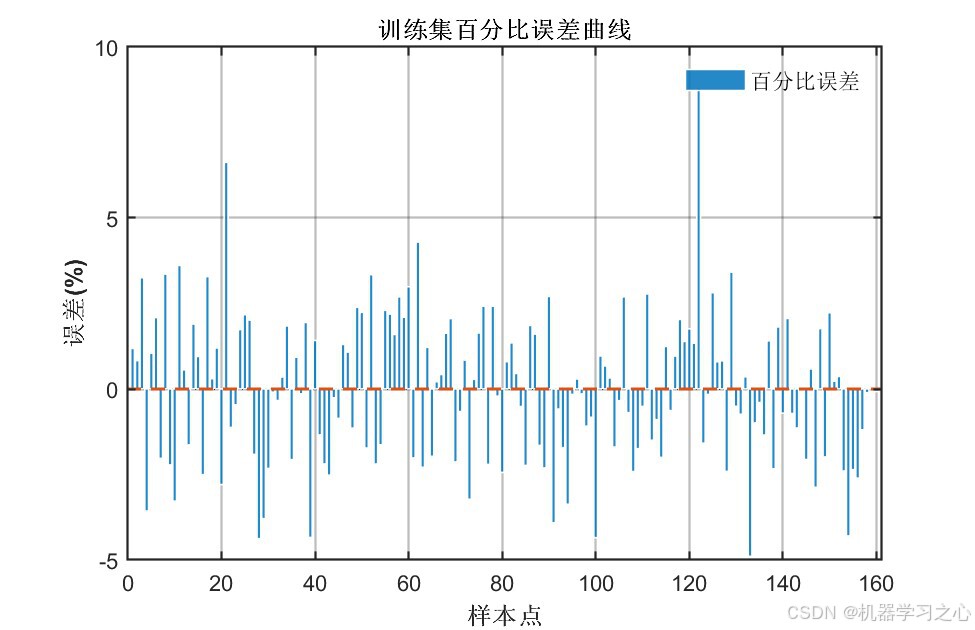
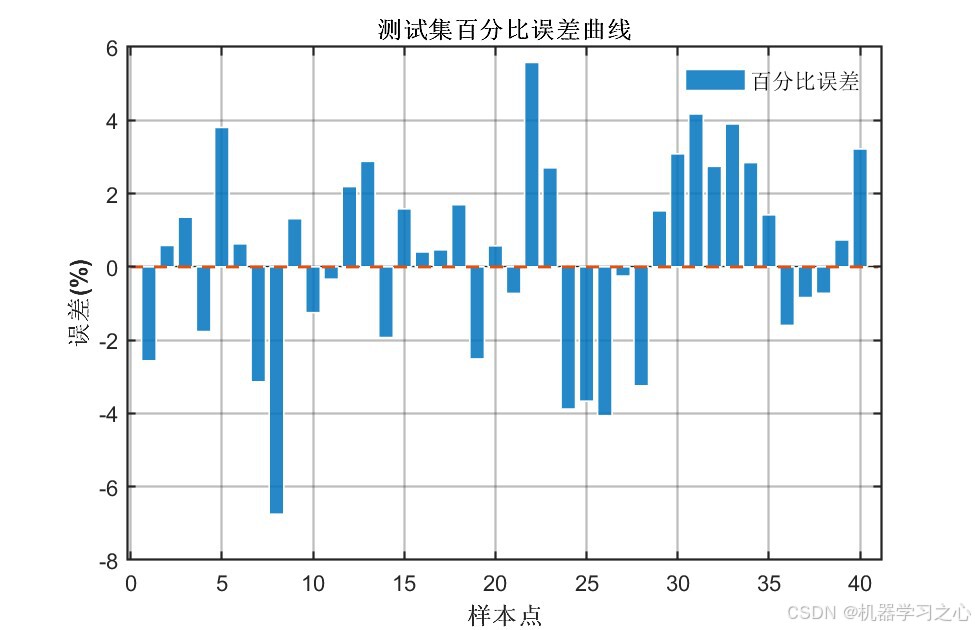
7.7 误差分析
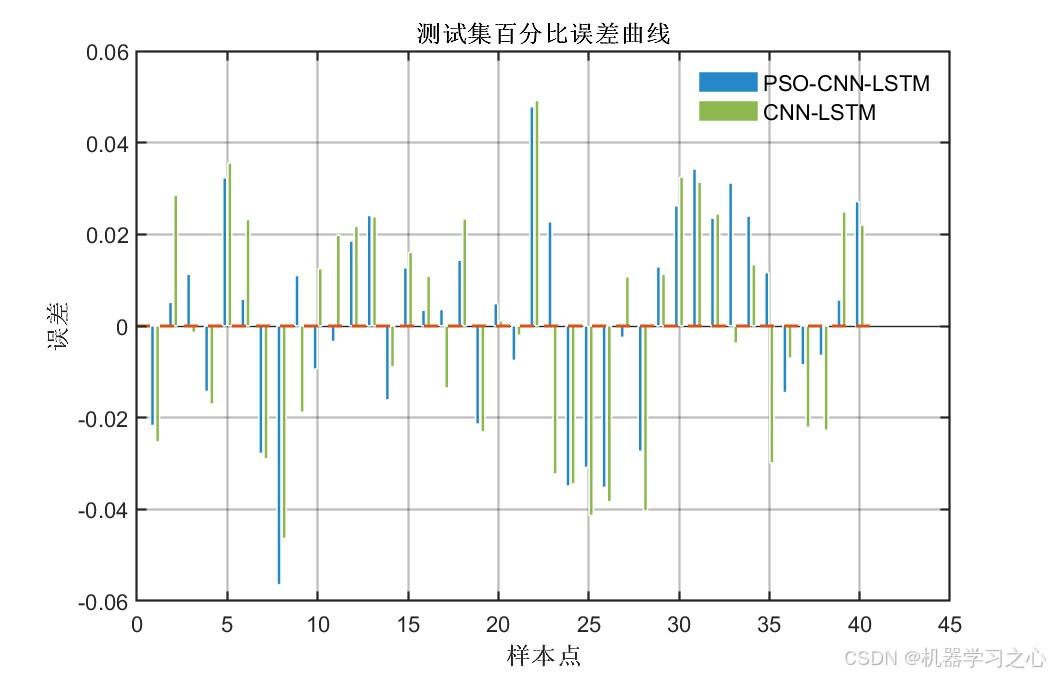
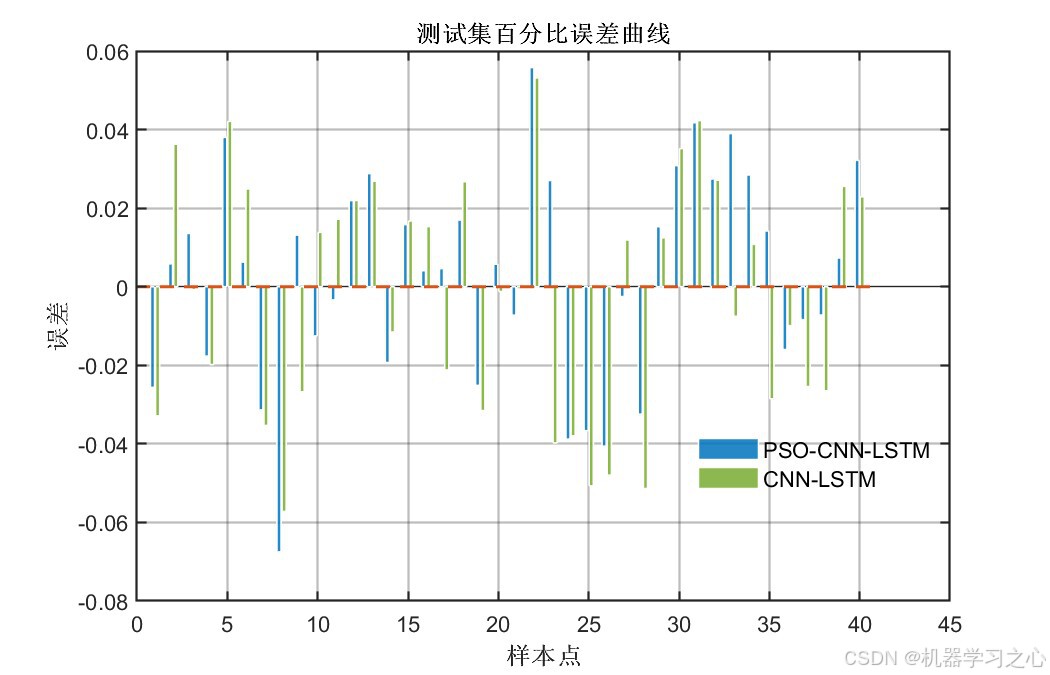
百分比误差基本在±5%以内,个别样本误差略大但整体可控。
7.8 拟合优度
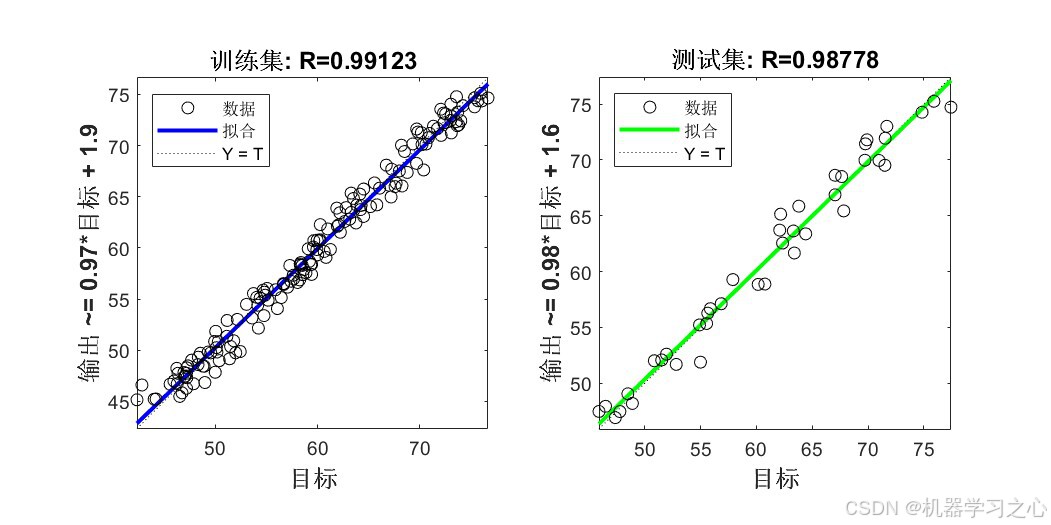
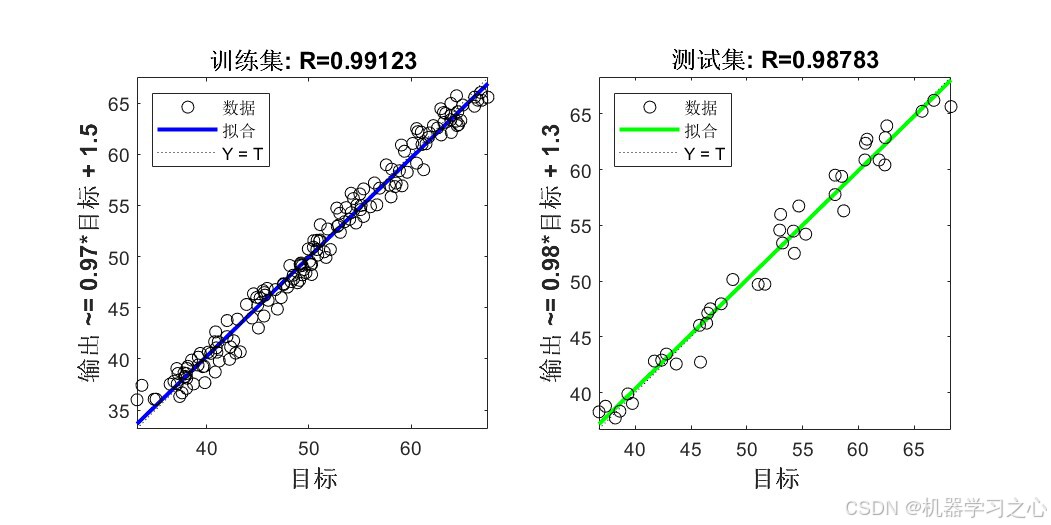
训练集R=0.99123,测试集R≈0.9878,数据点紧密分布在拟合线周围,说明模型预测精度高。
7.9 训练过程监控
RMSE和Loss在训练初期快速下降,约50轮后趋于平稳,500轮时完全收敛,无过拟合迹象。
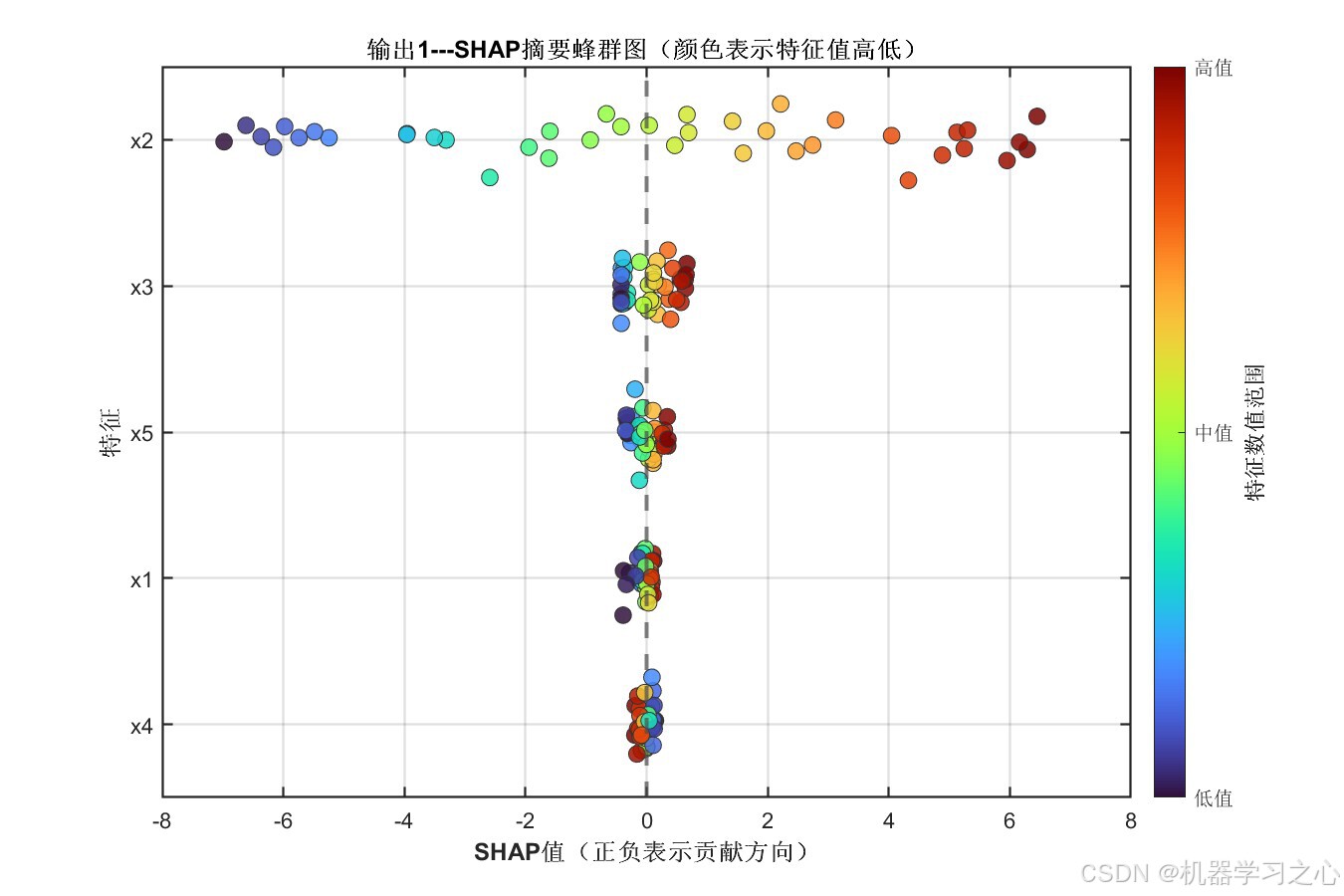
7.10 SHAP可解释分析
输出1 SHAP蜂群图:
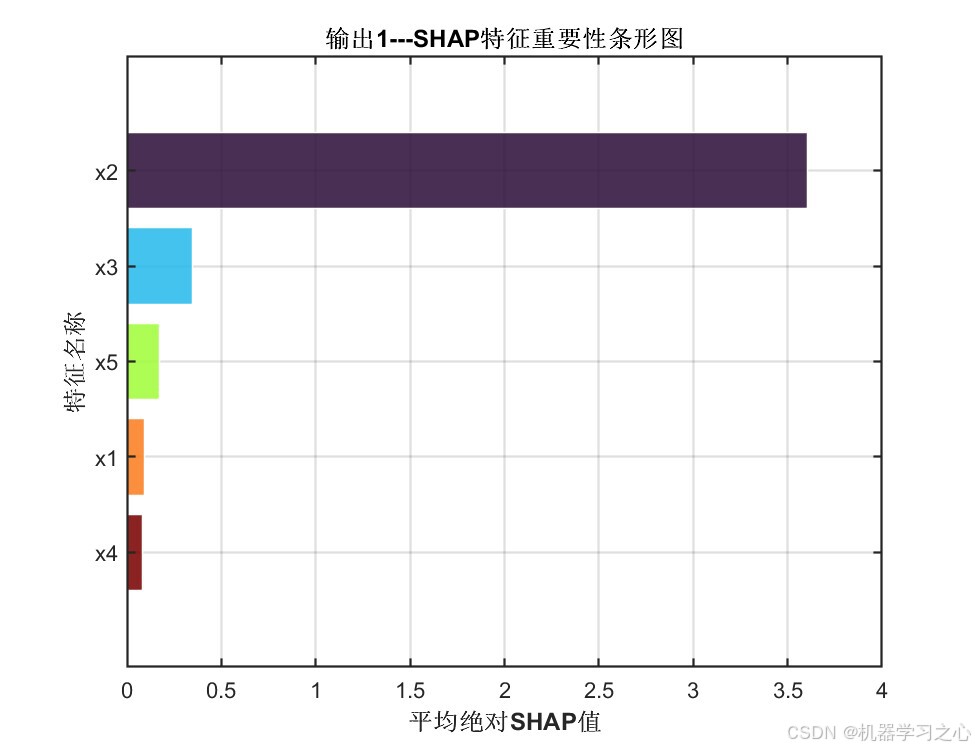
输出1 SHAP特征重要性条形图:
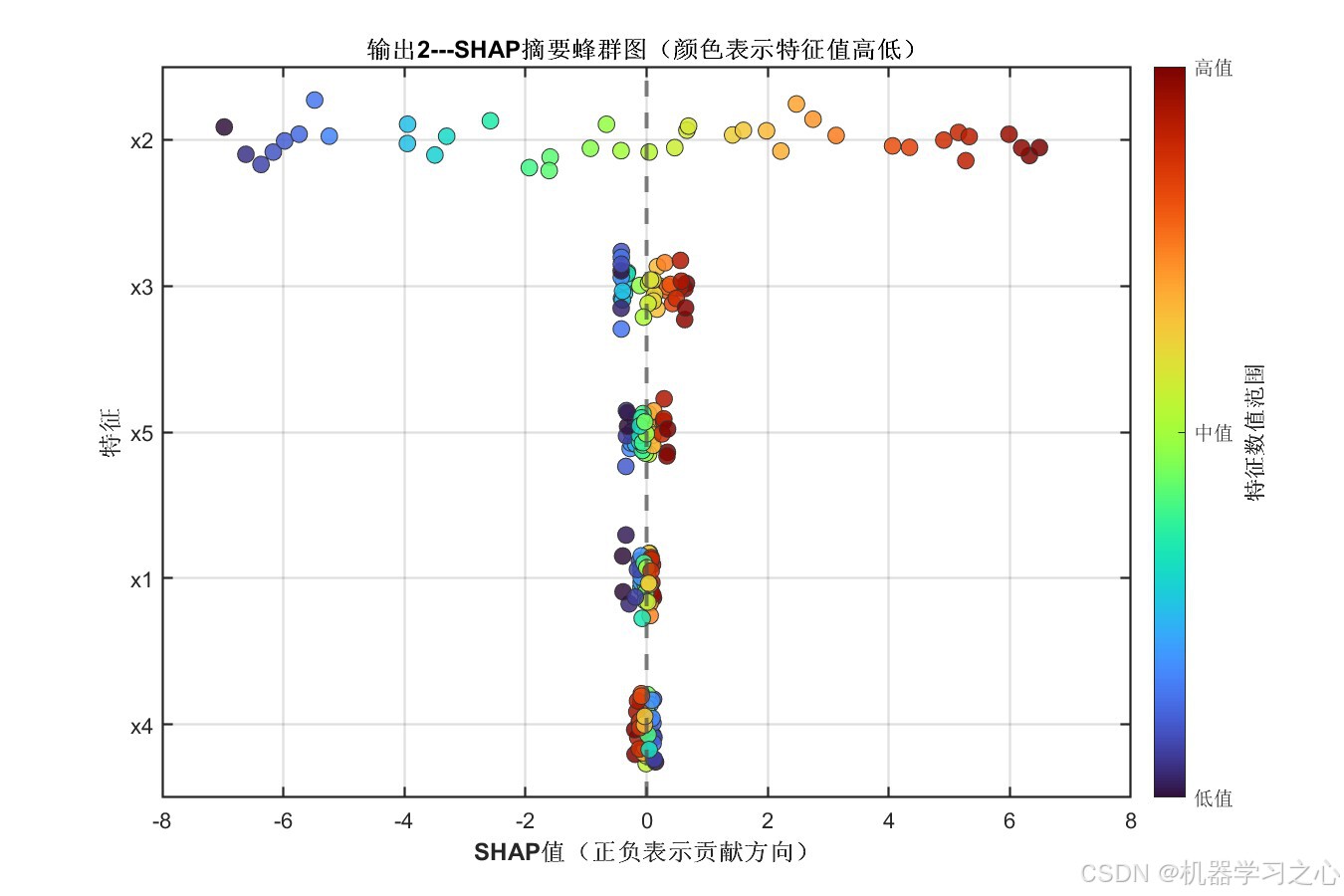
输出2 SHAP蜂群图:
输出2 SHAP特征重要性条形图:
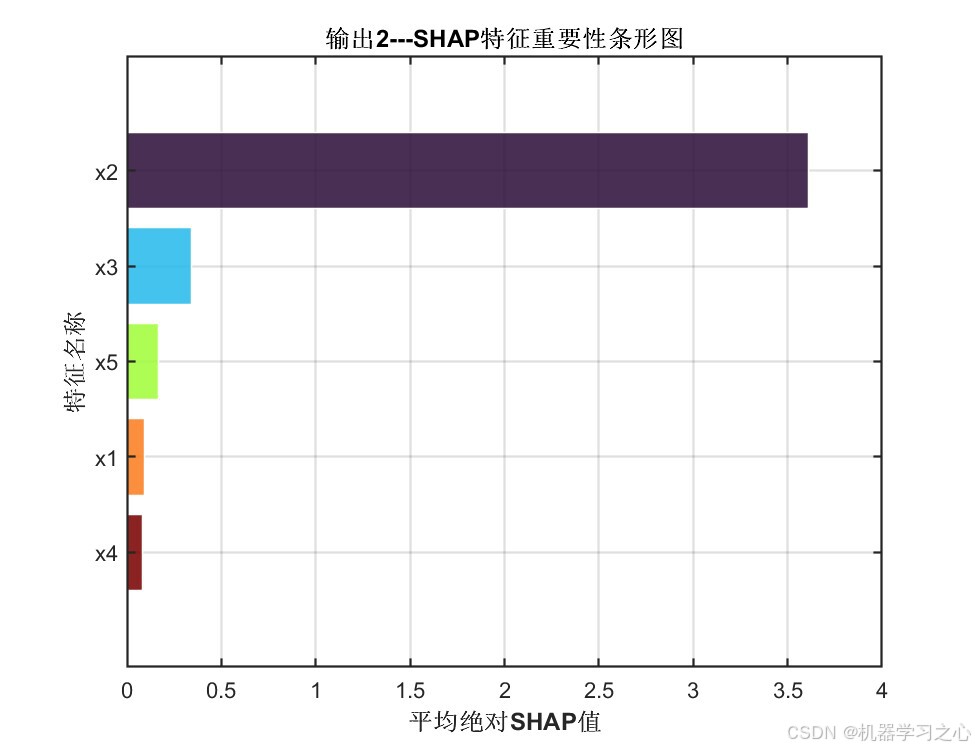
SHAP分析结论:
| 特征 | 输出1平均绝对SHAP值 | 输出2平均绝对SHAP值 | 重要性排序 |
|---|---|---|---|
| x2 | 3.6065 | 3.6125 | 第1位(绝对主导) |
| x3 | 0.3460 | 0.3432 | 第2位 |
| x5 | 0.1698 | 0.1674 | 第3位 |
| x1 | 0.0931 | 0.0946 | 第4位 |
| x4 | 0.0810 | 0.0817 | 第5位 |
- x2 是两个输出的绝对主导特征,SHAP值约为其他特征总和的5倍以上
- x2的SHAP值呈现明显的单调趋势:低值(蓝色)对应负SHAP(降低预测),高值(红色)对应正SHAP(提升预测)
- x3、x5具有中等重要性,x1和x4的影响相对较小
- 两个输出的特征重要性排序几乎一致,说明输入特征对不同目标的影响模式相似
八、应用场景
本系统适用于以下典型场景:
8.1 工业过程预测
- 化工反应多参数预测(温度、压力、产量等)
- 电力负荷多时段预测
- 机械设备多状态参数预测
8.2 环境与能源
- 多污染物浓度预测(PM2.5、NO2、SO2等)
- 新能源发电功率预测(风电、光伏)
- 水质多指标预测
8.3 金融与经济
- 多资产收益率预测
- 宏观经济多指标预测
- 信用风险多维度评估
8.4 农业与生物
- 作物多产量指标预测
- 生物发酵多参数优化
- 药物多响应变量建模
九、使用指南
9.1 快速开始
- 准备数据:将输入特征放前列,输出目标放后列,保存为
回归数据.xlsx - 打开
main.m,设置label选择混沌映射(1-9) - 修改第88行选择优化算法(如
PSO、GWO、WOA等) - 运行
main.m,按提示选择是否打乱样本 - 查看输出图片和Excel结果文件
9.2 切换优化算法
matlab
% 当前使用PSO
[gBestScore,gBest,cg_curve]=PSO(N,Max_iteration,lb,ub,dim,fitness,label);
% 切换为灰狼算法(GWO)
[gBestScore,gBest,cg_curve]=GWO(N,Max_iteration,lb,ub,dim,fitness,label);
% 切换为鲸鱼算法(WOA)
[gBestScore,gBest,cg_curve]=WOA(N,Max_iteration,lb,ub,dim,fitness,label);9.3 新数据预测
将新的输入数据保存为新的多输入.xlsx,运行主程序后自动输出新的输出.xlsx。
十、总结与展望
本文介绍了一套完整的智能优化CNN-LSTM回归预测 + SHAP可解释分析解决方案,核心亮点包括:
- 22种智能算法 + 9种混沌映射 = 198种组合方案,为超参数优化提供丰富选择
- CNN-LSTM混合架构兼顾局部特征提取与长程时序建模
- 多输出支持,不限输入/输出个数,灵活适应各类回归任务
- SHAP可解释分析让"黑箱"模型透明化,量化每个特征的贡献度
- 完整可视化体系:收敛曲线、雷达图、预测对比、误差分析、拟合图、SHAP图
- 新数据预测功能,支持模型部署后的实际应用
未来可拓展方向:
- 引入注意力机制(Attention)增强LSTM的时序聚焦能力
- 结合贝叶斯优化进一步提升超参搜索效率
- 支持GPU加速训练,提升大规模数据处理能力
- 集成更多可解释性方法(LIME、Permutation Importance等)进行交叉验证
代码获取与讨论:欢迎在评论区交流使用心得与改进建议。如需完整代码或遇到运行问题,可留言讨论。