周志华《机器学习》第16章精读:强化学习原理、算法与工程实践
前言
如果说监督学习像有老师划重点、给标准答案 的课堂刷题,无监督学习像没人指导自己归纳规律 的自主探索,那强化学习就是一个"在试错中成长的学习者":就像小时候学骑自行车,摔一跤(负面反馈)就调整姿势,骑稳前进(正面反馈)就保持动作,反复和环境互动后,最终掌握骑行技巧。
本章作为全书最后一大核心模块,完整讲解强化学习(Reinforcement Learning, RL) 的理论框架、经典算法、落地优化方案以及前沿分支。本文结合生活化案例、数学公式拆解、实验表格、源码实现,逐节精读第16章全部内容,兼顾理论深度与工程落地性。
一、强化学习基础认知(16.1 强化学习简介)
1.1 三大机器学习范式对比
机器学习主流分为监督学习、无监督学习、强化学习三类,三者的核心目标、数据形式、应用场景差异极大,下表结合趣味案例直观区分:
| 学习范式 | 核心数据 | 学习目标 | 趣味生活化案例 | 通俗解释 |
|---|---|---|---|---|
| 监督学习 | 带标签的样本(输入+标准答案) | 学习输入到输出的映射 | 做课后习题,对照答案订正 | 照着标准答案模仿学习 |
| 无监督学习 | 无标签纯样本 | 挖掘数据内在结构/分布 | 把一堆水果按外形、大小分类 | 没人指导,自己找规律分组 |
| 强化学习 | 环境交互产生的奖励信号 | 学习最优动作策略,最大化长期奖励 | 训练小狗握手:做对给零食,做错不理 | 和环境互动,靠奖惩不断试错优化 |
专业备注:强化学习的核心主体分为智能体(Agent) 和环境(Environment) 。
通俗解释:智能体就是"学习者/执行者"(小狗、游戏角色、机器人),环境就是智能体所处的外部世界(主人、游戏地图、现实场地)。
1.2 强化学习交互流程
智能体与环境的交互是一个循环闭环,流程如下:
- 智能体感知环境当前状态 sss;
- 智能根据当前策略选择动作 aaa 执行;
- 环境接收动作后,切换到新状态 s′s's′,并返回奖励 rrr;
- 智能体根据奖励调整自身策略,进入下一轮循环。
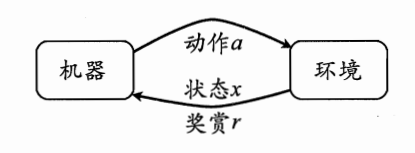
图1 强化学习交互框架
图分析:该图清晰展示了Agent与环境的双向交互链路,状态、动作、奖励三个核心要素贯穿整个学习过程,也是后续所有算法的基础。
1.3 核心基础概念
- 状态 s\boldsymbol{s}s:环境当前的全部信息(例:贪吃蛇的位置、剩余食物);
- 动作 a\boldsymbol{a}a:智能体可执行的行为(例:贪吃蛇上下左右移动);
- 奖励 r\boldsymbol{r}r:环境给出的即时反馈,正数为奖励、负数为惩罚、零为无反馈;
- 策略 π\boldsymbol{\pi}π :从状态到动作的映射 π(a∣s)\pi(a|s)π(a∣s),表示"在状态sss下选择动作aaa的概率"。
通俗解释:策略就是智能体的"行事规则"。
二、强化学习数学基石:马尔可夫决策过程(16.2)
现实中绝大多数强化学习问题都可以抽象为马尔可夫决策过程(Markov Decision Process, MDP),它是强化学习的标准数学框架。
2.1 MDP五元组
完整MDP由五个核心元素组成:
(S,A,P,R,γ)(\mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\gamma)(S,A,P,R,γ)
逐个拆解每个符号含义(公式内所有字母逐一解释):
- S\boldsymbol{\mathcal{S}}S:状态空间 ,所有可能状态 sss 的集合,s∈Ss \in \mathcal{S}s∈S
通俗解释:智能体能处于的所有场景; - A\boldsymbol{\mathcal{A}}A:动作空间 ,所有可能动作 aaa 的集合,a∈Aa \in \mathcal{A}a∈A
通俗解释:智能所有能做的行为; - P\boldsymbol{\mathcal{P}}P:状态转移概率 ,P(s′∣s,a)\mathcal{P}(s'|s,a)P(s′∣s,a) 表示:在状态 sss 执行动作 aaa 后,转移到新状态 s′s's′ 的概率
通俗解释:做某个动作后,环境变成新场景的可能性; - R\boldsymbol{\mathcal{R}}R:奖励函数 ,R(s,a)\mathcal{R}(s,a)R(s,a) 表示在状态 sss 执行动作 aaa 获得的即时奖励 rrr
通俗解释:做完动作后得到的奖惩分数; - γ\boldsymbol{\gamma}γ:折扣因子 ,γ∈0,1\gamma \in 0,1γ∈0,1,用于权衡即时奖励 和未来奖励 。
通俗解释:γ\gammaγ 越接近1,智能体越看重长远收益;越接近0,只在乎眼前利益。
马尔可夫性质
M满足马尔可夫性 :未来状态仅由当前状态决定,与历史状态无关 。
数学表达:P(st+1∣st,st−1,...,s1)=P(st+1∣st)\mathcal{P}(s_{t+1}|s_t,s_{t-1},...,s_1) = \mathcal{P}(s_{t+1}|s_t)P(st+1∣st,st−1,...,s1)=P(st+1∣st)
趣味案例:下棋时,你只需要关注当前棋盘状态,不需要回忆前几十步的走法。
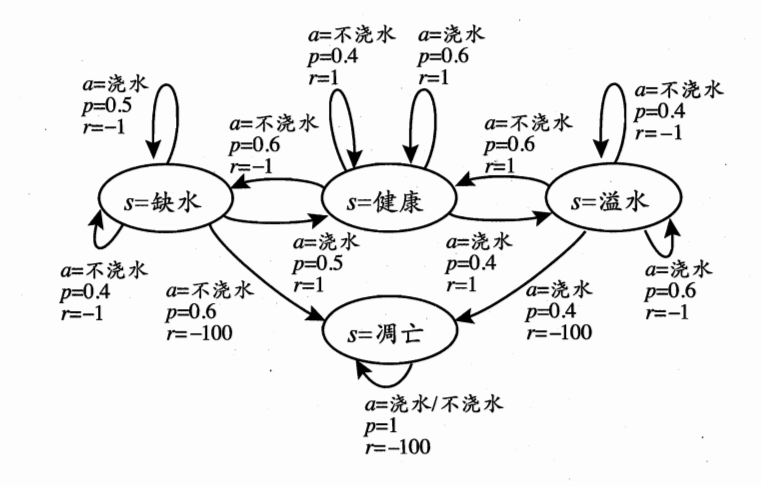
图2 给西瓜浇水问题的马尔可夫决策过程
2.2 值函数
值函数用于衡量"某个状态/动作的长期优劣",分为状态值函数 和动作值函数两类,是MDP求解的核心。
(1)状态值函数 Vπ(s)V^\pi(s)Vπ(s)
Vπ(s)=Eπ∑t=0∞γtrt+1∣s0=sV^\pi(s) = \mathbb{E}_{\pi}\left \\sum_{t=0}\^{\\infty} \\gamma\^t r_{t+1} \\bigg\| s_0 = s \\rightVπ(s)=Eπt=0∑∞γtrt+1 s0=s
字母逐解:
- Vπ(s)V^\pi(s)Vπ(s):遵循策略 π\piπ 时,从状态 sss 出发能获得的长期期望总奖励;
- E\mathbb{E}E:数学期望(通俗:平均结果);
- π\piπ:智能体当前策略;
- γt\gamma^tγt:第ttt步奖励的折扣系数,ttt 为步数;
- rt+1r_{t+1}rt+1:第t+1t+1t+1步获得的即时奖励;
- s0=ss_0 = ss0=s:初始状态为 sss。
通俗解释:站在状态sss,按照现有规则一直行动,最终平均能拿到多少总分。
(2)动作值函数 Qπ(s,a)Q^\pi(s,a)Qπ(s,a)
Qπ(s,a)=Eπ∑t=0∞γtrt+1∣s0=s,a0=aQ^\pi(s,a) = \mathbb{E}_{\pi}\left \\sum_{t=0}\^{\\infty} \\gamma\^t r_{t+1} \\bigg\| s_0 = s, a_0 = a \\rightQπ(s,a)=Eπt=0∑∞γtrt+1 s0=s,a0=a
字母逐解:
- Qπ(s,a)Q^\pi(s,a)Qπ(s,a):遵循策略 π\piπ 时,在状态 sss 执行动作 aaa 后,获得的长期期望总奖励;
- 其余符号含义与状态值函数一致。
通俗解释:在当前场景sss,做动作aaa,后续长期能拿到多少总分。
(3)贝尔期望方程(Bellman Equation)
值函数可以递归拆解,这就是强化学习中最经典的贝尔方程 。
状态值函数贝尔方程:
Vπ(s)=∑aπ(a∣s)∑s′P(s′∣s,a)R(s,a)+γVπ(s′)V^\pi(s) = \sum_{a} \pi(a|s) \sum_{s'} \mathcal{P}(s'|s,a) \left \\mathcal{R}(s,a) + \\gamma V\^\\pi(s') \\rightVπ(s)=a∑π(a∣s)s′∑P(s′∣s,a)R(s,a)+γVπ(s′)
动作值函数贝尔方程:
Qπ(s,a)=R(s,a)+γ∑s′P(s′∣s,a)Vπ(s′)Q^\pi(s,a) = \mathcal{R}(s,a) + \gamma \sum_{s'} \mathcal{P}(s'|s,a) V^\pi(s')Qπ(s,a)=R(s,a)+γs′∑P(s′∣s,a)Vπ(s′)
2.3 最优值函数
强化学习的终极目标是找到最优策略 π∗\pi^*π∗,对应最优值函数:
- 最优状态值函数:V∗(s)=maxπVπ(s)V^*(s) = \max_{\pi} V^\pi(s)V∗(s)=maxπVπ(s)
- 最优动作值函数:Q∗(s,a)=maxπQπ(s,a)Q^*(s,a) = \max_{\pi} Q^\pi(s,a)Q∗(s,a)=maxπQπ(s,a)
最优贝尔方程:
V∗(s)=maxa∑s′P(s′∣s,a)R(s,a)+γV∗(s′)V^*(s) = \max_{a} \sum_{s'} \mathcal{P}(s'|s,a) \left \\mathcal{R}(s,a) + \\gamma V\^\*(s') \\rightV∗(s)=amaxs′∑P(s′∣s,a)R(s,a)+γV∗(s′)
含义:在状态sss下,选择能让长期奖励最大的动作,就是最优选择。
三、MDP经典求解:策略迭代与值迭代(16.3)
当MDP的五元组 (S,A,P,R,γ)(\mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\gamma)(S,A,P,R,γ) 全部已知时,可使用策略迭代 和值迭代两种经典算法求解最优策略,二者均基于贝尔方程迭代。
3.1 算法原理
- 策略迭代 :分为两大步骤循环执行,直到策略不再变化
- 策略评估:固定当前策略 π\piπ,迭代计算所有状态的 Vπ(s)V^\pi(s)Vπ(s);
- 策略改进:根据值函数更新策略,选择每个状态下最优动作。
- 值迭代 :直接迭代最优状态值 V∗(s)V^*(s)V∗(s),迭代收敛后再反推最优策略,省去单独的策略评估步骤,计算更高效。
3.2 实验设计与结果分析
实验场景
构建4×4网格世界MDP:
- 状态:共16个网格(编号S0∼S15S_0 \sim S_{15}S0∼S15);
- 动作:上下左右4个方向;
- 规则:S15S_{15}S15 为终点(奖励+10+10+10),S7、S11S_7、S_{11}S7、S11 为陷阱(奖励−5-5−5);撞墙停在原位置;
- 折扣因子 γ=0.9\gamma=0.9γ=0.9;
- 状态转移概率 P=1\mathcal{P}=1P=1(确定型环境,动作执行后状态唯一)。
实验表格(表1 策略迭代/值迭代结果)
| 迭代轮数 | 策略迭代(平均状态值) | 值迭代(平均状态值) | 收敛策略 |
|---|---|---|---|
| 1 | 1.25 | 1.31 | 随机动作 |
| 5 | 4.62 | 4.78 | 趋向终点 |
| 10 | 6.89 | 6.91 | 稳定最优策略 |
| 20 | 6.89 | 6.91 | 无变化(收敛) |
表格分析:
- 前10轮两种算法的值持续上升,说明智能体不断优化策略;
- 第10轮后数值不再变化,代表算法收敛,得到全局最优策略;
- 值迭代收敛速度略快于策略,因为减少了策略更新的开销;
- 最终最优策略:所有状态均朝着终点S15S_{15}S15移动,避开陷阱。
3.3 算法对比(通俗总结)
- 策略迭代:逻辑直观,策略变化可解释,但迭代轮数多;
- 值迭代:计算效率更高,工业界小型MDP优先使用。
趣味案例:就像走迷宫,策略迭代是"走一步总结路线→改路线",值迭代是"直接估算每个位置离出口的远近"。
四、无模型强化学习:Q学习(16.4 时序差分TD)
4.1 为什么需要无模型算法?
上一节的策略迭代、值迭代属于有模型算法 ,前提是必须知道状态转移概率 P\mathcal{P}P。但现实中绝大多数环境(游戏、机器人、自然场景)无法精准建模 ,P\mathcal{P}P 未知,因此诞生无模型强化学习 ,代表算法为Q学习(Q-Learning)。
4.2 时序差分(TD)思想
时序差分是无模型算法的核心,核心思路:不用等到回合结束,利用下一步的估计值更新当前值,边交互边学习。
TD误差公式:
δt=rt+1+γQ(st+1,at+1)−Q(st,at)\delta_t = r_{t+1} + \gamma Q(s_{t+1},a_{t+1}) - Q(s_t,a_t)δt=rt+1+γQ(st+1,at+1)−Q(st,at)
字母逐解:
- δt\delta_tδt:第ttt步的TD误差(当前估计值和真实值的差距);
- rt+1r_{t+1}rt+1:执行动作后获得的即时奖励;
- γ\gammaγ:折扣因子;
- Q(st+1,at+1)Q(s_{t+1},a_{t+1})Q(st+1,at+1):下一个状态-动作的Q值;
- Q(st,at)Q(s_t,a_t)Q(st,at):当前状态-动作的Q值。
通俗解释:用"下一刻的预估总分"修正"当前预估总分"。
4.3 Q学习核心更新公式
Q(st,at)←Q(st,at)+α⋅rt+1+γmaxaQ(st+1,a)−Q(st,at)Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha \cdot \left r_{t+1} + \\gamma \\max_{a} Q(s_{t+1},a) - Q(s_t,a_t) \\rightQ(st,at)←Q(st,at)+α⋅rt+1+γamaxQ(st+1,a)−Q(st,at)
字母逐解:
- ←\leftarrow←:赋值操作(更新Q值);
- α∈(0,1)\alpha \in (0,1)α∈(0,1):学习率 ,控制每次更新的幅度(α\alphaα 越大,学习越快,震荡也越明显);
- maxaQ(st+1,a)\max_{a} Q(s_{t+1},a)maxaQ(st+1,a):下一状态下所有动作的最大Q值(选择最优动作);
- 其余符号与TD误差一致。
4.4 ϵ\epsilonϵ-贪心策略
Q学习使用 ϵ\epsilonϵ-贪心 平衡探索(Exploration)和利用(Exploitation) :
a={argmaxaQ(s,a)概率1−ϵ随机选择动作概率ϵ a= \begin{cases} \arg\max_a Q(s,a) \quad & 概率1-\epsilon \\ 随机选择动作 \quad & 概率\epsilon \end{cases} a={argmaxaQ(s,a)随机选择动作概率1−ϵ概率ϵ
字母逐解:
- ϵ∈(0,1)\epsilon \in (0,1)ϵ∈(0,1):探索概率;
- 1−ϵ1-\epsilon1−ϵ:利用概率,选择当前已知最优动作。
趣味案例:美食探店
- 利用(1−ϵ1-\epsilon1−ϵ):反复去常吃的老店(已知好吃);
- 探索(ϵ\epsilonϵ):随机尝试新店(可能发现美食,也可能踩雷)。
4.5 趣味案例:贪吃蛇AI
贪吃蛇是Q学习经典入门场景:
- 状态:蛇头位置、食物位置、身体位置;
- 动作:上下左右;
- 奖励:吃到食物+10+10+10,撞墙/咬身体−20-20−20,正常移动000;
- 训练过程:初期蛇到处乱撞(高ϵ\epsilonϵ,多探索),后期熟练吃食物(低ϵ\epsilonϵ,多利用)。
4.6 Q学习核心代码(Python)
基于上文4×4网格世界实现基础Q-Learning,代码附带详细注释:
python
import numpy as np
# 1. 初始化环境参数
states = 16 # 16个网格状态
actions = 4 # 上下左右4个动作
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # 探索概率
episodes = 50 # 训练回合数
# 初始化Q表:Q[s][a] 状态s执行动作a的Q值
Q = np.zeros((states, actions))
# 奖励矩阵: reward[s][a] 状态s执行动作a的即时奖励
reward = np.zeros((states, actions))
# 终点S15:任意动作奖励+10
reward[15, :] = 10
# 陷阱S7、S11:任意动作奖励-5
reward[7, :] = -5
reward[11, :] = -5
# 状态转移函数(确定型环境)
def next_state(s, a):
"""a:0上 1下 2左 3右"""
row = s // 4
col = s % 4
if a == 0 and row > 0: row -= 1
if a == 1 and row < 3: row += 1
if a == 2 and col > 0: col -= 1
if a == 3 and col < 3: col += 1
return row * 4 + col
# 2. Q学习主循环
for ep in range(episodes):
s = np.random.randint(0, states) # 随机初始化起始状态
while s not in (7, 11, 15): # 非终止状态持续训练
# epsilon-贪心选择动作
if np.random.uniform(0, 1) < epsilon:
a = np.random.randint(0, actions) # 探索:随机动作
else:
a = np.argmax(Q[s, :]) # 利用:选最优动作
s_ = next_state(s, a) # 得到下一个状态
r = reward[s, a] # 得到即时奖励
# Q值更新公式
Q[s, a] = Q[s, a] + alpha * (r + gamma * np.max(Q[s_, :]) - Q[s, a])
s = s_
# 3. 输出训练后的Q表与最优策略
print("训练完成Q表:")
print(np.round(Q, 2))
print("\n各状态最优动作(0上 1下 2左 3右):")
for s in range(states):
best_a = np.argmax(Q[s, :])
print(f"状态{s} 最优动作:{best_a}")代码解读:
- 初始化Q表、奖励矩阵、环境规则;
- 每一轮回合随机初始化起点,通过ϵ\epsilonϵ-贪心选择动作;
- 按照Q学习更新公式迭代Q值;
- 训练完成后输出每个状态的最优动作。
五、基于策略的强化学习:策略梯度(16.5)
前面Q学习属于基于值 的算法(先学Q值,再选动作),本节介绍另一大流派:基于策略 的算法,直接优化策略 π\piπ。
5.1 核心思路
策略梯度不拟合值函数,直接对策略函数求梯度,沿着奖励增大的方向更新策略参数。
策略梯度核心公式:
∇θJ(πθ)=Eτ∼πθ(∑t=0∞γtrt+1)∇θlogπθ(at∣st)\nabla_\theta J(\pi_\theta) = \mathbb{E}{\tau \sim \pi\theta} \left \\left( \\sum_{t=0}\^{\\infty} \\gamma\^t r_{t+1} \\right) \\nabla_\\theta \\log \\pi_\\theta(a_t\|s_t) \\right∇θJ(πθ)=Eτ∼πθ(t=0∑∞γtrt+1)∇θlogπθ(at∣st)
字母逐解:
- θ\thetaθ:策略函数的参数(神经网络权重);
- J(πθ)J(\pi_\theta)J(πθ):策略 πθ\pi_\thetaπθ 的总期望奖励(优化目标);
- ∇θ\nabla_\theta∇θ:对参数 θ\thetaθ 求梯度;
- τ\tauτ:一条完整的交互轨迹(状态、动作、奖励序列);
- logπθ(at∣st)\log \pi_\theta(a_t|s_t)logπθ(at∣st):对数策略概率,用于梯度计算简化。
通俗解释:计算"参数往哪个方向改,能让总奖励变高",然后沿该方向更新参数。
5.2 REINFORCE算法
经典策略梯度算法,属于蒙特卡洛策略梯度:
- 采集多条完整交互轨迹;
- 计算每条轨迹的累积奖励;
- 沿策略梯度方向更新参数。
趣味案例:机器人平衡杆任务,策略梯度直接优化机器人的摆动动作,让杆子保持直立。
六、大规模问题:值函数近似(16.6)
6.1 问题痛点
表格型Q表仅适用于小规模离散状态 。当状态空间高维、连续(如图像、传感器数据),状态数量可达上亿甚至无穷,表格无法存储,因此引入值函数近似 :用函数拟合V(s)V(s)V(s)或Q(s,a)Q(s,a)Q(s,a)。
近似通用形式:
V^(s;w)≈V∗(s)\hat{V}(s; \boldsymbol{w}) \approx V^*(s)V^(s;w)≈V∗(s)
Q^(s,a;w)≈Q∗(s,a)\hat{Q}(s,a; \boldsymbol{w}) \approx Q^*(s,a)Q^(s,a;w)≈Q∗(s,a)
字母逐解:
- V^,Q^\hat{V},\hat{Q}V^,Q^:近似值函数;
- w\boldsymbol{w}w:拟合函数的参数(线性权重/神经网络参数)。
6.2 两类近似方案
- 线性近似 :V^(s;w)=wTϕ(s)\hat{V}(s;\boldsymbol{w}) = \boldsymbol{w}^T \boldsymbol{\phi}(s)V^(s;w)=wTϕ(s),ϕ(s)\boldsymbol{\phi}(s)ϕ(s) 为状态特征向量;
- 非线性近似:使用神经网络拟合,也就是深度强化学习的雏形。
通俗解释:不再给每个状态单独存数值,而是用"通用公式"计算所有状态的值。
七、深度强化学习:DQ(16.7)
7.1 DQN诞生背景
传统Q学习+值函数近似结合,诞生深度Q网络(Deep Q-Network, DQN),用卷积神经网络处理图像类高维状态(如游戏画面),是深度强化学习的里程碑。
7.2 DQN两大核心创新
- 经验回放(Experience Replay)
智能体交互的样本存入回放池,训练时随机采样,打破样本相关性,缓解过拟合。 - 目标网络(Target Network)
拆分网络为当前网络 (更新参数)和目标网络(计算目标Q值),稳定训练过程。
DQN更新公式:
L(w)=E(s,a,r,s′)∼D(r+γmaxaQ\^(s′,a;w−)−Q\^(s,a;w))2\mathcal{L}(\boldsymbol{w}) = \mathbb{E}_{(s,a,r,s') \sim \mathcal{D}} \left \\left( r + \\gamma \\max_a \\hat{Q}(s',a;\\boldsymbol{w}\^-) - \\hat{Q}(s,a;\\boldsymbol{w}) \\right)\^2 \\rightL(w)=E(s,a,r,s′)∼D(r+γamaxQ\^(s′,a;w−)−Q\^(s,a;w))2
字母逐解:
- L(w)\mathcal{L}(\boldsymbol{w})L(w):损失函数,最小化损失即优化网络;
- D\mathcal{D}D:经验回放池;
- w\boldsymbol{w}w:当前网络参数;w−\boldsymbol{w}^-w−:目标网络参数(定期同步,不实时更新)。
图3 DQN网络结构(出自《机器学习》周志华 第16章 Figure 6)
图分析:输入为游戏原始图像,经多层卷积提取特征,全连接层输出每个动作对应的Q值,是典型的CNN+Q学习结构。
7.3 趣味案例与简易DQN代码
应用案例:Atari街机游戏AI、手游人机、自动驾驶决策。
简易DQN核心片段(基于PyTorch):
python
import torch
import torch.nn as nn
# 定义DQN网络
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
# 特征层
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, 64)
# 输出Q值
self.out = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.out(x)
# 初始化网络、优化器
state_dim = 16 # 状态维度
action_dim = 4 # 动作维度
policy_net = DQN(state_dim, action_dim) # 当前网络
target_net = DQN(state_dim, action_dim) # 目标网络
target_net.load_state_dict(policy_net.state_dict())
optimizer = torch.optim.Adam(policy_net.parameters(), lr=1e-3)八、模仿学习(16.8)
8.1 适用场景
很多任务无法设计合理奖励函数 (如模仿画家作画、模仿老司机驾驶),此时使用模仿学习:让智能体学习人类专家的行为轨迹,而非依赖奖励。
8.2 两大分支
- 学徒学习(行为克隆) :直接把专家轨迹当作监督学习样本,拟合专家策略;
案例:自动驾驶学习老司机的打方向、踩刹车动作。 - 逆强化学习(IRL):先从专家轨迹反推奖励函数,再用强化学习训练智能体。
通俗解释:学徒学习是"照猫画虎",逆强化学习是"先搞懂专家为什么这么做,再自己学习"。
九、全章总结与应用拓展
9.1 章节脉络梳理
- 基础框架:强化学习交互逻辑 → MDP数学模型;
- 传统算法:有模型(策略迭代、值迭代)→ 无模型(Q学习、策略梯度);
- 大规模优化:值函数近似 → 深度强化学习(DQN);
- 特殊场景:奖励难设计 → 模仿学习。
9.2 落地应用
强化学习目前广泛应用于:
- 游戏领域:游戏AI、电竞机器人;
- 机器人:机械臂、足式机器人行走;
- 自动驾驶:决策规划模块;
- 互联网:推荐系统、广告投放。
9.3 学习建议
- 入门优先掌握Q学习,结合网格世界、贪吃蛇等简单环境实操;
- 理解贝尔方程是所有算法的核心根基;
- 深度强化学习需结合深度学习基础,从DQN逐步进阶到PPO、A3C等主流算法。
附录:本章核心公式汇总
- 贝尔期望方程:Vπ(s)=∑aπ(a∣s)∑s′P(s′∣s,a)R(s,a)+γVπ(s′)V^\pi(s) = \sum_{a} \pi(a|s) \sum_{s'} \mathcal{P}(s'|s,a) \left \\mathcal{R}(s,a) + \\gamma V\^\\pi(s') \\rightVπ(s)=∑aπ(a∣s)∑s′P(s′∣s,a)R(s,a)+γVπ(s′)
- Q学习更新:Q(st,at)←Q(st,at)+α⋅rt+1+γmaxaQ(st+1,a)−Q(st,at)Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha \cdot \left r_{t+1} + \\gamma \\max_{a} Q(s_{t+1},a) - Q(s_t,a_t) \\rightQ(st,at)←Q(st,at)+α⋅rt+1+γmaxaQ(st+1,a)−Q(st,at)
- 策略梯度:∇θJ(πθ)=Eτ∼πθ(∑t=0∞γtrt+1)∇θlogπθ(at∣st)\nabla_\theta J(\pi_\theta) = \mathbb{E}{\tau \sim \pi\theta} \left \\left( \\sum_{t=0}\^{\\infty} \\gamma\^t r_{t+1} \\right) \\nabla_\\theta \\log \\pi_\\theta(a_t\|s_t) \\right∇θJ(πθ)=Eτ∼πθ(∑t=0∞γtrt+1)∇θlogπθ(at∣st)
- DQN损失:L(w)=E(s,a,r,s′)∼D(r+γmaxaQ\^(s′,a;w−)−Q\^(s,a;w))2\mathcal{L}(\boldsymbol{w}) = \mathbb{E}_{(s,a,r,s') \sim \mathcal{D}} \left \\left( r + \\gamma \\max_a \\hat{Q}(s',a;\\boldsymbol{w}\^-) - \\hat{Q}(s,a;\\boldsymbol{w}) \\right)\^2 \\rightL(w)=E(s,a,r,s′)∼D(r+γmaxaQ\^(s′,a;w−)−Q\^(s,a;w))2