目录
[Callable 接⼝](#Callable 接⼝)
[ReentrantLock 和 synchronized 的区别](#ReentrantLock 和 synchronized 的区别)
2) ConcurrentHashMap ConcurrentHashMap)
JUC常⻅类
JUC(java.util.concurrent) 的 常⻅类
Callable 接⼝
Callable接口 是与Runnable接口 并行关系
相当于把线程封装了⼀个**"返回值"**.⽅便程序借助多线程的⽅式计算结果
java
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int result = 0;
for (int i = 1; i <= 100; i++) {
result += i;
}
return result;
}
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask);
t.start();
System.out.println(futureTask.get());thread 本身不具有获取结果的方法 所以 futureTask 对象获取结果
此外
Callable 和 Runnable相对,都是描述⼀个"任务".Callable描述的是带有返回值 的任务,Runnable 描述的是不带返回值的任务.
Callable 通常需要搭配 FutureTask 来使⽤.FutureTask⽤来保存Callable的返回结果.因为 Callable 往往是在另⼀个线程中执⾏的,执⾏完并不确定.
FutureTask 就可以负责这个等待结果出来的⼯作.
ReentrantLock
可重⼊互斥锁(与synchronized类似,都是实现互斥效果 并 保证线程安全的)
ReentrantLock 有以下三种常见的方法 :
- lock(): 加锁,如果获取不到锁就死等.
2**.**trylock(超时时间): 加锁,如果获取不到锁,等待⼀定的时间之后就放弃加锁
- unlock(): 解锁
ReentrantLock 和 synchronized 的区别
其一 JVM内外实现的差别synchronized 是⼀个关键字 是JVM 内部实现的
ReentrantLock 是标准库的⼀个类,在JVM外实现的
其二 对待阻塞的区别 synchronized 在申请锁失败时,会死等
但是 ReentrantLock 会可以使用 trylock 等待⼀定的时间之后就放弃加锁
其三 锁的类别 synchronized 是⾮公平锁,
ReentrantLock默认是⾮公平锁.可以通过构造⽅法传⼊⼀个true开启 公平锁模式.
其四 synchronized使⽤时不需要⼿动释放锁.
ReentrantLock使⽤时需要⼿动释放.使⽤起来更灵活,但 是也容易遗漏 unlock.
其Ⅴ 更强的唤醒机制 synchronized 是通过 Object 的 wait/notify 实现等待-唤醒 每次唤醒的是 ⼀ 个 随机等待 的线程
ReentrantLock搭配 Condition类 实现等待-唤醒,可以更精确控制 唤醒某个 指定的线程.
信号量Semaphore
信号量,⽤来表⽰ "可⽤资源的个数" . 本质上就是⼀个 计数器.
CountDownLatch
同时等待N个任务执⾏结束.
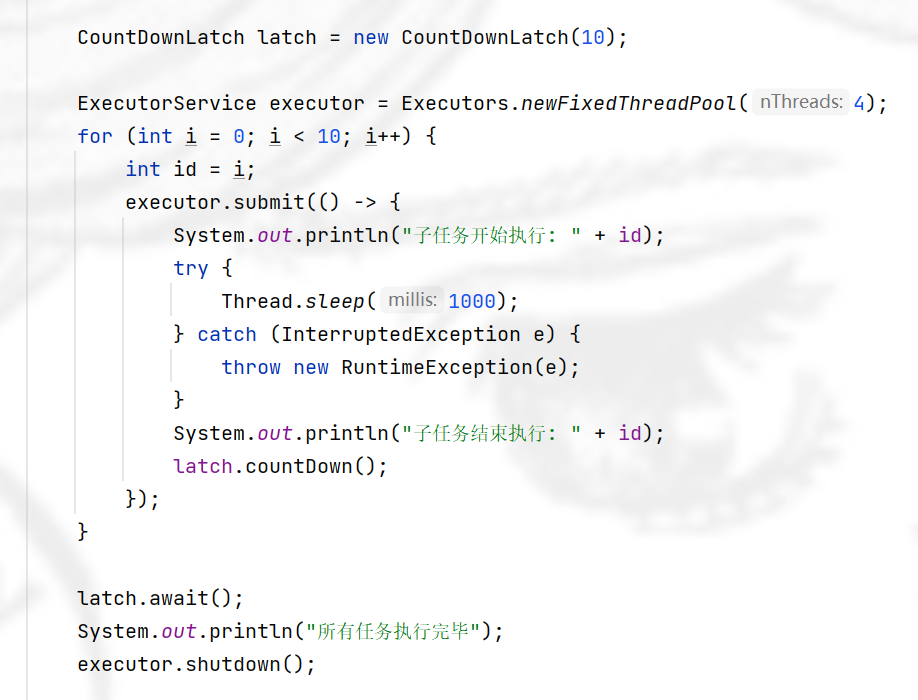
每个任务执⾏完毕 在 CountDownLatch 内部的计数器同时⾃增
线程安全的集合类
多线程环境使⽤ArrayList
1) 自行完成加锁 (synchronized或者ReentrantLock)
要分析 代码 将其打包成 '原子' 再进行加锁
2) Collections.synchronizedList(new ArrayList);
本质作为 套壳 像是Vector, Stack, HashTable 内含有synchronized
3)使⽤CopyOnWriteArrayList
CopyOnWrite容器(写时复制的容器)
当想在容器内添加新数据时 不是选择直接加入 而是先copy 一个新的容器在其添加数据
添加完元素之后,再将原容器的引⽤指向新的容器
优
读多写少 的场景下, 性能很⾼,不需要加锁竞争反之会非常低效
缺
占⽤内存较多. 新写的数据不能被第⼀时间读取到.
也是显然易见的
多线程环境使⽤队列
1)ArrayBlockingQueue
基于数组实现的阻塞队列
2)LinkedBlockingQueue
基于链表实现的阻塞队列
3)PriorityBlockingQueue
基于堆实现的带优先级的阻塞队列
4)TransferQueue
最多只包含⼀个元素的阻塞队列
多线程环境使⽤哈希表
HashMap本⾝不是线程安全的.
但是多线程中使用 哈希表仅此为二
Hashtable
只是简单的把关键⽅法加上了 synchronized 关键字.
相当于直接针对 Hashtable对象本⾝加锁.
所以多线程中 访问同⼀个 Hashtable 就会直接造成 锁冲突
此外 size属性 也是通过 synchronized 来控制同步,是⽐较慢的
如果⼀旦触发扩容,就由该线程完成整个扩容过程.
这个过程会涉及到⼤量的元素拷⻉,效率会⾮常低
但是 实际上 两个线程恰巧同时访问一个链表的概率是比较低的
ConcurrentHashMap
相⽐于 Hashtable做出了⼀系列的改进和优化
- 简单说 锁对象不在是单个对象
而是锁整个对象,⽽是**"锁桶"** (⽤每个链表的头结点作为锁对象),⼤⼤ 降低了锁冲突的概率
读操作没有加锁(但是使⽤了volatile保证从内存读取结果),只对写操作进⾏加锁
- 充分利⽤CAS特性
使用原子类对 size类型进行维护
size属性通过CAS来更新.避免出现重量级锁的情况
- 优化了扩容⽅式 化整为零
发现需要扩容的线程,只需要 创建⼀个新的数组,同时只搬⼏个元素过去.
分次多批的搬运减少耗时
每个来操作ConcurrentHashMap的线程,都会参与搬家的过程.每个操作负责搬运⼀⼩部分元素.
新老数组同时存在 查询时二者一起查询 添加数据仅仅存放到新数组中
当搬完最后⼀个元素再把 ⽼数组 删掉.
over